【名词解释】ImageCaption任务中的CIDEr、n-gram、TF-IDF、BLEU、METEOR、ROUGE 分别是什么?它们是怎样计算的?
CIDEr
CIDEr(Consensus-based Image Description Evaluation)是一种用于自动评估图像描述(image captioning)任务性能的指标。它主要通过计算生成的描述与一组参考描述之间的相似性来评估图像描述的质量。CIDEr的独特之处在于它考虑了人类对图像描述的共识,尝试捕捉描述的自然性和信息量。
CIDEr的计算过程
CIDEr的计算可以分为以下几个步骤:
-
词干提取:首先,对所有的参考描述和候选描述进行分词,然后将分词后的结果转化为它们的词干形式,以减少单词的变形对评分的影响。
-
TF-IDF权重计算:为了让常见词(如“the”,“is”等)的权重降低而让稀有词的权重提高,CIDEr使用TF-IDF(词频-逆文档频率)来计算每个词的权重。这一步骤的目的是提高描述中独特、信息丰富词汇的权重。
-
n-gram相似度计算:CIDEr通过计算候选描述和参考描述间n-gram(n可以从1到某个最大值,常用的是4)的余弦相似度来评估它们的相似性。这些n-gram的权重由第二步中计算的TF-IDF值决定。
-
相似度打分汇总:将上一步骤中计算出的所有n-gram相似度汇总,得到一个总体的相似度得分。通常,这个得分会对不同长度的n-gram给予不同的权重,以平衡信息量和流畅度。
-
归一化:最后,为了消除不同数据集之间评分的差异,CIDEr得分通常会经过归一化处理。
计算公式
CIDEr的计算可以用下面的公式表示:
CIDEr = ∑ n = 1 N w n ⋅ 1 m ∑ j = 1 m ∑ i min ( g i ( n ) , r i j ( n ) ) ∑ i ( g i ( n ) ) 2 ⋅ ∑ i ( r i j ( n ) ) 2 \text{CIDEr} = \sum_{n=1}^{N} w_n \cdot \frac{1}{m} \sum_{j=1}^{m} \frac{\sum_{i} \min(g_i^{(n)}, r_{ij}^{(n)})}{\sqrt{\sum_{i} (g_i^{(n)})^2} \cdot \sqrt{\sum_{i} (r_{ij}^{(n)})^2}} CIDEr=n=1∑Nwn⋅m1j=1∑m∑i(gi(n))2⋅∑i(rij(n))2∑imin(gi(n),rij(n))
其中:
- N N N是n-gram的最大长度。
- w n w_n wn是n-gram长度为 n n n的权重,通常为1。
- m m m是参考描述的数量。
- g i ( n ) g_i^{(n)} gi(n)是候选描述中n-gram i i i的权重(通常是TF-IDF权重)。
- r i j ( n ) r_{ij}^{(n)} rij(n)是第 j j j个参考描述中n-gram i i i的权重。
- 分子中的 min ( g i ( n ) , r i j ( n ) ) \min(g_i^{(n)}, r_{ij}^{(n)}) min(gi(n),rij(n))确保了只考虑共现的n-gram,而且以它们最小的出现频率为准。
- 分母中的两个平方根项是候选描述和参考描述n-gram权重向量的欧几里得范数,用于归一化相似度得分。
CIDEr的设计使其不仅重视单词的匹配程度,而且考虑了描述中信息的丰富性,通过TF-IDF权重强调了描述中独特和信息丰富的词汇,从而更好地评估图像描述的质量。
CIDEr与其他评价指标的对比
与CIDEr相比,其他流行的图像描述评价指标包括BLEU、METEOR和ROUGE等:
-
BLEU:主要通过计算机器生成的描述与一组参考描述之间的n-gram精确度来评估性能。它更侧重于准确性,但可能忽略流畅性和自然性。
-
METEOR:除了考虑n-gram匹配外,还引入了同义词和词形变化的匹配,以及对句子结构的考虑,使得评分更为细致和全面。
-
ROUGE:主要用于评估自动摘要任务,通过计算重叠的n-gram、词对(word pairs)和最长公共子序列来评估生成的摘要与参考摘要的相似度。对于图像描述任务,ROUGE评估重点可能与文本生成的质量和覆盖度相关。
总的来说,CIDEr独特的地方在于它专门为评估图像描述设计,通过考虑描述中的信息量和与人类评价者的共识来提供评分,这使得它在某些情况下比BLEU和METEOR更为适用。然而,选择哪个指标最好,往往取决于特定任务的需求和目标。
什么是n-gram?
n-gram是自然语言处理(NLP)中一种基本的概念,它指的是文本中连续的n个项(可以是音节、字或词)组成的序列。n-gram模型通过考察这些连续项的出现概率来捕捉文本中的语言规律,从而用于各种语言模型和文本处理任务,如拼写检查、语音识别、机器翻译以及搜索引擎中的查询预测等。
n-gram的类型
- Unigram (1-gram):单个项的序列。例如,在句子“The quick brown fox”中,unigrams是“The”、“quick”、“brown”、“fox”。
- Bigram (2-gram):连续的两个项组成的序列。同一句子中的bigrams包括“Thw quick”、“quick brown”、“brown fox”。
- Trigram (3-gram):连续的三个项。在上述示例中,“The quick brown”和“quick brown fox”就是trigrams。
- 以此类推,你可以有更高维度的n-grams。
n-gram的应用
n-gram模型在很多NLP任务中都非常有用,因为它们简单且有效。它们可以用来建模和预测文本中的词序列概率,这对于理解和生成自然语言至关重要。以下是一些n-gram模型的应用示例:
- 文本生成:给定一个或多个词的序列,n-gram模型可以预测下一个最可能出现的词,这对于自动文本生成很有用。
- 语音识别:在语音到文本的转换中,n-gram可以帮助识别和预测词序列,提高识别的准确性。
- 拼写检查和更正:n-gram模型可以用来识别和建议更正拼写错误,因为错误的拼写通常会导致不常见的词序列出现。
- 机器翻译:在将一种语言翻译成另一种语言的过程中,n-gram模型有助于捕捉源语言和目标语言之间的语言规律,从而生成更自然、准确的翻译。
n-gram的限制
尽管n-gram模型在很多场景中都非常有用,但它们也有一些局限性。例如,随着n的增加,模型的复杂度和所需的存储空间也会大幅增加(称为“维度灾难”)。此外,n-gram模型也不能很好地捕捉长距离依赖(即远距离的词之间的关系),这在某些语言结构中非常重要。因此,尽管n-gram模型是构建更复杂NLP系统的基石,但它们通常会与其他模型和技术结合使用,以克服这些限制。
什么是TF-IDF?
