MySQL CTEs通用表表达式:进阶学习-递归查询
MySQL CTEs通用表表达式:进阶学习-递归查询
递归通用表表达式是其会引用自身的通用表表达式。
CTEs 递归通用表表达式补上了MySQL8之前无法使用递归查询的空白。在之前,递归查询需要使用函数等方法实现。
基础使用,请参考前文:
MySQL CTE 通用表表达式:基础学习
https://blog.csdn.net/kaka_buka/article/details/136507502
基础使用
具体示例如下:
WITH RECURSIVE cte (n) AS
(SELECT 1UNION ALLSELECT n + 1 FROM cte WHERE n < 5
)
SELECT * FROM cte;
执行该语句会得到以下结果,一个包含简单线性序列的单列:
+------+
| n |
+------+
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
+------+
递归CTE具有以下结构:
- 如果WITH子句中的任何CTE引用自身,则WITH子句必须以WITH RECURSIVE开头(如果没有CTE引用自身,则允许使用RECURSIVE,但不是必需的)。
如果在递归CTE中忘记使用RECURSIVE,可能会导致以下错误:
ERROR 1146 (42S02): Table 'cte_name' doesn't exist
-
递归CTE子查询有两部分,用UNION ALL或UNION [DISTINCT]分隔:
SELECT ... -- return initial row set UNION ALL SELECT ... -- return additional row sets第一个SELECT生成CTE的初始行或行,并且不引用CTE名称。第二个SELECT生成额外的行并进行递归,通过在其FROM子句中引用CTE名称。当这一部分不再产生新行时,递归结束。因此,递归CTE由非递归SELECT部分后跟递归SELECT部分组成。
每个SELECT部分本身都可以是多个SELECT语句的并集。
-
CTE结果列的类型仅从非递归SELECT部分的列类型推断,并且所有列都可为空。对于类型确定,递归SELECT部分将被忽略。
-
如果非递归部分和递归部分之间用UNION DISTINCT分隔,则将消除重复行。这对于执行传递闭包的查询非常有用,以避免无限循环。
-
递归部分的每次迭代仅对前一次迭代生成的行起作用。如果递归部分有多个查询块,则每个查询块的迭代按未指定的顺序安排,并且每个查询块都对自上一次迭代或自该上一次迭代结束以来由其他查询块生成的行起作用。
非递归部分
之前显示的递归CTE子查询具有检索单个行以生成初始行集的非递归部分:
SELECT 1
CTE子查询还具有以下递归部分:
SELECT n + 1 FROM cte WHERE n < 5
在每次迭代中,该SELECT会生成一个新值,该值比上一行集中的n值大1。第一次迭代操作初始行集(1),并生成1+1=2;第二次迭代操作第一次迭代的行集(2),并生成2+1=3;依此类推。这将继续,直到递归结束,即当n不再小于5时。
如果递归CTE的递归部分为某列生成的值比非递归部分宽,则可能需要扩展非递归部分中的列,以避免数据截断。考虑以下语句:
WITH RECURSIVE cte AS
(SELECT 1 AS n, 'abc' AS strUNION ALLSELECT n + 1, CONCAT(str, str) FROM cte WHERE n < 3
)
SELECT * FROM cte;
在非严格SQL模式下,该语句会产生以下输出:
+------+------+
| n | str |
+------+------+
| 1 | abc |
| 2 | abc |
| 3 | abc |
+------+------+
因为非递归SELECT确定了列的宽度,所以str列的所有值都是’abc’。因此,递归SELECT生成的更宽的str值被截断。
在严格SQL模式下,该语句会产生错误:
ERROR 1406 (22001): Data too long for column 'str' at row 1
为了解决这个问题,使语句不会产生截断或错误,可以在非递归SELECT中使用CAST()使str列变宽:
WITH RECURSIVE cte AS
(SELECT 1 AS n, CAST('abc' AS CHAR(20)) AS strUNION ALLSELECT n + 1, CONCAT(str, str) FROM cte WHERE n < 3
)
SELECT * FROM cte;
现在,该语句会产生以下结果,没有截断:
+------+--------------+
| n | str |
+------+--------------+
| 1 | abc |
| 2 | abcabc |
| 3 | abcabcabcabc |
+------+--------------+
非递归子查询列的访问
列是通过名称而不是位置访问的,这意味着递归部分中的列可以访问非递归部分中具有不同位置的列,如下所示:
WITH RECURSIVE cte AS
(SELECT 1 AS n, 1 AS p, -1 AS qUNION ALLSELECT n + 1, q * 2, p * 2 FROM cte WHERE n < 5
)
SELECT * FROM cte;
因为一个行中的 p 是由前一个行中的 q 导出的,反之亦然,所以输出的每一行中的正负值交换位置:
+------+------+------+
| n | p | q |
+------+------+------+
| 1 | 1 | -1 |
