容器库(12)-std::unordered_multiset
unordered_multiset是以key为元素无序的关联容器,搜索、移除和插入操作是平均常数的时间复杂度。unordered_multiset在内部没有按任何顺序排列,而是放在桶当中的,放进哪个桶是通过计算key的hash值来决定的。和unordered_set不同的是,unordered_multiset中的key值可以重复。
template<class Key,class Hash = std::hash<Key>,class KeyEqual = std::equal_to<Key>,class Allocator = std::allocator<Key>
> class unordered_multiset;本文章的代码库:
https://gitee.com/gamestorm577/CppStd
成员函数
构造、析构和赋值
构造函数
可以构造一个空的unordered_multiset,也可以用迭代器、另一个unordered_multiset或者元素列表来构造一个unordered_multiset。构造的时候还可以指定最小桶数、hash函数、比较函数或者分配器。代码示例:
std::vector<int> tmp{1, 1, 2, 3};std::unordered_multiset<int> s1;
std::unordered_multiset<int> s2(tmp.begin(), tmp.end());
std::unordered_multiset<int> s3(s2);
std::unordered_multiset<int> s4{1, 2, 3};std::cout << "s1 size = " << s1.size() << std::endl;
std::cout << "s2 size = " << s2.size() << std::endl;
std::cout << "s3 size = " << s3.size() << std::endl;
std::cout << "s4 size = " << s4.size() << std::endl;输出结果:
s1 size = 0
s2 size = 4
s3 size = 4
s4 size = 3对于自定义的类型,需要定义hash函数以及比较函数。代码示例:
struct MyStruct
{int Num1;double Num2;
};struct MyHash
{std::size_t operator()(const MyStruct& val) const{return std::hash<int>()(val.Num1) + std::hash<double>()(val.Num2);}
};struct MyEqual
{bool operator()(const MyStruct& lhs, const MyStruct& rhs) const{return true;}
};std::unordered_multiset<MyStruct, MyHash, MyEqual> s;析构函数
销毁容器时,会调用各元素的析构函数。代码示例:
struct MyStruct
{MyStruct(int i): Num(i){}~MyStruct(){std::cout << "destruct, Num = " << Num << std::endl;}int Num = 0;
};struct MyHash
{std::size_t operator()(const MyStruct& val) const{return std::hash<int>()(val.Num);}
};struct MyEqual
{bool operator()(const MyStruct& lhs, const MyStruct& rhs) const{return lhs.Num == rhs.Num;}
};std::unordered_multiset<MyStruct, MyHash, MyEqual> s{1, 1, 2, 3};
std::cout << "end" << std::endl;输出结果:
destruct, Num = 3
destruct, Num = 2
destruct, Num = 1
destruct, Num = 1
end
destruct, Num = 3
destruct, Num = 2
destruct, Num = 1
destruct, Num = 1赋值函数
可以用另一个unordered_multiset或者元素列表给unordered_multiset赋值。代码示例:
std::unordered_multiset<int> tmp{1, 1, 2};
std::unordered_multiset<int> s1;
std::unordered_multiset<int> s2;
s1 = tmp;
s2 = {1, 1, 2, 3};
std::cout << "s1 size = " << s1.size() << std::endl;
std::cout << "s2 size = " << s2.size() << std::endl;输出结果:
s1 size = 3
s2 size = 4迭代器
接口begin、cbegin指向unordered_multiset起始的迭代器,end、cend指向末尾的迭代器。无论什么迭代器都不能修改元素的值。代码示例:
std::unordered_multiset<int> s{1, 1, 2, 3};
for (auto iter = s.begin(); iter != s.end(); ++iter)
{std::cout << "num = " << *iter << std::endl;
}输出结果:
num = 3
num = 2
num = 1
num = 1容量
empty
检查unordered_multiset是否为空。代码示例:
std::unordered_multiset<int> s1{1, 1, 2};
std::unordered_multiset<int> s2;
std::cout << std::boolalpha;
std::cout << "s1 empty: " << s1.empty() << std::endl;
std::cout << "s2 empty: " << s2.empty() << std::endl;输出结果:
s1 empty: false
s2 empty: truesize
获取unordered_multiset的元素个数。代码示例:
std::unordered_multiset<int> s1{1, 1, 2};
std::unordered_multiset<int> s2;
std::cout << "s1 size: " << s1.size() << std::endl;
std::cout << "s2 size: " << s2.size() << std::endl;输出结果:
s1 size: 3
s2 size: 0max_size
返回可以容纳的最大元素个数。代码示例:
std::unordered_multiset<char> s1;
std::unordered_multiset<std::string> s2;
std::cout << "s1 max size = " << s1.max_size() << std::endl;
std::cout << "s2 max size = " << s2.max_size() << std::endl;输出结果:
s1 max size = 768614336404564650
s2 max size = 461168601842738790修改器
clear
清除所有的元素。代码示例:
std::unordered_multiset<int> s{1, 1, 2, 3};
std::cout << "s size = " << s.size() << std::endl;
