【六 (2)机器学习-EDA探索性数据分析模板】
目录
- 文章导航
- 一、EDA:
- 二、导入类库
- 三、导入数据
- 四、查看数据类型和缺失情况
- 五、确认目标变量和ID
- 六、查看目标变量分布情况
- 七、特征变量按照数据类型分成定量变量和定性变量
- 八、查看定量变量分布情况
- 九、查看定量变量的离散程度
- 十、查看定量变量与目标变量关系
- 十一、查看定性变量分布情况
- 十二、查看定性变量与目标变量关系
- 十三、查看定性变量对目标变量的显著性影响
- 十四、查看定性变量和目标变量的spearman相关系数
- 十五、查看定量变量与目标变量相关性
- 十六、查看定性变量与目标变量相关性
文章导航
【一 简明数据分析进阶路径介绍(文章导航)】
一、EDA:
EDA(Exploratory Data Analysis)即探索性数据分析,EDA通过可视化、统计和图形化的方法,对数据集进行全面的、非形式化的初步分析,帮助分析人员了解数据的基本特征,发现数据中的规律和模式。这有助于获取对数据的直观感受和深刻理解,为后续的数据处理和建模提供基础。
二、导入类库
# 导入类库
import numpy as np
import pandas as pd
import scipy.stats as statsimport matplotlib.pyplot as plt
import seaborn as sns
import plotly.express as px import warnings
warnings.filterwarnings('ignore')
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import RobustScalerfrom sklearn.decomposition import PCA
from sklearn.model_selection import cross_val_score, GridSearchCV, KFoldfrom sklearn.base import BaseEstimator, TransformerMixin, RegressorMixin
from sklearn.base import clone
from sklearn.linear_model import Lasso
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Ridge
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor, ExtraTreesRegressor
from sklearn.svm import SVR, LinearSVR
from sklearn.linear_model import ElasticNet, SGDRegressor, BayesianRidge
from sklearn.kernel_ridge import KernelRidge
from xgboost import XGBRegressor
# 显示中文
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# pandas显示所有行和列
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
三、导入数据
train = pd.read_csv('./train.csv')
test = pd.read_csv('./test.csv')train.head()
四、查看数据类型和缺失情况
train.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 90615 entries, 0 to 90614
Data columns (total 10 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 id 90615 non-null int64 1 Sex 90615 non-null object 2 Length 90615 non-null float643 Diameter 90615 non-null float644 Height 90615 non-null float645 Whole weight 90615 non-null float646 Whole weight.1 90615 non-null float647 Whole weight.2 90615 non-null float648 Shell weight 90615 non-null float649 Rings 90615 non-null int64
