人工智能|深度学习——基于Xception实现戴口罩人脸表情识别
一、项目背景
近年来,随着人工智能技术的不断发展,人脸表情识别已经成为了计算机视觉领域中的重要研究方向之一。然而,在当前的疫情形势下,佩戴口罩已经成为了一项必要的防疫措施,但是佩戴口罩会遮挡住人脸的部分区域,给表情识别带来了一定的挑战。
目前,已经有很多关于没有遮挡人脸的表情识别的技术研究,例如基于深度学习的卷积神经网络(CNN)和循环神经网络(RNN)等。这些技术已经取得了不错的成果,并且已经应用于实际的场景中,例如情感识别、人机交互等。
然而,在佩戴口罩的情况下,传统的表情识别技术无法识别出人脸的表情信息,因为口罩遮挡了人脸的大部分区域,导致识别的准确率降低。因此,一些研究人员开始关注口罩人脸识别技术,并提出了一些新的方法来解决这个问题。例如,他们使用图像处理技术来减少口罩的遮挡效果,或者使用额外的传感器来收集面部表情的其他数据。
然而,戴口罩人脸表情识别存在一些技术难点。首先,佩戴口罩会导致人脸的特征信息被遮挡,难以准确识别。其次,戴口罩人脸的表情信息可能会因为口罩遮挡而变得不够丰富,这也给表情识别带来了一定的挑战。最后,因为戴口罩人脸表情识别的研究资料较少,数据集需要个人收集标注。因此,如何在遮挡的情况下准确地识别出人脸表情信息是戴口罩人脸表情识别技术研究的重要问题之一
二、数据集来源与详情
2.1 来源
本项目基于fer2013人脸表情数据集,它于2013年国际机器学习会议(ICML)上推出,并成为比较表情识别模型性能的基准之一,同时也作为了2013年Kaggle人脸识别比赛的数据。Fer2013包含28709张训练集图像、3589张公开测试集图像和3589张私有测试集图像,每张图像为4848大小的灰度图片,如下图所示。Fer2013数据集中由有生气(angry)、厌恶(disgust)、恐惧(fear)、开心(happy)、难过(sad)、惊讶(surprise)和中性(neutral)七个类别组成。由于这个数据集大多是通过爬虫在互联网上进行爬取所得,因此存在一定的误差性。

本项目使用face-mask对人脸添加口罩,简单介绍一下face-mask是基于dlib和face_recognition两大人脸检测的库实现的人脸关键点检测的方法。处理完成后共得到11870张训练集,3016张测试集(原数据集存在一些不能被face-mask所识别到的人脸)。经过实验发现sad、disgust、anger眼部特征十分相识,因此本试验只进行对anger、fear、happy、surprise的分类。
2.2 详细处理
- 安装face-mask 在安装之前要先配置dlib,具体过程请大家自行探索。
pip install face-mask
- 关键代码
# -*- coding: utf-8 -*-
import os
import numpy as np
from PIL import Image, ImageFile__version__ = '0.3.0'IMAGE_DIR = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'images')
DEFAULT_IMAGE_PATH = os.path.join(IMAGE_DIR, 'default-mask.png')
BLACK_IMAGE_PATH = os.path.join(IMAGE_DIR, 'black-mask.png')
BLUE_IMAGE_PATH = os.path.join(IMAGE_DIR, 'blue-mask.png')
RED_IMAGE_PATH = os.path.join(IMAGE_DIR, 'red-mask.png')class FaceMasker:KEY_FACIAL_FEATURES = ('nose_bridge', 'chin')def __init__(self, face_path, mask_path, show=False, model='hog'):self.face_path = face_pathself.mask_path = mask_pathself.show = showself.model = modelself._face_img: ImageFile = Noneself._mask_img: ImageFile = Nonedef mask(self):import face_recognitionface_image_np = face_recognition.load_image_file(self.face_path)face_locations = face_recognition.face_locations(face_image_np, model=self.model)face_landmarks = face_recognition.face_landmarks(face_image_np, face_locations)self._face_img = Image.fromarray(face_image_np)self._mask_img = Image.open(self.mask_path)found_face = Falsefor face_landmark in face_landmarks:# check whether facial features meet requirementskip = Falsefor facial_feature in self.KEY_FACIAL_FEATURES:if facial_feature not in face_landmark:skip = Truebreakif skip:continue# mask facefound_face = Trueself._mask_face(face_landmark)if found_face:if self.show:self._face_img.show()# saveself._save()else:print('Found no face.')def _mask_face(self, face_landmark: dict):nose_bridge = face_landmark['nose_bridge']nose_point = nose_bridge[len(nose_bridge) * 1 // 4]nose_v = np.array(nose_point)chin = face_landmark['chin']chin_len = len(chin)chin_bottom_point = chin[chin_len // 2]chin_bottom_v = np.array(chin_bottom_point)chin_left_point = chin[chin_len // 8]chin_right_point = chin[chin_len * 7 // 8]# split mask and resizewidth = self._mask_img.widthheight = self._mask_img.heightwidth_ratio = 1.2new_height = int(np.linalg.norm(nose_v - chin_bottom_v))# leftmask_left_img = self._mask_img.crop((0, 0, width // 2, height))mask_left_width = self.get_distance_from_point_to_line(chin_left_point, nose_point, chin_bottom_point)mask_left_width = int(mask_left_width * width_ratio)mask_left_img = mask_left_img.resize((mask_left_width, new_height))# rightmask_right_img = self._mask_img.crop((width // 2, 0, width, height))mask_right_width = self.get_distance_from_point_to_line(chin_right_point, nose_point, chin_bottom_point)mask_right_width = int(mask_right_width * width_ratio)mask_right_img = mask_right_img.resize((mask_right_width, new_height))# merge masksize = (mask_left_img.width + mask_right_img.width, new_height)mask_img = Image.new('RGBA', size)mask_img.paste(mask_left_img, (0, 0), mask_left_img)mask_img.paste(mask_right_img, (mask_left_img.width, 0), mask_right_img)# rotate maskangle = np.arctan2(chin_bottom_point[1] - nose_point[1], chin_bottom_point[0] - nose_point[0])rotated_mask_img = mask_img.rotate(angle, expand=True)# calculate mask locationcenter_x = (nose_point[0] + chin_bottom_point[0]) // 2center_y = (nose_point[1] + chin_bottom_point[1]) // 2offset = mask_img.width // 2 - mask_left_img.widthradian = angle * np.pi / 180box_x = center_x + int(offset * np.cos(radian)) - rotated_mask_img.width // 2box_y = center_y + int(offset * np.sin(radian)) - rotated_mask_img.height // 2# add maskself._face_img.paste(mask_img, (box_x, box_y), mask_img)def _save(self):path_splits = os.path.splitext(self.face_path)new_face_path = path_splits[0] + '-with-mask' + path_splits[1]self._face_img.save(new_face_path)print(f'Save to {new_face_path}')@staticmethoddef get_distance_from_point_to_line(point, line_point1, line_point2):distance = np.abs((line_point2[1] - line_point1[1]) * point[0] +(line_point1[0] - line_point2[0]) * point[1] +(line_point2[0] - line_point1[0]) * line_point1[1] +(line_point1[1] - line_point2[1]) * line_point1[0]) / \np.sqrt((line_point2[1] - line_point1[1]) * (line_point2[1] - line_point1[1]) +(line_point1[0] - line_point2[0]) * (line_point1[0] - line_point2[0]))return int(distance)if __name__ == '__main__':FaceMasker("./face/1.jpg", DEFAULT_IMAGE_PATH, True, 'hog').mask()
- 本项目已为大家提供处理好的数据集地址 ,后边直接使用。如果想了解更多处理细节请关注我的主页

