04-自媒体文章-自动审核
自媒体文章-自动审核
1)自媒体文章自动审核流程
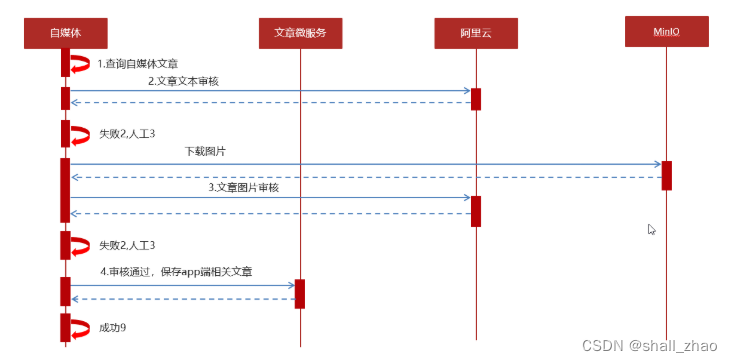
1 自媒体端发布文章后,开始审核文章
2 审核的主要是审核文章的内容(文本内容和图片)
3 借助第三方提供的接口审核文本
4 借助第三方提供的接口审核图片,由于图片存储到minIO中,需要先下载才能审核
5 如果审核失败,则需要修改自媒体文章的状态,status:2 审核失败 status:3 转到人工审核
6 如果审核成功,则需要在文章微服务中创建app端需要的文章
2)内容安全第三方接口
2.1)概述
内容安全是识别服务,支持对图片、视频、文本、语音等对象进行多样化场景检测,有效降低内容违规风险。
目前很多平台都支持内容检测,如阿里云、腾讯云、百度AI、网易云等国内大型互联网公司都对外提供了API。
按照性能和收费来看,黑马头条项目使用的就是阿里云的内容安全接口,使用到了图片和文本的审核。
阿里云收费标准:https://www.aliyun.com/price/product/?spm=a2c4g.11186623.2.10.4146401eg5oeu8#/lvwang/detail
2.2)准备工作
您在使用内容检测API之前,需要先注册阿里云账号,添加Access Key并签约云盾内容安全。
操作步骤
-
前往阿里云官网注册账号。如果已有注册账号,请跳过此步骤。
进入阿里云首页后,如果没有阿里云的账户需要先进行注册,才可以进行登录。由于注册较为简单,课程和讲义不在进行体现(注册可以使用多种方式,如淘宝账号、支付宝账号、微博账号等…)。
需要实名认证和活体认证。
-
打开云盾内容安全产品试用页面,单击立即开通,正式开通服务。
内容安全控制台
-
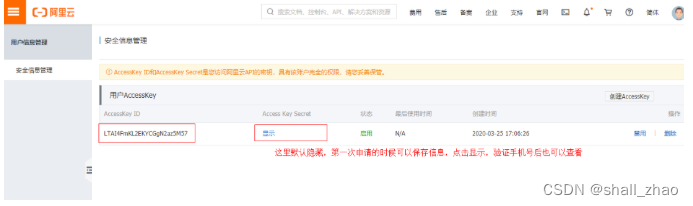
在AccessKey管理页面管理您的AccessKeyID和AccessKeySecret。
管理自己的AccessKey,可以新建和删除AccessKey
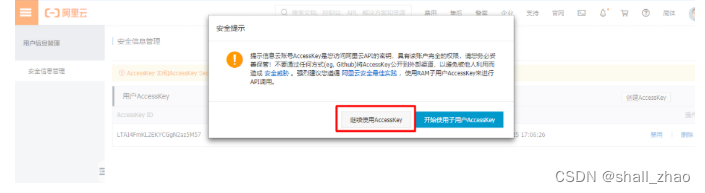
查看自己的AccessKey,
AccessKey默认是隐藏的,第一次申请的时候可以保存AccessKey,点击显示,通过验证手机号后也可以查看
2.3)文本内容审核接口
文本垃圾内容检测:https://help.aliyun.com/document_detail/70439.html?spm=a2c4g.11186623.6.659.35ac3db3l0wV5k

文本垃圾内容Java SDK: https://help.aliyun.com/document_detail/53427.html?spm=a2c4g.11186623.6.717.466d7544QbU8Lr
2.4)图片审核接口
图片垃圾内容检测:https://help.aliyun.com/document_detail/70292.html?spm=a2c4g.11186623.6.616.5d7d1e7f9vDRz4

图片垃圾内容Java SDK: https://help.aliyun.com/document_detail/53424.html?spm=a2c4g.11186623.6.715.c8f69b12ey35j4
2.5)项目集成
①:拷贝资料文件夹中的类到common模块下面,并添加到自动配置
包括了GreenImageScan和GreenTextScan及对应的工具类
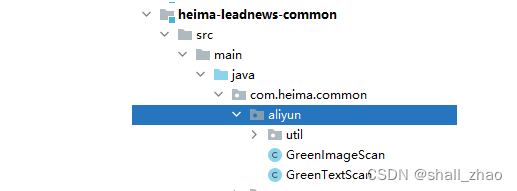
添加到自动配置中
②: accessKeyId和secret(需自己申请)
在heima-leadnews-wemedia中的nacos配置中心添加以下配置:
aliyun:accessKeyId: LTAI5tCWHCcfvqQzu8k2oKmXsecret: auoKUFsghimbfVQHpy7gtRyBkoR4vc
#aliyun.scenes=porn,terrorism,ad,qrcode,live,logoscenes: terrorism
③:在自媒体微服务中测试类中注入审核文本和图片的bean进行测试
package com.heima.wemedia;import com.heima.common.aliyun.GreenImageScan;
import com.heima.common.aliyun.GreenTextScan;
import com.heima.file.service.FileStorageService;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;import java.util.Arrays;
import java.util.Map;@SpringBootTest(classes = WemediaApplication.class)
@RunWith(SpringRunner.class)
public class AliyunTest {@Autowiredprivate GreenTextScan greenTextScan;@Autowiredprivate GreenImageScan greenImageScan;@Autowiredprivate FileStorageService fileStorageService;@Testpublic void testScanText() throws Exception {Map map = greenTextScan.greeTextScan("我是一个好人,冰毒");System.out.println(map);}@Testpublic void testScanImage() throws Exception {byte[] bytes = fileStorageService.downLoadFile("http://192.168.200.130:9000/leadnews/2021/04/26/ef3cbe458db249f7bd6fb4339e593e55.jpg");Map map = greenImageScan.imageScan(Arrays.asList(bytes));System.out.println(map);}
}
3)app端文章保存接口
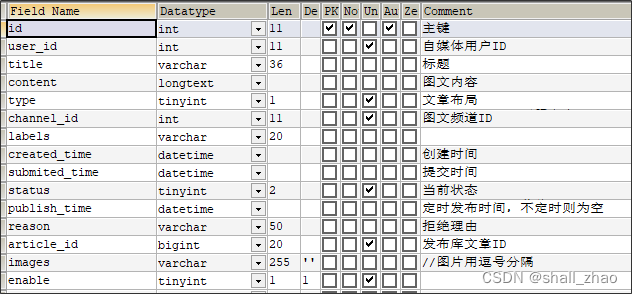
3.1)表结构说明
ap_article 文章信息表
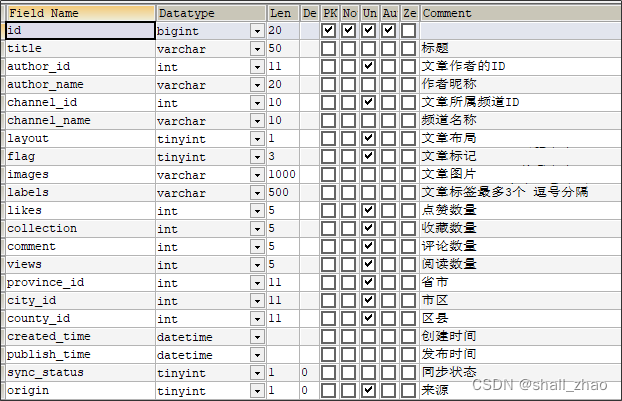
ap_article_config 文章配置表
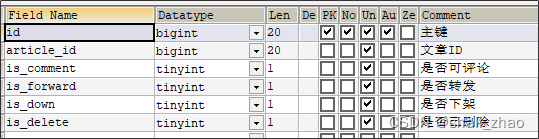
ap_article_content 文章内容表