dtypes: float64(7), int64(2), object(1)
memory usage: 6.9+ MB
五、确认目标变量和ID
Target_features = ['Rings'] #目标变量
ID_features = ['id'] #id
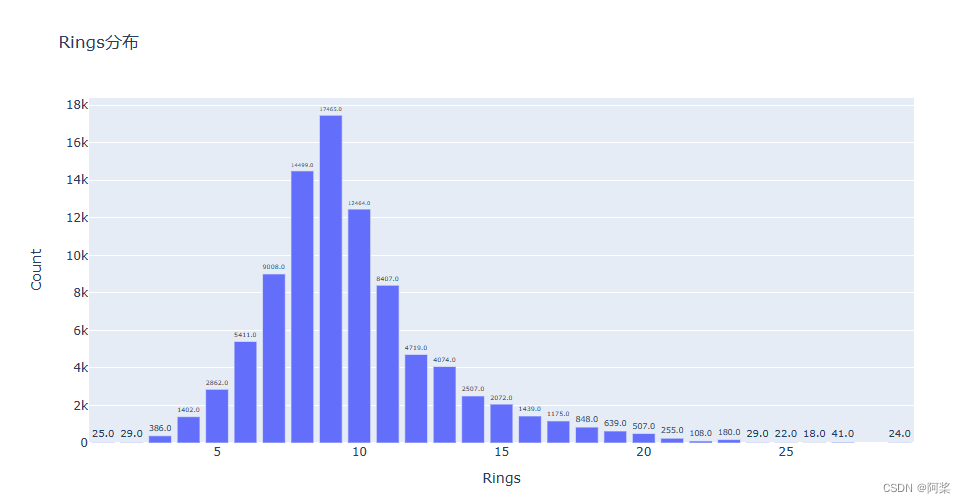
六、查看目标变量分布情况
Target_counts = train[Target_features].value_counts().reset_index()
Target_counts.columns = [Target_features[0], 'Count'] # 绘制条形图
fig = px.bar(Target_counts,x=Target_features[0], y='Count', title=Target_features[0]+'分布') # 遍历每个轨迹并设置文本
def set_text(trace): trace.text = [f"{val:.1f}" for val in trace.y] trace.textposition = 'outside' fig.for_each_trace(set_text) # 显示图表
fig.show()
七、特征变量按照数据类型分成定量变量和定性变量
# 移除ID和目标变量
train_columns = list(train.columns)
train_columns.remove(Target_features[0])
train_columns.remove(ID_features[0])# 特征变量按照数据类型分成定量变量和定性变量
quantitative = [feature for feature in train_columns if train.dtypes[feature] != 'object'] # 定量变量
print('定量变量')
print(quantitative)
qualitative = [feature for feature in train_columns if train.dtypes[feature] == 'object'] # 定性变量
print('定性变量')
print(qualitative)
定量变量
['Length', 'Diameter', 'Height', 'Whole weight', 'Whole weight.1', 'Whole weight.2', 'Shell weight']
定性变量
['Sex']
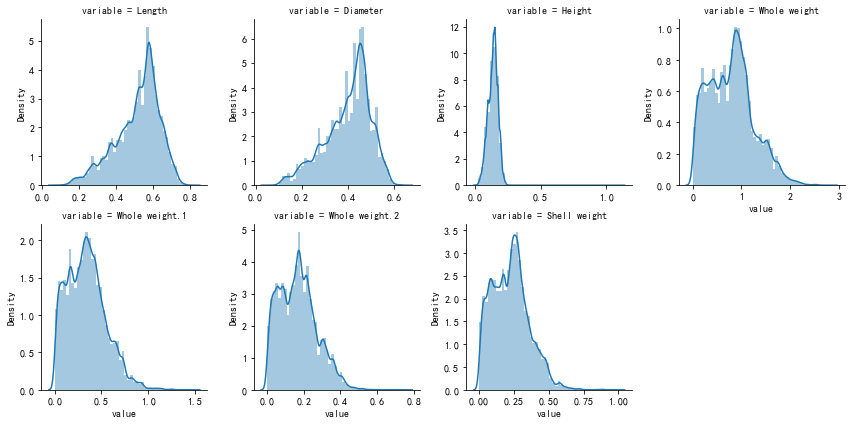
八、查看定量变量分布情况
# 查看定量变量分布情况
m_cont = pd.melt(train, value_vars=quantitative)
g = sns.FacetGrid(m_cont, col='variable', col_wrap=4, sharex=False, sharey=False)
g.map(sns.distplot, 'value')
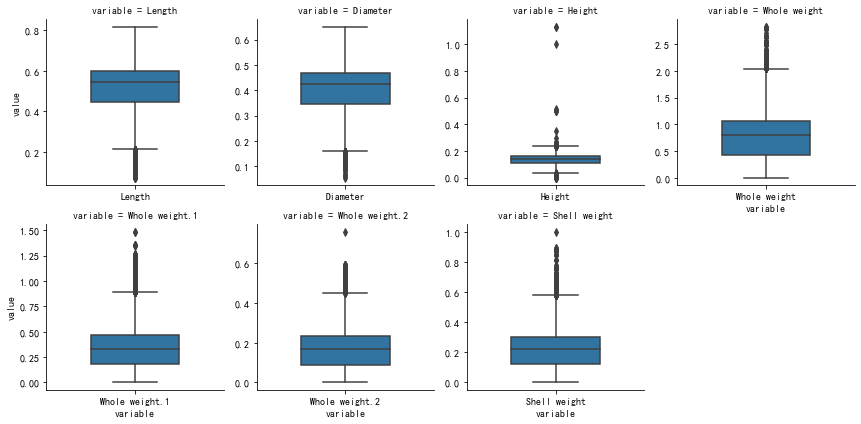
九、查看定量变量的离散程度
# 查看定量变量的离散程度
def plot_boxplots(df):m_disc = pd.melt(df)g = sns.FacetGrid(m_disc, col='variable', col_wrap=4, sharex=False, sharey=False)g.map(sns.boxplot, 'variable', 'value', width=0.5)plt.show()plot_boxplots(train[quantitative])
十、查看定量变量与目标变量关系
# 定量变量与目标变量关系图
m_cont = pd.melt(train, id_vars=Target_features[0], value_vars=quantitative)
g = sns.FacetGrid(m_cont, col='variable', col_wrap=4, sharex=False, sharey=True)
g.map(plt.scatter, 'value', Target_features[0])

