pytorch中的torch.nn.Linear
torch.nn.Linear是pytorch中的线性层,应该是最常见的网络层了,官方文档:torch.nn.Linear。
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
其中,in_features表示输入的维度;out_features表示输出的维度;bias表示是否包含偏置,默认为True。
nn.linear的作用其实就是对输入进行了一个线性变换,中学时我们学习的线性变换是y=kx+b,但是对于神经网络来说,我们的输入、输出和权重都是一个矩阵,即: o u t p u t = i n p u t ∗ W + b output=input*W+b output=input∗W+b 其中, i n p u t ∈ R n × i input\in R^{n×i} input∈Rn×i, W ∈ R i × o W\in R^{i×o} W∈Ri×o, o u t p u t ∈ R n × o output\in R^{n×o} output∈Rn×o,n为输入向量的行数(通常为batch数),i为输入神经元的个数,o为输出神经元的个数。使用举例:
FC = nn.Linear(20, 40)
input = torch.randn(128, 20) # (128,20)
output = FC(input)
print(output.size()) # (128,40)
官方源码:
import mathimport torch
from torch import Tensor
from torch.nn.parameter import Parameter, UninitializedParameter
from .. import functional as F
from .. import init
from .module import Module
from .lazy import LazyModuleMixinclass Identity(Module):r"""A placeholder identity operator that is argument-insensitive.Args:args: any argument (unused)kwargs: any keyword argument (unused)Shape:- Input: :math:`(*)`, where :math:`*` means any number of dimensions.- Output: :math:`(*)`, same shape as the input.Examples::>>> m = nn.Identity(54, unused_argument1=0.1, unused_argument2=False)>>> input = torch.randn(128, 20)>>> output = m(input)>>> print(output.size())torch.Size([128, 20])"""def __init__(self, *args, **kwargs):super(Identity, self).__init__()def forward(self, input: Tensor) -> Tensor:return inputclass Linear(Module):r"""Applies a linear transformation to the incoming data: :math:`y = xA^T + b`This module supports :ref:`TensorFloat32<tf32_on_ampere>`.Args:in_features: size of each input sampleout_features: size of each output samplebias: If set to ``False``, the layer will not learn an additive bias.Default: ``True``Shape:- Input: :math:`(*, H_{in})` where :math:`*` means any number ofdimensions including none and :math:`H_{in} = \text{in\_features}`.- Output: :math:`(*, H_{out})` where all but the last dimensionare the same shape as the input and :math:`H_{out} = \text{out\_features}`.Attributes:weight: the learnable weights of the module of shape:math:`(\text{out\_features}, \text{in\_features})`. The values areinitialized from :math:`\mathcal{U}(-\sqrt{k}, \sqrt{k})`, where:math:`k = \frac{1}{\text{in\_features}}`bias: the learnable bias of the module of shape :math:`(\text{out\_features})`.If :attr:`bias` is ``True``, the values are initialized from:math:`\mathcal{U}(-\sqrt{k}, \sqrt{k})` where:math:`k = \frac{1}{\text{in\_features}}`Examples::>>> m = nn.Linear(20, 30)>>> input = torch.randn(128, 20)>>> output = m(input)>>> print(output.size())torch.Size([128, 30])"""__constants__ = ['in_features', 'out_features']in_features: intout_features: intweight: Tensordef __init__(self, in_features: int, out_features: int, bias: bool = True,device=None, dtype=None) -> None:factory_kwargs = {'device': device, 'dtype': dtype}super(Linear, self).__init__()self.in_features = in_featuresself.out_features = out_featuresself.weight = Parameter(torch.empty((out_features, in_features), **factory_kwargs))if bias:self.bias = Parameter(torch.empty(out_features, **factory_kwargs))else:self.register_parameter('bias', None)self.reset_parameters()def reset_parameters(self) -> None:# Setting a=sqrt(5) in kaiming_uniform is the same as initializing with# uniform(-1/sqrt(in_features), 1/sqrt(in_features)). For details, see# https://github.com/pytorch/pytorch/issues/57109init.kaiming_uniform_(self.weight, a=math.sqrt(5))if self.bias is not None:fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight)bound = 1 / math.sqrt(fan_in) if fan_in > 0 else 0init.uniform_(self.bias, -bound, bound)def forward(self, input: Tensor) -> Tensor:return F.linear(input, self.weight, self.bias)def extra_repr(self) -> str:return 'in_features={}, out_features={}, bias={}'.format(self.in_features, self.out_features, self.bias is not None)# This class exists solely to avoid triggering an obscure error when scripting
# an improperly quantized attention layer. See this issue for details:
# https://github.com/pytorch/pytorch/issues/58969
# TODO: fail fast on quantization API usage error, then remove this class
# and replace uses of it with plain Linear
class NonDynamicallyQuantizableLinear(Linear):def __init__(self, in_features: int, out_features: int, bias: bool = True,device=None, dtype=None) -> None:super().__init__(in_features, out_features, bias=bias,device=device, dtype=dtype)[docs]class Bilinear(Module):r"""Applies a bilinear transformation to the incoming data::math:`y = x_1^T A x_2 + b`Args:in1_features: size of each first input samplein2_features: size of each second input sampleout_features: size of each output samplebias: If set to False, the layer will not learn an additive bias.Default: ``True``Shape:- Input1: :math:`(*, H_{in1})` where :math:`H_{in1}=\text{in1\_features}` and:math:`*` means any number of additional dimensions including none. All but the last dimensionof the inputs should be the same.