在低成本loT mcu上实现深度神经网络端到端自动部署-深度神经网络、物联网、边缘计算、DNN加速——文末完整资料
目录
前言
DNN
量化神经网络
并行超低功耗计算范式
面向内存的部署
结果
原文与源码下载链接
REFERENCES
前言
在物联网极端边缘的终端节点上部署深度神经网络( Deep Neural Networks,DNNs )是支持普适深度学习增强应用的关键手段。基于低成本MCU的终端节点片内存储器有限,通常使用划线板代替高速缓存,以减少面积开销和提高能量效率- -需要在内存层次结构的不同级别之间进行显式的基于DMA的内存传输。在这些系统上映射现代DNN需要进行积极的拓扑依赖平铺和双缓冲。在这项工作中,我们提出了DORY (面向memoRY的部署) - -一种自动工具,用于将DNN部署在片上SRAM内存通常小于1MB的低成本MCU上。DORY将平铺抽象为一个约束规划( CP )问题。
物联网( Internet of Things,IoT )设想有数十亿无线互联个终端节点,可以感知、处理和传输数据,广泛应用于监控、健康监测、农业、机器人等领域。然而,与这种新的计算模式相关的主要挑战包括可靠性、安全性、容量以及高带宽数据的产生。在这种情况下,基于边缘的深度学习( Deep Learning,DL )是一种有吸引力的方法,因为它能够从原始传感器数据中提取高级特征,减少节点外的传输,并通过在现场进行大部分处理来提高安全性。现代深度神经网络( Deep Neural Network,DNN )推理任务在云服务器、个人电脑或智能手机上运行。即使在最受约束的需要积极的硬件、软件和算法协同优化,以最大程度地利用这些系统上的稀缺资源。特别地,内存的稀缺性构成了真正的深度学习记忆墙:是嵌入式DNN计算系统最大性能的根本限制。
最近引入的算法改进,如量化DNN推理,旨在匹配DNN的全精度精度,同时仅使用8位(或更小)整数数据,以减少内存占用和执行复杂度。在硬件方面,加速器,和利用量化的指令集架构( ISA )扩展已经被引入来加速计算,减少内存限制的影响并最小化能耗。本质上,现在大多数框架都支持8位网络,如TensorFlow和PyTorch。最近提出的架构范式旨在最大化物联网终端节点上的DNN性能和效率,同时保障典型微控制器( Micro controller Unit,MCU )的灵活性,从而实现共同控制。
DNN
DNN算法最小化从算法的角度来看,DL部署的首要任务是确保DNN是"最小冗余"的,即它们不执行任何额外的操作,除非它导致更好的结果质量。在这个方向上,当前的一个研究趋势是通过直接收缩DNN拓扑结构本身来适应DNN架构在受限平台中的部署,或者使用神经架构搜索,或,[。正交地,系统设计人员可以采用训练后量化和量化感知微调的技术,以减少在能量方面的单个操作和在内存方面的单个参数的成本,试图在结果质量方面最小化价格。
面向DNN计算的优化软件和ISA给定一个尺寸优化和精度调整的DNN,我们需要解决部署挑战,即实现计算单元的最大利用率,同时最小化与跨内存层级的数据传输相关的性能和能量代价。特定应用的硬件结构在加速特定层和在某些情况下,整个网络是非常有用的 -但它们缺乏灵活性可能是一个领域的责任,例如DL,每年研究人员介绍数十种新的拓扑结构和不同的方法来组合DNN基本块。为了提供更高的灵活性,在许多情况下,DNN原语是在高度优化的软件中实现的,而不是硬件化块。
面向DNN的微控制器和相关工具,第一代面向低功耗神经网络的微控制器已经推出,它将DNN计算的优化软件和ISA扩展与"传统"控制和I/O密集型活动耦合在一起。为了使两类任务都能得到最优执行,这些MCU采用并行和异构处理;例如,ST Microelectronics6和NXP最近推出了具有专用于I / O的ARM M0处理器和具有单周期乘累加和SIMD功能的ARM M4处理器的新一代双核微控制器。与传统的扁平存储器MCU相比,这些平台在存储器层次结构方面表现出更高的复杂性,其中L1存储器优化了速度,L2存储器优化了容量。
量化神经网络
训练后量化或量化感知训练作为输出产生量化神经网络( Quantized Neural Network,QNN )。在本文的工作背景下,我们考虑QNNs通过线性均匀逐层量化产生,其中定义在范围[ αt,βt )内的所有张量t (例如,权重w ,输入x ,或输出y)可以通过双射映射映射到N比特整数张量 t:

其中ε t = ( βt-αt) / ( 2N-1 ) .我们称ε t为量子,因为它是我们在量子化张量中所能表示的最小量。每个QNN层由线性、批量归一化(可选)和量化/激活( Quantization / Activation )三个算子序列组成。不失一般性,我们考虑对Linear的所有输入和Quantization / Activation operator10的输出都有α x = αy = 0,但不考虑权重。利用Eq . 1,所有算子都映射在整数域上:
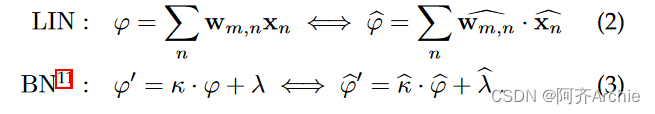
式中的点积运算。2导致用于表示φ ε的量子收缩,即φ ε = ε w ε x。因此,在累加结束时重新量化之前,我们需要用更高精度(例如, 32位)表示线性算子( φ )关于其输入的整数输出。类似的考虑也适用于Batch Normalization及其输出φ′。最后的量化/激活算子i )提供了QNN工作所必需的非线性激活,ii )将累加器压缩成更小的位宽:
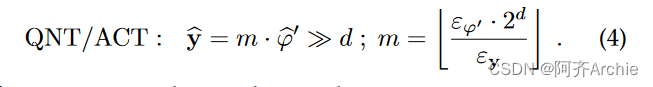
D是在量化过程中选择的整数,使得ε φ ε / ε y在m内具有足够的精度。类似于式( 1 )的方法。当网络的多个分支,每个分支都有自己的ε,在单个张量(通常使用求和的方法)中重新收敛时,也使用4。在这种情况下,分支使用方程的变体"匹配"到同一个量子。4 .得益于等式的映射。1,可以仅使用整数数据执行整个网络。在这项工作中,我们使用8比特量化的目标网络,其中包括有符号的蜡质( w )和无符号的蜡质( x / y );φ、φ′和κ、λ、m、d参数采用32位整数(符号)。我们依赖开源的NEMO库[ 40 ]来生成本节所述格式的QNN拓扑。
并行超低功耗计算范式
研究和工业界越来越关注具有专门协处理器(加速器)和层次化存储器的边缘节点,旨在利用新兴数据分析任务(例如,深度学习)中普遍存在的数据规律性。并行超低功耗计算( Parallel Ultra-Low Power Computing )是一种利用近阈值计算来实现高能效的架构范例,再加上并行性来改善低电压下的性能下降[ 42 ]。PULP范式建立在趋势的基础上
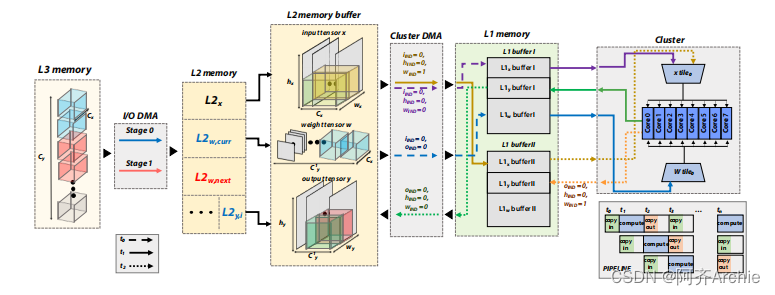
针对DSP和DNN计算的ISA优化;异构并行加速,架构上不同的计算单元专用于不相关的任务;并显式地管理了内存管理。PULP系统以具有标准外设的单核微控制器( I / O域)为核心。I / O核将并行任务卸载到一个由N个额外核组成的可软件编程的并行加速器上,驻留在自己的电压域和频域(集群域)。GWT GAP-8 [ 23 ] (如图1所示)是一个商用的PULP系统,具有9个扩展的RISC - V核(一个I / O +一个八核集群),我们选择它作为本工作的参考平台,因为它代表了DNN专用MCU的最先进的实施方案之一
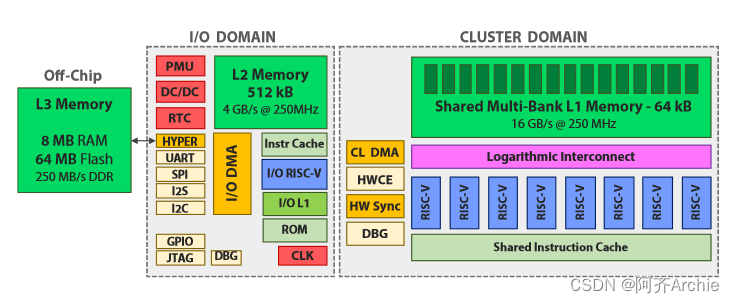
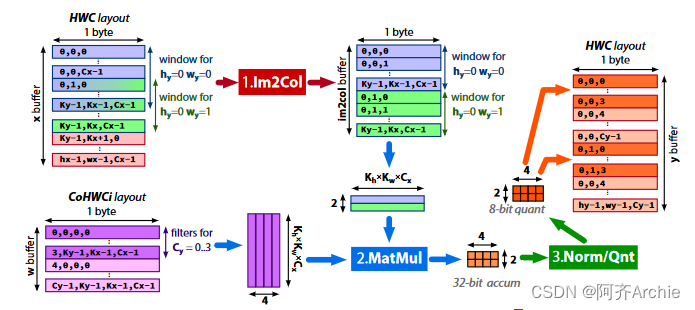
