学习周报3.5
文章目录
- 前言
- 文献阅读
- 摘要
- 介绍
- 方法
- 总结
- 相关性
- 总结
前言
本周阅读文献《Multi-step ahead probabilistic forecasting of multiple hydrological》,文献主要提出一种基于三维卷积神经网络、卷积最小门记忆神经网络和变分贝叶斯神经网络的混合深度学习模型(B-CM-C4D),实现多站多水文变量的多步提前概率预测。作者提出了一种时间序列相关性分析方法,分析上下游站点随时间变化的相关性解决到底考虑过去和未来选取多少场景进行预测的问题。深度学习神经网络层(ConvMGM)主要是改进复杂的预测模型(ConvLSTM),以提高其预测准确性并减少训练时间的问题。引入变分贝叶斯概率预测框架来量化CM-C2D模型的预测不确定性。其次,学习了相关性的基础知识,了解了三种相关系数。
This week,I read an article which proposes a new hybrid deep learning model (B-CM-C3D) based on 3-D Convolutional Neural Network, Convolutional Minimum Gate Memory Neural Network and Variational Bayesian Neural Network to obtain multi-step ahead probabilistic forecasting of multiple hydrological variables for multiple stations.A time series correlation analysis method is proposed to analyze the correlation of upstream and downstream stations over time, and to solve the problems of the number of historical scenario inputs and the number of future scenario outputs. A new deep learning neural network layer (ConvMGM) is proposed to reduce the training time of ConvLSTM.A variational Bayesian probabilistic forecasting framework is introduced to quantify the forecasting uncertainty of the CM-C3D model.Then I learn the basics of correlation and three kinds of correlation coefficients.
文献阅读
题目:Multi-step ahead probabilistic forecasting of multiple hydrological
variables for multiple stations
作者:Zhendong Zhang , Haihua Tang , Hui Qin , Bin Luo , Chao Zhou , Huayan Zhou
摘要
要想精确的模拟物理流域需要对水文预报站数量、水文变量类型、预报精度、预测周期和定量不确定性提出了更高的要求。如何同时获取多个站点的多个水文变量的多步提前概率预测是本研究要解决的关键问题。文献介绍了河流流域数字孪生的背景,分析了在此背景下水文预报面临的新问题;将水文预测的输入和输出重构为四维张量;提出一种基于三维卷积神经网络、卷积最小门记忆神经网络和变分贝叶斯神经网络的混合深度学习模型(B-CM-C3D),实现多站多水文变量的多步提前概率预测;为了验证该模型的性能,将该模型与长江流域的4种主流模型进行了比较。实验结果表明模型的预测精度和概率预测综合性能有80%优于其他对比模型。
介绍
数字孪生(DT)是指在虚拟世界中模拟真实世界的系统。河流流域数字孪生(River Basin Digital Twin,RBDT)是数字世界中对物理河流流域的映射,它能较理想地模拟物理河流流域的运行规律。RBDT有两个关键方面:外部显示和内部驱动。前者使RBDT看起来像一个物理流域,后者使RBDT按照物理流域的规律运行。在RBDT中,为了更精确地模拟物理流域,离不开高精度的预报模型、调度模型、洪水演化模型等模型。本研究重点研究RBDT背景下的水文预报,需要考虑以下4个重要方面:(1)下游站点流量受上游站点流量的影响;(2)河道内流量、水位等水文变量也相互影响;(3)水文变量多步提前预测比单步提前预测提供更多的信息(4)水文预报存在不确定性。因此,如何在RBDT背景下同时获得多站多水文变量的多步提前概率预报是本研究的目的。
