pytorch常用的模块函数汇总(1)
目录
torch:核心库,包含张量操作、数学函数等基本功能
torch.nn:神经网络模块,包括各种层、损失函数和优化器等
torch.optim:优化算法模块,提供了各种优化器,如随机梯度下降 (SGD)、Adam、RMSprop 等。
torch.autograd:自动求导模块,用于计算张量的梯度
torch:核心库,包含张量操作、数学函数等基本功能
torch.tensor(): 创建张量torch.zeros(),torch.ones(): 创建全零或全一张量torch.rand(): 创建随机张量torch.from_numpy(): 从 NumPy 数组创建张量-
torch.add(),torch.sub(),torch.mul(),torch.div(): 加法、减法、乘法、除法 -
torch.mm(),torch.matmul(): 矩阵乘法 -
torch.exp(),torch.log(),torch.sin(),torch.cos(): 指数、对数、正弦、余弦等数学函数 -
torch.index_select(): 按索引选取张量的子集 -
切片操作:类似 Python 中的列表切片操作,如torch.masked_select(): 根据掩码选取张量的子集tensor[2:5] -
torch.view(),torch.reshape(): 改变张量的形状 -
torch.squeeze(),torch.unsqueeze(): 压缩或扩展张量的维度 -
torch.mean(),torch.sum(),torch.max(),torch.min(): 计算张量均值、和、最大值、最小值等 -
torch.broadcast_tensors(): 对张量进行广播操作 -
torch.cat(): 拼接张量 -
torch.stack(): 堆叠张量 -
torch.split(): 分割张量
torch.nn:神经网络模块,包括各种层、损失函数和优化器等
-
神经网络层:
torch.nn.Linear(in_features, out_features): 全连接层,进行线性变换。torch.nn.Conv2d(in_channels, out_channels, kernel_size): 2D卷积层。torch.nn.MaxPool2d(kernel_size): 2D 最大池化层。torch.nn.ReLU(): ReLU 激活函数。torch.nn.Sigmoid(): Sigmoid 激活函数。torch.nn.Dropout(p): Dropout 层,用于防止过拟合。
备注:Sigmoid 激活函数是一种常用的非线性激活函数,其作用可以总结如下:
将输入映射到 (0, 1) 范围内:输出范围在 0 到 1 之间,可以将任意实数输入映射到 0 到 1 之间。这种特性在某些情况下很有用,比如对于二分类任务,Sigmoid 函数的输出可以被解释为样本属于正类的概率。
引入非线性变换: Sigmoid 函数是一种非线性函数,可以引入神经网络的非线性变换能力,使得神经网络可以学习更加复杂的模式和关系。在深度神经网络中,非线性激活函数的使用可以帮助神经网络学习非线性模式,提高网络的表达能力。
输出平滑且连续: Sigmoid 函数具有平滑的 S 形曲线,在定义域内都是可导的,这使得在反向传播算法中计算梯度变得相对容易。这一点对于神经网络的训练至关重要。
-
损失函数:
torch.nn.CrossEntropyLoss(): 交叉熵损失函数,常用于多分类问题。
交叉熵损失函数用于衡量两个概率分布之间的差异,通常用于多分类任务中。在神经网络的多分类任务中,输入模型的输出是一个概率分布,表示每个类别的预测概率,而交叉熵损失函数则用于比较这个预测概率分布与实际标签的分布之间的差异。