PULP - NN是基于HWC数据布局的。在后端库中实现了一个高效的QNN层,分为3个阶段,如图2所示。首先,Im2Col步骤使用加载/存储操作将从其内存排列中的三维输入非序列生成单个输出像素(即,感受野)所需的像素复制到一维向量中。值得注意的是,由于给定HWC数据布局,所有必要的输入像素( 1 × 1 × Cx)在内存中已经是顺序的,因此该步骤对于1 × 1卷积是不执行的。然后,核的线性部分矩阵乘法( MatMul )将当前的一维向量与层的权重参数进行卷积,利用RI5CY SIMD指令实现方程的整数部分。
在QNN部署的情况下,一个平铺策略包括对第3.1节中提到的数据张量进行常规的软件管理的分片,i )在可用内存内进行拟合,ii )在各个层次之间透明地移动数据,使用下一个平铺的双缓冲和DMA,并在当前平铺上进行计算。在这项工作中,我们的目标是一个具有三层内存层次结构的硬件架构:一个几乎无限大小的片外L3;片上L2内存均衡大小(例如, 256 k B到几个MB)和带宽;而片上L1对计算单元的带宽几乎是无限的,但大小有限,为(通常< 128kB)。如果我们考虑DNN中的卷积层,一般来说,输入、输出和权重都应该平铺以满足内存约束
面向内存的部署
DORY的目标是存储层次中具有三级( L3、L2、L1)的计算节点。它支持权重和激活的L3 - L2和L2 - L1拼接。在L3 ( > 512kB)中存储权重对于大多数非平凡网络的部署是必不可少的,如[ 30 ],[ 31 ]。另一方面,激活拼接通常只对工作在具有大空间维度的高分辨率图像上的网络是必要的,这在边缘计算领域是罕见的。DORY的运行分为三个步骤,在网络部署之前离线执行。首先,ONNX解码器使用开放神经网络交换( ONNX格式)接收作为输入的QNN图。
结果
在这一部分中,我们使用GWT GAP - 8作为我们探索的目标平台,并使用我们扩展的PULP - NN库作为后端,在单层和全网络上评估了DORY的结果质量(性能和能量效率)。我们还将我们的结果与使用STM XCUBE - AI的STM32 - H743 MCU以及使用专有的AutoTiler工具在相同的GAP - 8平台上得到的结果进行了比较。单层的结果是指3.1节定义的一个完整的8位QNN层,包括Linear、Batch - Normalization和Quantization / Activation子层。我们在目标函数中设置α为0.5,βHIDE _ IM2COL为102,其他β i为106。
观察几种效应。对于逐点层,大致所有的时间都在Mat Mul (其中大部分是纯MAC操作)的最内层循环中度过;其余部分是由于构建了Im2Col buffer,Norm / Qnt和MatMul循环,覆盖了SIMD遗留案例(例如, Ct y不是向量大小的倍数4)。在深度层的情况下,后一类循环主导了后端执行时间。对于DORY产生的Tiling带来的开销,我们观察到Cluster DMA不会损害逐点卷积层,因为它们是受计算限制的的并且是高效流水线的:此外,多次调用Cluster DMA的处理开销在集群中的8个核心上是并行的,降低了实现复杂Tiling方案的成本。

