机器学习每周挑战——信用卡申请用户数据分析


数据集的截图
# 字段 说明 # Ind_ID 客户ID # Gender 性别信息 # Car_owner 是否有车 # Propert_owner 是否有房产 # Children 子女数量 # Annual_income 年收入 # Type_Income 收入类型 # Education 教育程度 # Marital_status 婚姻状况 # Housing_type 居住方式 # Birthday_count 以当前日期为0,往前倒数天数,-1代表昨天 # Employed_days 雇佣开始日期。以当前日期为0,往前倒数天数。正值意味着个人目前未就业。 # Mobile_phone 手机号码 # Work_phone 工作电话 # Phone 电话号码 # EMAIL_ID 电子邮箱 # Type_Occupation 职业 # Family_Members 家庭人数 # Label 0表示申请通过,1表示申请拒绝# 知道了数据集的情况,我们来看问题 # 问题描述 # 用户特征与信用卡申请结果之间存在哪些主要的相关性或规律?这些相关性反映出什么问题? # # 从申请用户的整体特征来看,银行信用卡业务可能存在哪些风险或改进空间?数据反映出的问题对银行信用卡业务有哪些启示? # # 根据数据集反映的客户画像和信用卡申请情况,如果你是该银行的风控或市场部门负责人,你会提出哪些战略思考或建议? # # 参考分析角度 # 用户画像分析 # # 分析不同人口统计学特征(如性别、年龄、婚姻状况等)对信用卡申请的影响和规律 # 分析不同社会经济特征(如收入、职业、教育程度等)与申请结果的关系 # 特征选取和模型建立 # # 评估不同特征对预测信用卡申请结果的重要性,进行特征筛选 # 建立信用卡申请结果预测模型,评估模型性能 # 申请结果分析 # # 分析不同用户群的申请通过率情况,找到可能的问题原因 # 对申请被拒绝的用户进行细分,寻找拒绝的主要原因# 知道问题后,我们先进行数据预处理
print(data.info()) # 有缺失值
print(data.isnull().sum() / len(data)) # 可以看出有的列缺失值有点多# GENDER 7 Annual_income 23 Birthday_count 22 Type_Occupation 488 # GENDER 0.004522 Annual_income 0.014858 Birthday_count 0.014212 Type_Occupation 0.315245 # Type_Occupation 0.315245 这一列缺失值数据占比有点高了,但是,这一列是职业,跟我们的业务相关性较高,我觉得应该将缺失值单独分为一个属性 # 其他的列的缺失值较少,woe们可以填充,也可以删除,我觉得对于信用卡这种模型精度要求较严的,我们就删除,填充的值不是很准确,可能对模型造成一定的影响 # 观察数据,我们可以发现,ID,电话号,邮箱这种特征对我们来说没有用 ,生日记数我也感觉没用
data['Type_Occupation'] = data['Type_Occupation'].fillna("无")
data = data.dropna()
data = data.drop(['Ind_ID','Mobile_phone','Work_Phone','Phone','EMAIL_ID','Birthday_count'],axis=1)# 分析不同人口统计学特征(如性别、年龄、婚姻状况等)对信用卡申请的影响和规律 # 分析不同社会经济特征(如收入、职业、教育程度等)与申请结果的关系
features = ['GENDER','EDUCATION','Marital_status','Annual_income','Type_Occupation','Type_Income']for i in range(len(features)):# plt.subplot(2,3,i+1)plt.figure()if data[features[i]].dtype == float:data[features[i]] = pd.cut(data[features[i]],bins=10)features_data = data[features[i]].value_counts()plt.bar(features_data.index.astype(str),features_data.values)else:features_data = data.groupby(features[i])['label'].sum()features_data = features_data.sort_values(ascending=False)plt.bar(features_data.index,features_data.values)plt.title(features[i]+"与信用卡申请之间的关系")plt.xlabel(features[i])plt.ylabel("总数量")plt.xticks(rotation=60)plt.tight_layout() 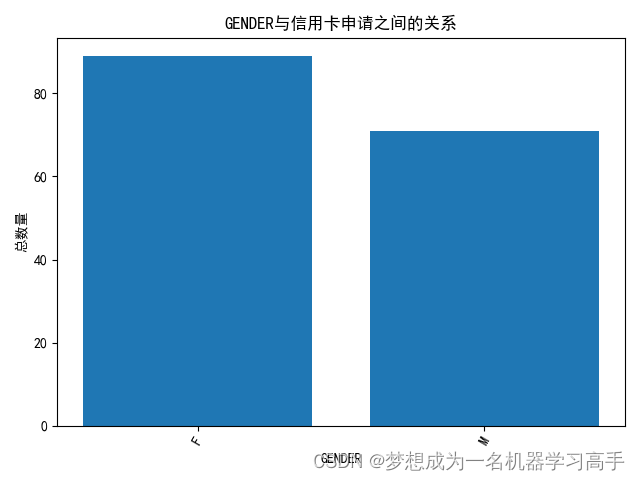


