【Python笔记20230307】
基础
编码、解码
str.encode('utf-8') # 编码
str.decode('utf-8') # 解码
关键字
import keyword
keyword.kwlist
格式化输出
%
'''
占位符:%s 字符串%d 整数%f 浮点数
'''
'Hello, %s' % 'world'
'Hi, %s, you have $%d.' % ('Michael', 1000000)
'''
占位符的修饰符
-左对齐 .小数点后位数 0左边补零
'''
# 3以左对齐占两个占位的形式输出,1以右对齐占两个占位的形式,并且前面填零补齐的形式输出
print("%-2d xx %02d" % (3, 1))
# 小数点后两位的形式输出:3.14
print('%.2f' % 3.1415926)# %s可以将任何数据转换为字符串
'Age: %s. Gender: %s' % (25, True) # 表示以字符串形式输出25和True
format
用传入的参数依次替换字符串内的占位符{0}、{1}…
print('Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125))
# 'Hello, 小明, 成绩提升了 17.1%'
输入
# python3
Name=input(“请输入你的名字:”)
print(“你的姓名是%s”%Name)
# python2
Name=raw_input(“请输入你的名字:”)
print(“你的姓名是%s”%Name)
数据结构
字符串
len(str) # 长
str[n] # 返回索引n的值
str['起始':'结束':'步长'] # 切片: 不包含‘结束’;‘步长’为负数时倒序遍历
str.find('xx') # 包含“xx”返回索引值,否报异常
str.rfind('xx') # 从右边开始查
str.index('xx') # 包含“xx”返回索引值,否返回-1
str.count('xx') # 出现次数
str.count('xx' , 0 , len(str)) # 起始下标,终止下标
str.replace('a','A',n) # a替换为A,替换n个
str.split(',',n) # 以","分割,分割n次
str.split('\n') str. splitlines() # 以换行符分割
str.partition('xx') # 把str分割成三部分(xx前,xx,xx后)
str.ljust(n) # 左对齐,n:字符串总长度
str.rjust(n) # 右对齐
str.center(n) # 居中
str.lstrip() # 删除左边空白字符
str.rstrip() # 删除右边空白字符
str.strip() # 删除两边空白字符
str.strip('x') # 删除两边x字符
str = ['a', 'b', 'c']
'-'.join(str) # 按指定格式合并字符串:a-b-c
列表
# 创建
list = []
# 遍历值
for i in list:print(i)
# 遍历索引及值
for index,name in list:print(index,name)list.count('xx') # xx出现的次数
list.append('xx') # 添加元素到末尾
list.insert(index,'xx') # 指定坐标插入
list.extend(list2) # 添加集合到末尾
list[1] = 'xx' # 修改
del list[index] # 根据下标删除元素
list.pop() # 删除最后一个元素
list.pop('xx') # 删除并返回索引值为xx的元素;list为空,会抛异常
list.remove('xx') # 删除第一个出现的xx
list.sort(reverse=True) # 排序,默认升序;reverse=True降序
list.reverse() # 翻转元素顺序
x in/not in list # x是否存在
元祖
Python的元组与列表类似,不同之处在于元组的元素不能修改。元组使用小括号,列表使用防括号。
tt = 3*('a', 2)
print(tt)
('a', 2, 'a', 2, 'a', 2)# 与字符串一样,元组可以进行连接、索引和切片等操作
t1 = (1, 'two', 3)
t2 = (t1, 3.25)
print(t2)
print((t1 + t2))
print((t1 + t2)[3])
print((t1 + t2)[2:5])('a', 2, 'a', 2, 'a', 2)
((1, 'two', 3), 3.25)
(1, 'two', 3, (1, 'two', 3), 3.25)
(1, 'two', 3)
(3, (1, 'two', 3), 3.25)
字典
dict 作为 Python 的关键字和内置函数,变量名不建议命名为 dict。
键一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
d = {key1 : value1, key2 : value2 }
d[key] = value # 修改、添加
del d[key] # 删除
d.keys() # 返回所有key-列表
d.values() # 返回所有value-列表
d.items() # 返回所有key、value-元祖
d.has_key(key) # 是否包含key
# 排序
a = {8:'b',1:'c',2:'a'}
b = sorted(a.items(),key=lambda x:x[0])
b2 = sorted(a.items(),key=lambda x:x[1])
print('key排序:%s'%b)
print('value排序: %s'%b2)
列表推导式
将某种操作应用到序列中的一个值上。它会创建一个新列表
L = [x**2 for x in range(1,7)]
print(L)
[1, 4, 9, 16, 25, 36]列表推导中的for从句后面可以有一个或多个if语句和for语句,它们可以应用到for子句产生的值。这些附加从句可以修改第一个for从句生成的序列中的值,并产生一个新的序列。例如,
mixed = [1, 2, 'a', 3, 4.0]
print([x**2 for x in mixed if type(x) == int])
对mixed中的整数求平方,输出:[1, 4, 9]
json序列化
json只适用简单的数据类型(字典、列表、字符串)
json.dumps(data) # 序列化
json.loads(data) # 反序列化import json
data = {'name':'张三','age':18,
}with open('a.txt','w',encoding='utf8') as f:f.write(json.dumps(data))#json.dump(data,f) 等同上面写法with open('a.txt','r',encoding='utf8') as f:data=json.loads(f.read())# data=json.load(f) 等同上面写法print(data['name'])
pickle序列化
import pickle
# pickle 只适用python所有的数据类型
# 用法和json完全一致,把‘json’换成‘pickle’即可
# (注意读写时是二进制文件)
pickle.dumps(data) # 序列化
pickle.loads(data) # 反序列化
排序(sorted)
sort 与 sorted 区别:
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
sorted(iterable, key=None, reverse=False)
# iterable:指定要排序的list或者iterable
# key:用来进行比较的元素
# reverse:reverse = True 降序 , reverse = False 升序(默认)
时间模块
格式输出
strftim(‘格式’, struct_time元组) 格式化的字符串
strftim(‘格式化的字符串’,‘格式’) struct_time元组
# 获取当前时间戳
time.time() # 返回:1970年1月1日午夜(历元)至今过了n秒
# 获取当前时间元组
time.localtime(time.time()) # 返回:struct_time元组
# 获取格式化的时间
time.asctime(struct_time元组)
time.ctime(时间戳)# 格式化日期
time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
'2023-02-27 15:48:42'
time.strftime("%a %b %d %H:%M:%S %Y", time.localtime())
'Mon Feb 27 15:48:46 2023'
time.mktime(time.strptime("Wed May 22 15:52:51 2019","%a %b %d %H:%M:%S %Y"))
1558511571.0
struct_time元组:
| 序号 | 属性 | 值 |
|---|---|---|
| 0 | tm_year | 2008 |
| 1 | tm_mon | 1 到 12 |
| 2 | tm_mday | 1 到 31 |
| 3 | tm_hour | 0 到 23 |
| 4 | tm_min | 0 到 59 |
| 5 | tm_sec | 0 到 61 (60或61 是闰秒) |
| 6 | tm_wday | 0到6 (0是周一) |
| 7 | tm_yday | 1 到 366(儒略历) |
| 8 | tm_isdst | -1, 0, 1, -1是决定是否为夏令时的旗帜 |
datatime
import datetime