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索和文本挖掘的常用加权技术。它反映了一个词在文档集合中的重要性。基本思想是:如果某个词在一个文档中频繁出现,同时在其他文档中很少出现,则认为这个词具有很好的类别区分能力,对理解文档的内容非常重要。
TF-IDF计算
TF-IDF由两部分组成:词频(TF)和逆文档频率(IDF)。具体计算如下:
-
词频(TF):词频是指某个词在文档中出现的频率。这个数值表明了一个词在文档中的重要性,但是仅考虑TF可能会偏向于频繁出现的词,而忽略了词的实际重要性。词频(TF)的计算公式通常为某个词在文档中出现次数与文档总词数的比值。
-
逆文档频率(IDF):逆文档频率是一个词的普遍重要性的度量。计算某个词的IDF会考虑整个文档集合,用以降低那些在文档集合中广泛出现的词的重要性。IDF的计算公式是文档集合中文档总数与包含该词的文档数的比值的对数。
TF-IDF值由TF和IDF乘积得到。具体公式如下:
TF-IDF ( t , d ) = TF ( t , d ) × IDF ( t ) \text{TF-IDF}(t, d) = \text{TF}(t, d) \times \text{IDF}(t) TF-IDF(t,d)=TF(t,d)×IDF(t)
其中:
- t t t是某个词,
- d d d是文档,
- TF ( t , d ) \text{TF}(t, d) TF(t,d)是词 t t t在文档 d d d中的词频,
- IDF ( t ) \text{IDF}(t) IDF(t)是词 t t t的逆文档频率。
TF怎么计算?
词频(Term Frequency,简称TF)是衡量一个词在文档中出现频率的指标。它的基本思想是:如果某个词在文档中出现次数越多,那么它在该文档中的重要性就越大。然而,单纯的计数可能会偏向于较长的文档(因为它们自然可能包含更多的词)。因此,词频通常需要进行归一化处理,以便在不同长度的文档间进行公平的比较。
基本计算方法
最简单的词频计算方法是原始计数,即一个词在文档中出现的次数。然而,为了进行有效的比较,通常采用以下几种归一化的方法之一:
-
词频(TF):
T F ( t , d ) = f t , d ∑ t ′ ∈ d f t ′ , d TF(t, d) = \frac{f_{t,d}}{\sum_{t' \in d} f_{t',d}} TF(t,d)=∑t′∈dft′,dft,d
其中, f t , d f_{t,d} ft,d是词 t t t在文档 d d d中出现的次数,分母是文档 d d d中所有词出现次数的总和。这种方法的优点是简单直观,但可能会偏向于较长的文档。 -
词频调整:
- 最大词频归一化:
T F ( t , d ) = 0.5 + 0.5 ⋅ f t , d max { f t ′ , d : t ′ ∈ d } TF(t, d) = 0.5 + 0.5 \cdot \frac{f_{t,d}}{\max\{f_{t',d}: t' \in d\}} TF(t,d)=0.5+0.5⋅max{ft′,d:t′∈d}ft,d
这里,分子是词 t t t在文档 d d d中的出现次数,分母是文档 d d d中出现最频繁的词的出现次数。这种方法试图降低长文档的偏向性,通过将所有的词频数值压缩到0.5到1的范围内。
- 最大词频归一化:
应用场景
词频(TF)是信息检索和文本挖掘中的一个基本概念,常与逆文档频率(IDF)一起用于计算TF-IDF值,从而衡量一个词对于一个文档集中的某个文档的重要性。TF-IDF值越高,表示词对文档的重要性越大。这个概念广泛应用于搜索引擎的关键词权重计算、文本分析、用户兴趣建模等领域。
注意点
尽管TF是一个重要的度量,但它仅仅考虑了词在单个文档中的频率,没有考虑词在整个文档集合中的分布。因此,单独使用TF可能会过高评估那些在许多文档中普遍出现的词的重要性。结合IDF可以更好地评估词的区分能力。
IDF 怎么计算?
逆文档频率(IDF)是一种用于量化单词在文档集合或语料库中的普遍重要性的度量。其基本思想是:如果一个词在很多文档中出现,则这个词的区分能力较低,因此其重要性应该相应减少。相反,如果一个词在较少的文档中出现,则认为这个词更能体现文档的特殊性,因此其重要性更高。
IDF的计算公式通常如下:
IDF ( t ) = log N n ( t ) \text{IDF}(t) = \log \frac{N}{n(t)} IDF(t)=logn(t)N
或为了避免分母为零,使用加一的形式:
IDF ( t ) = log N + 1 n ( t ) + 1 + 1 \text{IDF}(t) = \log \frac{N + 1}{n(t) + 1} + 1 IDF(t)=logn(t)+1N+1+1
其中:
- N N N是语料库中文档的总数。
- n ( t ) n(t) n(t)是包含词 t t t的文档数量。即在这 N N N篇文档中,有 n ( t ) n(t) n(t)篇文档至少出现了一次词 t t t。
- log \log log通常是以2为底或以10为底的对数,但也可以使用自然对数。
通过这种方式,如果一个词在许多文档中出现( n ( t ) n(t) n(t)接近 N N N),其IDF值会接近于0,反映出这个词提供的信息量较小。如果一个词在较少的文档中出现,其IDF值较高,意味着这个词能够提供更多的信息,对于区分文档是很有用的。
IDF是TF-IDF(词频-逆文档频率)权重的一部分,TF-IDF通过结合词频(TF)和逆文档频率(IDF)来评估一个词在文档中的重要性。这种方法常用于信息检索和文本挖掘中的特征提取,以及搜索引擎中的文档或网页的排名。
TF-IDF的应用
TF-IDF可以用于多种场景,包括:
- 文档相似性:计算两个文档的TF-IDF向量的余弦相似度,来评估它们的相似性。
- 关键词提取:文档中TF-IDF值高的词可以视为该文档的关键词。
- 文档分类和聚类:使用文档的TF-IDF向量作为特征,来进行文档分类或聚类分析。
- 搜索引擎评分:在搜索引擎中,TF-IDF可以用来评估查询词与文档的相关性,从而影响搜索结果的排名。
TF-IDF的优势在于它简单易理解,且在实际应用中效果良好,特别是在处理文档的相关性和文档内关键词的重要性时。然而,它也有局限性,例如不能完全捕捉词之间的上下文关系,因此在一些需要深层次文本理解的应用中,可能会与其他更复杂的模型(如词嵌入或深度学习模型)结合使用。
什么是BLEU?METEOR?ROUGE?计算公式分别是什么?
BLEU(Bilingual Evaluation Understudy),METEOR(Metric for Evaluation of Translation with Explicit ORdering),和ROUGE(Recall-Oriented Understudy for Gisting Evaluation)都是评估自然语言处理任务的自动评估指标,特别是在机器翻译和文本摘要生成等领域。下面是每个指标的简要说明和计算公式。