| 2 | -2 | 2 |
| 3 | 4 | -4 |
| 4 | -8 | 8 |
| 5 | 16 | -16 |
+------+------+------+
语法约束
在递归CTE子查询中有一些语法约束:
-
递归SELECT部分不得包含以下结构:
-
聚合函数如SUM()
-
窗口函数
-
GROUP BY
-
ORDER BY
-
DISTINCT
递归CTE的递归SELECT部分还可以使用LIMIT子句,以及可选的OFFSET子句。使用LIMIT与递归SELECT一起会停止生成行,一旦生成了请求的行数,结果集的效果与在最外层SELECT中使用LIMIT相同,但更有效。
对于UNION成员,不允许使用DISTINCT。
-
-
递归SELECT部分只能引用CTE一次,并且只能在其FROM子句中引用,而不是在任何子查询中。它可以引用除CTE之外的表,并将它们与CTE连接。如果在这样的连接中使用,CTE不能在LEFT JOIN的右侧。
这些约束来自SQL标准,除了前面提到的MySQL特定的排除项。
对于递归CTE,EXPLAIN输出的递归SELECT部分的行在Extra列中显示为Recursive。
EXPLAIN显示的成本估算代表每次迭代的成本,这可能与总成本有很大不同。优化器无法预测迭代次数,因为它无法预测WHERE子句何时变为false。
CTE的实际成本也可能受到结果集大小的影响。生成许多行的CTE可能需要一个足够大的内部临时表,以便从内存转换为磁盘格式,并可能遭受性能损失。如果是这样,增加允许的内存临时表大小可能会提高性能。
递归通用表表达式示例
斐波那契数列生成
斐波那契数列以两个数字0和1(或1和1)开始,之后的每个数字是前两个数字的和。如果递归SELECT产生的每一行都可以访问到数列中前两个数字,那么递归通用表表达式可以生成一个斐波那契数列。以下通用表表达式使用0和1作为前两个数字生成一个包含10个数字的数列:
WITH RECURSIVE fibonacci (n, fib_n, next_fib_n) AS
(SELECT 1, 0, 1UNION ALLSELECT n + 1, next_fib_n, fib_n + next_fib_nFROM fibonacci WHERE n < 10
)
SELECT * FROM fibonacci;
该通用表表达式生成以下结果:
+------+-------+------------+
| n | fib_n | next_fib_n |
+------+-------+------------+
| 1 | 0 | 1 |
| 2 | 1 | 1 |
| 3 | 1 | 2 |
| 4 | 2 | 3 |
| 5 | 3 | 5 |
| 6 | 5 | 8 |
| 7 | 8 | 13 |
| 8 | 13 | 21 |
| 9 | 21 | 34 |
| 10 | 34 | 55 |
+------+-------+------------+
通用表表达式的工作原理:
-
n是一个展示列,表示该行包含第n个斐波那契数。例如,第8个斐波那契数是13。
-
fib_n列显示斐波那契数n。
-
next_fib_n列显示数列中数字n之后的下一个斐波那契数。该列提供下一行的下一个数列值,因此该行可以在其fib_n列中产生前两个数列值的和。
-
当n达到10时,递归结束。这是一个任意选择,目的是将输出限制为一个小的行集。
前面的输出显示了整个通用表表达式的结果。要仅选择其中的一部分,请在顶层SELECT中添加一个适当的WHERE子句。例如,要选择第8个斐波那契数,请执行以下操作:
mysql> WITH RECURSIVE fibonacci ......SELECT fib_n FROM fibonacci WHERE n = 8;
+-------+
| fib_n |
+-------+
| 13 |
+-------+
生成连续日期序列
通用表表达式可以生成一系列连续的日期,这对于生成包含所有日期的摘要非常有用,包括在摘要数据中未表示的日期。
假设销售数字表包含以下行:
mysql> SELECT * FROM sales ORDER BY date, price;
+------------+--------+
| date | price |
+------------+--------+
| 2017-01-03 | 100.00 |
| 2017-01-03 | 200.00 |
| 2017-01-06 | 50.00 |
| 2017-01-08 | 10.00 |
| 2017-01-08 | 20.00 |
| 2017-01-08 | 150.00 |
| 2017-01-10 | 5.00 |
+------------+--------+
以下查询对每天的销售进行了汇总:
mysql> SELECT date, SUM(price) AS sum_priceFROM salesGROUP BY dateORDER BY date;
+------------+-----------+
| date | sum_price |
+------------+-----------+
| 2017-01-03 | 300.00 |
| 2017-01-06 | 50.00 |
| 2017-01-08 | 180.00 |
| 2017-01-10 | 5.00 |
+------------+-----------+
然而,该结果包含了在表跨度日期范围内未表示的日期的“空洞”。可以使用递归通用表表达式生成该日期范围的日期集合,然后与销售数据进行左连接来生成代表范围内所有日期的结果。
以下是生成日期范围序列的通用表表达式:
WITH RECURSIVE dates (date) AS
