【机器学习之旅】概念启程、步骤前行、分类掌握与实践落地

🎈个人主页:豌豆射手^
🎉欢迎 👍点赞✍评论⭐收藏
🤗收录专栏:机器学习
🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进步!
【机器学习之旅】概念启程、步骤前行、分类掌握与实践落地
- 一 引言
- 二 机器学习的基本概念
- 1.1 机器学习定义
- 1.2 机器学习与传统编程的区别
- 1.3 机器学习的核心要素:数据、算法、计算力
- 三 机器学习的主要步骤
- 3.1 数据收集与预处理
- 3.2 特征工程
- 3.3 模型选择与训练
- 3.4 模型评估与优化
- 3.5 模型部署与应用
- 四 机器学习的分类
- 4.1 监督学习
- 4.2 非监督学习
- 4.3 其他学习方法
- 五 机器学习实践案列
- 5.1 分类问题实践
- 5.2 回归问题实践
- 5.3 聚类分析实践
- 六 机器学习实战代码
- 1. 文本分类(使用朴素贝叶斯算法)
- 2. 房价预测(使用线性回归)
- 3. 客户分群(使用K-means聚类)
- 总结


一 引言

随着信息技术的飞速发展和数据资源的日益丰富,机器学习作为人工智能的重要分支,正在逐渐改变着我们的生活方式和思维模式。
机器学习的发展历程可以追溯到上个世纪五十年代,经历了从早期的符号学习到统计学习的转变,再到近年来深度学习的崛起,其技术与应用不断取得突破和进步。
当前,机器学习已经渗透到各个行业和领域,从医疗、金融、教育到交通、娱乐等,无处不在。
在医疗领域,机器学习技术被用于疾病诊断、药物研发和个性化治疗等方面,大大提高了医疗水平和效率;
在金融领域,机器学习算法能够准确预测市场趋势和风险,帮助投资者做出更明智的决策;
在教育领域,机器学习可以根据学生的学习进度和能力,提供个性化的学习资源和辅导;
在交通领域,机器学习技术则能够优化交通流量、减少拥堵和事故;
在娱乐领域,机器学习为我们提供了更智能的推荐系统和虚拟助手。
机器学习的重要性不言而喻。它不仅能够处理海量数据,提取有价值的信息,还能够通过学习不断优化自身的性能,实现自动化和智能化的决策。
在当今社会,数据已经成为一种重要的资源,而机器学习正是处理和分析这些数据的关键工具。
通过机器学习,我们能够更好地理解和应对复杂的社会现象,提高生产力和生活质量。
因此,深入学习和理解机器学习技术,掌握其应用方法和实践案例,对于我们每个人来说都具有重要意义。
无论是在学术研究、技术创新还是商业应用方面,机器学习都将发挥越来越重要的作用。
本文旨在全面介绍机器学习的基本概念、步骤、分类和实践案例,帮助读者更好地了解和掌握这一前沿技术,为未来的发展和应用提供有力支持。
二 机器学习的基本概念

1.1 机器学习定义
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。它的核心在于专门研究计算机如何模拟或实现人类的学习行为,从而获取新的知识或技能,并重新组织已有的知识结构,使其不断改善自身的性能。
简而言之,机器学习旨在使计算机具有智能,并通过从数据中学习来自动发现模式和规律。
1.2 机器学习与传统编程的区别
1. 传统编程:
- 基于规则与逻辑:传统编程主要依赖程序员定义的规则和逻辑来完成特定任务。程序员需要明确指定输入、输出以及中间的逻辑过程。
- 适用于明确问题:传统编程在解决具体、确定且逻辑清晰的问题上表现优秀。
2. 机器学习:
- 数据驱动:机器学习则是一种从数据中学习的方法,它能够从大量数据中自动提取信息和规律,并根据这些信息调整和优化模型。
- 预测与决策:通过训练和优化模型,机器学习能够对未见过的数据进行预测和决策,这种能力使其在处理复杂和不确定的问题上具有优势。
1.3 机器学习的核心要素:数据、算法、计算力
1. 数据(Data):
- 机器学习的基础:数据是机器学习的起点,它提供了学习的原材料。数据集通常包含输入样本和相应的标签或目标值。
- 数据质量与规模:数据集的质量和规模对机器学习的性能至关重要。高质量、大规模的数据集能够提供更丰富、更准确的信息,有助于训练出性能更好的模型。
2. 算法(Algorithm):
- 学习模型的方法:算法是机器学习中负责从数据集中学习模型的关键部分。机器学习算法可以分为监督学习、无监督学习和强化学习等不同类别。
- 算法选择与优化:选择合适的算法对于机器学习任务的成功至关重要。同时,算法的优化也是提高模型性能的关键步骤。
3. 计算力(Computational Power):
- 支撑学习与推理:计算力是机器学习过程中的重要支撑。它涉及到处理数据、训练模型以及进行推理所需的计算能力。
- 硬件与软件支持:随着机器学习任务的复杂性和数据规模的增加,对计算力的需求也在不断提高。因此,高性能的硬件和软件支持对于机器学习的成功至关重要。
总结:机器学习是一门旨在使计算机具有智能的学科,它通过从数据中学习来自动发现模式和规律。与传统编程相比,机器学习更加注重数据驱动和预测决策。
同时,数据、算法和计算力作为机器学习的核心要素,共同支撑着机器学习任务的完成和性能的提升。
三 机器学习的主要步骤