i = datetime.datetime.now()
print ("当前的日期和时间是 %s" % i)
print ("ISO格式的日期和时间是 %s" % i.isoformat() )
print ("当前的年份是 %s" %i.year)
print ("当前的月份是 %s" %i.month)
print ("当前的日期是 %s" %i.day)
print ("dd/mm/yyyy 格式是 %s/%s/%s" % (i.day, i.month, i.year) )
print ("当前小时是 %s" %i.hour)
print ("当前分钟是 %s" %i.minute)
print ("当前秒是 %s" %i.second)
timedelta(时间的加减)
from datetime import date,timedelta
time = date(2019,4,17)+ timedelta(days=2) # 加两天
time = date(2019,4,17)+ timedelta(days=-1) # 减两天
random模块-随机数
import random
# 随机0-1浮点数
random.random()
# 随机1-3浮点数
random.uniform(1,3)
# 随机1-10整数
random.randint(1,10)
# 随机1-10整数
random.randrange(1,10)
# 列表、字符串、元组随机
random.choice('hello')
random.choice(['hello','hah'])
# 随机取两位
random.sample('hello',2)
# 用于将一个列表中的元素打乱顺序
# 值得注意的是使用这个方法不会生成新的列表,只是将原列表的次序打乱
list=[1,2,3,4,5]
random.shuffle(list)
print(list)
OS模块
os.path.exists(‘文件名’) 判断是否存在
os.rename(’源名’,’新名’) 文件重命名
os.remove(’文件名’) 删除文件
os.rmdir(‘文件夹’) 删除文件夹
os.mkdir(‘文件夹名’) 创建文件夹
os.getcwd() 获取当前目录
os.chdir(‘path’) 切换目录
os.listdir(‘path’) 获取目录列表
os.remove() 删除文件
os.rename() 重命名文件
os.walk() 生成目录树下的所有文件名
os.chdir() 改变目录
os.mkdir/makedirs 创建目录/多层目录
os.rmdir/removedirs 删除目录/多层目录
os.listdir() 列出指定目录的文件
os.getcwd() 取得当前工作目录
os.chmod() 改变目录权限
os.path.basename() 去掉目录路径,返回文件名
os.path.dirname() 去掉文件名,返回目录路径
os.path.join() 将分离的各部分组合成一个路径名
os.path.split() 返回(dirname(),basename())元组
os.path.splitext() (返回 filename,extension)元组
os.path.getatime\ctime\mtim 分别返回最近访问、创建、修改时间
os.path.getsize() 返回文件大小
os.path.exists() 是否存在
os.path.isabs() 是否为绝对路径
os.path.isdir() 是否为目录
os.path.isfile() 是否为文件
加密
import hashlib# md5加密
m = hashlib.md5()
m.update(b"Hello")
print(m.hexdigest())
===============================================================
# sha512加密
s = hashlib.sha512()
s.update(b"Hello")
print(s.hexdigest())
===============================================================
# 创建一个key和内容,再进行处理后加密
import hmac
h = hmac.new('key'.encode(encoding="utf-8"),'msg'.encode(encoding="utf-8"))
print(h.digest()) # 十进制加密
print(h.hexdigest())# 十六进制加密
反射
通过字符串映射或修改程序运行时的状态、属性、方法。
把字符串反射成内存中的对象地址。
"""
1.什么是反射:把字符映射到实例的变量或实例的方法,然后可以去执行调用、修改反射的本质(核心):基于字符串的事件驱动,利用字符串的形式去操作对象/模块中成员(方法、属性)
2.反射的四个重要方法1)getattr获取对象属性/对象方法2)hasattr判断对象是否有对应的属性及方法3)delattr删除指定的属性4)setattr为对象设置内容
"""
class TestObject:def __init__(self, name, age):self.name = nameself.age = agedef test(self):print("执行test方法")def a():print("类的外部方法")if __name__ == '__main__':"""1.getattr 获取对象属性、对象方法"""xiaoyu = TestObject("小于", 20)# 获取对象的属性print(getattr(xiaoyu, "name"))# 获取对象的方法result = getattr(xiaoyu, "test")print(type(result))result()"""2.hasattr 判断对象是否有对应的属性、方法"""if hasattr(xiaoyu, "address"):print(getattr(xiaoyu, "address"))if hasattr(xiaoyu, "name"):print(getattr(xiaoyu, "name"))"""3.delattr 删除属性"""# delattr(xiaoyu,"name")"""4.setattr 为对象设置内容"""# 修改属性的值setattr(xiaoyu, "name", "liuwei")print(getattr(xiaoyu, "name"))# 修改方法setattr(xiaoyu, "test11", a)getattr(xiaoyu, "test11")()# 相当于增加了test11方法xiaoyu.test11()
"""
实现某个业务,定义类,类里面封装了很多方法,提供一个统一的入口能够调用各种方法
业务:登录 退出 注册 注销
"""
class Test:func_list = ["login", "loginOut", "register", "delete"]def login(self):print("这是登录")def loginOut(self):print("这是退出")def register(self):print("这是注册")def delete(self):print("这是注销")# 1.login 2.loginOut 3.register 4.deletedef run(self, num):getattr(self, self.func_list[num - 1])()num = int(input("请输入你的操作(1.login 2.loginOut 3.register 4.delete):"))
Test().run(num)
open 文件
文件的输入/输出都是相对于内存;
in:输入,读入。从硬盘读到内存。
out:输出。从内存写到硬盘。
file = open('/path/file', 'w')
# 写入
str = file.write('xx') # 写入(文件不存在,会新建)
str = file.writelines('set') # 将集合中的每个元素作为一个单独的行写入
# 读取
str = file.read() # 读取全部
str = file.read(num) # 读取num字节
set = file.readlines() # 按行读取全部,并返回一个列表集合
file.readline() # 读取一行
# 光标
num = file.tell() # 光标所在的位置
file.seek(0) # 指定光标位置(0:开始位置)file.close() # 关闭
import shutil
shutil.copyfile('源文件路径', '目的路径') # 复制文件
shutil.move('源文件路径', '目的路径') # 移动文件
# with语句会自动调用close()方法
with open('/path/file', 'r') as f:print(f.read())
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
| 属性 | 描述 |
|---|---|
| file.closed | 返回true如果文件已被关闭,否则返回false。 |
| file.mode | 返回被打开文件的访问模式。 |
| file.name | 返回文件的名称。 |
| file.softspace | 如果用print输出后,必须跟一个空格符,则返回false。否则返回true。 |
函数
函数是组织好的,可重复使用的,用来实现单一或相关功能的代码段。
可变参数
参数必须加*,传递过去之后,会组合成元组
*组成元组,**组成字典
*args:表示可以传多个值
list = [1,2,3,4] # 参数是列表时,调用加* fun(*list)
# 参数必须加 *,传递过去之后,会组合成元组
# * 组成元组,**组成字典
def A(a, b, c=1, *d, **e):print(11, a)print(22, b)print(33, c)print(44, d)print(55, e)A(1, 2, 33, 44, 55, bb='bb')11 1
