大语言模型(LLM)token解读
1. 什么是token?
人们经常在谈论大模型时候,经常会谈到模型很大,我们也常常会看到一种说法:
参数会让我们了解神经网络的结构有多复杂,而token的大小会让我们知道有多少数据用于训练参数。
什么是token?比较官方的token解释:
Token是对输入文本进行分割和编码时的最小单位。它可以是单词、子词、字符或其他形式的文本片段。
看完是不是一脸懵逼?为此我们先补充点知识。
2. 大模型工作原理
本质上就是神经网络。但是训练这么大的神经网络,肯定不能是监督学习,如果使用监督学习,必然需要大量的人类标记数据,这几乎是不可能的。那么,如何学习?
当然,可以不用标记数据,直接训练,这种学习方法称为自监督学习。引用学术点的描述:
自监督学习主要是利用辅助任务(pretext)从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息训练模型,从而学习到对下游任务有价值的表征。
自监督学习无标签数据和辅助信息,这是定义自监督学习的两个关键依据。它会通过构造辅助任务来获取监督信息,这个过程中有学习到新的知识;而无监督学习不会从数据中挖掘新任务的标签信息。
例如,在英语考试中,通过刷题可以提高自己的能力,其中的选项就相当于标签。当然,也可以通过听英文音频、阅读英文文章、进行英文对话交流等方式来间接提高英语水平,这些都可以视为辅助性任务(pretext),而这些数据本身并不包含标签信息。
那么,GPT是如何在人类的文本数据上实现自监督学习的呢?那就是用文本的前文来预测后文。
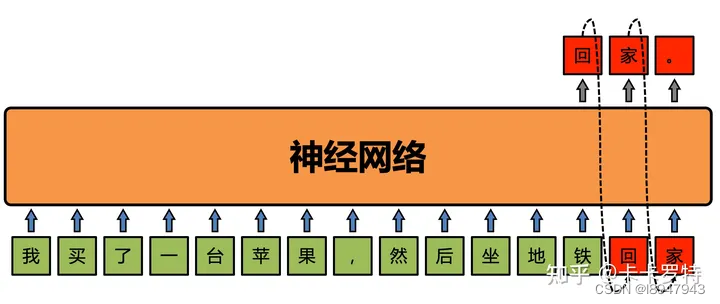
此处引用知乎大佬的案例,例如在下面这段文本中:
我买了一台苹果,然后坐地铁回家。
GPT 模型会将回家两个字掩盖住。将我买了一台苹果,然后坐地铁视为数据,将回家。视为待预测的内容。 GPT 要做的就是根据前文我买了一台苹果,然后坐地铁来预测后文回家。
这个过程依靠神经网络进行,简单操作过程如图:
3. 谈谈语言模型中的token
GPT 不是适用于某一门语言的大型语言模型,它适用于几乎所有流行的自然语言。所以这告诉我们 GPT 实际的输入和输出并不是像上面那个图中那个样子。计算机要有通用适配或者理解能力,因此,我们需要引入 token 的概念。token 是自然语言处理的最细粒度。简单点说就是,GPT 的输入是一个个的 token,输出也是一个个的 token。
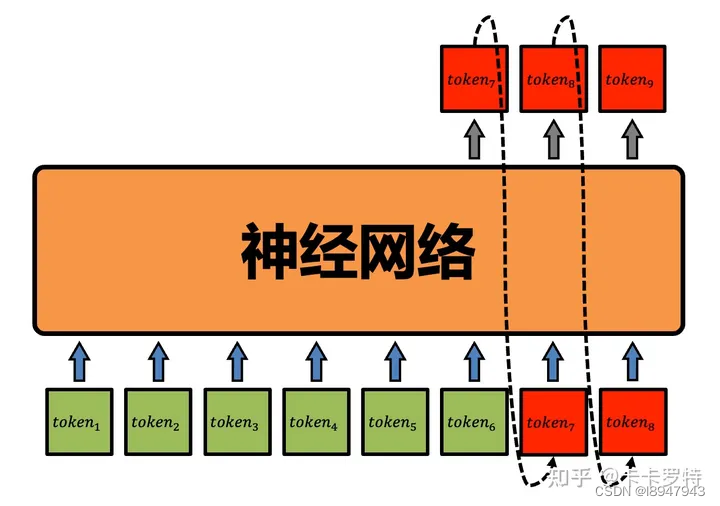
GPT 不是适用于某一门语言的大型语言模型,它适用于几乎所有流行的自然语言。所以 GPT 的 token 需要兼容几乎人类的所有自然语言,那意味着 GPT 有一个非常全的 token 词汇表,它能表达出所有人类的自然语言。如何实现这个目的呢?
答案是通过 unicode 编码。
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。
例如,我们在输入你,对应的unicode 编码为:\u4f60,转换成16进制为0100 1111 0110 0000,转换成10进制对应20320。直接将 unicode 的编码作为 GPT 中 token 的词表,会存在一些问题。 一方面直接使用 unicode 作为词汇表太大了,另一方面 unicode 自身的粒度有时候太细了,例如 unicode 中的英文编码是以字母粒度进行的。
于是我们会将 unicode 的2进制结果以8个二进制位为单位进行拆分。用0100 1111和0110 0000表示你8个二进制位只有256种可能,换句话说,只需要256个 token 的词汇表就能表示所有 unicode。
然而这种方法的词汇表又太小了,编码方法太粗糙了。实际上 GPT 是使用一种称为 BPE (Byte Pair Encoding)的算法,在上面的基础上进一步生成更大的词汇表。
它的基本思想如下,将上述的基础 token (256种可能)做组合,然后统计文本数据中这些组合出现的频率,将频率最大的那些保留下来,形成新的 token 词汇表。因此,通过此方法得到的 token 和文字的映射不一定是一对一的关系。