3.1 数据收集与预处理
1. 数据来源与收集方式
机器学习的第一步是收集数据。数据来源多种多样,可能包括公开数据集、企业内部数据库、传感器数据、用户行为日志等。
数据的收集方式则根据数据类型和应用场景的不同而有所差异,如通过网络爬虫爬取互联网数据、使用API接口获取数据等。
2. 数据清洗与预处理技术
数据清洗是预处理的关键步骤,主要包括去除重复值、填充缺失值、处理异常值等。
例如,对于缺失值,可以采用均值填充、中位数填充或基于机器学习模型的预测填充等方法。
此外,数据清洗还包括去除噪声和无关特征,以提高数据质量。
预处理技术还包括数据标准化或归一化,使不同特征具有相同的尺度,以便后续模型处理。
此外,数据降维技术如PCA(主成分分析)可以帮助降低数据复杂度,提高模型训练效率。
3.2 特征工程
1. 特征提取与选择
特征工程是机器学习中至关重要的步骤,它涉及从原始数据中提取有意义的特征,并选择对模型性能有正面影响的特征。
特征提取可以通过领域知识、统计方法或深度学习技术实现。
特征选择则是从提取的特征中筛选出最相关、最具代表性的特征,以减少模型的复杂度并提高性能。
2. 特征转换与编码
特征转换是将原始特征转换为更适合模型处理的形式。
例如,对于文本数据,可以使用词袋模型或TF-IDF进行向量化;
对于图像数据,可以提取其颜色、纹理或形状等特征。编码技术则用于将非数值型特征转换为数值型特征,如标签编码、独热编码等。
3.3 模型选择与训练
1. 常见机器学习模型介绍
机器学习模型种类繁多,包括线性回归、逻辑回归、决策树、随机森林、支持向量机、神经网络等。
每种模型都有其适用的场景和优缺点,因此需要根据具体任务和数据特点选择合适的模型。
2. 模型训练过程与参数调优
模型训练是使用收集的数据对选定的模型进行学习的过程。
通过优化算法如梯度下降法,不断调整模型参数以最小化损失函数,使模型在训练数据上达到较好的性能。
参数调优是通过对模型参数进行调整,以找到使模型性能最优的参数组合。
这通常涉及交叉验证、网格搜索等技术。
3.4 模型评估与优化
1. 评估指标与交叉验证
模型评估是衡量模型性能的关键步骤,常用评估指标包括精度、召回率、F1值、准确率等。
交叉验证是一种评估模型性能的有效方法,通过将数据集划分为训练集和验证集(或更多子集),多次训练和验证模型,以评估模型的泛化能力。
2. 模型优化策略与防止过拟合
模型优化旨在提高模型的性能和泛化能力。
常见的优化策略包括调整模型复杂度、使用正则化技术(如L1正则化、L2正则化)、集成学习等。
防止过拟合是模型优化中的重要问题,可以通过增加数据量、采用早停法、使用dropout等技术来降低过拟合风险。
3.5 模型部署与应用
1. 模型部署方式
当模型训练和优化完成后,需要将其部署到实际应用场景中。
模型部署方式可以根据具体需求和环境来选择,如将模型集成到Web应用中提供API接口、部署到移动设备上实现实时预测等。
2. 模型在实际问题中的应用与效果评估
模型在实际问题中的应用涉及将模型与具体业务场景结合,实现预测、分类等任务。
效果评估则是通过对比模型预测结果与实际结果,分析模型的性能表现,并根据业务需求进行迭代优化。
综上所述,机器学习的主要步骤包括数据收集与预处理、特征工程、模型选择与训练、模型评估与优化以及模型部署与应用。
每个步骤都至关重要,需要仔细设计和执行,以确保机器学习模型能够在实际应用中发挥最佳性能。
四 机器学习的分类

