深度学习PyTorch 之 transformer-中文多分类
transformer的原理部分在前面基本已经介绍完了,接下来就是代码部分,因为transformer可以做的任务有很多,文本的分类、时序预测、NER、文本生成、翻译等,其相关代码也会有些不同,所以会分别进行介绍
但是对于不同的任务其流程是一样的,所以一些重复的步骤就不过多解释了。
1、 前期准备
数据和之前LSTM是一样的,同时我们还使用上次训练好的词嵌入模型
以下是代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
import numpy as np
from gensim.models import KeyedVectors
from sklearn.model_selection import train_test_split
import pandas as pd
import jieba
import re
from sklearn.preprocessing import LabelEncoder# 加载数据
file_path = './data/news.csv'
data = pd.read_csv(file_path)# 显示数据的前几行
data.head()# 文本清洗和分词函数
def clean_and_cut(text):# 删除特殊字符和数字text = re.sub(r'[^a-zA-Z\u4e00-\u9fff]', '', text)# 使用jieba进行分词words = jieba.cut(text)return ' '.join(words)X_train_cut = data["text"].apply(clean_and_cut)
# 显示处理后的文本
data.head()# 将标签转换为数值形式
label_encoder = LabelEncoder()
data["label"] = label_encoder.fit_transform(data["label"])
# 加载保存的word vectors
loaded_wv = KeyedVectors.load('word_vector', mmap='r') class Word2VecDataset(Dataset):def __init__(self, texts, labels, word2vec, max_len=100):self.texts = textsself.labels = labelsself.word2vec = word2vecself.max_len = max_lendef __len__(self):return len(self.texts)def __getitem__(self, idx):text = self.texts[idx]label = self.labels[idx]embeds = [self.word2vec[word] if word in self.word2vec else np.zeros(self.word2vec.vector_size) for word in text]if len(embeds) > self.max_len:embeds = embeds[:self.max_len]else:embeds += [np.zeros(self.word2vec.vector_size) for _ in range(self.max_len - len(embeds))]return torch.tensor(embeds, dtype=torch.float), torch.tensor(label, dtype=torch.long)# texts和labels是数据集中的文本和标签列表
texts = X_train_cut.tolist()
labels = data['label'].tolist()# 划分数据集
train_texts, test_texts, train_labels, test_labels = train_test_split(texts, labels, test_size=0.2)2、位置编码和主模型
import mathclass PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=100):super(PositionalEncoding, self).__init__()# 创建一个位置编码矩阵pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0) # (1, max_len, d_model)self.register_buffer('pe', pe)def forward(self, x):# x: (batch_size, max_len, d_model)x = x + self.pe.expand(x.size(0), -1, -1)return x
2.1 PositionalEncoding 类
这个类用于创建和提供位置编码。位置编码是 Transformer 模型中用于注入序列中单词的位置信息的机制。这种位置信息对于模型理解单词的顺序很重要。
初始化方法 __init__
d_model:模型的维度,也是词嵌入的维度。max_len:序列的最大长度。pe:位置编码矩阵,大小为(1, max_len, d_model)。这个矩阵被注册为一个缓冲区,这意味着它会被保存和加载与模型的其他参数一起。
前向传播方法 forward
- 输入
x的形状是(batch_size, max_len, d_model)。 self.pe.expand(x.size(0), -1, -1):这个操作将位置编码矩阵扩展为(batch_size, max_len, d_model),以便它可以与输入数据相加。- 最后,将扩展后的位置编码矩阵加到输入数据上,并返回结果。
#修改Transformer模型以添加位置编码
class TransformerClassifierWithPE(nn.Module):def __init__(self, num_classes, d_model=100, nhead=2, num_layers=2, dim_feedforward=2048, dropout=0.1):super(TransformerClassifierWithPE, self).__init__()# 位置编码self.pos_encoder = PositionalEncoding(d_model)# Transformer编码器层encoder_layers = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward, dropout=dropout)self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers=num_layers)# 分类器self.classifier = nn.Linear(d_model, num_classes)def forward(self, x):# x: (batch_size, max_len, d_model)x = self.pos_encoder(x)x = x.permute(1, 0, 2) # (max_len, batch_size, d_model)x = self.transformer_encoder(x) # (max_len, batch_size, d_model)x = x.mean(dim=0) # (batch_size, d_model)x = self.classifier(x) # (batch_size, num_classes)return x2.2 TransformerClassifierWithPE 类