BLEU
BLEU用于评估机器翻译质量,它通过比较机器翻译的文本和一个或多个参考翻译来工作。BLEU主要关注词汇的精确匹配,特别是n-gram的匹配。
计算公式:
- BLEU的计算基于n-gram的精确度,通常n取1到4。对于每个n-gram,计算其在机器翻译中出现次数与在参考翻译中出现次数的最小值,然后除以机器翻译中该n-gram的总数,得到n-gram精确度。
- 计算所有n-gram精确度的几何平均值,并乘以一个简短惩罚因子(brevity penalty, BP)来得到BLEU分数。
BLEU = B P ⋅ exp ( ∑ n = 1 N w n log ( p n ) ) \text{BLEU} = BP \cdot \exp\left(\sum_{n=1}^{N} w_n \log(p_n)\right) BLEU=BP⋅exp(n=1∑Nwnlog(pn))
其中, p n p_n pn是n-gram精确度, w n w_n wn是权重(通常取相等值),BP是简短惩罚因子,用于惩罚过短的翻译输出。
METEOR
METEOR考虑了同义词和词形变化,尝试与人类评判标准更为一致。它基于单词级别的匹配,包括精确、同义词和词干匹配。
计算公式:
METEOR分数是基于匹配单词的精确度(Precision)和召回率(Recall)的调和平均数,还会加入一个惩罚因子来考虑词序列的匹配度。
METEOR = ( 1 − Penalty ) ⋅ P ⋅ R α P + ( 1 − α ) R \text{METEOR} = (1 - \text{Penalty}) \cdot \frac{P \cdot R}{\alpha P + (1 - \alpha) R} METEOR=(1−Penalty)⋅αP+(1−α)RP⋅R
其中, P P P是精确度, R R R是召回率, α \alpha α是控制精确度和召回率相对重要性的参数, Penalty \text{Penalty} Penalty是基于单词匹配顺序不一致程度的惩罚因子。
ROUGE
ROUGE主要用于评估自动文摘或机器翻译的质量,侧重于内容的召回率,即参考摘要或翻译中的信息在生成的摘要或翻译中被覆盖的程度。
ROUGE有多个变体,如ROUGE-N、ROUGE-L等。
ROUGE-N
ROUGE-N计算参考摘要和生成摘要之间n-gram的重叠度。
计算公式:
ROUGE-N = ∑ s ∈ { Reference Summaries } ∑ gram n ∈ s Count match ( gram n ) ∑ s ∈ { Reference Summaries } ∑ gram n ∈ s Count ( gram n ) \text{ROUGE-N} = \frac{\sum_{\text{s} \in \{\text{Reference Summaries}\}} \sum_{\text{gram}_n \in \text{s}} \text{Count}_{\text{match}}(\text{gram}_n)}{\sum_{\text{s} \in \{\text{Reference Summaries}\}} \sum_{\text{gram}_n \in \text{s}} \text{Count}(\text{gram}_n)} ROUGE-N=∑s∈{Reference Summaries}∑gramn∈sCount(gramn)∑s∈{Reference Summaries}∑gramn∈sCountmatch(gramn)
其中, Count match ( gram n ) \text{Count}_{\text{match}}(\text{gram}_n) Countmatch(gramn)是n-gram在参考摘要和生成摘要中同时出现的次数,而 Count ( gram n ) \text{Count}(\text{gram}_n) Count(gramn)是n-gram在参考摘要中出现的次数。
ROUGE-L
ROUGE-L(Recall-Oriented Understudy for Gisting Evaluation based on Longest Common Subsequence)是ROUGE评价体系中的一个重要变体,专门用来衡量摘要或翻译文本与参考文本之间的相似度。它基于最长公共子序列(Longest Common Subsequence, LCS)来评估。最长公共子序列是指在两个文本序列中以相同顺序出现,但不必连续(即可以有间断)的最长子序列。ROUGE-L通过考察生成文本和参考文本之间LCS的长度,来评估二者的相似度,特别是在句子层面的流畅度和完整性。
计算公式
ROUGE-L的计算分为三个步骤:首先计算最长公共子序列的长度,然后基于这个长度计算召回率(Recall)、精确率(Precision)和F1分数。召回率是指参考摘要中与生成摘要共享的最长公共子序列的长度占参考摘要长度的比例;精确率是共享的最长公共子序列的长度占生成摘要长度的比例。F1分数是召回率和精确率的调和平均值。
公式如下:
LCS ( X , Y ) \text{LCS}(X, Y) LCS(X,Y) 是序列X和Y的最长公共子序列的长度。
-
召回率 ( R l c s R_{lcs} Rlcs) 是通过将最长公共子序列的长度除以参考摘要的长度来计算的:
R l c s = LCS ( X , Y ) Length of Reference Summary R_{lcs} = \frac{\text{LCS}(X, Y)}{\text{Length of Reference Summary}} Rlcs=Length of Reference SummaryLCS(X,Y)
-
精确率 ( P l c s P_{lcs} Plcs) 是通过将最长公共子序列的长度除以生成摘要的长度来计算的:
P l c s = LCS ( X , Y ) Length of Candidate Summary P_{lcs} = \frac{\text{LCS}(X, Y)}{\text{Length of Candidate Summary}} Plcs=Length of Candidate SummaryLCS(X,Y)
-
F1分数 是精确率和召回率的调和平均值:
F l c s = ( 2 ⋅ P l c s ⋅ R l c s ) ( P l c s + R l c s ) F_{lcs} = \frac{(2 \cdot P_{lcs} \cdot R_{lcs})}{(P_{lcs} + R_{lcs})} Flcs=(Plcs+Rlcs)(2⋅Plcs⋅Rlcs)
ROUGE-L的优势在于能够以不需要连续匹配的方式捕捉到句子级的结构相似性,因此它对句子的重排列较为鲁棒。这使得ROUGE-L成为评估那些重组句子元素以生成摘要或翻译的系统的有用指标。
相关文章:

【名词解释】ImageCaption任务中的CIDEr、n-gram、TF-IDF、BLEU、METEOR、ROUGE 分别是什么?它们是怎样计算的?
CIDEr CIDEr(Consensus-based Image Description Evaluation)是一种用于自动评估图像描述(image captioning)任务性能的指标。它主要通过计算生成的描述与一组参考描述之间的相似性来评估图像描述的质量。CIDEr的独特之处在于它考…...
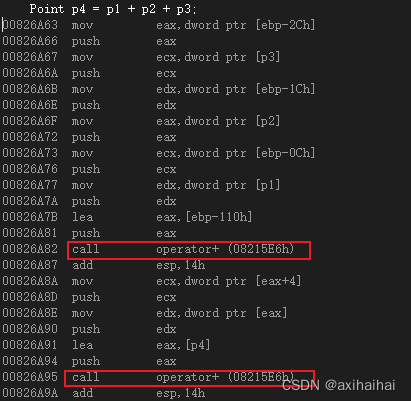
C++其他语法..
1.运算符重载 之前有一个案例如下所示 其中我们可以通过add方法将两个点组成一个新的点 class Point {friend Point add(Point, Point);int m_x;int m_y; public:Point(int x, int y) : m_x(x), m_y(y) {}void display() {cout << "(" << m_x <<…...