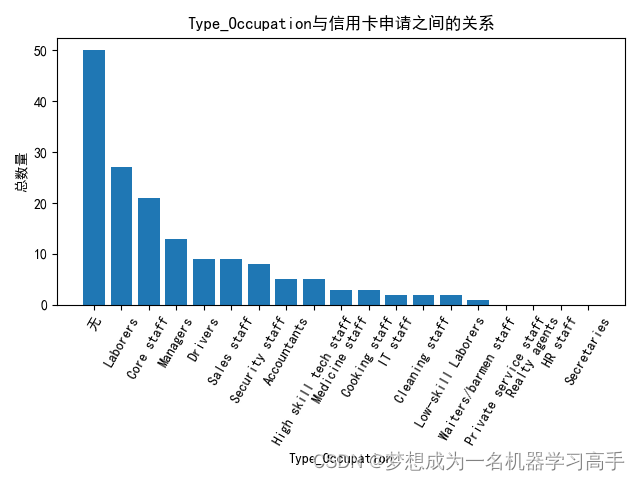
# 这样我们可以看出各个特征列与标签列之间的关系 # 我们看一下标签列的分布情况
labels = data['label'].value_counts()
# print(labels)plt.figure()
plt.bar(labels.index,labels.values)
plt.title("信用卡申请人数比较")
plt.xticks([0,1],['未申请到信用卡','成功申请到信用卡'])
# 由图可以看出,申请到信用卡的人数比没申请到信用卡的人数少,数据存在不均衡,因此我们建立模型时,要注意处理不均横的数据 # 由于计算机只能处理数字,因此我们先将字符型数据转换为数值型,这里我们可以用标签编码或者独热编码。这里我们选择标签编码
data['Annual_income'] = pd.factorize(data['Annual_income'])[0]
data['label'] = data['label'].astype(int)for i in data.columns:if data[i].dtype == object:encode = LabelEncoder()data[i] = encode.fit_transform(data[i])X = data.drop('label',axis=1)
y = data.labelrfc = RandomForestClassifier(n_estimators=100,random_state=42)
rfc.fit(X,y)importance = rfc.feature_importances_
sort_importance = importance.argsort()
feature = X.columnsplt.figure()
plt.barh(range(len(sort_importance)),importance[sort_importance])
plt.yticks(range(len(sort_importance)), [feature[i] for i in sort_importance])
plt.title('特征重要性分析')
plt.xlabel("特征重要性")# plt.show()# 通过特征重要性分析我们可以看出离职天,年收入和职业类型与信用卡的申请有很大的关联X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=42)#分离少数类和多数类
X_minority = X_train[y_train == 1]
y_minority = y_train[y_train == 1]
X_majority = X_train[y_train == 0]
y_majority = y_train[y_train == 0]
X_minority_resampled = resample(X_minority, replace=True, n_samples=len(X_majority), random_state=42)
y_minority_resampled = resample(y_minority, replace=True, n_samples=len(y_majority), random_state=42)
new_X_train = pd.concat([X_majority, X_minority_resampled])
new_y_train = pd.concat([y_majority, y_minority_resampled])rfc = RandomForestClassifier(n_estimators=100,random_state=42)
rfc.fit(new_X_train,new_y_train)
rfc_y_pred = rfc.predict(X_test)class_report_rfc = classification_report(y_test,rfc_y_pred)
print(class_report_rfc)# 有了准确率,F1分数等,我们来绘制混淆矩阵