22 2
33 33
44 (44, 55)
55 {'bb': 'bb'}
全局变量
在代码块中,首先是从当前代码中找是否有这样名字的变量如果有,拿来用,如果没有,再从全局变量中找是否有。
global 变量名:
1、先在全局中找是否有这个变量
2、如果有,拿来用,如果没有,创建并放到全局中,如果想在函数中修改全局变量,将变量声明位global
建议:全局变量命名规则g_num
例: global g_num (不能直接赋值,先声明)
递归
"""
1、函数本身调用本身
2、有反复执行的过程
3、有退出的条件
"""
#输入一个数字求阶乘
num=int(input('输入一个数字求阶乘:'))
def f1(num):if num==1:return 1return(num*f1(num-1))
set=f1(num)
print(set)
类
三大特征:封装、继承、多态
魔法方法
class Person(object):# 实例化类时调用# 创建对象时同时给对象赋值属性# 在java里叫构造方法def __init__(self, name):print('__init__')self.name = name# 创建实例时def __new__(cls, name):print('__new__')return object.__new__(cls)# 在对象转成字符串的时候(打印对象时)调用def __str__(self):print('__str__')return "name is : %s" % (self.name)# 通过'对象()' 或 '类()()'触发def __call__(self):print('__call__')# 会在对象被垃圾回收的时候被调用# 释放资源:比如文件的连接,数据库的连接def __del__(self):print('__del__')A = Person('张三')
print(A)
A()
# 输出
__new__
__init__
__str__
name is : 张三
__call__
__del__
对象的引用数量
import sys
sys.getrefcount('对象')
封装
'''
私有属性和方法:__属性名、__方法名
获取:1、set、get方法 2、实例化对象名._类名__私有属性名
'''
class Person(object):def __init__(self):self.__name = Nonedef getname(self):return self.__namedef setname(self, name):self.__name = namedef delname(self):del self.__namename = property(getname, setname, delname, "说明。。")print(help(Person.name)) # 说明。。
A = Person()
print(A.getname()) # None
A.setname('张三')
print(A.getname()) # 张三
#####################################
# 将 property 函数用作装饰器
class Person(object):def __init__(self):self.__name = None@propertydef name(self):return self.__name@name.getterdef name(self, name):self.__name = name@name.deleterdef name(self):del self.__nameA = Person()
print(A.getname())
A.setname('张三')
print(A.getname())
类属性、实例属性
类属性:直接在类中定义的,与方法平齐,不在方法里的属性。
实例属性:方法里通过self.属性的都是实例属性。
类方法、静态方法
类方法(cls) : @classmethod
静态方法() : @staticmethod
形式上的区别:实例方法隐含的参数为类实例self,而类方法隐含的参数为类本身cls。 静态方法无隐含参数,主要为了类实例也可以直接调用静态方法。
逻辑上:类方法被类调用,实例方法被实例调用,静态方法两者都能调用。主要区别在于参数传递上的区别,实例方法悄悄传递的是self引用作为参数,而类方法悄悄传递的是cls引用作为参数,静态方法没有类似 self、cls 这样的特殊参数
class Person:# 类属性name = '张三'# 普通方法/实例方法def myName(self):print('实例方法.','访问类属性:',self.name)# 类方法,可以访问类属性和类方法@classmethoddef className(cls):print('类方法.','访问类属性:', cls.name)# 静态方法,无法调用任何类属性和类方法@staticmethoddef staticName():print('静态方法.','不能访问类属性')P = Person()
# 实例访问
P.name = '李四'
P.myName() # 实例方法. 访问类属性: 李四
P.className() # 类方法. 访问类属性: 张三
P.staticName() # 静态方法. 不能访问类属性
# 类访问
print(Person.name) # 张三
# Person.myName() # 类不能访问 实例方法
Person.className() # 类方法. 访问类属性: 张三
Person.staticName() # 静态方法. 不能访问类属性
继承
将共性的内容放在父类中,子类只需要关注自己特有的内容。(符合逻辑习惯,利于扩展)
重写父类方法:(子对父)子类中和父类同名的方法,子类的方法会覆盖父类的方法。
# 返回该类的所有父类:类名.__mor__
# 调用父类中的属性
def __init__(self):Father.__init__(self)
# 子类调用父类的方法
super().父类方法()
父类名.父类方法(self)# 多继承(从左向右找)
class C2:def f2(self):print('C2...f2')def hehe(self):print('C2...hehe')class C3:def f3(self):print('C3...f3')def haha(self):print('C3...haha')def hehe(self):print('C3...hehe')class C4(C2):def f4(self):print('C4...f4')def haha(self):print('C4...haha')class C5(C4, C3):def f5(self):print('C5...f5')def hehe(self):print('C5...hehe')c5 = C5()
c5.haha() # C4...haha
c5.hehe() # C5...hehe
判断是否为子类、实例
# A是否为B的子类/A是否为B的实例
Issubclass( A , B )
多态
一个对象在不同的情况下显示不同的形态。因python是弱类型语言,对类型没有限定。Python中不完全支持多态,但是多态的思想,也是能体现的。
变量的类型永远都是通过右侧的值判断,方法中的参数传递任何值都行,但要考虑方法内部的业务逻辑。
'''
多态:1、父类作为参数,可以传递父类和子类对象。2、接口作为参数,只能传递实现对象。所以有两种理解:
1、pyhton不支持多态:python是弱类型,没有类型限定,无法区分父与子,或者说接口和实现类
2、python处处是多态:python是弱类型,没有类型限定,传递任何内容都行
'''
对象的创建过程
'''
1.调用__new__方法,在object中返回一个对象;
2.调用__init__方法,将1中的返回对象传递给__init__中的selif;
3.返回这个对象;
'''
class Dog(object):def __init__(self):print('__init__')def __new__(cls):print('__new__')obj = object.__new__(cls)print('obj: %s, cls: %s' % (obj, cls))return objwangcai = Dog()
print(wangcai)# 输出
__new__
obj: <__main__.Dog object at 0x0093D3D0>, cls: <class '__main__.Dog'>
__init__
<__main__.Dog object at 0x0093D3D0>
单例模式
class F(object):# 创建对象def __new__(cls):return object.__new__(cls)a = F()
b = F()
print(a == b) # False
########################################################
class F2(object):# 定义一个变量存储new处理的对象a = Nonedef __new__(cls):# 如果对象为None,调用父类方法,创建对象,并赋值给aif cls.a == None:cls.a == object.__new__(cls)# 对象不为None,返回第一次创建的对象return cls.aaa = F2()
bb = F2()
print(aa == bb) # True
异常
Exception:所有异常的父类
try:# …可能出现异常的代码块
except Exception [as xx]: # 有异常执行;xx 异常的基本信息
# except (NameErrot, IOError) as xx: # 捕获多个异常# …处理异常print(xx)
else: # 没异常执行,可以不用pass