torch.nn.CrossEntropyLoss() 来计算交叉熵损失函数,它会自动将模型的输出通过 Softmax 函数转换为概率分布,并计算交叉熵损失。
torch.nn.MSELoss(): 均方误差损失函数,常用于回归问题。
均方误差损失函数用于衡量模型输出与实际目标之间的差异,通常在回归任务中使用。该损失函数计算预测值与真实值之间的平方差,并将所有样本的平方差求平均得到最终的损失值。
-
优化器:
torch.optim.SGD(model.parameters(), lr=learning_rate): 随机梯度下降优化器。torch.optim.Adam(model.parameters(), lr=learning_rate): Adam 优化器。
-
模型定义相关:
torch.nn.Module: 所有神经网络模型的基类,需要继承这个类。model.forward(input_tensor): 定义前向传播。
-
数据处理相关:
torch.utils.data.Dataset: PyTorch 数据集的基类,需要自定义数据集时使用。torch.utils.data.DataLoader(dataset, batch_size, shuffle): 数据加载器,用于批量加载数据。
-
torch.optim:优化算法模块,提供了各种优化器,如随机梯度下降 (SGD)、Adam、RMSprop 等。
-
优化器(Optimizer)类:
torch.optim.SGD(params, lr=0.01, momentum=0, weight_decay=0):随机梯度下降优化器,实现了带动量的随机梯度下降。torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-8, weight_decay=0):Adam 优化器,结合了动量方法和 RMSProp 方法,通常在深度学习中表现良好。torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0):Adagrad 优化器,自适应地为参数分配学习率。它根据参数的历史梯度信息对每个参数的学习率进行调整。这意味着对于不同的参数,Adagrad可以为其分配不同的学习率,从而更好地适应参数的更新需求torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e-8, weight_decay=0, momentum=0, centered=False):RMSprop 优化器,有效地解决了 Adagrad 学习率下降较快的问题(RMSprop对梯度平方项进行指数加权平均)。
备注:
1.在优化算法中,momentum(动量)是一种用于加速模型训练的技巧。动量项的引入旨在解决标准随机梯度下降在训练过程中可能遇到的震荡和收敛速度慢的问题。
动量项的引入可以帮助优化算法在参数更新时更好地利用之前的更新方向,从而在一定程度上减少参数更新的波动,加快收敛速度,并有助于跳出局部极小值。具体来说,动量项在参数更新时会考虑之前的更新方向,并对当前的更新方向进行一定程度的调整。
在 PyTorch 的 torch.optim.SGD 中,动量可以通过设置 momentum 参数来控制。通常情况下,动量的取值范围在 0 到 1 之间,常见的默认取值为 0.9。当动量设为0.9时,每次迭代,都会保留上一次速度的 90%,并使用当前梯度微调最终的更新方向。
总结来说,动量项的引入可以提高随机梯度下降的稳定性和收敛速度,有助于在训练神经网络时更快地找到较优的解。
2.
在优化算法中,weight decay(权重衰减)是一种用于控制模型参数更新的正则化技术。权重衰减通过在优化过程中对参数进行惩罚,防止其取值过大,从而有助于降低过拟合的风险。
具体来说,在SGD中的weight_decay参数是对模型的权重进行L2正则化,即在计算梯度时额外增加一个关于参数的惩罚项。这个惩罚项会使得优化算法更倾向于选择较小的权重值,从而降低模型的复杂度,减少过拟合的风险。