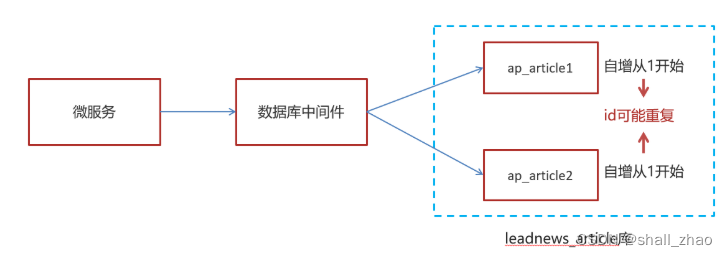
3.2)分布式id
随着业务的增长,文章表可能要占用很大的物理存储空间,为了解决该问题,后期使用数据库分片技术。将一个数据库进行拆分,通过数据库中间件连接。如果数据库中该表选用ID自增策略,则可能产生重复的ID,此时应该使用分布式ID生成策略来生成ID。
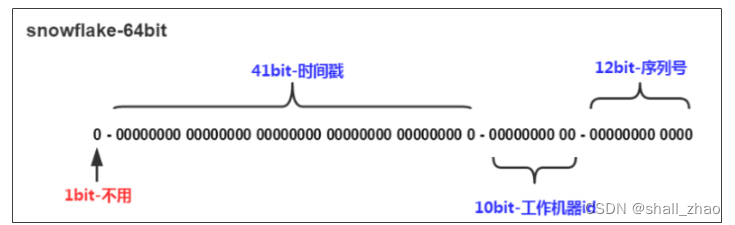
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0
文章端相关的表都使用雪花算法生成id,包括ap_article、 ap_article_config、 ap_article_content
mybatis-plus已经集成了雪花算法,完成以下两步即可在项目中集成雪花算法
第一:在实体类中的id上加入如下配置,指定类型为id_worker
@TableId(value = "id",type = IdType.ID_WORKER)
private Long id;
第二:在application.yml文件中配置数据中心id和机器id
mybatis-plus:mapper-locations: classpath*:mapper/*.xml# 设置别名包扫描路径,通过该属性可以给包中的类注册别名type-aliases-package: com.heima.model.article.pojosglobal-config:datacenter-id: 1workerId: 1
datacenter-id:数据中心id(取值范围:0-31)
workerId:机器id(取值范围:0-31)
3.3)思路分析
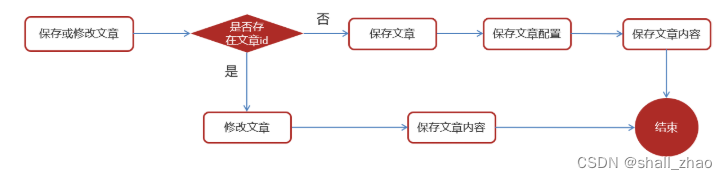
在文章审核成功以后需要在app的article库中新增文章数据
1.保存文章信息 ap_article
2.保存文章配置信息 ap_article_config
3.保存文章内容 ap_article_content
实现思路:
3.4)feign接口
| 说明 | |
|---|---|
| 接口路径 | /api/v1/article/save |
| 请求方式 | POST |
| 参数 | ArticleDto |
| 响应结果 | ResponseResult |
ArticleDto
package com.heima.model.article.dtos;import com.heima.model.article.pojos.ApArticle;
import lombok.Data;@Data
public class ArticleDto extends ApArticle {/*** 文章内容*/private String content;
}
成功:
{"code": 200,"errorMessage" : "操作成功","data":"1302864436297442242"}
失败:
{"code":501,"errorMessage":"参数失效",}
{"code":501,"errorMessage":"文章没有找到",}
功能实现:
①:在heima-leadnews-feign-api中新增接口
第一:线导入feign的依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
第二:定义文章端的接口
package com.heima.apis.article;import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.common.dtos.ResponseResult;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;import java.io.IOException;@FeignClient(value = "leadnews-article")
public interface IArticleClient {@PostMapping("/api/v1/article/save")public ResponseResult saveArticle(@RequestBody ArticleDto dto) ;
}
②:在heima-leadnews-article中实现该方法
package com.heima.article.feign;import com.heima.apis.article.IArticleClient;
import com.heima.article.service.ApArticleService;
import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.common.dtos.ResponseResult;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;import java.io.IOException;@RestController
public class ArticleClient implements IArticleClient {@Autowiredprivate ApArticleService apArticleService;@Override@PostMapping("/api/v1/article/save")public ResponseResult saveArticle(@RequestBody ArticleDto dto) {return apArticleService.saveArticle(dto);}}
③:拷贝mapper
在资料文件夹中拷贝ApArticleConfigMapper类到mapper文件夹中
同时,修改ApArticleConfig类,添加如下构造函数
package com.heima.model.article.pojos;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import lombok.NoArgsConstructor;import java.io.Serializable;/*** <p>* APP已发布文章配置表* </p>** @author itheima*/@Data
@NoArgsConstructor
@TableName("ap_article_config")
public class ApArticleConfig implements Serializable {public ApArticleConfig(Long articleId){this.articleId = articleId;this.isComment = true;this.isForward = true;this.isDelete = false;this.isDown = false;}@TableId(value = "id",type = IdType.ID_WORKER)private Long id;/*** 文章id*/@TableField("article_id")private Long articleId;/*** 是否可评论* true: 可以评论 1* false: 不可评论 0*/@TableField("is_comment")private Boolean isComment;/*** 是否转发* true: 可以转发 1* false: 不可转发 0*/@TableField("is_forward")private Boolean isForward;/*** 是否下架* true: 下架 1* false: 没有下架 0*/@TableField("is_down")private Boolean isDown;/*** 是否已删除* true: 删除 1* false: 没有删除 0*/@TableField("is_delete")private Boolean isDelete;
}
④:在ApArticleService中新增方法
/*** 保存app端相关文章* @param dto* @return*/
ResponseResult saveArticle(ArticleDto dto) ;
实现类:
@Autowired
private ApArticleConfigMapper apArticleConfigMapper;@Autowired
private ApArticleContentMapper apArticleContentMapper;/*** 保存app端相关文章* @param dto* @return*/
@Override
public ResponseResult saveArticle(ArticleDto dto) {//1.检查参数if(dto == null){return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);}ApArticle apArticle = new ApArticle();BeanUtils.copyProperties(dto,apArticle);//2.判断是否存在idif(dto.getId() == null){//2.1 不存在id 保存 文章 文章配置 文章内容//保存文章save(apArticle);//保存配置ApArticleConfig apArticleConfig = new ApArticleConfig(apArticle.getId());apArticleConfigMapper.insert(apArticleConfig);//保存 文章内容ApArticleContent apArticleContent = new ApArticleContent();apArticleContent.setArticleId(apArticle.getId());apArticleContent.setContent(dto.getContent());apArticleContentMapper.insert(apArticleContent);}else {//2.2 存在id 修改 文章 文章内容//修改 文章updateById(apArticle);//修改文章内容ApArticleContent apArticleContent = apArticleContentMapper.selectOne(Wrappers.<ApArticleContent>lambdaQuery().eq(ApArticleContent::getArticleId, dto.getId()));apArticleContent.setContent(dto.getContent());apArticleContentMapper.updateById(apArticleContent);}//3.结果返回 文章的idreturn ResponseResult.okResult(apArticle.getId());
}
⑤:测试
编写junit单元测试,或使用postman进行测试
{"id":1390209114747047938,"title":"黑马头条项目背景22222222222222","authoId":1102,"layout":1,"labels":"黑马头条","publishTime":"2028-03-14T11:35:49.000Z","images": "http://192.168.200.130:9000/leadnews/2021/04/26/5ddbdb5c68094ce393b08a47860da275.jpg","content":"22222222222222222黑马头条项目背景,黑马头条项目背景,黑马头条项目背景,黑马头条项目背景,黑马头条项目背景"
}
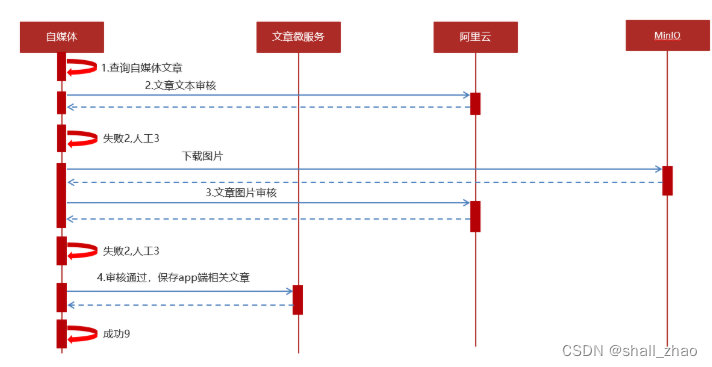
4)自媒体文章自动审核功能实现
4.1)表结构说明
wm_news 自媒体文章表
status字段:0 草稿 1 待审核 2 审核失败 3 人工审核 4 人工审核通过 8 审核通过(待发布) 9 已发布
4.2)实现
在heima-leadnews-wemedia中的service新增接口
package com.heima.wemedia.service;public interface WmNewsAutoScanService {/*** 自媒体文章审核* @param id 自媒体文章id*/public void autoScanWmNews(Integer id);
}
实现类:
package com.heima.wemedia.service.impl;import com.alibaba.fastjson.JSONArray;
import com.heima.apis.article.IArticleClient;
import com.heima.common.aliyun.GreenImageScan;
import com.heima.common.aliyun.GreenTextScan;
import com.heima.file.service.FileStorageService;
import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.wemedia.pojos.WmChannel;
import com.heima.model.wemedia.pojos.WmNews;
import com.heima.model.wemedia.pojos.WmUser;
import com.heima.wemedia.mapper.WmChannelMapper;
import com.heima.wemedia.mapper.WmNewsMapper;
import com.heima.wemedia.mapper.WmUserMapper;
import com.heima.wemedia.service.WmNewsAutoScanService;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;import java.util.*;
import java.util.stream.Collectors;@Service
@Slf4j
@Transactional
public class WmNewsAutoScanServiceImpl implements WmNewsAutoScanService {@Autowiredprivate WmNewsMapper wmNewsMapper;/*** 自媒体文章审核** @param id 自媒体文章id*/@Overridepublic void autoScanWmNews(Integer id) {//1.查询自媒体文章WmNews wmNews = wmNewsMapper.selectById(id);if(wmNews == null){throw new RuntimeException("WmNewsAutoScanServiceImpl-文章不存在");}if(wmNews.getStatus().equals(WmNews.Status.SUBMIT.getCode())){//从内容中提取纯文本内容和图片Map<String,Object> textAndImages = handleTextAndImages(wmNews);//2.审核文本内容 阿里云接口boolean isTextScan = handleTextScan((String) textAndImages.get("content"),wmNews);if(!isTextScan)return;//3.审核图片 阿里云接口boolean isImageScan = handleImageScan((List<String>) textAndImages.get("images"),wmNews);if(!isImageScan)return;//4.审核成功,保存app端的相关的文章数据ResponseResult responseResult = saveAppArticle(wmNews);if(!responseResult.getCode().equals(200)){throw new RuntimeException("WmNewsAutoScanServiceImpl-文章审核,保存app端相关文章数据失败");}//回填article_idwmNews.setArticleId((Long) responseResult.getData());updateWmNews(wmNews,(short) 9,"审核成功");}}@Autowiredprivate IArticleClient articleClient;@Autowiredprivate WmChannelMapper wmChannelMapper;@Autowiredprivate WmUserMapper wmUserMapper;/*** 保存app端相关的文章数据* @param wmNews*/private ResponseResult saveAppArticle(WmNews wmNews) {ArticleDto dto = new ArticleDto();//属性的拷贝BeanUtils.copyProperties(wmNews,dto);//文章的布局dto.setLayout(wmNews.getType());//频道WmChannel wmChannel = wmChannelMapper.selectById(wmNews.getChannelId());if(wmChannel != null){dto.setChannelName(wmChannel.getName());}//作者dto.setAuthorId(wmNews.getUserId().longValue());WmUser wmUser = wmUserMapper.selectById(wmNews.getUserId());if(wmUser != null){dto.setAuthorName(wmUser.getName());}//设置文章idif(wmNews.getArticleId() != null){dto.setId(wmNews.getArticleId());}dto.setCreatedTime(new Date());ResponseResult responseResult = articleClient.saveArticle(dto);return responseResult;}@Autowiredprivate FileStorageService fileStorageService;@Autowiredprivate GreenImageScan greenImageScan;/*** 审核图片* @param images* @param wmNews* @return*/private boolean handleImageScan(List<String> images, WmNews wmNews) {boolean flag = true;if(images == null || images.size() == 0){return flag;}//下载图片 minIO//图片去重images = images.stream().distinct().collect(Collectors.toList());List<byte[]> imageList = new ArrayList<>();for (String image : images) {byte[] bytes = fileStorageService.downLoadFile(image);imageList.add(bytes);}//审核图片try {Map map = greenImageScan.imageScan(imageList);if(map != null){//审核失败if(map.get("suggestion").equals("block")){flag = false;updateWmNews(wmNews, (short) 2, "当前文章中存在违规内容");}//不确定信息 需要人工审核if(map.get("suggestion").equals("review")){flag = false;updateWmNews(wmNews, (short) 3, "当前文章中存在不确定内容");}}} catch (Exception e) {flag = false;e.printStackTrace();}return flag;}@Autowiredprivate GreenTextScan greenTextScan;/*** 审核纯文本内容* @param content* @param wmNews* @return*/private boolean handleTextScan(String content, WmNews wmNews) {boolean flag = true;if((wmNews.getTitle()+"-"+content).length() == 0){return flag;}try {Map map = greenTextScan.greeTextScan((wmNews.getTitle()+"-"+content));if(map != null){//审核失败if(map.get("suggestion").equals("block")){flag = false;updateWmNews(wmNews, (short) 2, "当前文章中存在违规内容");}//不确定信息 需要人工审核if(map.get("suggestion").equals("review")){flag = false;updateWmNews(wmNews, (short) 3, "当前文章中存在不确定内容");}}} catch (Exception e) {flag = false;e.printStackTrace();}return flag;}/*** 修改文章内容* @param wmNews* @param status* @param reason*/private void updateWmNews(WmNews wmNews, short status, String reason) {wmNews.setStatus(status);wmNews.setReason(reason);wmNewsMapper.updateById(wmNews);}/*** 1。从自媒体文章的内容中提取文本和图片* 2.提取文章的封面图片* @param wmNews* @return*/private Map<String, Object> handleTextAndImages(WmNews wmNews) {//存储纯文本内容StringBuilder stringBuilder = new StringBuilder();List<String> images = new ArrayList<>();//1。从自媒体文章的内容中提取文本和图片if(StringUtils.isNotBlank(wmNews.getContent())){List<Map> maps = JSONArray.parseArray(wmNews.getContent(), Map.class);for (Map map : maps) {if (map.get("type").equals("text")){stringBuilder.append(map.get("value"));}if (map.get("type").equals("image")){images.add((String) map.get("value"));}}}//2.提取文章的封面图片if(StringUtils.isNotBlank(wmNews.getImages())){String[] split = wmNews.getImages().split(",");images.addAll(Arrays.asList(split));}Map<String, Object> resultMap = new HashMap<>();resultMap.put("content",stringBuilder.toString());resultMap.put("images",images);return resultMap;}
}
4.3)单元测试
package com.heima.wemedia.service;import com.heima.wemedia.WemediaApplication;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;import static org.junit.Assert.*;@SpringBootTest(classes = WemediaApplication.class)
@RunWith(SpringRunner.class)
public class WmNewsAutoScanServiceTest {@Autowiredprivate WmNewsAutoScanService wmNewsAutoScanService;@Testpublic void autoScanWmNews() {wmNewsAutoScanService.autoScanWmNews(6238);}
}
4.4)feign远程接口调用方式
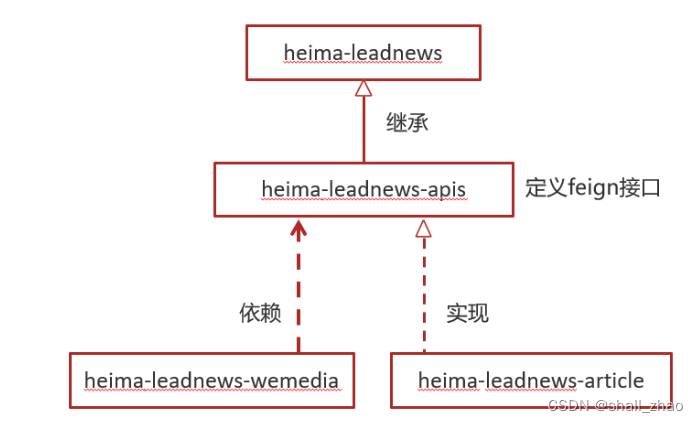
在heima-leadnews-wemedia服务中已经依赖了heima-leadnews-feign-apis工程,只需要在自媒体的引导类中开启feign的远程调用即可
注解为:@EnableFeignClients(basePackages = "com.heima.apis") 需要指向apis这个包
4.5)服务降级处理