【Vue3源码学习】— CH2.6 effect.ts:详解
effect.ts:详解 1. 理解activeEffect1.1 定义1.2 通过一个例子来说明这个过程a. 副作用函数的初始化b. 执行副作用函数前c. 访问state.countd. get拦截器中的track调用e. 修改state.count时的set拦截器f. trigger函数中的依赖重新执行 1.3 实战应用1.4 activeEffect…...
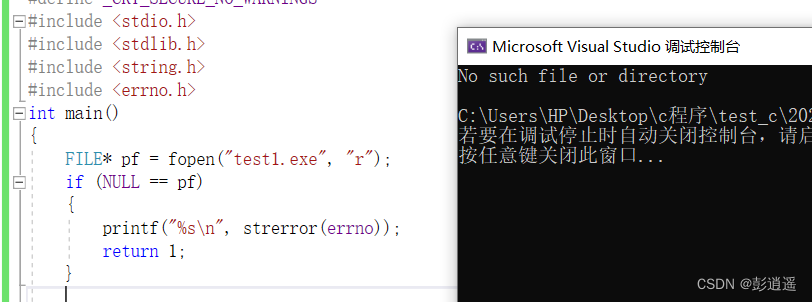
C语言:文件操作(一)
目录 前言 1、为什么使用文件 2、什么是文件 2.1 程序文件 2.2 数据文件 2.3 文件名 3、文件的打开和关闭 3.1 文件指针 3.2 文件的打开和关闭 结(一) 前言 本篇文章将介绍C语言的文件操作,在后面的内容讲到:为什么使用文…...