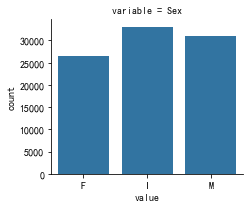
十一、查看定性变量分布情况
# 定性变量频数统计图
m_disc = pd.melt(train, value_vars=qualitative)
g = sns.FacetGrid(m_disc, col='variable', col_wrap=4, sharex=False, sharey=False)
g.map(sns.countplot, 'value')
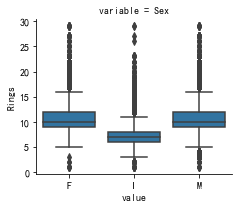
十二、查看定性变量与目标变量关系
# 定性变量与目标变量关系图
m_disc = pd.melt(train, id_vars=Target_features[0], value_vars=qualitative)
g = sns.FacetGrid(m_disc, col='variable', col_wrap=4, sharex=False, sharey=False)
g.map(sns.boxplot, 'value', Target_features[0])
十三、查看定性变量对目标变量的显著性影响
# 查看定性变量对目标变量的显著性影响
def anova(frame, qualitative):anv = pd.DataFrame()anv['feature'] = qualitativep_vals = []for fea in qualitative:samples = []cls = frame[fea].unique() # 变量的类别值for c in cls:c_array = frame[frame[fea]==c][Target_features[0]].valuessamples.append(c_array)p_val = stats.f_oneway(*samples)[1] # 获得p值,p值越小,对SalePrice的显著性影响越大p_vals.append(p_val)anv['pval'] = p_valsreturn anv.sort_values('pval')
a = anova(train, qualitative)
a['disparity'] = np.log(1./a['pval'].values) # 对SalePrice的影响悬殊度
plt.figure(figsize=(8, 6))
sns.barplot(x='feature', y='disparity', data=a)
plt.xticks(rotation=90)
plt.show()