rfc_corr = confusion_matrix(y_test,rfc_y_pred)
plt.figure()
sns.heatmap(rfc_corr,annot=True,fmt='g')
plt.title('随机森林的混淆矩阵')
# plt.show()
print(rfc.predict_proba(X_test)[:1])
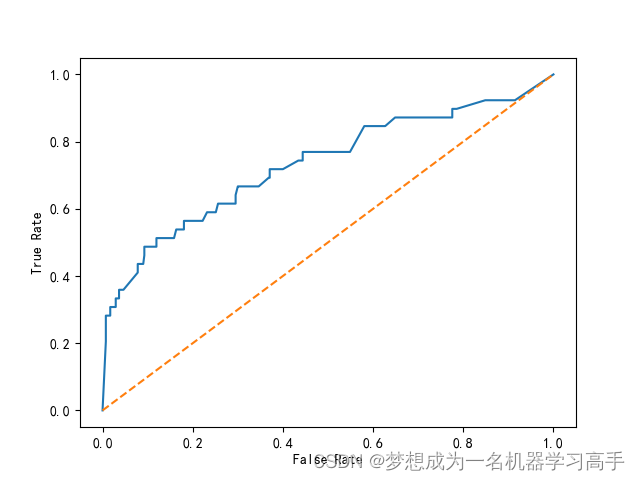
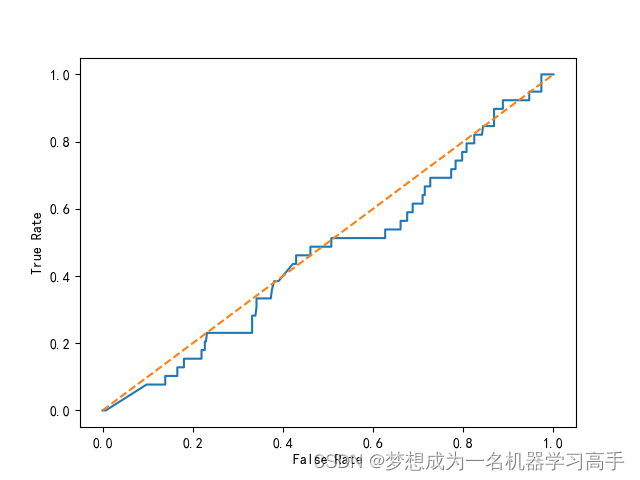
rfc_fpr,rfc_tpr,_ = roc_curve(y_test,rfc.predict_proba(X_test)[:,1])
rfc_roc = auc(rfc_fpr,rfc_tpr)plt.figure()
plt.plot(rfc_fpr,rfc_tpr,label='ROC(area = %0.2f)')
plt.plot([0,1],[0,1],linestyle='--')
plt.xlabel("False Rate")
plt.ylabel("True Rate")svm = SVC(kernel='rbf',probability=True,random_state=42)
svm.fit(new_X_train,new_y_train)
svm_y_pred = svm.predict(X_test)class_report_svm = classification_report(y_test,svm_y_pred)
print(class_report_svm)# 混淆矩阵
svm_corr = confusion_matrix(y_test,svm_y_pred)
plt.figure()
sns.heatmap(svm_corr,annot=True,fmt='g')
plt.title('支持向量机(SVM)的混淆矩阵')svm_fpr,svm_tpr,_ = roc_curve(y_test,svm.predict_proba(X_test)[:,1])
svm_roc = auc(svm_fpr,svm_tpr)plt.figure()
plt.plot(svm_fpr,svm_tpr,label='ROC(area = %0.2f)')
plt.plot([0,1],[0,1],linestyle='--')
plt.xlabel("False Rate")
plt.ylabel("True Rate")Xgb = xgb.XGBClassifier(random_state=42,use_label_encoder=False)
Xgb.fit(new_X_train,new_y_train)
Xgb_y_pred = Xgb.predict(X_test)class_report_Xgb = classification_report(y_test,Xgb_y_pred)
print(class_report_Xgb)# 混淆矩阵
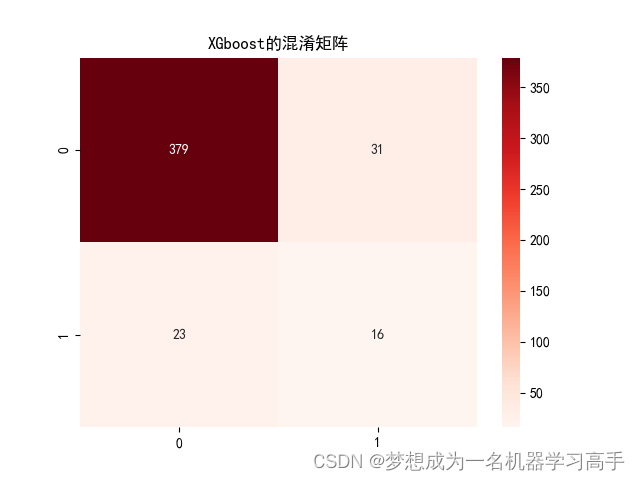
Xgb_corr = confusion_matrix(y_test,Xgb_y_pred)
plt.figure()
sns.heatmap(Xgb_corr,annot=True,fmt='g')
plt.title('XGboost的混淆矩阵')Xgb_fpr,Xgb_tpr,_ = roc_curve(y_test,Xgb.predict_proba(X_test)[:,1])
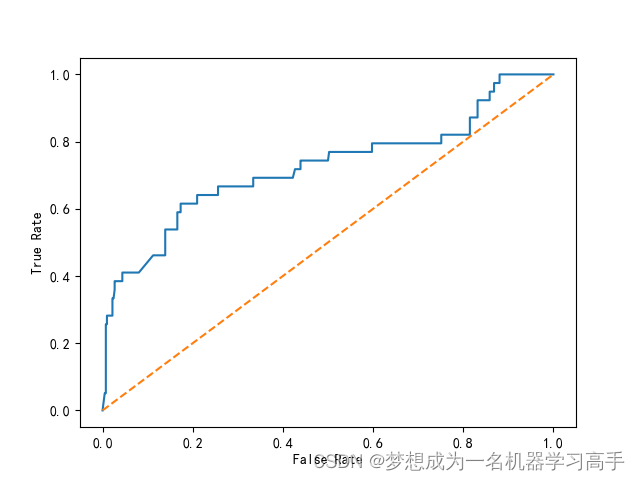
Xgb_roc = auc(Xgb_fpr,Xgb_tpr)plt.figure()
plt.plot(Xgb_fpr,Xgb_tpr,label='ROC(area = %0.2f)')
plt.plot([0,1],[0,1],linestyle='--')
plt.xlabel("False Rate")
plt.ylabel("True Rate")plt.show() 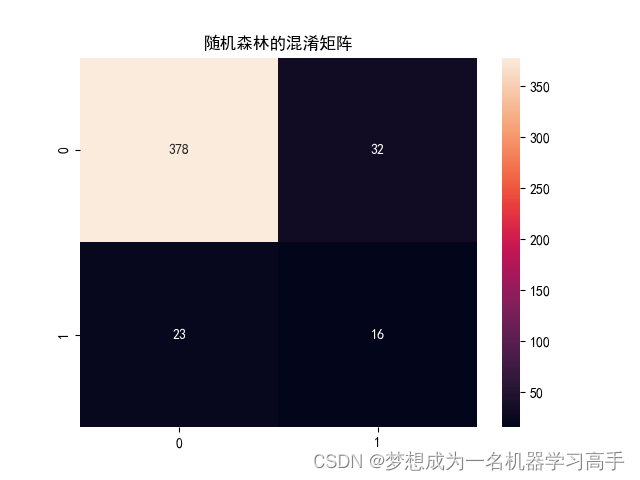