- Input2: :math:`(*, H_{in2})` where :math:`H_{in2}=\text{in2\_features}`.- Output: :math:`(*, H_{out})` where :math:`H_{out}=\text{out\_features}`and all but the last dimension are the same shape as the input.Attributes:weight: the learnable weights of the module of shape:math:`(\text{out\_features}, \text{in1\_features}, \text{in2\_features})`.The values are initialized from :math:`\mathcal{U}(-\sqrt{k}, \sqrt{k})`, where:math:`k = \frac{1}{\text{in1\_features}}`bias: the learnable bias of the module of shape :math:`(\text{out\_features})`.If :attr:`bias` is ``True``, the values are initialized from:math:`\mathcal{U}(-\sqrt{k}, \sqrt{k})`, where:math:`k = \frac{1}{\text{in1\_features}}`Examples::>>> m = nn.Bilinear(20, 30, 40)>>> input1 = torch.randn(128, 20)>>> input2 = torch.randn(128, 30)>>> output = m(input1, input2)>>> print(output.size())torch.Size([128, 40])"""__constants__ = ['in1_features', 'in2_features', 'out_features']in1_features: intin2_features: intout_features: intweight: Tensordef __init__(self, in1_features: int, in2_features: int, out_features: int, bias: bool = True,device=None, dtype=None) -> None:factory_kwargs = {'device': device, 'dtype': dtype}super(Bilinear, self).__init__()self.in1_features = in1_featuresself.in2_features = in2_featuresself.out_features = out_featuresself.weight = Parameter(torch.empty((out_features, in1_features, in2_features), **factory_kwargs))if bias:self.bias = Parameter(torch.empty(out_features, **factory_kwargs))else:self.register_parameter('bias', None)self.reset_parameters()def reset_parameters(self) -> None:bound = 1 / math.sqrt(self.weight.size(1))init.uniform_(self.weight, -bound, bound)if self.bias is not None:init.uniform_(self.bias, -bound, bound)def forward(self, input1: Tensor, input2: Tensor) -> Tensor:return F.bilinear(input1, input2, self.weight, self.bias)def extra_repr(self) -> str:return 'in1_features={}, in2_features={}, out_features={}, bias={}'.format(self.in1_features, self.in2_features, self.out_features, self.bias is not None)class LazyLinear(LazyModuleMixin, Linear):r"""A :class:`torch.nn.Linear` module where `in_features` is inferred.In this module, the `weight` and `bias` are of :class:`torch.nn.UninitializedParameter`class. They will be initialized after the first call to ``forward`` is done and themodule will become a regular :class:`torch.nn.Linear` module. The ``in_features`` argumentof the :class:`Linear` is inferred from the ``input.shape[-1]``.Check the :class:`torch.nn.modules.lazy.LazyModuleMixin` for further documentationon lazy modules and their limitations.Args:out_features: size of each output samplebias: If set to ``False``, the layer will not learn an additive bias.Default: ``True``Attributes:weight: the learnable weights of the module of shape:math:`(\text{out\_features}, \text{in\_features})`. The values areinitialized from :math:`\mathcal{U}(-\sqrt{k}, \sqrt{k})`, where:math:`k = \frac{1}{\text{in\_features}}`bias: the learnable bias of the module of shape :math:`(\text{out\_features})`.If :attr:`bias` is ``True``, the values are initialized from:math:`\mathcal{U}(-\sqrt{k}, \sqrt{k})` where:math:`k = \frac{1}{\text{in\_features}}`"""cls_to_become = Linear # type: ignore[assignment]weight: UninitializedParameterbias: UninitializedParameter # type: ignore[assignment]def __init__(self, out_features: int, bias: bool = True,device=None, dtype=None) -> None:factory_kwargs = {'device': device, 'dtype': dtype}# bias is hardcoded to False to avoid creating tensor# that will soon be overwritten.super().__init__(0, 0, False)self.weight = UninitializedParameter(**factory_kwargs)self.out_features = out_featuresif bias:self.bias = UninitializedParameter(**factory_kwargs)def reset_parameters(self) -> None:if not self.has_uninitialized_params() and self.in_features != 0:super().reset_parameters()def initialize_parameters(self, input) -> None: # type: ignore[override]if self.has_uninitialized_params():with torch.no_grad():self.in_features = input.shape[-1]self.weight.materialize((self.out_features, self.in_features))if self.bias is not None:self.bias.materialize((self.out_features,))self.reset_parameters()
# TODO: PartialLinear - maybe in sparse?
相关文章:

pytorch中的torch.nn.Linear
torch.nn.Linear是pytorch中的线性层,应该是最常见的网络层了,官方文档:torch.nn.Linear。 torch.nn.Linear(in_features, out_features, biasTrue, deviceNone, dtypeNone)其中,in_features表示输入的维度;out_featu…...

03-MySQl数据库的-用户管理
一、创建新用户 mysql> create user xjzw10.0.0.% identified by 1; Query OK, 0 rows affected (0.01 sec) 二、查看当前数据库正在登录的用户 mysql> select user(); ---------------- | user() | ---------------- | rootlocalhost | ---------------- 1 row …...