-
服务降级是服务自我保护的一种方式,或者保护下游服务的一种方式,用于确保服务不会受请求突增影响变得不可用,确保服务不会崩溃
-
服务降级虽然会导致请求失败,但是不会导致阻塞。
实现步骤:
①:在heima-leadnews-feign-api编写降级逻辑
package com.heima.apis.article.fallback;import com.heima.apis.article.IArticleClient;
import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.common.enums.AppHttpCodeEnum;
import org.springframework.stereotype.Component;/*** feign失败配置* @author itheima*/
@Component
public class IArticleClientFallback implements IArticleClient {@Overridepublic ResponseResult saveArticle(ArticleDto dto) {return ResponseResult.errorResult(AppHttpCodeEnum.SERVER_ERROR,"获取数据失败");}
}
在自媒体微服务中添加类,扫描降级代码类的包
package com.heima.wemedia.config;import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;@Configuration
@ComponentScan("com.heima.apis.article.fallback")
public class InitConfig {
}
②:远程接口中指向降级代码
package com.heima.apis.article;import com.heima.apis.article.fallback.IArticleClientFallback;
import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.common.dtos.ResponseResult;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;@FeignClient(value = "leadnews-article",fallback = IArticleClientFallback.class)
public interface IArticleClient {@PostMapping("/api/v1/article/save")public ResponseResult saveArticle(@RequestBody ArticleDto dto);
}
③:客户端开启降级heima-leadnews-wemedia
在wemedia的nacos配置中心里添加如下内容,开启服务降级,也可以指定服务响应的超时的时间
feign:# 开启feign对hystrix熔断降级的支持hystrix:enabled: true# 修改调用超时时间client:config:default:connectTimeout: 2000readTimeout: 2000
④:测试
在ApArticleServiceImpl类中saveArticle方法添加代码
try {Thread.sleep(3000);
} catch (InterruptedException e) {e.printStackTrace();
}
在自媒体端进行审核测试,会出现服务降级的现象
5)发布文章提交审核集成
5.1)同步调用与异步调用
同步:就是在发出一个调用时,在没有得到结果之前, 该调用就不返回(实时处理)
异步:调用在发出之后,这个调用就直接返回了,没有返回结果(分时处理)