水文预测方法主要分为物理过程驱动方法和数据驱动方法两大类。物理过程驱动方法基于水文原理。物理过程驱动法的优点是模型可解释性强,但缺点是需要更多的基础数据、复杂的建模、耗时的求解。数据驱动方法通常基于机器学习或深度学习等统计方法根据历史径流信息和气象相关因素对水文变量进行预测。数据驱动方法的优点是计算速度快,预测精度高;缺点是预测模型为黑箱模型,可解释性较差。常用的数据驱动方法可分为时间序列模型、机器学习或深度学习模型和多方法混合模型。近年来,深度学习模型逐渐应用于水文预测领域。长短期记忆网络(Long Short-Term Memory Network,LSTM)和卷积神经网络(convolutional Neural Network,CNN)分别擅长于时间序列处理和特征提取,因此被用于水文预测。为了克服单一预测模型的缺点,同时利用多个预测模型的优势,混合模型逐渐成为水文预测的主流方法。
现有的多步预测方法通常有两种思路。一是将单步提前预测的结果作为输入,对预测模型进行多次滚动。这样,误差累积严重,容易出现趋势总是上升或下降的情况,难以预测多步超前预测结果中的拐点。另一种方法是通过打乱时间序列数据来构建多步预测模型。这种方法没有将多个预测周期的水文变量作为一个整体来考虑,将多个单步超前预测模型进行了分离。贝叶斯推理是一种概率预测框架。当与不同的确定性预测模型相结合时,需要在原有框架思想的基础上进行公式推导,完成确定性预测模型的不确定性量化。深度学习模型的训练通常是耗时的。因此,本研究需要解决的关键问题如下:(1)如何同时获得多个站点的多个水文变量的预测结果?(2)多步提前预测如何实现全局考虑?(3)如何利用贝叶斯推理量化多站多水文变量多步提前预测结果的不确定性?(4)如何减少模型的训练时间?
本文提出了一种基于三维卷积神经网络(Conv3D)、卷积最小门记忆神经网络(ConvMGM)和变分贝叶斯神经网络(VBNN) 的概率预测混合模型,获得RBDT背景下多站多水文变量的多步提前概率预测。本研究的主要贡献如下:(1)将多站点的多个水文变量时间序列重新排列为4-D张量。(2)提出了一种新的深度学习神经网络层ConvMGM,缩短了现有卷积长短期记忆网络层的训练并提高了预测精度。(3)将Conv3D和ConvMGM相结合,形成一种新的混合深度学习模型(CM-C3D),该模型结合了Conv3D擅长挖掘特征和ConvMGM擅长处理时间序列的优点。(4)利用变分贝叶斯框架量化CM-C3D的不确定性,得到一个全新的概率预测深度学习模型(B-CM-C3D)。
流域数字孪生的背景
RBDT可以简单地理解为在数字世界中构建一个真实的河流流域。RBDT建设的两个重点是三维可视化技术和流域运行模型。前者使RBDT看起来像一个真实的河流流域,后者通过模拟河流流域的关键水文过程,使RBDT能够真正映射出真实的河流流域。预测模型、水库调度模型、流量演化模型都是流域运行模型的重要组成部分。本文研究的重点是如何模拟河道内多个关键站点水文变量的变化过程,并量化预测的不确定性。
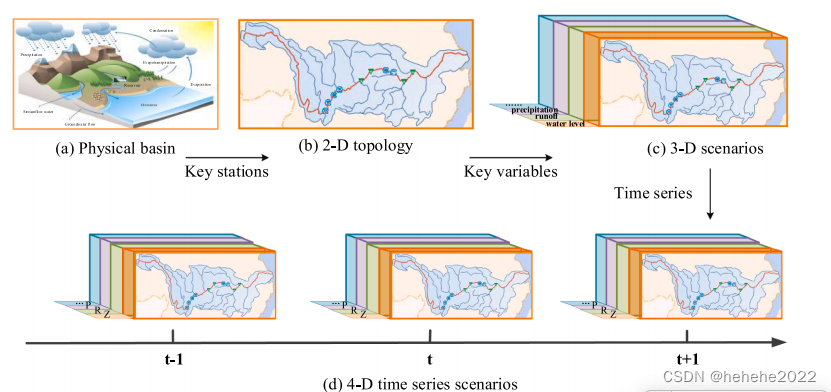
RBDT原理图如图所示,其中子图(a)为物理真实流域。通常,一条真实河流会被水库、水文站等站点切割成多个河段。这些站点和河段构成了数字世界中的二维拓扑,如图子图(b)所示。每个站点都有多个关键的水文变量,如水位(Z)、径流®和降水§。通过考虑水文变量,二维结构变成了三维场景,如图子图©所示。同时,这些水文元素大多是时间序列,因此,完整的RBDT是一个四维时间序列场景,如图(d)所示。
利用历史4-D时间序列场景预测未来4-D时间序列场景。本研究需要解决的具体问题如下:
(1)如何构建具有4-D输入和4-D输出的预测模型?
(2)有多少过去的情景适合预测。如果过去3-D场景数量过少,预测精度会过低,如果数量过大,模型训练会非常耗时。
(3)预测未来最多有多少个3-D场景是合适的。如果预测的未来场景数量过多,精度就会降低。
(4)如何改进如此复杂的预测模型,提高其预测精度,减少训练时间?
(5)没有一个模型可以完美预测,总是存在不确定性。如何获取4-D场景的概率密度函数(probability density function, PDF)是该研究要解决的关键问题。
方法
时间序列相关性分析
皮尔逊相关系数(PCC)和最大信息系数(MIC)是常用的相关性分析方法。它们通常同时分析两组变量,但如果两组变量之间存在时间滞后,则会影响分析结果。当洪水在河道中从上游流向下游时,上游的径流与下游的径流是相关的。同时,考虑到水流速度的影响,上游洪峰向下游传播需要一段时间。如果同时利用上游站和下游站的径流过程来计算相关系数,结果会较小,因此,本文提出了一种时间序列相关分析(time series correlation analysis, TSCA)方法来分析水文过程与时间滞后的相关性。前t步PCC和MIC的计算公式如下:
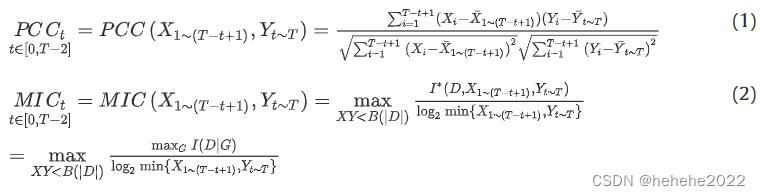
PCCt和MICt分别提前T步的PCC和MIC。X1 ~ (T−T +1)表示从1到T−T +1索引的自变量样本,Yt~ T表示从T到T索引的因变量样本。X1 ~ (T−T +1)和Yt~ T是样本均值。D是一个集合为[X1 ~ (T−T +1),Yt~ T]的序对。对于网格G, D|G是数据D在G单元上诱导的概率分布。I(D|G)表示相互信息。函数B(n) = n0.6和|D|是数据D的大小,T是样本总数。符号t表示时滞,其范围在[0,t−2]内。
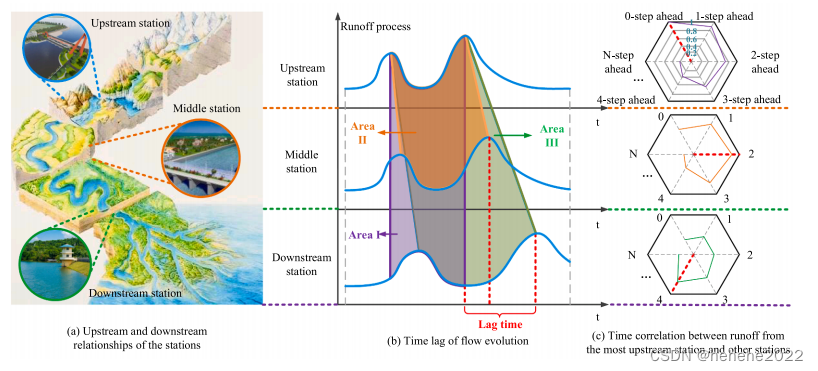
TSCA的目的是寻找相关系数最大的滞后,即tmax。设t从0变为t−2,依次计算相应的PCCt和MICt。然后找出最大的PCCt和MICt对应的t为tmax。在上图的子图©中,从上游到下游分别显示了上游站与上游站、上游站与中游站、上游站与下游站径流过程的时间序列相关系数雷达图。雷达图中带颜色的实线表示步进0到N对应的相关系数,红色虚线表示相关系数最大对应的步进数。越靠近雷达图中心,相关系数越小,反之亦然。对于上游站本身,PCC0最大,所以tmax = 0。tmax 中游站和下游站的分别为2和4。上游站和下游站距离越远,滞后时间越长,tmax。
TSCA不仅有利于探索上下游站点之间的相关性,也有助于解决提出的(2)和(3)问题。t值max 可以指导多水文变量多步提前概率预测模型的输入和输出使用多少3-D情景。由于对应于tmax 是最大的,不建议最长的预测周期超过tmax。同时,用于预测输入的历史3-D情景数量应大于tmax。如果训练模型的计算机性能更好,可以考虑更多的历史场景输入,3到4倍的t值max。如果计算机性能相对平均,则输入个数大于t的预测结果max 或者是t的两倍大max 是可以接受的。在本研究中,建议使用历史场景数量为t值的两到三倍max 作为预测模型的输入,且场景数等于tmax 为预测输出。
卷积最小门内存神经网络 (ConvMGM)
LSTM擅长处理序列数据,CNN擅长挖掘输入中的特征。卷积长短期记忆神经网络融合了两者的优点。卷积门控循环单元神经网络(Convolutional Gated Recurrent Unit Neural Network,ConvGRU)将ConvLSTM中三个门(输入门、遗忘门、输出门)的结构缩减为两个门的结构(重置门、更新门),在不降低预测精度的情况下减少了训练时间。本文提出了卷积最小门记忆神经网络(convolution Minimum Gate Memory Neural Network,简称conmgm),将门结构的数目减少到一种。大大减少了模型参数和训练时间,提高了预测精度。ConvMGM的网络结构如图所示。
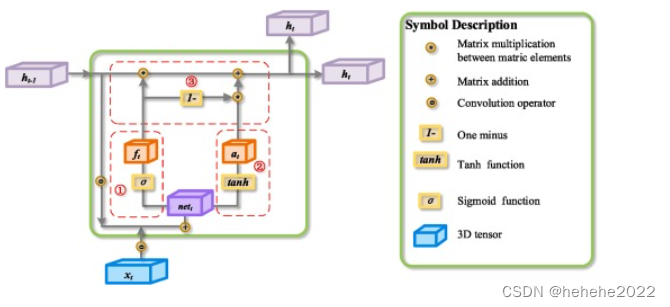
前向传播公式:
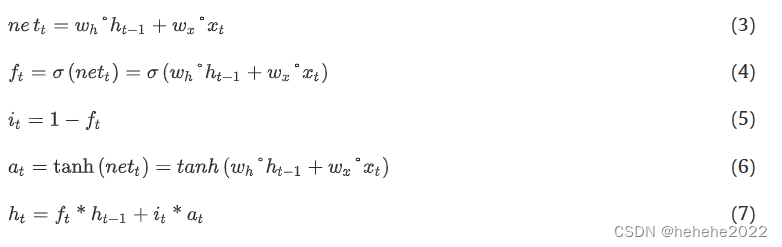 基于ConvMGM和Conv3D的情景预测模型(CM-C3D)
基于ConvMGM和Conv3D的情景预测模型(CM-C3D)
Conv3D是一个三维卷积神经网络,ConvMGM具有时间记忆功能,Conv3D擅长挖掘特征输入中的关系,两者都有利于水文情景预报。ConvMGM 图层 (CM) 与 Conv3D 图层 (C3D) 具有相同的输入和输出格式。因此,将这两种类型的层组合为隐藏层的一部分,形成了一种新的混合深度学习模型(CM-C3D)。CM-C3D模型是一种确定性预测模型,无法量化预测的不确定性。CM-C3D模型的输入和输出形状均为4D。
变分贝叶斯概率预测框架
概率神经网络与确定性神经网络的不同之处在于,它们的权重变量服从概率分布而不是确定性的单一值。这些概率分布描述了权重的不确定性,因此可用于量化预测不确定性。
变分贝叶斯情景概率预测模型 (B-CM-C3D)
本研究结合ConvMGM、Conv3D和VBNN构建了一种新的混合深度学习模型(B-CM-C3D)用于水文概率预测。B-CM-C3D模型有一个输入层,五个隐藏层(两个ConvMGM层,两个Conv3D层,一个VBNN层)和一个输出层。输入形状为(TxMxQxW)以及变量的含义(T,M,Q,A) 与上述相同。前两个隐藏层是 ConvMGM 层,分别称为 CM-1 层和 CM-2 层。第三层和第四个隐藏层是 Conv3D 层,分别称为 C3D-1 层和 C3D-2 层。第五个隐藏层是VBNN层,通过该层可以将确定性预测结果转换为概率预测结果。最后一层是输出层。