s.clear();
std::cout << "s size = " << s.size() << std::endl;输出结果:
s size = 4
s size = 0insert
插入元素,参数可以是元素、迭代器或者元素节点。代码示例:
std::unordered_multiset<int> s;s.insert(1);
s.insert(1);
std::cout << "s size = " << s.size() << std::endl;std::vector<int> tmp{2, 2, 3};
s.insert(tmp.begin(), tmp.end());
std::cout << "s size = " << s.size() << std::endl;输出结果:
s size = 2
s size = 5emplace
构造一个元素到容器中。代码示例:
struct MyStruct
{MyStruct(int num1, int num2): Num1(num1), Num2(num2){std::cout << "construct: " << num1 << " " << num2 << std::endl;}int Num1 = 0;int Num2 = 0;
};struct MyHash
{std::size_t operator()(const MyStruct& val) const{return std::hash<int>()(val.Num1) + std::hash<int>()(val.Num2);}
};struct MyEqual
{bool operator()(const MyStruct& lhs, const MyStruct& rhs) const{return (lhs.Num1 == rhs.Num1) && (lhs.Num2 == rhs.Num2);}
};std::unordered_multiset<MyStruct, MyHash, MyEqual> s;
s.emplace(1, 1);
s.emplace(1, 2);
s.emplace(1, 2);输出结果:
construct: 1 1
construct: 1 2
construct: 1 2emplace_hint
向容器中尽可能靠近hint之前的位置插入新元素:
template <class... Args>
iterator emplace_hint(const_iterator hint, Args&&... args);不同的hint会导致插入元素的效率不同。代码示例:
auto timer = [](std::function<std::size_t()> func, std::string tag) -> void
{auto start = std::chrono::system_clock::now();std::size_t size = func();auto end = std::chrono::system_clock::now();std::chrono::duration<double, std::milli> time = end - start;std::cout << tag << ", size: " << size << ", use time: " << time.count()<< std::endl;
};const int count = 3000000;auto unordered_multiset_emplace = [=]() -> std::size_t
{std::unordered_multiset<int> s;for (int i = 0; i < count; ++i){s.emplace(i);}return s.size();
};auto unordered_multiset_emplace_hint1 = [=]() -> std::size_t
{std::unordered_set<int> s;auto iter = s.begin();for (int i = 0; i < count; ++i){s.emplace_hint(iter, i);iter = s.end();}return s.size();
};auto unordered_multiset_emplace_hint2 = [=]() -> std::size_t
{std::unordered_set<int> s;auto iter = s.begin();for (int i = 0; i < count; ++i){s.emplace_hint(iter, i);iter = s.begin();}return s.size();
};auto unordered_multiset_emplace_hint3 = [=]() -> std::size_t
{std::unordered_set<int> s;auto iter = s.begin();for (int i = 0; i < count; ++i){iter = s.emplace_hint(iter, i);}return s.size();
};timer(unordered_multiset_emplace, "unordered_multiset_emplace");
timer(unordered_multiset_emplace_hint1, "unordered_multiset_emplace_hint1");
timer(unordered_multiset_emplace_hint2, "unordered_multiset_emplace_hint2");
timer(unordered_multiset_emplace_hint3, "unordered_multiset_emplace_hint3");输出结果:
unordered_multiset_emplace, size: 3000000, use time: 498.258
unordered_multiset_emplace_hint1, size: 3000000, use time: 511.267
unordered_multiset_emplace_hint2, size: 3000000, use time: 499.438
unordered_multiset_emplace_hint3, size: 3000000, use time: 474.257erase
移除指定位置的元素或者移除指定的值。代码示例:
std::unordered_multiset<int> s1{1, 1, 2, 2, 3, 3, 3, 4, 4};
std::cout << "s1 size = " << s1.size() << std::endl;
s1.erase(s1.begin());
std::cout << "s1 size = " << s1.size() << std::endl;
s1.erase(s1.begin(), std::next(s1.begin(), 3));
std::cout << "s1 size = " << s1.size() << std::endl;std::unordered_multiset<int> s2{1, 1, 3, 3, 3};
std::cout << "s2 size = " << s2.size() << std::endl;
s2.erase(3);
std::cout << "s2 size = " << s2.size() << std::endl;输出结果:
s1 size = 9
s1 size = 8
s1 size = 5
s2 size = 5
s2 size = 2swap
和另一个容器交换元素内容。代码示例:
std::unordered_multiset<int> s1{1, 1, 2, 2};
std::unordered_multiset<int> s2{1, 1};
s1.swap(s2);