它使用非常通用的API,不需要进行深度优化。在同一平台上,XCUBE - AI的性能优于XCUBE - AI 6.1 × ~ 12.7 ×,这得益于其更高效的后端。尽管如此,DORY为GAP - 8平台生成的图层在MAC / cycle上比TFLite Micro和X - CUBE - AI都高出2.9 ×到229.6 ×。这一显著优势得益于GAP - 8 (多核加速, DSP指令增强)的建筑优势,如上一节所示,DORY可以通过PULP - NN充分利用这一优势。在第6.1节中,我们将DORY的性能增强和架构优势解耦,以强调我们框架的优势,在STM32H7和GAP8上部署DORY层,并强制使其在单核上运行。
与针对同一平台的GWT AutoTiler相比,DORY在点卷积中的速度快1.6倍,而在深度卷积中的速度则慢1.9倍。这些差异主要体现在各自后端工具所遵循的不同策略上,将在第6.1节进行深入讨论。正如3.2节所述,输出通道的数量对性能有很大的影响,因为为更多的输出通道复用输入数据可以抵消Im2Col操作的成本。对于深度卷积,每个输入通道都与单个输出通道相连:因此,这种数据重用的来源是不可用的。
我们关注DORY在部署全网络中的性能,这些全网络已经被用作许多面向边的工作的基准[ 34 ]。所有的网络都在GWT GAP - 8上运行,验证了所有的中间结果以及最终的端到端运行结果,并与QNNs的基于PyTorch的位精确黄金模型[ 40 ]进行了比较,以确认DORY框架和PULP - NN后端的正确功能。
在这里,我们讨论了新的DORY核库对PULP - NN核[ 14 ] ( HWC布局)和Greenwaves核库( CHW布局)的改进。在图9中,我们展示了不同层上的比较,代表了普通卷积和深度卷积。在经典卷积上,我们的方法比CHW布局快2.5倍。正如4.3节所讨论的,DORY库包含了一个优化的深度层次,减少了在执行过程中使用HWC布局的代价。在深度方向的层上使用HWC布局,如果与CHW布局相比,可以导致高达3.7倍的减慢,这将严重影响这些层的性能。我们将这一损失降低了2倍:我们的内核比HWC内核快1.5 × / 2.0 ×,达到了Greenwaves内核性能的0.54 ×。
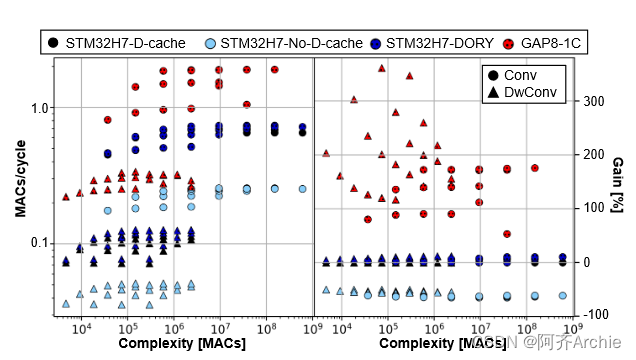
结果如图所示。首先,由于预期的性能下降,STM32上的D - Cache急剧失活:在所有的基准层中,我们观察到相对于基线的降级为58.5 ± 5.5 %。更有趣的是,我们的结果还表明,DORY在DTCM上实现的软件缓存机制可以平均达到与D - Cache相同的性能,在某些情况下有轻微的加速:平均9.1 ± 2.1 % (深度方向)和3.9 ± 3.8 % (普通卷积)。另一方面,在GAP - 8上的单核执行在cycle / cycle方面相对于STM32H7基线平均有2.5 ± 0.9 ×的加速比。由于本测试中多核执行被禁用,因此主要参考GAP8相对于STM32H7所实现的加速
原文与源码下载链接
https://download.csdn.net/download/m0_61712829/89053141![]() https://download.csdn.net/download/m0_61712829/89053141
https://download.csdn.net/download/m0_61712829/89053141
REFERENCES
[1] M. S. Mahdavinejad, M. Rezvan, M. Barekatain, P. Adibi, P. Barnaghi, and A. P. Sheth, “Machine learning for internet of things data analysis: a survey,” Digital Communications and Networks, vol. 4, no. 3, pp. 161 – 175, 2018.
[2] N. H. Motlagh, M. Bagaa, and T. Taleb, “UAV-based IoT platform: A crowd surveillance use case,” IEEE Communications Magazine, vol. 55, no. 2, pp. 128–134, 2017.
[3] M. Zanghieri, S. Benatti, A. Burrello, V. Kartsch, F. Conti, and L. Benini, “Robust Real-Time Embedded EMG Recognition Framework Using Temporal Convolutional Networks on a Multicore IoT Processor,” IEEE Transactions on Biomedical Circuits and Systems, 2019.
[4] O. Elijah, T. A. Rahman, I. Orikumhi, C. Y. Leow, and M. N. Hindia, “An overview of Internet of Things (IoT) and data analytics in agriculture: Benefits and challenges,” IEEE Internet of Things Journal, vol. 5, no. 5, pp. 3758–3773, 2018.
[5] D. Palossi, A. Loquercio, F. Conti, E. Flamand, D. Scaramuzza, and L. Benini, “A 64mW DNN-based Visual Navigation Engine for Autonomous Nano-Drones,” IEEE Internet of Things Journal, 2019.
[6] F. Conti, R. Schilling, P. D. Schiavone, A. Pullini, D. Rossi, F. K. G ̈ urkaynak, M. Muehlberghuber, M. Gautschi, I. Loi, G. Haugou et al., “An IoT Endpoint System-on-Chip for Secure and EnergyEfficient Near-Sensor Analytics,” IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 64, no. 9, pp. 2481–2494, 2017.
[7] F. Conti, M. Rusci, and L. Benini, “The Memory Challenge in UltraLow Power Deep Learning,” in NANO-CHIPS 2030. Springer, 2020, pp. 323–349.
[8] H. Gao, W. Tao, D. Wen, T.-W. Chen, K. Osa, and M. Kato, “Ifqnet: Integrated fixed-point quantization networks for embedded vision,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2018, pp. 607–615.
[9] Y. Chen, J. Emer, and V. Sze, “Eyeriss: A Spatial Architecture for Energy-Efficient Dataflow for Convolutional Neural Networks,” in 2016 ACM/IEEE 43rd Annual International Symposium on Computer Architecture (ISCA), 2016, pp. 367–379
[10]Alessio Burrello,Angelo Garofalo,Nazareno Bruschi,et al.DORY: Automatic End-to-End Deployment of Real-World DNNs on Low-Cost IoT MCUs[Z].arxiv,2021.
相关文章:
在低成本loT mcu上实现深度神经网络端到端自动部署-深度神经网络、物联网、边缘计算、DNN加速——文末完整资料
目录 前言 DNN 量化神经网络 并行超低功耗计算范式 面向内存的部署 结果 原文与源码下载链接 REFERENCES 前言 在物联网极端边缘的终端节点上部署深度神经网络( Deep Neural Networks,DNNs )是支持普适深度学习增强应用的关键手段。基于低成本MCU的终端节点…...
【linux】基础IO |文件操作符
需要掌握:操作文件,本质:进程操作文件。进程和文件的关系 向文件中写入,本质上向硬件中写入->用户没有权利直接写入->操作系统是硬件的管理者,我们可以通过操作系统往硬件写入->操作系统必须提供系统调用&…...