在PyTorch中,torch.optim.SGD中的weight_decay参数用于控制权重衰减的程度。通常情况下,weight_decay的取值为一个小的正数,比如 0.001 或 0.0001。设置了weight_decay之后,在计算梯度时会额外考虑到权重的惩罚项,从而影响参数的更新方式。
总结来说,权重衰减是一种正则化技术,通过对模型参数的惩罚来控制模型的复杂度,减少过拟合的风险,提高模型的泛化能力。
3.
-
L1正则化:L1正则化会给模型的损失函数添加一个关于权重绝对值的惩罚项,即L1范数(权重的绝对值之和)。在梯度下降过程中,L1正则化会导致部分权重直接变为0,因此可以实现稀疏性,有特征选择的效果。L1正则化倾向于产生稀疏的权重矩阵,可以用于特征选择和降维。
L1正则化的惩罚项是模型权重的L1范数,即权重的绝对值之和。在优化过程中,为了最小化损失函数并减少正则化项的影响,优化算法会尝试将权重调整到较小的值。由于L1正则化的几何形状在坐标轴上拐角处就会与坐标轴相交,这就导致了在坐标轴上许多点都是对称的,因此在这些点上的梯度不唯一。这意味着在这些对称点上,优化算法更有可能将权重调整为0,从而导致稀疏性。
-
L2正则化:L2正则化会给模型的损失函数添加一个关于权重平方的惩罚项,即L2范数的平方(权重的平方和)。在梯度下降过程中,L2正则化会使得权重都变得比较小,但不会直接导致稀疏性。L2正则化对异常值比较敏感,因为它会平方每个权重,使得异常值对损失函数的影响更大。
- 总的来说,L1正则化和L2正则化都是常用的正则化技术,它们在模型训练过程中都有助于控制模型的复杂度,减少过拟合的风险。选择使用哪种正则化方法通常取决于具体的问题和数据特点,以及对模型稀疏性的需求。在实际应用中,有时也会将L1和L2正则化结合起来,形成弹性网络正则化(Elastic Net regularization),以兼顾两种正则化方法的优势。
4.
betas 是 Adam 算法中的两个超参数之一,它控制了梯度的一阶矩估计和二阶矩估计的指数衰减率。betas 是一个长度为2的元组,通常形式为 (beta1, beta2)。在 Adam 算法中,beta1 控制了一阶矩估计(梯度的均值)的衰减率,beta2 控制了二阶矩估计(梯度的平方的均值)的衰减率。
通常情况下,beta1 的默认值为 0.9,beta2 的默认值为 0.999。这意味着在每次迭代中,一阶矩估计将保留当前梯度的 90%,而二阶矩估计将保留当前梯度的平方的 99.9%。这些衰减率的选择使得 Adam 算法能够在训练过程中自适应地调整学习率,并对梯度的变化做出快速或缓慢的响应,从而更有效地更新模型参数。
总之,betas 参数在 Adam 算法中起着调节梯度一阶和二阶矩估计衰减率的作用,通过合理设置 betas 可以影响算法的收敛性和稳定性。
-
调整学习率的函数:
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda):根据给定的函数lr_lambda调整学习率。torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1):每个step_size个 epoch 将学习率降低为原来的gamma倍。torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1):在指定的里程碑上将学习率降低为原来的gamma倍。
-
其他常用函数:
zero_grad():用于将模型参数的梯度清零,通常在每个 batch 后调用。step(closure):用于执行单步优化器的更新,需要传入一个闭包函数closure。state_dict()和load_state_dict():用于保存和加载优化器的状态字典,方便恢复训练。
-
torch.autograd:自动求导模块,用于计算张量的梯度