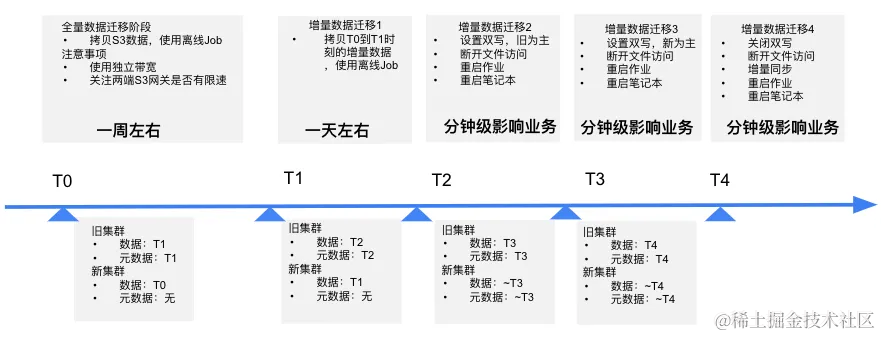
知乎:多云架构下大模型训练,如何保障存储稳定性?
知乎,中文互联网领域领先的问答社区和原创内容平台,2011 年 1 月正式上线,月活跃用户超过 1 亿。平台的搜索和推荐服务得益于先进的 AI 算法,数百名算法工程师基于数据平台和机器学习平台进行海量数据处理和算法训练任务。 为了提…...
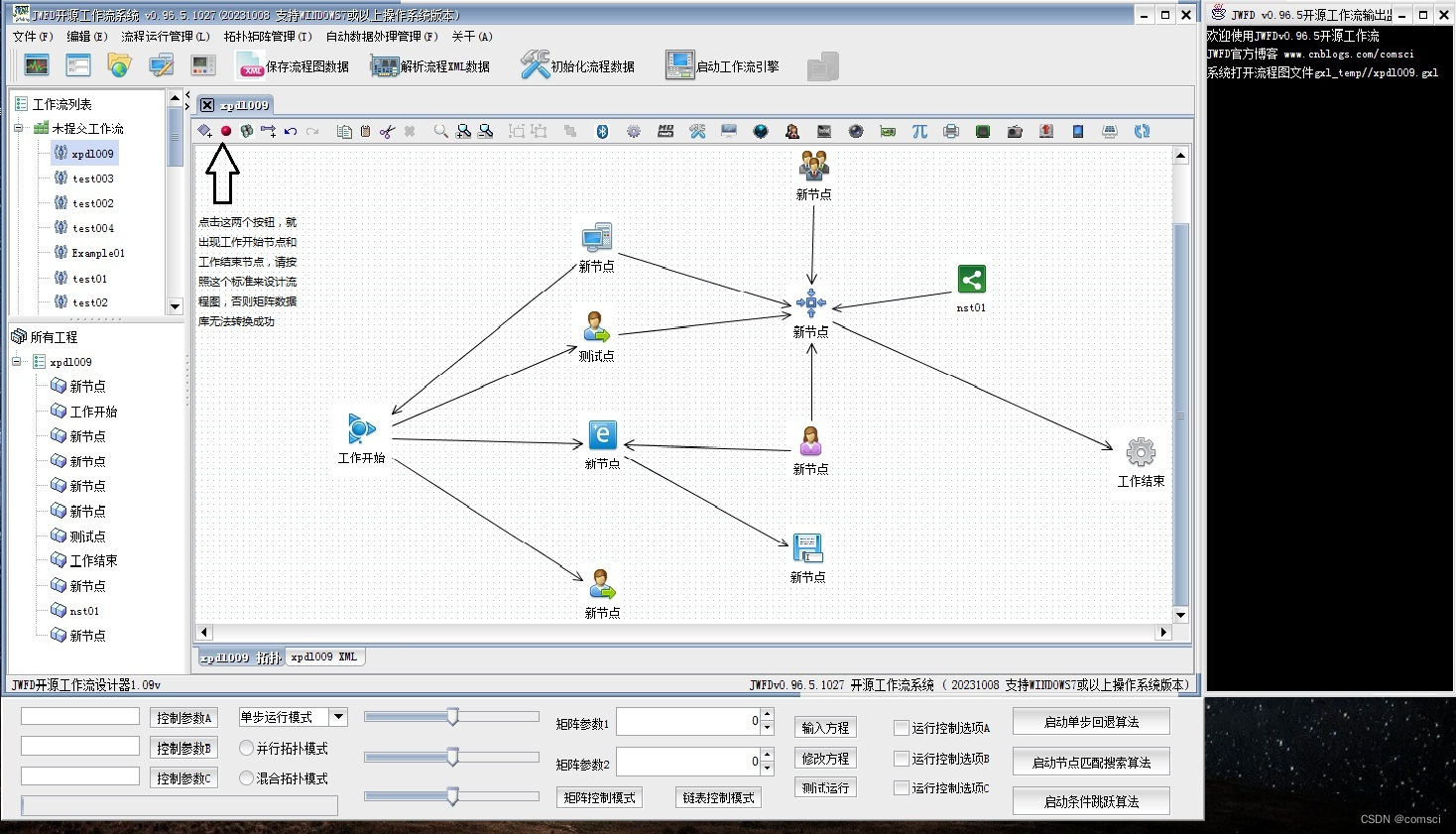
JWFD流程图转换为矩阵数据库的过程说明
在最开始设计流程图的时候,请务必先把开始节点和结束节点画到流程图上面,就是设计器面板的最开始两个按钮,先画开始点和结束点,再画中间的流程,然后保存,这样提交到矩阵数据库就不会出任何问题,…...