(SELECT MIN(date) FROM salesUNION ALLSELECT date + INTERVAL 1 DAY FROM datesWHERE date + INTERVAL 1 DAY <= (SELECT MAX(date) FROM sales)
)
SELECT * FROM dates;
该通用表表达式生成以下结果:
+------------+
| date |
+------------+
| 2017-01-03 |
| 2017-01-04 |
| 2017-01-05 |
| 2017-01-06 |
| 2017-01-07 |
| 2017-01-08 |
| 2017-01-09 |
| 2017-01-10 |
+------------+
通用表表达式的工作原理:
- 非递归SELECT生成销售表跨度日期范围中的最早日期。
- 递归SELECT生成的每一行将前一行生成的日期加一天。
- 当日期达到销售表跨度日期范围中的最大日期时,递归结束。
将该通用表表达式与销售表进行左连接,可以生成每个日期范围内的销售摘要:
WITH RECURSIVE dates (date) AS
(SELECT MIN(date) FROM salesUNION ALLSELECT date + INTERVAL 1 DAY FROM datesWHERE date + INTERVAL 1 DAY <= (SELECT MAX(date) FROM sales)
)
SELECT dates.date, COALESCE(SUM(price), 0) AS sum_price
FROM dates LEFT JOIN sales ON dates.date = sales.date
GROUP BY dates.date
ORDER BY dates.date;
输出如下所示:
+------------+-----------+
| date | sum_price |
+------------+-----------+
| 2017-01-03 | 300.00 |
| 2017-01-04 | 0.00 |
| 2017-01-05 | 0.00 |
| 2017-01-06 | 50.00 |
| 2017-01-07 | 0.00 |
| 2017-01-08 | 180.00 |
| 2017-01-09 | 0.00 |
| 2017-01-10 | 5.00 |
+------------+-----------+
需要注意的一些要点:
- 查询是否低效,特别是包含MAX()子查询的递归SELECT中的每一行?EXPLAIN显示,包含MAX()的子查询仅评估一次,并且结果被缓存。
- 使用COALESCE()避免在销售表中未发生销售数据的日期上在sum_price列中显示NULL。
遍历层次数据
递归通用表表达式对于遍历形成层次结构的数据非常有用。考虑以下创建一个小数据集的语句,该数据集显示公司中每个员工的姓名、ID号以及员工的经理的ID号。顶级员工(CEO)的经理ID为NULL(没有经理)。
CREATE TABLE employees (id INT PRIMARY KEY NOT NULL,name VARCHAR(100) NOT NULL,manager_id INT NULL,INDEX (manager_id),FOREIGN KEY (manager_id) REFERENCES employees (id)
);INSERT INTO employees VALUES
(333, "Yasmina", NULL), # Yasmina是CEO(manager_id为NULL)
(198, "John", 333), # John的ID为198,汇报给333(Yasmina)
(692, "Tarek", 333),
(29, "Pedro", 198),
(4610, "Sarah", 29),
(72, "Pierre", 29),
(123, "Adil", 692);
生成的数据集如下所示:
mysql> SELECT * FROM employees ORDER BY id;
+------+---------+------------+
| id | name | manager_id |
+------+---------+------------+
| 29 | Pedro | 198 |
| 72 | Pierre | 29 |
| 123 | Adil | 692 |
| 198 | John | 333 |
| 333 | Yasmina | NULL |
| 692 | Tarek | 333 |
| 4610 | Sarah | 29 |
+------+---------+------------+
要为每个员工(即从CEO到员工的管理链)生成组织结构图,可以使用递归通用表表达式:
WITH RECURSIVE employee_paths (id, name, path) AS
(SELECT id, name, CAST(id AS CHAR(200))FROM employeesWHERE manager_id IS NULLUNION ALLSELECT e.id, e.name, CONCAT(ep.path, ',', e.id)FROM employee_paths AS ep JOIN employees AS eON ep.id = e.manager_id
)
SELECT * FROM employee_paths ORDER BY path;
该通用表表达式生成以下输出:
+------+---------+-----------------+
| id | name | path |
+------+---------+-----------------+