相关文章:
pytorch常用的模块函数汇总(1)
目录 torch:核心库,包含张量操作、数学函数等基本功能 torch.nn:神经网络模块,包括各种层、损失函数和优化器等 torch.optim:优化算法模块,提供了各种优化器,如随机梯度下降 (SGD)、Adam、RMS…...
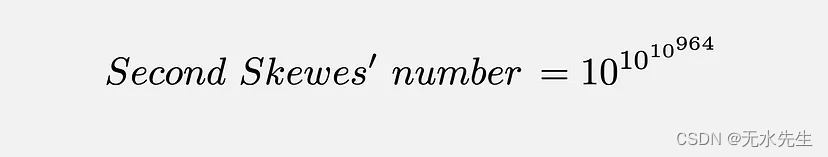
素数的计数律:Π函数、歪斜数
相当多的数字! 一、说明 自从人类开始掌握最起码的算术概念以来,有一类数字一直处于最前沿——素数。素数定义简单,但难以捕捉,众所周知,素数是数学中一些最困难问题的罪魁祸首,让几代最优秀的数学家感到…...

图像识别在农业领域的应用
图像识别技术在农业领域的应用正在逐渐成熟,它通过分析处理拍摄的植物或农田的图像,为农业生产提供决策支持。以下是图像识别在农业中的一些关键应用: 病虫害检测:图像识别技术能够识别作物上的病斑、虫害或异常状况。通过比较高…...
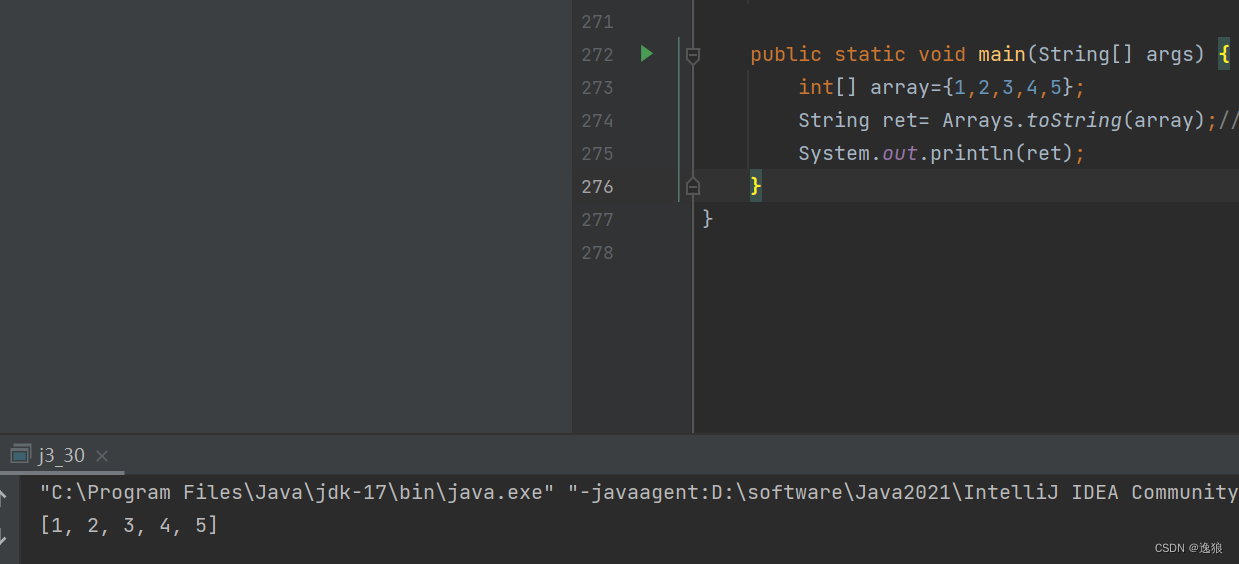
【JavaSE】java刷题--数组练习
前言 本篇讲解了一些数组相关题目(主要以代码的形式呈现),主要目的在于巩固数组相关知识。 上一篇 数组 讲解了一维数组和二维数组的基础知识~ 欢迎关注个人主页:逸狼 创造不易,可以点点赞吗~ 如有错误,欢迎…...