三、模型介绍
3.1 Xception简介
Xception是Google公司继Inception后提出的对 Inception-v3 的另一种改进。作者认为,通道之间的相关性与空间相关性最好要分开处理。于是采用 Separable Convolution来替换原来 Inception-v3中的卷积操作。
传统卷积的实现过程:
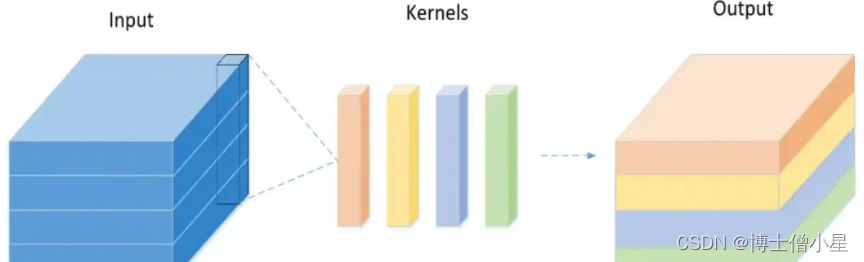
Depthwise Separable Convolution 的实现过程:
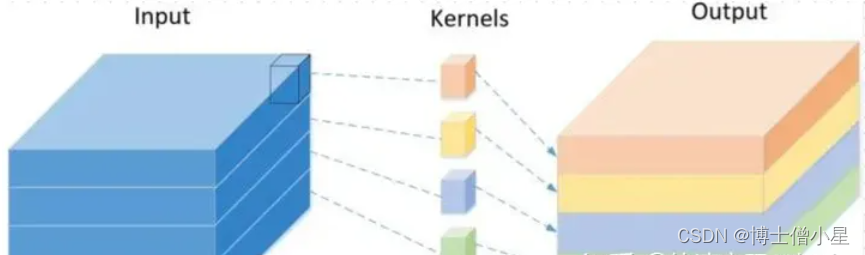
深度可分离卷积 Depthwise Separable Convolution
Depthwise Separable Convolution 与 极致的 Inception 区别:
极致的 Inception:
- 第一步:普通 1×1 卷积。
- 第二步:对 1×1 卷积结果的每个 channel,分别进行 3×3卷积操作,并将结果 concat。
Depthwise Separable Convolution:
- 第一步:Depthwise 卷积,对输入的每个channel,分别进行 3×3卷积操作,并将结果 concat。
- 第二步:Pointwise 卷积,对 Depthwise 卷积中的 concat 结果,进行1×1卷积操作。
两种操作的顺序不一致:Inception 先进行1×1卷积,再进行3×3 卷积;Depthwise Separable Convolution 先进行 3×3卷积,再进行 1×1卷积。
3.2 Xception网络框架
先进行普通卷积操作,再对 1×1 卷积后的每个channel分别进行 3×3 卷积操作,最后将结果 concat。
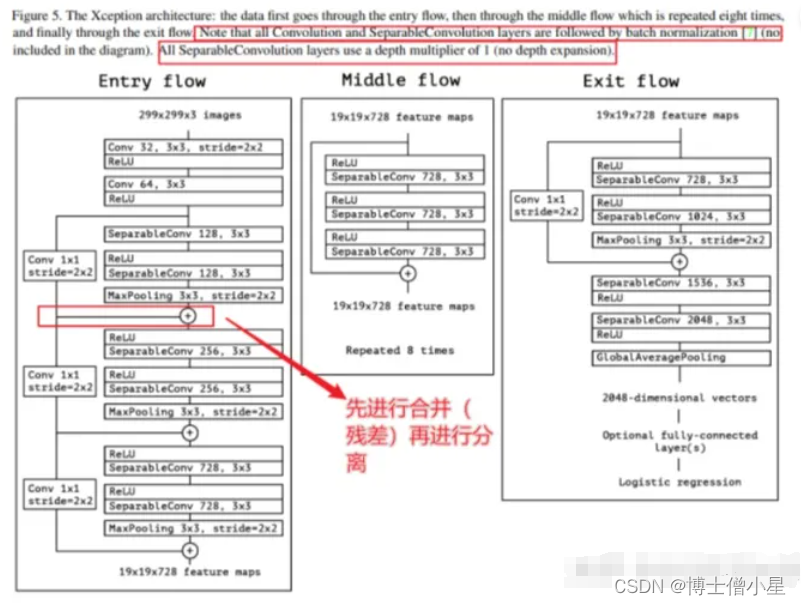
注:Xception包含三个部分:输入部分,中间部分和结尾部分;其中所有卷积层和可分离卷积层后面都使用Batch Normalization处理,所有的可分离卷积层使用一个深度乘数1(深度方向并不进行扩充)。
三、技术路线
3.1 PaddleClas简介
飞桨图像分类套件PaddleClas是飞桨为工业界和学术界所准备的一个图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。
PaddleClas特性:
- 丰富的模型库:基于ImageNet1k分类数据集,PaddleClas提供了29个系列的分类网络结构和训练配置,133个预训练模型和性能评估。
- SSLD知识蒸馏:基于该方案蒸馏模型的识别准确率普遍提升3%以上。
- 数据增广:支持AutoAugment、Cutout、Cutmix等8种数据增广算法详细介绍、代码复现和在统一实验环境下的效果评估。
- 10万类图像分类预训练模型:百度自研并开源了基于10万类数据集训练的 ResNet50_vd 模型,在一些实际场景中,使用该预训练模型的识别准确率最多可以提升30%。
- 多种训练方案,包括多机训练、混合精度训练等。
- 多种预测推理、部署方案,包括TensorRT预测、Paddle-Lite预测、模型服务化部署、模型量化、Paddle Hub等。可运行于Linux、Windows、MacOS等多种系统。
3.2 模型库链接
Paddleclas代码GitHub链接: https://github.com/PaddlePaddle/PaddleClas
Paddleclas代码Gitee链接: https://gitee.com/PaddlePaddle/PaddleClas
Paddleclas文档链接: https://paddleclas.readthedocs.io
四、环境配置
- 更新pip(很重要,要不然很多包装不上)
pip install --upgrade pip
- 克隆Paddleclas仓库
%cd /home/aistudio/work/