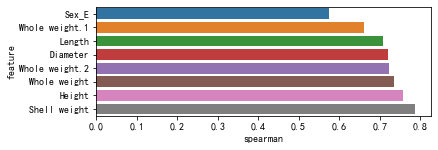
十四、查看定性变量和目标变量的spearman相关系数
# 查看定性变量和目标变量的spearman相关系数
# 需要先把定性变量处理为数值类型
def encode(frame, feature):ordering = pd.DataFrame()ordering['val'] = frame[feature].unique()ordering.index = ordering['val']ordering['spmean'] = frame[[feature, Target_features[0]]].groupby(feature)[Target_features[0]].mean()ordering = ordering.sort_values('spmean')ordering['ordering'] = np.arange(1, ordering.shape[0]+1)ordering = ordering['ordering'].to_dict() # 返回的数据样例{category1:1, category2:2, ...}# 对frame[feature]编码for category, code_value in ordering.items():frame.loc[frame[feature]==category, feature+'_E'] = code_value
qual_encoded = []
for qual in qualitative:encode(train, qual)qual_encoded.append(qual+'_E')
# print(qual_encoded)def spearman(frame, features):spr = pd.DataFrame()spr['feature'] = featuresspr['spearman'] = [frame[f].corr(frame[Target_features[0]], 'spearman') for f in features]spr = spr.sort_values('spearman')plt.figure(figsize=(6, 0.25*len(features)))sns.barplot(x='spearman', y='feature', data=spr)
spearman(train, quantitative+qual_encoded)
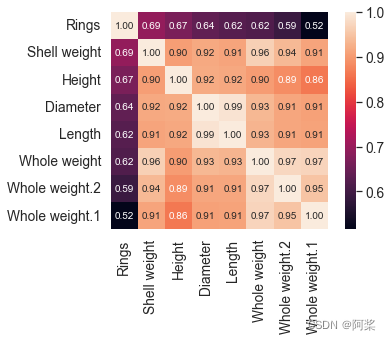
十五、查看定量变量与目标变量相关性
# 定量变量与目标变量相关性
# plt.figure(1, figsize=(12,9))
corrmat = train[quantitative+[Target_features[0]]].corr()
k = 10 #number of variables for heatmap
cols = corrmat.nlargest(k, Target_features[0])[Target_features[0]].index
corr = train[list(cols)].corr()
sns.set(font_scale=1.25)
sns.heatmap(corr, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()
十六、查看定性变量与目标变量相关性
# 定性变量与目标变量相关性# plt.figure(1, figsize=(12,9))
corrmat = train[qual_encoded+[Target_features[0]]].corr()
k = 10 #number of variables for heatmap
cols = corrmat.nlargest(k, Target_features[0])[Target_features[0]].index
corr = train[list(cols)].corr()
sns.set(font_scale=1.25)
sns.heatmap(corr, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()