这个类定义了一个带有位置编码的 Transformer 分类器模型。
初始化方法 __init__
num_classes:分类任务的类别数量。d_model:模型的维度,也是词嵌入的维度。nhead:多头注意力的头数。num_layers:Transformer 编码器层的数量。dim_feedforward:前馈网络中的隐藏层维度。dropout:Dropout 的概率。pos_encoder:PositionalEncoding 实例,用于位置编码。transformer_encoder:Transformer 编码器,由多个 TransformerEncoderLayer 组成。classifier:线性分类器,用于生成最终的分类结果。
前向传播方法 forward
- 输入
x的形状是(batch_size, max_len, d_model)。 - 首先,使用
self.pos_encoder(x)获取位置编码后的输入。 - 然后,将输入的维度从
(batch_size, max_len, d_model)转换为(max_len, batch_size, d_model),这是因为 PyTorch 的 Transformer 编码器期望的输入维度是这样的。 - 接下来,通过
self.transformer_encoder(x)应用 Transformer 编码器。 - 然后,使用
x.mean(dim=0)获取每个序列的平均表示。 - 最后,通过
self.classifier(x)应用线性分类器,得到最终的分类结果。
这个模型可以用于文本分类任务,其中输入是文本序列的词嵌入表示。
3、训练模型
# 模型参数
d_model = 512
nhead = 8
num_encoder_layers = 3
dim_feedforward = 2048
num_classes = len(data.label.unique()) # 假设label_dict是我们的标签字典
max_len = 256model = TransformerClassifierWithPE( d_model=d_model, nhead=nhead, num_layers=num_encoder_layers, dim_feedforward=dim_feedforward, num_classes=num_classes, max_len=max_len,dropout=0.1)-----------------------------
TransformerModel((pos_encoder): PositionalEncoding()(transformer_encoder): TransformerEncoder((layers): ModuleList((0-2): 3 x TransformerEncoderLayer((self_attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=512, out_features=512, bias=True))(linear1): Linear(in_features=512, out_features=2048, bias=True)(dropout): Dropout(p=0.1, inplace=False)(linear2): Linear(in_features=2048, out_features=512, bias=True)(norm1): LayerNorm((512,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((512,), eps=1e-05, elementwise_affine=True)(dropout1): Dropout(p=0.1, inplace=False)(dropout2): Dropout(p=0.1, inplace=False))))(decoder): Linear(in_features=512, out_features=10, bias=True)
)
# 训练模型
num_epochs = 20
for epoch in range(num_epochs):for inputs, labels in train_loader:# 清除梯度optimizer.zero_grad()# 前向传播outputs = model(inputs)# 计算损失loss = criterion(outputs, labels)# 反向传播loss.backward()# 更新参数optimizer.step()print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
# 在测试集上评估模型
model.eval()
with torch.no_grad():correct = 0total = 0for inputs, labels in test_loader:outputs = model(inputs)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Accuracy of the model on the test set: {100 * correct / total}%')
相关文章:
深度学习PyTorch 之 transformer-中文多分类
transformer的原理部分在前面基本已经介绍完了,接下来就是代码部分,因为transformer可以做的任务有很多,文本的分类、时序预测、NER、文本生成、翻译等,其相关代码也会有些不同,所以会分别进行介绍 但是对于不同的任务…...
STC 51单片机烧录程序遇到一直检测单片机的问题
准备工作 一,需要一个USB-TTL的下载器 ,并安装好对应的驱动程序 二、对应的下载软件,stc软件需要官方的软件(最好是最新的,个人遇到旧的下载软件出现问题) 几种出现一直检测的原因 下载软件图标…...
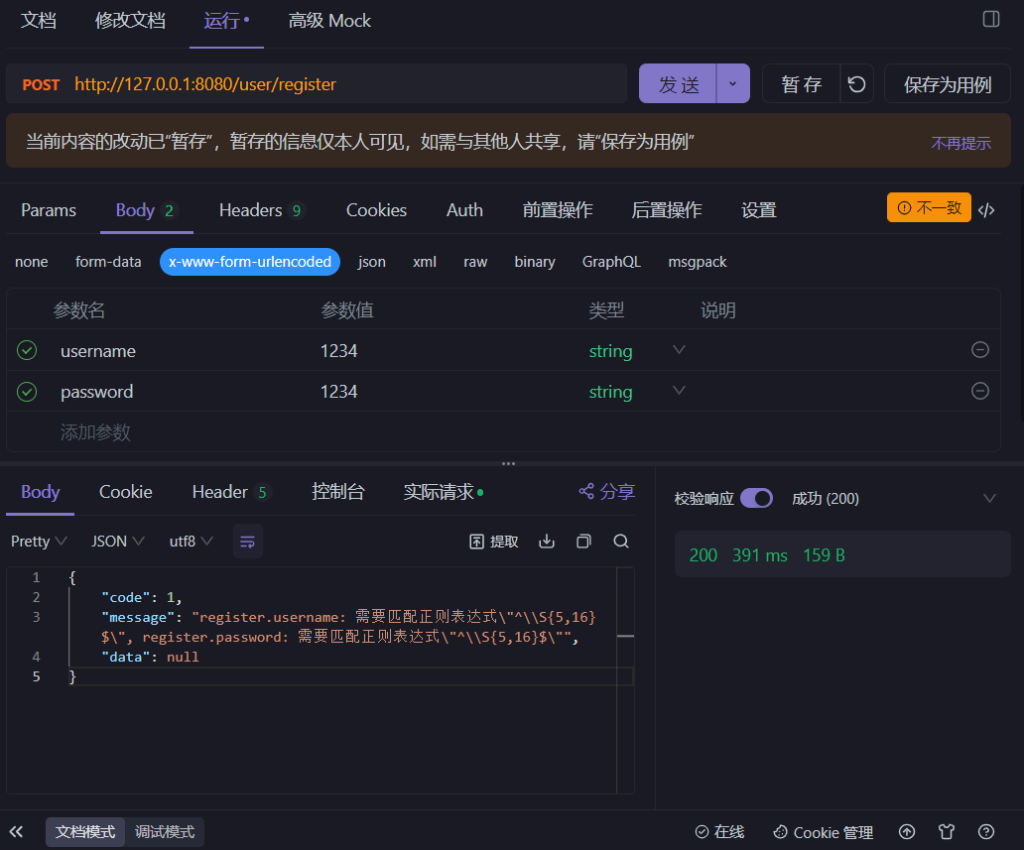
后端系统开发之——接口参数校验
今天难得双更,大家点个关注捧个场 原文地址:后端系统开发之——接口参数校验 - Pleasure的博客 下面是正文内容: 前言 在上一篇文章中提到了接口的开发,虽然是完成了,但还是缺少一些细节——传入参数的校验。 即用户…...
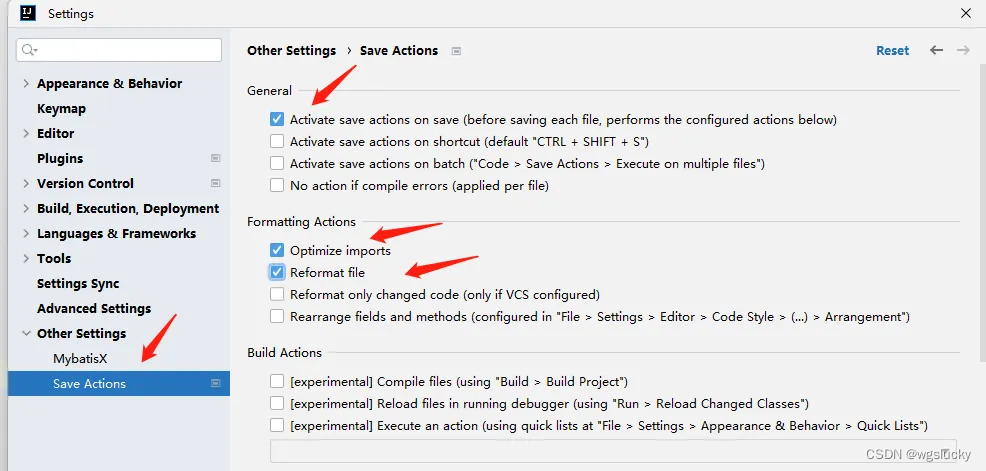
IDEA 配置阿里规范检测
IDEA中安装插件 配置代码风格检查规范 使用代码风格检测 在代码类中,右键 然后会给出一些不符合规范的修改建议: 保存代码时自动格式化代码 安装插件: 配置插件:...