预处理、编译、汇编、链接过程
预处理、编译、汇编、链接过程 预处理 引入头文件 #include 展开宏定义 #define 处理条件编译指令 #ifdef 删除注释 添加行号 在Linux下可以使用gcc -E命令把hello.c文件预处理成hello.i文件。windows这些操作都集成在编译器visual studio这些里面了。 编译 进行语法分…...

3、Cocos Creator 节点和组件
目录 1、 节点和组件 2、 节点层级和显示顺序 3、坐标系和节点变换属性 坐标系 锚点 旋转 缩放 尺寸 4、 常用技巧 5、参考 1、 节点和组件 Cocos Creator 的工作流程是以组件式开发为核心的,组件式架构也称作 组件 — 实体系统(或 Entity-C…...
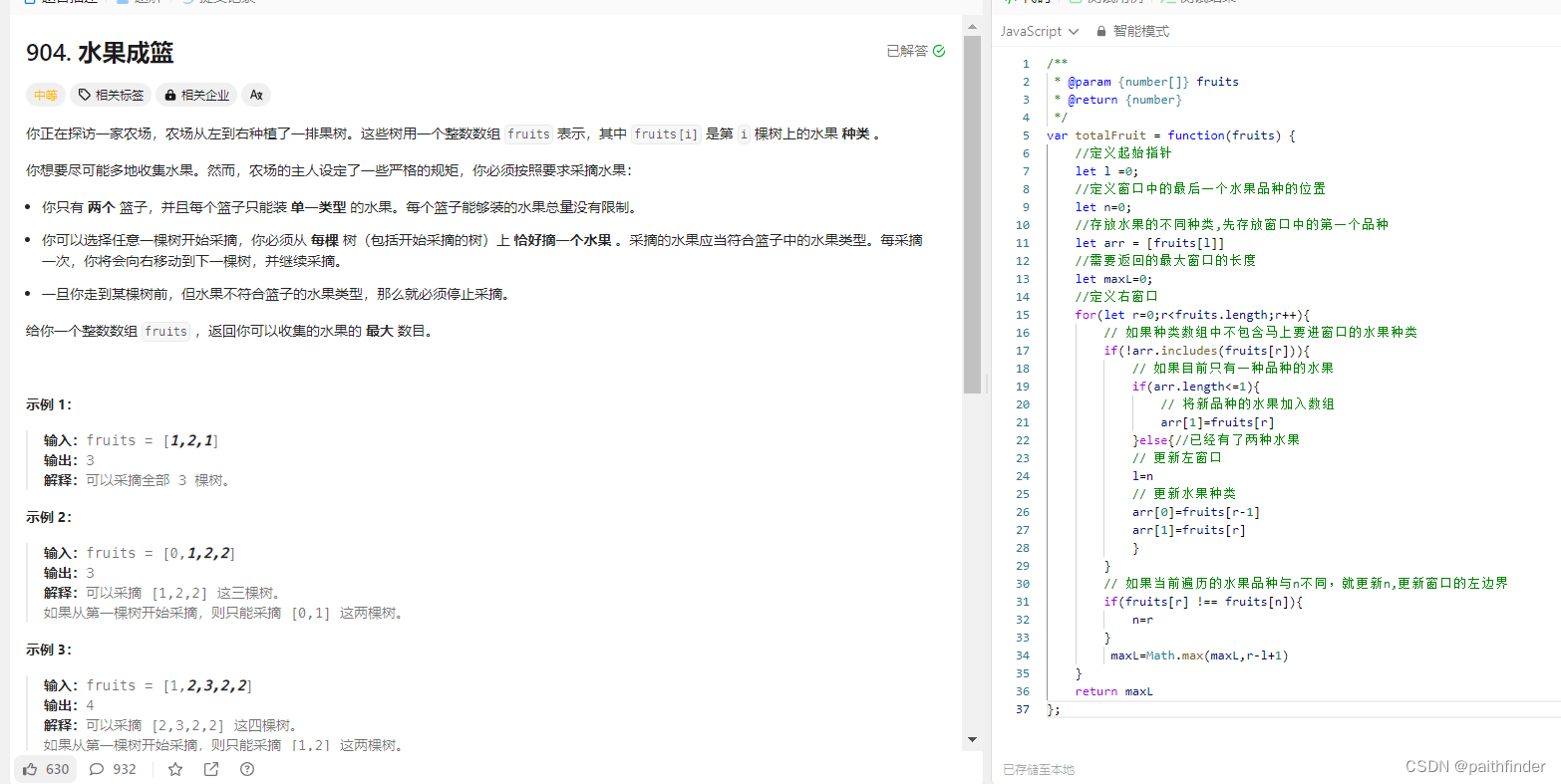
【js刷题:数据结构数组篇之长度最小的子数组】
长度最小的子数组 一、题目二、方法1.暴力解法2.滑动窗口是什么滑动窗口的起始位置滑动窗口的结束位置代码展示 3.力扣刷题水果成篮题目思路代码 一、题目 给定一个含有 n 个正整数的数组和一个正整数 s ,找出该数组中满足其和 ≥ s 的长度最小的 连续 子数组&…...

大话设计模式之装饰模式
装饰模式(Decorator Pattern)是一种结构型设计模式,它允许向现有对象动态地添加新功能,同时又不改变其结构。装饰模式通过将对象放入包装器中来实现,在包装器中可以动态地添加功能。 在装饰模式中,通常会有…...