precision recall f1-score support (随机森林)
0 0.94 0.92 0.93 410 (0和1代表着标签列的0和1)
1 0.33 0.41 0.37 39
accuracy 0.88 449
macro avg 0.64 0.67 0.65 449
weighted avg 0.89 0.88 0.88 449
precision recall f1-score support (SVM)
0 0.95 0.05 0.10 410
1 0.09 0.97 0.16 39
accuracy 0.13 449
macro avg 0.52 0.51 0.13 449
weighted avg 0.88 0.13 0.10 449
precision recall f1-score support (XGboost)
0 0.94 0.92 0.93 410
1 0.34 0.41 0.37 39
accuracy 0.88 449
macro avg 0.64 0.67 0.65 449
weighted avg 0.89 0.88 0.88 449
相关文章:
机器学习每周挑战——信用卡申请用户数据分析
数据集的截图 # 字段 说明 # Ind_ID 客户ID # Gender 性别信息 # Car_owner 是否有车 # Propert_owner 是否有房产 # Children 子女数量 # Annual_income 年收入 # Type_Income 收入类型 # Education 教育程度 # Marital_status 婚姻状况 # Housing_type 居住…...
Vulnhub:WESTWILD: 1.1
目录 信息收集 arp nmap nikto whatweb WEB web信息收集 dirmap enm4ulinux sumbclient get flag1 ssh登录 提权 横向移动 get root 信息收集 arp ┌──(root㉿ru)-[~/kali/vulnhub] └─# arp-scan -l Interface: eth0, type: EN10MB, MAC: 0…...
[C#]winform使用OpenCvSharp实现透视变换功能支持自定义选位置和删除位置
【透视变换基本原理】 OpenCvSharp 是一个.NET环境下对OpenCV原生库的封装,它提供了大量的计算机视觉和图像处理的功能。要使用OpenCvSharp实现透视变换(Perspective Transformation),你首先需要理解透视变换的原理和它在图像处理…...
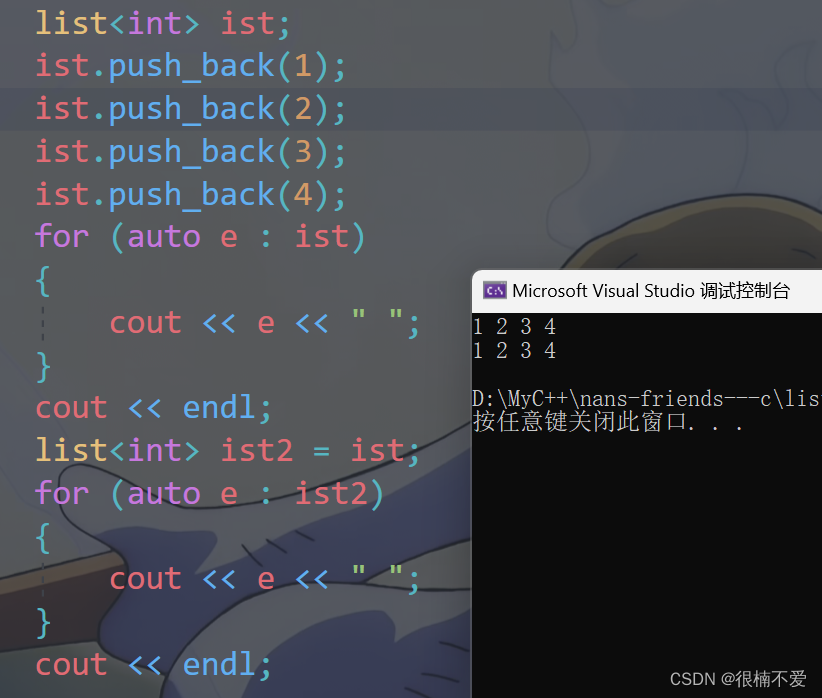
C++——list类及其模拟实现
前言:这篇文章我们继续进行C容器类的分享——list,也就是数据结构中的链表,而且是带头双向循环链表。 一.基本框架 namespace Mylist {template<class T>//定义节点struct ListNode{ListNode<T>* _next;ListNode<T>* _pre…...
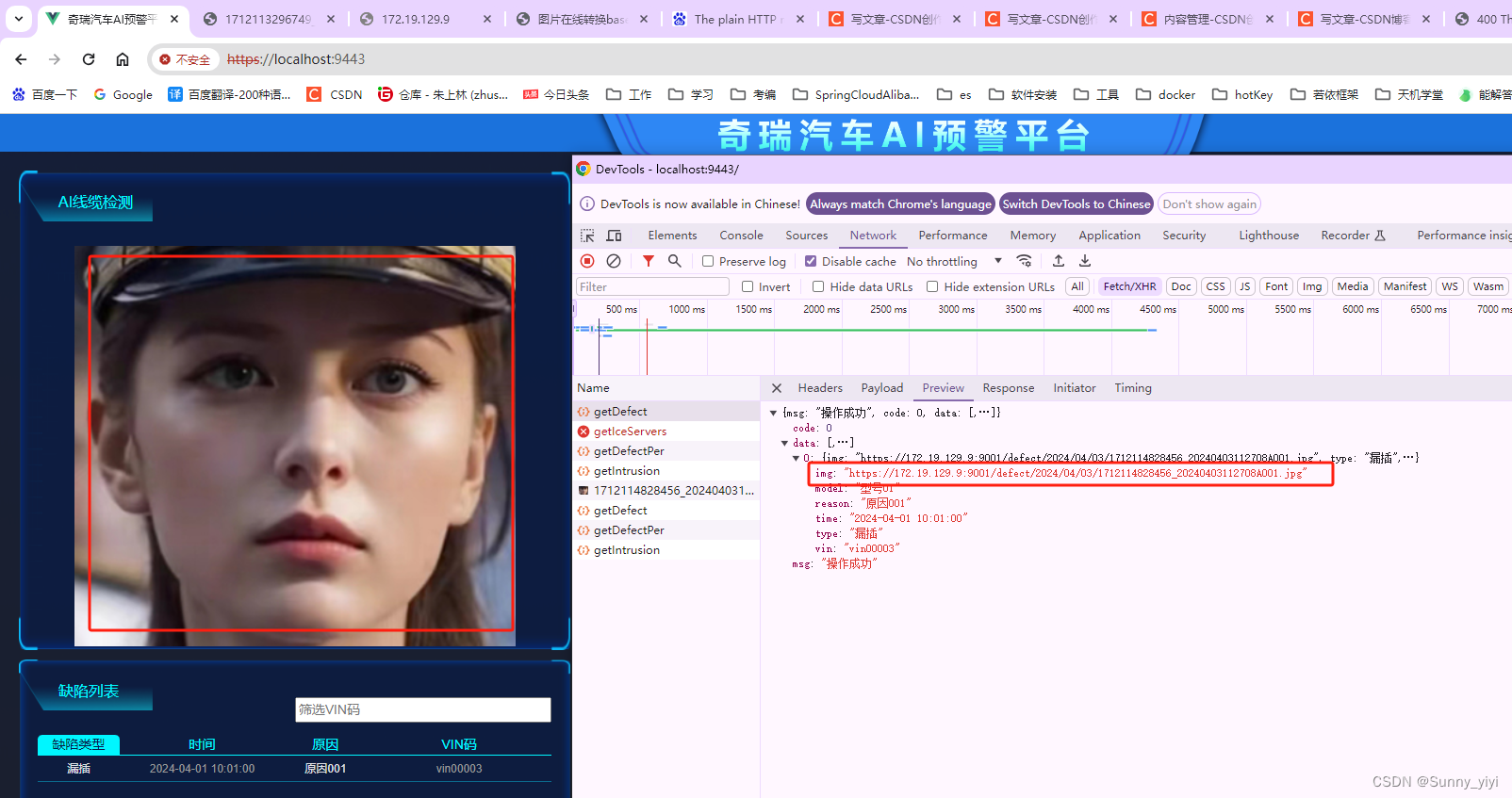
https访问http的minio 图片展示不出来
问题描述:请求到的图片地址单独访问能显示,但是在网页中展示不出来 原因:https中直接访问http是不行的,需要用nginx再转发一下 nginx配置如下(注意:9000是minio默认端口,已经占用,…...