| 333 | Yasmina | 333 |
| 198 | John | 333,198 |
| 29 | Pedro | 333,198,29 |
| 4610 | Sarah | 333,198,29,4610 |
| 72 | Pierre | 333,198,29,72 |
| 692 | Tarek | 333,692 |
| 123 | Adil | 333,692,123 |
+------+---------+-----------------+
通用表表达式的工作原理:
- 非递归SELECT生成CEO的行(具有NULL经理ID的行)。
- path列扩展为CHAR(200),以确保递归SELECT生成的更长的路径值有足够的空间。
- 递归SELECT生成的每一行查找所有直接报告给以前行生成的员工的员工。对于这样的员工,行包括员工ID和姓名,以及员工管理链。链是经理的链,加上员工ID放在末尾。
- 当员工没有其他人报告给他们时,递归结束。
要查找特定员工或多个员工的路径,可以将WHERE子句添加到顶层SELECT。例如,要显示Tarek和Sarah的结果,可以修改SELECT如下所示:
mysql> WITH RECURSIVE ......SELECT * FROM employees_extendedWHERE id IN (692, 4610)ORDER BY path;
+------+-------+-----------------+
| id | name | path |
+------+-------+-----------------+
| 4610 | Sarah | 333,198,29,4610 |
| 692 | Tarek | 333,692 |
+------+-------+-----------------+
如何限制递归通用表表达式?
递归通用表达式(CTE)非常重要的一点是,递归SELECT部分必须包含一个条件来终止递归。作为一种开发技术,防止递归CTE失控的一种方法是通过限制执行时间来强制终止递归:
-
cte_max_recursion_depth系统变量强制限制CTE的递归级别数。服务器会终止执行任何递归级别超过该变量值的CTE。 -
max_execution_time系统变量强制对当前会话中执行的SELECT语句设置执行超时时间。 -
MAX_EXECUTION_TIME优化器提示为其出现的SELECT语句强制设置每个查询的执行超时时间。
假设一个递归CTE被错误地编写为没有递归执行终止条件:
WITH RECURSIVE cte (n) AS
(SELECT 1UNION ALLSELECT n + 1 FROM cte
)
SELECT * FROM cte;
默认情况下,cte_max_recursion_depth的值为1000,导致CTE在递归超过1000级时终止。应用程序可以更改会话值以适应其需求:
SET SESSION cte_max_recursion_depth = 10; -- 仅允许浅层递归
SET SESSION cte_max_recursion_depth = 1000000; -- 允许更深的递归
您还可以设置全局cte_max_recursion_depth值,以影响所有随后开始的会话。
对于执行缓慢或存在设置cte_max_recursion_depth值非常高的上下文的查询,另一种防止深度递归的方法是设置每个会话的超时时间。为此,请在执行CTE语句之前执行类似以下的语句:
SET max_execution_time = 1000; -- 强制一秒超时
或者在CTE语句本身中包含一个优化器提示:
WITH RECURSIVE cte (n) AS
(SELECT 1UNION ALLSELECT n + 1 FROM cte
)
SELECT /*+ SET_VAR(cte_max_recursion_depth = 1M) */ * FROM cte;WITH RECURSIVE cte (n) AS
(SELECT 1UNION ALLSELECT n + 1 FROM cte
)
SELECT /*+ MAX_EXECUTION_TIME(1000) */ * FROM cte;
您还可以在递归查询中使用LIMIT来强制返回给最外层SELECT的最大行数,例如:
WITH RECURSIVE cte (n) AS
(SELECT 1UNION ALLSELECT n + 1 FROM cte LIMIT 10000
)
SELECT * FROM cte;
您可以在设置时间限制的同时或者代替设置时间限制来执行此操作。因此,以下CTE在返回一万行或运行一秒钟(1000毫秒)后终止:
WITH RECURSIVE cte (n) AS
(SELECT 1UNION ALLSELECT n + 1 FROM cte LIMIT 10000
)
SELECT /*+ MAX_EXECUTION_TIME(1000) */ * FROM cte;
如果一个没有执行时间限制的递归查询进入无限循环,您可以在另一个会话中使用KILL QUERY来终止它。在会话本身内部,用于运行查询的客户端程序可能提供了终止查询的方法。例如,在mysql中,键入Control+C会中断当前语句。
参考链接
- 官方文档:
https://dev.mysql.com/doc/refman/8.0/en/with.html
相关文章:

MySQL CTEs通用表表达式:进阶学习-递归查询
MySQL CTEs通用表表达式:进阶学习-递归查询 递归通用表表达式是其会引用自身的通用表表达式。 CTEs 递归通用表表达式补上了MySQL8之前无法使用递归查询的空白。在之前,递归查询需要使用函数等方法实现。 基础使用,请参考前文: …...