相关文章:
【六 (2)机器学习-EDA探索性数据分析模板】
目录 文章导航一、EDA:二、导入类库三、导入数据四、查看数据类型和缺失情况五、确认目标变量和ID六、查看目标变量分布情况七、特征变量按照数据类型分成定量变量和定性变量八、查看定量变量分布情况九、查看定量变量的离散程度十、查看定量变量与目标变量关系十一…...
Java集合——Map、Set和List总结
文章目录 一、Collection二、Map、Set、List的不同三、List1、ArrayList2、LinkedList 四、Map1、HashMap2、LinkedHashMap3、TreeMap 五、Set 一、Collection Collection 的常用方法 public boolean add(E e):把给定的对象添加到当前集合中 。public void clear(…...

Python TensorFlow 2.6 获取 MNIST 数据
Python TensorFlow 2.6 获取 MNIST 数据 2 Python TensorFlow 2.6 获取 MNIST 数据1.1 获取 MNIST 数据1.2 检查 MNIST 数据 2 Python 将npz数据保存为txt3 Java 获取数据并使用SVM训练4 Python 测试SVM准确度 2 Python TensorFlow 2.6 获取 MNIST 数据 1.1 获取 MNIST 数据 …...

EChart简单入门
echart的安装就细不讲了,直接去官网下,实在不会的直接用cdn,省的一番口舌。 cdn.staticfile.net/echarts/4.3.0/echarts.min.js 正入话题哈 什么是EChart? EChart 是一个使用 JavaScript 实现的开源可视化库,Echart支持多种常…...
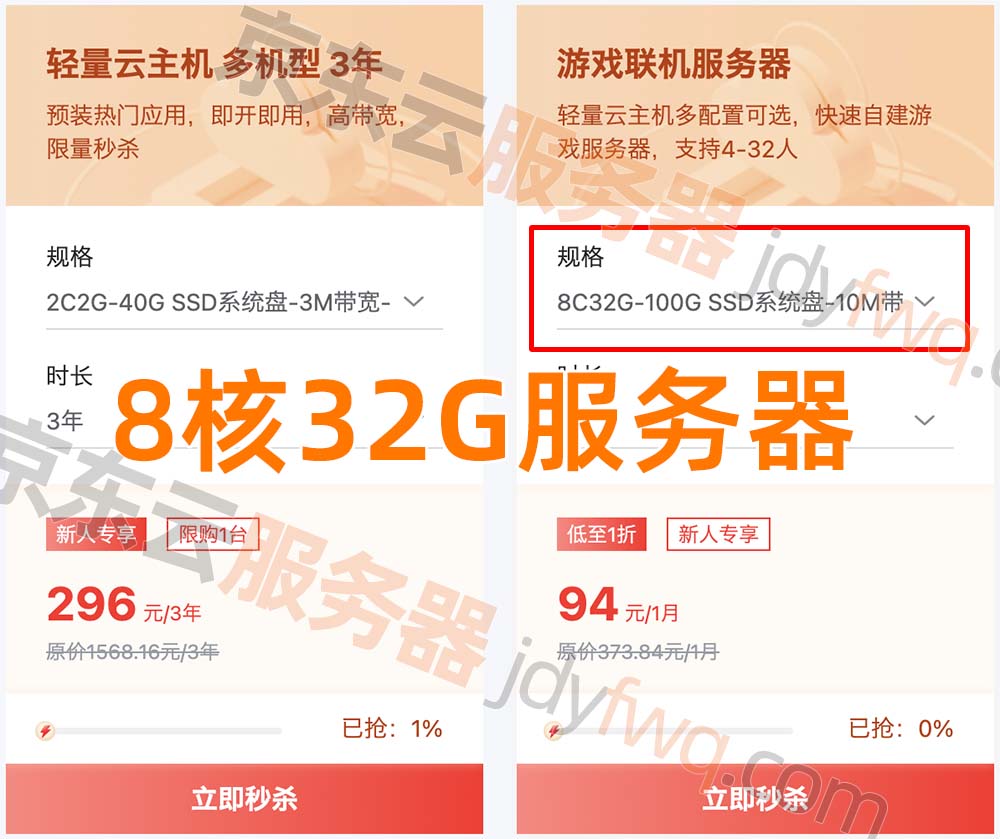
阿里云8核32G云服务器租用优惠价格表,包括腾讯云和京东云
8核32G云服务器租用优惠价格表,云服务器吧yunfuwuqiba.com整理阿里云8核32G服务器、腾讯云8核32G和京东云8C32G云主机配置报价,腾讯云和京东云是轻量应用服务器,阿里云是云服务器ECS: 阿里云8核32G服务器 阿里云8核32G服务器价格…...