finally: # 无论有没有异常都会执行# 有没有异常都要执行的代码
自定义异常
1、必须继承异常类
2、自己通过 raise 触发自定义异常
class XxError(Exception):# 不显示异常# silent_variable_failure = True def __init__(self,m):super().__init__() self.m=m
class SexErrot(Exception):def __init__(self, msg):self.msg = msgdef fun():sex = input('请输入性别:')if sex not in ['男', '女']:raise SexErrot('性别只能是男女!') # raise 抛出异常try:fun()
except Exception as ex: # ex 相当于ex.msgprint(ex)
包
# 包将有联系的模块组织在一起,即放在同一个文件夹下,并且在这个文件夹创建一个同名字为__init__.py的文件,那么这个文件就称之为包。
# __init__.py :导入的同时,直接运行import 包名.文件名(模块).函数名 [as 别名]
引用:包名.文件名(模块).函数名from 包名 import * 或者 [模块1,模块2…] # *表示到py文件
引用:文件名(模块).函数名from 模块 import * # 将模块里的所有内容导入
引用:函数名
深、浅拷贝
在Python中每个变量都有自己的标识、类型和值。每个对象一旦创建,它的标识就绝对不会变。一个对象的标识,我们可以理解成其在内存中的地址。is()运算符比较的是两个对象的标识;id()方法返回的就是对象标识的整数表示。
is比较对象的标识;==`运算符比较两个对象的值(对象中保存的数据)。
1、赋值其实只是传递对象引用,引用对象id是一样的。
2、浅拷贝是指拷贝的只是原始对象元素的引用,换句话说,浅拷贝产生的对象本身是新的,但是它的内容不是新的,只是对原对象的一个引用。 浅拷贝只是拷贝数据的第一层,不会拷贝子对象。
3、深拷贝是指完全拷贝原始对象,而且产生的对象是新的,并且不受其他引用对象的操作影响。
a = [1, 2, 3]
b = [1, 2, 3]print(id(a)) # 32096712
print(id(b)) # 32099848print(a == b) # True
print(a is b) # False# is 是比较两个应用是否指向同一个对象(引用比较)
# == 是比较连个对象是否相等
结论:
- 在不可变数据类型中,深浅拷贝都不会开辟新的内存空间,用的都是同一个内存地址。
- 在存在嵌套可变类型的数据时,深浅拷贝都会开辟新的一块内存空间;同时,不可变类型的值还是指向原来的值的地址。
- 不同的是:在嵌套可变类型中,浅拷贝只会拷贝最外层的数据,而深拷贝会拷贝所有层级的可变类型数据。
生成器
列表生成器
>>> [0,1,2,3,4,5,6,7,8,9]
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> [x**2 for x in range(10)]
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> ret = [x for x in range(10)]
>>> ret
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> ret = [(x,y) for x in range(3) for y in range(4)]
>>> ret
[(0, 0), (0, 1), (0, 2), (0, 3), (1, 0), (1, 1), (1, 2), (1, 3), (2, 0), (2, 1), (2, 2), (2, 3)]
generator 生成器
相当于保存了一个算法,只有调用的时候使用。
好处:防止数据量过大的内存溢出!
ge=(x for x in range(3))
print(ge) # <generator object <genexpr> at 0x01EDDAA8> (可遍历)
# 没有下一个值时,报StopIteration异常
print(next(ge)) # 0 获取下一个值
print(ge.__next__()) # 1 获取下一个值,同next(ge)
生成器写法
# 一旦数据量大了,可能造成内存溢出
def fib(times):n = 0a, b = 0, 1while n < times:print(b)a, b = b, a + bn += 1return 'done'ret = fib(4) # 1 1 2 3
print(ret) # done# 并没有完全保存值,而是通过算法每次计算出需要的值,这样一旦是大数据,也不会造成内存溢出
def fib(times):n = 0a, b = 0, 1while n < times:yield b # 函数遇到yield会停止运行,直到next()输出或者遍历a, b = b, a + bn += 1return 'over'ret = fib(4)
print(ret) # <generator object fib at 0x0239DA70>
print(next(ret)) # 1
send用法
# 相当于可以传值的__next__()
# 向生成器中传递参数,用一个变量=yield … 接收传递的参数
def fun():for i in range(10):temp = yield i # temp 默认为Noneif temp%2 == 0:print('xx')else:print('yy')gen = fun()
print(gen)
print(next(gen))
print(gen.send(3)) # send 传参给temp,可以添加一些逻辑
print(gen.send(6))# 输出
<generator object fun at 0x0197AB18>
0
yy
1
xx
2
迭代器
可以被next()函数调用并不断返回下一个值的对象称为迭代器;
可以使用iter(object),把对象变成迭代器;
优点:可以减少使用内存。
# 是否可迭代
import collections isinstance(object, collections.Iterable) # True/False
闭包
在函数内部再定义一个函数,并且这个函数用到了外部函数的变量,那么这个函数以及用到的一些变量称之为闭包。
# 闭包结构
def outer(xx):passdef inner(yy):passreturn inner
# inner 函数里一定存在对outer 函数变量的引用# 本来如果outer执行完后,outer内的变量会被垃圾回收机制回收。
# 但是一旦在闭包中,python会发现,内部函数引用了外部函数的变量,这个变量不会被立即销毁。
# 只有内部对象执行后才会销毁。这样就在内部函数中保存了外部函数的一些变量,进行一些业务逻辑。
装饰器
在运行原来代码的基础上,加入一些功能;比如权限的验证等;
不修改原来的代码,进行功能的扩展。比如:java中的动态代理;
装饰器的功能
1.引入日志
2.函数的执行时间
3.执行函数前预备处理
4.执行函数后清理功能
5.权限验证等场景
6.缓存
单个装饰器
def outer(fn):print('outer...')def inner():print('inner...')# 可以在fn前后加逻辑fn()print(inner)return inner@outer # 相当于 myFunc=outer(myFunc)
def myFunc():print('myFunc...')myFunc()# 输出
outer...
<function outer.<locals>.inner at 0x01316148>
inner...
myFunc...
多个装饰器
# 如果装饰器运行完毕后还有装饰器,交给下一个装饰器;
# 直到没有装饰器了,执行功能代码def decorator1(fn):def inner1():print('decorator1_inner1 begin...')fn()print('decorator1_inner1 end...')return inner1def decorator2(fn):def inner2():print('decorator2_inner2 begin...')fn()print('decorator2_inner2 end...')return inner2@decorator1
@decorator2
def myFunc():print('myFunc...')myFunc()# 输出
decorator1_inner1 begin...
decorator2_inner2 begin...
myFunc...
decorator2_inner2 end...
decorator1_inner1 end...
带参数的装饰器
# 装饰带参数的函数
def timeFun(func):def wrappedfunc(*args, **kwargs):func(*args, **kwargs)return wrappedfunc@timeFun
def foo(a, b, c):print(a+b)# 为了传递一些参数,再通过这些参数完成一些业务逻辑
def decorator(num):def timeFun(func):def wrappedfunc(*args, **kwargs):# 可以添加一些业务逻辑代码if num % 2 == 0:print('验证权限...')else:print('记录日志...')# 调用最终想要调用的功能方法return func(*args, **kwargs)return wrappedfuncreturn timeFun@decorator(4) # 装饰器传参
def foo():print('foo...')foo() # 输出
验证权限...
foo...
