Elasticsearch:从 Java High Level Rest Client 切换到新的 Java API Client
作者:David Pilato

我经常在讨论中看到与 Java API 客户端使用相关的问题。 为此,我在 2019 年启动了一个 GitHub 存储库,以提供一些实际有效的代码示例并回答社区提出的问题。
从那时起,高级 Rest 客户端 (High Level Rest Cliet - HLRC) 已被弃用,并且新的 Java API 客户端已发布。
为了继续回答问题,我最近需要将存储库升级到这个新客户端。 尽管它在幕后使用相同的低级 Rest 客户端,并且已经提供了升级文档,但升级它并不是一件小事。
我发现分享为此必须执行的所有步骤很有趣。 如果你 “只是寻找” 进行升级的拉取请求,请查看:
- 切换到新的 Java API 客户端
- 升级到 Elastic 8.7.1
这篇博文将详细介绍你在这些拉取请求中可以看到的一些主要步骤。
Java 高级 Rest 客户端 (High Level Rest Client)
我们从一个具有以下特征的项目开始:
- Maven 项目(但这也可以应用于 Gradle 项目)
- 使用以下任一方法运行 Elasticsearch 7.17.16:
- Docker compose
- 测试容器
- 使用高级 Rest 客户端 7.17.16
注意:大家在这里对于 7.17.16 的选择可能有点糊涂。我们需要记住的一点是上一个大的版本的最后一个版本和下一个大的版本的第一个是兼容的。

客户端依赖项是:
<!-- Elasticsearch HLRC -->
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.17.16</version>
</dependency><!-- Jackson for json serialization/deserialization -->
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>2.15.0</version>
</dependency>
<dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-databind</artifactId><version>2.15.0</version>
</dependency>我们正在检查本地 Elasticsearch 实例是否正在 http://localhost:9200 上运行。 如果没有,我们将启动测试容器:
@BeforeAll
static void startOptionallyTestcontainers() {client = getClient("http://localhost:9200");if (client == null) {container = new ElasticsearchContainer(DockerImageName.parse("docker.elastic.co/elasticsearch/elasticsearch").withTag("7.17.16")).withPassword("changeme");container.start();client = getClient(container.getHttpHostAddress());assumeNotNull(client);}
}为了构建客户端(RestHighLevelClient),我们使用:
static private RestHighLevelClient getClient(String elasticsearchServiceAddress) {try {final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();credentialsProvider.setCredentials(AuthScope.ANY,new UsernamePasswordCredentials("elastic", "changeme"));// Create the low-level clientRestClientBuilder restClient = RestClient.builder(HttpHost.create(elasticsearchServiceAddress)).setHttpClientConfigCallback(hcb -> hcb.setDefaultCredentialsProvider(credentialsProvider));// Create the high-level clientRestHighLevelClient client = new RestHighLevelClient(restClient);MainResponse info = client.info(RequestOptions.DEFAULT);logger.info("Connected to a cluster running version {} at {}.", info.getVersion().getNumber(), elasticsearchServiceAddress);return client;} catch (Exception e) {logger.info("No cluster is running yet at {}.", elasticsearchServiceAddress);return null;}
}你可能已经注意到,我们正在尝试调用 GET / 端点来确保客户端在开始测试之前确实已连接:
MainResponse info = client.info(RequestOptions.DEFAULT);然后,我们可以开始运行测试,如下例所示:
@Test
void searchData() throws IOException {try {// Delete the index if existclient.indices().delete(new DeleteIndexRequest("search-data"), RequestOptions.DEFAULT);} catch (ElasticsearchStatusException ignored) { }// Index a documentclient.index(new IndexRequest("search-data").id("1").source("{\"foo\":\"bar\"}", XContentType.JSON), RequestOptions.DEFAULT);// Refresh the indexclient.indices().refresh(new RefreshRequest("search-data"), RequestOptions.DEFAULT);// Search for documentsSearchResponse response = client.search(new SearchRequest("search-data").source(new SearchSourceBuilder().query(QueryBuilders.matchQuery("foo", "bar"))), RequestOptions.DEFAULT);logger.info("response.getHits().totalHits = {}", response.getHits().getTotalHits().value);
}所以如果我们想将此代码升级到 8.11.3,我们需要:
- 使用相同的 7.17.16 版本将代码升级到新的 Elasticsearch Java API Client
- 将服务器和客户端都升级到 8.11.3
另一个非常好的策略是先升级服务器,然后升级客户端。 它要求你设置 HLRC 的兼容模式:
RestHighLevelClient esClient = new RestHighLevelClientBuilder(restClient).setApiCompatibilityMode(true).build()我选择分两步进行,以便我们更好地控制升级过程并避免混合问题。 升级的第一步是最大的一步。 第二个要轻得多,主要区别在于 Elasticsearch 现在默认受到保护(密码和 SSL 自签名证书)。
在本文的其余部分中,我有时会将 “old” Java 代码作为注释,以便你可以轻松比较最重要部分的更改。
新的 Elasticsearch Java API 客户端
所以我们需要修改 pom.xml:
<!-- Elasticsearch HLRC -->
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.17.16</version>
</dependency>到:
<!-- Elasticsearch Java API Client -->
<dependency><groupId>co.elastic.clients</groupId><artifactId>elasticsearch-java</artifactId><version>7.17.16</version>
</dependency>容易,对吧?
