PyTorch深度学习:60分钟入门
PyTorch深度学习:60分钟入门
本教程的目的:
- 更高层级地理解PyTorch的Tensor库以及神经网络。
- 训练一个小的神经网络来对图像进行分类。
本教程以您拥有一定的numpy基础的前提下展开
Note: 务必确认您已经安装了 torch 和 torchvision 两个包。
这是一个基于Python的科学计算包,其旨在服务两类场合:
- 替代numpy发挥GPU潜能
- 一个提供了高度灵活性和效率的深度学习实验性平台
我们开搞
pytorch基础入门
(一)tensors
张量是一种特殊的数据结构,与数组矩阵类似,在pytoch中,使用tensors对模型的输入和输出进行编码
import torch
import numpy as np
1.tensor 初始化
# 直接数据
data=[[1,2],[3,4]]
x_data=torch.tensor(data)
# numpy 数组
np_array=np.array(data)
x_np=torch.from_numpy(np_array)
# 从另一个tensor
x_ones=torch.ones_like(x_data)#保留shape,datatype
print(f'ones tensor:\n{x_ones}\n')
x_rands=torch.rand_like(x_data,dtype=torch.float)#保留shape
print(f'random tensor:\n{x_rands}\n')
ones tensor:
tensor([[1, 1],[1, 1]])random tensor:
tensor([[0.3272, 0.3049],[0.3315, 0.8603]])
shape是tensor维度
shape=(2,3,)
rand_tensor=torch.rand(shape)
ones_tensor=torch.ones(shape)
zeros_tensor=torch.zeros(shape)
print(rand_tensor)
print(ones_tensor)
print(zeros_tensor)
tensor([[0.3955, 0.7930, 0.1733],[0.3849, 0.5444, 0.3754]])
tensor([[1., 1., 1.],[1., 1., 1.]])
tensor([[0., 0., 0.],[0., 0., 0.]])
2.tensor 性质
shape,datatype,device(存储位置)
tensor=torch.rand(3,4)
print(tensor.shape,'\n',tensor.dtype,'\n',tensor.device)
torch.Size([3, 4]) torch.float32 cpu
3.tensor 运算
转置、索引、切片、数学运算、线性代数、随机采样
# 索引和切片
tensor=torch.ones(4,4)
tensor[:,1]=0
print(tensor)
tensor([[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.]])
# 连接
t1=torch.cat([tensor,tensor,tensor],dim=1)
t1
tensor([[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.],[1., 0., 1., 1., 1., 0., 1., 1., 1., 0., 1., 1.]])
# 数字乘
tensor.mul(tensor)
tensor*tensor
# 矩阵乘
tensor.matmul(tensor.T)
tensor@tensor.T
tensor([[3., 3., 3., 3.],[3., 3., 3., 3.],[3., 3., 3., 3.],[3., 3., 3., 3.]])
# 就地操作_
print(tensor)
tensor.add_(4)
print(tensor)
tensor([[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.],[1., 0., 1., 1.]])
tensor([[5., 4., 5., 5.],[5., 4., 5., 5.],[5., 4., 5., 5.],[5., 4., 5., 5.]])
4.bridge numpy
# tensor-->numpy
t=torch.ones(5)
print(f't:{t}')
n=t.numpy()
print(f'n:{n}')
t:tensor([1., 1., 1., 1., 1.])
n:[1. 1. 1. 1. 1.]
# tensor变化会在numpy中反应
t.add_(1)
print(t)
print(n)
tensor([2., 2., 2., 2., 2.])
[2. 2. 2. 2. 2.]
# numpy-->tensor
n=np.ones(5)
t=torch.from_numpy(n)
np.add(n,1,out=n)
print(t)
print(n)
tensor([2., 2., 2., 2., 2.], dtype=torch.float64)
[2. 2. 2. 2. 2.]
(二)torch.autograd
pytorch自动差分引擎,可为神经网络训练提供支持
1.usage in pytorch
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
import torch,torchvision
model=torchvision.models.resnet18(pretrained=True)
data=torch.rand(1,3,64,64)
labels=torch.rand(1,1000)
prediction=model(data)#forward
loss=(prediction-labels).sum()#loss function
loss.backward()#backward
optim=torch.optim.SGD(model.parameters(),lr=1e-2,momentum=0.9)#lr学习率
optim.step()#初始化梯度下降
2.differentiation in autograd
import torch
#requires_grad=True:every operation on them should be tracked.
a=torch.tensor([2.,3.],requires_grad=True)
b=torch.tensor([6.,4.],requires_grad=True)
#a,b是NN参数,Q是误差
Q=3*a**3-b**2
external_grad=torch.tensor([1,1])
#Q.backward:计算Q对a,b的gradients并储存在tensor.grad中
Q.backward(gradient=external_grad)
print(a.grad)
print(b.grad)
tensor([36., 81.])
tensor([-12., -8.])
3.computational graph
autograd保留DAG(有向无环图,包含函数对象)中的所有数据(tensors)和操作
1.前向传播:计算结果tensor,记录gradient function(leaves–root)
2.反向传播:计算每个参数的梯度并保存在tensor.grad中,链式法则(root–leaves)
x=torch.rand(5,5)
y=torch.rand(5,5)
z=torch.rand((5,5),requires_grad=True)
a=x+y
print(a.requires_grad)
b=x+z
print(b.requires_grad)
False
True
frozen parameters:不计算梯度的参数,减少计算量
from torch import nn,optim
model=torchvision.models.resnet18(pretrained=True)
#frozen 所有的参数除了function的权重和偏差
for param in model.parameters():param.requires_grad=False
model.fc=nn.Linear(512,10)
optimizer=optim.SGD(model.parameters(),lr=1e-2, momentum=0.9)
(三)神经网络
torch.nn包构建神经网络
神经网络训练步骤:
1.定义神经网络(包含一些需要学习的参数/权重)
2.遍历输入数据集
3.通过网络处理输入
4.计算损失函数
5.网络参数梯度反向传播
6.通常使用简单的更新规则来更新网络的权重:weight = weight - learning_rate * gradient
1.define network
(1)Containers:
- Module:所有神经网络模型的基类
(2)Convolution Layers:
- nn.Conv2d:Applies a 2D convolution over an input signal composed of several input planes
(3)Linear Layers
- nn.Linear:Applies a linear transformation to the incoming data(y=wx+b)

import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):def __init__(self):super(Net, self).__init__()# 1 input image channel, 6 output channels, 5x5 square convolution# kernelself.conv1 = nn.Conv2d(1, 6, 5)self.conv2 = nn.Conv2d(6, 16, 5)# an affine operation: y = Wx + bself.fc1 = nn.Linear(16 * 5 * 5, 120) # 5*5 from image dimensionself.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):# Max pooling over a (2, 2) windowx = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))# If the size is a square, you can specify with a single numberx = F.max_pool2d(F.relu(self.conv2(x)), 2)x = torch.flatten(x, 1) # flatten all dimensions except the batch dimensionx = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x
net = Net()
print(net)
Net((conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))(fc1): Linear(in_features=400, out_features=120, bias=True)(fc2): Linear(in_features=120, out_features=84, bias=True)(fc3): Linear(in_features=84, out_features=10, bias=True)
)
只需要定义forward函数,就可以使用autograd自定义backward函数
模型学习参数由net.parameters()返回
params = list(net.parameters())
print(len(params))
print(params[0].size())#卷积层1的权重
#print(params)
10
torch.Size([6, 1, 5, 5])
input = torch.randn(1,1,32,32)
out = net(input)
print(out)
tensor([[ 0.0735, -0.0377, 0.1258, -0.0828, -0.0173, -0.0726, -0.0875, -0.0256,-0.0797, 0.0959]], grad_fn=<AddmmBackward0>)
使用随机梯度将所有参数和反向传播的梯度缓冲区归零
net.zero_grad
out.backward(torch.randn(1,10))
torch.nn仅支持小批量。 整个torch.nn包仅支持作为微型样本而不是单个样本的输入。例如,nn.Conv2d采用nSamples x nChannels x Height x Width的4D张量
目前为止看到的类:
- torch.Tensor:一个多维数组,支持backward()的自动微分操作,保存张量梯度
- nn.Module:神经网络模块,封装参数
- nn.Parameter:一种张量,将其分配为Module的属性时,自动注册为参数
- autograd.Function:实现自动微分操作的正向和反向定义,每个Tensor操作都会创建至少一个Function节点,该节点连接到创建Tensor的函数,并且编码其历史记录。
2.loss function
损失函数采用(输出,目标)作为输入,并计算一个值估计输出与目标之间的距离,nn包有好几种不同的损失函数,简单的如nn.MSELoss,计算均方误差
output = net(input)
target = torch.randn(10)#只是用于例子
target = target.view(1,-1)#使其与输出保持相同shape
criterion = nn.MSELoss()
loss = criterion(output,target)
print(loss)
tensor(0.4356, grad_fn=<MseLossBackward0>)