探索 2024 年 Web 开发最佳前端框架
前端框架通过简化和结构化的网站开发过程改变了 Web 开发人员设计和实现用户界面的方法。随着 Web 应用程序变得越来越复杂,交互和动画功能越来越多,这是开发前端框架的初衷之一。 在网络的早期,网页相当简单。它们主要以静态 HTML 为特色&a…...

解决: MAC ERROR [internal] load metadata for docker.io/library/openjdk:17
错误信息: ERROR [internal] load metadata for docker.io/library/openjdk:17 ERROR: failed to solve: openjdk:17: error getting credentials - err: exit status 1, out: 解决方法: running this command rm ~/.docker/config.json before …...
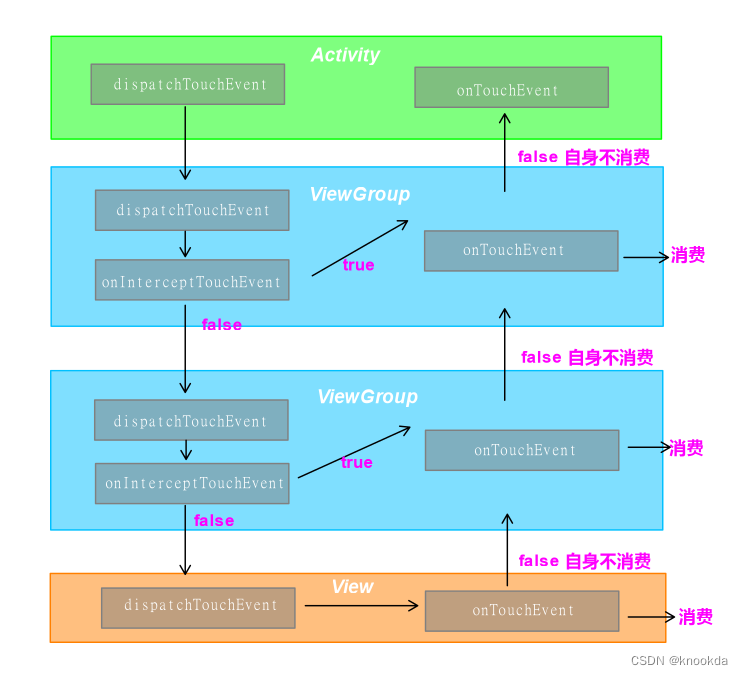
View事件分发
MotionEvent 1.简介 MotionEvent 是Android系统中一个非常重要的类,它代表了屏幕上发生的触摸事件。当用户在屏幕上触摸、滑动或者长按时,都会生成一个MotionEvent对象,这个对象包含了触摸动作的各种信息。 2.事件类型 ACTION_DOWN&#x…...