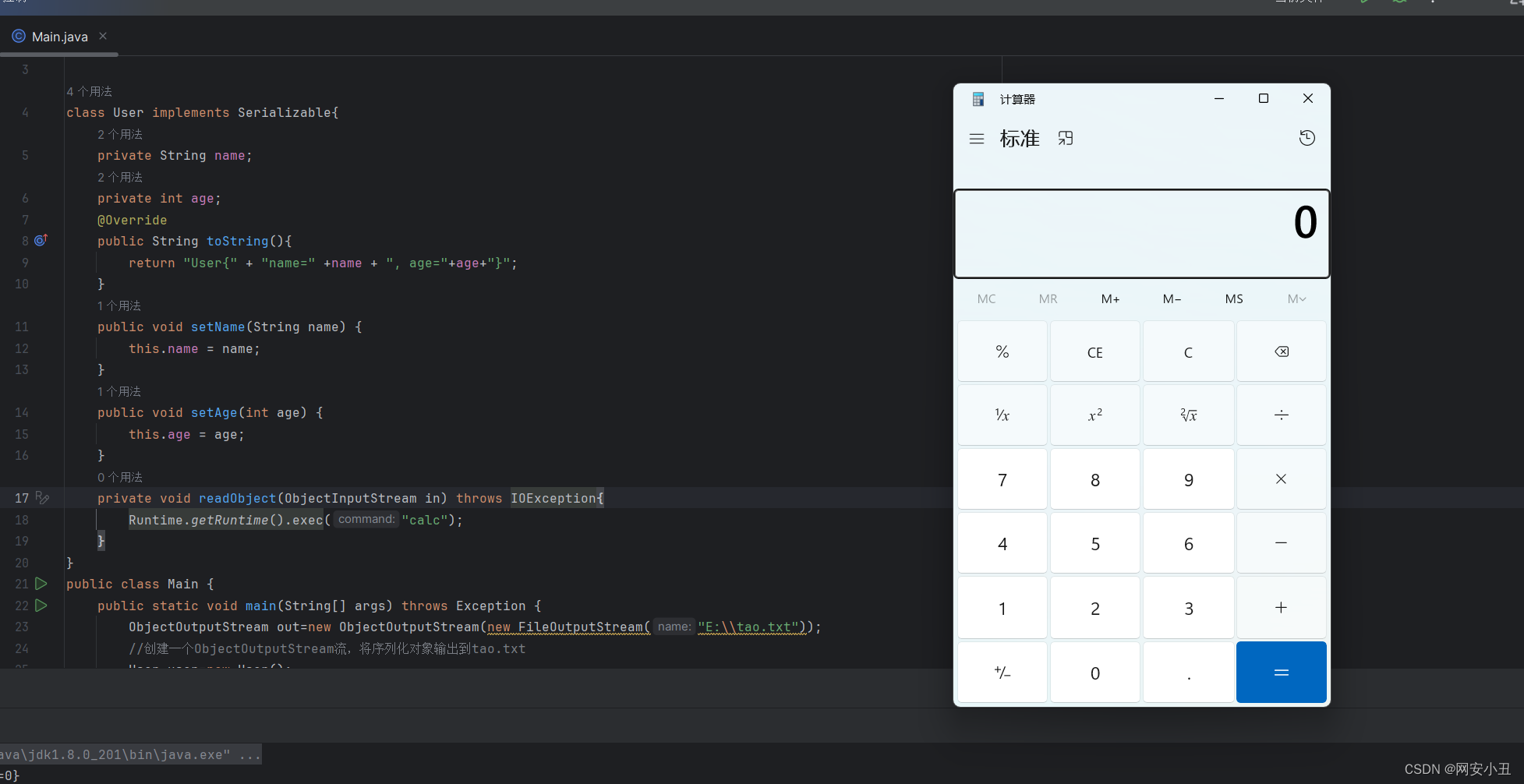
[Java安全入门]二.序列化与反序列化
一.概念 Serialization(序列化)是一种将对象以一连串的字节描述的过程;反序列化deserialization是一种将这些字节重建成一个对象的过程。将程序中的对象,放入文件中保存就是序列化,将文件中的字节码重新转成对象就是反…...