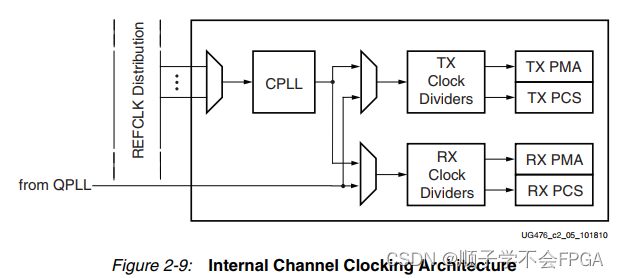
GT收发器第一篇_总体结构介绍
文章目录 前言GT收发器介绍 前言 之前写过一篇简单介绍GT的文章https://blog.csdn.net/m0_56222647/article/details/136730026,可以先通过这篇文章对整体进行简单了解一下。 GT收发器介绍 参考xilinx手册ug476 对于7系列的FPGA,共有3个系列…...
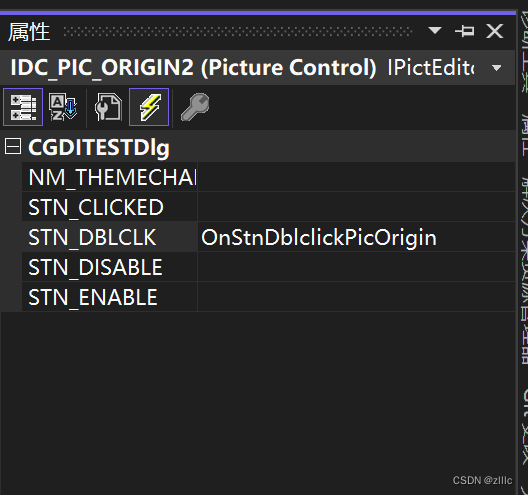
[图像处理] MFC载入图片并进行二值化处理和灰度处理及其效果显示
文章目录 工程效果重要代码完整代码参考 工程效果 载入图片,并在左侧显示原始图片、二值化图片和灰度图片。 双击左侧的图片控件,可以在右侧的大控件中,显示双击的图片。 初始画面: 载入图片: 双击左侧的第二个控件…...
)
centos7.5 安装gitlab-ce (Omnibus)
一、安装前置依赖 # 安装基础依赖 $ sudo yum -y install policycoreutils openssh-server openssh-clients postfix# 启动 ssh 服务 & 设置为开机启动 $ sudo systemctl enable sshd & sudo systemctl start sshd二、安装gitlab rpm包 # 下载并执行社区版脚本 curl …...
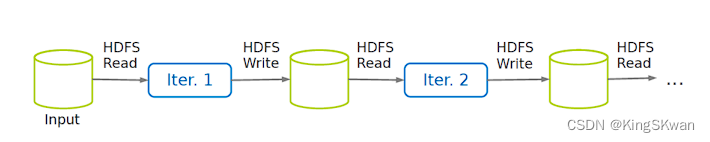
深入理解MapReduce:从Map到Reduce的工作原理解析
当谈到分布式计算和大数据处理时,MapReduce是一个经典的范例。它是一种编程模型和处理框架,用于在大规模数据集上并行运行计算任务。MapReduce包含三个主要阶段:Map、Shuffle 和 Reduce。 ** Map 阶段 ** Map 阶段是 MapReduce 的第一步&am…...
初始Java篇(JavaSE基础语法)(5)(类和对象(上))
个人主页(找往期文章包括但不限于本期文章中不懂的知识点):我要学编程(ಥ_ಥ)-CSDN博客 目录 面向对象的初步认知 面向对象与面向过程的区别 类的定义和使用 类的定义格式 类的实例化 this引用 什么是this引用? this引用…...

机器人---人形机器人之技术方向
1 背景介绍 在前面的文章《行业杂谈---人形机器人的未来》中,笔者初步介绍了人形机器人的未来发展趋势。同智能汽车一样,它也会是未来机器人领域的一个重要分支。目前地球上最高智慧的结晶体就是人类,那么人形机器人的未来会有非常大的发展空…...