集中进行一系列处理——函数
需要多次执行相同的处理,除了编写循环语句之外,还可以集中起来对它进行定义。 对一系列处理进行定义的做法被称为函数,步骤,子程序。 对函数进行定一后,只需要调用该函数就可以了。如果需要对处理的内容进行修正&…...

git diff
1. 如何将库文件的变化生成到patch中 git diff --binary commit1 commit2 > test.patch 打patch: git apply test.patch 2. 如何消除trailing whitespace 问题 git diff --ignore-space-at-eol commit1 commit2 > test.patch 打patch: git ap…...
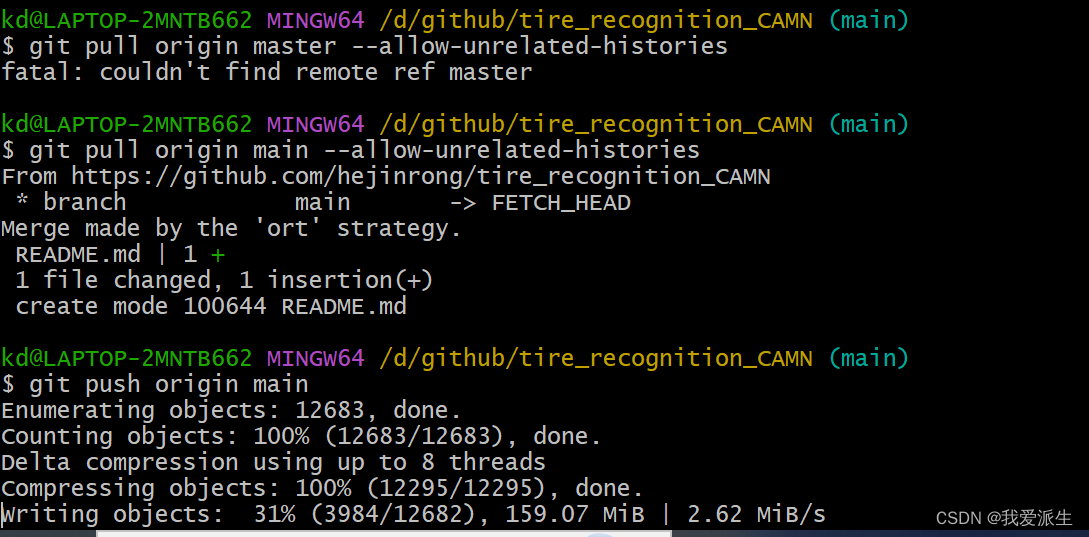
新手使用GIT上传本地项目到Github(个人笔记)
亲测下面的文章很有用处。 1. 初次使用git上传代码到github远程仓库 - 知乎 (zhihu.com) 2. 使用Git时出现refusing to merge unrelated histories的解决办法 - 知乎...