【Python整理】 Python知识点复习
1.Python中__init__()中声明变量必须都是self吗? 在Python中的类定义里,init() 方法是一个特殊的方法,称为类的构造器。在这个方法中,通常会初始化那些需要随着对象实例化而存在的实例变量。使用 self 是一种约定俗成的方式来引用实例本身。…...

汽车电子行业知识:UWB技术及应用
文章目录 1.什么是UWB技术1.1.UWB测距原理1.2.UWB数据传输原理2.汽车UWB技术应用2.1.UWB雷达2.1.1.信道的冲击响应CIR2.2.舱外检测目标2.3.舱内检测活体2.3.1.活体检测原理2.4.脚踢尾箱开门2.4.1.脚踢检测原理1.什么是UWB技术 UWB(ultra wideband)也叫超宽带技术,是一种使用…...

Claude-3全解析:图片问答,专业写作能力显著领先GPT-4
人工智能技术的飞速发展正在深刻改变着我们的工作和生活方式。作为一名资深的技术爱好者,我最近有幸体验了备受瞩目的AI助手Claude-3。这款由Anthropic公司推出的新一代智能工具展现出了非凡的实力,尤其在图像识别和专业写作领域的表现更是让人眼前一亮&…...

Mac 如何彻底卸载Python 环境?
第一步:首先去应用程序文件夹中,删除关于Python的所有文件; 第二步:打开terminal终端,输入下面命令查看versions下有哪些python版本; ls /library/frameworks/python.framework/versions第三步࿱…...
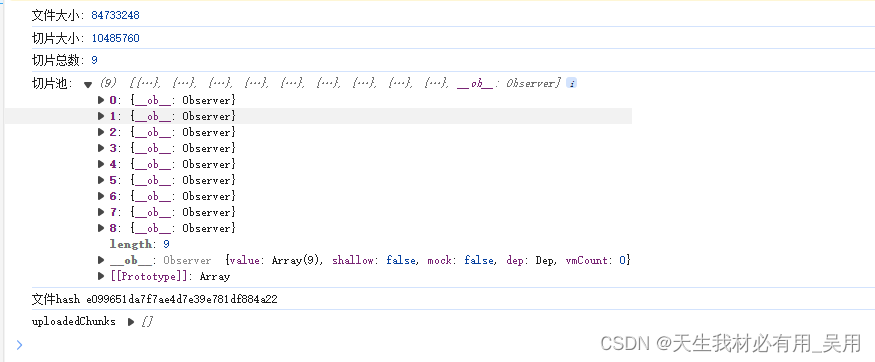
Vue 大文件切片上传实现指南包会,含【并发上传切片,断点续传,服务器合并切片,计算文件MD5,上传进度显示,秒传】等功能
Vue 大文件切片上传实现指南 背景 在Web开发中,文件上传是一个常见的功能需求,尤其是当涉及到大文件上传时,为了提高上传的稳定性和效率,文件切片上传技术便显得尤为重要。通过将大文件切分成多个小块(切片࿰…...

【VUE+ElementUI】el-table表格固定列el-table__fixed导致滚动条无法拖动
【VUEElementUI】el-table表格固定列el-table__fixed导致滚动条无法拖动 背景 当设置了几个固定列之后,表格无数据时,点击左侧滚动条却被遮挡,原因是el-table__fixed过高导致的 解决 在index.scss中直接加入以下代码即可 /* 设置默认高…...