机器学习是一门涉及多个领域的交叉学科,它涵盖了多种不同的学习方法和分类。
4.1 监督学习
监督学习是机器学习中最常见和广泛应用的一种学习方式。
在监督学习中,模型通过一组已知标签的样本进行学习,然后根据这些样本的特征和标签之间的关系来预测新样本的标签。
监督学习可以进一步细分为回归问题和分类问题。
1. 回归问题
回归问题是指在给定一组自变量的情况下,通过找到最佳拟合曲线或平面,来预测或估计连续的因变量。它的目标是建立一个函数模型,能够用自变量的值来预测因变量的值。
回归问题在各个领域都有广泛的应用,如经济学中的股市预测、医学中的药物剂量研究等。
2. 分类问题
分类问题则是将输入数据划分为预定义的类别之一。
在监督学习中,分类问题通常涉及已知每个数据点的标签,通过训练数据集来建立一个分类模型,以预测未知数据的标签。
常见的分类算法包括决策树、朴素贝叶斯、支持向量机等。
分类问题在图像识别、语音识别、垃圾邮件过滤等领域有着广泛的应用。
4.2 非监督学习
与监督学习不同,非监督学习是指在没有标签的数据上进行学习的方法。
非监督学习的目标是发现数据中的内在结构或模式,而不需要依赖于外部的标签信息。
1. 聚类分析
聚类分析是非监督学习中的一种重要技术,它将物理或抽象对象的集合分组为由类似的对象组成的多个类。
聚类分析的目标是在相似的基础上收集数据来分类,其应用范围广泛,包括数据挖掘、图像识别、社交网络分析等。
2. 降维技术
降维技术是非监督学习中的另一种关键技术,主要用于减少数据集的特征数量,以提高数据分析和模型训练的效率和准确性。
降维技术可以分为特征选择和特征提取两种方法。
特征选择是通过评估特征之间的相关性,从原始数据中选取最能代表问题的特征;
而特征提取则是通过统计分析方法,将高维数据转换为低维数据,同时保留重要信息。
4.3 其他学习方法
除了监督学习和非监督学习,机器学习还包括其他多种学习方法。
1. 半监督学习
半监督学习介于监督学习和非监督学习之间,它利用少量的标签数据和大量的无标签数据进行学习。
半监督学习旨在通过结合有标签和无标签数据的优点,提高学习性能。
2. 强化学习
强化学习是一种通过试错来进行学习的方法。
在强化学习中,智能体通过与环境的交互来学习如何做出决策,以最大化累积奖励。
强化学习在机器人控制、游戏AI等领域具有广泛的应用。
3. 深度学习
深度学习是机器学习的一个子领域,它利用深度神经网络模型来处理和分析数据。
深度学习在处理复杂模式识别和特征提取任务上表现出色,广泛应用于图像识别、语音识别、自然语言处理等领域。
4. 迁移学习
迁移学习是一种利用在一个任务上学习的知识来改进另一个相关任务上的学习性能的方法。
迁移学习可以有效地解决数据稀缺或标注困难的问题,提高模型在新任务上的泛化能力。
总之,机器学习涵盖了多种不同的学习方法和分类,每种方法都有其独特的适用场景和优势。在实际应用中,可以根据具体问题和数据特点选择合适的学习方法和技术。
五 机器学习实践案列
机器学习实践案例涵盖了多个应用领域,下面将分别介绍分类问题实践(图像识别和文本分类)、回归问题实践(房价预测和股票价格预测)以及聚类分析实践(客户分群和社交网络分析)。
5.1 分类问题实践
1. 图像识别
图像识别是机器学习在分类问题中的一个重要应用。
以人脸识别为例,通过训练大量的人脸数据,机器学习算法可以学习到人脸的特征并进行准确鉴别。
在安保、身份认证和犯罪侦查等领域,人脸识别技术已经得到了广泛应用。
另一个案例是医疗图像诊断,通过对医学影像数据的训练,机器学习模型可以帮助医生快速准确地识别病变部位,提高诊断效率。
2. 文本分类
文本分类是机器学习在自然语言处理领域的另一个重要应用。
例如,新闻分类系统可以根据新闻内容将其自动归类到不同的类别,如体育、娱乐、科技等。
通过训练包含大量文本数据和对应标签的数据集,机器学习模型可以学习到文本的特征和分类规则,实现自动化和高效的文本分类。
5.2 回归问题实践
1. 房价预测
房价预测是回归问题中的一个典型应用。
通过对历史房价数据以及其他相关因素(如房屋面积、地理位置、周边设施等)的训练,机器学习模型可以学习到房价的规律和趋势,进而预测未来房价。
这对于房地产投资者、购房者和政府决策都具有重要的参考价值。
2. 股票价格预测
股票价格预测也是回归问题的一个重要应用。
基于历史股票价格数据、交易量、公司财报以及其他相关信息,机器学习模型可以学习到股票价格的变动规律,并预测未来价格走势。
这有助于投资者制定更合理的投资策略,降低投资风险。
常见的用于股票价格预测的机器学习模型包括长短期记忆网络(LSTM)、支持向量回归(SVR)和卷积神经网络(CNN)等。
5.3 聚类分析实践
1. 客户分群
在市场营销领域,聚类分析可以帮助企业将客户分成不同的细分市场,以便更好地满足客户需求。
通过对客户的购买记录、浏览行为、兴趣爱好等数据进行聚类分析,企业可以发现具有相似特征的客户群体,并制定相应的营销策略和产品推荐。
这有助于提高企业营销效率和客户满意度。
2. 社交网络分析
在社交网络分析中,聚类分析可以帮助我们发现用户之间的相似性和群体特征。
以微博为例,通过对用户的发帖内容、点赞和评论等信息进行聚类分析,我们可以将用户分成不同的兴趣群体,如运动爱好者、美食爱好者、电影迷等。
这有助于社交平台进行精准的内容推荐和广告投放,提升用户体验和平台收益。
这些实践案例展示了机器学习在不同领域的应用和潜力。随着技术的不断发展和数据的日益丰富,机器学习将在更多领域发挥重要作用,推动社会的进步和发展。
六 机器学习实战代码
以下是几个机器学习实战的示例代码,涵盖了分类问题(文本分类)、回归问题(房价预测)和聚类分析(客户分群)。
1. 文本分类(使用朴素贝叶斯算法)
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score# 加载数据集
newsgroups_train = fetch_20newsgroups(subset='train')
X_train, X_test, y_train, y_test = train_test_split(newsgroups_train.data, newsgroups_train.target, test_size=0.25, random_state=42)# 文本特征提取
vectorizer = CountVectorizer()
X_train_counts = vectorizer.fit_transform(X_train)
X_test_counts = vectorizer.transform(X_test)# 使用朴素贝叶斯分类器
clf = MultinomialNB()
clf.fit(X_train_counts, y_train)# 预测
y_pred = clf.predict(X_test_counts)# 评估
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")
2. 房价预测(使用线性回归)
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error# 加载数据(这里假设你有一个包含房价信息的CSV文件)
data = pd.read_csv('house_prices.csv')
X = data.drop('price', axis=1) # 特征
y = data['price'] # 目标变量# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 使用线性回归模型
reg = LinearRegression()
reg.fit(X_train, y_train)# 预测
y_pred = reg.predict(X_test)# 评估
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.2f}")
3. 客户分群(使用K-means聚类)
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt# 加载数据(这里假设你有一个包含客户信息的CSV文件)
data = pd.read_csv('customer_data.csv')
X = data.drop('customer_id', axis=1) # 假设'customer_id'是客户ID列# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)# 使用K-means聚类
kmeans = KMeans(n_clusters=3, random_state=42) # 假设我们想要分成3个群
kmeans.fit(X_scaled)# 获取聚类标签
labels = kmeans.labels_# 可视化结果(这里仅假设我们有两个特征用于二维可视化)
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=labels, cmap='viridis')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Customer Segmentation')
plt.show()
请注意,上述代码中的fetch_20newsgroups、pd.read_csv('house_prices.csv')和pd.read_csv('customer_data.csv')函数假设你已经有了相应的数据集。
在实际应用中,你需要将'house_prices.csv'和'customer_data.csv'替换为你自己的数据文件的路径。
此外,这些代码片段仅提供了基础的模型训练和评估流程,实际应用中可能还需要进行更多的数据预处理、特征工程、模型调优和验证等步骤。
总结
通过本文的介绍,我们全面了解了机器学习的基本概念、主要步骤、分类方法以及实践应用。
机器学习作为一种强大的数据处理和分析工具,已经广泛应用于各个领域,并取得了显著的成果。
然而,机器学习并非一蹴而就的过程,它需要我们在实践中不断探索和优化。
通过本文提供的实战代码,我们可以更加深入地理解机器学习的实现过程,并为日后的实际应用打下坚实的基础。
在未来的学习和工作中,让我们继续探索机器学习的奥秘,用技术为生活带来更多的便利和惊喜。