# 克隆Paddleclas仓库
# gitee 国内下载比较快
!git clone https://gitee.com/PaddlePaddle/PaddleClas.git
# github
# !git clone https://github.com/PaddlePaddle/PaddleClas.git
- 导入package
%cd /home/aistudio/work/PaddleClas
# 导入package
!pip install -r requirements.txt
- 解压数据集
# 解压数据集
# 注意数据集压缩包的名字和位置
!echo "解压数据集"
!unzip -oq /home/aistudio/data/data201630/fer2013(添加口罩_四分类) _.zip -d /home/aistudio/work/PaddleClas/dataset
- 数据集结构
dataset:train:imags # 训练集图片train_list.txt # 训练集标签eval:imags # 评估图片eval_list.txt # 评估标签test:imags #测试图片test_list.txt #测试标签list.txt # 标签对应含义五、模型训练
5.1 配置训练参数文件(已为大家提供参考参数文件)
- 本项目使用的配置文件是
/home/aistudio/work/PaddleClas/ppcls/configs/ImageNet/Xception/Xception65.yaml
# global configs
Global:...output_dir: ./output/ # 模型保存路径epochs: 200 # 训练步数...use_visualdl: Ture # 训练可视化,在训练时可以绘制出可视化图像...save_inference_dir: ./inference #导出模型保存路径....Optimizer:....lr:name: Cosinelearning_rate: 0.045 # 学习率,根据训练时的可视化图像进行调整regularizer:name: 'L2'coeff: 0.0001
.....
# data loader for train and eval
DataLoader:Train:dataset:name: ImageNetDatasetimage_root: ./dataset/ # 图片路径cls_label_path: ./dataset/train/train_list.txt # 标签路径......sampler:name: DistributedBatchSamplerbatch_size: 64 # 根据配置进行调整,在环境最左边工具栏的监控中根据显存和cup占用率进行调整....Eval:dataset: name: ImageNetDatasetimage_root: ./dataset/cls_label_path: ./dataset/eval/eval_list.txt # 同上.....Infer:infer_imgs: ./dataset/test/imags/10276.jpg # 预测的图片batch_size: 10 # 根据实际调整....class_id_map_file: ./dataset/test/list.txt# 此文件是标签对应的含义,根据开始数据集说明时的图片可知:0对应生气 1害怕.....5.2 训练
%cd /home/aistudio/work/PaddleClas
!echo "开始炼丹"
!python3 -m paddle.distributed.launch tools/train.py \
-c /home/aistudio/work/PaddleClas/ppcls/configs/ImageNet/Xception/Xception65.yaml
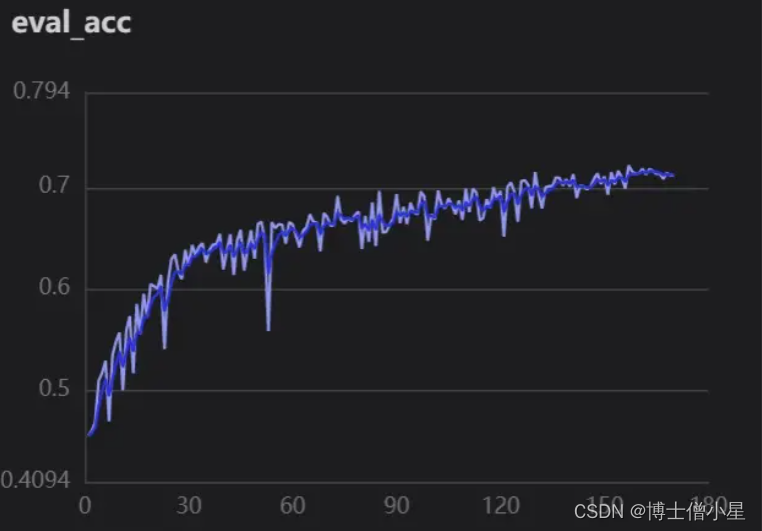
- 精确度
5.3 加载训练可视化
- 设置VisualDL服务