结合《人力资源管理系统》的Java基础题
1.编写一个Java方法,接受一个整数数组作为参数,返回该数组中工资高于平均工资的员工数量。假设数组中的每个元素都代表一个员工的工资。 2.设计一个Java方法,接受一个字符串数组和一个关键字作为参数,返回包含该关键字的姓名的员…...

PostgreSQL备份还原数据库
1.切换PostgreSQL bin目录 配置Postgresql环境变量后可以不用切换 pg_dump 、psql都在postgresql bin目录下,所以需要切换到bin目录执行命令 2.备份数据库 方式一 语法 pg_dump -h <ip> -U <pg_username> -p <port> -d <databaseName>…...

实现读写分离与优化查询性能:通过物化视图在MySQL、PostgreSQL和SQL Server中的应用
实现读写分离与优化查询性能:通过物化视图在MySQL、PostgreSQL和SQL Server中的应用 在数据库管理中,读写分离是一种常见的性能优化方法,它通过将读操作和写操作分发到不同的服务器或数据库实例上,来减轻单个数据库的负载&#x…...

pytest中文使用文档----10skip和xfail标记
1. 跳过测试用例的执行 1.1. pytest.mark.skip装饰器1.2. pytest.skip方法1.3. pytest.mark.skipif装饰器1.4. pytest.importorskip方法1.5. 跳过测试类1.6. 跳过测试模块1.7. 跳过指定文件或目录1.8. 总结 2. 标记用例为预期失败的 2.1. 去使能xfail标记 3. 结合pytest.param方…...
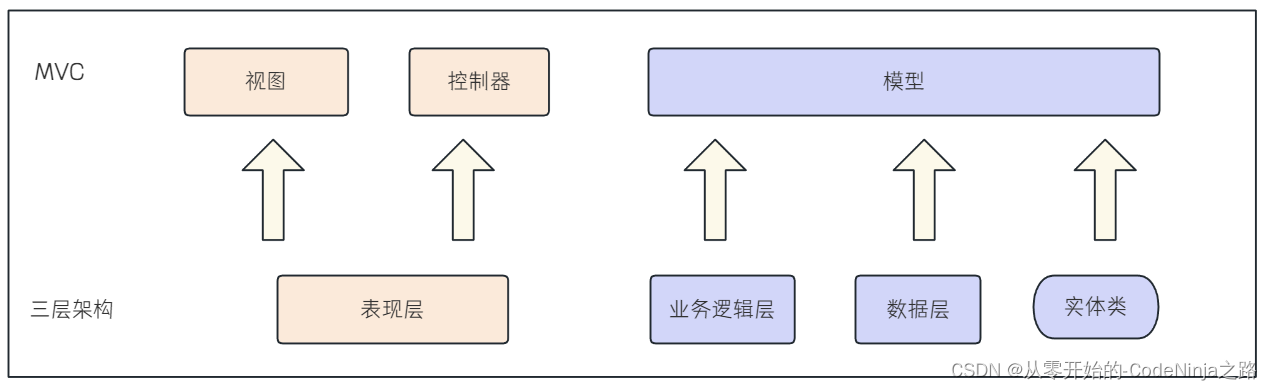
【Spring MVC】快速学习使用Spring MVC的注解及三层架构
💓 博客主页:从零开始的-CodeNinja之路 ⏩ 收录文章:【Spring MVC】快速学习使用Spring MVC的注解及三层架构 🎉欢迎大家点赞👍评论📝收藏⭐文章 目录 Spring Web MVC一: 什么是Spring Web MVC࿱…...

Python(乱学)
字典在转化为其他类型时,会出现是否舍弃value的操作,只有在转化为字符串的时候才不会舍弃value 注释的快捷键是ctrl/ 字符串无法与整数,浮点数,等用加号完成拼接 5不入??? 还有一种格式化的方法…...

OpenHarmony实战:轻量级系统之子系统移植概述
OpenHarmony系统功能按照“系统 > 子系统 > 部件”逐级展开,支持根据实际需求裁剪某些非必要的部件,本文以部分子系统、部件为例进行介绍。若想使用OpenHarmony系统的能力,需要对相应子系统进行适配。 OpenHarmony芯片适配常见子系统列…...