嗯,没那么容易。 。 。 因为现在我们的项目不再编译了。 因此,让我们进行必要的调整。 首先,我们需要更改创建 ElasticsearchClient 而不是 RestHighLevelClient 的方式:
static private ElasticsearchClient getClient(String elasticsearchServiceAddress) {try {final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();credentialsProvider.setCredentials(AuthScope.ANY,new UsernamePasswordCredentials("elastic", "changeme"));// Create the low-level client// Before:// RestClientBuilder restClient = RestClient.builder(HttpHost.create(elasticsearchServiceAddress))// .setHttpClientConfigCallback(hcb -> hcb.setDefaultCredentialsProvider(credentialsProvider));// After:RestClient restClient = RestClient.builder(HttpHost.create(elasticsearchServiceAddress)).setHttpClientConfigCallback(hcb -> hcb.setDefaultCredentialsProvider(credentialsProvider)).build();// Create the transport with a Jackson mapperElasticsearchTransport transport = new RestClientTransport(restClient, new JacksonJsonpMapper());// And create the API client// Before:// RestHighLevelClient client = new RestHighLevelClient(restClient);// After:ElasticsearchClient client = new ElasticsearchClient(transport);// Before:// MainResponse info = client.info(RequestOptions.DEFAULT);// After:InfoResponse info = client.info();// Before:// logger.info("Connected to a cluster running version {} at {}.", info.getVersion().getNumber(), elasticsearchServiceAddress);// After:logger.info("Connected to a cluster running version {} at {}.", info.version().number(), elasticsearchServiceAddress);return client;} catch (Exception e) {logger.info("No cluster is running yet at {}.", elasticsearchServiceAddress);return null;}
}主要的变化是我们现在在 RestClient(低级别)和 ElasticsearchClient 之间有一个 ElasticsearchTransport 类。 此类负责 JSON 编码和解码。 这包括应用程序类的序列化和反序列化,以前必须手动完成,现在由 JacksonJsonpMapper 处理。
另请注意,请求选项是在客户端上设置的。 我们不再需要通过任何 API 来传递 RequestOptions.DEFAULT,这里是 info API (GET /):
InfoResponse info = client.info();“getters” 也被简化了很多。 因此,我们现在调用 info.version().number(),而不是调用 info.getVersion().getNumber()。 不再需要获取前缀!
使用新客户端
让我们将之前看到的 searchData() 方法切换到新客户端。 现在删除索引是:
try {// Before:// client.indices().delete(new DeleteIndexRequest("search-data"), RequestOptions.DEFAULT);// After:client.indices().delete(dir -> dir.index("search-data"));
} catch (/* ElasticsearchStatusException */ ElasticsearchException ignored) { }在这段代码中我们可以看到什么?
- 我们现在大量使用 lambda 表达式,它采用构建器对象作为参数。 它需要在思想上切换到这种新的设计模式。 但这实际上是超级智能的,就像你的 IDE 一样,你只需要自动完成即可准确查看选项,而无需导入任何类或只需提前知道类名称。 经过一些练习,它成为使用客户端的超级优雅的方式。 如果你更喜欢使用构建器对象,它们仍然可用,因为这是这些 lambda 表达式在幕后使用的内容。 但是,它使代码变得更加冗长,因此你确实应该尝试使用 lambda。
- dir 在这里是删除索引请求构建器。 我们只需要使用 index(“search-data”) 定义我们想要删除的索引。
- ElasticsearchStatusException 更改为 ElasticsearchException。
要索引单个 JSON 文档,我们现在执行以下操作:
// Before:
// client.index(new IndexRequest("search-data").id("1").source("{\"foo\":\"bar\"}", XContentType.JSON), RequestOptions.DEFAULT);
// After:
client.index(ir -> ir.index("search-data").id("1").withJson(new StringReader("{\"foo\":\"bar\"}")));与我们之前看到的一样,lambdas (ir) 的使用正在帮助我们创建索引请求。 这里我们只需要定义索引名称 (index("search-data")) 和 id (id("1")) 并使用 withJson(new StringReader("{\"foo\":\ "bar\"}"))。
refresh API 调用现在非常简单:
// Before:
// client.indices().refresh(new RefreshRequest("search-data"), RequestOptions.DEFAULT);
// After:
client.indices().refresh(rr -> rr.index("search-data"));搜索是另一场野兽。 一开始看起来很复杂,但通过一些实践你会发现生成代码是多么容易:
// Before:
// SearchResponse response = client.search(new SearchRequest("search-data").source(
// new SearchSourceBuilder().query(
// QueryBuilders.matchQuery("foo", "bar")
// )
// ), RequestOptions.DEFAULT);
// After:
SearchResponse<Void> response = client.search(sr -> sr.index("search-data").query(q -> q.match(mq -> mq.field("foo").query("bar"))),Void.class);lambda 表达式参数是构建器:
- sr 是 SearchRequest 构建器。
- q 是查询构建器。
- mq 是 MatchQuery 构建器。
如果你仔细查看代码,你可能会发现它非常接近我们所知的 json 搜索请求:
{"query": {"match": {"foo": {"query": "bar"}}}
}这实际上是我一步步编码的方式:
client.search(sr -> sr, Void.class);我将 Void 定义为我想要返回的 bean,这意味着我不关心解码 _source JSON 字段,因为我只想访问响应对象。
然后我想定义要在其中搜索数据的索引:
client.search(sr -> sr.index("search-data"), Void.class);因为我想提供一个查询,所以我基本上是这样写的:
client.search(sr -> sr.index("search-data").query(q -> q),Void.class);我的 IDE 现在可以帮助我找到我想要使用的查询:
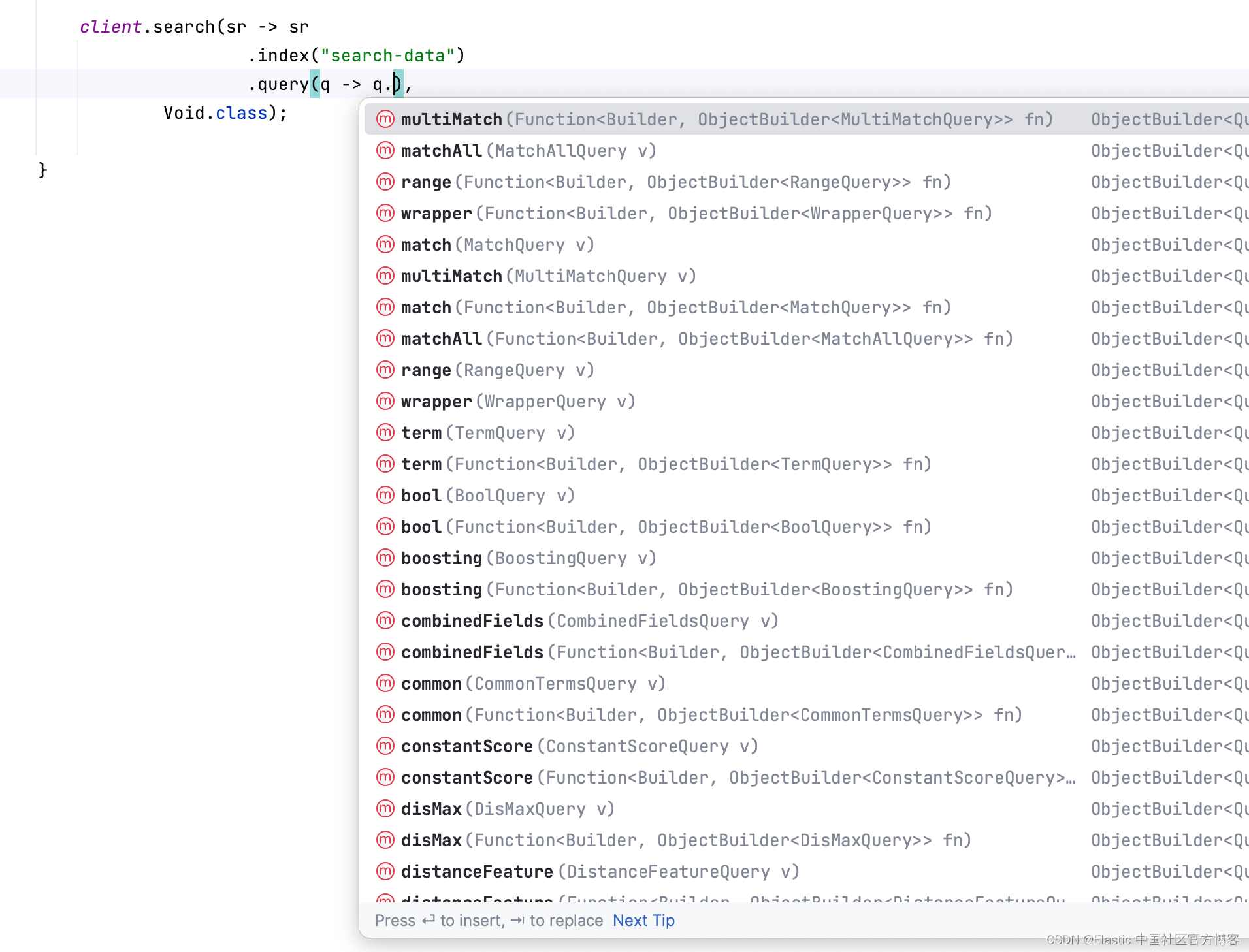
我想使用匹配查询:
client.search(sr -> sr.index("search-data").query(q -> q.match(mq -> mq)),Void.class);我只需定义要搜索的 field (foo) 和要应用的 query (bar):
client.search(sr -> sr.index("search-data").query(q -> q.match(mq -> mq.field("foo").query("bar"))),Void.class);我现在可以要求 IDE 从结果中生成一个字段,并且我可以进行完整的调用:
SearchResponse<Void> response = client.search(sr -> sr.index("search-data").query(q -> q.match(mq -> mq.field("foo").query("bar"))),Void.class);我可以从响应对象中读取 hits 总数:
// Before:
// logger.info("response.getHits().totalHits = {}", response.getHits().getTotalHits().value);
// After:
logger.info("response.hits.total.value = {}", response.hits().total().value());Exists API
让我们看看如何将调用切换到 exists API:
// Before:
boolean exists1 = client.exists(new GetRequest("test", "1"), RequestOptions.DEFAULT);
boolean exists2 = client.exists(new GetRequest("test", "2"), RequestOptions.DEFAULT);现在可以变成:
// After:
boolean exists1 = client.exists(gr -> gr.index("exist").id("1")).value();
boolean exists2 = client.exists(gr -> gr.index("exist").id("2")).value();Bulk API
要批量对 Elasticsearch 进行索引/删除/更新操作,你绝对应该使用 Bulk API:
BinaryData data = BinaryData.of("{\"foo\":\"bar\"}".getBytes(StandardCharsets.UTF_8), ContentType.APPLICATION_JSON);
BulkResponse response = client.bulk(br -> {br.index("bulk");for (int i = 0; i < 1000; i++) {br.operations(o -> o.index(ir -> ir.document(data)));}return br;