国赛大纲解读
1. 第一部分,是针对5G基础知识的掌握,第二部分是人工智能基本算法的掌握,就是人工智能的应用,用5G+人工智能(AI算法)进行网络优化的问题,要有网络优化的基础知识,比如说:某个区域的覆盖问题,覆盖特别差,但有数据,覆盖电频,srp值这些数据给你,根据数据来判断是…...
:原型模式)
设计模式(5):原型模式
一.原型模式 通过 n e w 产生一个对象需要非常繁琐的数据准备或访问权限,则可以使用原型模式。 \color{red}{通过new产生一个对象需要非常繁琐的数据准备或访问权限,则可以使用原型模式。} 通过new产生一个对象需要非常繁琐的数据准备或访问权限…...
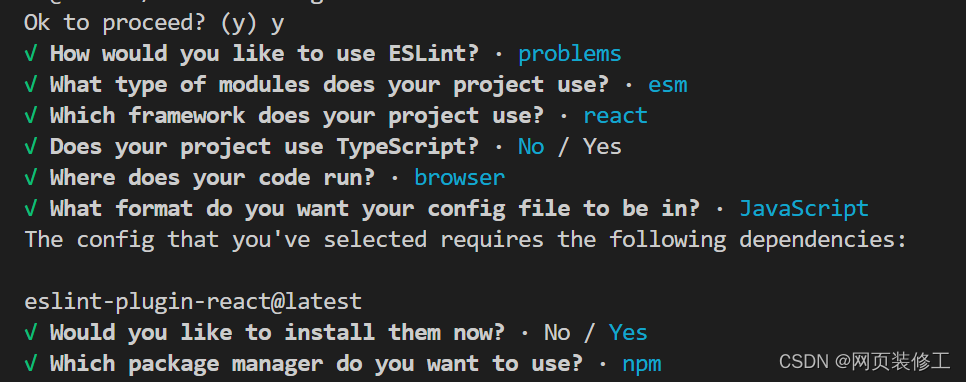
【React】vite + react 项目,进行配置 eslint
安装与配置 eslint 1 安装 eslint babel/eslint-parser2 初始化配置 eslint3 安装 vite-plugin-eslint4 配置 vite.config.js 文件5 修改 eslint 默认配置 1 安装 eslint babel/eslint-parser npm i -D eslint babel/eslint-parser2 初始化配置 eslint npx eslint --init相关…...
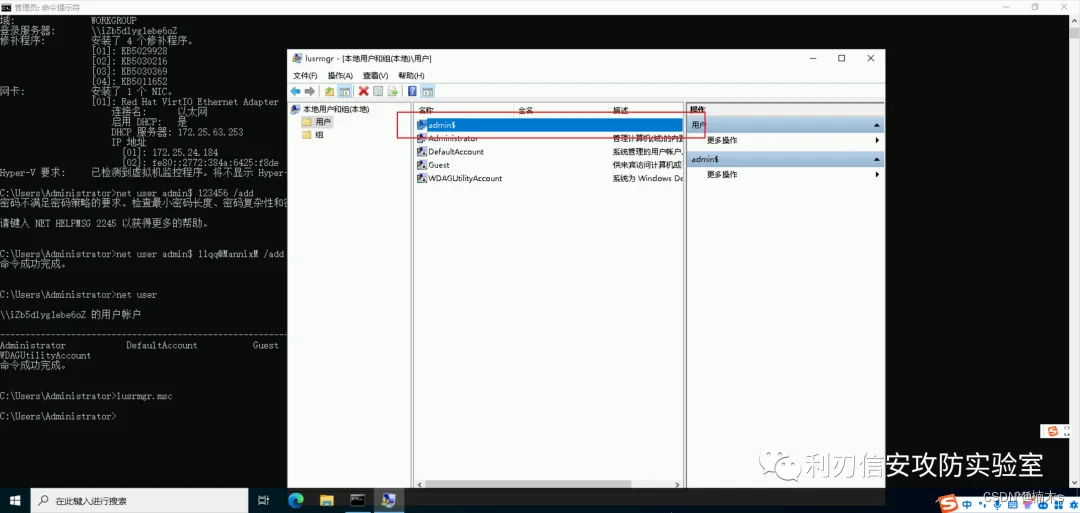
Windows入侵排查
目录 0x00 前言 0x01 入侵排查思路 1.1 检查系统账号安全 1.2 检查异常端口、进程 1.3 检查启动项、计划任务、服务 0x00 前言 当企业发生黑客入侵、系统崩溃或其它影响业务正常运行的安全事件时,急需第一时间进行处理,使企业的网络信息系统在最短时…...