带返回值的装饰器
def timeFu(func):def wrappedfunc(*args, **kwargs):return func(*args, **kwargs)return wrappedfunc@timeFu
def foo(a,b):return a+bret = foo(1,2)
print(ret) # 3
类装饰器
'''
装饰器函数其实是这样一个接口约束,它必须接受一个callable对象作为参数,然后返回一个callable对象。
一般callable对象都是函数,但也有例外;只要某个对象重写了__call__()方法,那么这个对象就是callable的。
callable:可调用的
'''class Test():def __call__(self, *args, **kwargs):print('call me!')t = Test()
t()
class Test(object):def __init__(self, fun):print('初始化...')print('fun name is %s'%fun.__name__)self.__fun = fundef __call__(self, *args, **kwargs):print('装饰器中的功能...')self.__fun@Test
def test():print('...test...')test() # 如果注释这句,重新运行,依然会看到"初始化..."
进程(Process)
进程是一堆资源(一个程序)的集合;
进程要操作CPU,必须要先创建一个线程;
多进程中,每个进程中所有数据(包括全局变量)都各拥有一份,互不影响。
os.fork( )
'''
加载os模块后,首先os.fork()函数生成一个子进程,返回值pid有两个,一个为0, 用以表示在子进程当中,一个为大于0的整数,表示在父进程,这个常数正是子进程的pid.
if pid == 0,在子进程当中os.getpid()是子进程的pid,os.getppid()是父进程pid
if pid >0 ,在父进程当中,os.getpid()是父进程的pid,os.fork()返回的就是子进程的pid
'''
import os
print('进程(%s)开始...'% os.getpid())
# 只适用于Unix/Linux/Mac操作系统
pid = os.fork()
if pid == 0:print('我是子进程(%s)and 我的父进程是(%s)'%(os.getpid(),os.getppid()))
else:print('(%s)创建了子进程(%s)'%(os.getpid(),pid))
multiprocessing
from multiprocessing import Process
def run(n):print('run.......',n)if __name__ == '__main__':print('1......')# 创建了一个子进程对象 状态:新建状态p = Process(target=run,args='a',name='张三')# 启动:并执行run方法 状态:就绪状态p.start()# 进程的名字,不传有默认值print(p.name)# join等待前面的进程执行完p.join()print('2......')
Process常用方法
is_alive():判断进程实例是否还在执行
join([timeout]):等待进程实例执行结束(等待多少秒)
start():启动(创建子进程)
treminate():不管任务是否完成,立即终止
name参数:当前进程实例别名,默认Process-N
pid:当前进程实例PID
继承Process创建进程
from multiprocessing import Process
class Process_Class(Process):def __init__(self,A):Process.__init__(self) # 初始化使用父类属性和方法self.A = Adef run(self):...
Pool(进程池)
进程池里的任务不需要自己start() !
进程池里的任务,不是按照放入的顺序的执行的!
哪个进程执行哪个任务,不能手动干预!
'''
1、第一步:设置进程池中进程的数量 po = Pool(n)进程池的数字根据硬件环境进行设定,一般设置为cpu的数量
2、第二步:放任务 po.apply_async(方法名, 参数--元祖) ---异步po. apply() ---同步(单任务,一般不用)
3、第三步:关闭进程池 po.close() 关闭进程池,关闭后po不再接收新的请求
4、第四步:开始执行 po.join()等待po中所有子进程执行完成,必须放在close语句之后进程池中的进程开始执行任务如果任务大于进程的数量,多余的任务等待一旦某个进程完成当下的任务,从等待的任务中随机找一个任务执行
'''
from multiprocessing import Pooldef worker1(msg):print(msg)def worker2(msg):print(msg)if __name__ == '__main__':po = Pool(2)# callback 回调,执行完worker后执行funpo.apply_async(worker1,(1,) , callback=fun)po.apply_async(worker2,(2,))po.close()# 如果不join,那么程序直接关闭po.join() # 进程池中进程执行完毕后再关闭,需要放在close后
进程锁
'''
进程数据相互独立,按理不需要锁;
这个锁存在的意义就是:防止打印显示时出错,因为它们共享一个屏幕。
'''
from multiprocessing import Process, Lock
def f(l, i):l.acquire()print('hello world', i)l.release()
if __name__ == '__main__':lock = Lock()for num in range(100):Process(target=f, args=(lock, num)).start()
Queue(进程之间的通信)
q = mulitprocessing.Queue(n)
q.put('a') # 放入
q.put('b') # n等于2,放3个会阻塞
q.get() # 获取先进先出# 进程实现数据读写
from multiprocessing import Process, Queue
import os, time, random
# 写数据
def write(q):print('Process to write: %s' % os.getpid())for value in ['A', 'B', 'C']:print('Put %s to queue...' % value)q.put(value)time.sleep(random.random())
# 读数据
def read(q):print('Process to read: %s' % os.getpid())while True:value = q.get(True)print('Get %s from queue.' % value)if __name__=='__main__':# 父进程创建Queue,并传给各个子进程q = Queue(2)pw = Process(target=write, args=(q,))pr = Process(target=read, args=(q,))# 启动子进程pw,写入pw.start()# 启动子进程pr,读取pr.start()# 等待pw结束pw.join()# pr进程里是死循环,无法等待其结束,只能强行终止pr.terminate()
Pipe(进程之间的通信)
from multiprocessing import Process, Pipe
def f(conn):# 向父进程发数据conn.send('hello from child')conn.send('hello from child2')# 接收父进程数据print("from parent:",conn.recv())conn.close()if __name__ == '__main__':# Pipe()返回两个参数表示管道的两头,用以连接父子进程parent_conn, child_conn = Pipe()# 把其中一头传给子进程p = Process(target=f, args=(child_conn,))p.start()# 接收子进程数据print(parent_conn.recv())print(parent_conn.recv())# 向子进程发数据parent_conn.send("Hello!!")p.join()
线程(threading)
'''
是操作系统的最小的调度单位,是一串指令的集合;
python的多线程不适合CPU密集操作型的任务,适合IO操作密集型的任务(IO操作不占用CPU,计算暂用CPU);
多线程中全局变量共享!