评估指标
在这项研究中,包括决定系数(R2),平均绝对误差(MAE),最大绝对误差(MaxAE),最小绝对误差(MinAE),对应于最大值的绝对误差(MaxValueAE)和对应于最小值的绝对误差(MinValueAE)用于评估确定性预测结果的准确性。R2越近为1,预测精度越高。MAE、MaxAE、MinAE、MaxValueAE和MinValueAE越小,预测精度越高。其计算公式如下:
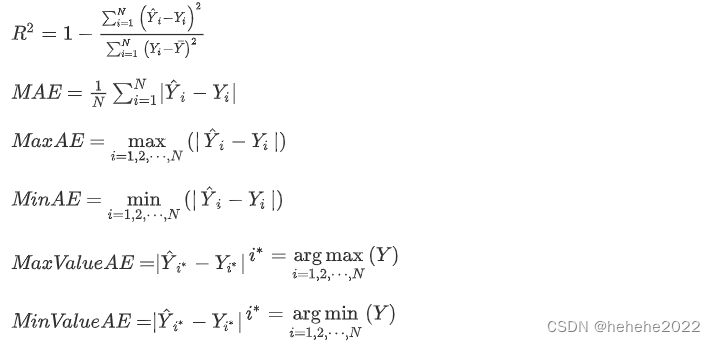
总结
本研究侧重于RBDT背景下多个水文变量的多步超前概率预测。然后提出了需要详细解决的五个关键问题。提出一种时间序列相关性分析方法,分析上下游站点随时间变化的相关性。其次,提出一种新的深度学习神经网络层(ConvMGM)来减少ConvLSTM的训练时间。此外,将ConvMGM和Conv2D组合成一个新的混合深度学习模型(CM-C3D)进行预测,引入变分贝叶斯概率预测框架来量化CM-C2D模型的预测不确定性。最后,以长江流域为例验证了本研究所提模型的性能,主要结论:
(1)本研究提出的B-CM-C3D模型在确定性预测精度和概率预测综合性能方面优于其他对比模型。
(2)B-CM-C3D将训练时间缩短了约43%。
相关性
相关分析是指对两个或多个具备相关性的变量元素进行分析,从而衡量两个因素的的相关密切程度,相关性的元素之间需要存在一定的联系或者概率才可以进行相关性分析。
相关系数:考察两个变量之间的相关程度。一般用字母r 表示,用来度量两个变量间的线性关系。
怎么确定相关关系的存在,相关关系呈现的形态和方向,相关关系的密切程度。其主要方法是绘制相关图表和计算相关系数。
第一种相关分析方法是将数据进行可视化处理,简单的说就是绘制图表。单纯从数据的角度很难发现其中的趋势和联系,而将数据点绘制成图表后趋势和联系就会变的清晰起来。
1.相关图(折线图及散点图)
利用直角坐标系第一象限,把自变量置于横轴上,因变量置于纵轴上,而将两变量相对应的变量值用坐标点形式描绘出来,用以表明相关点分布状况的图形。相关图被形象地称为相关散点图。因素标志分了组,结果标志表现为组平均数,所绘制的相关图就是一条折线,这种折线又叫相关曲线。
2.相关表
编制相关表前首先要通过实际调查取得一系列成对的标志值资料作为相关分析的原始数据。
相关表的分类:简单相关表和分组相关表。单变量分组相关表:自变量分组并计算次数,而对应的因变量不分组,只计算其平均值;该表特点:使冗长的资料简化,能够更清晰地反映出两变量之间相关关系。双变量分组相关表:自变量和因变量都进行分组而制成的相关表,这种表形似棋盘,故又称棋盘式相关表。
3.相关系数
1、相关系数是按积差方法计算,同样以两变量与各自平均值的离差为基础,通过两个离差相乘来反映两变量之间相关程度;着重研究线性的单相关系数。
2、确定相关关系的数学表达式。
3、确定因变量估计值误差的程度。
在进行相关分析时,首先需要绘制散点图来判断变量之间的关系形态,如果是线性关系,则可以利用相关系数来测度两个变量之间的关系强度,然后对相关系数进行显著性检验,以判断样本所反映的关系是否代表两个变量总体上的关系。
根据散点图,当自变量取某一值时,因变量对应为一概率分布,如果对于所有的自变量取值的概率分布都相同,则说明因变量和自变量是没有相关关系的。反之,如果,自变量的取值不同,因变量的分布也不同,则说明两者是存在相关关系的。
通过散点图可以判断两个变量之间有无相关关系,并对变量之间的关系形态作出大致的描述,但散点图不能准确反映变量之间的关系强度。因此,为准确度量两个变量之间的关系强度,需要计算相关系数。
相关系数(correlation coefficient)是根据样本数据计算的度量两个变量之间线性关系强度的统计量。
若相关系数是根据总体全部数据计算的,称为总体相关系数,记为:ρ
若是根据样本数据计算的,则称为样本相关系数,记为:r
样本相关系数的计算公式为:
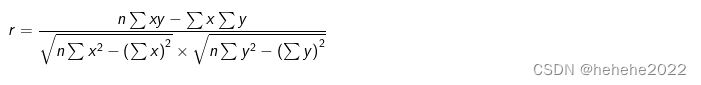
按上述公式计算的相关系数也称为线性相关系数(Linear Correlation Coefficient),或称为 Pearson 相关系数(Pearson’s Correlation Coefficient)
Pearson相关系数
Pearson相关系数(Pearson CorrelationCoefficient)是用来衡量两个数据集合是否在一条线上面,它用来衡量定距变量间的线性关系。
当两个变量都是正态连续变量,而且两者之间呈线性关系时,表现这两个变量之间相关程度用积差相关系数,主要有Pearson简单相关系数。
Pearson积差相关系数对应的计算公式如下:

Spearman相关系数
在统计学中, 以查尔斯·斯皮尔曼命名的斯皮尔曼等级相关系数,即spearman相关系数。经常用希腊字母ρ表示。 它是衡量两个变量的依赖性的 非参数 指标。 它利用单调方程评价两个统计变量的相关性。 如果数据中没有重复值, 并且当两个变量完全单调相关时,斯皮尔曼相关系数则为+1或−1。
斯皮尔曼相关系数被定义成等级变量之间的皮尔逊相关系数。对于样本容量为n的样本,n个原始数据被转换成等级数据,相关系数ρ为:
 Kendall秩相关系数
Kendall秩相关系数
Kendall(肯德尔)系数的定义:n个同类的统计对象按特定属性排序,其他属性通常是乱序的。同序对(concordant pairs)和异序对(discordant pairs)之差与总对数(n*(n-1)/2)的比值定义为Kendall(肯德尔)系数。
定义了Kendall-tau系数:
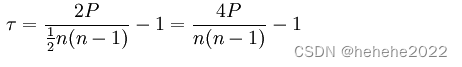
其中n是项目数,P是在所有项目中,在给定项目之后按两个排名排列的项目数之和。
总结
相关系数衡量变量之间相关程度的一个量值相关系数r的数值范围是在-1到+1之间,相关系数r的正负号表示变化方向。“+”号表示变化方向一致,即正相关;“-”号表示变化方向相反,即负相关。r的绝对值表示变量之间的密切程度(即强度)。绝对值越接近1,表示两个变量之间关系越密切;越接近0,表示两个变量之间关系越不密切。
相关文章:
学习周报3.5
文章目录前言文献阅读摘要介绍方法总结相关性总结前言 本周阅读文献《Multi-step ahead probabilistic forecasting of multiple hydrological》,文献主要提出一种基于三维卷积神经网络、卷积最小门记忆神经网络和变分贝叶斯神经网络的混合深度学习模型(…...

