我就不信你还不懂HashSet/HashMap的底层原理
💥注💥
💗阅读本博客需备的前置知识如下💗
- 🌟数据结构常识🌟👉1️⃣八种数据结构快速扫盲
- 🌟Java集合常识🌟👉2️⃣Java单列集合扫盲
⭐️本博客知识点收录于⭐️👉🚀《JavaSE系列教程》:🚀—>🚗11【泛型、Map、异常】🚗
文章目录
- 二、Set集合
- 2.1 Set集合概述
- 2.2 HashSet 集合
- 2.2.1 HashSet数据结构
- 1)HashSet简介
- 2)Hash冲突1
- 3)Hash冲突2
- 4)HashSet底层存储原理
- 5)HashSet特点总结
- 2.2.2 HashSet去重原理
- 2.2.3 HashSet存储测试
- 1)hash冲突情况1
- 2)hash冲突情况2
二、Set集合
2.1 Set集合概述
Set接口和List接口一样,继承与Collection接口,也是一个单列集合;Set集合中的方法和Collection基本一致;并没有对Collection接口进行功能上的扩充,只是底层实现的方式不同了(采用的数据结构不一样);
- Set集合体系结构:

2.2 HashSet 集合
2.2.1 HashSet数据结构
1)HashSet简介
HashSet是Set接口的一个实现类,它所存储的元素是不可重复的,并且元素都是无序的(即存取顺序不一致)。
HashSet底层数据结构在JDK8做了一次重大升级,JDK8之前采用的是Hash表,也就是数组+链表来实现;到了JDK8之后采用数组+链表+红黑树来实现;
Tips:关于红黑树我们暂时理解为红黑树就是一颗平衡的二叉树(即使他不是绝对平衡);
- HashSet简单使用:
package com.dfbz.demo01;import java.util.HashSet;/*** @author lscl* @version 1.0* @intro:*/
public class Demo01 {public static void main(String[] args) {//创建 Set集合HashSet set = new HashSet<String>();//添加元素set.add("湖北");set.add("河北");set.add("河北"); // HashSet带有去重特点,"河北"已经存储过了,不会再存储System.out.println(set); // [河北, 湖北]}
}
HashSet判断两个元素是否重复的依据是什么呢?下面案例代码HashSet将会存储几个元素呢?
- 示例代码:
package com.dfbz.demo01;import java.util.HashSet;/*** @author lscl* @version 1.0* @intro:*/
public class Demo01 {public static void main(String[] args) {//创建 Set集合HashSet<String> set = new HashSet();//添加元素set.add(new String("河北"));set.add("湖北");set.add("河北");set.add("湖北");System.out.println(set.size()); // ?System.out.println("--------------------");HashSet<A> set2 =new HashSet<>();set2.add(new A());set2.add(new A());System.out.println(set2.size()); // ?}
}class A{}
要探究HashSet的去重原理我们需要继续往下看!
2)Hash冲突1
我们知道hash表数据结构的特点是:根据元素的hash值来对数组的长度取余,最终计算出元素所要存储的位置;Object类中有一个特殊的方法hashCode(),该方法被native关键字修饰(不是采用Java语言实现);
public native int hashCode():获取该对象的hash值,默认情况下根据该对象的内存地址值来计算;
默认情况下,对象的hash值是根据对象的内存地址值来计算;但是这种hash算法并不是特别完美,有时候不同的两个对象(内存地址值不一致)计算出来的hash值可能会一样,我们把这种情况称为hash冲突。尽管这种情况非常少,但依旧存在;
- 下面是String类对hashCode代码的实现:
public int hashCode() {int h = hash;if (h == 0 && value.length > 0) {char val[] = value;for (int i = 0; i < value.length; i++) {h = 31 * h + val[i];}hash = h;}return h;
}
String默认情况下是获取每一个字符的ASCII码来参与hashCode的计算,在上面算法中,AB和BA得出的hashCode是不一致的;有效的解决了一定情况下的hash冲突问题,但是hash算法不能保证在所有情况下hash都能唯一;
例如Aa和BB的hashCode却是一样的,这种造成了Hash冲突问题;
Aa:
h = 31*0+65
h = 31*65+97
h = 2112
BB:
h = 31*0+66
H = 31*66+66
h = 2112
- 示例代码:
package com.dfbz.demo01;/*** @author lscl* @version 1.0* @intro:*/
public class Demo01 {public static void main(String[] args) {System.out.println("Aa".hashCode()); // 2112System.out.println("BB".hashCode()); // 2112}
}
通过String类对hashCode的实现可以看出来:hash算法并不能绝对的保证两个不同的对象算出来的hash值不一样,当hash冲突时,HashSet将会调用当前对象的equlas方法来比较两个对象是否一致,如果一致则不存储该元素;