std::cout << "s1 size = " << s1.size() << std::endl;
std::cout << "s2 size = " << s2.size() << std::endl;输出结果:
s1 size = 2
s2 size = 4extract
提取容器中的某个元素节点,提取后容器不再拥有该元素。代码示例:
std::unordered_multiset<int> s{1, 1, 2, 3, 4};
std::cout << "s size = " << s.size() << std::endl;
auto node1 = s.extract(1);
std::cout << "s size = " << s.size() << std::endl;
auto node2 = s.extract(s.begin());
std::cout << "s size = " << s.size() << ", node2 = " << node2.value()<< std::endl;
s.insert(std::move(node2));
std::cout << "s size = " << s.size() << std::endl;输出结果:
s size = 5
s size = 4
s size = 3, node2 = 4
s size = 4merge
合并另一个unordered_set或者unordered_multiset中的元素。代码示例:
std::unordered_multiset<int> s1{1, 1, 2};
std::unordered_multiset<int> s2{1, 2};
s1.merge(s2);
std::cout << "s1 size = " << s1.size() << std::endl;
std::cout << "s2 size = " << s2.size() << std::endl;输出结果:
s1 size = 5
s2 size = 0查找
count
获取给定key值的元素数量。代码示例:
std::unordered_multiset<int> s{1, 1, 2, 3};
std::cout << "elment 1 count = " << s.count(1) << std::endl;
std::cout << "elment 2 count = " << s.count(2) << std::endl;
std::cout << "elment 4 count = " << s.count(4) << std::endl;输出结果:
elment 1 count = 2
elment 2 count = 1
elment 4 count = 0find
获取指定key值的元素的迭代器。如果有多个元素匹配key值,那么返回任意一个。代码示例:
std::unordered_multiset<int> s{1, 1, 2, 3};
auto iter1 = s.find(1);
auto iter2 = s.find(4);
std::cout << std::boolalpha;
std::cout << "elment has 1: " << (iter1 == s.end()) << std::endl;
std::cout << "elment has 4: " << (iter2 == s.end()) << std::endl;输出结果:
elment has 1: false
elment has 4: truecontains
检查是否包含特定的元素。代码示例:
std::unordered_multiset<int> s{1, 1, 2, 3};
std::cout << std::boolalpha;
std::cout << "contain 1: " << s.contains(1) << std::endl;
std::cout << "contain 4: " << s.contains(4) << std::endl;输出结果:
contain 1: true
contain 4: falseequal_range
获取容器中等于给定key值的元素范围。返回第一个迭代器指向范围的首元素,第二个迭代器指向范围的最后一个元素后面的位置。代码示例:
std::unordered_multiset<int> s{1, 1, 2, 3, 3, 4};
for (auto item : s)
{std::cout << item << " ";
}
std::cout << std::endl;
auto [iter1, iter2] = s.equal_range(3);
std::cout << "iter1 = " << *iter1 << std::endl;
std::cout << "iter2 = " << *iter2 << std::endl;桶接口
bucket_count
返回unordered_multiset的桶数量。代码示例:
std::unordered_multiset<int> s{1, 1, 2, 3, 3, 3, 3};
std::cout << "bucket count = " << s.bucket_count() << std::endl;输出结果:
bucket count = 11max_bucket_count
返回unordered_multiset可以容纳的最大桶数量。代码示例:
std::unordered_multiset<int> s1;
std::unordered_multiset<std::string> s2;
std::cout << "s1 max bucket count: " << s1.max_bucket_count() << std::endl;
std::cout << "s2 max bucket count: " << s2.max_bucket_count() << std::endl;输出结果:
s1 max bucket count: 768614336404564650
s2 max bucket count: 461168601842738790bucket_size
范围特定桶中的元素数量。代码示例:
std::unordered_multiset<int> s{1, 1, 1, 2, 2, 2, 3, 3};
for (int i = 0; i < s.bucket_count(); ++i)
{std::cout << "bucket " << i << " has item num " << s.bucket_size(i)<< std::endl;
}输出结果:
bucket 0 has item num 0
bucket 1 has item num 3
bucket 2 has item num 3
bucket 3 has item num 2
bucket 4 has item num 0
bucket 5 has item num 0
bucket 6 has item num 0
bucket 7 has item num 0
bucket 8 has item num 0
bucket 9 has item num 0
bucket 10 has item num 0bucket
返回给定key值的元素所在桶的索引。代码示例:
std::unordered_multiset<int> s{11, 11, 13, 13, 13, 14, 14, 15};
auto n = s.bucket(13);
std::cout << "item 13 is in bucket " << n << std::endl;输出结果:
item 13 is in bucket 2begin、cbegin、end、cend
begin和cbegin返回索引为n的桶中的首个元素的迭代器。end和cend返回索引为n的桶中的末尾迭代器。代码示例:
std::unordered_multiset<int> s{11, 11, 13, 13, 13, 14, 14, 15};