java基础学习篇
java学习 多写(代码、笔记、文章),多练(交流、思维、技能),多分享,多提问、多思考 什么是计算机 由硬件和软件组成,广泛应用在科学计算、数据处理、自动控制,计算机辅…...

Go 语言基础语法及应用实践
Go语言是一门由Google开发的静态类型、编译型的开源编程语言,被设计成简单、高效、安全的语言。作为一门相对年轻的语言,Go语言的使用范围正在不断扩大,特别是在Web开发、云计算、容器化和分布式系统等领域越来越受到欢迎。 在本篇文章中,我们将探讨Go语言的基础语法及应用…...

C语言自定义类型---进阶
之前的文章中有结构体初阶知识的讲解,对结构体不是很了解的小伙伴可以先去去看一下结构体初阶 结构体,枚举,联合结构体结构体类型的声明特殊的声明结构的自引用结构体变量的定义和初始化结构体内存对齐 <3 <3 <3(重点)那为什么存在内…...

85.链表总结
链表总结 链表总结与进阶 抽象数据类型(ADT abstract data type)与抽象数据接口(ADI abstract data Interface) 链表实际上就是对于结构体、结构体指针和结构体内可以包含指向同类型的结构体指针不可以包含指向同类型的结构体的应…...
【博学谷学习记录】超强总结,用心分享|狂野大数据课程【DataFrame的相关API】的总结分析
操作dataFrame一般有二种操作的方式, 一种为SQL方式, 另一种为DSL方式 SQL方式: 通过编写SQL语句完成统计分析操作DSL方式: 领域特定语言 指的通过DF的特有API完成计算操作(通过代码形式)从使用角度来说: SQL可能更加的方便一些, 当适应了DSL写法后, 你会发现DSL要比SQL更加…...

粒子群优化最小二乘支持向量机SVM回归分析,pso-lssvm回归预测
目录 支持向量机SVM的详细原理 SVM的定义 SVM理论 SVM应用实例,粒子群优化最小二乘支持向量机SVM回归分析 代码 结果分析 展望 支持向量机SVM的详细原理 SVM的定义 支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大…...

lavis多模态开源框架学习--安装
安装lavis安装lavis测试安装问题过程中的其他操作安装lavis 因为lavis已经发布在pypi中,所以可以直接利用pip安装 pip install salesforce-lavis测试安装 from lavis.models import model_zoo print(model_zoo) # # Architectures Types # # …...
【IDEA】如何在Tomcat上创建部署第一个Web项目?
看了网上很多教程,发现或多或都缺失了一些关键步骤信息,对于新手小白很不友好,那么今天就教大家如何在Tomcat服务器(本地)上部署我们的第一个Web项目: 共分为三个部分: 1. IDEA创建Web项目&am…...
程序员画流程图的工具Draw.io
Draw.io 是一个很好用的免费流程图绘制工具,制图结果本质上是xml文件,web版和桌面版可以支持导出图像(png或者svg矢量图都可以)。你可以利用它绘制一系列的图表、图示或图形,包括流程图、UML类图、组织结构图、泳道图、E-R 图、文…...

CAPL脚本DBLookup函数动态访问CAN 报文的属性
🍅 我是蚂蚁小兵,专注于车载诊断领域,尤其擅长于对CANoe工具的使用🍅 寻找组织 ,答疑解惑,摸鱼聊天,博客源码,点击加入👉【相亲相爱一家人】🍅 玩转CANoe&…...