3)Hash冲突2
假设数组的长度为9,当元素1的hash值为6,元素2的hash值为15,计算的数组槽位都是6,同样的,那么这个时候也会触发hash冲突问题;
- Integer对hashCode的实现:
@Override
public int hashCode() {return Integer.hashCode(value);
}
- Integer.hashCode():
public static int hashCode(int value) {// 就是返回元素本身return value;
}
- 示例代码:
package com.dfbz.demo01;/*** @author lscl* @version 1.0* @intro:*/
public class Demo10 {public static void main(String[] args) {System.out.println(new Integer(15).hashCode()); // 15System.out.println(new Integer(6).hashCode()); // 6}
}
Tips:Integer的hashCode就是本身数值;
HashSet存储时的Hash冲突情况(假设散列表中的数组长度为9):

发生上面这种Hash冲突时HashSet采用拉链法,将新增的元素添加到上一个元素之后形成链表;
需要注意的是:
- 1)hashCode一致的两个对象不能说明两个对象一定相同,因为可能会造成hash冲突(例如上面的Aa和BB)
- 2)但是如果hashCode不同,则一定能说明这两个对象肯定不同,因为同一个对象计算的hashCode永远一样;
因此在hash冲突的第二种情况下,并不需要调用equals来去重;而是采用拉链法直接将新添加的元素链在后面形成链表;
4)HashSet底层存储原理
我们前面了解过HashSet底层采用的是散列表这种数据结构(数组+链表),并且在JDK1.8对传统的散列表进行了优化,增加了红黑树来优化链表查询慢的情况;在默认情况下,HashSet中散列表的数组长度为16,并通过负载因子来控制数组的长度;HashSet中负载因子默认为0.75;
负载因子=HashSet中存储的元素/数组的长度
由此可以得出当HashSet中的元素个数为12个时(16*0.75=12),将进行数组的扩容,默认情况下将会扩容到原来的2倍;数组长度将会变为32,由公式可以推算出,下一次HashSet数组扩容时元素个数将为32*0.75=24,以此类推…
负载因子是控制数组扩容的一个重要参数;并且HashSet允许我们在创建时指定负载因子和数值的默认容量大小;
HashSet底层存储如图所示:

上述图中是一个hash表数据结构(数组+链表),也是JDK8之前的HashSet底层存储结构或者说还未达到阈值转换为红黑树的时候;
当存储的元素越来越多,hash也越来越多时,势必造成链表长度非常长,查找元素时性能会变得很低;在JDK8中当链表长度到达指定阈值8,并且数组容量达到了64时,将链表转换为红黑树,这样大大降低了查询的时间;
如图所示:

5)HashSet特点总结
- 1)存取无序,元素唯一,先比较hashCode,
- 1)Hash冲突情况1:hash值直接冲突了,当hash冲突时再比较equals,equals返回true则不存;
- 2)Hash冲突情况2:hash值没有冲突,但是%数组的长度得到槽位冲突了,使用拉链法形成链表
- 2)底层采用Hash表数据结构,当数组长度大于等于64并且链表长度大于等于8时,链表将会转换为红黑树,当长度降到6时将会重新转换为链表;
- 3)HashSet默认数组长度为16,默认的负载因子为0.75;
- 4)每次数组扩容时,默认扩容到原来的2倍;
2.2.2 HashSet去重原理
前面在分析hash冲突时就得出了结论:HashSet保证元素唯一性的方式依赖于:hashCode与equals方法。
来解释我们之前的问题:
package com.dfbz.demo01;import java.util.HashSet;/*** @author lscl* @version 1.0* @intro:*/
public class Demo01 {public static void main(String[] args) {//创建 Set集合HashSet<String> set = new HashSet();//添加元素set.add(new String("河北"));set.add("河北");System.out.println(set.size()); // ?}
}
- 分析:
HashSet在存储元素时,都会调用对象的hashCode()方法计算该对象的hash值,如果hash值与集合中的其他元素一样,则调用equals方法对冲突的元素进行对比,如果equals方法返回true,说明两个对象是一致的,HashSet并不会存储该对象,反之则存储该元素;
一般情况下,不同对象的hash值计算出来的结果是不一样的,但还是有某些情况下,不同一个对象的hash值计算成了同一个,这种情况我们称为hash冲突;当hash冲突时,HashSet会调用equals方法进行对比,默认情况下equals方法对比的是对象内存地址值,因此如果对象不是同一个,equals返回的都是false;

另外,Java中的HashSet还进行了优化,如果两个字符串都是存储在常量池,那么直接在常量池中进行判断,不需要调用equals来判断是否重复;
- 示例代码:
package com.dfbz.demo01;import java.util.HashSet;/*** @author lscl* @version 1.0* @intro:*/
public class Demo02 {public static void main(String[] args) {//创建 Set集合HashSet<String> set = new HashSet();set.add("河北");/*存储第二个"河北"时,hashSet发现两个hashCode一致并且都是存储在常量池,因此都不需要调用equals来判断这个元素是否存在hashSet*/set.add("河北");System.out.println(set.size()); // 2}
}
2.2.3 HashSet存储测试
1)hash冲突情况1
HashSet的去重原理是依靠对象的hashCode和equals方法来决定是否要存储这个对象的;如果不同的两个对象其hashCode是不同的,即使hash冲突了,equals也不可能相同(默认情况下,Object中的equals比较是两个对象的内存地址值);
但是在实际开发中,地址值并不是我们用来判断两个对象是否相等的依据,我们的习惯是,对象中的属性相等即判断两个对象是同一个对象;
- 定义一个Person类:
package com.dfbz.demo01;/*** @author lscl* @version 1.0* @intro:*/
public class Person {private String name;private Integer age;@Overridepublic String toString() {return "Person{" +"name='" + name + '\'' +", age=" + age +'}';}public Person() {}public Person(String name, Integer age) {this.name = name;this.age = age;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getAge() {return age;}public void setAge(Integer age) {this.age = age;}
}
- 测试类:
package com.dfbz.demo01;import java.util.HashSet;
import java.util.Set;/*** @author lscl* @version 1.0* @intro:*/
public class Demo02 {public static void main(String[] args) {Set persons = new HashSet<>();persons.add(new Person("小灰", 20));persons.add(new Person("小灰", 20));System.out.println(persons.size()); // 2}
}
默认情况下,hashCode的值是根据对象的内存地址值计算的,hashCode应该不一样,即使hashCode一样(hash冲突)调用equals返回值也是false,因为equlas默认的比较规则是比较两个对象的内存地址值
但是我们在实际开发中,即使new了两个对象,如果里面的属性是完全一样的,我们就认为两个对象是同一个对象,HashSet应该帮我们去除这样的重复对象;
我们可以重写hashCode和equals方法:
@Override
public boolean equals(Object o) {System.out.println("equals执行了...");// 为了测试,这样固定死是毫无意义的return false;
}@Override
public int hashCode() {System.out.println("hashCode执行了...");// 为了测试,这样固定死是毫无意义的return 1;
}
测试代码:
package com.dfbz.demo01;import java.util.HashSet;
import java.util.Set;/*** @author lscl* @version 1.0* @intro:*/
public class Demo02 {public static void main(String[] args) {Set persons = new HashSet<>();persons.add(new Person("小灰", 20));persons.add(new Person("小蓝", 18));System.out.println(persons.size()); // 1}
}
运行结果:

分析:
1)存储第一个Person对象时,调用这个Person对象的hashCode方法得出:1,并将其存储起来
2)存储第二个Person对象时,调用这个Person对象的hashCode方法得出:1,发现集合中已经有了hashCode为1的对象,因此调用Person对象的equals方法,将冲突了的Person对象传入(第一次添加的那个Person对象),然后equals方法返回的是true,因此不存这个Person对象(第二个Person对象),最终persons.size()为1;
真正的hashCode与equals的方法内部逻辑应该是:相同属性的对象的hashCode应该是一样的,也就是说hashCode应该根据对象属性来计算,并且equals对比的应该是对象属性的值;
使用idea快捷键:alt+insert
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3WT8GGut-1677985759628)(media/96.png)]
一直回车,生成hashCode和equals方法:
@Override
public boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Person person = (Person) o;return Objects.equals(name, person.name) &&Objects.equals(age, person.age);
}@Override
public int hashCode() {return Objects.hash(name, age);
}
此时再执行测试类:

将Person属性都改为一样的:

2)hash冲突情况2
当hashCode不一样,但是%数组的长度得到的槽位是一样时,也会产生hash冲突,但是这种hash冲突并不需要调用equals来判断,而是直接使用拉链法拼接在上一个元素的后面形成链表;
- 示例代码:
package com.dfbz.demo01;import java.util.HashSet;/*** @author lscl* @version 1.0* @intro:*/
public class Demo01 {public static void main(String[] args) {HashSet<A> set = new HashSet();set.add(new A(1)); // 1 % 16 = 1set.add(new A(17)); // 17 % 16 = 1System.out.println(set);}
}class A {private Integer num;@Overridepublic boolean equals(Object o) {System.out.println("equals调用了...");return false;}@Overridepublic int hashCode() {return this.num;}public A(Integer num) {this.num = num;}
}
运行程序,发现并没有调用equals:

相关文章:
我就不信你还不懂HashSet/HashMap的底层原理
💥注💥 💗阅读本博客需备的前置知识如下💗 🌟数据结构常识🌟👉1️⃣八种数据结构快速扫盲🌟Java集合常识🌟👉2️⃣Java单列集合扫盲 ⭐️本博客知识点收录于…...
Qt中调用gtest进行单元测试及生成覆盖率报告
一.环境配置 googletest地址:https://github.com/google/googletest 我下载的是1.12.1,这是最后一个支持C++11的版本。 首先编译gtest,在windows上的编译方式和编译gRPC一模一样,详见Qt中调用gRPC,编译完了会生成几个静态库,如下图所示 本文主要用到了libgtest.a 下载ms…...

ChatGPT vs Bard 背后的技术对比分析和未来发展趋势
ChatGPT vs Bard 背后的技术对比分析和未来发展趋势 目录 ChatGPT vs Bard 背后的技术对比分析和未来发展趋势...
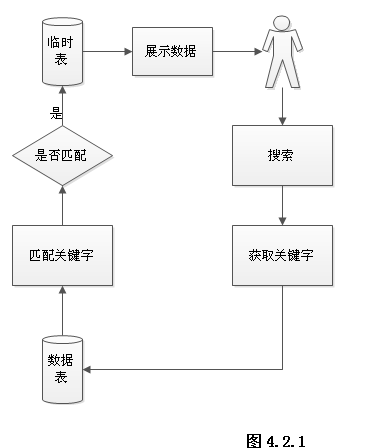
搜索引擎的设计与实现
技术:Java、JSP等摘要:随着互联网的快速发展,网络上的数据也随着爆炸式地增长。如何最快速筛选出对我们有用的信息成了主要问题。搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后&…...
动态规划之买卖股票问题
🌈🌈😄😄 欢迎来到茶色岛独家岛屿,本期将为大家揭晓动态规划之买卖股票问题 ,做好准备了么,那么开始吧。 🌲🌲🐴🐴 动态规划算法本质上就是穷举…...