这篇文章到这里就结束了
谢谢大家的阅读!
如果觉得这篇博客对你有用的话,别忘记三连哦。
我是豌豆射手^,让我们我们下次再见


相关文章:
【机器学习之旅】概念启程、步骤前行、分类掌握与实践落地
🎈个人主页:豌豆射手^ 🎉欢迎 👍点赞✍评论⭐收藏 🤗收录专栏:机器学习 🤝希望本文对您有所裨益,如有不足之处,欢迎在评论区提出指正,让我们共同学习、交流进…...
外星人m18R2国行中文版原厂预装23H2原装Win11系统恢复带F12恢复重置
戴尔外星人m18R2国行中文版原厂预装23H2系统恢复安装 远程恢复安装:https://pan.baidu.com/s/166gtt2okmMmuPUL1Fo3Gpg?pwdm64f 提取码:m64f 1.自带原厂预装系统各驱动,主题,Logo,Office带所有Alienware主题壁纸、Alienware软件驱动 2.带…...
libVLC 视频抓图
Windows操作系统提供了多种便捷的截图方式,常见的有以下几种: 全屏截图:通过按下PrtSc键(Print Screen),可以截取整个屏幕的内容。截取的图像会保存在剪贴板中,可以通过CtrlV粘贴到图片编辑工具…...

Docker搭建LNMP环境实战(06):Docker及Docker-compose常用命令
Docker搭建LNMP环境实战(06):Docker及Docker-compose常用命令 此处列举了docker及docker-compose的常用命令,一方面可以做个了解,另一方面可以在需要的时候进行查阅。不一定要强行记忆,用多了就熟悉了。 1、…...

ClickHouse10-ClickHouse中Kafka表引擎
Kafka表引擎也是一种常见的表引擎,在很多大数据量的场景下,会从源通过Kafka将数据输送到ClickHouse,Kafka作为输送的方式,ClickHouse作为存储引擎与查询引擎,大数据量的数据可以得到快速的、高压缩的存储。 Kafka大家…...