设计模式,工厂方法模式
工厂方法模式概述 工厂方法模式,是对简单工厂模式的进一步抽象和推广。以我个人理解,工厂方法模式就是对生产工厂的抽象,就是用一个生产工厂的工厂来进行目标对象的创建。 工厂方法模式的角色组成和简单工厂方法相比,创建了一个…...

WPF中嵌入3D模型通用结构
背景:wpf本身有提供3D的绘制,但是自己通过代码描绘出3D是比较困难的。3D库helix-toolkit支持调用第三方生成的模型,比如Blender这些,所以在wpf上使用3D就变得非常简单。这里是一个通过helix-toolkit库调用第三方生成的3d模型的样例…...

举个例子说明联邦学习
学习目标: 一周掌握 Java 入门知识 学习内容: 联邦学习是一种机器学习方法,它允许多个参与者协同训练一个共享模型,同时保持各自数据的隐私。 联邦学习概念(例子): 假设有三家医院,它们都希望…...

【Python】免费的图片/图标网站
专栏文章索引:Python 有问题可私聊:QQ:3375119339 这里是我收集的几个免费的图片/图标网站: iconfont-阿里巴巴矢量图标库icon(.ico)INCONFINDER(.ico)...
)
Pytorch中的nn.Embedding()
模块的输入是一个索引列表,输出是相应的词嵌入。 Embedding.weight(Tensor)–形状模块(num_embeddings,Embedding_dim)的可学习权重,初始化自(0,1)。 也就是…...

WebSocketServer后端配置,精简版
首先需要maven配置 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-websocket</artifactId><version>2.1.3.RELEASE</version></dependency> 然后加上配置类 这段代码是一个Spri…...

Python程序设计 多重循环(二)
1.打印数字图形 输入n(n<9),输出由数字组成的直角三角图形。例如,输入5,输出图形如下 nint(input("")) #开始 for i in range(1,n1):for j in range(1,i1):print(j,end"")print()#结束 2.打印字符图形 …...
)
前端面试题--CSS系列(一)
CSS系列--持续更新中 1.CSS预处理器有哪些类型,有什么区别2.盒模型是什么,有哪两种类型3.css选择器有哪些,优先级是怎样的,哪些属性可以继承4. 说说em/px/rem/vh/vw的区别5.元素实现水平垂直居中的方法有哪些,如果元素…...
VSCode好用插件
由于现在还是使用vue2,所以本文只记录vue2开发中好用的插件。 美化类插件不介绍了,那些貌似对生产力起不到什么大的帮助,纯粹的“唯心主义”罢了,但是如果你有兴趣的话可以查看上一篇博客:VSCode美化 1. vuter 简介&…...

Vue3:对ref、reactive的一个性能优化API
一、情景说明 我们知道,在Vue3中,想要创建响应式的变量,就要用到ref、reactive来包裹一下数据即可。 但是,这里有个损耗性能的地方 就是,被它包裹的数据,都会构建成响应式的,无论多少层次&…...
Python 用pygame简简单单实现一个打砖块
# -*- coding: utf-8 -*- # # # Copyright (C) 2024 , Inc. All Rights Reserved # # # Time : 2024/3/30 14:34 # Author : 赫凯 # Email : hekaiiii163.com # File : ballgame.py # Software: PyCharm import math import randomimport pygame import sys#…...