C语言每日一题
1.题目 二.分析 本题有两点需要注意的: do-while循环 :在判断while条件前先执行一次do循环static变量 :程序再次调用时static变量的值不会重新初始化,而是在上一次退出时的基础上继续执行。for( i 1; i < 3; i )将调用两次…...

TheMoon 恶意软件短时间感染 6,000 台华硕路由器以获取代理服务
文章目录 针对华硕路由器Faceless代理服务预防措施 一种名为"TheMoon"的新变种恶意软件僵尸网络已经被发现正在侵入全球88个国家数千台过时的小型办公室与家庭办公室(SOHO)路由器以及物联网设备。 "TheMoon"与“Faceless”代理服务有关联,该服务…...

人脸68关键点与K210疲劳检测
目录 人脸68关键点检测 检测闭眼睁眼 双眼关键点检测 计算眼睛的闭合程度: 原理: 设置阈值进行判断 实时监测和更新 拓展:通过判断上下眼皮重合程度去判断是否闭眼 检测嘴巴是否闭合 提取嘴唇上下轮廓的关键点 计算嘴唇上下轮廓关键点之间的距…...

【跟着GPT4学JAVA】异常篇
JAVA异常中的知识点 问: 介绍下JAVA中的异常有哪些知识点吧 答: Java中的异常处理是一个重要的知识点,主要包括以下内容: 异常体系:Java的异常类是Throwable类派生出来的,Throwable下有两个重要的子类:Err…...
Ubuntu上安装d4rl数据集
Ubuntu上安装d4rl数据集 D4RL的官方 github: https://github.com/Farama-Foundation/D4RL 一、安装Mujoco 1.1 官网下载mujoco210文件 如果装过可以跳过这步 链接:https://github.com/deepmind/mujoco/releases/tag/2.1.0 下载第一个文件即可。我这里是在windo…...
之set 用法(创建、赋值、增删查改)详解)
C++之STL整理(4)之set 用法(创建、赋值、增删查改)详解
C之STL整理(4)之set 用法(创建、赋值、增删查改)详解 注:整理一些突然学到的C知识,随时mark一下 例如:忘记的关键字用法,新关键字,新数据结构 C 的map用法整理 C之STL整理…...
IDEA MyBatisCodeHelper Pro最新版(持续更新)
目录 0. 你想要的0.1 包下载0.2 使用jh 1. 功能介绍2. 下载安装2.1 在idea中插件市场安装2.2 在jetbrains插件市场下载安装 3. 简单使用3.1 创建一个SpringBoot项目3.2 配置数据库3.3 一键生成实体类、mapper 0. 你想要的 0.1 包下载 测试系统:Windows(…...
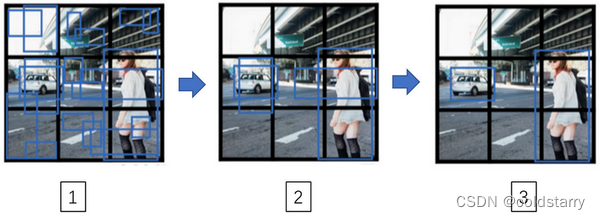
sheng的学习笔记-AI-YOLO算法,目标检测
AI目录:sheng的学习笔记-AI目录-CSDN博客 目录 目标定位(Object localization) 定义 原理图 具体做法: 输出向量 图片中没有检测对象的样例 损失函数 编辑 特征点检测(Landmark detection) 定义&a…...