2022年显卡性能跑分排名表
2022年显卡性能跑分排名表(数据来源于快科技)这个版本的电脑显卡跑分榜第一的是NVIDIA GeForce RTX 3090 Ti显卡。由于显卡跑分受不同的测试环境、不同的显卡驱动版本以及不同散热设计而有所不同,所以显卡跑分会一直变化。 前二十名的台式电…...
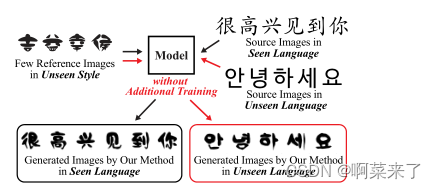
mx-font
Abstract 短镜头字体生成(FFG)方法必须满足两个目标:生成的图像既要保留目标字符的底层全局结构,又要呈现多样化的局部参考风格。现有的FFG方法旨在通过提取通用表示样式或提取多个组件样式表示来分离内容和样式。然而,以往的方法要么无法捕捉不同的本地风格,要么无法推广到…...
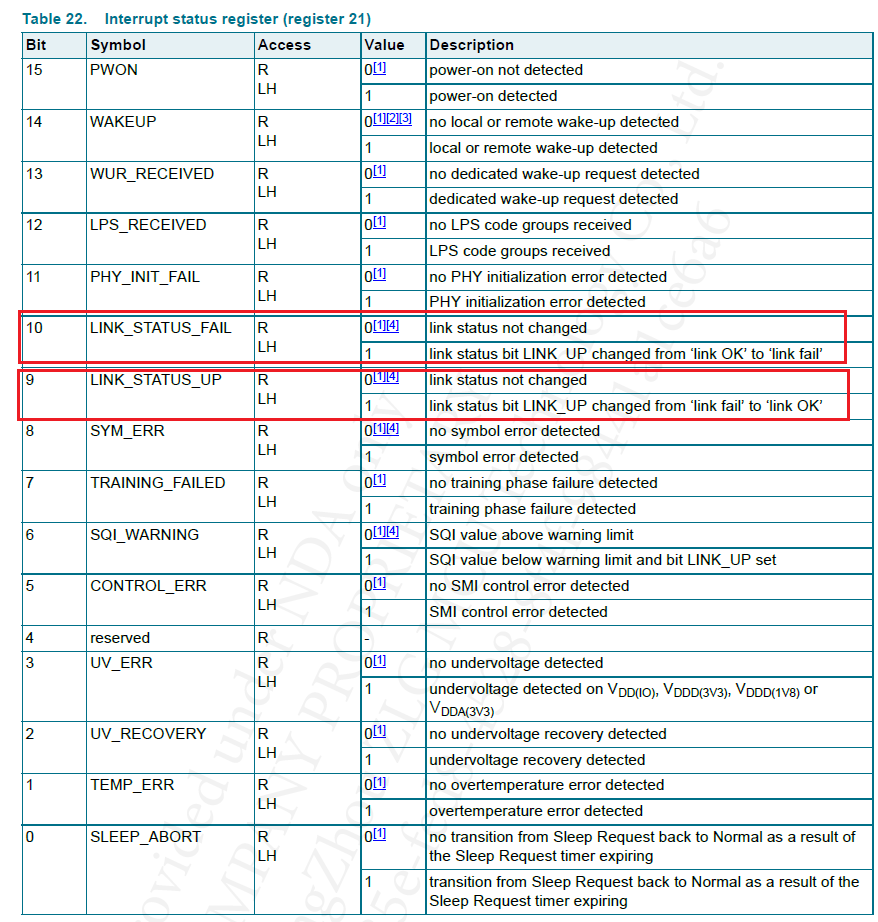
基于S32K148快速调试TJA1101
文章目录1.前言2.TJA1101简介3.TJA1101调试3.1 硬件3.1.1 整体框图3.1.2 评估板3.1.2.1 参考原理图3.1.2.2 引脚说明3.1.3 转接板3.1.3.1 参考原理图3.1.3.2 模式配置3.1.3.3 原理介绍3.2 软件3.2.1 物理层(TJA1101):3.2.2 数据链路层&#x…...

万字长文详解webpack知识图谱
webpack概念 概念 Webpack 是一种用于构建 JavaScript 应用程序的静态模块打包器,它能够以一种相对一致且开放的处理方式,加载应用中的所有资源文件(图片、CSS、视频、字体文件等),并将其合并打包成浏览器兼容的 Web…...
)
模板测试(Stencil Test)
模板测试可以用来针对特殊的区域进行渲染控制,实现有趣的效果,例如绘制物体轮廓。在 使用模板测试的时候,一般的步骤如下: 启用模板测试,以便写入数值到模板缓冲中渲染物体,根据渲染的物体将特定的数值写入到模板缓冲中禁用模板缓冲写入设置模板函数,根据于模板缓冲中的…...
【Go语言学习】安装与配置
文章目录前言一、Go语言学习站二、安装与配置1.安装2.环境变量配置3.Gland编辑器安装与配置Hello, World!总结前言 Go语言特性 Go,又称为 Golang,是一门开源的编程语言,由 Google 开发。Go 语言的设计目标是提供一种简单、快速、高效、安全…...
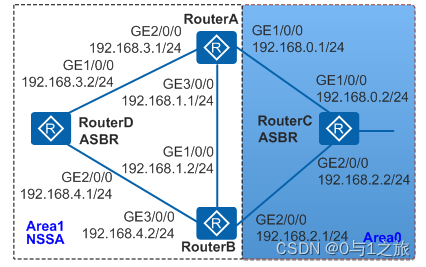
HCIP-5OSPF区域类型学习笔记
1、OSPF区域类型 OSPF提出了区域的概念(AREA),区域是将所有运行OSPF 的路由器人为的分成不同的组,以区域ID来标示。在区域内路由计算的方法不变,由于划分区域之后,每个区域内的路由器不会很多,…...