4.再深入理解一下什么是token
Token是LLM处理文本数据的基石,它们是将自然语言转换成机器可理解格式的关键步骤。几个基本概念:
- 标记化过程(Tokenization):这是将自然语言文本分解成token的过程。在这个过程中,文本被分割成小片段,每个片段是一个token,它可以代表一个词、一个字符或一个词组等。
- 变体形式:根据不同的标记化方案,一个token可以是一个单词,单词的一部分(如子词),甚至是一个字符。例如,单词"transformer"可能被分成"trans-", “form-”, "er"等几个子词token。
- 模型模型限制:大型语言模型通常有输入输出token数量的限制,比如2K、4K或最多32K token。这是因为基于Transformer的模型其计算复杂度和空间复杂度随序列长度的增长而呈二次方增长,这限制了模型能够有效处理的文本长度。
- token可以作为数值标识符:Token在LLM内部被赋予数值或标识符,并以序列的形式输入或从模型输出。这些数值标识符是模型处理和生成文本时实际使用的表示形式,说白了可以理解成一种索引,索引本身又是一种标识符。
5. 为什么token会有长度限制?
有以下3方面的相互制约:文本长短、注意力、算力,这3方面不可能同时满足。也就是说:上下文文本越长,越难聚焦充分注意力,难以完整理解;注意力限制下,短文本无法完整解读复杂信息;处理长文本需要大量算力,从而提高了成本。(这是因为GPT底层基于Transformer的模型,Transformer模型的Attention机制会导致计算量会随着上下文长度的增加呈平方级增长)
参考
- 自监督学习(Self-supervised Learning)
- ChatGPT实用指南(一)
- 大型语言模型(LLM)中的token
- LLM 大模型为什么会有上下文 tokens 的限制?
相关文章:
大语言模型(LLM)token解读
1. 什么是token? 人们经常在谈论大模型时候,经常会谈到模型很大,我们也常常会看到一种说法: 参数会让我们了解神经网络的结构有多复杂,而token的大小会让我们知道有多少数据用于训练参数。 什么是token?比…...
【Micro 2014】NoC Architectures for Silicon Interposer Systems
NoC Architectures for Silicon Interposer Systems 背景和动机 硅中介层 主要内容 基于interposer的多核 NOC架构 试验评估 方法 NoC Architectures for Silicon Interposer Systems Natalie Enright Jerger, University of Toronto Gabriel H. Loh AMD Research 硅中介层…...
【文章笔记 + 个人思考】)
《极客时间 - 左耳听风》01 | 程序员如何用技术变现?(上)【文章笔记 + 个人思考】
《极客时间 - 左耳听风》 原文链接 :https://time.geekbang.org/column/intro/100002201?tabcatalog 备注:加粗部分为个人思考 程序员用自己的技术变现是天经地义的事情。写程序是一门手艺活,程序员作为手艺人完全可以不依赖任何公司或者其他…...
Typora结合PicGo + Github搭建个人图床
目录 一 、GitHub仓库设置 1、新建仓库 2、创建Token 并复制保存 二、PicGo客户端配置 1、下载 & 安装 2、配置图床 三、Typora配置 一 、GitHub仓库设置 1、新建仓库 点击主页右上角的 号创建 New repository 填写仓库信息 2、创建Token 并复制保存 点击右上角…...