监听页面的使用时间
如果是比较新的vue架构(推荐,参考若依) 监听create()和destory()两个函数,写通用的js调用函数,在路由守卫的时候使用,就可以获取到每个页面停留时间 如果是比…...

【 yolo红外微小无人机-直升机-飞机-飞鸟目标检测】
yolo无人机-直升机-飞机-飞鸟目标检测 1. 小型旋翼无人机目标检测2. yolo红外微小无人机-直升机-飞机-飞鸟目标检测3. yolo细分类型飞机-鸟类-无人机检测4. yolo红外大尺度无人机检测5. 小型固定翼无人机检测6. 大型固定翼无人机检测7. yolo航空俯视场景下机场飞机检测 1. 小型…...
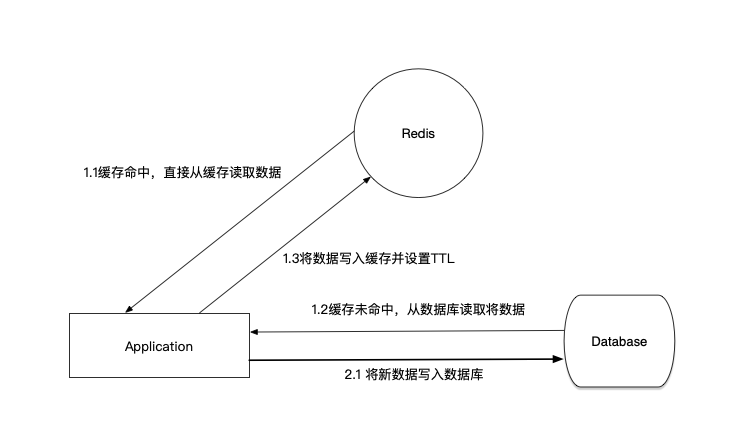
Redis与数据库的一致性
Redis与数据库的数据一致性 在使用Redis作为应用缓存来提高数据的读性能时,经常会遇到Redis与数据库的数据一致性问题。简单来说,就是同一份数据同时存在于Redis和数据库,如何在数据更新的时候,保证两边数据的一致性。首先&#…...

使用maxwell实时同步mysql数据到kafka
一、软件环境: 操作系统:CentOS release 6.5 (Final) java版本: jdk1.8 zookeeper版本: zookeeper-3.4.11 kafka 版本: kafka_2.11-1.1.0.tgz maxwell版本:maxwell-1.16.0.tar.gz 注意 : 关闭所有机器的防火墙,同时注意…...

知识图谱与大数据:区别、联系与应用
目录 前言1 知识图谱1.1 定义1.2 特点1.3 应用 2 大数据2.1 定义2.2 应用 3. 区别与联系3.1 区别3.2 联系 结语 前言 在当今信息爆炸的时代,数据成为了我们生活和工作中不可或缺的资源。知识图谱和大数据是两个关键概念,它们在人工智能、数据科学和信息…...

Nagios工具
一 nagios 相关概念 Nagios 是一款开源的免费网络监视工具,能有效监控 Windows、Linux 和 Unix 的主机状态,交换机路由器等网络设置,打印机等。在系统或服务状态异常时发出邮件或短信报警第 一时间通知网站运维人员,在状态恢复后…...

微信小程序全局数据共享
文章目录 安装MobX相关的包根目录创建store文件夹,添加store.js文件绑定到页面中绑定到组件 mobx-miniprogram和mobx-miniprogram-bindings实现全局数据共享 mobx-miniprogram用来创建Store实例对象 mobx-miniprogram-bindings用来把Store中的共享数据或方法&…...