数据仓库系列总结
一、数据仓库架构 1、数据仓库的概念 数据仓库(Data Warehouse)是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支持管理决策。 数据仓库通常包含多个来源的数据,这些数据按照主题进行组织和存储&#x…...

gitlab runner没有内网的访问权限应该怎么解决
如果你的GitLab Runner没有内网访问权限,但你需要访问内部资源(如私有仓库或其他服务),你可以考虑以下几种方法: VPN 或 SSH 隧道: 在允许的情况下,通过VPN或SSH隧道连接到内部网络。这将允许Gi…...
el-tree 设置默认展开指定层级
el-tree默认关闭所有选项,但是有添加或者编辑删除的情况下,需要刷新接口,此时会又要关闭所有选项; 需求:在编辑时、添加、删除 需要将该内容默认展开 <el-tree :default-expanded-keys"expandedkeys":da…...
python便民超市管理系统flask-django-nodejs-php
随着人们生活节奏的加快,以前传统的购物方式发生了巨大的改变,以前一个超市要想经营好自己的门店,每天都要忙着记账出账,尤其是出库入库统计,如果忙中出乱,可能导致今天所有的营业流水,要重新换…...
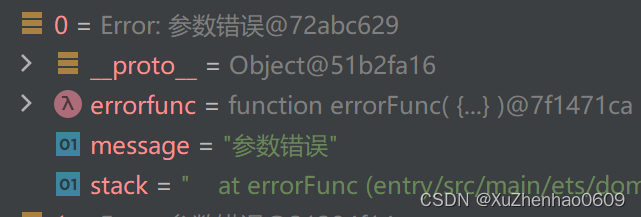
HarmonyOS — BusinessError 不能被 JSON.stringify转换
在鸿蒙中BusinessError 继承于Error,而在JavaScript(以及TypeScript,因为它是JavaScript的超集)中,Error 对象包含一些不能被 JSON.stringify 直接序列化的属性。JSON.stringify 方法会将一个JavaScript对象或者值转换…...