【JavaWeb】Day27.Web入门——Tomcat介绍
目录 WEB服务器-Tomcat 一.服务器概述 二.Web服务器 三.Tomcat- 基本使用 1.下载 2.安装与卸载 3.启动与关闭 4.常见问题 四.Tomcat- 入门程序 WEB服务器-Tomcat 一.服务器概述 服务器硬件:指的也是计算机,只不过服务器要比我们日常使用的计算…...

怎么更新sd-webui AUTOMATIC1111/stable-diffusion-webui ?
整个工程依靠脚本起来的: 可直接到stable-diffusion-webui子目录执行: git pull更新代码完毕后,删除venv的虚拟环境。 然后再次执行webui.sh,这样会自动重新启动stable-diffusion-webui....
)
Apache Iceberg最新最全面试题及详细参考答案(持续更新)
目录 1. 描述Apache Iceberg的架构设计和它的主要组件? 2. Iceberg如何处理数据的版本控制和时间旅行?...
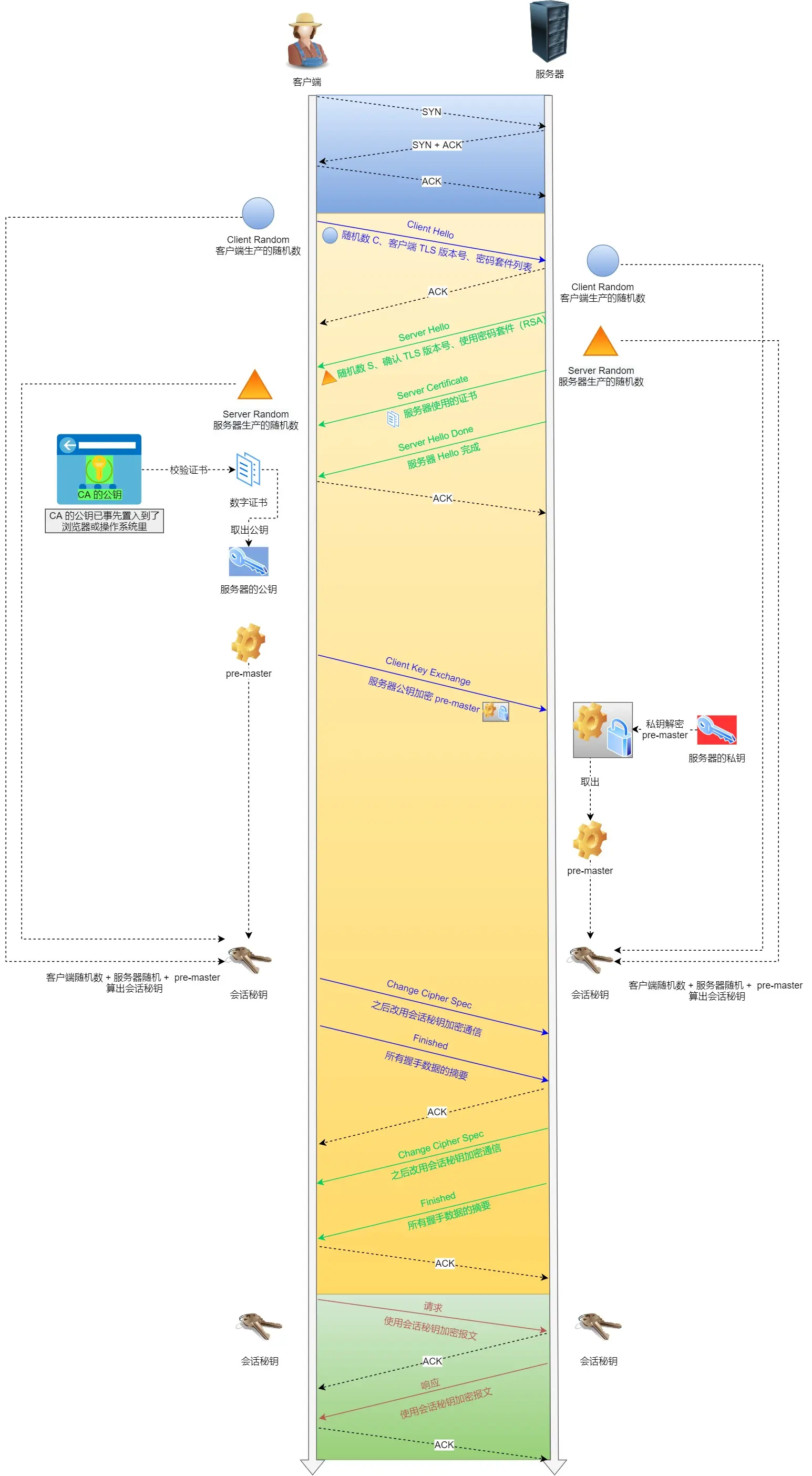
从TCP/IP协议到socket编程详解
我的所有学习笔记:https://github.com/Dusongg/StudyNotes⭐⭐⭐ 文章目录 1 网络基础知识1.1 查看网络信息1.2 认识端口号1.3 UDP1.4 TCP1.4.1 确认应答机制1.4.2 TCP三次握手/四次挥手为什么是三次握手为什么是四次挥手listen 的第二个参数 backlog—— 全…...
uniapp开发小程序遇到的问题,持续更新中
一、uniapp引入全局scss 在App.vue中引入uni.scss <style lang"scss">/* #ifndef APP-NVUE */import "uni.scss";/* #endif */ </style>注意:nvue页面的样式在编译时,有很多样式写法被限制了,容易报错。所…...
)