算法训练营第24天|回溯算法理论基础 LeetCode 77.组合
终于把二叉树做完了!开始新的篇章,回溯! 回溯算法理论基础 回溯算法题目分类: 1.组合 2.分割 3.子集 4.排列 5.棋盘问题 什么是回溯? 回溯叫做回溯搜索法,是一种搜索方式。回溯是递归的副产品&…...

pip永久修改镜像地址
修改命令: pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/ 效果: 会在C:\Users\PC(用户名)\AppData\Roaming\pip目录下新增或修改文件pip.ini 文件内容: [global] index-url https://pypi.tuna.tsinghua.e…...
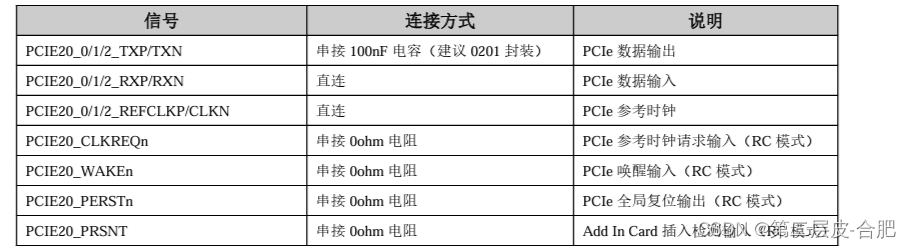
RK3588平台开发系列讲解(硬件篇-功能外设2)
USB2.0/USB3.0 电路 RK3588 芯片内置两个USB3.0 OTG控制器(内嵌2个USB2.0 OTG,下图绿色处),1个USB3.0 HOST 控制器,2个USB2.0 HOST控制器。 这些控制器与PHY的内部复用图如下: USB3.0 OTG0 控制器支持SS/H…...
SpringBoot学习记录
SpringBoot是用于加速Spring开发的。 我们先来看看如何使用SpringBoot来创建一个基于Web的程序,可以发现相较于SpringMVC其有巨大改变。 3.开发控制器类 GetMapping("/{id}")public String getById(PathVariable Integer id){System.out.println("…...
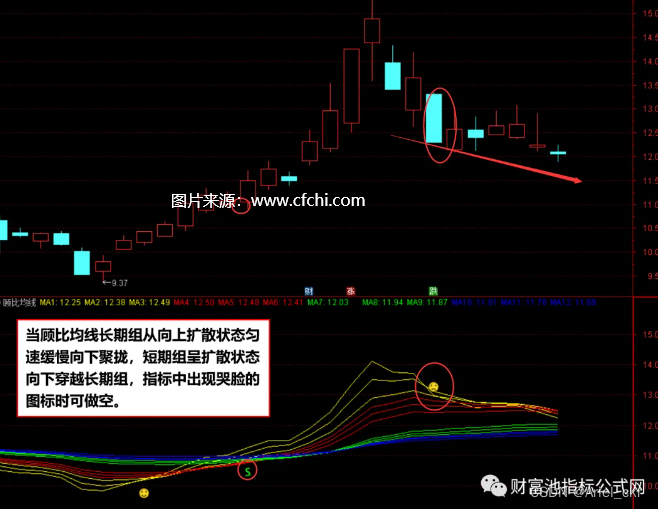
财富池指标--通达信顾比均线实战指标免费源码
顾比均线是由两组均线构成,短期组为3、5、8、10、12、15。长期组为:30、35、40、45、50、60。顾比均线由澳大利亚的投资家戴若-顾比先生发明,因此叫顾比线。 顾比均线可以广泛运用于股票、期货和外汇交易中,只要是能运用K线图的投…...
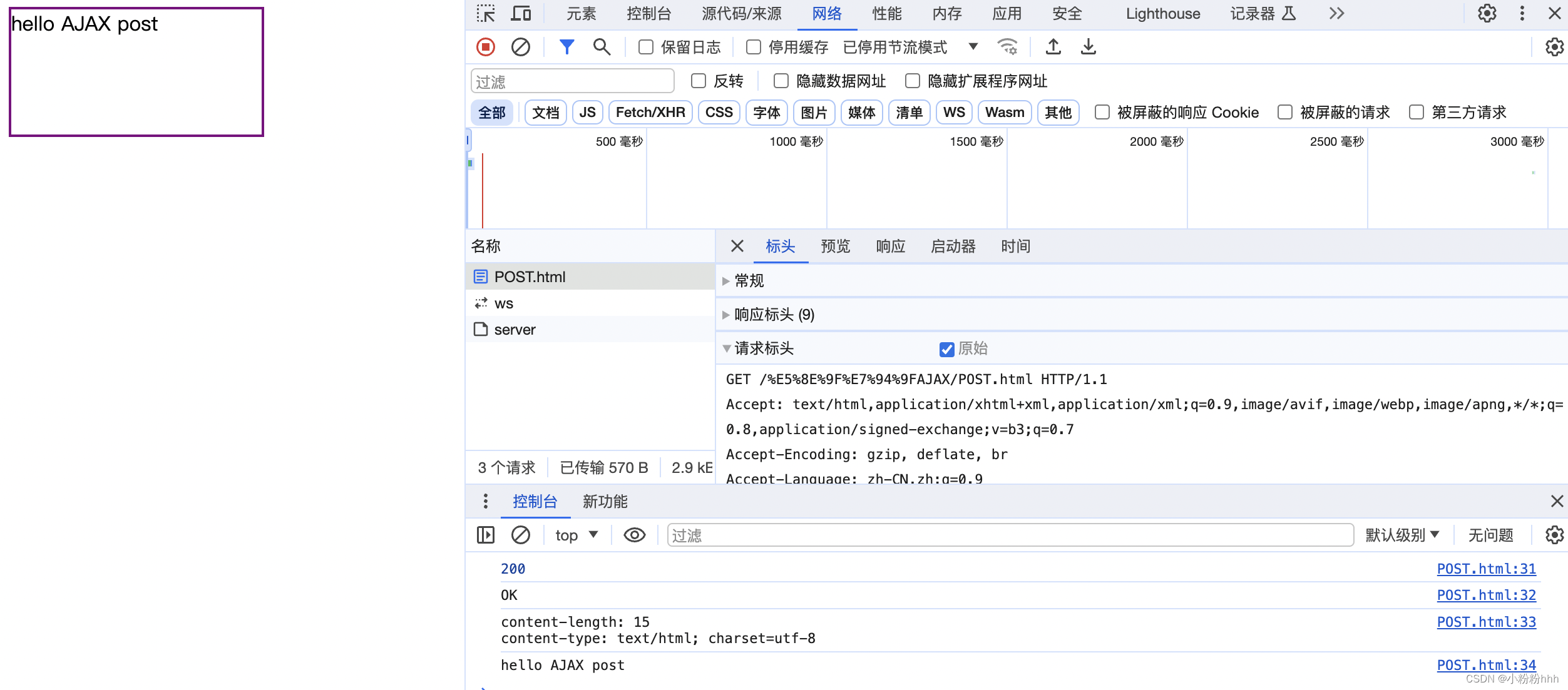
AJAX(一):初识AJAX、http协议、配置环境、发送AJAX请求、请求时的问题
一、什么是AJAX 1.AJAX 就是异步的JS和XML。通过AJAX 可以在浏览器中向服务器发送异步请求,最大的优势:无刷新获取数据。AJAX 不是新的编程语言,而是一种将现有的标准组合在一起使用的新方式。 2.XML 可扩展标记语言。XML被设计用来传输和…...