JupyterNotebook 如何切换使用的虚拟环境kernel
在Jupyter Notebook中,如果需要修改使用的虚拟环境Kernel: 首先,需要确保虚拟环境已经安装conda上【conda基本操作】 打开Jupyter Notebook。 在Jupyter Notebook的顶部菜单中,选择 “New” 在弹出的窗口中,列出了…...

预防GPT-3和其他复杂语言模型中的“幻觉”
标题:预防GPT-3和其他复杂语言模型中的“幻觉” 正文: “假新闻”的一个显著特征是它经常在事实正确信息的环境中呈现虚假信息,通过一种文学渗透的方式,使不真实的数据获得感知权威,这是半真半假力量令人担忧的展示。…...

从源码解析AQS
前置概念 要彻底了解AQS的底层实现就必须要了解一下线程相关的知识。 包括voliatevoliate 我们使用翻译软件翻译一下volatile,会发现它有以下几个意思:易变的;无定性的;无常性的;可能急剧波动的;不稳定的;易恶化的;易挥发的;易发散的。这也正式使用vola…...

基于Spring Boot的云上水果超市的设计与实现
摘 要 伴随着我国社会的发展,人民生活质量日益提高。于是对云上水果超市进行规范而严格是十分有必要的,所以许许多多的信息管理系统应运而生。此时单靠人力应对这些事务就显得有些力不从心了。所以本论文将设计一套云上水果超市,帮助商家进行…...