使用.grad_fn属性向后跟随loss,将得到一个计算图,调用loss.backward()时,整个图被微分,图中具有requires_grad=True的所有张量将随梯度累积其.grad张量
print(loss.grad_fn) # MSELoss
print(loss.grad_fn.next_functions[0][0]) # linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # relu
<MseLossBackward0 object at 0x7fef4965df10>
<AddmmBackward0 object at 0x7fef4965d3a0>
<AccumulateGrad object at 0x7fef4965df10>
3.Backprop
反向传播,只需要loss.backward(),在此之前先清除现有梯度,否则梯度将累计到现在的梯度中
net.zero_grad() # 清除梯度print('conv1的前偏差梯度')
print(net.conv1.bias.grad)loss.backward()print('conv1的后偏差梯度')
print(net.conv1.bias.grad)
conv1的前偏差梯度
tensor([0., 0., 0., 0., 0., 0.])
conv1的后偏差梯度
tensor([ 0.0124, 0.0051, -0.0029, -0.0088, 0.0048, 0.0012])
4.Update the weights
最简单的更新规则是随机梯度下降(SGD)
- weight = weight - learning_rate * gradient
learning_rate = 0.01
for f in net.parameters():f.data.sub_(f.grad.data*learning_rate)
但是使用神经网络时,可能需要用到不用的更新规则,如SGD,Nesterov-SGD,Adam,RMSProp等,使用torch.optim包可实现所有方法
import torch.optim as optim# 创建optimizer
optimizer = optim.SGD(net.parameters(),lr=0.01)# 在training loop里
optimizer.zero_grad() # 将梯度缓冲区手动设置为0
output = net(input)
loss = criterion(output,target)
loss.backward()
optimizer.step()
print(net.conv1.bias.grad)
tensor([ 0.0119, 0.0050, -0.0034, -0.0109, 0.0049, -0.0009])
Pytorch入门
Tensors
Tensors和numpy中的ndarrays较为相似, 与此同时Tensor也能够使用GPU来加速运算。
from __future__ import print_function
import torch
x = torch.Tensor(5, 3) # 构造一个未初始化的5*3的矩阵
x = torch.rand(5, 3) # 构造一个随机初始化的矩阵
x # 此处在notebook中输出x的值来查看具体的x内容
x.size()#NOTE: torch.Size 事实上是一个tuple, 所以其支持相关的操作*
y = torch.rand(5, 3)#此处 将两个同形矩阵相加有两种语法结构
x + y # 语法一
torch.add(x, y) # 语法二# 另外输出tensor也有两种写法
result = torch.Tensor(5, 3) # 语法一
torch.add(x, y, out=result) # 语法二
y.add_(x) # 将y与x相加# 特别注明:任何可以改变tensor内容的操作都会在方法名后加一个下划线'_'
# 例如:x.copy_(y), x.t_(), 这俩都会改变x的值。#另外python中的切片操作也是资次的。
x[:,1] #这一操作会输出x矩阵的第二列的所有值
阅读材料:
100+ Tensor的操作,包括换位、索引、切片、数学运算、线性算法和随机数等等。
详见:torch - PyTorch 0.1.9 documentation
Numpy桥
将Torch的Tensor和numpy的array相互转换简直就是洒洒水啦。注意Torch的Tensor和numpy的array会共享他们的存储空间,修改一个会导致另外的一个也被修改。
# 此处演示tensor和numpy数据结构的相互转换
a = torch.ones(5)
b = a.numpy()# 此处演示当修改numpy数组之后,与之相关联的tensor也会相应的被修改
a.add_(1)
print(a)
print(b)# 将numpy的Array转换为torch的Tensor
import numpy as np
a = np.ones(5)
b = torch.from_numpy(a)
np.add(a, 1, out=a)
print(a)
print(b)# 另外除了CharTensor之外,所有的tensor都可以在CPU运算和GPU预算之间相互转换
# 使用CUDA函数来将Tensor移动到GPU上
# 当CUDA可用时会进行GPU的运算
if torch.cuda.is_available():x = x.cuda()y = y.cuda()x + y
PyTorch中的神经网络
接下来介绍pytorch中的神经网络部分。PyTorch中所有的神经网络都来自于autograd包
首先我们来简要的看一下,之后我们将训练我们第一个的神经网络。
Autograd: 自动求导
autograd 包提供Tensor所有操作的自动求导方法。
这是一个运行时定义的框架,这意味着你的反向传播是根据你代码运行的方式来定义的,因此每一轮迭代都可以各不相同。
以这些例子来讲,让我们用更简单的术语来看看这些特性。
autograd.Variable 这是这个包中最核心的类。 它包装了一个Tensor,并且几乎支持所有的定义在其上的操作。一旦完成了你的运算,你可以调用 .backward()来自动计算出所有的梯度。
你可以通过属性 .data 来访问原始的tensor,而关于这一Variable的梯度则集中于 .grad 属性中。
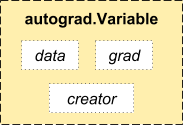
还有一个在自动求导中非常重要的类 Function。
Variable 和 Function 二者相互联系并且构建了一个描述整个运算过程的无环图。每个Variable拥有一个 .creator 属性,其引用了一个创建Variable的 Function。(除了用户创建的Variable其 creator 部分是 None)。
如果你想要进行求导计算,你可以在Variable上调用.backward()。 如果Variable是一个标量(例如它包含一个单元素数据),你无需对backward()指定任何参数,然而如果它有更多的元素,你需要指定一个和tensor的形状想匹配的grad_output参数。
from torch.autograd import Variable
x = Variable(torch.ones(2, 2), requires_grad = True)
y = x + 2
y.creator# y 是作为一个操作的结果创建的因此y有一个creator
z = y * y * 3
out = z.mean()# 现在我们来使用反向传播
out.backward()# out.backward()和操作out.backward(torch.Tensor([1.0]))是等价的
# 在此处输出 d(out)/dx
x.grad
最终得出的结果应该是一个全是4.5的矩阵。设置输出的变量为o。我们通过这一公式来计算:
o=14∑izio = \frac{1}{4}\sum_i z_io=41∑izio = \frac{1}{4}\sum_i z_i,zi=3(xi+2)2z_i = 3(x_i+2)^2zi=3(xi+2)2z_i = 3(x_i+2)^2,zi∣xi=1=27z_i\bigr\rvert_{x_i=1} = 27zixi=1=27z_i\bigr\rvert_{x_i=1} = 27,因此,∂o∂xi=32(xi+2)\frac{\partial o}{\partial x_i} = \frac{3}{2}(x_i+2)∂xi∂o=23(xi+2)\frac{\partial o}{\partial x_i} = \frac{3}{2}(x_i+2),最后有∂o∂xi∣xi=1=92=4.5\frac{\partial o}{\partial x_i}\bigr\rvert_{x_i=1} = \frac{9}{2} = 4.5∂xi∂oxi=1=29=4.5\frac{\partial o}{\partial x_i}\bigr\rvert_{x_i=1} = \frac{9}{2} = 4.5
你可以使用自动求导来做许多疯狂的事情。
x = torch.randn(3)
x = Variable(x, requires_grad = True)
y = x * 2
while y.data.norm() < 1000:y = y * 2
gradients = torch.FloatTensor([0.1, 1.0, 0.0001])
y.backward(gradients)
x.grad
阅读材料:
你可以在这读更多关于Variable 和 Function的文档: pytorch.org/docs/autograd.html
神经网络
使用 torch.nn 包可以进行神经网络的构建。
现在你对autograd有了初步的了解,而nn建立在autograd的基础上来进行模型的定义和微分。
nn.Module中包含着神经网络的层,同时forward(input)方法能够将output进行返回。
举个例子,来看一下这个数字图像分类的神经网络。
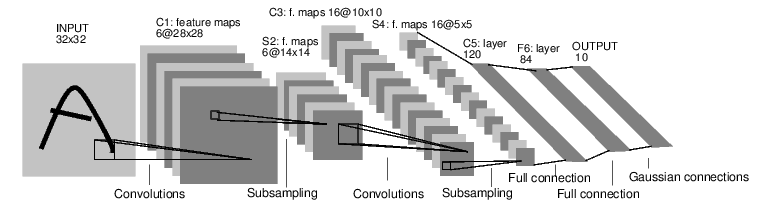
这是一个简单的前馈神经网络。 从前面获取到输入的结果,从一层传递到另一层,最后输出最后结果。
一个典型的神经网络的训练过程是这样的:
-
定义一个有着可学习的参数(或者权重)的神经网络
-
对着一个输入的数据集进行迭代:
-
用神经网络对输入进行处理
-
计算代价值 (对输出值的修正到底有多少)
-
将梯度传播回神经网络的参数中
-
更新网络中的权重
-
通常使用简单的更新规则: weight = weight + learning_rate * gradient
让我们来定义一个神经网络:
import torch.nn as nn
import torch.nn.functional as Fclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 6, 5) # 1 input image channel, 6 output channels, 5x5 square convolution kernelself.conv2 = nn.Conv2d(6, 16, 5)self.fc1 = nn.Linear(16*5*5, 120) # an affine operation: y = Wx + bself.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # Max pooling over a (2, 2) windowx = F.max_pool2d(F.relu(self.conv2(x)), 2) # If the size is a square you can only specify a single numberx = x.view(-1, self.num_flat_features(x))x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xdef num_flat_features(self, x):size = x.size()[1:] # all dimensions except the batch dimensionnum_features = 1for s in size:num_features *= sreturn num_featuresnet = Net()
net'''神经网络的输出结果是这样的
Net ((conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))(fc1): Linear (400 -> 120)(fc2): Linear (120 -> 84)(fc3): Linear (84 -> 10)
)
'''
仅仅需要定义一个forward函数就可以了,backward会自动地生成。
你可以在forward函数中使用所有的Tensor中的操作。
模型中可学习的参数会由net.parameters()返回。
params = list(net.parameters())
print(len(params))
print(params[0].size()) # conv1's .weightinput = Variable(torch.randn(1, 1, 32, 32))
out = net(input)
'''out 的输出结果如下
Variable containing:
-0.0158 -0.0682 -0.1239 -0.0136 -0.0645 0.0107 -0.0230 -0.0085 0.1172 -0.0393
[torch.FloatTensor of size 1x10]
'''net.zero_grad() # 对所有的参数的梯度缓冲区进行归零
out.backward(torch.randn(1, 10)) # 使用随机的梯度进行反向传播
注意: torch.nn 只接受小批量的数据
整个torch.nn包只接受那种小批量样本的数据,而非单个样本。 例如,nn.Conv2d能够结构一个四维的TensornSamples x nChannels x Height x Width。
如果你拿的是单个样本,使用input.unsqueeze(0)来加一个假维度就可以了。
复习一下前面我们学到的:
- torch.Tensor - 一个多维数组
- autograd.Variable - 改变Tensor并且记录下来操作的历史记录。和Tensor拥有相同的API,以及backward()的一些API。同时包含着和张量相关的梯度。
- nn.Module - 神经网络模块。便捷的数据封装,能够将运算移往GPU,还包括一些输入输出的东西。
- nn.Parameter - 一种变量,当将任何值赋予Module时自动注册为一个参数。
- autograd.Function - 实现了使用自动求导方法的前馈和后馈的定义。每个Variable的操作都会生成至少一个独立的Function节点,与生成了Variable的函数相连之后记录下操作历史。
到现在我们已经明白的部分:
- 定义了一个神经网络。
- 处理了输入以及实现了反馈。
仍然没整的:
- 计算代价。
- 更新网络中的权重。
一个代价函数接受(输出,目标)对儿的输入,并计算估计出输出与目标之间的差距。
nn package包中一些不同的代价函数.
一个简单的代价函数:nn.MSELoss计算输入和目标之间的均方误差。
举个例子:
output = net(input)
target = Variable(torch.range(1, 10)) # a dummy target, for example
criterion = nn.MSELoss()
loss = criterion(output, target)
'''loss的值如下
Variable containing:38.5849
[torch.FloatTensor of size 1]
'''
现在,如果你跟随loss从后往前看,使用.creator属性你可以看到这样的一个计算流程图:
input -> conv2d -> relu -> maxpool2d -> conv2d -> relu -> maxpool2d -> view -> linear -> relu -> linear -> relu -> linear -> MSELoss-> loss
因此当我们调用loss.backward()时整个图通过代价来进行区分,图中所有的变量都会以.grad来累积梯度。
# For illustration, let us follow a few steps backward
print(loss.creator) # MSELoss
print(loss.creator.previous_functions[0][0]) # Linear
print(loss.creator.previous_functions[0][0].previous_functions[0][0]) # ReLU'''
<torch.nn._functions.thnn.auto.MSELoss object at 0x7fe8102dd7c8>
<torch.nn._functions.linear.Linear object at 0x7fe8102dd708>
<torch.nn._functions.thnn.auto.Threshold object at 0x7fe8102dd648>
'''# 现在我们应当调用loss.backward(), 之后来看看 conv1's在进行反馈之后的偏置梯度如何
net.zero_grad() # 归零操作
print('conv1.bias.grad before backward')
print(net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)''' 这些步骤的输出结果如下
conv1.bias.grad before backward
Variable containing:000000
[torch.FloatTensor of size 6]conv1.bias.grad after backward
Variable containing:0.0346
-0.01410.0544
-0.1224
-0.16770.0908
[torch.FloatTensor of size 6]
'''
现在我们已经了解如何使用代价函数了。
阅读材料:
神经网络包中包含着诸多用于神经网络的模块和代价函数,带有文档的完整清单在这里:torch.nn - PyTorch 0.1.9 documentation
只剩下一个没学了:
- 更新网络的权重
最简单的更新的规则是随机梯度下降法(SGD):
weight = weight - learning_rate * gradient
我们可以用简单的python来表示:
learning_rate = 0.01
for f in net.parameters():f.data.sub_(f.grad.data * learning_rate)
然而在你使用神经网络的时候你想要使用不同种类的方法诸如:SGD, Nesterov-SGD, Adam, RMSProp, etc.
我们构建了一个小的包torch.optim来实现这个功能,其中包含着所有的这些方法。 用起来也非常简单:
import torch.optim as optim
# create your optimizer
optimizer = optim.SGD(net.parameters(), lr = 0.01)# in your training loop:
optimizer.zero_grad() # zero the gradient buffers
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # Does the update
就是这样。
但你现在也许会想。
那么数据怎么办呢?
通常来讲,当你处理图像,声音,文本,视频时需要使用python中其他独立的包来将他们转换为numpy中的数组,之后再转换为torch.*Tensor。
- 图像的话,可以用Pillow, OpenCV。
- 声音处理可以用scipy和librosa。
- 文本的处理使用原生Python或者Cython以及NLTK和SpaCy都可以。
特别的对于图像,我们有torchvision这个包可用,其中包含了一些现成的数据集如:Imagenet, CIFAR10, MNIST等等。同时还有一些转换图像用的工具。 这非常的方便并且避免了写样板代码。
本教程使用CIFAR10数据集。 我们要进行的分类的类别有:‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’。 这个数据集中的图像都是3通道,32x32像素的图片。