});
logger.info("bulk executed in {} ms {} errors", response.errors() ? "with" : "without", response.ingestTook());
if (response.errors()) {response.items().stream().filter(p -> p.error() != null).forEach(item -> logger.error("Error {} for id {}", item.error().reason(), item.id()));
}请注意,该操作也可以是 DeleteRequest:
br.operations(o -> o.delete(dr -> dr.id("1")));BulkProcessor 到 BulkIngester 助手
我一直很喜欢的 HLRC 功能之一是 BulkProcessor。 它就像 “一劳永逸 ”的功能,当你想要使用批量(bulk API)发送大量文档时,该功能非常有用。
正如我们之前所看到的,我们需要手动等待数组被填充,然后准备批量请求。
有了BulkProcessor,事情就容易多了。 你只需添加索引/删除/更新操作,BulkProcessor 将在你达到阈值时自动创建批量请求:
- 文件数量
- 全局有效载荷的大小
- 给定的时间范围
// Before:
BulkProcessor bulkProcessor = BulkProcessor.builder((request, bulkListener) -> client.bulkAsync(request, RequestOptions.DEFAULT, bulkListener),new BulkProcessor.Listener() {@Override public void beforeBulk(long executionId, BulkRequest request) {logger.debug("going to execute bulk of {} requests", request.numberOfActions());}@Override public void afterBulk(long executionId, BulkRequest request, BulkResponse response) { logger.debug("bulk executed {} failures", response.hasFailures() ? "with" : "without");}@Override public void afterBulk(long executionId, BulkRequest request, Throwable failure) { logger.warn("error while executing bulk", failure);}}).setBulkActions(10).setBulkSize(new ByteSizeValue(1L, ByteSizeUnit.MB)).setFlushInterval(TimeValue.timeValueSeconds(5L)).build();让我们将该部分移至新的 BulkIngester 以注入我们的 Person 对象:
// After:
BulkIngester<Person> ingester = BulkIngester.of(b -> b.client(client).maxOperations(10_000).maxSize(1_000_000).flushInterval(5, TimeUnit.SECONDS));更具可读性,对吧? 这里的要点之一是你不再被迫提供 listener,尽管我相信这仍然是正确处理错误的良好实践。 如果你想提供一个 listener,只需执行以下操作:
// After:
BulkIngester<Person> ingester = BulkIngester.of(b -> b.client(client).maxOperations(10_000).maxSize(1_000_000).flushInterval(5, TimeUnit.SECONDS)).listener(new BulkListener<Person>() {@Override public void beforeBulk(long executionId, BulkRequest request, List<Person> persons) {logger.debug("going to execute bulk of {} requests", request.operations().size());}@Override public void afterBulk(long executionId, BulkRequest request, List<Person> persons, BulkResponse response) {logger.debug("bulk executed {} errors", response.errors() ? "with" : "without");}@Override public void afterBulk(long executionId, BulkRequest request, List<Person> persons, Throwable failure) {logger.warn("error while executing bulk", failure);}});每当你需要在代码中添加一些请求到 BulkProcessor 时:
// Before:
void index(Person person) {String json = mapper.writeValueAsString(person);bulkProcessor.add(new IndexRequest("bulk").source(json, XContentType.JSON));
}现在变成了:
// After:
void index(Person person) {ingester.add(bo -> bo.index(io -> io.index("bulk").document(person)));