MySQL学习笔记之子查询
自连接方式 自连接就是表A连接表A,通过where关键字实现,比如查询工资比Abel高的员工信息: SELECTe2.last_name,e2.salary FROMemployees e1,employees e2 WHEREe1.last_name "Abel" AND e2.salary > e1.salary;子查询 亦称为…...

HCIP-5OSPF域内域间外部路由学习笔记
1、OSPF区域 每个区域都维护一个独立的LSDB。 Area 0是骨干区域,其他区域都必须与此区域相连。 划分OSPF区域可以缩小路由器的LSDB规模,减少网络流量。 区域内的详细拓扑信息不向其他区域发送,区域间传递的是抽象的路由信息,而不…...

【编程实践】简单是好软件的关键:Simplicity is key to good software
Simplicity is key to good software 简单是好软件的关键 目录 Simplicity is key to good software简单是好软件的关键 Complexity is tempting. 复杂性很诱人。 The smallest way to create value创造价值的最小方法 Simple 简单的 Complexity is tempting. 复杂性很诱人…...
Python|贪心|数组|二分查找|贪心|数学|树|二叉搜索树|在排序数组中查找元素的第一个和最后一个位置|计数质数 |将有序数组转换为二叉搜索树
1、在排序数组中查找元素的第一个和最后一个位置(数组,二分查找) 给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。 如果数组中不存在目标值 target,返回 […...
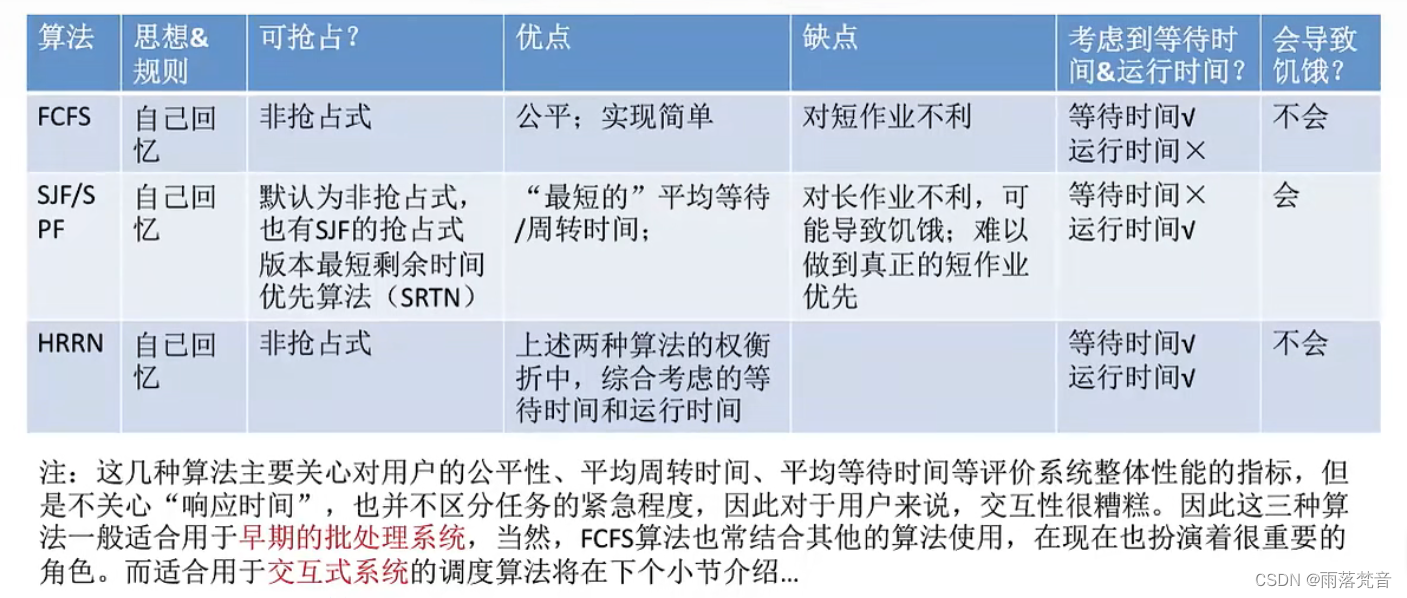
操作系统——15.FCFS、SJF、HRRN调度算法
这节我们来看一下进程调度的FCFS、SJF、HRRN调度算法 目录 1.概述 2.先来先服务算法(FCFS,First Come First Serve) 3.短作业优先算法(SJF,Shortest Job First) 4.高响应比优先算法(HRRN&…...
如何防止用户打开浏览器开发者工具?
大家好,我是前端西瓜哥。作为一名前端开发,在浏览一些网页时,有时会在意一些交互效果的实现,会打开开发者工具查看源码实现。 但有些网站做了防窥探处理,打开开发者工具后,会无法再正常进行网页的操作。 …...
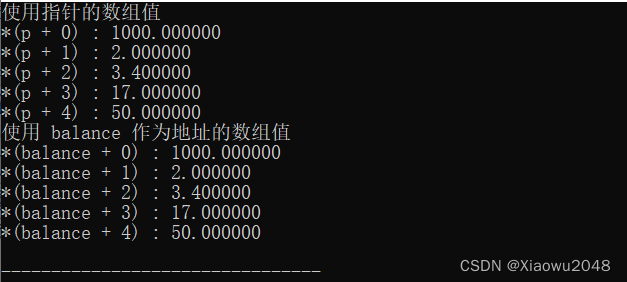
C语言-基础了解-12-C数组
C数组 一、C数组 C 语言支持数组数据结构,它可以存储一个固定大小的相同类型元素的顺序集合。数组是用来存储一系列数据,但它往往被认为是一系列相同类型的变量。 数组的声明并不是声明一个个单独的变量,比如 runoob0、runoob1、…、runoo…...