下面是对torch神经网络使用的一个实战练习。
训练一个图片分类器
我们要按顺序做这几个步骤:
- 使用torchvision来读取并预处理CIFAR10数据集
- 定义一个卷积神经网络
- 定义一个代价函数
- 在神经网络中训练训练集数据
- 使用测试集数据测试神经网络
1. 读取并预处理CIFAR10
使用torchvision读取CIFAR10相当的方便。
import torchvision
import torchvision.transforms as transforms# torchvision数据集的输出是在[0, 1]范围内的PILImage图片。
# 我们此处使用归一化的方法将其转化为Tensor,数据范围为[-1, 1]transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4, shuffle=True, num_workers=2)testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4, shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat','deer', 'dog', 'frog', 'horse', 'ship', 'truck')
'''注:这一部分需要下载部分数据集 因此速度可能会有一些慢 同时你会看到这样的输出Downloading http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data/cifar-10-python.tar.gz
Extracting tar file
Done!
Files already downloaded and verified
'''
我们来从中找几张图片看看。
# functions to show an image
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
def imshow(img):img = img / 2 + 0.5 # unnormalizenpimg = img.numpy()plt.imshow(np.transpose(npimg, (1,2,0)))# show some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()# print images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s'%classes[labels[j]] for j in range(4)))
结果是这样的:

2. 定义一个卷积神经网络
class Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5)self.pool = nn.MaxPool2d(2,2)self.conv2 = nn.Conv2d(6, 16, 5)self.fc1 = nn.Linear(16*5*5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = x.view(-1, 16*5*5)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xnet = Net()
3. 定义代价函数和优化器
criterion = nn.CrossEntropyLoss() # use a Classification Cross-Entropy loss
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
4. 训练网络
事情变得有趣起来了。 我们只需一轮一轮迭代然后不断通过输入来进行参数调整就行了。
for epoch in range(2): # loop over the dataset multiple timesrunning_loss = 0.0for i, data in enumerate(trainloader, 0):# get the inputsinputs, labels = data# wrap them in Variableinputs, labels = Variable(inputs), Variable(labels)# zero the parameter gradientsoptimizer.zero_grad()# forward + backward + optimizeoutputs = net(inputs)loss = criterion(outputs, labels)loss.backward() optimizer.step()# print statisticsrunning_loss += loss.data[0]if i % 2000 == 1999: # print every 2000 mini-batchesprint('[%d, %5d] loss: %.3f' % (epoch+1, i+1, running_loss / 2000))running_loss = 0.0
print('Finished Training')
'''这部分的输出结果为
[1, 2000] loss: 2.212
[1, 4000] loss: 1.892
[1, 6000] loss: 1.681
[1, 8000] loss: 1.590
[1, 10000] loss: 1.515
[1, 12000] loss: 1.475
[2, 2000] loss: 1.409
[2, 4000] loss: 1.394
[2, 6000] loss: 1.376
[2, 8000] loss: 1.334
[2, 10000] loss: 1.313
[2, 12000] loss: 1.264
Finished Training
'''
我们已经训练了两遍了。 此时需要测试一下到底结果如何。
通过对比神经网络给出的分类和已知的类别结果,可以得出正确与否,如果预测的正确,我们可以将样本加入正确预测的结果的列表中。
好的第一步,让我们展示几张照片来熟悉一下。
dataiter = iter(testloader)
images, labels = dataiter.next()# print images
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s'%classes[labels[j]] for j in range(4)))
结果是这样的:

好的,接下来看看神经网络如何看待这几个照片。
outputs = net(Variable(images))# the outputs are energies for the 10 classes.
# Higher the energy for a class, the more the network
# thinks that the image is of the particular class# So, let's get the index of the highest energy
_, predicted = torch.max(outputs.data, 1)print('Predicted: ', ' '.join('%5s'% classes[predicted[j][0]] for j in range(4)))'''输出结果为
Predicted: cat plane car plane
'''
结果看起来挺好。
看看神经网络在整个数据集上的表现结果如何。
correct = 0
total = 0
for data in testloader:images, labels = dataoutputs = net(Variable(images))_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum()print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))'''输出结果为
Accuracy of the network on the 10000 test images: 54 %
'''
看上去这玩意输出的结果比随机整的要好,随机选择的话从十个中选择一个出来,准确率大概只有10%。
看上去神经网络学到了点东西。
嗯。。。那么到底哪些类别表现良好又是哪些类别不太行呢?
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
for data in testloader:images, labels = dataoutputs = net(Variable(images))_, predicted = torch.max(outputs.data, 1)c = (predicted == labels).squeeze()for i in range(4):label = labels[i]class_correct[label] += c[i]class_total[label] += 1for i in range(10):print('Accuracy of %5s : %2d %%' % (classes[i], 100 * class_correct[i] / class_total[i]))'''输出结果为
Accuracy of plane : 73 %
Accuracy of car : 70 %
Accuracy of bird : 52 %
Accuracy of cat : 27 %
Accuracy of deer : 34 %
Accuracy of dog : 37 %
Accuracy of frog : 62 %
Accuracy of horse : 72 %
Accuracy of ship : 64 %
Accuracy of truck : 53 %
'''
好吧,接下来该怎么搞了?
我们该如何将神经网络运行在GPU上呢?
在GPU上进行训练
就像你把Tensor传递给GPU进行运算一样,你也可以将神经网络传递给GPU。
这一过程将逐级进行操作,直到所有组件全部都传递到GPU上。
net.cuda()'''输出结果为
Net ((conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))(pool): MaxPool2d (size=(2, 2), stride=(2, 2), dilation=(1, 1))(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))(fc1): Linear (400 -> 120)(fc2): Linear (120 -> 84)(fc3): Linear (84 -> 10)
)
'''
记住,每一步都需要把输入和目标传给GPU。
inputs, labels = Variable(inputs.cuda()), Variable(labels.cuda())
我为什么没有进行CPU运算和GPU运算的对比呢?因为神经网络实在太小了,其中的差距并不明显。
目标达成:
- 在更高层级上理解PyTorch的Tensor库和神经网络。
- 训练一个小的神经网络。
pytorch官方教程(详细版)
(一)Datasets & DataLoaders
处理数据样本的代码可能会变得凌乱,难以维护;理想情况下,我们希望数据集代码与模型训练代码分离,以获得更好的可读性和模块性。PyTorch提供了两种数据原语:torch.utils.data.DataLoader和torch.utils.data.Dataset,允许你使用预加载的数据集以及自己的数据。Dataset 存储样本及其相应的标签,DataLoader将Dataset封装成一个迭代器以便轻松访问样本。PyTorch域库提供了许多预加载的数据集(比如FashionMNIST),属于torch.utils.data.Dataset的子类,并实现指定于特定数据的功能。它们可以用于原型和基准测试你的模型。
加载数据集
这是一个从TorchVision中加载Fashion-MNIST数据集的例子,Fashion MNIST是Zalando文章图片的数据集,包含60000个训练示例和10000个测试示例。每个示例包括一个28×28的灰度图像和一个来自10个类别之一的相关标签。加载FashionMNIST需要以下参数
root:训练/测试数据存储路径train:指定训练或测试数据集download=True:如果在“根目录”中不可用,则从internet下载数据transform和target_transform指定特征和标签变换
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plttrain_data = datasets.FashionMNIST(root='data',train=True,download=True,transform=ToTensor())test_data = datasets.FashionMNIST(root='data',train=False,download=True,transform=ToTensor())
迭代和可视化数据集
我们可以像列表一样手动索引Datasets:train_data[index]。使用matplotlib可视化一些训练数据样本
labels_map = {0: "T-Shirt",1: "Trouser",2: "Pullover",3: "Dress",4: "Coat",5: "Sandal",6: "Shirt",7: "Sneaker",8: "Bag",9: "Ankle Boot",}
figure = plt.figure(figsize=(8,8))
cols,rows = 3,3
for i in range(1,cols * rows + 1):sample_index = torch.randint(len(train_data),size=(1,)).item() # 获取随机索引img,label = train_data[sample_index] # 找到随机索引下的图像和标签figure.add_subplot(rows,cols,i) # 增加子图,add_subplot面向对象,subplot面向函数plt.title(labels_map[label])plt.axis("off") # 关闭坐标轴plt.imshow(img.squeeze(),cmap='gray') # 对图像进行处理,cmap颜色图谱
plt.show() # 显示图像

创建自定义数据集文件
自定义数据集类必须包含三个函数:__init__, __len__,和 __getitem__。比如图像存储在img_dir目录里,标签分开存储在一个CSV 文件annotations_file
import os
import pandas as pd
from torchvision.io import read_imageclass CustomImageDataset(Dataset):def __init__(self,annotations_file,img_dir,transform = None,target_transform = None):self.img_labels = pd.read_csv(annotations_file)self.img_dir = img_dirself.transform = transformself.traget_transform = target_transformdef __len__(self):return len(self.img_labels)def __getitem__(self, idx):# iloc[:,:]切片,左闭右开,iloc[idx,0]取idx行0列元素# os.path.join路径连接img_path = os.path.join(self.img_dir,self.img_labels.iloc[idx,0])image = read_image(img_path)label = self.img_labels.iloc[idx,1]if self.transform:image = self.transform(image)if self.traget_transform:label = self.traget_transform(label)return image,label
init
__init__函数在实例化Dataset对象时运行一次。我们初始化包含图像、注释文件和两种转换的目录。labels.csv文件内容如下:
tshirt1.jpg, 0
tshirt2.jpg, 0
......
ankleboot999.jpg, 9
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):self.img_labels = pd.read_csv(annotations_file)self.img_dir = img_dirself.transform = transformself.target_transform = target_transform
len
__len__函数返回数据集中的样本数
def __len__(self):return len(self.img_labels)
getitem
__getitem__函数加载和返回数据集中给定索引idx位置的一个样本。基于索引,它识别图像在磁盘上的位置,使用read_image将其转换为张量,从self.img_labelscsv数据中检索相应的标签。调用其上的变换函数(如果适用),并以元组形式返回张量图像和相应标签。
def __getitem__(self, idx):img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])image = read_image(img_path)label = self.img_labels.iloc[idx, 1]if self.transform:image = self.transform(image)if self.target_transform:label = self.target_transform(label)return image, label
使用DataLoaders预备训练数据
Dataset一次检索一个样本的数据集特征和标签,在训练模型时,我们通常希望以“小minibatches”的方式传递样本,在每个epoch重新排列数据以减少模型过度拟合,并使用Python的multiprocessing加速数据检索。DataLoader 是一个迭代器能实现上面功能
from torch.utils.data import DataLoader
# shuffle如果设置为True,则会在每个epoch重新排列数据
train_dataloader = DataLoader(train_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
通过DataLoader进行迭代
已经将数据加载到DataLoader,能够迭代遍历数据集,每次迭代都会返回批量(batch_size=64)的train_features和train_labels,设置了shuffle=True,在我们迭代所有batches之后,数据被洗牌(以便对数据加载顺序进行更细粒度的控制)
train_features,train_labels = next(iter(train_dataloader))
print(f'feature batch shape:{train_features.size()}')
print(f'label batch shape:{train_labels.size()}')
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img,cmap='gray')
plt.show()
print(f'label:{label}')
feature batch shape:torch.Size([64, 1, 28, 28])
label batch shape:torch.Size([64])