游戏引擎中的动画基础
一、动画技术简介 视觉残留理论 - 影像在我们的视网膜上残留1/24s。 游戏中动画面临的挑战: 交互:游戏中的玩家动画需要和场景中的物体进行交互。实时:最慢需要在1/30秒内算完所有的场景渲染和动画数据。(可以用动画压缩解决&am…...
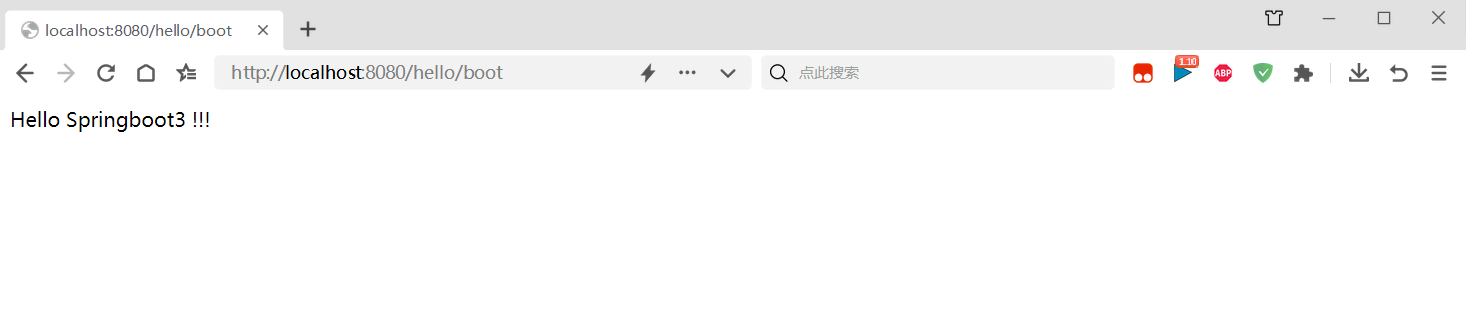
springboot3快速入门案例2024最新版
前边 springboot3 系统要求 技术&工具版本(or later)maven3.6.3 or later 3.6.3 或更高版本Tomcat10.0Servlet9.0JDK17 SpringBoot的主要目标是: 为所有 Spring 开发提供更快速、可广泛访问的入门体验。开箱即用,设置合理的…...
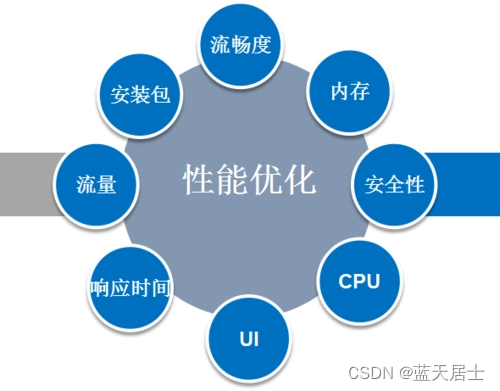
软考 系统架构设计师系列知识点之系统性能(1)
所属章节: 第2章. 计算机系统基础知识 第9节. 系统性能 系统性能是一个系统提供给用户的所有性能指标的集合。它既包括硬件性能(如处理器主频、存储器容量、通信带宽等)和软件性能(如上下文切换、延迟、执行时间等)&a…...

Trent-FPGA硬件设计课程
本课程涵盖FPGA硬件设计的基础概念和实践应用。学生将学习Verilog语言编程、数字电路设计原理、FPGA架构和开发工具的使用。通过项目实践,掌握FPGA设计流程和调试技巧,为硬件加速和嵌入式系统开发打下坚实基础。 课程大小:4.3G 课程下载&am…...

【大模型学习记录】db-gpt源码安装问题汇总
1、首次源码安装时安装的其实dbgpt到conda环境中,会将路径一起安装。 如果有其他的路径使用同样的conda环境会报错,一直读取的就是原先的路径的内容。需要自己新创建一个conda env 2、界面中配置知识库问答时,报错 # 1、报的错如下&#x…...
QB PHP 多语言配置
1: 下载QBfast .exe 的文件 2: 安装的时候 ,一定点击 仅为我 安装 而不是 所有人 3: 如果提示 更新就 更新 , 安装如2 4: 如果遇到 新增 或者编辑已经 配置的项目时 不起作用 : 右…...
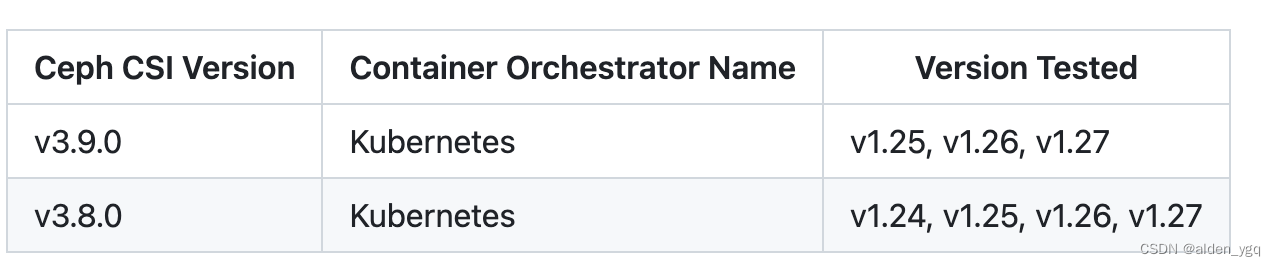
Kubernetes实战(三十一)-使用开源CEPH作为后端StorageClass
1 引言 K8S在1.13版本开始支持使用Ceph作为StorageClass。其中云原生存储Rook和开源Ceph应用都非常广泛。本文主要介绍K8S如何对接开源Ceph使用RBD卷。 K8S对接Ceph的技术栈如下图所示。K8S主要通过容器存储接口CSI和Ceph进行交互。 Ceph官方文档:Block Devices a…...