}如果你想发送原始 json 字符串,你应该使用 Void 类型这样做:
BulkIngester<Void> ingester = BulkIngester.of(b -> b.client(client).maxOperations(10));void index(String json) {BinaryData data = BinaryData.of(json.getBytes(StandardCharsets.UTF_8), ContentType.APPLICATION_JSON);ingester.add(bo -> bo.index(io -> io.index("bulk").document(data)));
}当你的应用程序退出时,你需要确保关闭 BulkProcessor,这将导致挂起的操作之前被刷新,这样你就不会丢失任何文档:
// Before:
bulkProcessor.close();现在很容易转换成:
// After:
ingester.close();当然,当使用 try-with-resources 模式时,你可以省略 close() 调用,因为 BulkIngester 是 AutoCloseable 的:
try (BulkIngester<Void> ingester = BulkIngester.of(b -> b.client(client).maxOperations(10_000).maxSize(1_000_000).flushInterval(5, TimeUnit.SECONDS)
)) {BinaryData data = BinaryData.of("{\"foo\":\"bar\"}".getBytes(StandardCharsets.UTF_8), ContentType.APPLICATION_JSON);for (int i = 0; i < 1000; i++) {ingester.add(bo -> bo.index(io -> io.index("bulk").document(data)));}
}好处
我们已经在 BulkIngester 部分中触及了这一点,但新 Java API 客户端添加的重要功能之一是你现在可以提供 Java Bean,而不是手动执行序列化/反序列化。 这在编码方面可以节省时间。
因此,要索引 Person 对象,我们可以这样做:
void index(Person person) {client.index(ir -> ir.index("person").id(person.getId()).document(person));
}以我的愚见,力量来自于搜索。 我们现在可以直接读取我们的实体:
client.search(sr -> sr.index("search-data"), Person.class);
SearchResponse<Person> response = client.search(sr -> sr.index("search-data"), Person.class);
for (Hit<Person> hit : response.hits().hits()) {logger.info("Person _id = {}, id = {}, name = {}", hit.id(), // Elasticsearch _id metadatahit.source().getId(), // Person idhit.source().getName()); // Person name
}这里的 source() 方法可以直接访问 Person 实例。 你不再需要自己反序列化 json _source 字段。
更多阅读:
- Elasticsearch:使用 Low Level Java 客户端来创建连接 - Elastic Stack 8.x
原文:Switching from the Java High Level Rest Client to the new Java API Client | Elastic Blog
相关文章:
Elasticsearch:从 Java High Level Rest Client 切换到新的 Java API Client
作者:David Pilato 我经常在讨论中看到与 Java API 客户端使用相关的问题。 为此,我在 2019 年启动了一个 GitHub 存储库,以提供一些实际有效的代码示例并回答社区提出的问题。 从那时起,高级 Rest 客户端 (High Level Rest Clie…...
七:分布式
一、Nginx nginx安装 【1】安装pcre依赖 1.下载压缩包:wget http://downloads.sourceforge.net/project/pcre/pcre/8.37/pcre-8.37.tar.gz 2.解压压缩包:tar -xvf pcre-8.37.tar.gz 3.安装gcc:yum install gcc 4.安装gcc:yum ins…...
1-postgresql数据库高可用脚本详解
问题: pgrep -f postgres > /dev/null && echo 0 || pkill keepalived 这是什么意思 建议换成 pgrep -f postmaster > /dev/null && echo 0 || pkill keepalived 回答 这条命令是一个复合命令,包含条件执行和重定向的元素。让我们…...

【亲测】Onlyfans年龄认证怎么办?Onlyfans需要年龄验证?
1. 引言 什么是OnlyFans:OnlyFans是一种内容订阅服务,成立于2016年,允许内容创作者从用户那里获得资金,用户需要支付订阅费用才能查看他们的内容。它在多个领域受到欢迎,包括音乐、健身、摄影,以及成人内容…...

ASP.NET Core新特性
1. ASP.NET Core2.1 ASP.NET Core 2.1于2018年5月30日发布。是ASP.NET Core框架的一个重要版本,带来了许多新功能和改进。以下是ASP.NET Core 2.1中一些主要的特性: SignalR:引入了 SignalR,这是一个实时通信库,使得构…...