auto cnt = s.bucket(13);
auto iter_begin = s.begin(cnt);
auto iter_end = s.end(cnt);
for (auto iter = iter_begin; iter != iter_end; ++iter)
{std::cout << "num = " << *iter << std::endl;
}输出结果:
num = 13
num = 13
num = 13哈希策略
load_factor
返回每个桶的平均元素数量。代码示例:
std::unordered_multiset<int> s{1, 1, 2, 3};
float num = s.load_factor();
std::cout << "load factor is: " << num << std::endl;输出结果:
load factor is: 0.8max_load_factor
没有参数的情况下返回每个桶的最大平均元素数。参数为float类型时设置每个桶的最大平均元素数,如果超出了该数量,容器就会自己增加桶数。代码示例:
int n_count = 200;std::unordered_multiset<int> s1;
s1.max_load_factor(1);
for (int i = 0; i < n_count; ++i)
{s1.insert(i);
}
std::cout << "s1 max load factor is: " << s1.max_load_factor() << std::endl;
std::cout << "s1 bucket count: " << s1.bucket_count() << std::endl;std::unordered_multiset<int> s2;
s2.max_load_factor(20);
for (int i = 0; i < n_count; ++i)
{s2.insert(i);
}
std::cout << "s2 max load factor is: " << s2.max_load_factor() << std::endl;
std::cout << "s2 bucket count: " << s2.bucket_count() << std::endl;输出结果:
s1 max load factor is: 1
s1 bucket count: 397
s2 max load factor is: 20
s2 bucket count: 11rehash
设置桶的最小数量并重新散列容器。代码示例:
std::unordered_multiset<int> s;
for (int i = 0; i < 200; ++i)
{s.insert(i);
}
std::cout << "bucket cnt: " << s.bucket_count() << std::endl;s.rehash(s.bucket_count() / 2);
std::cout << "bucket cnt: " << s.bucket_count() << std::endl;
s.rehash(s.bucket_count() * 4);
std::cout << "bucket cnt: " << s.bucket_count() << std::endl;输出结果:
bucket cnt: 397
bucket cnt: 211
bucket cnt: 853reserve
设置桶的最小元素个数,并重新散列容器。重新散列后的容器的平均桶数不能超过设定的值。代码示例:
std::unordered_multiset<int> s;
for (int i = 0; i < 200; ++i)
{s.insert(i);
}
std::cout << "bucket cnt: " << s.load_factor() << std::endl;s.reserve(5);
std::cout << "bucket cnt: " << s.load_factor() << std::endl;输出结果:
bucket cnt: 0.503778
bucket cnt: 0.947867观察器
hash_function
返回计算hash值的函数。代码示例:
std::unordered_multiset<std::string> s;
auto hash_func = s.hash_function();
std::cout << "hash is: " << hash_func("hello world") << std::endl;输出结果:
hash is: 12386028635079221413key_eq
返回用于比较key相等性的函数。代码示例:
std::unordered_multiset<int> s;
auto key_eq_func = s.key_eq();
std::cout << std::boolalpha;
std::cout << key_eq_func(1, 1) << std::endl;
std::cout << key_eq_func(1, 2) << std::endl;输出结果:
true
false非成员函数
比较运算符
比较两个unordered_multiset是否相等。代码示例:
std::unordered_multiset<int> s1{1, 1, 2};
std::unordered_multiset<int> s2{1, 2};
std::cout << std::boolalpha;
std::cout << "s1 == s2: " << (s1 == s2) << std::endl;
std::cout << "s1 != s2: " << (s1 != s2) << std::endl;输出结果:
s1 == s2: false
s1 != s2: trueswap
交换两个容器的元素内容。代码示例:
std::unordered_multiset<int> s1{1, 1, 2};
std::unordered_multiset<int> s2{1, 2};
std::swap(s1, s2);
std::cout << "s1 size = " << s1.size() << std::endl;
std::cout << "s2 size = " << s2.size() << std::endl;输出结果:
s1 size = 2
s2 size = 3enable_if
删除满足条件的元素。代码示例:
std::unordered_multiset<int> s = {1, 1, 2, 3, 3};
std::cout << "s size = " << s.size() << std::endl;
std::erase_if(s,[](int a){return a > 2;});
std::cout << "s size = " << s.size() << std::endl;输出结果:
s size = 5
s size = 3相关文章:
-std::unordered_multiset)
容器库(12)-std::unordered_multiset
unordered_multiset是以key为元素无序的关联容器,搜索、移除和插入操作是平均常数的时间复杂度。unordered_multiset在内部没有按任何顺序排列,而是放在桶当中的,放进哪个桶是通过计算key的hash值来决定的。和unordered_set不同的是ÿ…...
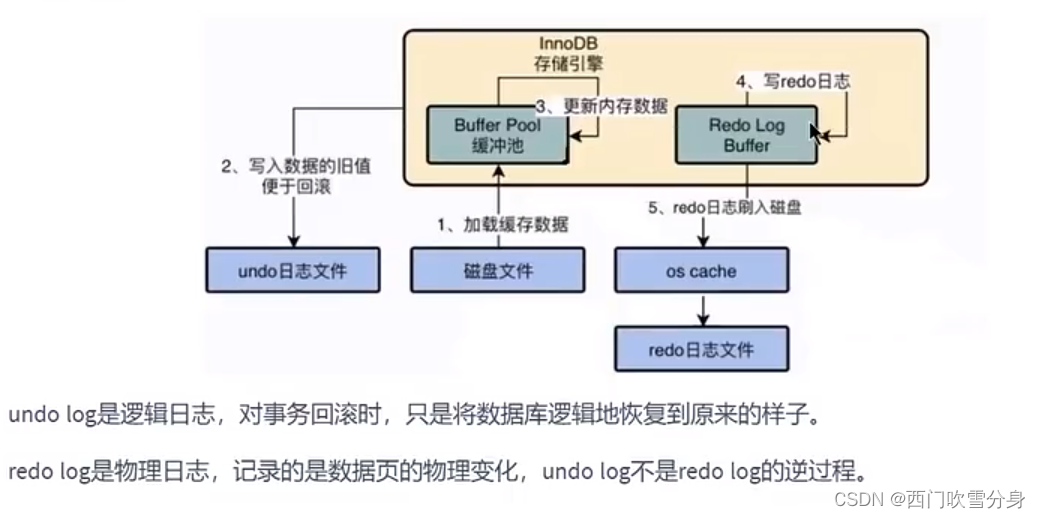
Mysql学习之事务日志undolog深入剖析
Undo log redo log 是事务持久性的保证,undo log是事务原子性的保证。在事务中更新数据的前置操作其实是要先写入一个undo log。 如何理解undo 日志? 事务需要保证原子性,也就是事务中的操作要么全部完成,要么什么也不做。但有时…...