Dutree:Linux 文件系统磁盘使用追踪工具
在 Linux 系统中,对文件系统的磁盘使用情况进行跟踪和管理是至关重要的。dutree 是一个功能强大的工具,它能够以可视化的方式展示文件系统中的目录和文件的大小,帮助用户更好地了解磁盘空间的使用情况。本文将介绍 dutree 工具的使用方法、功…...

http和https的区别是什么?
–前言 传输信息安全性不同、连接方式不同、端口不同、证书申请方式不同 一、传输信息安全性不同 1、http协议:是超文本传输协议,信息是明文传输。如果攻击者截取了Web浏览器和网站服务器之间的传输报文,就可以直接读懂其中的信息。 2、h…...

学习Android的第十九天
目录 Android ExpandableListView 分组列表 ExpandableListView 属性 ExpandableListView 事件 ExpandableListView 的 Adapter 范例 参考文档 Android ViewFlipper 翻转视图 ViewFlipper 属性 ViewFlipper 方法 为 ViewFlipper 加入 View 例子:全屏幕可…...

C#上位机调试经验
1.使用Visual Studio的远程工具 因为上位机软件安装在工控机上,不方便调试。如果直接把代码放在工控机上,又不太安全。 可以在工控机上安装一个Visual Studio的远程工具,把随身带的笔记本电脑通过网线插在工控机上 这样可以在笔记本上使用…...

BUUCTF---[极客大挑战 2019]BabySQL1
1.这道题和之前做的几道题是相似的,这道题考的知识点更多。难度也比之前的大一些 2.尝试万能密码 or 1#发现过滤了or,使用1和1,发现他对单引号也进行了过滤。于是我尝试进行双写绕过,发现可以通过了。 3.由之前的做题经验可知,这道题会涉及到…...
0基础跨考计算机|408保姆级全年计划
我也是零基础备考408! 虽说是计算机专业,但是本科一学期学十几门,真的期末考试完脑子里什么都不进的...基本都是考前一周发疯学完水过考试...😅 想要零基础跨考可以直接从王道开始!跟教材一点一点啃完全没必要🥸 现在…...
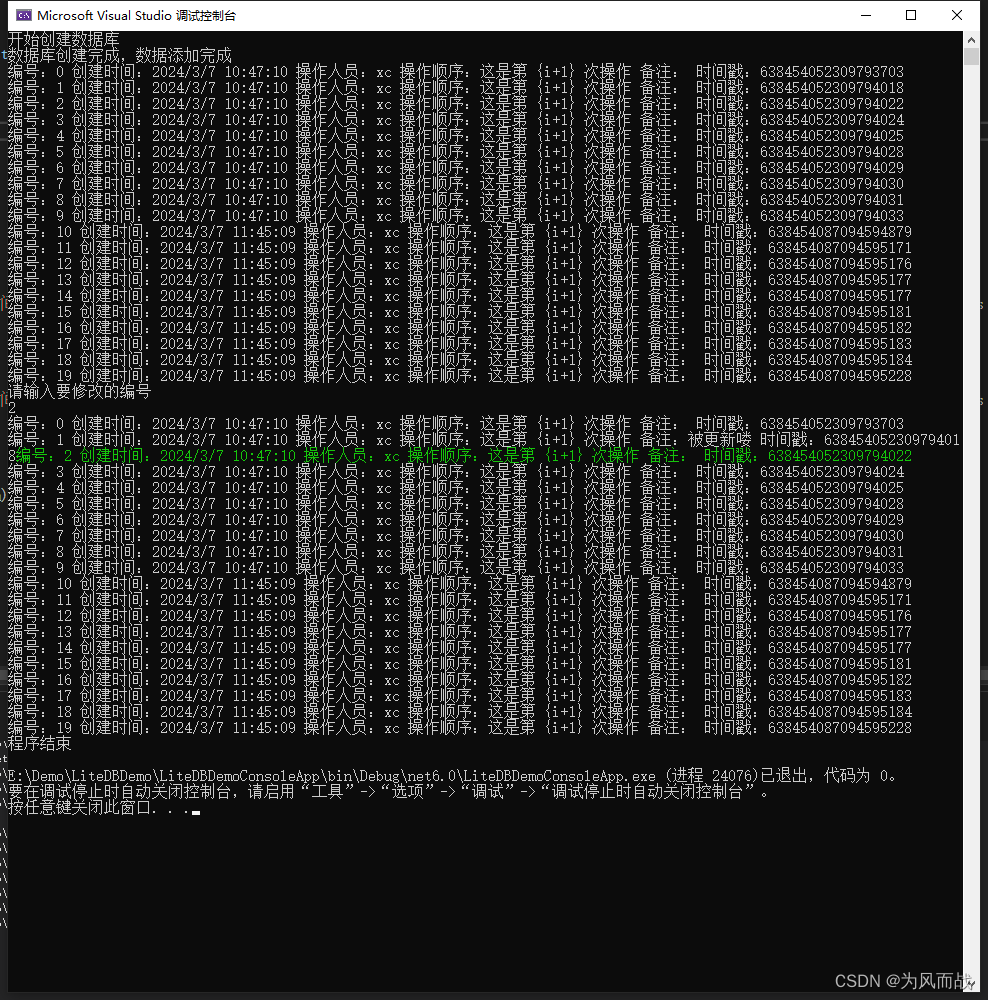
C# 操作LiteDB
1、很简单的东西不废话,直接上图上代码。 2、NuGet程序中根据自己的项目版本安装LiteDB,如下图: 3、程序运行加过如下图: 4、程序代码如下: using System; using System.Collections.Generic; using System.Linq; using System…...