label:4
(二)Transforms
数据并不总是以训练机器学习算法所需的最终处理形式出现。我们使用transforms对数据进行一些操作,使其适合训练。所有的TorchVision数据集都有两个参数transform(修正特征),target_transform(修正标签),torchvision.transforms模块提供了几种常用的转换。
FashionMNIST特征是PIL图像形式, 标签是整数。为了训练,需要把特征作为归一化张量,标签作为一个one-hot编码张量。使用ToTensor 和Lambda实现
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambdads = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor(),target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1))
)
ToTensor( )
ToTensor将一个PIL image或者NumPy 数组ndarray变成浮点型张量FloatTensor,在[0,1]范围内缩放图像的像素强度值
Lambda Transforms
Lambda transforms应用任何用户定义的Lambda函数,此处定义了一个函数将整数变成one-hot编码张量,首先创建一个大小为10(标签数)的全0张量,然后调用scatter_ 在标签y的索引位置上将值修改为1
target_transform = Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(dim=0, index=torch.tensor(y), value=1))
Tensor.scatter_(dim, index, src, reduce=None)在dim维度上,找到index对应的元素,将值换成src
print(torch.zeros(10, dtype=torch.float).scatter_(dim=0, index=torch.tensor(3), value=1))
tensor([0., 0., 0., 1., 0., 0., 0., 0., 0., 0.])
(三)构建神经网络
使用pytorch构建神经网络进行FashionMNIST数据集中的图像分类
import os
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('using {} device'.format(device))
using cpu device
定义神经网络类
继承nn.Module构建神经网络,包括两个部分
__init__:定义网络层forward:执行前向传播
class network(nn.Module):def __init__(self):super(network, self).__init__()self.flatten = nn.Flatten() # 将连续范围的维度拉平成张量self.layers = nn.Sequential(nn.Linear(28*28,512),nn.ReLU(),nn.Linear(512,512),nn.ReLU(),nn.Linear(512,10))def forward(self,x):x = self.flatten(x) # 输入到网络中的是(batch_size,input)values = self.layers(x)return values
torch.nn.Flatten(start_dim=1, end_dim=- 1)默认只保留第一维度
-
start_dim:first dim to flatten (default = 1).
-
end_dim:last dim to flatten (default = -1).
# torch.nn.Flatten示例
input = torch.randn(32,1,5,5)
m = nn.Flatten()
output = m(input)
print(output.size())
m1 = nn.Flatten(0,2)
print(m1(input).size())
torch.Size([32, 25])
torch.Size([160, 5])
创建一个network实例并移动到 device,输出结构
model = network().to(device)
print(model)
network((flatten): Flatten(start_dim=1, end_dim=-1)(layers): Sequential((0): Linear(in_features=784, out_features=512, bias=True)(1): ReLU()(2): Linear(in_features=512, out_features=512, bias=True)(3): ReLU()(4): Linear(in_features=512, out_features=10, bias=True))
)
遍历输入数据,执行模型前向传播,不用直接调用forward
x = torch.rand(2,28,28,device=device)
value = model(x)
print(value)
print(value.size())
pred_probab = nn.Softmax(dim=1)(value)
print(pred_probab)
y_pred = pred_probab.argmax(1)
print(f'predicted class:{y_pred}')
tensor([[-0.0355, 0.0948, -0.1048, 0.0802, 0.0177, 0.0038, -0.0281, -0.0767,0.0303, -0.1290],[-0.0238, 0.1298, -0.0700, 0.0861, 0.0168, -0.0418, -0.0421, -0.0772,0.0369, -0.1391]], grad_fn=<AddmmBackward0>)
torch.Size([2, 10])
tensor([[0.0977, 0.1113, 0.0912, 0.1097, 0.1030, 0.1016, 0.0984, 0.0938, 0.1043,0.0890],[0.0986, 0.1149, 0.0941, 0.1100, 0.1027, 0.0968, 0.0968, 0.0935, 0.1048,0.0878]], grad_fn=<SoftmaxBackward0>)
predicted class:tensor([1, 1])
torch.nn.Softmax(dim=None)softmax归一化
# torch.nn.Softmax示例
m = nn.Softmax(dim=1)
input = torch.randn(2,3)
print(input)
output = m(input)
print(output)
tensor([[-0.5471, 1.3495, 1.5911],[-0.0185, -0.1420, -0.0556]])
tensor([[0.0619, 0.4126, 0.5254],[0.3512, 0.3104, 0.3384]])
模型结构层
拆解模型中的层次,观察输入和输出
原始输入
input_image = torch.rand(3,28,28)
print(input_image.size())
torch.Size([3, 28, 28])
nn.Flatten
将2维的28✖️28图像变成784像素值,batch维度(dim=0)保留
flatten = nn.Flatten()
flat_image = flatten(input_image)
print(flat_image.size())
torch.Size([3, 784])
nn.Linear
线性转换
layer1 = nn.Linear(in_features=28*28,out_features=20)
hidden1 = layer1(flat_image)
print(hidden1.size( ))
torch.Size([3, 20])
nn.ReLU
非线性修正单元(激活函数)
print(f"Before ReLU: {hidden1}\n\n")
hidden1 = nn.ReLU()(hidden1)
print(f"After ReLU: {hidden1}")
print(hidden1.size())
Before ReLU: tensor([[ 0.4574, -0.5313, -0.4628, -0.9403, -0.7630, 0.1807, -0.2847, -0.2741,0.0954, 0.2327, 0.4603, 0.0227, -0.1299, -0.2346, -0.1800, 0.9115,-0.0870, -0.0171, -0.0064, 0.0540],[ 0.0888, -0.6782, -0.2557, -0.6717, -0.4488, 0.1024, -0.3013, -0.3186,-0.1338, 0.3944, 0.0704, 0.1429, 0.0521, -0.3326, -0.3113, 0.6518,-0.0978, -0.0721, -0.3396, 0.4712],[ 0.1781, 0.0885, -0.4775, -0.5661, -0.0099, 0.2617, -0.2678, -0.1444,0.1345, 0.3259, 0.3984, 0.2392, 0.0529, -0.0349, -0.3266, 0.7488,-0.3498, 0.1157, 0.0126, 0.3502]], grad_fn=<AddmmBackward0>)After ReLU: tensor([[0.4574, 0.0000, 0.0000, 0.0000, 0.0000, 0.1807, 0.0000, 0.0000, 0.0954,0.2327, 0.4603, 0.0227, 0.0000, 0.0000, 0.0000, 0.9115, 0.0000, 0.0000,0.0000, 0.0540],[0.0888, 0.0000, 0.0000, 0.0000, 0.0000, 0.1024, 0.0000, 0.0000, 0.0000,0.3944, 0.0704, 0.1429, 0.0521, 0.0000, 0.0000, 0.6518, 0.0000, 0.0000,0.0000, 0.4712],[0.1781, 0.0885, 0.0000, 0.0000, 0.0000, 0.2617, 0.0000, 0.0000, 0.1345,0.3259, 0.3984, 0.2392, 0.0529, 0.0000, 0.0000, 0.7488, 0.0000, 0.1157,0.0126, 0.3502]], grad_fn=<ReluBackward0>)
torch.Size([3, 20])
nn.Sequential
nn.Sequential 是一个模块的有序容纳器,数据按照定义的顺序传递给所有模块
seq_modules = nn.Sequential(flatten,layer1,nn.ReLU(),nn.Linear(20,10))
input_image = torch.randn(3,28,28)
values1 = seq_modules(input_image)
print(values1)
tensor([[ 0.2472, 0.2597, -0.0157, 0.3206, -0.0073, 0.1631, 0.2956, 0.0561,0.2993, 0.1807],[-0.0782, 0.1838, -0.0215, 0.2395, -0.0804, -0.0021, 0.0883, -0.0698,0.1463, -0.0151],[-0.1162, 0.0673, -0.2301, 0.1612, -0.1472, -0.0447, 0.0671, -0.2915,0.3176, 0.2391]], grad_fn=<AddmmBackward0>)
nn.Softmax
神经网络的最后一个线性层返回原始值在[-\infty, \infty],经过nn.Softmax模块,输出值在[0, 1],代表了每个类别的预测概率,dim参数表示改维度的值总和为1
softmax = nn.Softmax(dim=1)
pred_probab1 = softmax(values1)
print(pred_probab1)
tensor([[0.1062, 0.1075, 0.0816, 0.1143, 0.0823, 0.0976, 0.1115, 0.0877, 0.1119,0.0994],[0.0884, 0.1148, 0.0935, 0.1214, 0.0882, 0.0954, 0.1044, 0.0891, 0.1106,0.0941],[0.0872, 0.1048, 0.0778, 0.1151, 0.0845, 0.0937, 0.1048, 0.0732, 0.1346,0.1244]], grad_fn=<SoftmaxBackward0>)
模型参数
使用parameters()和named_parameters()能获取每层的参数,包括weight和bias
print(f'model structure:{model}\n')for name,param in model.named_parameters():print(f'layer:{name}|size"{param.size()}|param:{param[:2]}\n')#print(model.parameters())
model structure:network((flatten): Flatten(start_dim=1, end_dim=-1)(layers): Sequential((0): Linear(in_features=784, out_features=512, bias=True)(1): ReLU()(2): Linear(in_features=512, out_features=512, bias=True)(3): ReLU()(4): Linear(in_features=512, out_features=10, bias=True))
)layer:layers.0.weight|size"torch.Size([512, 784])|param:tensor([[ 0.0122, -0.0204, -0.0185, ..., -0.0196, 0.0257, -0.0084],[-0.0066, -0.0195, -0.0199, ..., -0.0175, -0.0007, 0.0003]],grad_fn=<SliceBackward0>)layer:layers.0.bias|size"torch.Size([512])|param:tensor([0.0086, 0.0104], grad_fn=<SliceBackward0>)layer:layers.2.weight|size"torch.Size([512, 512])|param:tensor([[-0.0306, -0.0408, 0.0062, ..., 0.0289, -0.0164, 0.0099],[ 0.0015, 0.0052, 0.0182, ..., 0.0431, -0.0174, 0.0049]],grad_fn=<SliceBackward0>)layer:layers.2.bias|size"torch.Size([512])|param:tensor([-0.0337, 0.0294], grad_fn=<SliceBackward0>)layer:layers.4.weight|size"torch.Size([10, 512])|param:tensor([[ 0.0413, 0.0015, 0.0388, ..., 0.0347, 0.0160, 0.0221],[-0.0010, 0.0031, 0.0421, ..., -0.0226, 0.0340, -0.0220]],grad_fn=<SliceBackward0>)layer:layers.4.bias|size"torch.Size([10])|param:tensor([0.0210, 0.0243], grad_fn=<SliceBackward0>)
(四)自动差分 torch.autograd
训练神经网络使用最频繁的算法是反向传播back propagation,参数(model weights)根据损失函数的梯度gradient进行调整。为了计算梯度,pytorch内置了
差分引擎torch.autograd,支持任何一个计算图的梯度计算,以最简单的单层神经网络为例,输入x,参数w和b和一些损失函数,
import torchx = torch.ones(5) # 输入张量
y = torch.zeros(3) # 预期输出
w = torch.randn(5, 3, requires_grad=True)
b = torch.randn(3, requires_grad=True)
z = torch.matmul(x, w)+b
loss = torch.nn.functional.binary_cross_entropy_with_logits(z, y)
print(loss)
tensor(2.2890, grad_fn=<BinaryCrossEntropyWithLogitsBackward0>)
张量,函数,计算图
代码定义了如下的计算图 computational graph:
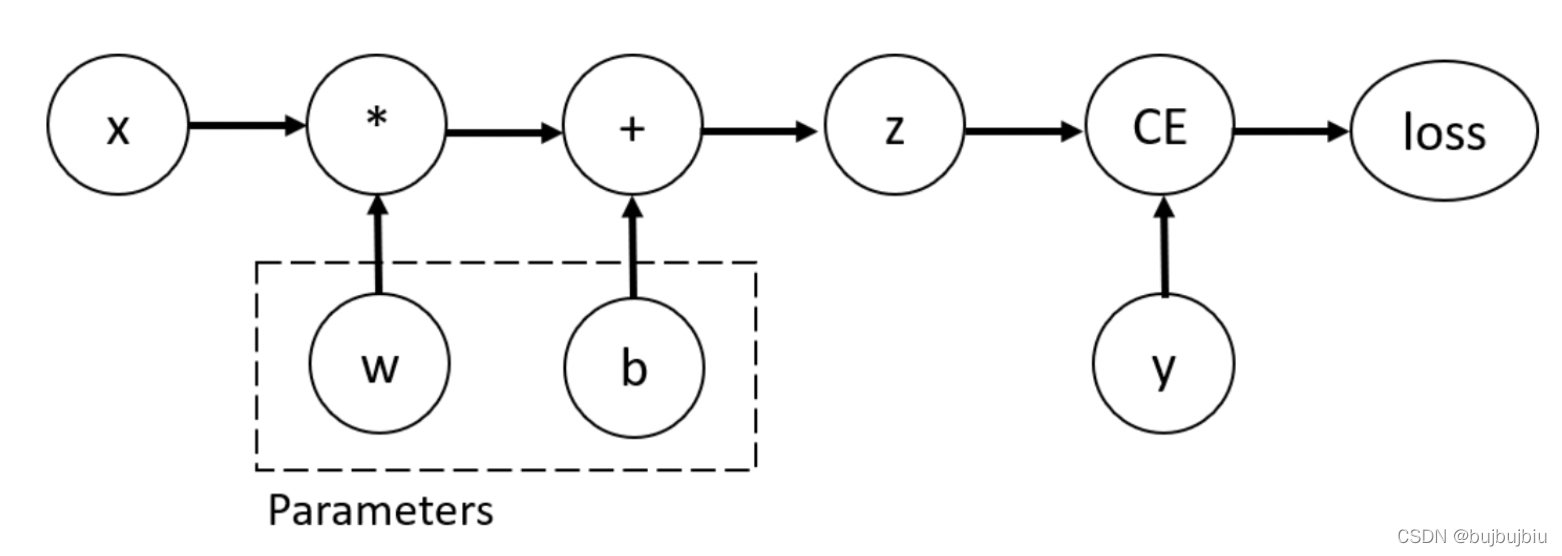
w 和 b 是需要优化的参数,因此需要计算这些变量各自对损失函数的梯度,设置张量的requires_grad属性
可以在创建一个张量的时候设置requires_grad的值,或者之后使用x.requires_grad_(True)方法,用在张量上实现前向传播和反向传播的函数是类Function的实例,反向传播函数存储在张量的grad_fn属性上
print(f'gradient function for z={z.grad_fn}\n')
print(f'gradient function for loss={loss.grad_fn}\n')