26-Java访问者模式 ( Visitor Pattern )
Java访问者模式 摘要实现范例 访问者模式(Visitor Pattern)使用了一个访问者类,它改变了元素类的执行算法,通过这种方式,元素的执行算法可以随着访问者改变而改变访问者模式中,元素对象已接受访问者对象&a…...
电子科技大学链时代工作室招新题C语言部分---题号G
1. 题目 问题的第一段也是非常逆天,说实话,你编不出问题背景可以不编。 这道题的大概意思就是, Pia要去坐飞机,那么行李就有限重。这时Pia想到自己带了个硬盘,众所周知,硬盘上存储的数据就是0和1的二进制序…...
体育运动直播中的智能运动跟踪和动作识别系统 - 视频分析如何协助流媒体做出实时决策
AI-Powered Streaming Vision: Transforming Real-Time Decisions with Video Analytics 原著:弗朗西斯科冈萨雷斯|斯特朗(STRONG)公司首席ML科学家 翻译:数字化营销工兵 实时视频分析通过即时处理实时视频数据&…...

Avalon总线学习
Avalon总线学习 avalon总线可以分为: Avalon clock interface Avalon reset interface Avalon Memory mapped interface Avalon iterrupt interface Avalon streaming interface Avalon tri-state conduit interface Avalon conduit interface 1、Avalon c…...
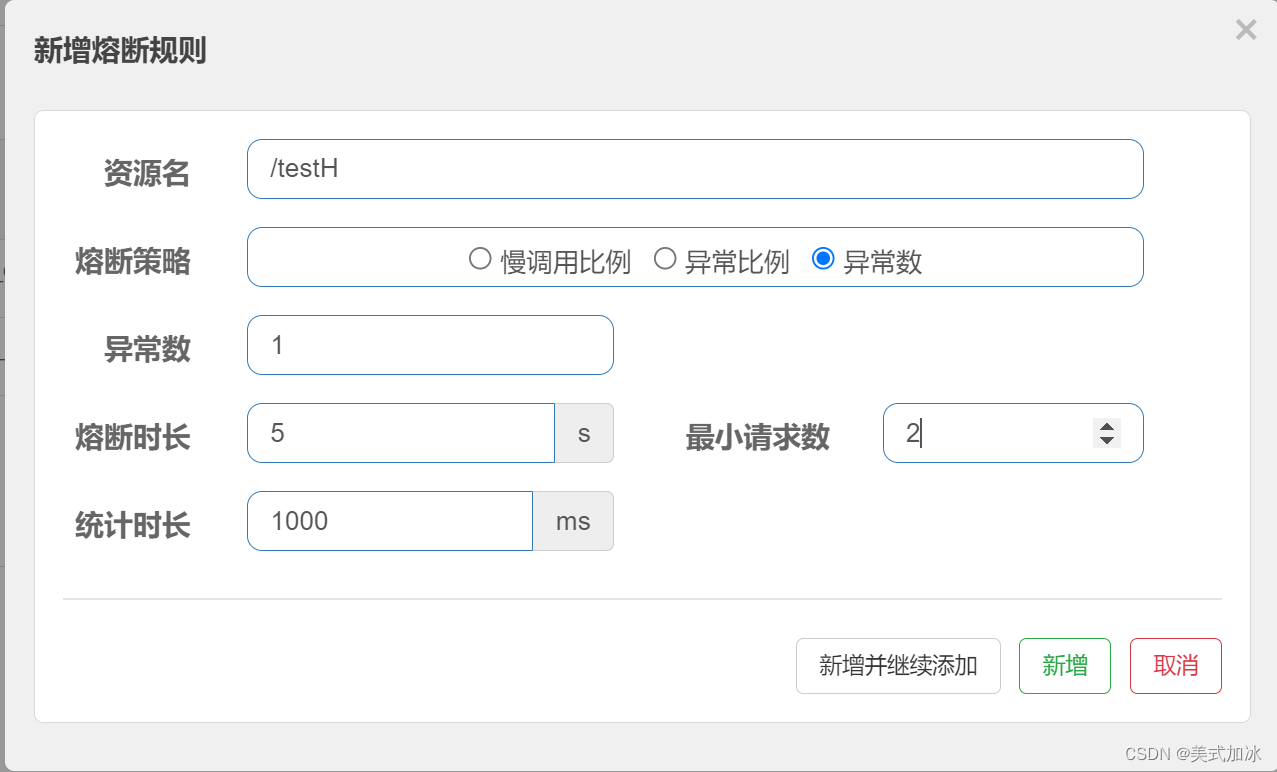
Sentinel(熔断规则)
慢调用比例 慢调用比例( SLOM_REQUEST_RATTo ):选择以慢调用比例作为阈值,需要设置允许的慢调用RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,…...