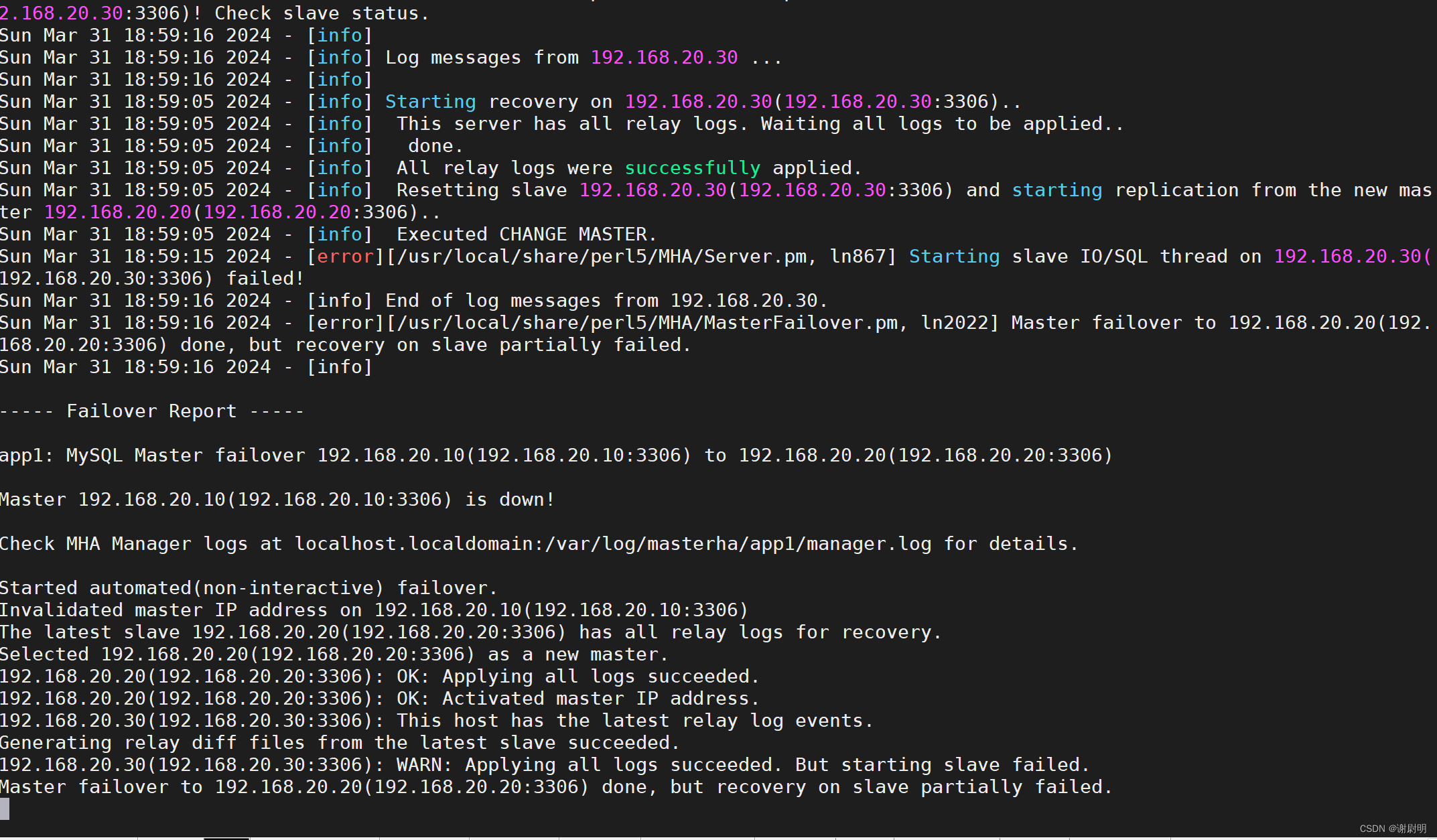
MySQL MHA高可用数据库
文章目录 MySQL MHA高可用数据库搭建MySQL MHA模拟故障故障修复: MySQL MHA高可用数据库 MHA(MySQL High Availability)是一个开源的高可用解决方案,用于实现MySQL主从复制集群的故障自动切换。MHA的主要目的是确保MySQL数据库集…...
比的是什么?)
LVS(Layout versus schematic)比的是什么?
概述 LVS不是一个简单地将版图与电路原理图进行比较的过程,它需要分两步完成。第一步“抽取”,第二步“比较”。首先根据LVS提取规则,EDA 工具从版图中抽取出版图所确定的网表文件;然后将抽取出的网表文件与电路网表文件进行比较…...
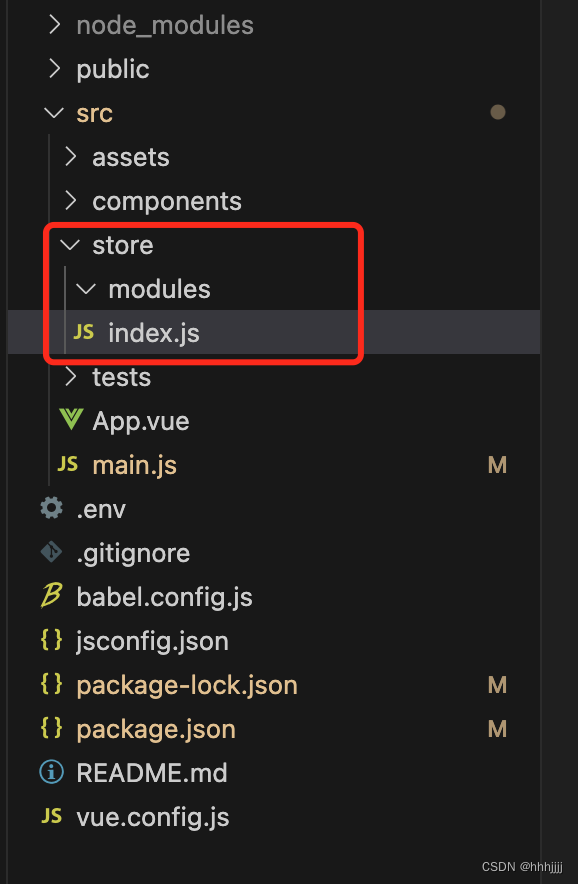
从0开始搭建基于VUE的前端项目(三) Vuex的使用与配置
准备与版本 vuex 3.6.2(https://v3.vuex.vuejs.org/zh/)概念 vuex是什么? 是用作 【状态管理】的 流程图如下 state 数据状态,成员是个对象 mapState 组件使用this.$store.state.xxx获取state里面的数据 getters 成员是个函数,方便获取state里面的数据,也可以加工数据 ma…...