C语言再学习第三章
例题3-1 编写一个函数,实现华氏度和摄氏度的转化。 已知公式:c (5/9)*(f-32) #include <stdio.h>double f_value 0; double c_value 0; int main(void) {printf("请输入华氏温度\n");scanf("%lf",&f_valu…...

【aiy篇】小目标检测综述
小目标检测(Small Object Detection)是指在图像中检测尺寸较小的目标物体,通常是指物体的尺寸小于图像大小的1/10或者更小,COCO为例,面积小于等于1024像素的对象维下目标。小目标检测是计算机视觉领域的一个重要研究方…...

mongodb源码分析session执行handleRequest命令find过程
mongo/transport/service_state_machine.cpp已经分析startSession创建ASIOSession过程,并且验证connection是否超过限制ASIOSession和connection是循环接受客户端命令,把数据流转换成Message,状态转变流程是:State::Created 》 St…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...

Python 高效图像帧提取与视频编码:实战指南
Python 高效图像帧提取与视频编码:实战指南 在音视频处理领域,图像帧提取与视频编码是基础但极具挑战性的任务。Python 结合强大的第三方库(如 OpenCV、FFmpeg、PyAV),可以高效处理视频流,实现快速帧提取、压缩编码等关键功能。本文将深入介绍如何优化这些流程,提高处理…...
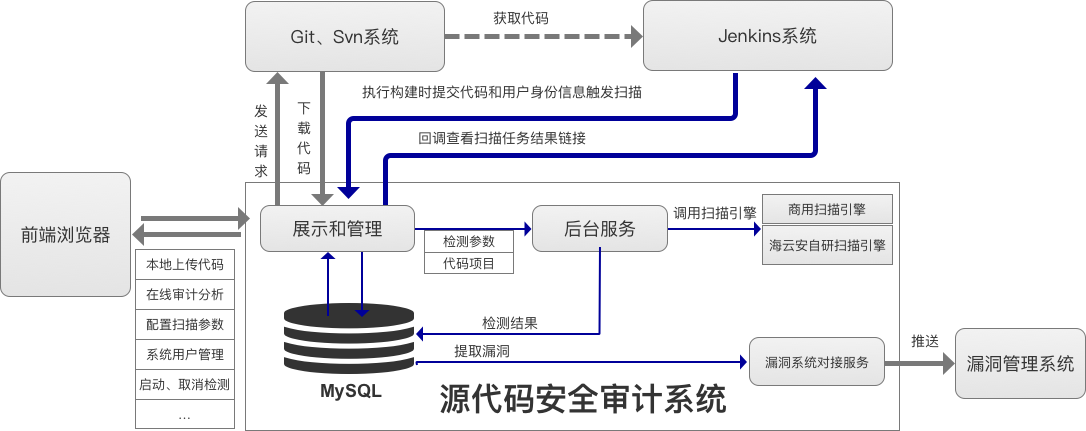
海云安高敏捷信创白盒SCAP入选《中国网络安全细分领域产品名录》
近日,嘶吼安全产业研究院发布《中国网络安全细分领域产品名录》,海云安高敏捷信创白盒(SCAP)成功入选软件供应链安全领域产品名录。 在数字化转型加速的今天,网络安全已成为企业生存与发展的核心基石,为了解…...
)
iOS 项目怎么构建稳定性保障机制?一次系统性防错经验分享(含 KeyMob 工具应用)
崩溃、内存飙升、后台任务未释放、页面卡顿、日志丢失——稳定性问题,不一定会立刻崩,但一旦积累,就是“上线后救不回来的代价”。 稳定性保障不是某个工具的功能,而是一套贯穿开发、测试、上线全流程的“观测分析防范”机制。 …...

视觉slam--框架
视觉里程计的框架 传感器 VO--front end VO的缺点 后端--back end 后端对什么数据进行优化 利用什么数据进行优化的 后端是怎么进行优化的 回环检测 建图 建图是指构建地图的过程。 构建的地图是点云地图还是什么信息的地图? 建图并没有一个固定的形式和算法…...