LeetCode 2917.找出数组中的 K-or 值:基础位运算
【LetMeFly】2917.找出数组中的 K-or 值:基础位运算 力扣题目链接:https://leetcode.cn/problems/find-the-k-or-of-an-array/ 给你一个下标从 0 开始的整数数组 nums 和一个整数 k 。 nums 中的 K-or 是一个满足以下条件的非负整数: 只有…...

MySQL窗口函数:从理论到实践
目录 1. ROW_NUMBER() 2. RANK() 3. DENSE_RANK() 4. NTILE(n) 5. LAG() 和 LEAD() 6. FIRST_VALUE() 和 LAST_VALUE() 总结 MySQL中的窗口函数(Window Functions)允许用户对一个结果集的窗口(或分区)执行计算,…...

Vue+SpringBoot打造考研专业课程管理系统
目录 一、摘要1.1 项目介绍1.2 项目录屏 二、功能模块2.1 数据中心模块2.2 考研高校模块2.3 高校教师管理模块2.4 考研专业模块2.5 考研政策模块 三、系统设计3.1 用例设计3.2 数据库设计3.2.1 考研高校表3.2.2 高校教师表3.2.3 考研专业表3.2.4 考研政策表 四、系统展示五、核…...
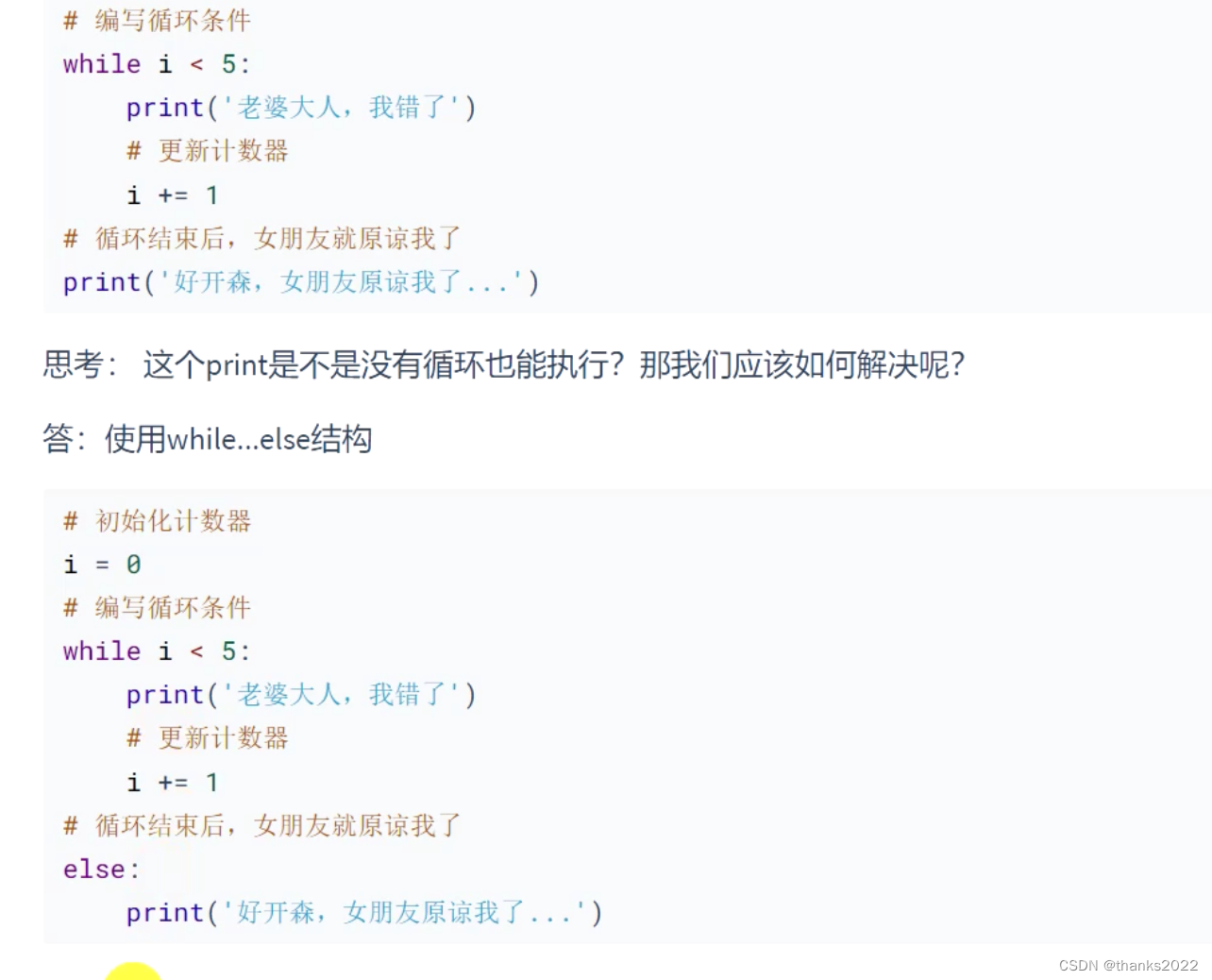
python基础第二天
世界杯小组赛成绩 注意: 1.循环 1.1while 1.2for 1.3 range 1.4 while else while 循环正常执行完才能执行else语句...

YOLOV9论文解读
代码:https://github.com/WongKinYiu/yolov9论文:https://arxiv.org/abs/2402.1361本文提出可编程梯度信息(PGI)和基于梯度路径规划的通用高效层聚合网络(GELAN),最终铸成YOLOv9目标检测全新工作!性能表现SOTA!在各个方…...

【Spring】21 通过@Primary注解优化注解驱动的自动装配