重置gitlab root密码
gitlab-rails console -e production user User.where(id: 1).first user User.where(name: "root").first #输入重置密码命令 user.password"admin123!" #再次确认密码 user.password_confirmation"admin123!" #输入保存命令&am…...

v-text 和v-html
接下来,我讲介绍一下v-text和v-html的使用方式以及它们之间的区别。 使用方法 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8" /><meta name"viewport" content"widthdevice-widt…...
)
学习笔记——C语言基本概念结构体共用体枚举——(10)
1、结构体 定义新的数据类型: 数据类型:char short int long float double 数组 指针 结构体 结构体: 新的自己定义的数据类型 格式: struct 名字{ 成员 1; 成员 2; 。 。 。 …...

VMware虚拟机三种网络模式
VMware虚拟机提供了三种主要的网络连接模式,它们分别是: 桥接模式(Bridged Mode)网络地址转换模式(NAT Mode)仅主机模式(Host-Only Mode) 1. 桥接模式(Bridged Mode&am…...

Ai音乐大师演示(支持H5、小程序)独立部署源码
Ai音乐大师演示(支持H5、小程序)独立部署源码...
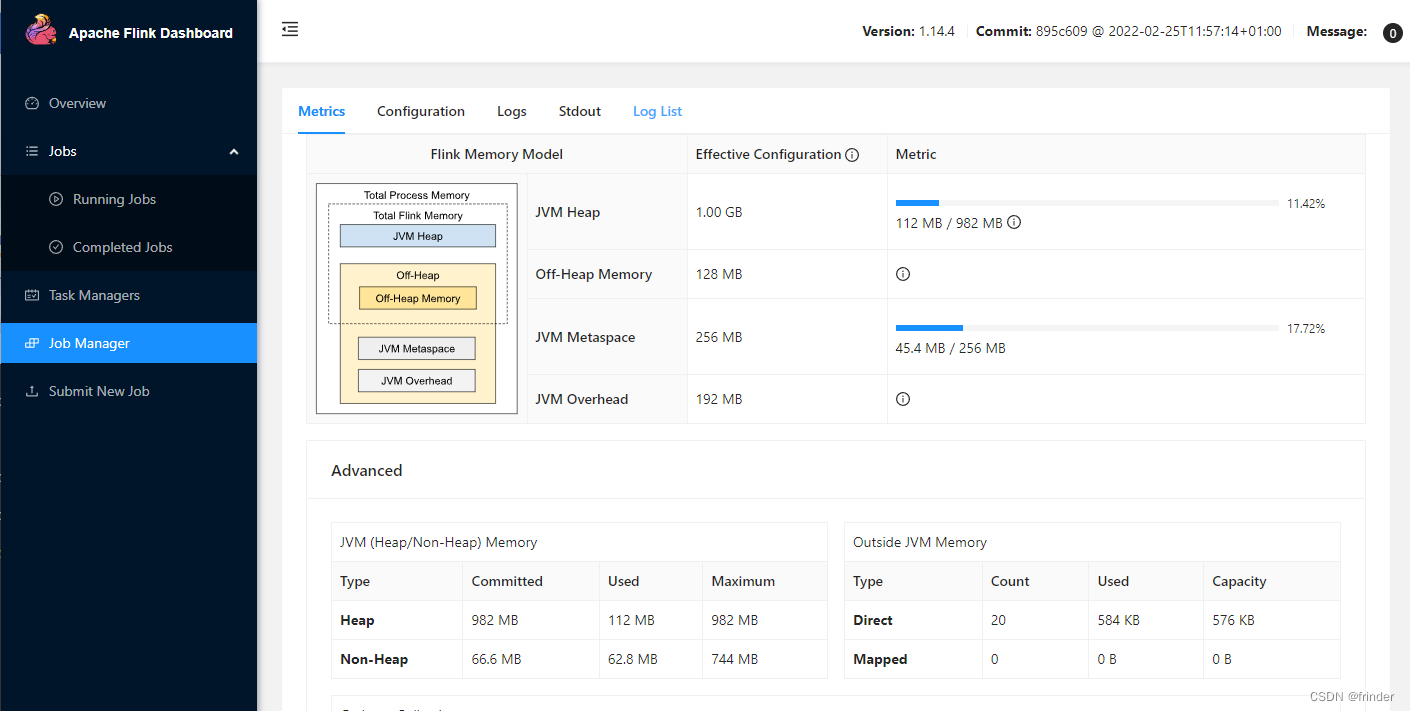
Windows下Docker搭建Flink集群
编写docker-compose.yml 参照:https://github.com/docker-flink/examples/blob/master/docker-compose.yml version: "2.1" services:jobmanager:image: flink:1.14.4-scala_2.11expose:- "6123"ports:- "18081:8081"command: jobma…...
VGA显示器驱动设计与验证
1.原理 场同步信号的单位是像素点 场同步信号的单位是一行 60的含义是每秒钟刷新60帧图像 全0表示黑色 2.1 CLK_gen.v module CLK_gen(input wire sys_clk ,input wire sys_rst_n ,output wire CLK_out ,output wire locked );parameter STATE1b0; reg [1:0] cnt; r…...

jupyter notebook 配置默认文件路径
Jupyter是一种基于Web的交互式计算环境,支持多种编程语言,如Python、R、Julia等。使用Jupyter可以在浏览器中编写和运行代码,同时还可以添加Markdown文本、数学公式、图片等多种元素,非常适合于数据分析、机器学习等领域。 安装 …...