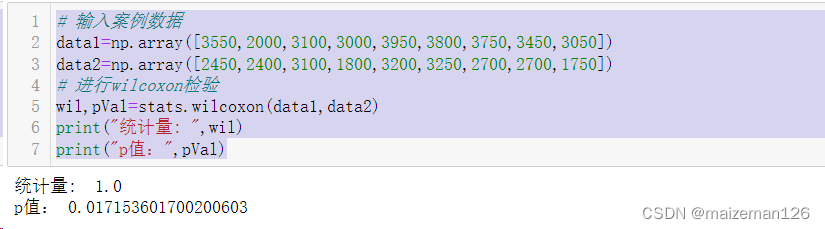
python统计分析——双样本均值比较
参考资料:python统计分析【托马斯】 1、配对样本t检验 在进行两组数据之间的比较时,有两种情况必须区分开。在第一种情况中,同一对象在不同时候的两个记录值进行相互比较。例如,用学生们进入初中时的身高和他们一年后的身高&…...
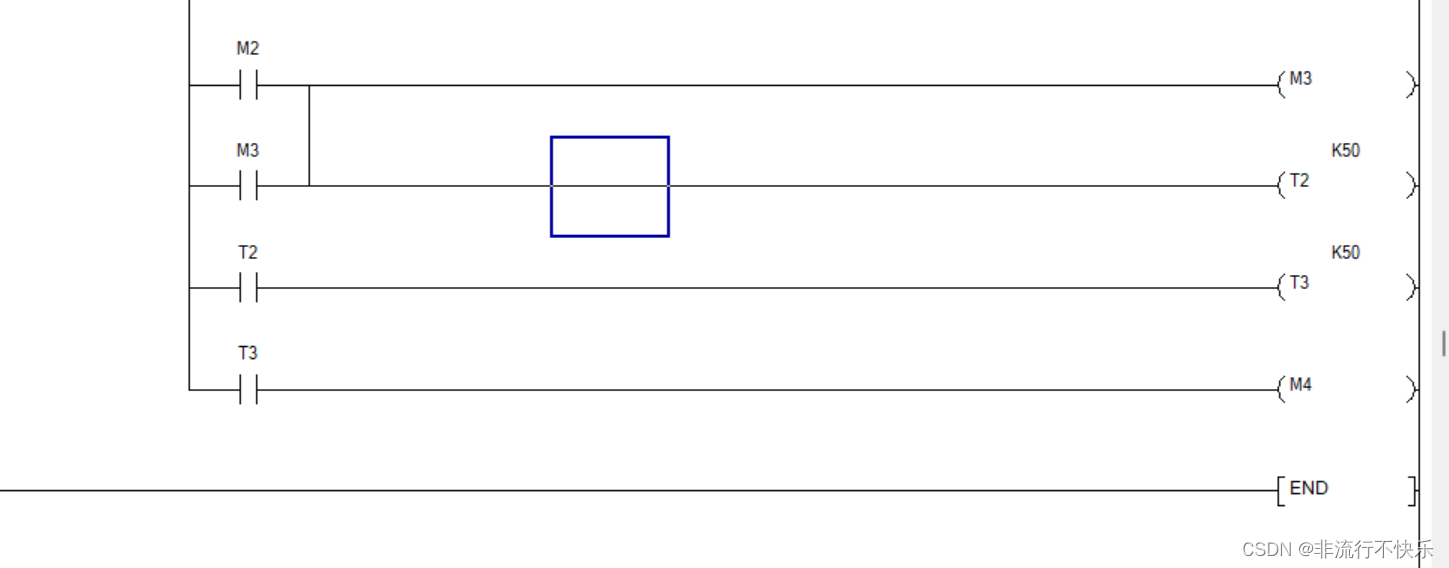
三台电机的顺启逆停
1,开启按钮输入信号是 电机一开始启动,5秒回电机2启动 ,在5秒电机三启动 关闭按钮输入时电机3关闭 ,5秒后电机2关闭 最后电机一关闭 2,思路开启按钮按下接通电机1 并且接通定时器T0 定时器T0 到时候接通电机2 并且开…...