gradient function for z=<AddBackward0 object at 0x7fb47069aa30>gradient function for loss=<BinaryCrossEntropyWithLogitsBackward0 object at 0x7fb47069a250>
计算梯度
为了优化网络参数的权重,需要计算x 和 y固定值下损失函数对各参数的导数 ∂ l o s s ∂ w \frac{\partial loss}{\partial w} ∂w∂loss和 ∂ l o s s ∂ b \frac{\partial loss}{\partial b} ∂b∂loss ,为了计算这些导数,需要调用loss.backward(),通过w.grad和b.grad获取梯度值
loss.backward()
print(w.grad)
print(b.grad)
tensor([[0.3263, 0.0754, 0.3122],[0.3263, 0.0754, 0.3122],[0.3263, 0.0754, 0.3122],[0.3263, 0.0754, 0.3122],[0.3263, 0.0754, 0.3122]])
tensor([0.3263, 0.0754, 0.3122])
只能获取计算图叶子节点的grad属性,其requires_grad设置为true,对于其它节点,梯度不可获取;出于性能原因,只能在给定的图形上使用“backward”进行一次梯度计算。如果要在同一个图上执行好几次“backward”调用,将“retain_graph=True”传递给“backward”调用
禁用梯度跟踪
设置requires_grad=True的张量会追踪计算历史并且支持梯度计算,但是某些情况下,不需要这么做,比如模型已经完成训练后,将其应用在输入数据上,只需执行前向传播_forward_,可以通过torch.no_grad()阻止跟踪计算
z = torch.matmul(x,w) + b
print(z.requires_grad)with torch.no_grad():z = torch.matmul(x,w) + b
print(z.requires_grad)
True
False
另一种有同样效果的方法是对张量使用detach()
z = torch.matmul(x, w)+b
z_det = z.detach()
print(z_det.requires_grad)
False
禁用梯度跟踪有以下原因:
- 将神经网络中的一些参数标记为frozen parameters,在微调预训练网络中比较常见
- 只进行前向传播中加速计算speed up computations,没有梯度跟踪的向量计算更高效
计算图Computational Graphs
从概念上讲,autograd在由函数对象组成的有向无环图(DAG)中记录数据(张量)和所有执行的操作(以及生成的新张量)。在这个DAG中,叶是输入张量,根是输出张量。通过从根到叶追踪此图,可以使用链式规则自动计算梯度
在前向传播中,autograd自动做两件事:
- 运行请求的操作以计算结果张量
- 在DAG中保留操作的梯度函数_gradient function_
DAG根的.backward()被调用时,autograd :
- 依照每个
.grad_fn计算梯度 - 将其累计到各自张量的
.grad属性中 - 使用链式规则传播到叶张量
DAGs are dynamic in PyTorch,图表是从头开始创建的,在调用.backward()后,autograd开始填充新图形,这也是模型中能使用控制流语句的原因,在每次迭代,都可以改变形状,大小和操作
(五)优化模型参数
有了模型和数据后需要通过优化参数进行模型训练,验证和测试。训练模型是一个迭代的过程,每次迭代(也叫一个_epoch_),模型会对输出进行预测,计算预测误差(loss),收集误差对各参数的导数。使用梯度下降优化这些参数。
之前数据加载和神经网络代码:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambdatrain_data = datasets.FashionMNIST(root="data",train=True,download=True,transform=ToTensor()
)test_data = datasets.FashionMNIST(root="data",train=False,download=True,transform=ToTensor()
)train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)class NeuralNetwork(nn.Module):def __init__(self):super(NeuralNetwork, self).__init__()self.flatten = nn.Flatten()self.layers = nn.Sequential(nn.Linear(28*28, 512),nn.ReLU(),nn.Linear(512, 512),nn.ReLU(),nn.Linear(512, 10),)def forward(self, x):x = self.flatten(x)values = self.layers(x)return valuesmodel = NeuralNetwork()
超参数Hyperparameters
超参数是可调整的参数,用来控制模型优化过程,不同的超参数值能影响模型训练和收敛速度
定义如下的超参数用于训练:
- Number of Epochs:迭代次数
- Batch Size:参数更新前通过网络传播的数据样本数量
- Learning Rate:学习率
learning_rate = 1e-3
batch_size = 64
epochs = 5
优化循环Optimization Loop
一旦设定了超参数,可以通过一个优化循环来训练和优化我们的模型。优化循环的每次迭代称为epoch。每个epoch包括两个主要的部分:
- The Train Loop:迭代训练数据集,并尝试收敛到最佳参数。
- The Validation/Test Loop:迭代测试数据集,检查模型性能是否正在改善。
loss function
当面对一些训练数据时,我们未经训练的网络可能不会给出正确的答案。损失函数衡量获得的结果与目标值的不同程度,我们希望在训练过程中最小化损失函数。为了计算损失,我们使用给定数据样本的输入进行预测,并将其与真实数据标签值进行比较。
普通的损失函数包括适合回归任务的nn.MSELoss(均方误差),适合分类的nn.NLLLoss(负对数似然),nn.CrossEntropyLoss结合了nn.LogSoftmax和nn.NLLLoss。此处使用nn.CrossEntropyLoss
# 初始化损失函数
loss_fn = nn.CrossEntropyLoss()
Optimizer
优化是在每个训练步骤中调整模型参数以减少模型误差的过程。优化算法定义了该过程的执行方式(在本例中使用随机梯度下降)。所有优化逻辑都封装在优化器对象中。这里使用SGD优化器;此外,pytorch中有许多不同的优化器,例如ADAM和RMSProp,它们可以更好地用于不同类型的模型和数据。
# 定义优化器
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
训练循环中,优化主要有三个步骤:
- 调用
optimizer.zero_grad()重置模型参数的梯度,梯度默认会累积,为了阻止重复计算,在每次迭代都会清零 - 调用
loss.backward()进行反向传播 - 一旦有了梯度,就调用
optimizer.step()来调整各参数值
训练循环和测试循环
定义train_loop训练优化,定义test_loop评估模型在测试集的表现
def train_loop(dataloader, model, loss_fn, optimizer):size = len(dataloader.dataset) # 训练集数据总量for number, (x, y) in enumerate(dataloader):# number迭代次数,每次迭代输入batch=64的张量(64,1,28,28)# 计算预测和误差pred = model(x)loss = loss_fn(pred, y)# 反向传播optimizer.zero_grad()loss.backward()optimizer.step()if number % 100 == 0:# 每迭代100次,输出当前损失函数值及遍历进度loss, current = loss.item(), number * len(x) # current当前已经遍历的图像数,len(x)=batch_sizeprint(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")def test_loop(dataloader, model, loss_fn):size = len(dataloader.dataset) # 测试集总量num_batches = len(dataloader) # 最大迭代次数test_loss, correct = 0, 0with torch.no_grad():for x, y in dataloader:pred = model(x)test_loss += loss_fn(pred, y).item()# 输出如:test_loss=torch.tensor(1.0873)# pred.argmax(1)返回值最大值对应的位置,sum()求批量的正确数correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batches # 单次迭代的误差总和/总迭代次数=平均误差correct /= size # 单次迭代的正确数总和/数据总量=准确率print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
print(len(train_dataloader.dataset))
print(len(train_dataloader))
print(len(test_dataloader.dataset))
print(len(test_dataloader))
x,y = next(iter(train_dataloader))
print(len(x))
print(x.size())
print(y.size())
60000
938
10000
157
64
torch.Size([64, 1, 28, 28])
torch.Size([64])
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)epochs = 2
for t in range(epochs):print(f"Epoch {t+1}\n-------------------------------")train_loop(train_dataloader, model, loss_fn, optimizer)test_loop(test_dataloader, model, loss_fn)
print("Done!")
Epoch 1
-------------------------------
loss: 1.040251 [ 0/60000]
loss: 1.070957 [ 6400/60000]
loss: 0.869483 [12800/60000]
loss: 1.033000 [19200/60000]
loss: 0.908716 [25600/60000]
loss: 0.930925 [32000/60000]
loss: 0.973219 [38400/60000]
loss: 0.913604 [44800/60000]
loss: 0.960071 [51200/60000]
loss: 0.904625 [57600/60000]
Test Error: Accuracy: 67.1%, Avg loss: 0.911718 Epoch 2
-------------------------------
loss: 0.952776 [ 0/60000]
loss: 1.005409 [ 6400/60000]
loss: 0.788150 [12800/60000]
loss: 0.969153 [19200/60000]
loss: 0.852390 [25600/60000]
loss: 0.862806 [32000/60000]
loss: 0.920238 [38400/60000]
loss: 0.863878 [44800/60000]
loss: 0.903000 [51200/60000]
loss: 0.858517 [57600/60000]
Test Error: Accuracy: 68.3%, Avg loss: 0.859433 Done!
(六)保存和加载模型
最后了解如何通过保存、加载和运行模型预测来保持模型状态。torchvision.models子包包含用于处理不同任务的模型定义,包括:图像分类、像素语义分割、对象检测、实例分割、人物关键点检测、视频分类和光流。
import torch
import torchvision.models as models
保存和加载模型权重
pytorch将学习的参数存储在内部状态字典中,叫做state_dict,这些能通过torch.save方法被保留
# vgg16是一种图像分类的模型结构
import ssl
ssl._create_default_https_context = ssl._create_unverified_contextmodel = models.vgg16(pretrained=True) # 以vgg16模型为例
torch.save(model.state_dict(), 'model_weights.pth')
要加载模型权重,需要先创建同一模型的实例,然后使用load_state_dict()方法加载参数
model = models.vgg16() # 不指定 pretrained=True,也就是不加载默认参数
model.load_state_dict(torch.load('model_weights.pth'))
model.eval()
VGG((features): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU(inplace=True)(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU(inplace=True)(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(6): ReLU(inplace=True)(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(8): ReLU(inplace=True)(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True)(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(13): ReLU(inplace=True)(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(15): ReLU(inplace=True)(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(18): ReLU(inplace=True)(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(20): ReLU(inplace=True)(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(22): ReLU(inplace=True)(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(25): ReLU(inplace=True)(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(27): ReLU(inplace=True)(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(29): ReLU(inplace=True)(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU(inplace=True)(2): Dropout(p=0.5, inplace=False)(3): Linear(in_features=4096, out_features=4096, bias=True)(4): ReLU(inplace=True)(5): Dropout(p=0.5, inplace=False)(6): Linear(in_features=4096, out_features=1000, bias=True))
)
在预测前一定要先调用model.eval()方法来设置dropout和batch normalization层为评估模型,否则会导致不一致的预测结果
保存和加载模型
加载模型权重时,我们需要首先实例化模型类,因为该类定义了网络的结构。为了将这个类的结构与模型一起保存,可以将model(而不是model.state_dict())传递给保存的函数:
torch.save(model, 'model.pth')
加载模型:
model = torch.load('model.pth')
这种方法在序列化模型时使用Python的pickle模块,因此它依赖于加载模型时可用的实际类定义。
相关文章:
PyTorch深度学习:60分钟入门
PyTorch深度学习:60分钟入门 本教程的目的: 更高层级地理解PyTorch的Tensor库以及神经网络。训练一个小的神经网络来对图像进行分类。 本教程以您拥有一定的numpy基础的前提下展开 Note: 务必确认您已经安装了 torch 和 torchvision 两个包。 这是一个基于Pytho…...