springboot整合druid及可能遇到的问题
第一步,导入druid的maven依赖 在这里,我们选择导入druid-spring-boot-starter,使用配置文件的形式进行配置(不需要再编写配置类) <dependency><groupId>com.alibaba</groupId><artifactId>dr…...

c++文件的打开、读写和关闭。缓冲区的使用和控制。
在C中,文件的打开、读写和关闭通常使用标准库中的文件流对象(如std::ifstream用于输入文件,std::ofstream用于输出文件)来完成。这些对象封装了与操作系统交互的底层细节,使得文件操作更为简单和安全。 以下是文件打开…...
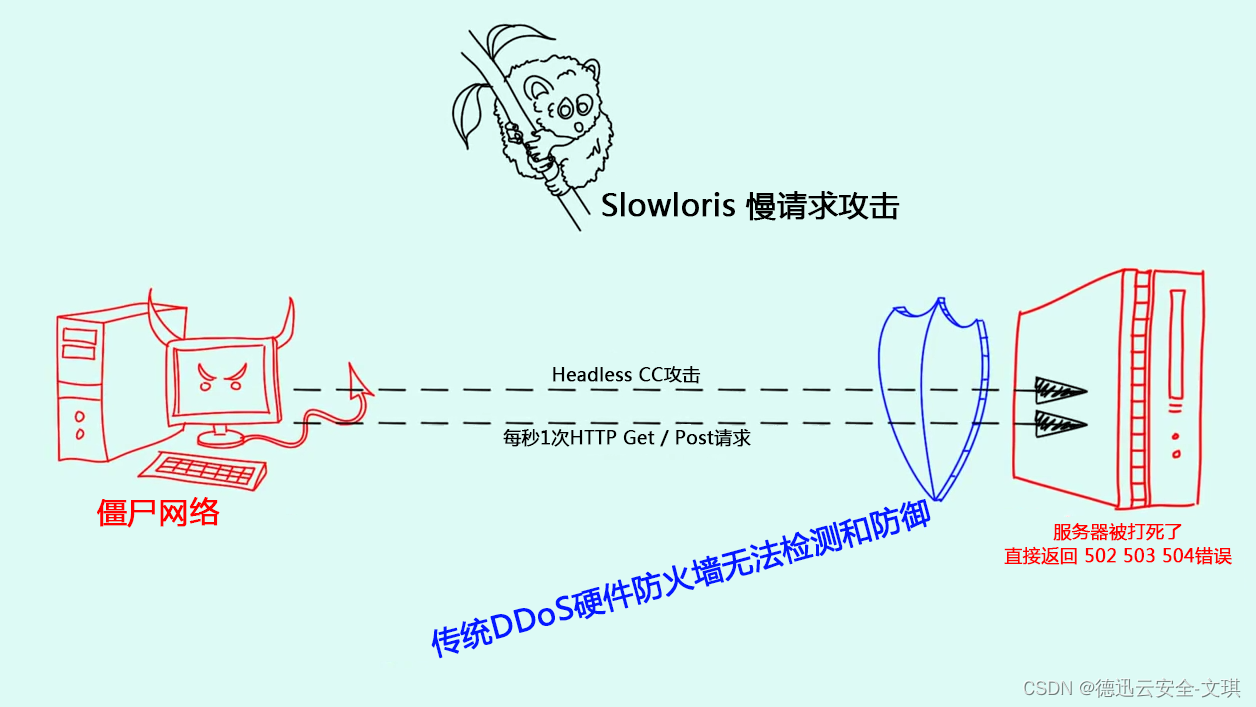
网络层的DDoS攻击与应用层的DDoS攻击之间的区别
DDoS攻击(即“分布是拒绝服务攻击”),是基于DoS的特殊形式的拒绝服务攻击,是一种分布式、协作的大规模攻击方式,主要瞄准一些企业或政府部门的网站发起攻击。根据攻击原理和方式的区别,可以把DDoS攻击分为两…...