'''
# 查看当前线程
threading.current_thread()
# 查看当前活动线程的个数
threading.active_count()
# 把当前线程设置为守护线程
# 相当于仆人,守护线程跟随主线程停止
t.setDaemon(True)
# 当前线程执行完,再继续执行后面线程
t.join()
创建
import threading
import time
def say(name):print(name)time.sleep(1)if __name__ == "__main__":# 存线程实例t_objs = []for i in range(5):# 创建子线程,子线程执行的功能方法是sayt = threading.Thread(target=say, args=("张三",))# 启动线程,即让线程开始执行t.start()# 为了不阻塞后面线程的启动,不在这里join,先放到一个列表里t_objs.append(t)# 循环线程实例列表,等待所有线程执行完毕for t in t_objs: t.join()
length = len(threading.enumerate()) # 查看线程的数量6
信号量(semaphore)
import threading, time
def run(n):semaphore.acquire()time.sleep(1)print("run the thread: %s\n" % n)semaphore.release()if __name__ == '__main__':# 最多允许5个线程同时运行# 每执行完一个线程,就加入一个semaphore = threading.BoundedSemaphore(5)for i in range(22):t = threading.Thread(target=run, args=(i,))t.start()
queue队列
q = queue.Queue(maxsize=n) # 先入先出
q = queue.LifoQueue(maxsize=n) # 后入先出
q = queue.PriorityQueue(maxsize=n) # 存储(put)数据时,设置优先级
q.put((-1,"数据")) # 优先级:数字,字符串。。# 生产者消费者模型案例
import threading,time,queue
q = queue.Queue(maxsize=5)
def Producer(name):count = 1while True:q.put("骨头%s" % count)print("[%s]生产了[骨头%s]"%(name,count))count +=1time.sleep(0.1)def Consumer(name):#while q.qsize()>0:while True:print("[%s] 取到[%s] 并且吃了它..." %(name, q.get()))time.sleep(1)p = threading.Thread(target=Producer,args=("生产者",))
c = threading.Thread(target=Consumer,args=("消费者01",))
c1 = threading.Thread(target=Consumer,args=("消费者02",))
p.start()
c.start()
c1.start()
Event
'''
用于线程间通信(True/False)
event = threading.Event()
event对象维护一个内部标志(标志初始值为False),通过event.set()将其置为True
wait(timeout)则用于堵塞线程直至Flag被set(或者超时,可选的)
isSet()、is_set()用于查询标志位是否为True
clear()则用于清除标志位(使之为False)
'''# 红绿灯案例
import threading,time
event = threading.Event()
def lighter():count = 0# event对象维护一个内部标志(初始值为False),通过set()将其置为True# 标志为True,表示绿灯event.set()while True:if count >5 and count < 10: #改成红灯# clear()则用于清除标志位(使之为False)event.clear()# "\033[41;1m内容\033[0m" 渲染字体显示颜色print("\033[41;1m红灯亮着....\033[0m")elif count >10:event.set() #变绿灯count = 0else:print("\033[42;1m绿灯亮着....\033[0m")time.sleep(1)count +=1def car(name):while True:# is_set()/isSet()用于查询标志位是否为Trueif event.is_set(): # True代表绿灯print("[%s] running..."% name )time.sleep(1)else:print("[%s] 看到红灯 , waiting...." %name)# wait(timeout)则用于堵塞线程直至标志位被设置(setevent.wait()print("\033[34;1m[%s] 绿灯亮了, start going...\033[0m" %name)light = threading.Thread(target=lighter,)
light.start()car = threading.Thread(target=car,args=("汽车",))
car.start()
锁(Lock)
import threading
# 创建对象
myLock = threading.Lock()
print(myLock)
print('1...')
# 锁住,如果此锁,已经锁了,如果再锁,会阻塞,直到开锁了,才能再锁
myLock.acquire()
print('2...')
# 开锁,如果锁住了,可以开锁。如果没锁,直接开,报错
myLock.release()
threadloca
'''
threadlocal就有俩功能:1、将各自的局部变量绑定到各自的线程中2、局部变量可以传递了,而且并没有变成形参
'''
import threading
# 创建全局ThreadLocal对象:
local_school = threading.local()
def process_student():# 获取当前线程关联的student:std = local_school.studentprint('Hello, %s (in %s)' % (std, threading.current_thread().name))def process_thread(name):# 绑定ThreadLocal的student:local_school.student = nameprocess_student()t1 =threading.Thread(target=process_thread,args=('yongGe',),name='Thread-A')
t2 =threading.Thread(target=process_thread, args=('老王',), name='Thread-B')
t1.start()
t2.start()
线程的几种状态
多线程程序的执行顺序是不确定的。当执行到sleep语句时,线程将被阻塞(Blocked),到sleep结束后,线程进入就绪(Runnable)状态,等待调度。而线程调度将自行选择一个线程执行。代码中只能保证每个线程都运行完整个run函数,但是线程的启动顺序、run函数中每次循环的执行顺序都不能确定。
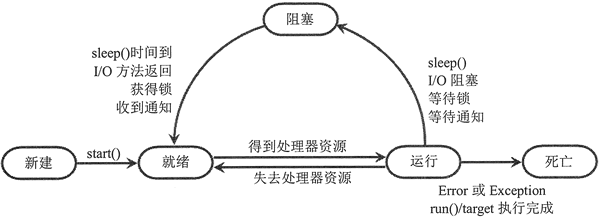
*参考:https://www.mianshigee.com/note/detail/19137chn/*
进程、线程的区别
一个程序至少有一个进程,一个进程至少有一个线程。
线程不能独立执行,必须依存在进程中;
线程是进程的一个实体,是CPU调度个分派的基本单位,它是比进程更小的能独立运行的基本单位。
线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源(如程序计算器,一组寄存器和栈),但它可与同属一个进程的其他线程共享进程所拥有的全部资源。
线程的划分小于进程(资源比进程少),使得多线程程序的并发性高 ;
| 区别 | 进程 | 线程 |
|---|---|---|
| 开销 | 每个经常都有独立的代码和数据空间(程序上下文),进程间的切换会有较大的开销 | 线程可以看成是轻量级的进程,同一类线程共享代码和数据空间,每个线程有独立的运行栈和程序计数器(PC),线程切换的开销小 |
| 所处环境 | 在操作系统中能同事运行多个任务(程序) | 在同一应用程序中有多个顺序流同时执行 |
| 分配内存 | 系统在运行时会为每个进程分配不通的内存区域 | 除了CPU外,不会为线程分配内存(线程所使用的资源是它所属进程的资源),线程组只能共享资源 |
| 包含关系 | 没有线程的进程是可以被看作单线程的,如果一个进程内拥有多个线程,则执行过程不是一条线的,而是多条线(线程)共同完成的 | 线程是进程的一部分,所以线程有的时候被称为是轻量级进程 |
协程
比线程更小的执行单元,又称微线程;协程是一种用户态的轻量级线程。
符合以下条件就能称之为协程:
1、必须在只有一个单线程里实现并发;
2、修改共享数据不需加锁;
3、用户程序里自己保存多个控制流的上下文栈;
4、一个协程遇到IO操作自动切换到其它协程;
'''
协程的切换只是单纯的操作CPU上下文,比线程的切换更快速;
1:N 模式:一个线程作为一个容器放置多个协程;
IO密集型的程序和CPU密集型程序。
'''
import gevent
def func1():print('...func1...')
# 模仿耗时操作gevent.sleep(2) print('...func1_1...')def func2():print('...func2...')gevent.sleep(1)print('...func2_2...')gevent.joinall([# 创建并开始协程gevent.spawn(func1),gevent.spawn(func2),
])# 输出
...func1...
...func2... # fun1耗时自动切换到fun2, fun2耗时自动切换到fun1
...func2_2...# fun1耗时2s还未结束,又切换到fun2
...func1_1...