idea常用的快捷键总结:
idea常用的快捷键总结: Ctrl相关的: Ctrl F 在当前文件进行文本查找 (必备) Ctrl R 在当前文件进行文本替换 (必备) Ctrl Z 撤销 (必备) Ctrl Y 删除光标所在行 或 删除选中的…...

LeetCode 热题 100 题解(一):哈希部分
《LeetCode热题 100》 经过了两个多月,终于刷完了代码随想录的题目,现在准备开始挑战热题一百了,接下来我会将自己的题解以博客的形式同步发到力扣和 c 站,希望在接下来的征程中与大家共勉! 题组一:哈希 题…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

mac 安装homebrew (nvm 及git)
mac 安装nvm 及git 万恶之源 mac 安装这些东西离不开Xcode。及homebrew 一、先说安装git步骤 通用: 方法一:使用 Homebrew 安装 Git(推荐) 步骤如下:打开终端(Terminal.app) 1.安装 Homebrew…...
)
GitHub 趋势日报 (2025年06月06日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 590 cognee 551 onlook 399 project-based-learning 348 build-your-own-x 320 ne…...

Git 3天2K星标:Datawhale 的 Happy-LLM 项目介绍(附教程)
引言 在人工智能飞速发展的今天,大语言模型(Large Language Models, LLMs)已成为技术领域的焦点。从智能写作到代码生成,LLM 的应用场景不断扩展,深刻改变了我们的工作和生活方式。然而,理解这些模型的内部…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...