C语言指针常见问题汇总
我们在学C语言时,指针是我们最头疼的问题之一,针对C语言指针,博主根据自己的实际学到的知识以及开发经验,总结了以下使用C语言指针时常见问题。 1、指针做函数参数 学习函数的时候,讲了函数的参数都是值拷贝…...
Coremail邮件系统全新上线存档邮箱功能
邮箱积累邮件太多,搜索起来又慢又麻烦! 我的重要邮件忘记下载丢失了!14天自动删除太难了! 有没有可能重要邮件自动存档,解救一下“遗忘星”人? 在我们日常工作中,邮件是最经常使用的办公工具之一…...
Python绘图
1.二维绘图 a. 一维数据集 用 Numpy ndarray 作为数据传入 ply 1. import numpy as np import matplotlib as mpl import matplotlib.pyplot as pltnp.random.seed(1000) y np.random.standard_normal(10) print "y %s"% y x range(len(y)) print "x%s&q…...
)
【独家】华为OD机试 - 第K个最小码值的字母(C 语言解题)
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析经验分享,题型分享,防作弊指南)华为od机试,独家整理 已参加机试…...
)
整数反转(python)
题目链接: https://leetcode.cn/problems/reverse-integer/ 题目描述: 给你一个 32 位的有符号整数 x ,返回将 x 中的数字部分反转后的结果。 如果反转后整数超过 32 位的有符号整数的范围 [−231,231−1][−2^{31}, 2^{31} − 1][−231,231…...
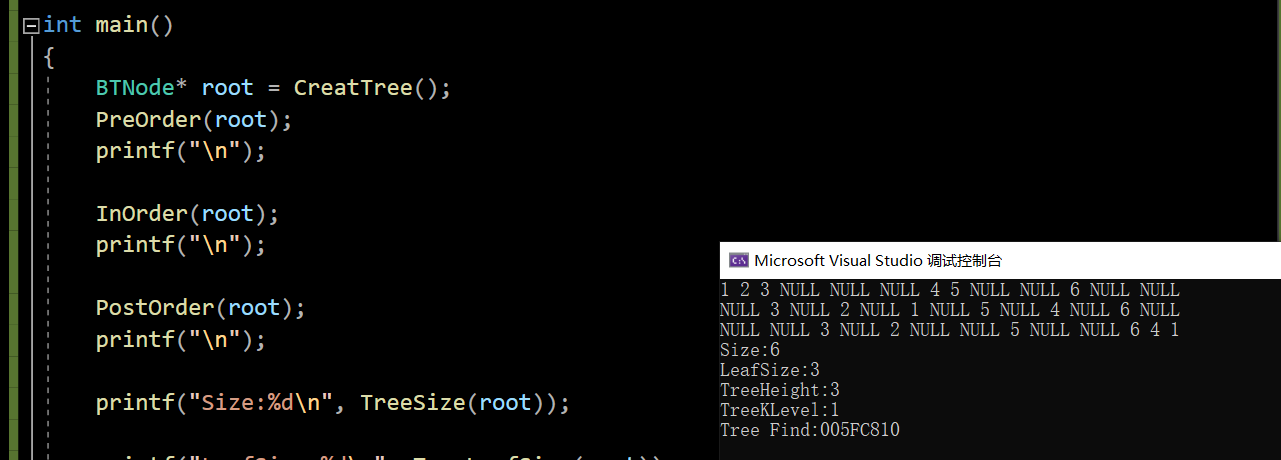
【数据结构】二叉树与堆
文章目录1.树概念及结构1.1树的相关概念1.2树的结构2.二叉树概念及结构2.1相关概念2.2特殊的二叉树2.3二叉树的性质2.4二叉树的存储结构3.二叉树的顺序结构及实现3.1二叉树的顺序结构3.2堆的概念3.3堆的实现Heap.hHeap.c3.4堆的应用3.4.1 堆排序3.4.2 TOP-KOJ题最小K个数4.二叉…...
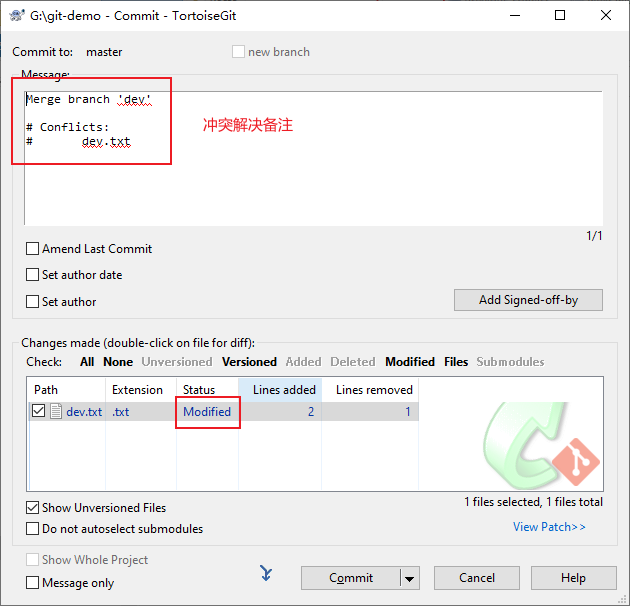
Git图解-常用命令操作-可视化
目录 一、前言 二、初始化仓库 2.1 设置用户名与邮箱 2.2 初始化仓库 三、添加文件 四、查看文件状态 五、查看提交日志 六、查看差异 七、版本回退 八、删除文件 九、分支管理 9.1 创建分支 9.2 切换分支 9.3 查看分支 9.4 合并分支 十、文件冲突 十一、转视…...