Windows系统安全策略设置之本地NTLM重放提权
经安全部门研究分析,近期利用NTLM重放机制入侵Windows 系统事件增多,入侵者主要通过Potato程序攻击拥有SYSTEM权限的端口伪造网络身份认证过程,利用NTLM重放机制骗取SYSTEM身份令牌,最终取得系统权限,该安全风险微软并…...

AI云增强升级!还原生动人像,拍出质感照片
近期不少细心用户发现,在用HUAWEI Mate 60 Pro手机拍照后,使用相册中的AI云增强功能,照片变得更加细腻有质感。这是因为AI云增强升级并更新支持了人像模式拍摄的照片,高清自然的人像细节还原和单反级别的光学景深效果,…...
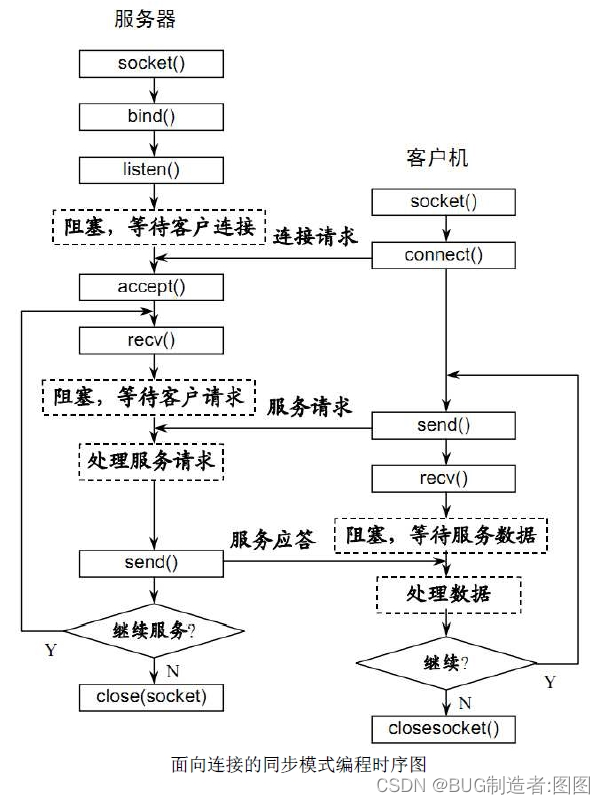
PHP WebSocket:技术解析与实用指南
本文旨在帮助初学者掌握在PHP中使用WebSocket的关键概念和技术。我们将深入讨论从建立连接、绑定到监听等各方面的操作,并提供易于理解和实践的指导。 一、socket协议的简介 WebSocket是什么,有什么优点 WebSocket是一个持久化的协议,这是…...