异步线程的方式审核文章
5.2)Springboot集成异步线程调用
①:在自动审核的方法上加上@Async注解(标明要异步调用)
@Override
@Async //标明当前方法是一个异步方法
public void autoScanWmNews(Integer id) {//代码略
}
②:在文章发布成功后调用审核的方法
@Autowired
private WmNewsAutoScanService wmNewsAutoScanService;/*** 发布修改文章或保存为草稿* @param dto* @return*/
@Override
public ResponseResult submitNews(WmNewsDto dto) {//代码略//审核文章wmNewsAutoScanService.autoScanWmNews(wmNews.getId());return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS);}
③:在自媒体引导类中使用@EnableAsync注解开启异步调用
@SpringBootApplication
@EnableDiscoveryClient
@MapperScan("com.heima.wemedia.mapper")
@EnableFeignClients(basePackages = "com.heima.apis")
@EnableAsync //开启异步调用
public class WemediaApplication {public static void main(String[] args) {SpringApplication.run(WemediaApplication.class,args);}@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));return interceptor;}
}
6)文章审核功能-综合测试
6.1)服务启动列表
1,nacos服务端
2,article微服务
3,wemedia微服务
4,启动wemedia网关微服务
5,启动前端系统wemedia
6.2)测试情况列表
1,自媒体前端发布一篇正常的文章
审核成功后,app端的article相关数据是否可以正常保存,自媒体文章状态和app端文章id是否回显
2,自媒体前端发布一篇包含敏感词的文章
正常是审核失败, wm_news表中的状态是否改变,成功和失败原因正常保存
3,自媒体前端发布一篇包含敏感图片的文章
正常是审核失败, wm_news表中的状态是否改变,成功和失败原因正常保存
7)新需求-自管理敏感词
7.1)需求分析
文章审核功能已经交付了,文章也能正常发布审核。突然,产品经理过来说要开会。
会议的内容核心有以下内容:
-
文章审核不能过滤一些敏感词:
私人侦探、针孔摄象、信用卡提现、广告代理、代开发票、刻章办、出售答案、小额贷款…
需要完成的功能:
需要自己维护一套敏感词,在文章审核的时候,需要验证文章是否包含这些敏感词
7.2)敏感词-过滤
技术选型
| 方案 | 说明 |
|---|---|
| 数据库模糊查询 | 效率太低 |
| String.indexOf(“”)查找 | 数据库量大的话也是比较慢 |
| 全文检索 | 分词再匹配 |
| DFA算法 | 确定有穷自动机(一种数据结构) |
7.3)DFA实现原理
DFA全称为:Deterministic Finite Automaton,即确定有穷自动机。
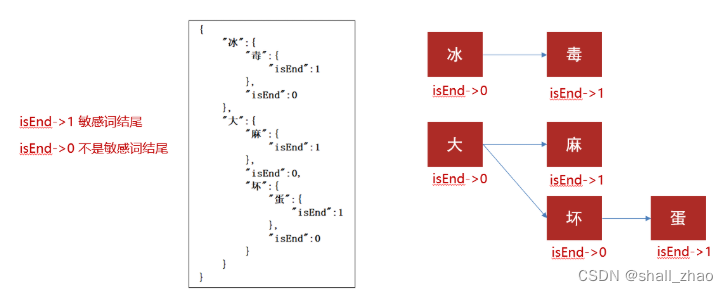
存储:一次性的把所有的敏感词存储到了多个map中,就是下图表示这种结构
敏感词:冰毒、大麻、大坏蛋
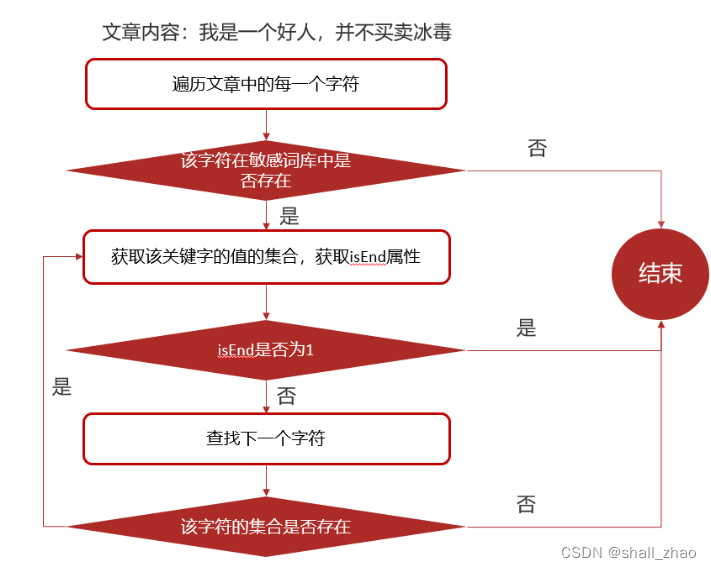
检索的过程
7.4)自管理敏感词集成到文章审核中
①:创建敏感词表,导入资料中wm_sensitive到leadnews_wemedia库中

package com.heima.model.wemedia.pojos;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;import java.io.Serializable;
import java.util.Date;/*** <p>* 敏感词信息表* </p>** @author itheima*/
@Data
@TableName("wm_sensitive")
public class WmSensitive implements Serializable {private static final long serialVersionUID = 1L;/*** 主键*/@TableId(value = "id", type = IdType.AUTO)private Integer id;/*** 敏感词*/@TableField("sensitives")private String sensitives;/*** 创建时间*/@TableField("created_time")private Date createdTime;}
②:拷贝对应的wm_sensitive的mapper到项目中
package com.heima.wemedia.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.heima.model.wemedia.pojos.WmSensitive;
import org.apache.ibatis.annotations.Mapper;@Mapper
public interface WmSensitiveMapper extends BaseMapper<WmSensitive> {
}
③:在文章审核的代码中添加自管理敏感词审核
第一:在WmNewsAutoScanServiceImpl中的autoScanWmNews方法上添加如下代码
//从内容中提取纯文本内容和图片
//.....省略//自管理的敏感词过滤
boolean isSensitive = handleSensitiveScan((String) textAndImages.get("content"), wmNews);
if(!isSensitive) return;//2.审核文本内容 阿里云接口
//.....省略
新增自管理敏感词审核代码
@Autowired
private WmSensitiveMapper wmSensitiveMapper;/*** 自管理的敏感词审核* @param content* @param wmNews* @return*/
private boolean handleSensitiveScan(String content, WmNews wmNews) {boolean flag = true;//获取所有的敏感词List<WmSensitive> wmSensitives = wmSensitiveMapper.selectList(Wrappers.<WmSensitive>lambdaQuery().select(WmSensitive::getSensitives));List<String> sensitiveList = wmSensitives.stream().map(WmSensitive::getSensitives).collect(Collectors.toList());//初始化敏感词库SensitiveWordUtil.initMap(sensitiveList);//查看文章中是否包含敏感词Map<String, Integer> map = SensitiveWordUtil.matchWords(content);if(map.size() >0){updateWmNews(wmNews,(short) 2,"当前文章中存在违规内容"+map);flag = false;}return flag;
}
8)新需求-图片识别文字审核敏感词
8.1)需求分析
产品经理召集开会,文章审核功能已经交付了,文章也能正常发布审核。对于上次提出的自管理敏感词也很满意,这次会议核心的内容如下:
- 文章中包含的图片要识别文字,过滤掉图片文字的敏感词

8.2)图片文字识别
什么是OCR?
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程
| 方案 | 说明 |
|---|---|
| 百度OCR | 收费 |
| Tesseract-OCR | Google维护的开源OCR引擎,支持Java,Python等语言调用 |
| Tess4J | 封装了Tesseract-OCR ,支持Java调用 |
8.3)Tess4j案例
①:创建项目导入tess4j对应的依赖
<dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>4.1.1</version>
</dependency>
②:导入中文字体库, 把资料中的tessdata文件夹拷贝到自己的工作空间下