- 加载logdir
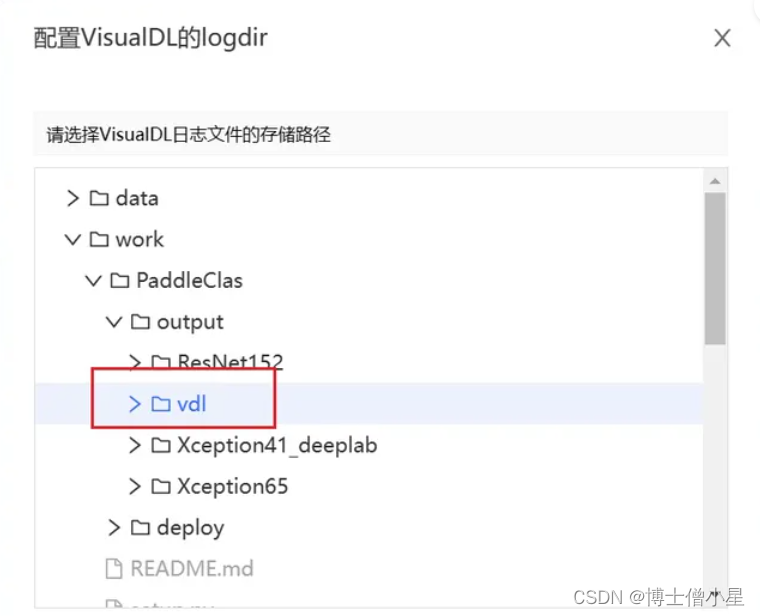
- 启动打开


5.4 效果
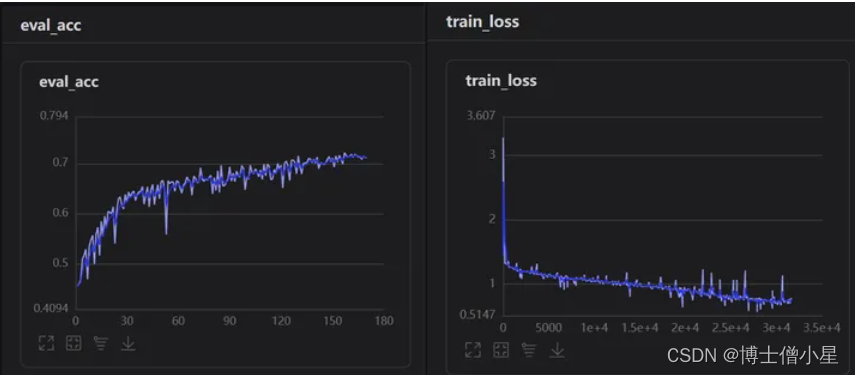
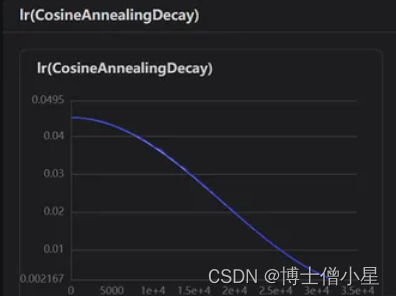
六、模型预测
备注:
- 这里-o Global.pretrained_model="/home/aistudio/work/PaddleClas/output/Xception65/best_model" 指定了当前最佳权重所在的路径,如果指定其他权重,只需替换对应的路径即可。
- 默认是对 /home/aistudio/work/data/test 进行预测,此处也可以通过增加字段 -o Infer.infer_imgs=xxx 对其他图片预测。
- 默认输出的是 Top-5 的值,如果希望输出 Top-k 的值,可以指定-o Infer.PostProcess.topk=k,其中,k 为您指定的值。
修改
/home/aistudio/work/PaddleClas-2.4.0/ppcls/engine/engine.py中的推理代码infer(self),将推理结果存入csv文件。
@paddle.no_grad()def infer(self):assert self.mode == "infer" and self.eval_mode == "classification"total_trainer = dist.get_world_size()local_rank = dist.get_rank()image_list = get_image_list(self.config["Infer"]["infer_imgs"])# data splitimage_list = image_list[local_rank::total_trainer]with open("/home/aistudio/work/PaddleClas/dataset/eval/eval_list.txt", "r") as f:dat = f.readlines()Dta= {}for delr in dat:wed=delr.replace('./eval/imags/','').replace('\n','').split(' ')Dta[wed[0]] =wed[1]print(Dta)csvfile = open("/home/aistudio/work/PaddleClas/output/result.csv", "w", newline="")writer = csv.writer(csvfile)batch_size = self.config["Infer"]["batch_size"]self.model.eval()batch_data = []image_file_list = []for idx, image_file in enumerate(image_list):with open(image_file, 'rb') as f:x = f.read()for process in self.preprocess_func:x = process(x)batch_data.append(x)image_file_list.append(image_file)if len(batch_data) >= batch_size or idx == len(image_list) - 1:batch_tensor = paddle.to_tensor(batch_data)if self.amp and self.amp_eval:with paddle.amp.auto_cast(custom_black_list={"flatten_contiguous_range", "greater_than"},level=self.amp_level):out = self.model(batch_tensor)else:out = self.model(batch_tensor)if isinstance(out, list):out = out[0]if isinstance(out, dict) and "Student" in out:out = out["Student"]if isinstance(out, dict) and "logits" in out:out = out["logits"]if isinstance(out, dict) and "output" in out:out = out["output"]result = self.postprocess_func(out, image_file_list)print(result)for res in result:file_name = res['file_name'].split('/')[-1]class_id = res['class_ids'][0]try:ture_id = Dta[file_name]writer.writerow([file_name, class_id,ture_id])except:passbatch_data.clear()image_file_list.clear()
%cd /home/aistudio/work/PaddleClas/
!echo "模型预测"
!python tools/infer.py \-c /home/aistudio/work/PaddleClas/ppcls/configs/ImageNet/Xception/Xception65.yaml\-o Global.pretrained_model=/home/aistudio/work/PaddleClas/output/Xception65/best_model
- 提取预测结果
import glob
import matplotlib.pyplot as plt
import pandas as pd
import cv2data_1=pd.read_csv("/home/aistudio/work/PaddleClas/output/result.csv",",",encoding="utf-8",header=None)
# 随机抽取数据
data_2=data_1.sample(10)
print(data_2)ji = 1
for index, row in data_2.iterrows():i=row.tolist()img = cv2.imread("/home/aistudio/work/PaddleClas/dataset/eval/imags/"+str(i[0]))title='pri:'+str(i[1])+' true:'+str(i[2])plt.subplot(3,5,ji)plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))plt.title(title,fontsize=10)ji=ji+1plt.tight_layout()
plt.show()
sum_num = 0
cr_num = 0
for index, row in data_1.iterrows():i = row.tolist()if int(i[1])==int(i[2]):cr_num = cr_num + 1sum_num = sum_num + 1print("正确:",cr_num,"\n总数:",sum_num)
print('ACC:',cr_num*100/sum_num,"%")