# 整体执行完成只需要2秒
协程-简单爬虫
from urllib import request
import gevent,time
from gevent import monkey
# 把当前程序的所有的IO操作给我单独的做上标记
# 让gevent知道该程序有哪些IO操作
monkey.patch_all()
def f(url):print('GET: %s' % url)resp = request.urlopen(url)data = resp.read()print('%d bytes received from %s.' % (len(data), url))urls = ['https://www.python.org/','https://www.yahoo.com/','https://github.com/' ]
time_start = time.time()
for url in urls:f(url)
print("串行cost",time.time() - time_start)async_time_start = time.time()
gevent.joinall([gevent.spawn(f, 'https://www.python.org/'),gevent.spawn(f, 'https://www.yahoo.com/'),gevent.spawn(f, 'https://github.com/'),
])
print("协程异步cost",time.time() - async_time_start)
相关文章:
【Python笔记20230307】
基础 编码、解码 str.encode(utf-8) # 编码 str.decode(utf-8) # 解码关键字 import keyword keyword.kwlist格式化输出 % 占位符:%s 字符串%d 整数%f 浮点数Hello, %s % world Hi, %s, you have $%d. % (Michael, 1000000) 占位符的修饰符 -左对齐 .小数点后位数 0左边补零…...

SBOM应该是软件供应链中的安全主食
当谈到软件材料清单(SBOM)时,通常的类比是食品包装上的成分列表,它让消费者知道他们将要吃的薯片中有什么。 美国机构有90天时间创建所有软件的清单 同样,SBOM是一个软件中组件的清单,在应用程序是来自多个来源的代码的集合的时…...
[计算机组成原理(唐朔飞 第2版)]第一章 计算机系统概论 第二章 计算机的发展及应用(学习复习笔记)
第1章 计算机系统概论 1.1 计算机系统简介 1.1.1 计算机的软硬件概念 计算机系统由“硬件”和“软件”两大部分组成。 硬件 是指计算机的实体部分,它由看得见摸得着的各种电子元器件,各类光、电、机设备的实物组成如主机、外部设备等 软件 软件看不见…...
Python的数据分析相关的框架
Python特别强大,也是一款可以实现可数据分析语言,它有很多开源的库和工具,可以帮助数据科学家处理和分析数据。 以下是一些常用的Python库和工具: NumPy:NumPy是一个Python库,用于处理大型多维数组和矩阵&…...

为什么会出现植物神经紊乱 总是检查不出来该怎么办
植物神经紊乱是一种很多人都害怕的疾病,你们知道是为什么吗? 植物神经紊乱是一种神经系统失调导致的多种症状的总称,这种疾病是由于社会因素所诱发的脏器功能的失调,是一种非常复杂的疾病。而这种疾病是可能会发生在任何年龄阶段的…...

宏任务和微任务
JavaScript 把异步任务又做了进一步的划分,异步任务又分为两类,分别是: ① 宏任务(macrotask) 异步 Ajax 请求setTimeout、setInterval文件操作其它宏任务 ② 微任务(microtask) Promise.then…...
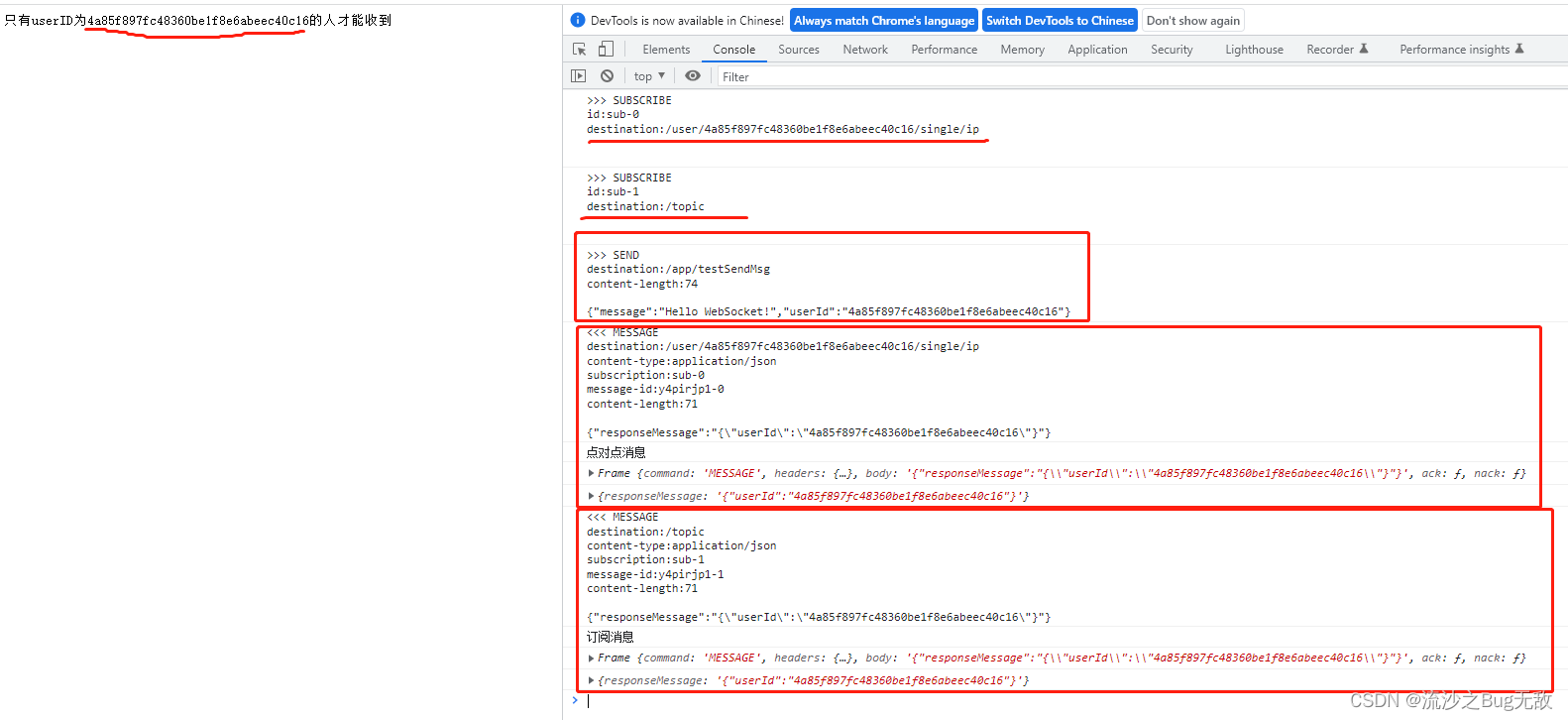
使用WebSocket、SockJS、STOMP实现消息实时通讯功能
客户端 <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <html> <head><title>websocket client</title><script src"http://cdn.bootcss.com/sockjs-client/1.1.1/sockjs.min.js"></script>…...
C++回顾(十一)—— 动态类型识别和抽象类
11.1 动态类识别 11.1.1 自定义类型 C中的多态根据实际的对象类型调用对应的函数 (1)可以在基类中定义虚函数返回具体的类型信息 (2)所有的派生类都必须实现类型相关的虚函数 (3)每个类中的类型虚函数都需…...