Hive借助java反射解决User-agent编码乱码问题
一、需求背景 在截取到浏览器user-agent,并想保存入数据库中,经查询发现展示的为编码后的结果。 现需要经过url解码过程,将解码后的结果保存进数据库,那么有几种实现方式。 二、问题解决 1、百度:url在线解码工具 …...
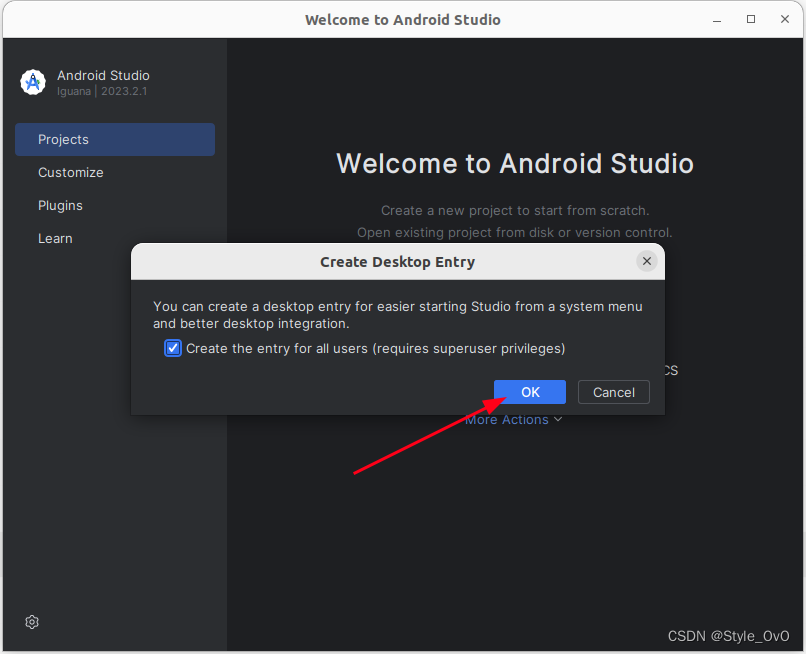
Linux下安装Android Studio及创建桌面快捷方式
下载 官网地址:https://developer.android.com/studio?hlzh-cn点击下载最新版本即可 安装 将下载完成后文件,进行解压,然后进入android-studio-2023.2.1.23-linux/android-studio/bin目录下,启动studio.sh即可为了更加方便的使…...
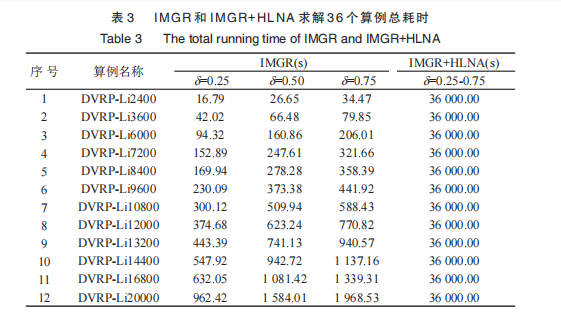
【析】一类动态车辆路径问题模型和两阶段算法
一类动态车辆路径问题模型和两阶段算法 摘要 针对一类动态车辆路径问题,分析4种主要类型动态信息对传统车辆路径问题的本质影响,将动态车辆路径问题(Dynamic Vehicle Routing Problem, DVRP)转化为多个静态的多车型开放式车辆路径问题(The Fleet Size a…...

从基础入门到学穿C++
前言知识 C简介 C是一门什么样的语言,它与C语言有着什么样的关系? C语言是结构化和模块化的语言,适合处理较小规模的程序。对于复杂的问题,规模较大的程序,需要高度的抽象和建模时,C语言则不合适。为了解…...

代码随想录算法训练营第二十四天|leetcode78、90、93题
一、leetcode第93题 class Solution { public:vector<string> restoreIpAddresses(string s) {int n s.size();vector<string> res;function<void(string, int, int)> dfs [&](string ss, int idx, int t) -> void {// 终止条件,枚举完&…...

Java学习笔记NO.20
Java流程控制 1. 用户交互 Scanner Java中的Scanner类用于获取用户输入,可以从标准输入(键盘)读取各种类型的数据。 import java.util.Scanner; public class UserInputExample { public static void main(String[] args) { Scanner sc…...

关系型数据库mysql(1)基础认知和安装
目录 一.数据库的基本概念 1.1数据 1.2表 1.3数据库 1.4 DBMS 数据库管理系统 1.4.1基本功能 1.4.2优点 1.4.3DBMS的工作模式 二.数据库的发展历史 2.1发展的三个阶段 第一代数据库 第二代数据库 第三代数据库 2.2mysql发展历史 三.主流数据库 四.关系型数据库和…...