七、模型导出
# 导出模型
!echo "模型导出"
!python tools/export_model.py -c /home/aistudio/work/PaddleClas/ppcls/configs/ImageNet/Xception/Xception65.yaml\-o Global.pretrained_model=/home/aistudio/work/PaddleClas/output/Xception65/best_model\-o Global.save_inference_dir=./inference
- 模型结构

八、模型部署
参考
- EfficientNet实现农业病害识别(FastDeploy部署和安卓端部署)
- 基于PP-PicoDet行车检测(完成安卓端部署))
九、项目总结
本次项目的完成可谓是经历重重困难,在看到题目时是懵懵的。在我以往学习的知识里,单纯人脸表情识别并没有太大的难度,但是要求对遮挡人脸的表情进行识别(口罩遮挡),查阅资料发现连数据集都没有找到,后来只能自己构建数据集,就利用以往做人脸表情识别的经验,使用未遮挡人脸通过检测人脸面部特征,定位眼、口、鼻、嘴给面部添加口罩。又学习了face-mask的一些操作,算是把数据集构建完成。当选取神经网络时问题有来了,该选取什么网络才好呢?从主流的ResNet、SwinTransformer、VGG效果都不是很理想。仔细分析问题,发现数据集中sad、disgust、anger眼部特征十分相识,所以就减少分类,重新处理数据集。在探索过程中隐约发现Xception网络特性(上文已介绍)可能对此数据集能产生较好的效果,果断进行测试,分别使用Xception41_deeplab和Xception65进行对比,发现ception65精度上升较快(这里可能不严谨,lr等当时并未考虑太多),紧接着使用可视化训练,观察lr,loss,acc曲线变化关系,调整参数,最终只实现了0.72左右精度。因为时间的原因,我没有办法继续优化项目,再以后的时间里我会不断的学习相关知识和优化项目,如果大家有好的想法和观点,欢迎给我留言!!!
相关文章:
人工智能|深度学习——基于Xception实现戴口罩人脸表情识别
一、项目背景 近年来,随着人工智能技术的不断发展,人脸表情识别已经成为了计算机视觉领域中的重要研究方向之一。然而,在当前的疫情形势下,佩戴口罩已经成为了一项必要的防疫措施,但是佩戴口罩会遮挡住人脸的部分区域&…...

【HTML】简单制作一个动态3D正方体
目录 前言 开始 HTML部分 JS部分 CSS部分 效果图 总结 前言 无需多言,本文将详细介绍一段代码,具体内容如下: 开始 首先新建文件夹,创建两个文本文档,其中HTML的文件名改为[index.html],JS的文件名改…...
Linux 常用指令及其理论知识
个人主页:仍有未知等待探索-CSDN博客 专题分栏:http://t.csdnimg.cn/Tvyou 欢迎各位指教!!! 目录 一、理论知识 二、基础指令 1、ls指令(列出该目录下的所有子目录和文件) 语法: …...

论文阅读——Sat2Vid
Sat2Vid: Street-view Panoramic Video Synthesis from a Single Satellite Image 提出了一种新颖的方法,用于从单个卫星图像和摄像机轨迹合成时间和几何一致的街景全景视频。 即根据单个卫星图像和给定的观看位置尽可能真实地、尽可能一致地合成街景全景视频序列。…...