Encoding类
Encoding System.Text.Encoding 是 C# 中用于处理字符编码和字符串与字节之间转换的类。它提供了各种静态方法和属性,**用于在不同字符编码之间进行转换,**以及将字符串转换为字节数组或反之。 在处理多语言文本、文件、网络通信以及其他字符数据的场景…...

标定系列——预备知识-OpenCV中实现Rodrigues变换的函数(二)
标定系列——预备知识-OpenCV中实现Rodrigues变换的函数(二) 说明记录 说明 简单介绍罗德里格斯变换以及OpenCV中的实现函数 记录...

2014年认证杯SPSSPRO杯数学建模C题(第一阶段)土地储备方案的风险评估全过程文档及程序
2014年认证杯SPSSPRO杯数学建模 C题 土地储备方案的风险评估 原题再现: 土地储备,是指市、县人民政府国土资源管理部门为实现调控土地市场、促进土地资源合理利用目标,依法取得土地,进行前期开发、储存以备供应土地的行为。土地…...

我的编程之路:从非计算机专业到Java开发工程师的成长之路 | 学习路线 | Java | 零基础 | 学习资源 | 自学
小伙伴们好,我是「 行走的程序喵」,感谢您阅读本文,欢迎三连~ 😻 【Java基础】专栏,Java基础知识全面详解:👉点击直达 🐱 【Mybatis框架】专栏,入门到基于XML的配置、以…...