K8S实战:Centos7部署Kubernetes1.24.0集群
本人在参考Kubernetes(k8s) 1.24.0版本基于Containerd的集群安装部署部署Kubernetes1.24.0集群时,遇到几个问题,下面将要注意的点罗列在下面: 集群需要配置hosts,如下所示,IP根据自己的实际情况填写,否则在kubeadm in…...

webpack的使用(中)
前言:(承接webpack的使用(上))在实际开发过程中,webpack 默认只能打包处理以 .js 后缀名结尾的模块,其他非 js 后缀名结尾的模块,webpack 默认处理不了,需要调用 loader 加载器才可以正常打包&a…...
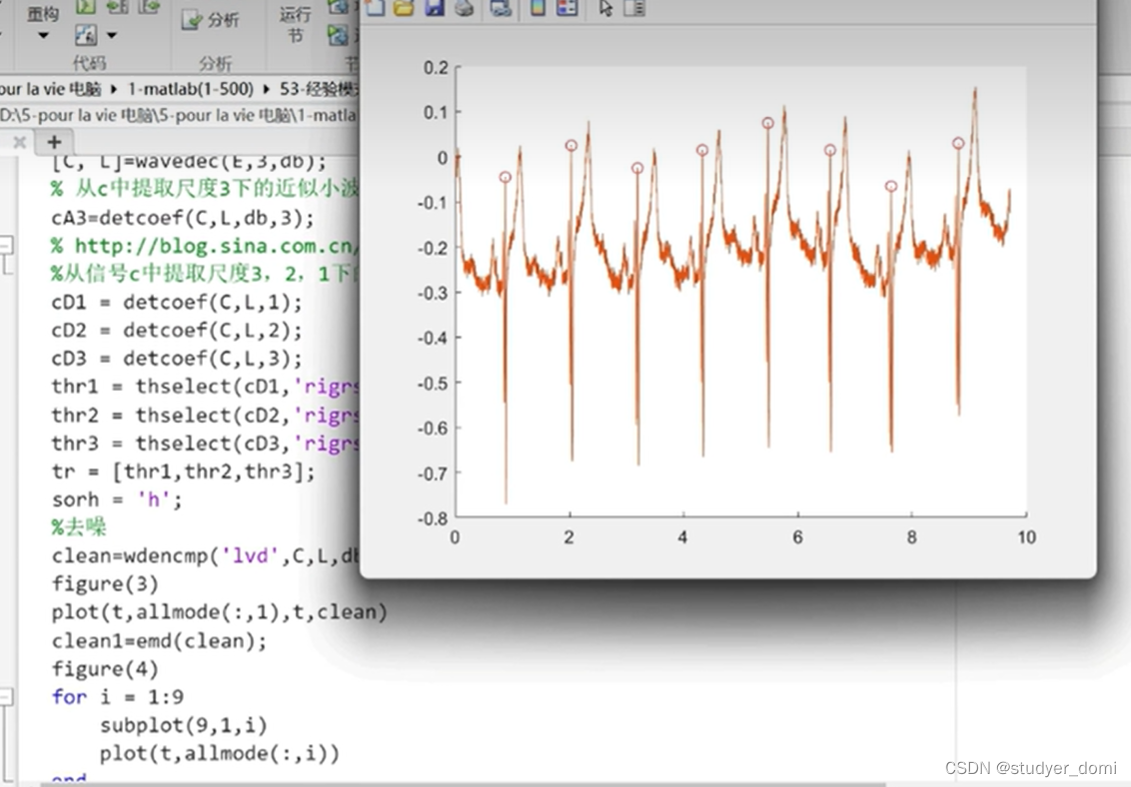
matlab经验模式分解的R波检测算法
1、内容简介 略 56-可以交流、咨询、答疑 2、内容说明 略 心血管疾病是威胁人类生命的主要疾病之一,而心电信号(electrocardiogram, ECG) 则是评价心脏功能的主要依据,因此,关于心电信号检测处理的研究一直为各方所…...
win10编译openjdk源码
上篇文章作者在ubuntu系统上实践完成openjdk源码的编译,但是平常使用更多的是window系统,ubuntu上编译出来JDK无法再windows上使用。所以作者又花费了很长时间在windows系统上完成openjdk源码的编译,陆续花费一个月的时间终于完成了编译。 本…...

mysql 自定义函数create function
方便后续查询,做以下记录; 自定义函数是一种与存储过程十分相似的过程式数据库对象, 它与存储过程一样,都是由 SQL 语句和过程式语句组成的代码片段,并且可以被应用程序和其他 SQL 语句调用。 自定义函数与存储过程之间…...
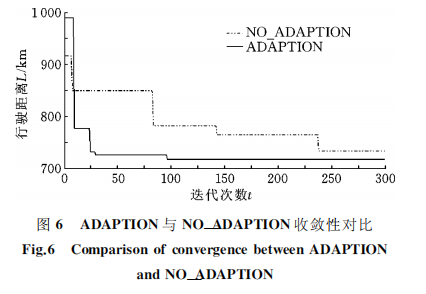
【析】装卸一体化车辆路径问题的自适应并行遗传算法
0 引言 国内外有关 VRPSPD的文献较多,求解目标多以最小化车辆行驶距离为主,但现实中可能存在由租赁费用产生的单次派出成本,需要综合考 虑单次派车成本和配送路径成本。…...

react项目中的redux以及react-router-dom
扫盲知识点: 1 传递自定义事件: <button onClick{(e)>{change(e)}}>获取事件对象e</button> 将事件对象e传递到了change的这个方法中。 2 同时传递自定义事件和参数: <button onClick{(e)>{change(‘我…...

django学习网址
https://www.django.cn/ Django中文网 https://docs.djangoproject.com/zh-hans/5.0/ Django 教程 | 菜鸟教程 (runoob.com) https://gitee.com/djangoadmin/DjangoAdmin_Django_Layui DjangoStarter: 基于Django定制的快速Web开发模板,功能包括:Do…...
|Day21(二叉树))
@ 代码随想录算法训练营第4周(C语言)|Day21(二叉树)
代码随想录算法训练营第4周(C语言)|Day21(二叉树) Day21、二叉树(包含题目 ● 530.二叉搜索树的最小绝对差 ● 501.二叉搜索树中的众数 ● 236. 二叉树的最近公共祖先 ) 530.二叉搜索树的最小绝对差 题目…...