QTQK-FJYJNDL-V137 远动及光伏群调群控装置技术介绍
一、产品概述QTQK-FJYJNDL-V137 群调群控装置由福建亿捷能电力科技公司自主研发,主要应用于光伏电站、风电场、储能电站、配电站等各类分布式电源场景,是一款专用的边缘计算与调控设备。该装置可实现现场测控装置、保护装置、逆变器、储能变流器等设备的…...
)
脚本开发必看:随机数使用中的3个常见误区及正确写法(按键精灵版)
脚本开发必看:随机数使用中的3个常见误区及正确写法(按键精灵版) 在自动化脚本开发中,随机数功能就像一把双刃剑——用得好能让脚本行为更接近人类操作,用得不好则可能导致不可预测的bug。特别是在按键精灵这类工具中&…...

AI编程助手入门:Ollama运行Yi-Coder-1.5B,快速生成函数与类
AI编程助手入门:Ollama运行Yi-Coder-1.5B,快速生成函数与类 1. 为什么选择Yi-Coder-1.5B作为编程助手 1.1 轻量级但功能强大 Yi-Coder-1.5B是一款专为代码生成优化的开源模型,虽然只有1.5B参数,但在编程任务上的表现却出人意料…...

如何针对不同行业制定SEO策略方案
如何针对不同行业制定SEO策略方案 在当今数字化时代,搜索引擎优化(SEO)已经成为每个企业线上推广的核心策略之一。不同行业的SEO策略并非一成不变。制定有效的SEO方案,需要对各个行业的特点、用户行为以及竞争态势有深刻的理解。…...

应对“中年危机”的前置策略:留学生入职第一天就该考虑的事情——如何建立你的“被动求职”网络?
在 2026 年的北美科技职场,拿到全职 Offer 签下字的那一刻,许多留学生会如释重负地认为自己终于进入了“保险箱”。然而,在残酷的宏观经济周期和快速迭代的 AI 浪潮面前,传统的“绝对稳定”早已不复存在。 无论是硅谷巨头…...

终极跨平台游戏优化工具迁移指南:从Windows到Linux/macOS的完整解决方案
终极跨平台游戏优化工具迁移指南:从Windows到Linux/macOS的完整解决方案 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款强大的游戏优化工具,专为管理NVIDIA DLSS、AMD FSR和…...
(1))
链表(两数相加)(1)
一.题目 2. 两数相加 - 力扣(LeetCode) 二.思路讲解 2.1 审题 题目给出两个非空链表,每个链表表示一个非负整数,并且数字是逆序存储的,即链表的头节点对应数字的最低位。例如,链表 2->4->3 表示数字…...

2026年知网AIGC检测4.0升级后怎么降AI?这个方法测了10次全过
知网AIGC检测4.0升级之后,有一段时间原来用的降AI方法突然不好用了——处理完以为能过,知网一检测还是20%多。后来摸索了一段时间,找到了稳定有效的方法,连续测了10次,全部通过。 方法核心:用支持4.0版本验…...

通义千问1.5-1.8B-Chat商业应用:企业智能助手快速落地方案
通义千问1.5-1.8B-Chat商业应用:企业智能助手快速落地方案 1. 企业智能助手市场现状与需求 当前企业运营面临人力成本上升、服务标准化不足、数据分析需求激增等挑战。传统解决方案往往需要投入大量资源进行定制开发,而基于大模型的智能助手提供了快速…...
完全解决方案:从原理、配置到故障排错全攻略)
ESXi 8.0U3I 硬盘直通(PCIe/RDM)完全解决方案:从原理、配置到故障排错全攻略
在 ESXi 8.0U3I 环境中,硬盘直通(含 PCIe 控制器直通 与 RDM 裸设备映射)是实现虚拟机直接访问物理硬盘、最大化存储性能与兼容性的核心技术,但 8.0U3I 对消费级硬件、SATA/NVMe 控制器、驱动签名的管控更严格,极易出现无法开启直通、直通后硬…...