③:编写测试类进行测试
package com.heima.tess4j;import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;import java.io.File;public class Application {public static void main(String[] args) {try {//获取本地图片File file = new File("D:\\26.png");//创建Tesseract对象ITesseract tesseract = new Tesseract();//设置字体库路径tesseract.setDatapath("D:\\workspace\\tessdata");//中文识别tesseract.setLanguage("chi_sim");//执行ocr识别String result = tesseract.doOCR(file);//替换回车和tal键 使结果为一行result = result.replaceAll("\\r|\\n","-").replaceAll(" ","");System.out.println("识别的结果为:"+result);} catch (Exception e) {e.printStackTrace();}}
}
8.4)管理敏感词和图片文字识别集成到文章审核
①:在heima-leadnews-common中创建工具类,简单封装一下tess4j
需要先导入pom
<dependency><groupId>net.sourceforge.tess4j</groupId><artifactId>tess4j</artifactId><version>4.1.1</version>
</dependency>
工具类
package com.heima.common.tess4j;import lombok.Getter;
import lombok.Setter;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;import java.awt.image.BufferedImage;@Getter
@Setter
@Component
@ConfigurationProperties(prefix = "tess4j")
public class Tess4jClient {private String dataPath;private String language;public String doOCR(BufferedImage image) throws TesseractException {//创建Tesseract对象ITesseract tesseract = new Tesseract();//设置字体库路径tesseract.setDatapath(dataPath);//中文识别tesseract.setLanguage(language);//执行ocr识别String result = tesseract.doOCR(image);//替换回车和tal键 使结果为一行result = result.replaceAll("\\r|\\n", "-").replaceAll(" ", "");return result;}}
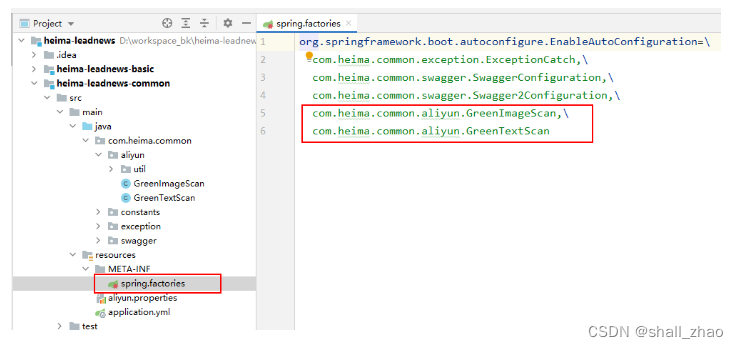
在spring.factories配置中添加该类,完整如下:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\com.heima.common.exception.ExceptionCatch,\com.heima.common.swagger.SwaggerConfiguration,\com.heima.common.swagger.Swagger2Configuration,\com.heima.common.aliyun.GreenTextScan,\com.heima.common.aliyun.GreenImageScan,\com.heima.common.tess4j.Tess4jClient
②:在heima-leadnews-wemedia中的配置中添加两个属性
tess4j:data-path: D:\workspace\tessdatalanguage: chi_sim
③:在WmNewsAutoScanServiceImpl中的handleImageScan方法上添加如下代码
try {for (String image : images) {byte[] bytes = fileStorageService.downLoadFile(image);//图片识别文字审核---begin-----//从byte[]转换为butteredImageByteArrayInputStream in = new ByteArrayInputStream(bytes);BufferedImage imageFile = ImageIO.read(in);//识别图片的文字String result = tess4jClient.doOCR(imageFile);//审核是否包含自管理的敏感词boolean isSensitive = handleSensitiveScan(result, wmNews);if(!isSensitive){return isSensitive;}//图片识别文字审核---end-----imageList.add(bytes);}
}catch (Exception e){e.printStackTrace();
}
最后附上文章审核的完整代码如下:
package com.heima.wemedia.service.impl;import com.alibaba.fastjson.JSONArray;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.heima.apis.article.IArticleClient;
import com.heima.common.aliyun.GreenImageScan;
import com.heima.common.aliyun.GreenTextScan;
import com.heima.common.tess4j.Tess4jClient;
import com.heima.file.service.FileStorageService;
import com.heima.model.article.dtos.ArticleDto;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.wemedia.pojos.WmChannel;
import com.heima.model.wemedia.pojos.WmNews;
import com.heima.model.wemedia.pojos.WmSensitive;
import com.heima.model.wemedia.pojos.WmUser;
import com.heima.utils.common.SensitiveWordUtil;
import com.heima.wemedia.mapper.WmChannelMapper;
import com.heima.wemedia.mapper.WmNewsMapper;
import com.heima.wemedia.mapper.WmSensitiveMapper;
import com.heima.wemedia.mapper.WmUserMapper;
import com.heima.wemedia.service.WmNewsAutoScanService;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.ByteArrayInputStream;
import java.util.*;
import java.util.stream.Collectors;@Service
@Slf4j
@Transactional
public class WmNewsAutoScanServiceImpl implements WmNewsAutoScanService {@Autowiredprivate WmNewsMapper wmNewsMapper;/*** 自媒体文章审核** @param id 自媒体文章id*/@Override@Async //标明当前方法是一个异步方法public void autoScanWmNews(Integer id) {// int a = 1/0;//1.查询自媒体文章WmNews wmNews = wmNewsMapper.selectById(id);if (wmNews == null) {throw new RuntimeException("WmNewsAutoScanServiceImpl-文章不存在");}if (wmNews.getStatus().equals(WmNews.Status.SUBMIT.getCode())) {//从内容中提取纯文本内容和图片Map<String, Object> textAndImages = handleTextAndImages(wmNews);//自管理的敏感词过滤boolean isSensitive = handleSensitiveScan((String) textAndImages.get("content"), wmNews);if(!isSensitive) return;//2.审核文本内容 阿里云接口boolean isTextScan = handleTextScan((String) textAndImages.get("content"), wmNews);if (!isTextScan) return;//3.审核图片 阿里云接口boolean isImageScan = handleImageScan((List<String>) textAndImages.get("images"), wmNews);if (!isImageScan) return;//4.审核成功,保存app端的相关的文章数据ResponseResult responseResult = saveAppArticle(wmNews);if (!responseResult.getCode().equals(200)) {throw new RuntimeException("WmNewsAutoScanServiceImpl-文章审核,保存app端相关文章数据失败");}//回填article_idwmNews.setArticleId((Long) responseResult.getData());updateWmNews(wmNews, (short) 9, "审核成功");}}@Autowiredprivate WmSensitiveMapper wmSensitiveMapper;/*** 自管理的敏感词审核* @param content* @param wmNews* @return*/private boolean handleSensitiveScan(String content, WmNews wmNews) {boolean flag = true;//获取所有的敏感词List<WmSensitive> wmSensitives = wmSensitiveMapper.selectList(Wrappers.<WmSensitive>lambdaQuery().select(WmSensitive::getSensitives));List<String> sensitiveList = wmSensitives.stream().map(WmSensitive::getSensitives).collect(Collectors.toList());//初始化敏感词库SensitiveWordUtil.initMap(sensitiveList);//查看文章中是否包含敏感词Map<String, Integer> map = SensitiveWordUtil.matchWords(content);if(map.size() >0){updateWmNews(wmNews,(short) 2,"当前文章中存在违规内容"+map);flag = false;}return flag;}@Autowiredprivate IArticleClient articleClient;@Autowiredprivate WmChannelMapper wmChannelMapper;@Autowiredprivate WmUserMapper wmUserMapper;/*** 保存app端相关的文章数据** @param wmNews*/private ResponseResult saveAppArticle(WmNews wmNews) {ArticleDto dto = new ArticleDto();//属性的拷贝BeanUtils.copyProperties(wmNews, dto);//文章的布局dto.setLayout(wmNews.getType());//频道WmChannel wmChannel = wmChannelMapper.selectById(wmNews.getChannelId());if (wmChannel != null) {dto.setChannelName(wmChannel.getName());}//作者dto.setAuthorId(wmNews.getUserId().longValue());WmUser wmUser = wmUserMapper.selectById(wmNews.getUserId());if (wmUser != null) {dto.setAuthorName(wmUser.getName());}//设置文章idif (wmNews.getArticleId() != null) {dto.setId(wmNews.getArticleId());}dto.setCreatedTime(new Date());ResponseResult responseResult = articleClient.saveArticle(dto);return responseResult;}@Autowiredprivate FileStorageService fileStorageService;@Autowiredprivate GreenImageScan greenImageScan;@Autowiredprivate Tess4jClient tess4jClient;/*** 审核图片** @param images* @param wmNews* @return*/private boolean handleImageScan(List<String> images, WmNews wmNews) {boolean flag = true;if (images == null || images.size() == 0) {return flag;}//下载图片 minIO//图片去重images = images.stream().distinct().collect(Collectors.toList());List<byte[]> imageList = new ArrayList<>();try {for (String image : images) {byte[] bytes = fileStorageService.downLoadFile(image);//图片识别文字审核---begin-----//从byte[]转换为butteredImageByteArrayInputStream in = new ByteArrayInputStream(bytes);BufferedImage imageFile = ImageIO.read(in);//识别图片的文字String result = tess4jClient.doOCR(imageFile);//审核是否包含自管理的敏感词boolean isSensitive = handleSensitiveScan(result, wmNews);if(!isSensitive){return isSensitive;}//图片识别文字审核---end-----imageList.add(bytes);}}catch (Exception e){e.printStackTrace();}//审核图片try {Map map = greenImageScan.imageScan(imageList);if (map != null) {//审核失败if (map.get("suggestion").equals("block")) {flag = false;updateWmNews(wmNews, (short) 2, "当前文章中存在违规内容");}//不确定信息 需要人工审核if (map.get("suggestion").equals("review")) {flag = false;updateWmNews(wmNews, (short) 3, "当前文章中存在不确定内容");}}} catch (Exception e) {flag = false;e.printStackTrace();}return flag;}@Autowiredprivate GreenTextScan greenTextScan;/*** 审核纯文本内容** @param content* @param wmNews* @return*/private boolean handleTextScan(String content, WmNews wmNews) {boolean flag = true;if ((wmNews.getTitle() + "-" + content).length() == 0) {return flag;}try {Map map = greenTextScan.greeTextScan((wmNews.getTitle() + "-" + content));if (map != null) {//审核失败if (map.get("suggestion").equals("block")) {flag = false;updateWmNews(wmNews, (short) 2, "当前文章中存在违规内容");}//不确定信息 需要人工审核if (map.get("suggestion").equals("review")) {flag = false;updateWmNews(wmNews, (short) 3, "当前文章中存在不确定内容");}}} catch (Exception e) {flag = false;e.printStackTrace();}return flag;}/*** 修改文章内容** @param wmNews* @param status* @param reason*/private void updateWmNews(WmNews wmNews, short status, String reason) {wmNews.setStatus(status);wmNews.setReason(reason);wmNewsMapper.updateById(wmNews);}/*** 1。从自媒体文章的内容中提取文本和图片* 2.提取文章的封面图片** @param wmNews* @return*/private Map<String, Object> handleTextAndImages(WmNews wmNews) {//存储纯文本内容StringBuilder stringBuilder = new StringBuilder();List<String> images = new ArrayList<>();//1。从自媒体文章的内容中提取文本和图片if (StringUtils.isNotBlank(wmNews.getContent())) {List<Map> maps = JSONArray.parseArray(wmNews.getContent(), Map.class);for (Map map : maps) {if (map.get("type").equals("text")) {stringBuilder.append(map.get("value"));}if (map.get("type").equals("image")) {images.add((String) map.get("value"));}}}//2.提取文章的封面图片if (StringUtils.isNotBlank(wmNews.getImages())) {String[] split = wmNews.getImages().split(",");images.addAll(Arrays.asList(split));}Map<String, Object> resultMap = new HashMap<>();resultMap.put("content", stringBuilder.toString());resultMap.put("images", images);return resultMap;}
}
9)文章详情-静态文件生成
9.1)思路分析
文章端创建app相关文章时,生成文章详情静态页上传到MinIO中