Android的消息机制--Handler
一、四大组件概述 Android的消息机制是由Handler、Message、MessageQueue,Looper四个类支撑,撑起了Android的消息通讯机制,Android是一个消息驱动系统,由这几个类来驱动消息与事件的执行 Handler: 用来发送消息和处…...

获取用户信息与token理解
获取用户信息和token是在开发Web应用程序时常见的需求,可以通过以下步骤来实现: 用户登录:用户在应用程序中输入用户名和密码进行登录验证。一旦验证成功,应用程序会生成一个唯一的token,并将其返回给客户端。存储tok…...

网络设备和网络软件
文章目录 网络设备和网络软件网卡交换机交换机的三个主要功能交换机的工作原理第二层交换和第三层交换交换机的堆叠和级联 路由器路由器工作原理 网关网关的分类 无线接入点(AP)调制解调器网络软件 网络设备和网络软件 网卡 网络接口卡又称网络适配器,简称网卡。网…...

EcomGPT-7B多语言商品描述生成:跨境电商实战案例
EcomGPT-7B多语言商品描述生成:跨境电商实战案例 用AI一键生成专业级多语言商品描述,效率提升10倍 1. 开场:跨境电商的语言挑战 做跨境电商的朋友都知道,多语言商品描述是个让人头疼的问题。每个产品都要用不同语言写描述&#x…...

LangChain:大模型时代的“神兵利器”,你了解多少?
2022年11月30日,ChatGPT横空出世,彻底点燃了全球对大模型的热情。但在聚光灯之外,一个更底层的生态也在悄然崛起——那就是大模型应用开发框架。今天,我想和你聊聊这个领域目前最耀眼的明星:LangChain。如果你关注GitH…...

英雄联盟智能辅助新纪元:League Akari的模块化解决方案
英雄联盟智能辅助新纪元:League Akari的模块化解决方案 【免费下载链接】LeagueAkari ✨兴趣使然的,功能全面的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/LeagueAkari 引言&am…...

SiameseAOE模型处理多语言文本实践:中英文混合评论观点抽取
SiameseAOE模型处理多语言文本实践:中英文混合评论观点抽取 最近在分析一些跨境电商平台的用户评论时,发现一个挺有意思的现象:很多评论是中英文混着写的。比如“这件衣服的design很fashion,但物流太slow了”。这种混合表达&…...

BigIntegerBigDecimal
BigInteger 构造方法 常用第二个,第四个1. 例子2. 总结常见方法1. 总结BigDecimal构造方法 这种构造有可能不太精确:通过传递字符串表示的小数来创建对象:静态方法获取Bigdecimal 对象:常见方法RoundingMode.HALF_UP (…...

告别答辩 PPT 熬夜:PaperXie AI PPT 如何让本科生从 “凑内容” 到 “控全场”
paperxie-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/aippthttps://www.paperxie.cn/ppt/createhttps://www.paperxie.cn/ppt/create 引言 毕业答辩的前一周,是无数本科生的 “至暗时刻”:刚改完论文终稿,又要面对空白的 PP…...

中断很难?看完这篇就懂了
1.内核,总线,外设这三个概念是理解中断的必要前提,一个芯片具有内核、总线、外设这三个结构内核:芯片里的内核有很多架构,如ARM架构内核,它包含了许多核心部件,是整个芯片的大脑总线:…...

投标路上的那些 “怕“ 与 “难“作为投标方,你是否也有过这些困扰?
怕不小心触碰合规红线,一份标书细节疏漏就可能导致废标;怕围串标风险波及自身,项目竞争中 "躺枪" 却无从自证;怕评审环节信息不透明,技术、商务得分逻辑模糊,结果难预判;怕流程繁琐耗…...

Unity报错?删Library秒解决!
写在最前面:每个Unity开发者都经历过的崩溃瞬间 凌晨两点。 你,盯着屏幕。 眼睛,已经发红。 项目,明天就要交。 然后,你打开Unity。 然后,它报错了。 Error: Failed to load assembly Assembly-CSharp.dll UnityEditor.BuildPlayerWindow+BuildMethodException As…...

想要实现真正的认知自动化?企业智脑定制难道不是必经之路?
想要实现真正的认知自动化?企业智脑定制难道不是必经之路?在企业数字化转型的漫长征途中,我们曾寄希望于ERP系统理顺流程,寄希望于RPA(机器人流程自动化)替代重复劳动。然而,当大模型浪潮席卷全…...