C++经典面试题目(十一)
1. final和override关键字 在C中,final 和 override 是两个用于类继承和成员函数重写的关键字,它们主要在面向对象编程的上下文中使用,以增强代码的可读性和安全性。 1. final 关键字 final 关键字主要有两种用法: 用于类&…...
:桥接模式)
设计模式(6):桥接模式
一.桥接模式核心要点 处理多层继承结构,处理多维度变化的场景,将各个维度设计成独立的继承结构,使各个维度可以独立的扩展在抽象层建立关系。 \color{red}{处理多层继承结构,处理多维度变化的场景,将各个维度设计成独立…...

Java切面编程
1.切面编程 无需改变原有类的情况下对业务功能实现扩展或增强。 2.目前最流行的AOP框架有两个,分别为Spring AOP 和 AspectJ。 3.Spring AOP使用纯java实现,不需要专门的编译过程和类加载器,在运行期间通过代理方式向目标类织入增强的代码。 …...
微服务demo(二)nacos服务注册与集中配置
环境:nacos1.3.0 一、服务注册 1、pom: 移步spring官网https://spring.io,查看集成Nacos所需依赖 找到对应版本点击进入查看集成说明 然后再里面找到集成配置样例,这里只截一张,其他集成内容继续向下找 我的&#x…...

面试题库二
1、简述TCP/IP的三次握手和四次挥手 TCP(Transmission Control Protocol)是一种可靠的、面向连接的传输层协议,用于在网络中传输数据。在建立连接和断开连接时,TCP 使用了三次握手和四次挥手来确保通信的可靠性和正确性。 三次握手…...
HarmonyOS实战开发-如何实现一个简单的电子相册应用开发
介绍 本篇Codelab介绍了如何实现一个简单的电子相册应用的开发,主要功能包括: 实现首页顶部的轮播效果。实现页面跳转时共享元素的转场动画效果。实现通过手势控制图片的放大、缩小、左右滑动查看细节等效果。 相关概念 Swiper:滑块视图容…...