软考113-上午题-【计算机网络】-IPv6、无线网络、Windows命令
一、IPv6 IPv6 具有长达 128 位的地址空间,可以彻底解决 IPv4 地址不足的问题。由于 IPv4 地址是32 位二进制,所能表示的IP 地址个数为 2^32 4 294 967 29640 亿,因而在因特网上约有 40亿个P 地址。 由 32 位的IPv4 升级至 128 位的IPv6&am…...
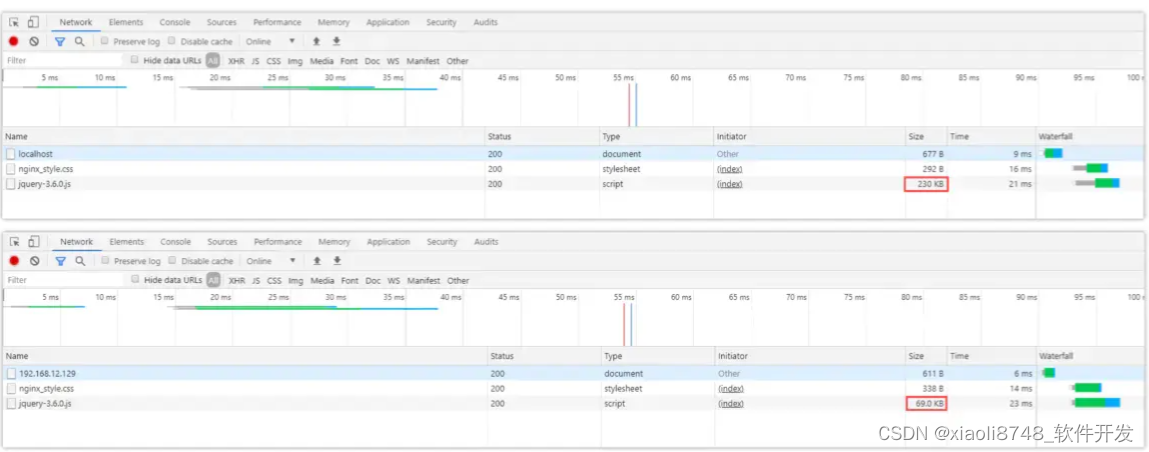
深入浅出 -- 系统架构之负载均衡Nginx资源压缩
一、Nginx资源压缩 建立在动静分离的基础之上,如果一个静态资源的Size越小,那么自然传输速度会更快,同时也会更节省带宽,因此我们在部署项目时,也可以通过Nginx对于静态资源实现压缩传输,一方面可以节省带宽…...
基于jsp+Spring boot+mybatis的图书管理系统设计和实现
基于jspSpring bootmybatis的图书管理系统设计和实现 博主介绍:多年java开发经验,专注Java开发、定制、远程、文档编写指导等,csdn特邀作者、专注于Java技术领域 作者主页 央顺技术团队 Java毕设项目精品实战案例《1000套》 欢迎点赞 收藏 ⭐留言 文末获…...
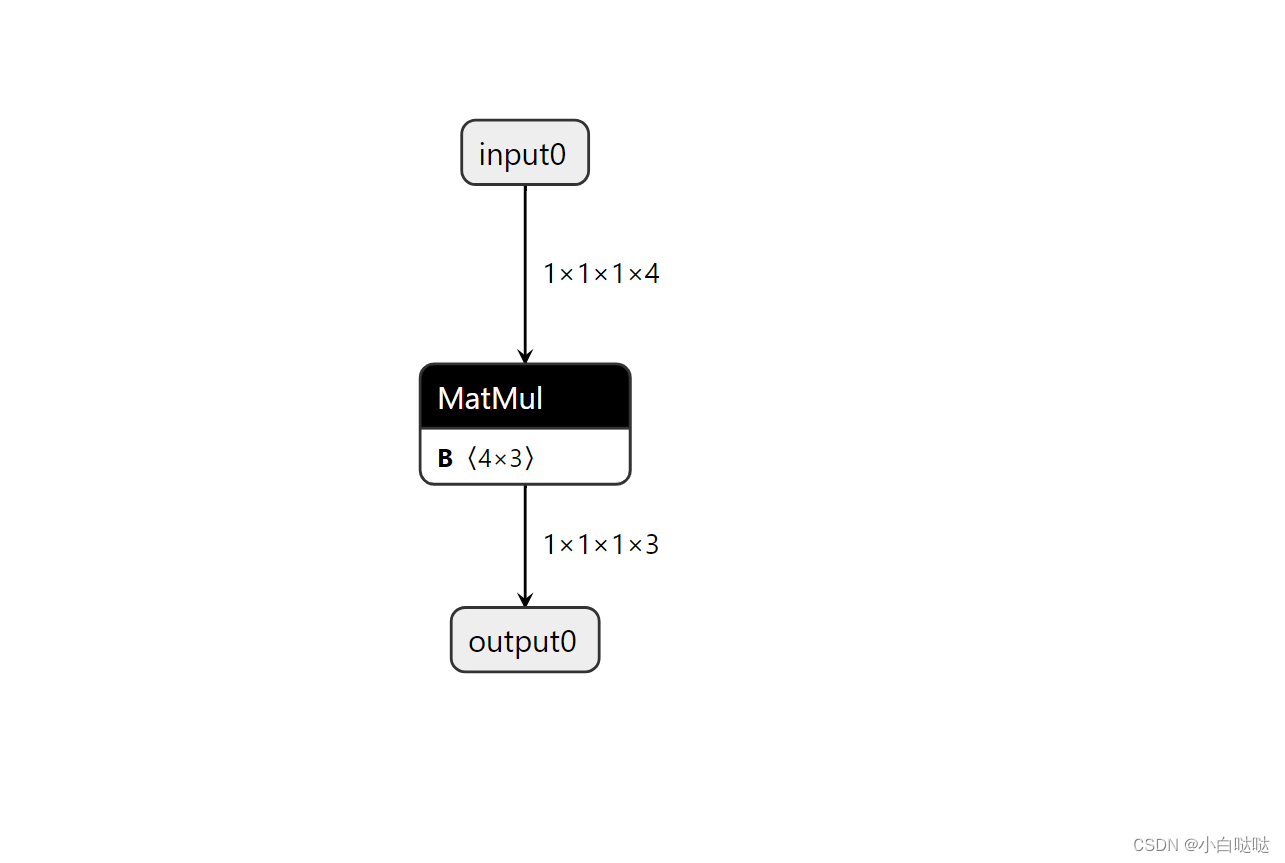
Pytorch转onnx
pytorch 转 onnx 模型需要函数 torch.onnx.export。 def export(model: Union[torch.nn.Module, torch.jit.ScriptModule, torch.jit.ScriptFunction],args: Union[Tuple[Any, ...], torch.Tensor],f: Union[str, io.BytesIO],export_params: bool True,verbose: bool False…...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...