9.2)实现步骤
1.新建ArticleFreemarkerService创建静态文件并上传到minIO中
package com.heima.article.service;import com.heima.model.article.pojos.ApArticle;public interface ArticleFreemarkerService {/*** 生成静态文件上传到minIO中* @param apArticle* @param content*/public void buildArticleToMinIO(ApArticle apArticle,String content);
}
实现
package com.heima.article.service.impl;import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.heima.article.mapper.ApArticleContentMapper;
import com.heima.article.service.ApArticleService;
import com.heima.article.service.ArticleFreemarkerService;
import com.heima.file.service.FileStorageService;
import com.heima.model.article.pojos.ApArticle;
import freemarker.template.Configuration;
import freemarker.template.Template;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;import java.io.ByteArrayInputStream;
import java.io.InputStream;
import java.io.StringWriter;
import java.util.HashMap;
import java.util.Map;@Service
@Slf4j
@Transactional
public class ArticleFreemarkerServiceImpl implements ArticleFreemarkerService {@Autowiredprivate ApArticleContentMapper apArticleContentMapper;@Autowiredprivate Configuration configuration;@Autowiredprivate FileStorageService fileStorageService;@Autowiredprivate ApArticleService apArticleService;/*** 生成静态文件上传到minIO中* @param apArticle* @param content*/@Async@Overridepublic void buildArticleToMinIO(ApArticle apArticle, String content) {//已知文章的id//4.1 获取文章内容if(StringUtils.isNotBlank(content)){//4.2 文章内容通过freemarker生成html文件Template template = null;StringWriter out = new StringWriter();try {template = configuration.getTemplate("article.ftl");//数据模型Map<String,Object> contentDataModel = new HashMap<>();contentDataModel.put("content", JSONArray.parseArray(content));//合成template.process(contentDataModel,out);} catch (Exception e) {e.printStackTrace();}//4.3 把html文件上传到minio中InputStream in = new ByteArrayInputStream(out.toString().getBytes());String path = fileStorageService.uploadHtmlFile("", apArticle.getId() + ".html", in);//4.4 修改ap_article表,保存static_url字段apArticleService.update(Wrappers.<ApArticle>lambdaUpdate().eq(ApArticle::getId,apArticle.getId()).set(ApArticle::getStaticUrl,path));}}}
2.在ApArticleService的saveArticle实现方法中添加调用生成文件的方法
/*** 保存app端相关文章* @param dto* @return*/
@Override
public ResponseResult saveArticle(ArticleDto dto) {// try {// Thread.sleep(3000);// } catch (InterruptedException e) {// e.printStackTrace();// }//1.检查参数if(dto == null){return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);}ApArticle apArticle = new ApArticle();BeanUtils.copyProperties(dto,apArticle);//2.判断是否存在idif(dto.getId() == null){//2.1 不存在id 保存 文章 文章配置 文章内容//保存文章save(apArticle);//保存配置ApArticleConfig apArticleConfig = new ApArticleConfig(apArticle.getId());apArticleConfigMapper.insert(apArticleConfig);//保存 文章内容ApArticleContent apArticleContent = new ApArticleContent();apArticleContent.setArticleId(apArticle.getId());apArticleContent.setContent(dto.getContent());apArticleContentMapper.insert(apArticleContent);}else {//2.2 存在id 修改 文章 文章内容//修改 文章updateById(apArticle);//修改文章内容ApArticleContent apArticleContent = apArticleContentMapper.selectOne(Wrappers.<ApArticleContent>lambdaQuery().eq(ApArticleContent::getArticleId, dto.getId()));apArticleContent.setContent(dto.getContent());apArticleContentMapper.updateById(apArticleContent);}//异步调用 生成静态文件上传到minio中articleFreemarkerService.buildArticleToMinIO(apArticle,dto.getContent());//3.结果返回 文章的idreturn ResponseResult.okResult(apArticle.getId());
}
3.文章微服务开启异步调用
相关文章:
04-自媒体文章-自动审核
自媒体文章-自动审核 1)自媒体文章自动审核流程 1 自媒体端发布文章后,开始审核文章 2 审核的主要是审核文章的内容(文本内容和图片) 3 借助第三方提供的接口审核文本 4 借助第三方提供的接口审核图片,由于图片存储到minIO中&…...

LeetCode-热题100:763. 划分字母区间
题目描述 给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。 注意,划分结果需要满足:将所有划分结果按顺序连接,得到的字符串仍然是 s 。 返回一个表示每个字符串片段的长度的列表。…...

IDEA2023创建SpringMVC项目
✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉 🍎个人主页:Leo的博客 💞当前专栏: 开发环境篇 ✨特色专栏: M…...
ubuntu-server部署hive-part2-安装hadoop
参照 https://blog.csdn.net/qq_41946216/article/details/134345137 操作系统版本:ubuntu-server-22.04.3 虚拟机:virtualbox7.0 安装hadoop 下载上传 下载地址 https://archive.apache.org/dist/hadoop/common/hadoop-3.3.4/ 以root用…...

Python深度学习032:conda操作虚拟环境env的全部命令
文章目录 创建和管理环境环境列表和检查环境的保存与复制更新环境清理 CondaConda 是一个开源的包管理器和环境管理器,可以用于安装、运行和升级包和环境。 使用 Conda,你可以创建、导出、列出、删除和更新环境,这些环境可以包含不同版本的 Python 以及/或软件包。 下面列出…...
使用Java拓展本地开源大模型的网络搜索问答能力
背景 开源大模型通常不具备最新语料的问答能力。因此需要外部插件的拓展,目前主流的langChain框架已经集成了网络搜索的能力。但是作为一个倔强的Java程序员,还是想要用Java去实现。 注册SerpAPI Serpapi 提供了多种搜索引擎的搜索API接口。 访问 Ser…...
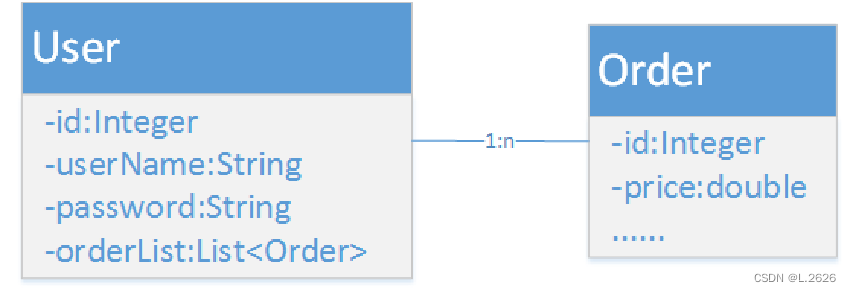
Mybatis——一对多关联映射
一对多关联映射 一对多关联映射有两种方式,都用到了collection元素 以购物网站中用户和订单之间的一对多关系为例 collection集合的嵌套结果映射 创建两个实体类和映射接口 package org.example.demo;import lombok.Data;import java.util.List;Data public cla…...