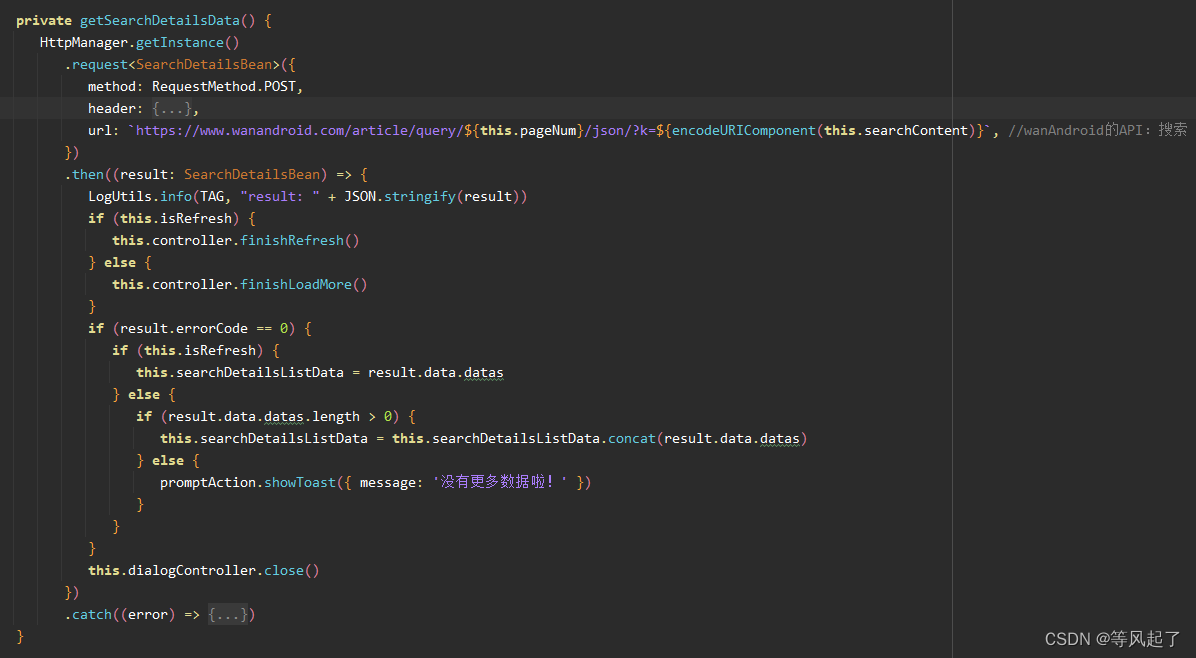
WanAndroid(鸿蒙版)开发的第三篇
前言 DevEco Studio版本:4.0.0.600 WanAndroid的API链接:玩Android 开放API-玩Android - wanandroid.com 其他篇文章参考: 1、WanAndroid(鸿蒙版)开发的第一篇 2、WanAndroid(鸿蒙版)开发的第二篇 3、WanAndroid(鸿蒙版)开发的第三篇 …...
全国农产品价格分析预测可视化系统设计与实现
全国农产品价格分析预测可视化系统设计与实现 【摘要】在当今信息化社会,数据的可视化已成为决策和分析的重要工具。尤其是在农业领域,了解和预测农产品价格趋势对于农民、政府和相关企业都至关重要。为了满足这一需求,设计并实现了全国农产…...

堆排序(数据结构)
本期讲解堆排序的实现 —————————————————————— 1. 堆排序 堆排序即利用堆的思想来进行排序,总共分为两个步骤: 1. 建堆 • 升序:建大堆 • 降序:建小堆 2. 利用堆删除思想来进行排序. 建堆和堆删…...

观成科技:隐蔽隧道工具Ligolo-ng加密流量分析
1.工具介绍 Ligolo-ng是一款由go编写的高效隧道工具,该工具基于TUN接口实现其功能,利用反向TCP/TLS连接建立一条隐蔽的通信信道,支持使用Let’s Encrypt自动生成证书。Ligolo-ng的通信隐蔽性体现在其支持多种连接方式,适应复杂网…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...

手机平板能效生态设计指令EU 2023/1670标准解读
手机平板能效生态设计指令EU 2023/1670标准解读 以下是针对欧盟《手机和平板电脑生态设计法规》(EU) 2023/1670 的核心解读,综合法规核心要求、最新修正及企业合规要点: 一、法规背景与目标 生效与强制时间 发布于2023年8月31日(OJ公报&…...

k8s从入门到放弃之HPA控制器
k8s从入门到放弃之HPA控制器 Kubernetes中的Horizontal Pod Autoscaler (HPA)控制器是一种用于自动扩展部署、副本集或复制控制器中Pod数量的机制。它可以根据观察到的CPU利用率(或其他自定义指标)来调整这些对象的规模,从而帮助应用程序在负…...