YSYX学习记录(八)
C语言,练习0: 先创建一个文件夹,我用的是物理机: 安装build-essential 练习1: 我注释掉了 #include <stdio.h> 出现下面错误 在你的文本编辑器中打开ex1文件,随机修改或删除一部分,之后…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

uniapp 实现腾讯云IM群文件上传下载功能
UniApp 集成腾讯云IM实现群文件上传下载功能全攻略 一、功能背景与技术选型 在团队协作场景中,群文件共享是核心需求之一。本文将介绍如何基于腾讯云IMCOS,在uniapp中实现: 群内文件上传/下载文件元数据管理下载进度追踪跨平台文件预览 二…...

RushDB开源程序 是现代应用程序和 AI 的即时数据库。建立在 Neo4j 之上
一、软件介绍 文末提供程序和源码下载 RushDB 改变了您处理图形数据的方式 — 不需要 Schema,不需要复杂的查询,只需推送数据即可。 二、Key Features ✨ 主要特点 Instant Setup: Be productive in seconds, not days 即时设置 :在几秒钟…...
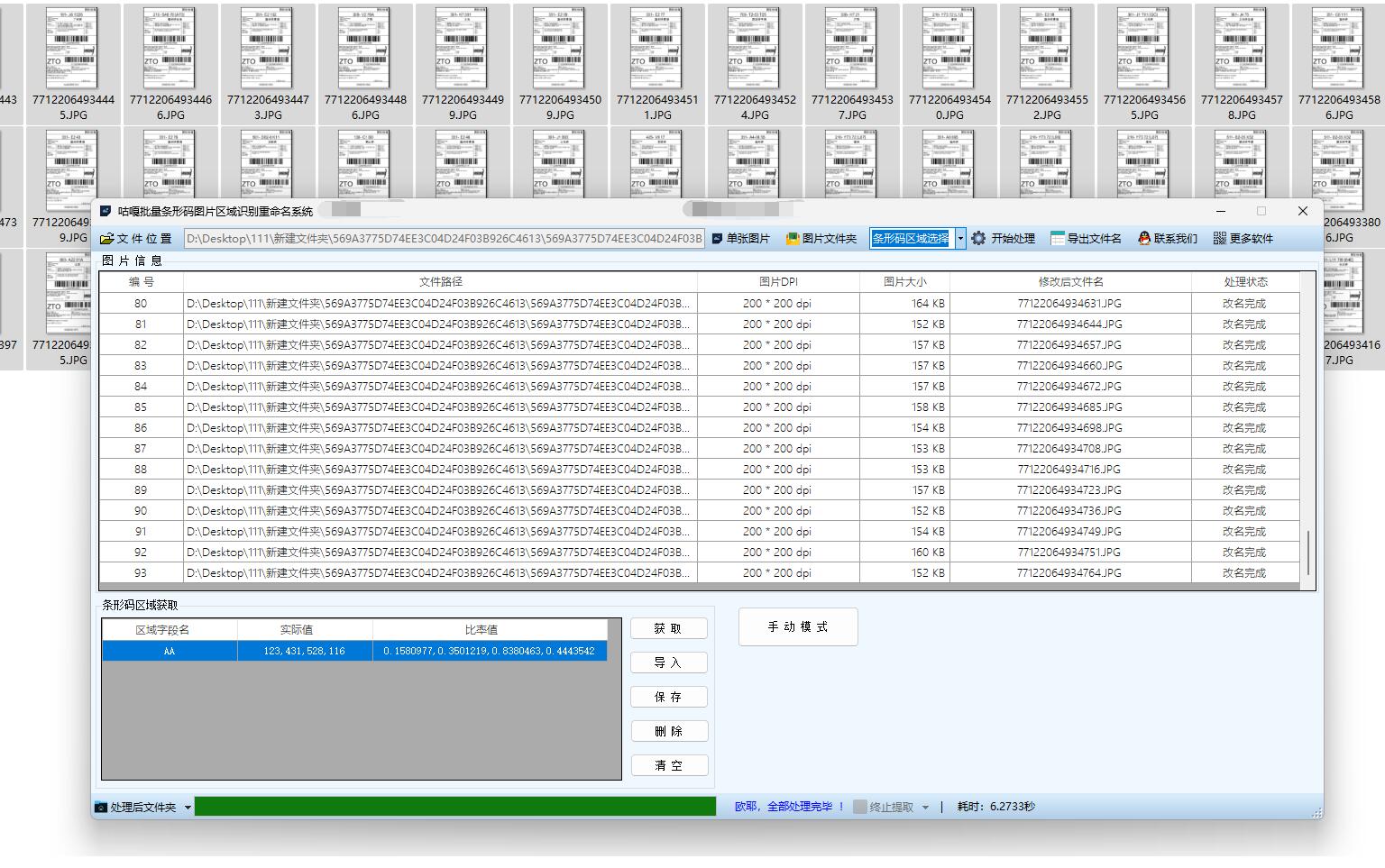
【工具教程】多个条形码识别用条码内容对图片重命名,批量PDF条形码识别后用条码内容批量改名,使用教程及注意事项
一、条形码识别改名使用教程 打开软件并选择处理模式:打开软件后,根据要处理的文件类型,选择 “图片识别模式” 或 “PDF 识别模式”。如果是处理包含条形码的 PDF 文件,就选择 “PDF 识别模式”;若是处理图片文件&…...
Linux【5】-----编译和烧写Linux系统镜像(RK3568)
参考:讯为 1、文件系统 不同的文件系统组成了:debian、ubuntu、buildroot、qt等系统 每个文件系统的uboot和kernel是一样的 2、源码目录介绍 目录 3、正式编译 编译脚本build.sh 帮助内容如下: Available options: uboot …...

C++信息学竞赛中常用函数的一般用法
在C 信息学竞赛中,有许多常用函数能大幅提升编程效率。下面为你介绍一些常见函数及其一般用法: 一、比较函数 1、max()//求出a,b的较大值 int a10,b5,c;cmax(a,b);//得出的结果就是c等于10. 2、min()//求出a,b的较小值 int a1…...

夏普比率(Sharpe ratio)
具有投资常识的人都明白,投资光看收益是不够的,还要看承受的风险,也就是收益风险比。 夏普比率描述的正是这个概念,即每承受一单位的总风险,会产生多少超额的报酬。 用数学公式描述就是: 其中࿱…...