RocksDB 架构
文章目录1、RocksDB 摘要1.1、RocksDB 特点1.2、基本接口1.3、编译2、LSM - Tree2.1、Memtable2.2、WAL2.3、SST2.4、BlockCache3、读写流程3.1、读取流程3.2、写入流程4、LSM-Tree 放大问题4.1、放大问题4.2、compactionRocksDB 是 Facebook 针对高性能磁盘开发开源的嵌入式持…...

MVVM和MVC的区别
首先,MVVM 和 MVC 都是一种设计模式MVCM(Model): 模型层。 用于处理应用程序数据逻辑的部分,模型对象负责在数据库中存取数据V (View): 视图层。 处理数据显示的部分 ,视…...

c++11 标准模板(STL)(std::unordered_map)(三)
定义于头文件 <unordered_map> template< class Key, class T, class Hash std::hash<Key>, class KeyEqual std::equal_to<Key>, class Allocator std::allocator< std::pair<const Key, T> > > class unordered…...
OpenGL环境配置
方法一:1.下载GLFW点击GLFW跳转2.下载后解压3.下载glad,解压后4.用vs2019新建Cmake项目5.在新建的Cmake项目下建立depend文件夹在depend里放置我们下载解压的glad和glfw-3.3.8.bin.WIN646.项目中可以看到我们加进来的文件7.编写我们项目的CMakeLists.txt…...