js怎样判断status
相信大家都知道Switch开关吧,他有两种状态,通常用1/2表示,开启时为true,关闭时为false,那么我们该怎样判断他是否为开启还是关闭你? 我们可以声明一个变量,让它等于status,判断它是否等于1/2&…...
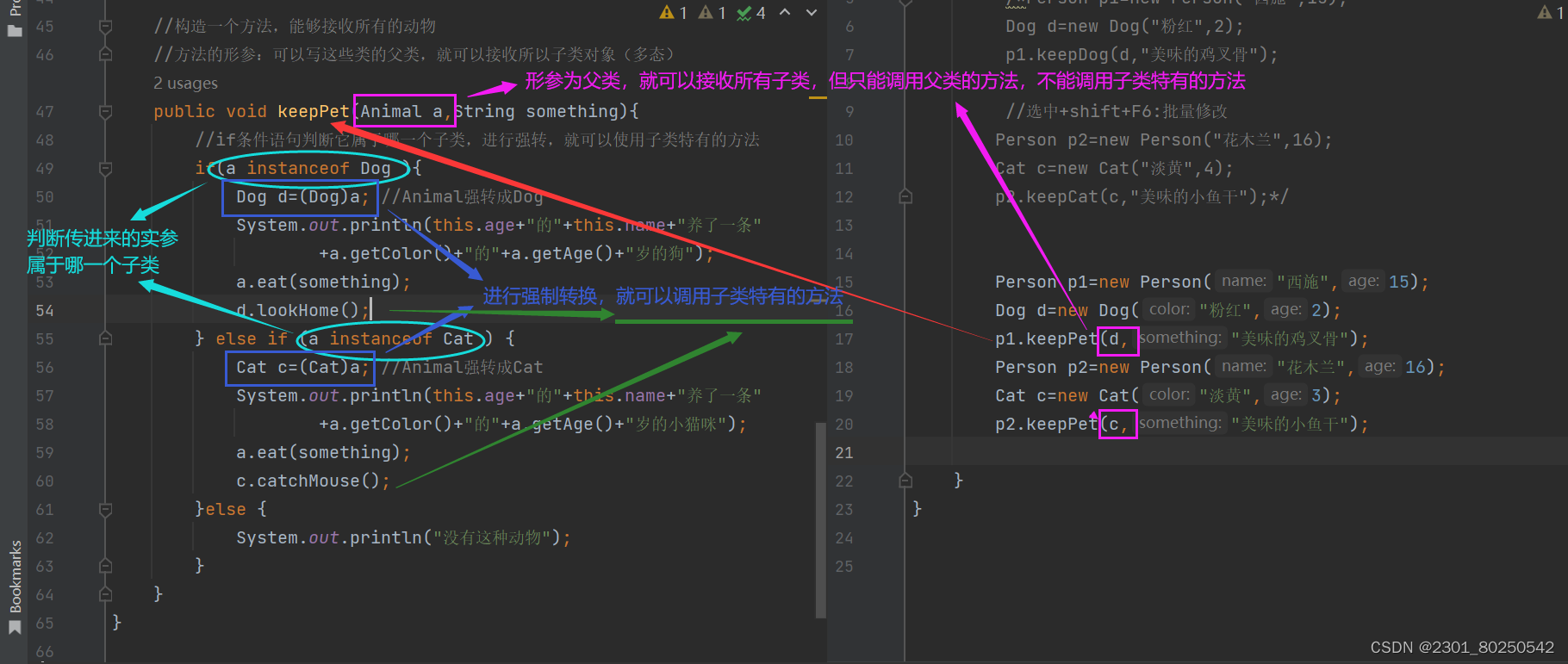
多态.Java
(1)什么是多态? 同类型的对象,表现出不同的形态。前者指父类,后者指不同的子类 说简单点,就是父类的同一种方法,可以在不同子类中表现出不同的状态,或者说在不同子类中可以实现不同…...

SSL根证书是什么
根证书是什么? 根证书是CA认证中心给自己颁发的证书,是信任链的起始点。安装根证书意味着对这个CA认证中心的信任。 从技术上讲,证书其实包含三部分,用户的信息,用户的公钥,还有CA中心对该证书里面的信息的签名&#…...
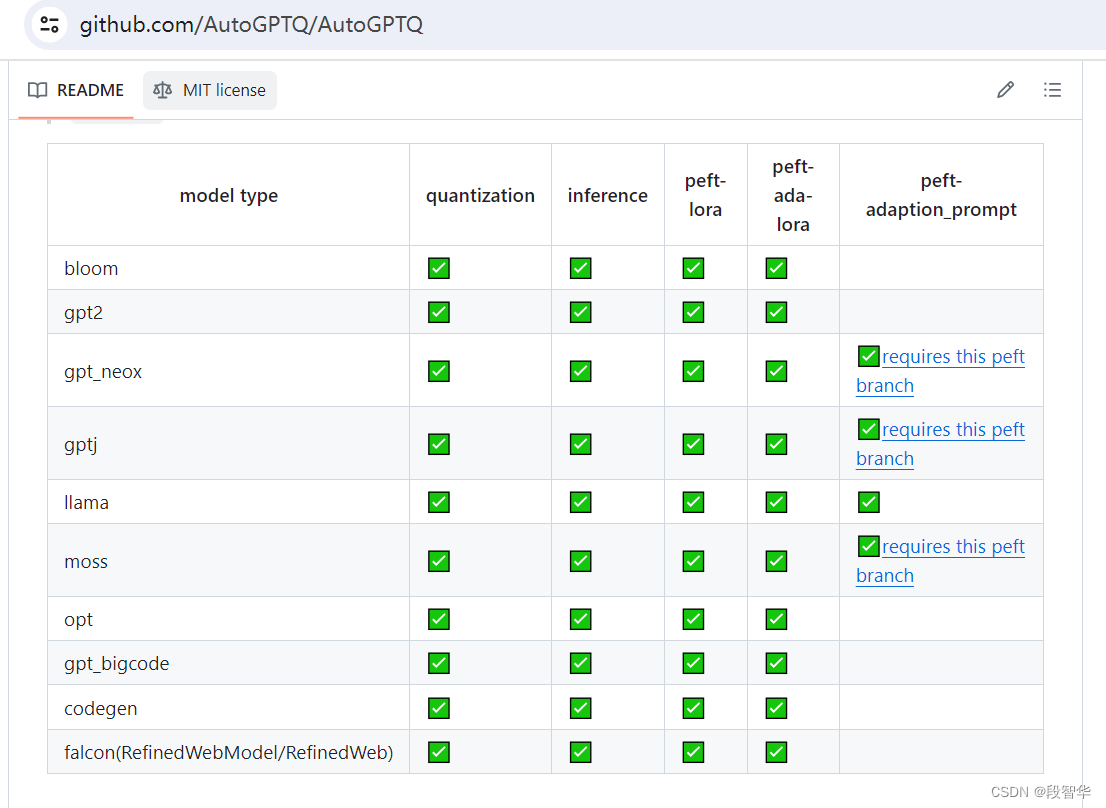
大模型量化技术-GPTQ
大模型量化技术-GPTQ 2022年,Frantar等人发表了论文 GPTQ:Accurate Post-Training Quantization for Generative Pre-trained Transformers。 这篇论文详细介绍了一种训练后量化算法,适用于所有通用的预训练 Transformer模型,同时只有微小的性能下降。 GPTQ算法需要通过…...