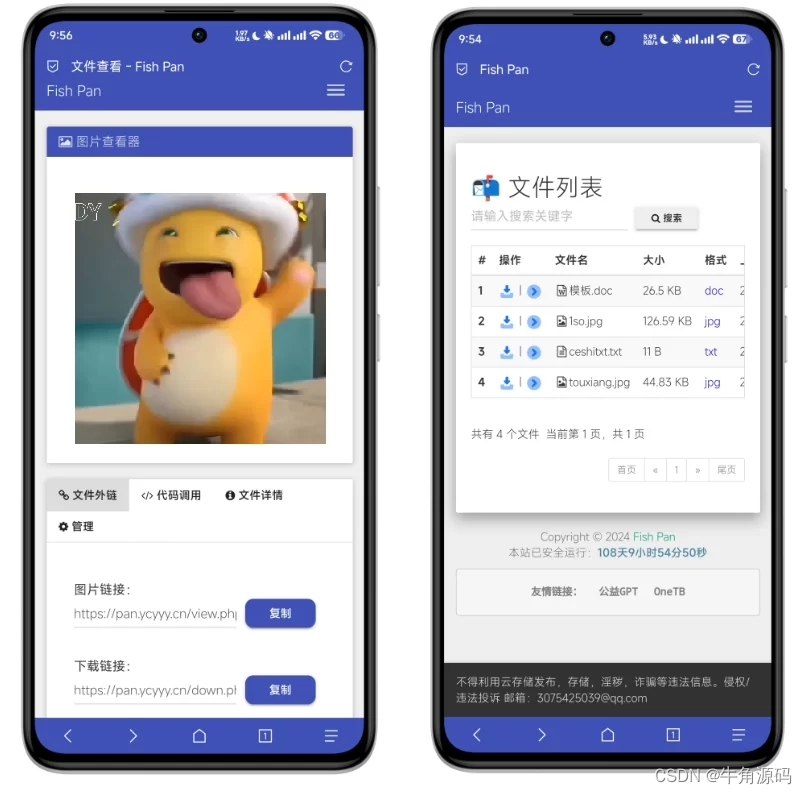
彩虹外链网盘界面UI美化版超级简洁好看
彩虹外链网盘,是一款PHP网盘与外链分享程序,支持所有格式文件的上传,可以生成文件外链、图片外链、音乐视频外链,生成外链同时自动生成相应的UBB代码和HTML代码,还可支持文本、图片、音乐、视频在线预览,这…...
企业微信知识库:从了解到搭建的全流程
你是否也有这样的疑惑:为什么现在的企业都爱创建企业微信知识库?企业微信知识库到底有什么用?如果想要使用企业微信知识库企业应该如何创建?这就是我今天要探讨的问题,感兴趣的话一起往下看吧! | 为什么企业…...

【华为OD机试C++】合并表记录
《最新华为OD机试题目带答案解析》:最新华为OD机试题目带答案解析,语言包括C、C++、Python、Java、JavaScript等。订阅专栏,获取专栏内所有文章阅读权限,持续同步更新! 文章目录 描述输入描述输出描述示例1示例2代码描述 数据表记录包含表索引index和数值value(int范围的…...
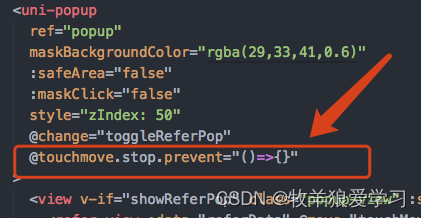
uniapp中使用u-popup组件导致的弹框下面的页面可滑动现象
添加代码: touchmove.stop.prevent"()>{}"...
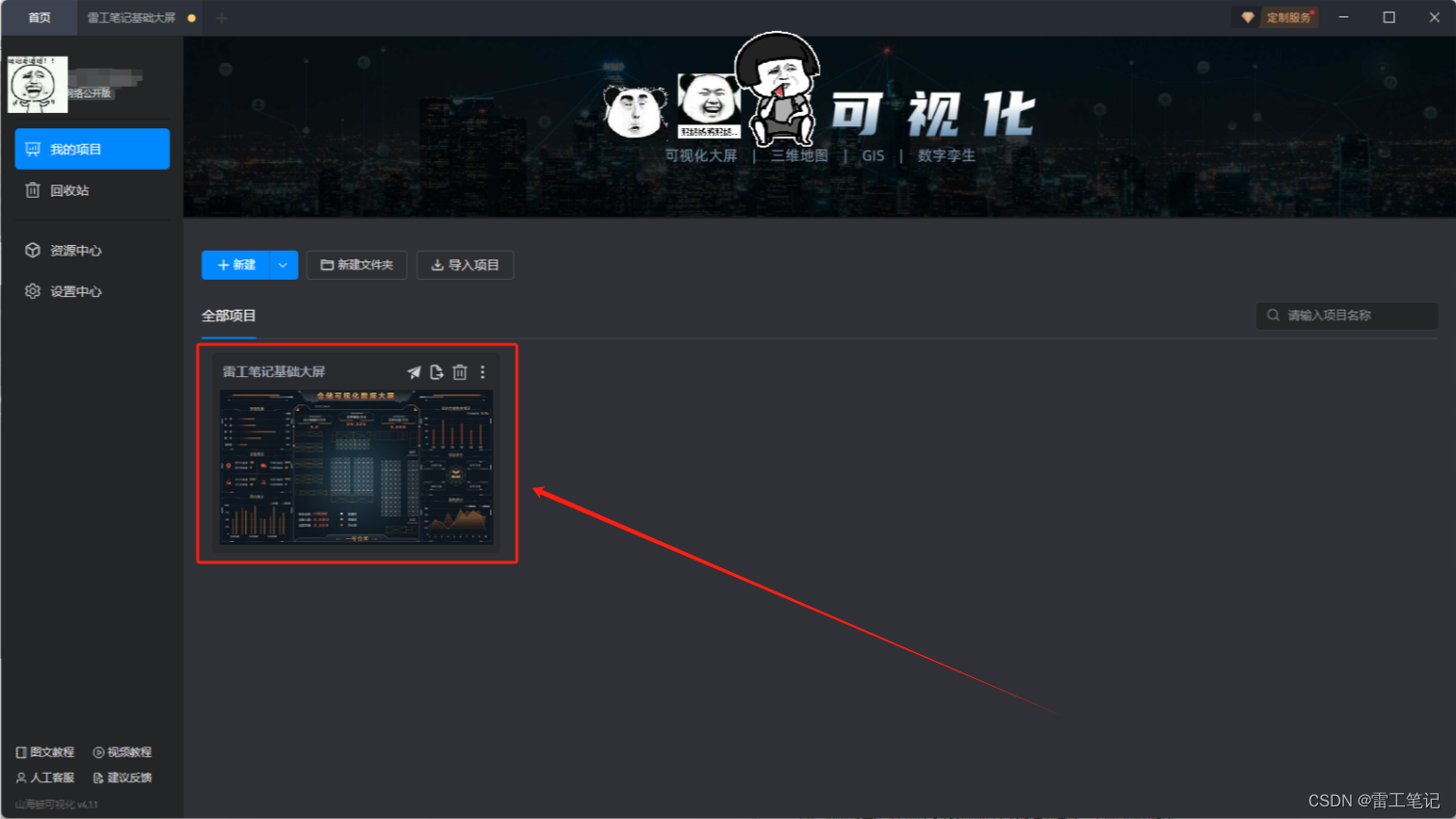
数字孪生|山海鲸可视化快速入门
哈喽,你好啊,我是雷工! 今天继续学习山海鲸可视化软件,以下为学习记录。 (一)新建项目 1.1、打开软件后,默认打开我的项目界面,初次打开需要注册,可以通过手机号快速注册。 点击“新建”按钮,新建一个项目。 1.2、根据项目需要选择一个快捷的项目模板,填写项目名称…...