FFmpeg将绿幕视频处理成透明视频播放
怎么在网页端插入透明视频呢,之前在做Web3D项目时,使用threejs可以使绿幕视频透明显示在三维场景中,但是在网页端怎么让绿幕视频透明显示呢? 如图上图,视频背景遮挡住后面网页内容 想要如下图效果 之前有使用过ffmpeg…...

【2024系统架构设计】案例分析- 4 嵌入式
目录 一 基础知识 二 真题 一 基础知识 1 基本概念 ◆系统可靠性是系统在规定的时间内及规定的环境条件下,完成规定功能的能力,也就是系统无故障运行的概率。或者,可靠性是软件系统在应用或系统错误面前,在意外或错误使用的情况下维持软件系统的功能特性的基本能力。...
基于javaweb(springboot+mybatis)生活美食分享平台管理系统设计和实现以及文档报告
基于javaweb(springbootmybatis)生活美食分享平台管理系统设计和实现以及文档报告 博主介绍:多年java开发经验,专注Java开发、定制、远程、文档编写指导等,csdn特邀作者、专注于Java技术领域 作者主页 央顺技术团队 Java毕设项目精品实战案例《1000套》 …...

【MySQL探索之旅】MySQL数据表的增删查改——约束
📚博客主页:爱敲代码的小杨. ✨专栏:《Java SE语法》 | 《数据结构与算法》 | 《C生万物》 《MySQL探索之旅》 |《Web世界探险家》 ❤️感谢大家点赞👍🏻收藏⭐评论✍🏻,您的三连就是我持续更…...
【Linux】体验一款开源的Linux服务器运维管理工具
今天为大家介绍一款开源的 Linux 服务器运维管理工具 - 1panel。 一、安装 根据官方那个提供的在线文档,这款工具的安装需要执行在线安装, # Redhat / CentOScurl -sSL https://resource.fit2cloud.com/1panel/package/quick_start.sh -o quick_start…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

NineData数据库DevOps功能全面支持百度智能云向量数据库 VectorDB,助力企业 AI 应用高效落地
NineData 的数据库 DevOps 解决方案已完成对百度智能云向量数据库 VectorDB 的全链路适配,成为国内首批提供 VectorDB 原生操作能力的服务商。此次合作聚焦 AI 开发核心场景,通过标准化 SQL 工作台与细粒度权限管控两大能力,助力企业安全高效…...

【Axure高保真原型】图片列表添加和删除图片
今天和大家分享图片列表添加和删除图片的原型模板,效果包括: 点击图片列表的加号可以显示图片选择器,选择里面的图片; 选择图片后点击添加按钮,可以将该图片添加到图片列表; 鼠标移入图片列表的图片&…...

Unity VR/MR开发-开发环境准备
视频讲解链接: 【XR马斯维】UnityVR/MR开发环境准备【UnityVR/MR开发教程--入门】_哔哩哔哩_bilibili...