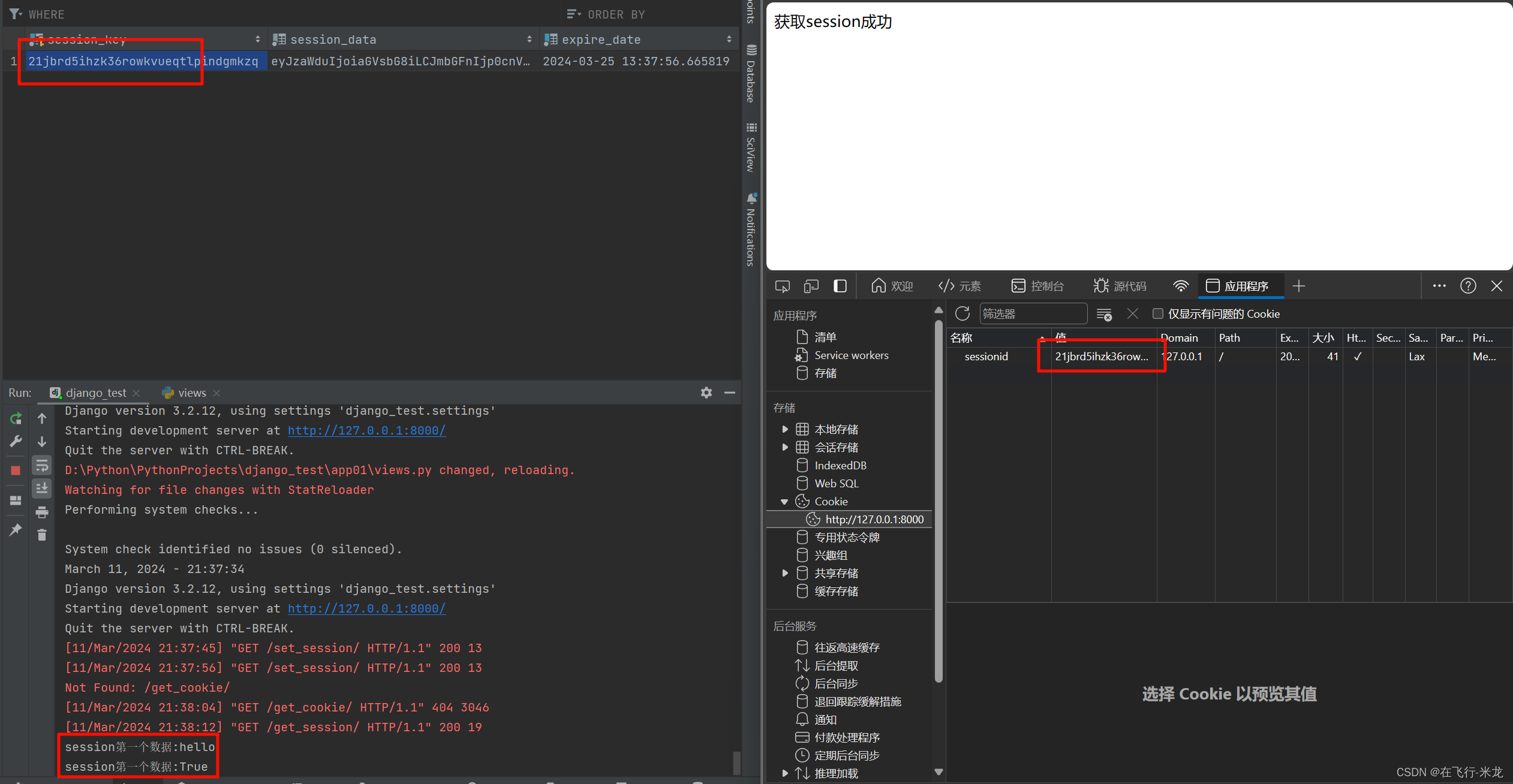
Django Cookie和Session
Django Cookie和Session 【一】介绍 【1】起因 HTTP协议四大特性 基于请求响应模式:客户端发送请求,服务端返回响应基于TCP/IP之上:作用于应用层之上的协议无状态:HTTP协议本身不保存客户端信息短链接:1.0默认使用短…...
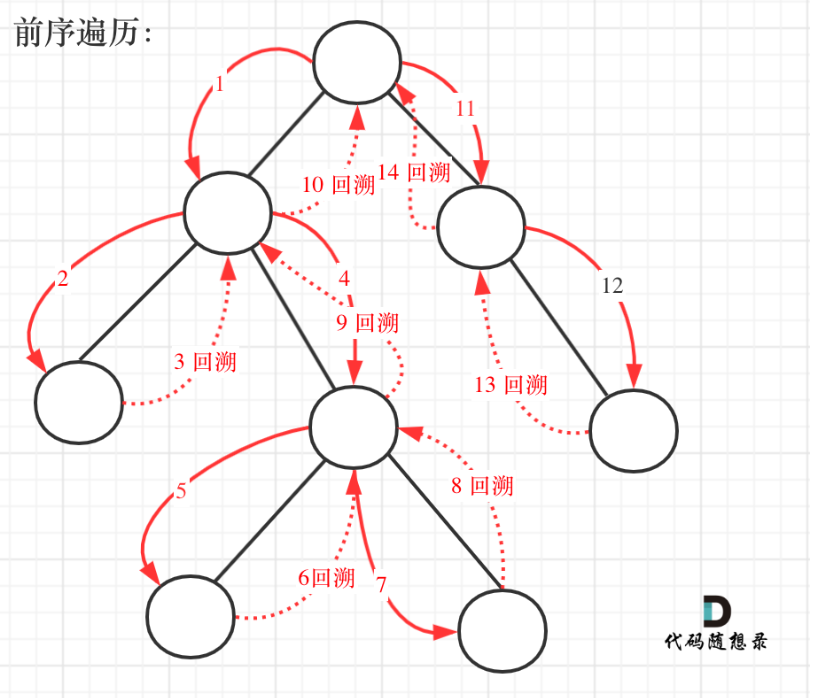
【算法刷题 | 二叉树 04】3.27(翻转二叉树、对称二叉树、完全二叉树的节点个数、平衡二叉树、完全二叉树的所有路径)
文章目录 6.翻转二叉树6.1问题6.2解法一:递归6.2.1递归思路(1)确定递归函数的参数和返回值(2)确定终止条件(3)确定单层递归的逻辑 6.2.2全部代码 6.3解法二:层序遍历 7.对称二叉树7.…...
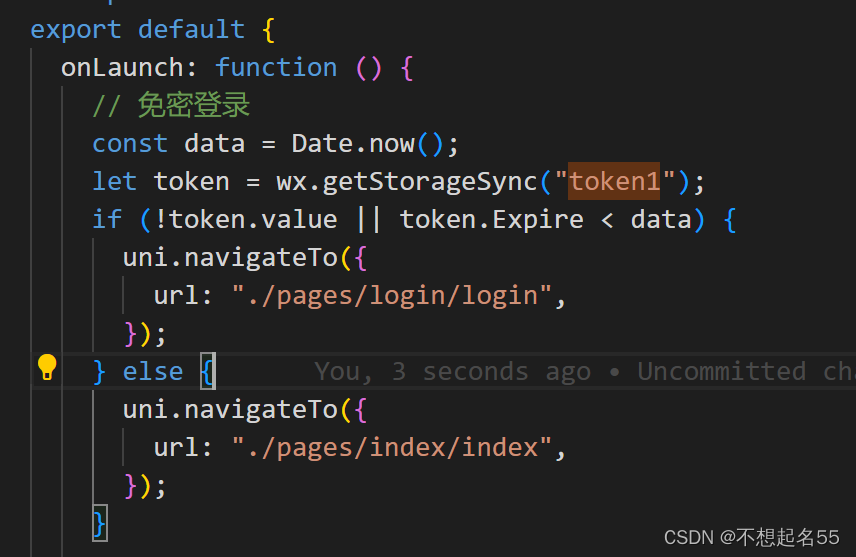
【uniapp】uniapp实现免密登录
文章目录 一、概要二、整体架构流程三、技术名词解释四 、技术细节1.存取token有效期?2.使用setStorageSync而不使用setStorage?3.使用onLaunch而不使用全局路由? 一、概要 打开一个网页或小程序的时候,我们有时候会自动进入主页…...