Ostrakon-VL-8B惊艳效果:复杂光照下多品牌饮料瓶自动计数与定位热力图
Ostrakon-VL-8B惊艳效果:复杂光照下多品牌饮料瓶自动计数与定位热力图 1. 引言:当AI走进零售货架 想象一下这个场景:一家大型连锁超市的饮料区,货架上密密麻麻摆满了各种品牌的饮料瓶。有可乐、雪碧、矿泉水、果汁,包…...

云容笔谈实战案例:3步生成1024×1024国风人像,Z-Image Turbo加速详解
云容笔谈实战案例:3步生成10241024国风人像,Z-Image Turbo加速详解 1. 东方美学影像创作新体验 「云容笔谈」是一个专注于东方审美风格的影像创作平台,它将现代AI算法与古典美学意境完美结合。这个系统基于Z-Image Turbo核心技术驱动&#…...

智能车竞赛实战指南:基于快马平台构建完整车辆控制应用
最近在准备智能车竞赛,发现很多同学在软件部分会遇到一个难题:如何快速搭建一个接近实战、能模拟真实车辆行为的综合控制程序?硬件调试固然重要,但一个稳定、逻辑清晰的软件框架是成功的基础。今天,我就结合自己的经验…...
深入解析影墨·今颜模型结构:从卷积神经网络到视觉Transformer
深入解析影墨今颜模型结构:从卷积神经网络到视觉Transformer 最近在图像生成领域,一个名为“影墨今颜”的模型引起了不小的关注。它生成的图像在细节、光影和风格一致性上表现相当出色。很多开发者好奇,它背后到底用了什么“黑科技”&#x…...

Matlab与MiniCPM-V-2_6联动:科学计算可视化与AI图像分析
Matlab与MiniCPM-V-2_6联动:科学计算可视化与AI图像分析 作为一名在工程仿真领域摸爬滚打了多年的工程师,我常常面临一个两难境地:Matlab跑出来的仿真结果图和数据曲线,专业、精准,但做报告或写论文时,总觉…...

Phi-3-mini新手必看:Ollama环境搭建与模型调用完整步骤
Phi-3-mini新手必看:Ollama环境搭建与模型调用完整步骤 想快速体验一个既聪明又轻巧的AI助手吗?今天要介绍的Phi-3-mini-4k-instruct,可能就是你的理想选择。它只有38亿参数,小到能在普通电脑上流畅运行,但智能程度却…...

Xilinx QSPI IP核的5个隐藏技巧:如何用AXI突发传输提升Flash读写速度
Xilinx QSPI IP核的5个隐藏技巧:如何用AXI突发传输提升Flash读写速度 在嵌入式系统设计中,Flash存储器的读写性能往往是制约整体系统响应速度的关键瓶颈。Xilinx的QSPI IP核作为连接外部Flash的重要桥梁,其配置优化对系统性能提升有着决定性影…...

GRR实战指南:从理论到实践,构建可靠的测量系统
1. GRR基础:为什么测量系统需要"体检报告"? 想象一下医生用不准的体温计给你量体温——38℃显示成36.5℃,后果会怎样?在工厂里,测量设备就像这个体温计,GRR就是给测量系统做的全面体检。我十年前…...

开源文件转换工具实战指南:3个鲜为人知的跨平台镜像处理技巧
开源文件转换工具实战指南:3个鲜为人知的跨平台镜像处理技巧 【免费下载链接】dmg2img DMG2IMG allows you to convert a (compressed) Apple Disk Images (imported from http://vu1tur.eu.org/dmg2img). Note: the master branch contains imported code, but lac…...

CGAL ::Surface Mesh 参考文档examples详解
1 引言 CGAL::Surface_mesh 是 CGAL 中用于表示多面体表面的半边数据结构(Halfedge Data Structure, HDS),是传统指针式半边结构和3D 多面体表面的轻量化替代方案,核心优势是基于整数索引而非指针,兼顾内存效率、易用…...