SpringCloud之 Eureka注册中心
文章目录Eureka注册中心一、服务注册与发现1.1 依赖导入①父工程 SpringCloud 版本管理②Eureka 服务端依赖③Eureka 客户端依赖1.2 服务注册①创建 Eureka 服务端的主类②设置 Eureka 服务端的配置文件③设置 Eureka 客户端的配置文件④关闭自我保护机制1.3 服务发现①远程调用…...

Linux入门篇-用户管理
简介 linux基本的用户管理。 ⽤户的管理(切换到root) ⽤户的添加(useradd) ⽤户的删除(userdel) ⽤户的修改(usermod) ⽤户的查看(查看/etc/passwd) id⽤户组的管理(切换到root) …...
)
G. Special Permutation(构造)
1、题目 G. Special Permutation 这道题的意思是给我们从111到nnn的排列,然后我们对这个排列的顺序上进行调换,需要满足的条件是任意两个相邻元素的绝对值的差满足条件:2≤∣pi−pi1∣≤42\leq |p_i-p_{i 1}|\leq 42≤∣pi−pi1∣≤4 …...
QML动态对象管理
QML中有多种方式来动态创建和管理QML对象: Loader (加载器)Repeater(复制器)ListView,GridWiew,PethView(视图) (之后会介绍)使用加载器ÿ…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

【kafka】Golang实现分布式Masscan任务调度系统
要求: 输出两个程序,一个命令行程序(命令行参数用flag)和一个服务端程序。 命令行程序支持通过命令行参数配置下发IP或IP段、端口、扫描带宽,然后将消息推送到kafka里面。 服务端程序: 从kafka消费者接收…...

UDP(Echoserver)
网络命令 Ping 命令 检测网络是否连通 使用方法: ping -c 次数 网址ping -c 3 www.baidu.comnetstat 命令 netstat 是一个用来查看网络状态的重要工具. 语法:netstat [选项] 功能:查看网络状态 常用选项: n 拒绝显示别名&#…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...

群晖NAS如何在虚拟机创建飞牛NAS
套件中心下载安装Virtual Machine Manager 创建虚拟机 配置虚拟机 飞牛官网下载 https://iso.liveupdate.fnnas.com/x86_64/trim/fnos-0.9.2-863.iso 群晖NAS如何在虚拟机创建飞牛NAS - 个人信息分享...
ZYNQ学习记录FPGA(一)ZYNQ简介
一、知识准备 1.一些术语,缩写和概念: 1)ZYNQ全称:ZYNQ7000 All Pgrammable SoC 2)SoC:system on chips(片上系统),对比集成电路的SoB(system on board) 3)ARM:处理器…...

在golang中如何将已安装的依赖降级处理,比如:将 go-ansible/v2@v2.2.0 更换为 go-ansible/@v1.1.7
在 Go 项目中降级 go-ansible 从 v2.2.0 到 v1.1.7 具体步骤: 第一步: 修改 go.mod 文件 // 原 v2 版本声明 require github.com/apenella/go-ansible/v2 v2.2.0 替换为: // 改为 v…...
0609)
书籍“之“字形打印矩阵(8)0609
题目 给定一个矩阵matrix,按照"之"字形的方式打印这个矩阵,例如: 1 2 3 4 5 6 7 8 9 10 11 12 ”之“字形打印的结果为:1,…...

从零开始了解数据采集(二十八)——制造业数字孪生
近年来,我国的工业领域正经历一场前所未有的数字化变革,从“双碳目标”到工业互联网平台的推广,国家政策和市场需求共同推动了制造业的升级。在这场变革中,数字孪生技术成为备受关注的关键工具,它不仅让企业“看见”设…...
Copilot for Xcode (iOS的 AI辅助编程)
Copilot for Xcode 简介Copilot下载与安装 体验环境要求下载最新的安装包安装登录系统权限设置 AI辅助编程生成注释代码补全简单需求代码生成辅助编程行间代码生成注释联想 代码生成 总结 简介 尝试使用了Copilot,它能根据上下文补全代码,快速生成常用…...