Java严格模式withResolverStyle解析日期错误及解决方案
在Java中使用DateTimeFormatter并启用严格模式(ResolverStyle.STRICT)时,解析日期字符串"2025-06-01"报错的根本原因是:模式字符串中的年份格式yyyy被解释为YearOfEra(纪元年份),而非…...
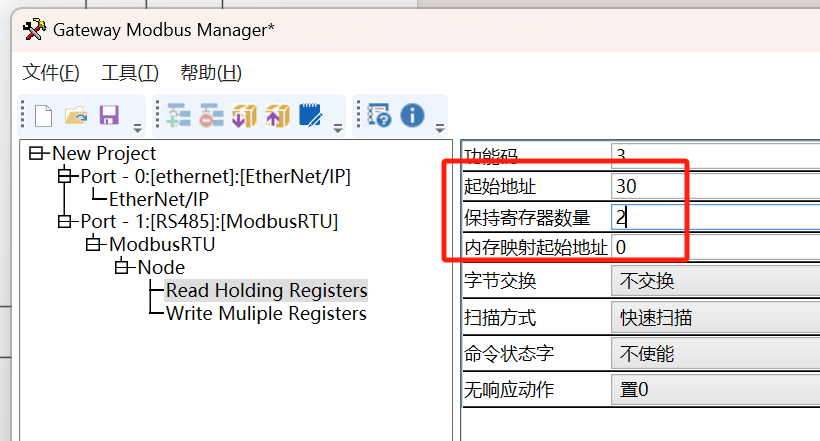
开疆智能Ethernet/IP转Modbus网关连接斯巴拓压力传感器配置案例
本案例是将ModbusRTU协议的压力传感器数据上传到欧姆龙PLC,由于PLC采用的是Ethernet/IP通讯协议,两者无法直接进行数据采集。故使用开疆智能研发的Ethernet转Modbus网关进行数据转换。 配置过程 首先我们开始配置Ethernet/IP主站(如罗克韦尔…...
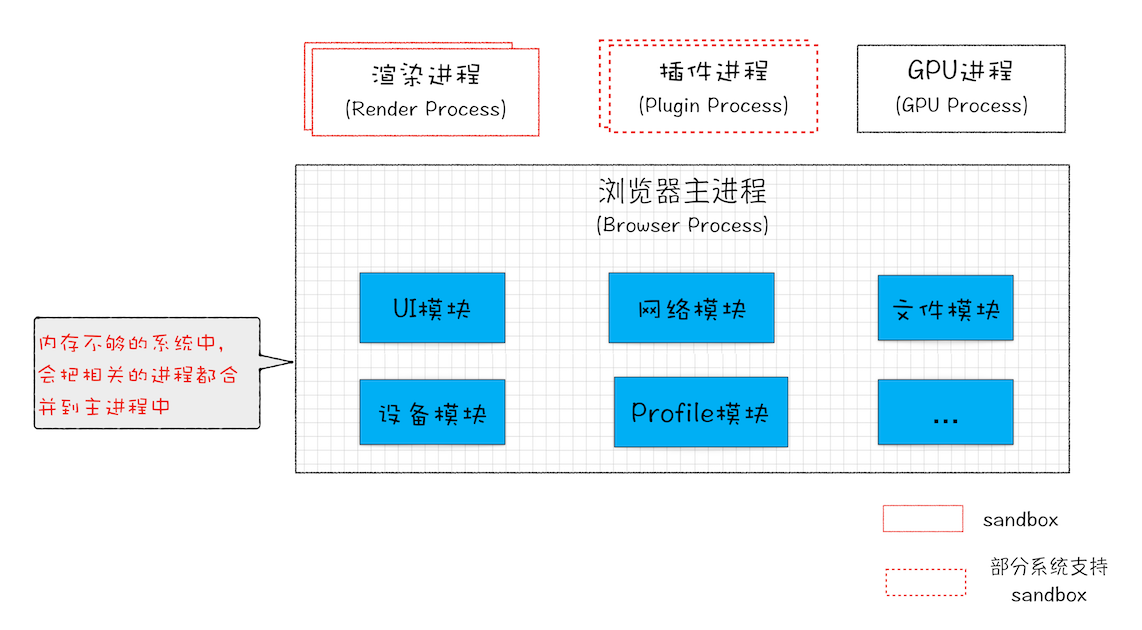
浏览器工作原理01 [#]Chrome架构:仅仅打开了1个页面,为什么有4个进程
引用 浏览器工作原理与实践 Chrome打开一个页面需要启动多少进程?你可以点击Chrome浏览器右上角的“选项”菜单,选择“更多工具”子菜单,点击“任务管理器”,这将打开Chrome的任务管理器的窗口,如下图 和Windows任务管…...

民锋视角下的资金流效率与账户行为建模
民锋视角下的资金流效率与账户行为建模 在当前复杂多变的金融环境中,资金流效率已成为衡量一家金融服务机构专业能力的重要指标。民锋在账户管理与资金调配的实战经验中,逐步建立起一套以资金流路径为核心的行为建模方法,用以评估客户行为、交…...