2024-03-27 问AI: 介绍一下深度学习中的 Darknet
文心一言 在深度学习中,Darknet是一个开源的神经网络框架,由Joseph Redmon开发,主要用于实现深度学习算法。它以其高效的实现和速度受到广泛关注,并在许多计算机视觉竞赛中取得了优异的结果。 Darknet的特点包括: 轻…...

POJ3037 + HDU-6714
两道最短路好题 POJ3037 手玩一下 发现每一点的速度可以直接搞出来,就是pow(2,h[1][1]-h[i][j])*V 那么从这个点出发到达别的点的耗费的时间都是上面这个数的倒数,然后直接跑最短路就好了 #include<iostream> #include<vector> #include<…...

Ubuntu搭建环境Cmake-Libtorch-Torchvision-PCL-VTK-OpenCV
Ubuntu搭建环境Cmake-Libtorch-Torchvision-PCL-VTK-OpenCV 安装Cmake安装libtorch安装torchvision安装PCL安装VTK安装OpenCV设置环境变量 仅供本人记录查阅使用 安装Cmake Cmake下载地址 解压 进入目录会看到只有 bin doc man share三个文件夹,没有 bootstrap文…...

分享多种mfc100u.dll丢失的解决方法(一键修复DLL丢失的方法)
在使用电脑过程中,我们经常会遇到一些陌生的DLL文件,例如mfc100u.dll。这些DLL文件是动态链接库(Dynamic Link Libraries)的缩写,它们包含了可以被多个程序共享的代码和数据。今天,我们将深入探讨mfc100u.d…...
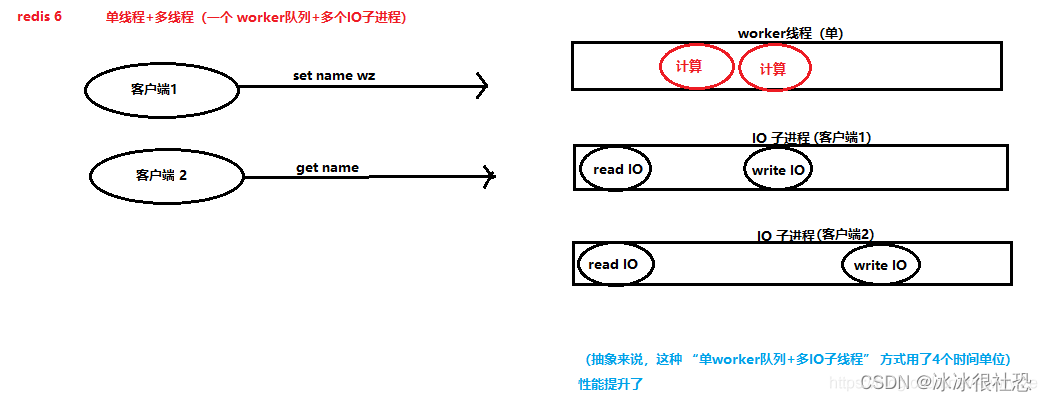
Redis是单线程还是多线程?(面试题)
1、Redis5及之前是单线程版本 2、Redis6开始引入多线程版本(实际上是 单线程多线程 版本) Redis6及之前版本(单线程) Redis5及之前的版本使用的是 单线程,也就是说只有一个 worker队列,所有的读写操作都要…...
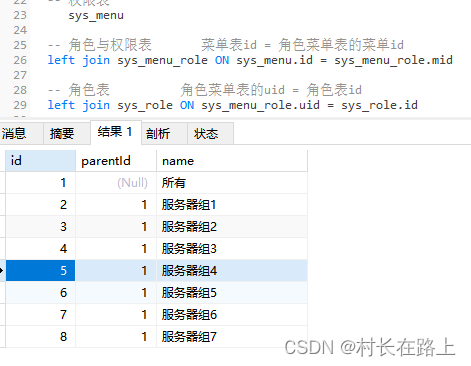
动态菜单设计
需求: 登录不同用户 显示不同的菜单 思路:根据用户id 左关联表 查询出对应的菜单选项 查询SQL select distinct-- 菜单表 去除重复记录sys_menu.id,sys_menu.parentId, sys_menu.name from -- 权限表sys_menu-- 角色与权限表 菜单表id 角色菜…...
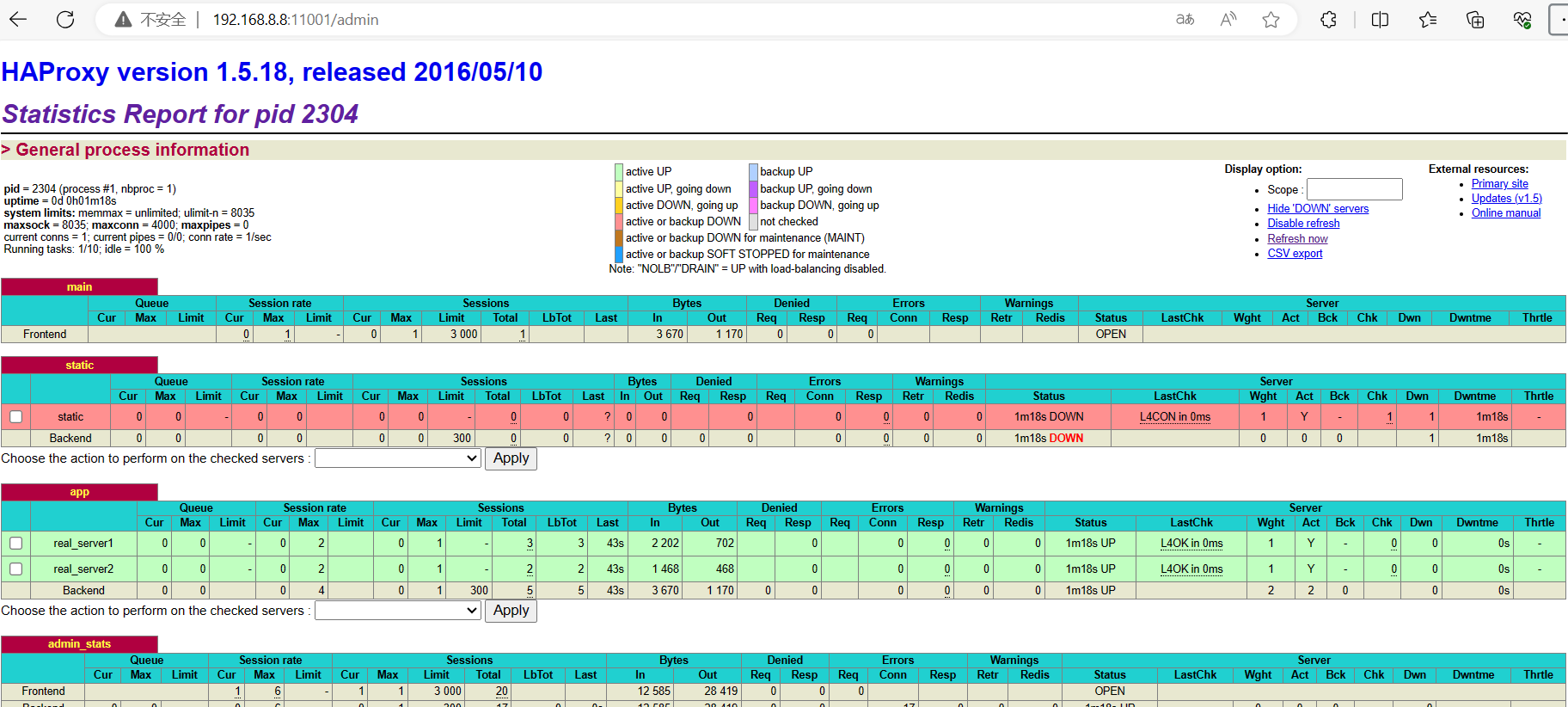
Haproxy负载均衡介绍即部署
haproxy的原理: 提供高可用、负载均衡以及基于TCP(四层)和HTTP(七层)应用的代理,支持虚拟主机,开源可靠的一款软件。 适用于哪些负载特别大的web站点,这些站点通常又需要回话保持和七…...