LangFlow企业级应用:如何用可视化工具搭建智能业务系统
LangFlow企业级应用:如何用可视化工具搭建智能业务系统 1. 引言:当低代码遇上AI工作流 想象一下这样的场景:你的市场团队需要快速搭建一个智能客服系统,但技术团队资源紧张;或者你的数据分析部门希望构建一个自动化的…...
)
【MCP集成实战指南】:20年专家亲授VS Code插件3步极速接入法(附避坑清单)
第一章:MCP与VS Code插件集成的核心价值与适用场景MCP(Model Control Protocol)作为面向大模型交互的标准化协议,其与 VS Code 插件生态的深度集成,显著提升了开发者在本地环境中调用、编排与调试 AI 模型的能力。这种…...

Qwen3-4B模型处理Mathtype公式:LaTeX转换与学术文档排版
Qwen3-4B模型处理Mathtype公式:LaTeX转换与学术文档排版 1. 引言 如果你写过科研论文或者技术报告,大概率遇到过这样的麻烦:好不容易在Mathtype里把公式画得漂漂亮亮,一到要往LaTeX文档里贴的时候,就傻眼了。要么是手…...

Nanbeige 4.1-3B在Java面试准备中的应用:高频考点解析
Nanbeige 4.1-3B在Java面试准备中的应用:高频考点解析 还在为Java面试熬夜刷题、背八股文而头疼吗?试试用AI来帮你高效备考吧 最近帮几个准备跳槽的朋友做面试辅导,发现大家普遍面临同样的困境:Java知识点太多太杂,八股…...
)
5分钟搞定:用MAX4173搭建高端电流检测电路的保姆级教程(附避坑指南)
高端电流检测实战:MAX4173电路设计与避坑全攻略 在电源管理、电池充放电监控等场景中,高端电流检测技术因其能实时监测负载异常状态而备受青睐。相比传统低端检测方案,它避免了"检测盲区",但随之而来的共模信号处理、电…...

如何用ESP32-S3开发板打造你的专属AI语音助手?星智立方开发板深度体验
如何用ESP32-S3开发板打造你的专属AI语音助手?星智立方开发板深度体验 【免费下载链接】xiaozhi-esp32 Build your own AI friend 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaozhi-esp32 想象一下,你只需要对一个小巧的设备说句话&am…...

医生必看!深度学习合成的医学影像靠谱吗?我们实测了3种常见场景
深度学习合成医学影像的临床可靠性评估:医生必备的3大实战指南 当第一次在屏幕上看到由AI生成的脑部MRI影像时,张医生几乎无法相信自己的眼睛——那些灰白质交界处的细节、脑室边缘的清晰度,与真实扫描结果几乎无异。作为神经内科主任医师&am…...

Pixel Dimension Fissioner真实作品:品牌Slogan裂变为Z世代/银发族/新中产三类话术
Pixel Dimension Fissioner真实作品:品牌Slogan裂变为Z世代/银发族/新中产三类话术 1. 像素语言工坊:当AI遇见16-bit创意革命 在数字营销领域,一个品牌口号往往需要同时打动多个截然不同的受众群体。传统方法需要文案团队耗费大量时间针对不…...

基于STM32的博物馆展柜环境闭环控制系统设计
1. 项目概述1.1 系统定位与工程目标博物馆文物展柜环境控制并非简单的参数监测任务,而是一项融合材料科学、热力学、嵌入式实时控制与人机交互的系统工程。本项目聚焦于中小型博物馆实际运维场景,以解决三类核心矛盾为出发点:人工巡检频次与环…...

Qwen3-VL-4B Pro API调用全攻略:从单张图到批量处理,代码示例直接可用
Qwen3-VL-4B Pro API调用全攻略:从单张图到批量处理,代码示例直接可用 1. API调用基础:为什么需要绕过WebUI? 当你第一次使用Qwen3-VL-4B Pro时,可能会被其直观的Web界面所吸引——上传图片、输入问题、获取回答&…...