强大缓存清理工具 NetShred X for Mac激活版
NetShred X for Mac是一款专为Mac用户设计的强大缓存清理工具,旨在帮助用户轻松管理和优化系统性能。这款软件拥有直观易用的界面,即使是初次使用的用户也能快速上手。 软件下载:NetShred X for Mac激活版下载 NetShred X能够深入扫描Mac系统…...
)
【声纳与人工智能融合——从理论前沿到自主系统实战】第四章 认知声纳与自适应信号处理(AI+SP深度融合)
目录 第四章 认知声纳与自适应信号处理(AI+SP深度融合) 4.1 认知声纳系统架构与感知循环 4.1.1 感知-规划-行动闭环设计 4.1.1.1 动态环境感知与反馈机制 4.1.1.2 基于强化学习的波形自适应选择 4.1.2 开放式认知声纳体系结构 4.1.2.1 硬件可重配置架构(SDR) 4.1.2…...

SSE vs. WebSocket:实时通信技术的深度对比与选型指南
1. 实时通信技术的基本概念 现代Web应用对实时性的需求越来越高,从股票行情更新到在线聊天室,都需要服务器能够快速将数据推送到客户端。在这个领域,SSE(Server-Sent Events)和WebSocket是两种主流技术方案。我第一次接…...

QSS样式表避坑指南:为什么你的Qt界面美化总是不生效?
QSS样式表深度解析:从失效原理到高效美化实战 在Qt界面开发中,QSS(Qt Style Sheets)作为界面美化的核心工具,其重要性不亚于CSS之于网页设计。然而许多开发者在使用过程中常遇到样式失效、优先级混乱等问题。本文将系统…...

OpenClaw技能市场盘点:10个适配Qwen3.5-4B-Claude的实用模块
OpenClaw技能市场盘点:10个适配Qwen3.5-4B-Claude的实用模块 1. 为什么需要关注技能市场? 去年冬天,当我第一次在本地部署OpenClaw时,最让我惊喜的不是框架本身,而是它背后那个不断生长的技能市场。作为一个长期被重…...

Squeezer性能优化指南:提升dApp响应速度的7个技巧
Squeezer性能优化指南:提升dApp响应速度的7个技巧 【免费下载链接】squeezer Squeezer Framework - Build serverless dApps 项目地址: https://gitcode.com/gh_mirrors/sq/squeezer Squeezer Framework作为构建无服务器去中心化应用(dApps)的强大工具&#…...

Raspotify多用户环境配置终极指南:在家庭网络中共享Spotify音乐服务
Raspotify多用户环境配置终极指南:在家庭网络中共享Spotify音乐服务 【免费下载链接】raspotify A Spotify Connect client that mostly Just Works™ 项目地址: https://gitcode.com/gh_mirrors/ra/raspotify 想要在家庭网络中打造一个完美的音乐共享系统吗…...
VSCode 高效开发:配置 Pixel Dream Workshop 模型调用的代码片段与插件
VSCode 高效开发:配置 Pixel Dream Workshop 模型调用的代码片段与插件 1. 为什么需要优化开发工作流 如果你经常使用Pixel Dream Workshop这类AI模型进行开发,可能会遇到一个共同痛点:每次调用API时都要重复编写相似的请求代码,…...

RDP Wrapper终极指南:解锁Windows多用户远程桌面完整功能
RDP Wrapper终极指南:解锁Windows多用户远程桌面完整功能 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap RDP Wrapper Library是一个革命性的开源工具,它能够让Windows家庭版用户也能享受到…...

AI图像放大神器Upscayl:告别模糊时代的终极解决方案
AI图像放大神器Upscayl:告别模糊时代的终极解决方案 【免费下载链接】upscayl 🆙 Upscayl - Free and Open Source AI Image Upscaler for Linux, MacOS and Windows built with Linux-First philosophy. 项目地址: https://gitcode.com/GitHub_Trendi…...

如何永久保存微信聊天记录?WeChatExporter 开源工具帮你解决数据备份难题
如何永久保存微信聊天记录?WeChatExporter 开源工具帮你解决数据备份难题 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾担心微信聊天记录会随着手机…...