Neo4j基础知识
图数据库简介 图数据库是基于数学里图论的思想和算法而实现的高效处理复杂关系网络的新型数据库系统。它善于高效处理大量的、复杂的、互连的、多变的数据。其计算效率远远高于传统的关系型数据库。 在图形数据库当中,每个节点代表一个对象,节点之间的…...
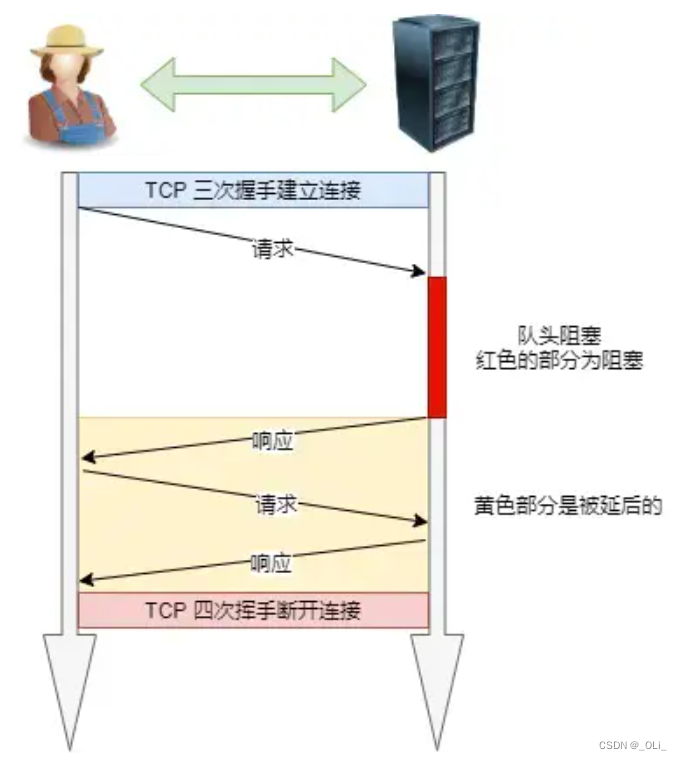
HTTP/1.1 特性(计算机网络)
HTTP/1.1 的优点有哪些? 「简单、灵活和易于扩展、应用广泛和跨平台」 1. 简单 HTTP 基本的报文格式就是 header body,头部信息也是 key-value 简单文本的形式,易于理解。 2. 灵活和易于扩展 HTTP 协议里的各类请求方法、URI/URL、状态码…...

每日一题————P5725 【深基4.习8】求三角形
题目: 题目乍一看非常的简单,属于初学者都会的问题——————————但是实际上呢,有一些小小的坑在里面。 就是三角形的打印。 平常我们在写代码的时候,遇到打印三角形的题,一般简简单单两个for循环搞定 #inclu…...

第三题:时间加法
题目描述 现在时间是 a 点 b 分,请问 t 分钟后,是几点几分? 输入描述 输入的第一行包含一个整数 a。 第二行包含一个整数 b。 第三行包含一个整数 t。 其中,0≤a≤23,0≤b≤59,0≤t, 分钟后还是在当天。 输出描…...

【RAG】内部外挂知识库搭建-本地GPT
大半年的项目告一段落了,现在自己找找感兴趣的东西学习下,看看可不可以搞出个效果不错的local GPT,自研下大模型吧 RAG是什么? 检索增强生成(RAG)是指对大型语言模型输出进行优化,使其能够在生成响应之前引用训练数据来…...

MySQL——锁
全局锁 全局锁是一种数据库锁定机制,它可以锁定整个数据库,阻止其他会话对数据库的读写操作。在MySQL中,全局锁定可以使用FLUSH TABLES WITH READ LOCK命令来实现。执行这个命令后,MySQL将获取一个全局读锁,直到当前会…...

铭豹扩展坞 USB转网口 突然无法识别解决方法
当 USB 转网口扩展坞在一台笔记本上无法识别,但在其他电脑上正常工作时,问题通常出在笔记本自身或其与扩展坞的兼容性上。以下是系统化的定位思路和排查步骤,帮助你快速找到故障原因: 背景: 一个M-pard(铭豹)扩展坞的网卡突然无法识别了,扩展出来的三个USB接口正常。…...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...