文章目录 Primary注解简介优势和适用场景小结 Spring 框架提供了强大的依赖注入机制,其中 Autowired 注解是一种常用的方式。然而,当存在多个候选 bean 时,通过类型自动装配可能导致选择困难。为了更好地控制这一过程,Spring 引入…...

【HTML】HTML基础7.3(自定义列表)
目录 标签 效果 代码 注意 标签 <dl> <dt>自定义标题</dt><dd>内容1</dd><dd>内容2</dd><dd>内容3</dd> 。。。。。。 </dl> 效果 代码 <dl><dt>蜘蛛侠系列</dt><dd>蜘蛛侠1</dd…...
)
java设计模式课后作业(待批改)
此文章仅记录学习,欢迎各位大佬探讨 实验(一) 面向对象设计 实验目的 ①使用类来封装对象的属性和功能; ②掌握类变量与实例变量,以及类方法与实例方法的区别; 知识回顾 详情见OOP课件 实验内容…...

qt 语音引擎 QTextToSpeech Microsoft SAPI
QT中语音播报的代码 在QT中实现语音播报可以使用QTextToSpeech类,具体代码如下: #include <QCoreApplication> #include <QTextToSpeech> #include <QDebug>int main(int argc, char *argv[]) {QCoreApplication a(argc, argv);// 创…...

react hook: useimperativeHandle
通过 useImperativeHandle,子组件可以选择性地暴露给父组件某些属性或方法,而不是将所有属性和方法暴露出去。 父组件 获得自组件的 ref,就能通过该 ref 来调用 focus来聚焦等功能 在 forwardRef 包装的组件中,ref 固定地是第二个…...
)
30天自制操作系统(第28天)
28.1 alloca __alloca 会在下述情况下被 C 语言的程序调用(采用 near-CALL 的方式)。 1、要执行的操作从栈中分配 EAX 个字节的内存空间( ESP - EAX; ) 2、要遵守的规则不能改变 ECX 、 EDX 、 EBX 、 EBP 、 ESI 、 EDI的值&am…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...