C语言-基础了解-20-typedef
typedef 一、typedef C 语言提供了 typedef 关键字,您可以使用它来为类型取一个新的名字。下面的实例为单字节数字定义了一个术语 BYTE: typedef unsigned char BYTE; 在这个类型定义之后,标识符 BYTE 可作为类型 unsigned char 的缩写&…...

Ubuntu系统升级16.04升级18.04
一、需求说明 作为Linux发行版中的后起之秀,Ubuntu 在短短几年时间里便迅速成长为从Linux初学者到实验室用计算机/服务器都适合使用的发行版,目前官网最新版本是22.04。Ubuntu16.04是2016年4月发行的版本,于2019年4月停止更新维护。很多软件支…...
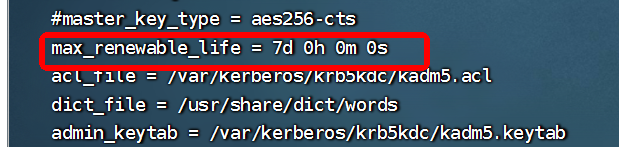
CM6.3.2启用Kerberos(附问题解决)
基础准备支持JCE的jdk重新安装JCE的jdk(已正确配置跳过)删除/usr/java/下面的jdk,然后通过CM->管理->安全->安装Java无限制...重新安装后,配置Java(可选)主机->主机配置->搜java->Java主目录 配置路径主机->所有主机->设置->高级:Java配置Kerberos安…...
)
QML 动画(组合动画)
在QML中,可以把多个动画组合成一个单一的动画。 组合动画的类型: ParallelAnimation 动画同时进行(并行)SequentialAnimation 动画按照顺序执行(顺序执行)注意:将动画分组为“顺序动画”或“…...
【PHP代码注入】PHP代码注入漏洞
漏洞原理RCE为两种漏洞的缩写,分别为Remote Command/Code Execute,远程命令/代码执行PHP代码注入也叫PHP代码执行(Code Execute)(Web方面),是指应用程序过滤不严,用户可以通过HTTP请求将代码注入到应用中执行。代码注入(代码执行)…...

Python 常用语句同C/C++、Java的不同
文章目录前言1. 数字 int2. 字符 string3. 列表 List4. 元组 tuple5. 字典 dictionary6. 集合 set7. 值类型变量与引用类型变量8. if elif else9. >、<、>、<、、!10. while11. for前言 本篇为本人前段时间的一个简单汇总,这里可能并不齐全,…...

一把火烧掉了苹果摆脱中国制造的幻想,印度制造难担重任
这几年苹果不断推动印度制造,希望摆脱对中国制造的依赖,然而近期苹果在印度的一家代工厂发生大火却证明了苹果的这一计划遭受重大打击,印度制造根本就无法中国制造。一、印度制造屡屡发生幺蛾子苹果推动印度制造已有多年了,然而印…...

常用的 JavaScript 数组 API
以下是一些常用的 JavaScript 数组 API 的代码示例: 1、push() push(): 在数组末尾添加一个或多个元素,返回新的数组长度 const arr [1, 2, 3]; const newLength arr.push(4, 5); console.log(arr); // [1, 2, 3, 4, 5] console.log(newLength); //…...
海思3531a pjsip交叉编译
学习文档: PJSUA2 Documentation — PJSUA2 Documentation 1.0-alpha documentationhttps://www.pjsip.org/docs/book-latest/html/index.html ./configure --prefix/opensource/pjproject-2.12/build3531a \ --host/opt/hisi-linux/x86-arm/arm-hisi…...
《安富莱嵌入式周报》第305期:超级震撼数码管瀑布,使用OpenAI生成单片机游戏代码的可玩性,120通道逻辑分析仪,复古电子设计,各种运动轨迹函数源码实现
往期周报汇总地址:嵌入式周报 - uCOS & uCGUI & emWin & embOS & TouchGFX & ThreadX - 硬汉嵌入式论坛 - Powered by Discuz! 说明: 谢谢大家的关注,继续为大家盘点上周精彩内容。 视频版: https://www.bi…...

力扣-查找每个员工花费的总时间
大家好,我是空空star,本篇带大家了解一道简单的力扣sql练习题。 文章目录前言一、题目:1741. 查找每个员工花费的总时间二、解题1.正确示范①提交SQL运行结果2.正确示范②提交SQL运行结果3.正确示范③提交SQL运行结果4.正确示范④提交SQL运行…...

企业级信息系统开发学习笔记1.8 基于Java配置方式使用Spring MVC
文章目录零、本节学习目标一、基于Java配置与注解的方式使用Spring MVC1、创建Maven项目 - SpringMVCDemo20202、在pom.xml文件里添加相关依赖3、创建日志属性文件 - log4j.properties4、创建首页文件 - index.jsp5、创建Spring MVC配置类 - SpringMvcConfig6、创建Web应用初始…...

YOLOv8 智能交通违章检测 - 疲劳/分心驾驶检测详解
YOLOv8 智能交通违章检测 - 疲劳/分心驾驶检测详解 疲劳驾驶和分心驾驶检测属于驾驶员状态监测(DMS, Driver Monitoring System)的核心功能。与外部交通违章不同,这需要摄像头安装在车内,对准驾驶员面部。 由于人脸关键点(眼睛、嘴巴)的微小变化对精度要求极高,单纯的…...

Phi-4-mini-reasoning数学推理开源生态:Jupyter Notebook交互式教学套件
Phi-4-mini-reasoning数学推理开源生态:Jupyter Notebook交互式教学套件 1. 模型简介 Phi-4-mini-reasoning 是一个基于合成数据构建的轻量级开源模型,专注于高质量、密集推理的数据处理。作为Phi-4模型家族的一员,它经过专门微调以提升数学…...

AI语音转换个性化模型实战指南:从认知到实践的全面探索
AI语音转换个性化模型实战指南:从认知到实践的全面探索 【免费下载链接】Retrieval-based-Voice-Conversion-WebUI Easily train a good VC model with voice data < 10 mins! 项目地址: https://gitcode.com/GitHub_Trending/re/Retrieval-based-Voice-Conver…...

推荐1款文字语音翻译神器,中英文转换语音实时录入
聊一聊发现一款好玩的工具,输入文字自动翻译成英文,也可以输入英文自动翻译成中文,语音也可以。主要是前几天有人问过我有没有,现在找到了,工具操作简单,下面会有文字配图,更多功能就需要大家自…...
的高级用法与实战技巧**在Go语言编程中,**slice(分片)** 是最常用)
**发散创新:Go语言中分片(Slice)的高级用法与实战技巧**在Go语言编程中,**slice(分片)** 是最常用
发散创新:Go语言中分片(Slice)的高级用法与实战技巧 在Go语言编程中,slice(分片) 是最常用、最灵活的数据结构之一。它不仅是数组的“智能包装器”,更是高效内存管理和性能优化的核心工具。本文…...

Phi-3-mini-4k-instruct-gguf参数详解:重复惩罚penalty对技术文档生成影响
Phi-3-mini-4k-instruct-gguf参数详解:重复惩罚penalty对技术文档生成影响 1. 模型概述 Phi-3-mini-4k-instruct-gguf是微软Phi-3系列中的轻量级文本生成模型GGUF版本,特别适合问答、文本改写、摘要整理和简短创作等场景。这个开箱即用的中文文本生成模…...

OpenClaw多模态编程:用Phi-3-vision-128k-instruct开发视觉脚本
OpenClaw多模态编程:用Phi-3-vision-128k-instruct开发视觉脚本 1. 为什么我们需要视觉脚本? 去年夏天,我接手了一个自动化测试项目,需要每天重复操作几十次相同的GUI流程。传统RPA工具在面对动态界面时频繁失效——按钮位置偏移…...

OpenClaw操作简化技巧:Kimi-VL-A3B-Thinking常用任务的一键触发
OpenClaw操作简化技巧:Kimi-VL-A3B-Thinking常用任务的一键触发 1. 为什么需要操作简化 第一次接触OpenClaw时,我被它强大的自动化能力震撼——直到需要反复输入冗长的指令来触发同一个任务。比如每天早晨需要让Kimi-VL-A3B-Thinking模型帮我整理前一天…...

千问3.5-27B模型托管:OpenClaw连接星图平台API最佳实践
千问3.5-27B模型托管:OpenClaw连接星图平台API最佳实践 1. 为什么选择星图平台托管大模型 去年冬天,当我第一次尝试在本地机器上部署Qwen3.5-27B模型时,显卡的轰鸣声和风扇的呼啸让我意识到——个人开发者要运行这种规模的模型实在太吃力了…...

前端性能监控看板
metricsperformance.getEntriesByType(navigation)[0]把获取数组的第一个元素给metrics...