NzN的数据结构--实现双向链表
上一章中,我们学习了链表中的单链表,那今天我们来学习另一种比较常见的链表--双向链表!! 目录 一、双向链表的结构 二、 双向链表的实现 1. 双向链表的初始化和销毁 2. 双向链表的打印 3. 双向链表的头插/尾插 4. 双向链表的…...

easyexcel-获取文件资源和导入导出excel
1、获取本地资源文件,根据模板填充数据导出 public void exportExcel(HttpServletResponse httpResponse, RequestBody AssayReportDayRecordQuery query) {AssayReportDayRecordDTO dto this.queryByDate(query);ExcelWriter excelWriter null;ExcelUtil.config…...

Android Monkey自动化测试
monkey一般用于压力测试,用户模拟用户事件 monkey 基本用法 adb shell monkey [参数] [随机事件数]monkey常用命令 -v:用于指定反馈信息级别,总共分三个等级-v -v -vadb shell mokey -v -v -v 100-s:用于指定伪随机数生成器的种…...

C++ //练习 11.20 重写11.1节练习(第376页)的单词计数程序,使用insert代替下标操作。你认为哪个程序更容易编写和阅读?解释原因。
C Primer(第5版) 练习 11.20 练习 11.20 重写11.1节练习(第376页)的单词计数程序,使用insert代替下标操作。你认为哪个程序更容易编写和阅读?解释原因。 环境:Linux Ubuntu(云服务…...

Nginx 安装与实践
目录 一、安装 Nginx1、先安装 Brew2、再安装 Nginx 二、常用的 Nginx 命令三、简单的 Nginx 配置四、查看日志的 Linux 命令1、查看日志的 Linux 命令2、实时查看项目运行时打印的日志 一、安装 Nginx 推荐使用 HomeBrew 来安装 Nginx。 1、先安装 Brew 详见:Home…...

QT 创建线程的几种方法
//qt创建线程的几种方法 //在Qt中,创建线程的主要方法有以下几种: //1.继承QThread类重写run方法 class MyThread : public QThread { Q_OBJECT public: void run() override { // 在这里执行你的代码 } }; // 使用 MyThread *myThread n…...
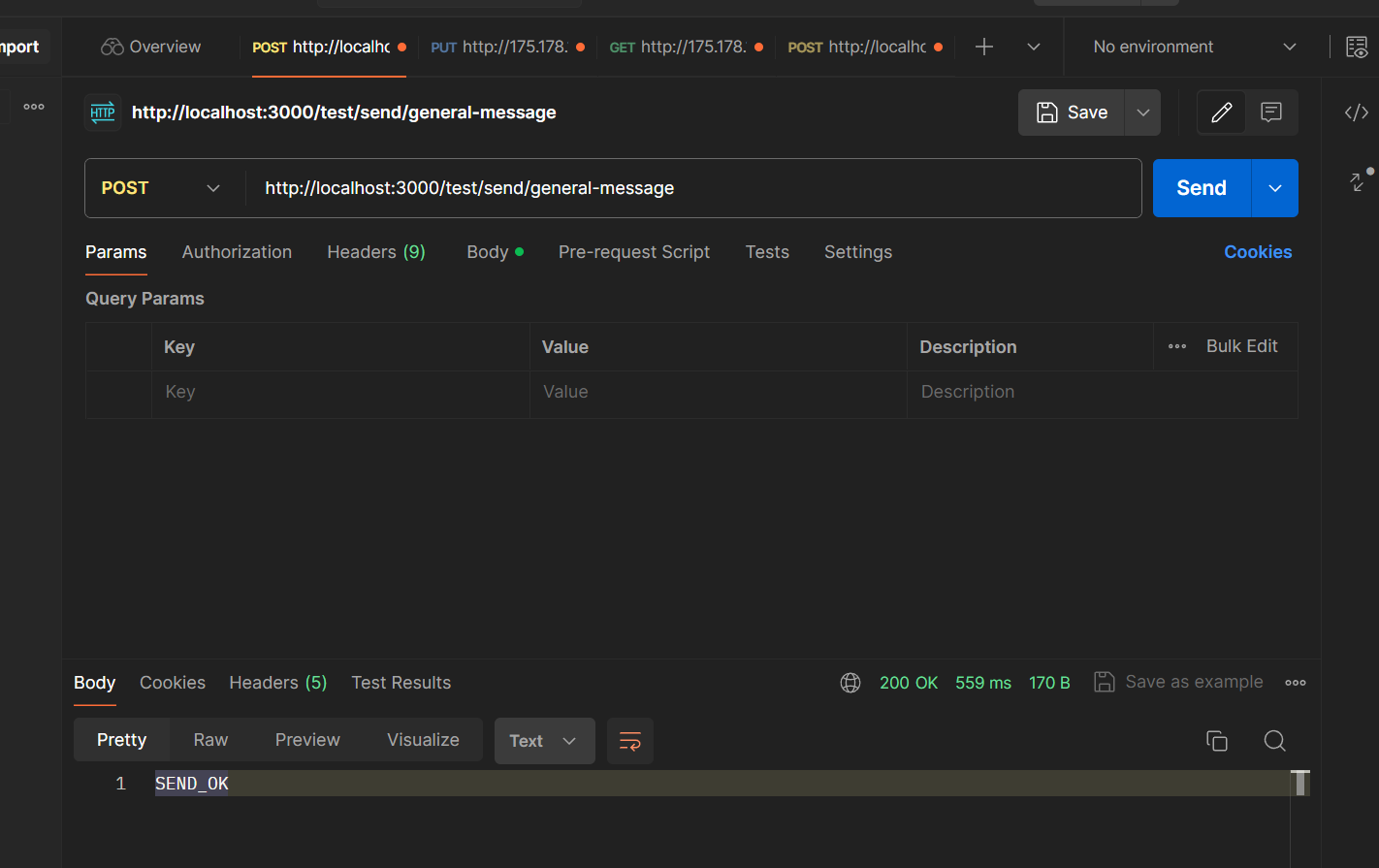
RocketMQ的简单使用
这里需要创建2.x版本的springboot项目 导入依赖 <dependencies><dependency><groupId>org.apache.rocketmq</groupId><artifactId>rocketmq-spring-boot-starter</artifactId><version>2.2.3</version></dependency>&…...