Pytorch实用教程:TensorDataset和DataLoader的介绍及用法示例
TensorDataset TensorDataset是PyTorch中torch.utils.data模块的一部分,它包装张量到一个数据集中,并允许对这些张量进行索引,以便能够以批量的方式加载它们。 当你有多个数据源(如特征和标签)时,TensorD…...
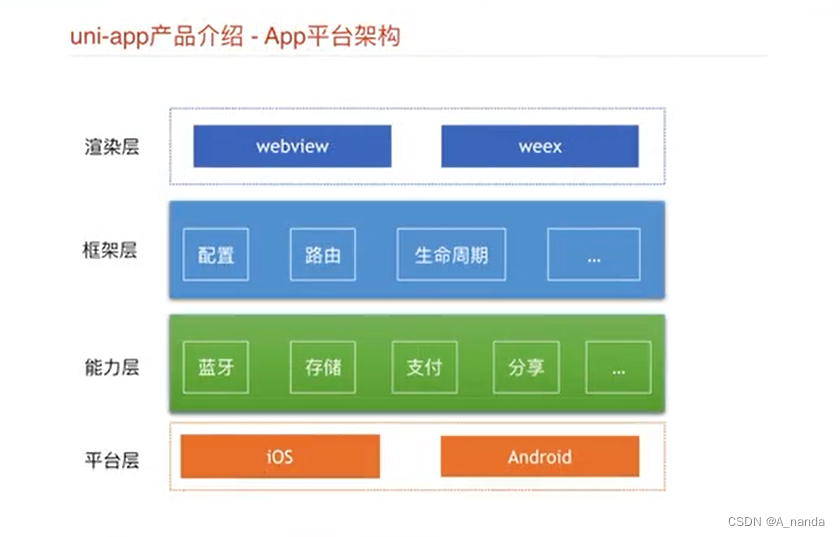
uni-app如何实现高性能
这篇文章主要讲解uni-app如何实现高性能的问题? 什么是uni-app? 简单说一下什么是uni-app,uni-app是继承自vue.js,对vue做了轻度定制,并且实现了完整的组件化开发,并且支持多端发布的一种架构,…...

docker 应用部署
参考:docker 构建nginx服务 环境 Redhat 9 步骤: 1、docker部署MySQL 安装yum 工具包 [rootadmin ~]# yum -y install yum-utils.noarch 正在更新 Subscription Management 软件仓库。 无法读取客户身份本系统尚未在权利服务器中注册。可使用 subscription-…...

java.awt.FontFormatException: java.nio.BufferUnderflowException
Font awardFont Font.createFont(Font.TRUETYPE_FONT, awardFontFile).deriveFont(120f).deriveFont(Font.BOLD);使用如上语句创建字体时出现问题。java.awt.FontFormatException: java.nio.BufferUnderflowException异常表明在处理字体数据时出现了缓冲区下溢(Buf…...

C++ 枚举类型 ← 关键字 enum
【知识点:枚举类型】● 枚举类型(enumeration)是 C 中的一种派生数据类型,它是由用户定义的若干枚举常量的集合。 ● 枚举元素作为常量,它们是有值的。C 编译时,依序对枚举元素赋整型值 0,1,2,3,…。 下面代…...

MySQL故障排查与优化
一、MySQL故障排查 1.1 故障现象与解决方法 1.1.1 故障1 1.1.2 故障2 1.1.3 故障3 1.1.4 故障4 1.1.5 故障5 1.1.6 故障6 1.1.7 故障7 1.1.8 故障8 1.1.9 MySQL 主从故障排查 二、MySQL优化 2.1 硬件方面 2.2 查询优化 一、MySQL故障排查 1.1 故障现象与解决方…...

如何做一个知识博主? 善用互联网检索
Google 使用引号: 使用双引号将要搜索的短语括起来,以便搜索结果中只包含该短语。例如,搜索 "人工智能" 将只返回包含该短语的页面。 排除词汇: 在搜索中使用减号 "-" 可以排除特定词汇。例如,搜索 "苹果 -手机" 将返回关于苹果公司的结果,但…...
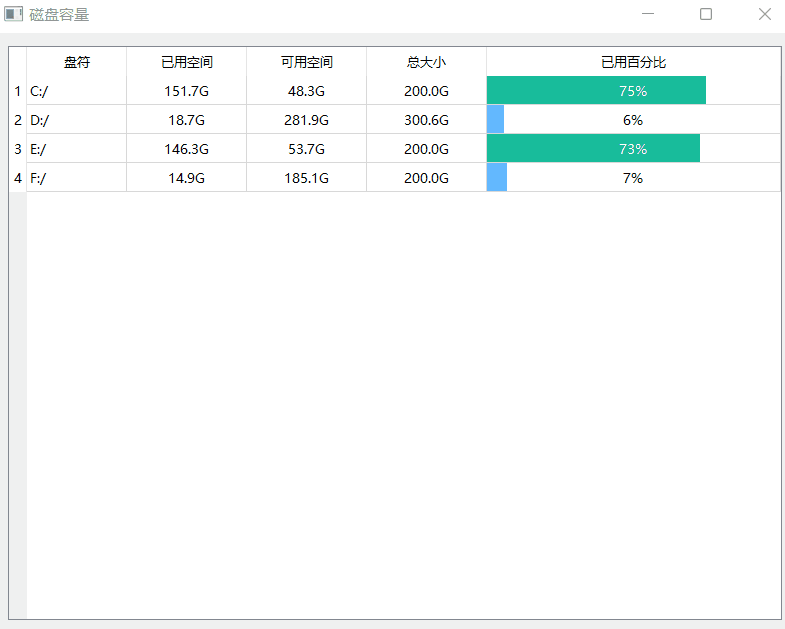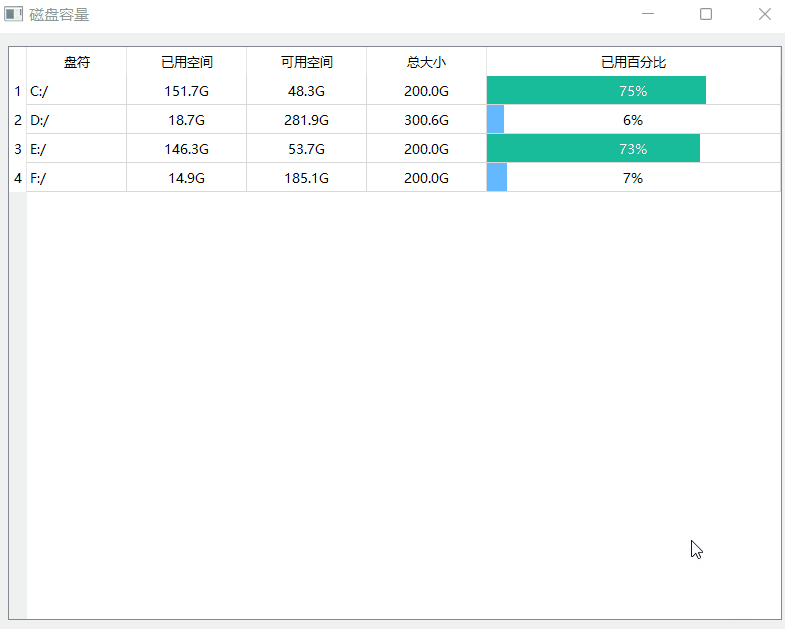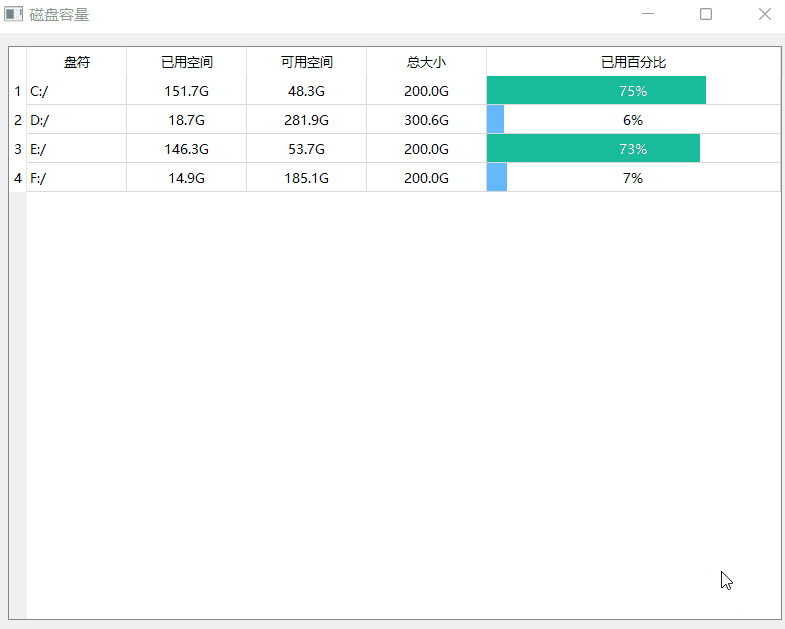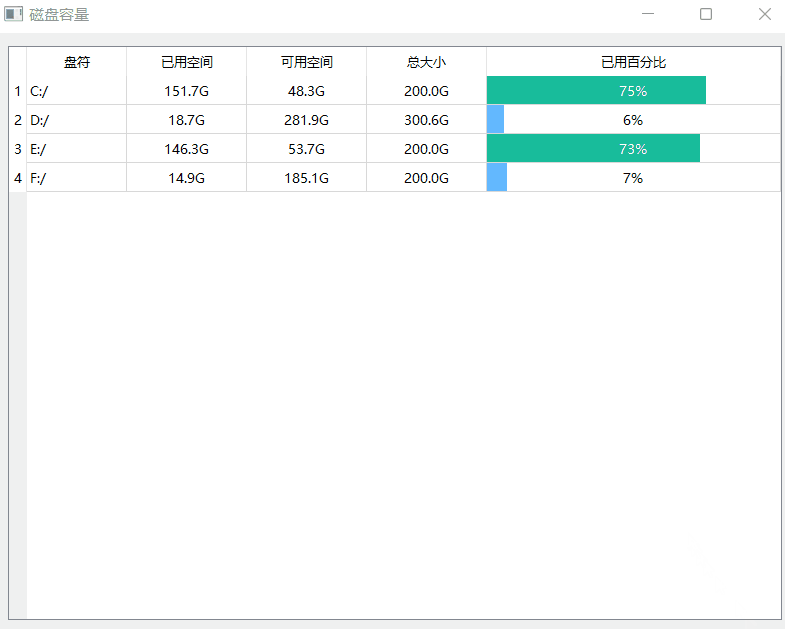
《QT实用小工具·十》本地存储空间大小控件
1、概述 源码放在文章末尾 本地存储空间大小控件,反应电脑存储情况: 可自动加载本地存储设备的总容量/已用容量。进度条显示已用容量。支持所有操作系统。增加U盘或者SD卡到达信号。 下面是demo演示: 项目部分代码如下: #if…...