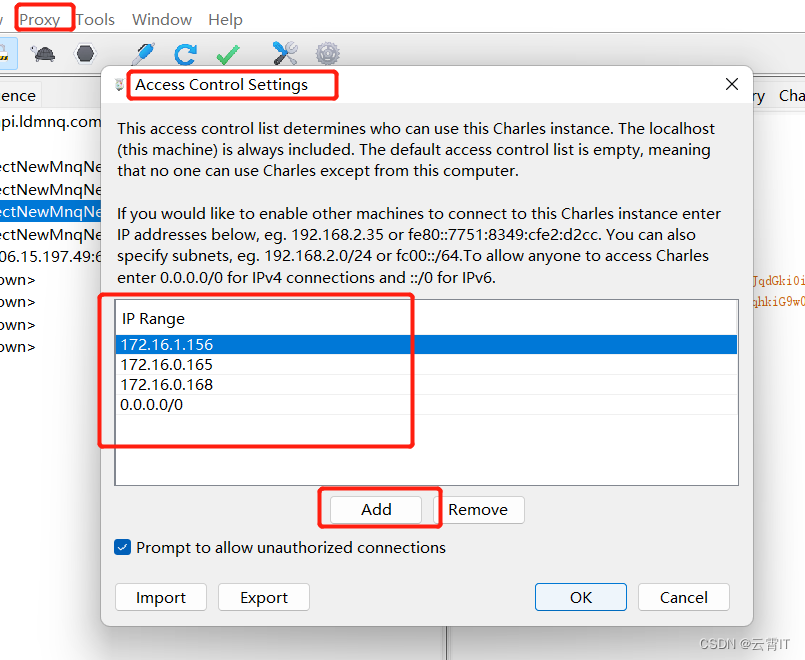
雷电模拟器安卓7以上+Charles抓包APP最新教程
一、工具准备: 证书安装工具全局代理工具下载: https://download.csdn.net/download/weixin_51111267/87536481 二、Charles设置 (一)电脑上证书安装 (二)安卓模拟器上系统证书安装(RooT权限打…...

vsvode 配置sftp,连接远程linux全过程
在本地安装sftp插件,配置参数https://blog.csdn.net/u011119817/article/details/106630599在linux机台安装vscode-service服务https://zhuanlan.zhihu.com/p/294933020连接超时,将配置文件添加超时时间遇到的错误处理:(272条消息) 【vscode插…...

C++类转换为蓝图、打印日志、蓝图关卡、删除C++文件
蓝图宏 UCLASS(Blueprintable)//c脚本可转换为蓝图 UPROPERTY(BlueprintReadWrite)//蓝图中可创建set,get节点 UFUNCTION(BlueprintCallable)//可创建函数节点 UPROPERTY(BlueprintReadWrite,Category”My Variables”)//节点进行分类打印日志 UE_LOG(LogTemp, Lo…...

elasticsearch高级篇:核心概念和实现原理
1.elasticsearch核心概念1.1 索引(index)一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母&#…...

部署安装Nginx服务实例
其他服务: 搭建zabbix4.0监控服务实例 普罗米修斯监控mysql数据库实战 Linux安装MySQL数据库步骤 一. Nginx概念介绍 1.介绍Nginx程序 Nginx (engine x) 是一款开源且高性能的HTTP和反向代理web服务器,同时也提供了IMAP/POP3/SMTP服务。主要特点是占用…...
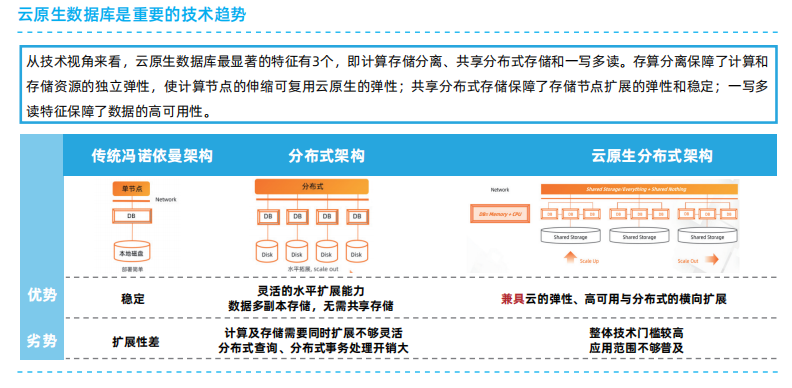
云原生架构设计原则及典型技术
云原生是面向云应用设计的一种思想理念,充分发挥云效能的最佳实践路径,帮助企业构建弹性可靠、松耦合、易管理可观测的应用系统,提升交付效率,降低运维复杂度。代表技术包括不可变基础设施、服务网格、声明式 API 及 Serverless 等…...

【Linux】-- 工具介绍 vim_gcc/g++_gdb
目录 Linux中的软件管理工具 – yum 在Linux下安装软件的方式 认识yum 查找软件包 安装 卸载 lrzsz.x86_64 rz sz Linux中的编辑器 – vim vim的基本概念 vim各模式切换 vim命令模式命令 vim底行模式命令 gcc / g gcc / g的作用 gcc / g语法 预处理 编译 汇…...

JAVA SE: IO流
一、Java流式输入输出原理Java对于输入输出是以流(Stream)的方式进行的,JDK提供各种各样的“流”类,以获取不同类型的数据。可以理解为将管道插入到文件中,然后从管道获取数据。这个管道外边还可以套管道,外边的管道对数据进行处理…...
打破原来软件开发模式的无代码开发平台
前言传统的系统开发是需要大量的时间和成本的,如今无代码开发平台的出现就改变了这种状况。那么你知道什么是无代码开发平台?无代码开发对企业来说有什么特殊的优势么?什么是无代码平台无代码平台指的是:使用者无需懂代码或手写代码,只需通…...

06-redux中的hook
知识点06-redux的hook 在函数组件中要和redux连接,分为两个步骤 前提状态机已经主备就绪 注入store到根组件 在函数组件中,使用Provider包裹根组件,并将store注入这一步,依旧是不能少的 import store from "./redux/store…...

watch监听不到数组对象的变化
watch监听不到数组对象的变化一、利用索引直接改变arr的值二、修改数组的长度arr.length三、添加和修改对象属性和值Vue不能监听到数组和对象值的变化其实和双向绑定的原理有关。Vue双向绑定原理是利用js中的Object.defineproperty重定义对象的GET和SET方法,而同时这…...

言语理解与表达之语句表达
考点一语句填空提问方式:填入划横线处最恰当的一句是( )1.横线在结尾:总结前文提出对策2.横线在开头:需概括文段的中心内容3.横线在中间:注意与上下文联系把握好主题词,保证文段话题一致实例1和…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

多场景 OkHttpClient 管理器 - Android 网络通信解决方案
下面是一个完整的 Android 实现,展示如何创建和管理多个 OkHttpClient 实例,分别用于长连接、普通 HTTP 请求和文件下载场景。 <?xml version"1.0" encoding"utf-8"?> <LinearLayout xmlns:android"http://schemas…...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

鸿蒙HarmonyOS 5军旗小游戏实现指南
1. 项目概述 本军旗小游戏基于鸿蒙HarmonyOS 5开发,采用DevEco Studio实现,包含完整的游戏逻辑和UI界面。 2. 项目结构 /src/main/java/com/example/militarychess/├── MainAbilitySlice.java // 主界面├── GameView.java // 游戏核…...