基于大语言模型的云故障根因分析|顶会EuroSys24论文
*马明华 微软主管研究员 2021年CCF国际AIOps挑战赛程序委员会主席(第四届) 2021年博士毕业于清华大学,2020年在佐治亚理工学院做访问学者。主要研究方向是智能运维(AIOps)、软件可靠性。近年来在ICSE、FSE、ATC、EuroS…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

Objective-C常用命名规范总结
【OC】常用命名规范总结 文章目录 【OC】常用命名规范总结1.类名(Class Name)2.协议名(Protocol Name)3.方法名(Method Name)4.属性名(Property Name)5.局部变量/实例变量(Local / Instance Variables&…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

BCS 2025|百度副总裁陈洋:智能体在安全领域的应用实践
6月5日,2025全球数字经济大会数字安全主论坛暨北京网络安全大会在国家会议中心隆重开幕。百度副总裁陈洋受邀出席,并作《智能体在安全领域的应用实践》主题演讲,分享了在智能体在安全领域的突破性实践。他指出,百度通过将安全能力…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

【7色560页】职场可视化逻辑图高级数据分析PPT模版
7种色调职场工作汇报PPT,橙蓝、黑红、红蓝、蓝橙灰、浅蓝、浅绿、深蓝七种色调模版 【7色560页】职场可视化逻辑图高级数据分析PPT模版:职场可视化逻辑图分析PPT模版https://pan.quark.cn/s/78aeabbd92d1...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...

深度学习之模型压缩三驾马车:模型剪枝、模型量化、知识蒸馏
一、引言 在深度学习中,我们训练出的神经网络往往非常庞大(比如像 ResNet、YOLOv8、Vision Transformer),虽然精度很高,但“太重”了,运行起来很慢,占用内存大,不适合部署到手机、摄…...

Unity VR/MR开发-VR开发与传统3D开发的差异
视频讲解链接:【XR马斯维】VR/MR开发与传统3D开发的差异【UnityVR/MR开发教程--入门】_哔哩哔哩_bilibili...