作为一个初学者该如何学习kali linux?
首先你要明白你学KALI的目的是什么,其次你要了解什么是kali,其实你并不是想要学会kali你只是想当一个hacker kali是什么: 只是一个集成了多种渗透工具的linux操作系统而已,抛开这些工具,他跟常规的linux没有太大区别。…...

多线程学习-线程池
目录 1.线程池的作用 2.线程池的实现 3.自定义创建线程池 1.线程池的作用 当我们使用Thread的实现类来创建线程并调用start运行线程时,这个线程只会使用一次并且执行的任务是固定的,等run方法中的代码执行完之后这个线程就会变成垃圾等待被回收掉。如…...
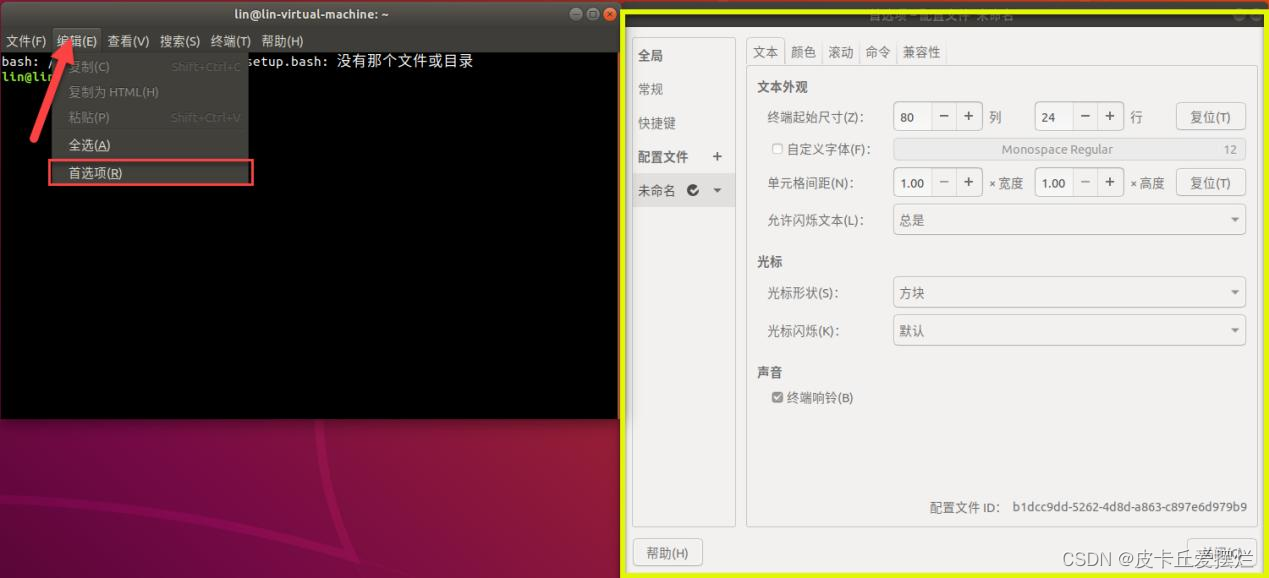
Linux第4课 Linux的基本操作
文章目录 Linux第4课 Linux的基本操作一、图形界面介绍二、终端界面介绍 Linux第4课 Linux的基本操作 一、图形界面介绍 本节以Ubuntu系统的GUI为例进行说明,Linux其他版本可自行网搜。 图形系统进入后,左侧黄框内为菜单栏,右侧为桌面&…...

堆排序解读
在算法世界中,排序算法一直是一个热门话题。推排序(Heap Sort)作为一种基于堆这种数据结构的有效排序方法,因其时间复杂度稳定且空间复杂度低而备受青睐。本文将深入探讨推排序的原理、实现方式,以及它在实际应用中的价…...

docker + miniconda + python 环境安装与迁移(详细版)
本文主要列出从安装dockerpython环境到迁移环境的整体步骤。windows与linux之间进行测试。 简化版可以参考:docker miniconda python 环境安装与迁移(简化版)-CSDN博客 目录 一、docker 安装和测试 二、docker中拉取minicondaÿ…...
)
保姆级教程:用OpenAI Whisper给视频自动生成字幕(附Python代码)
视频创作者必备:用Whisper打造高效字幕工作流 每次剪辑视频最头疼的就是加字幕?作为过来人,我完全理解那种对着时间轴逐帧调整的痛苦。直到发现Whisper这个神器,我的工作效率直接翻了三倍。今天就把这套全自动字幕生成方案完整分享…...

MariaDB Docker容器权限配置问题分析与解决方案
MariaDB Docker容器权限配置问题分析与解决方案 1. 问题背景 在使用MariaDB Docker容器时,用户遇到了远程访问权限配置失效的问题。具体表现为: 手动创建的远程用户(如root%、****%、********%)在容器重启后无法远程连接权限表中显…...

5分钟搞定AutoHotkey脚本转EXE:Ahk2Exe终极编译指南
5分钟搞定AutoHotkey脚本转EXE:Ahk2Exe终极编译指南 【免费下载链接】Ahk2Exe Official AutoHotkey script compiler - written itself in AutoHotkey 项目地址: https://gitcode.com/gh_mirrors/ah/Ahk2Exe 想要将AutoHotkey脚本快速转换为独立的可执行文件…...

AD快捷键避坑指南:为什么你的自定义快捷键总是不生效?
AD快捷键避坑指南:为什么你的自定义快捷键总是不生效? 在AD(Altium Designer)这个功能强大的电子设计自动化软件中,快捷键是提升工作效率的利器。但很多用户都遇到过这样的困扰:明明按照教程设置了自定义快…...

终极免费抖音无水印视频下载完整教程:3步快速获取高清素材
终极免费抖音无水印视频下载完整教程:3步快速获取高清素材 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...
Pixel Couplet Gen应用场景:微信小程序开发者如何复用像素皇城UI组件
Pixel Couplet Gen应用场景:微信小程序开发者如何复用像素皇城UI组件 1. 项目背景与价值 Pixel Couplet Gen是一款融合传统春节文化与现代像素艺术风格的创新应用。作为微信小程序开发者,您可以直接复用其UI组件库,快速构建具有以下特点的应…...

揭秘Windows热键失踪案:Hotkey Detective侦探手册
揭秘Windows热键失踪案:Hotkey Detective侦探手册 【免费下载链接】hotkey-detective A small program for investigating stolen hotkeys under Windows 8 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾在Windows系统中按下熟悉的…...

从零开始:使用VSCode + CMake + Ninja + GCC构建高效MCU开发环境
1. 为什么需要这套开发环境? 作为一名在嵌入式领域摸爬滚打多年的开发者,我深知传统IDE的痛点。记得刚入行时,公司清一色使用某商业IDE,直到某天收到法务部的紧急通知——需要立即处理软件版权问题。这让我意识到,基于…...

Ku频段相控阵天线避坑指南:从G/T骤降到EIRP波动,这些实测数据你要知道
Ku频段相控阵天线性能衰减实测:60离轴角下的G/T与EIRP工程修正策略 相控阵天线在卫星通信领域正经历从实验室到工程应用的跨越式发展。当无人机以60离轴角追踪卫星时,实测数据显示天线增益可能骤降4.5dB——这个数字足以让精心计算的链路预算彻底失效。在…...

造相-Z-Image实战手册:基于Z-Image的AIGC版权合规提示词生成规范
造相-Z-Image实战手册:基于Z-Image的AIGC版权合规提示词生成规范 1. 项目概述与核心价值 造相-Z-Image是一款专为RTX 4090显卡优化的本地化文生图系统,基于通义千问官方Z-Image模型构建。这个项目最大的特点是将强大的AI图像生成能力带到了个人电脑上&…...