速盾:服务器有cdn 带宽上限建议多少
CDN(内容传输网络)是一种通过分布在全球不同地点的服务器来提供高效内容分发的技术。当用户请求访问某个网站时,CDN会根据用户的地理位置,将内容从离用户最近的服务器上提供给用户,这样可以减少延迟和带宽消耗…...

智慧工地安全+绿色施工方案
塔机监测 塔吊监测可以实现对塔机监测、群塔防碰撞、塔机区域防护和吊钩可视化 1司机身份识别认证:只有司机在监控设备进行刷卡、指纹、人脸、虹膜验证身份后才能进行设备的作业操作。 2运行工况采集与显示:清晰实时显示起重机械设备运行工况,主要显示的内容:起重量、起…...
)
SQL Server 存储过程:BBS论坛(表结构文档下载及30个存储过程)
基于 Asp.Net 和 SQL Server 实现了一个BBS论坛,论坛功能比较强大,论坛大部分业务逻辑基于存储过程实现,记录一下。 BBS论坛存储过程清单 序号存储过程功能说明1sp_bbs_admin_add添加管理员2sp_bbs_admin_del删除系统管理员3sp_bbs_admin_m…...

03 Python进阶:MySQL - mysql-connector
mysql-connector安装 要在 Python 中使用 MySQL 数据库,你需要安装 MySQL 官方提供的 MySQL Connector/Python。下面是安装 MySQL Connector/Python 的步骤: 首先,确保你已经安装了 Python,如果没有安装,可以在 Python…...

InnoDB 行记录格式(“存储一行行数据的结构“)
1.行格式 1.1 Compact行格式 1.1.1 示意图 1.1.2 准备一下 1)建表 mysql> CREATE TABLE record_format_demo (-> c1 VARCHAR(10),-> c2 VARCHAR(10) NOT NULL,-> c3 CHAR(10),-> c4 VARCHAR(10)-> ) CHARSETascii ROW_FORMATCOM…...

Wan2.2-I2V-A14B企业应用:法律文书解读AI动画视频生成系统
Wan2.2-I2V-A14B企业应用:法律文书解读AI动画视频生成系统 1. 系统概述与核心价值 法律行业每天需要处理大量文书材料,传统的人工解读和可视化呈现方式效率低下且成本高昂。Wan2.2-I2V-A14B法律文书解读AI动画视频生成系统正是为解决这一痛点而生。 这…...

跨平台部署YOLOv5的路径陷阱:从WindowsPath错误看Python pathlib的兼容性设计
1. 当WindowsPath遇上Linux:YOLOv5部署的路径陷阱 最近帮朋友调试一个YOLOv5模型部署问题,场景特别典型:在Windows训练好的目标检测模型,迁移到Linux服务器就报错。错误信息直指一个看似简单的路径问题:"NotImple…...
抓包过程及其分析)
有线/无线(空口)抓包过程及其分析
一、如何判断该抓有线包,还是无线包层级问题类型抓包位置L1/L2(无线)连不上、掉线、弱信号无线抓包L2(有线)VLAN错误有线抓包L3(IP)DHCP失败有线抓包L4(传输)丢包、重传有…...

超越本地插件:利用快马平台ai能力全面提升你的编码效率与工作流
最近在开发前端项目时,我一直在寻找能提升效率的AI工具。之前用过一些本地IDE插件,虽然能提供基础的代码补全,但功能比较局限。后来尝试了InsCode(快马)平台,发现它把AI辅助开发做到了一个新高度,特别适合需要快速迭代…...

WebPages 发布
WebPages 发布 引言 随着互联网技术的飞速发展,Web技术已经成为现代信息社会不可或缺的一部分。WebPages作为Web技术的重要应用,旨在为用户提供高效、便捷的网页浏览体验。本文将详细介绍WebPages的发布过程,包括技术选型、功能设计、性能优化以及用户体验等方面。 技术选…...

果实采摘机械手的设计【论文+CAD图纸+Creo三维+外文文献翻译】
果实采摘机械手作为现代农业装备领域的重要创新,其核心作用在于解决传统人工采摘效率低、劳动强度大、成本高等问题。通过机械结构与控制系统的协同设计,该设备可模拟人手抓取动作,精准完成果实识别、定位、采摘及收集全流程,显著…...

COMSOL 6.2有限元仿真模型:“1-3压电复合材料厚度共振模态、阻抗相位曲线、表面位移仿...
COMSOL有限元仿真模型_1-3压电复合材料的厚度共振模态、阻抗相位曲线、表面位移仿真。 材料的几何参数可任意改变 版本为COMSOL6.2,低于此版本会打不开文件 ps:支持超声、光声、压电等相关内容仿真代做搞压电复合材料仿真最头疼的就是参数调麻了——厚度…...

别再为MoveIt安装发愁了!Ubuntu 20.04 + ROS Noetic 保姆级配置全流程
别再为MoveIt安装发愁了!Ubuntu 20.04 ROS Noetic 保姆级配置全流程 刚接触ROS和机械臂控制时,MoveIt的安装过程就像一道难以逾越的门槛。记得我第一次尝试配置时,整整两天都卡在依赖报错和环境变量设置上。本文将带你用最稳妥的方式&#x…...

如何快速突破iOS限制:终极降级完全手册
如何快速突破iOS限制:终极降级完全手册 【免费下载链接】downr1n downgrade tethered checkm8 idevices ios 14, 15. 项目地址: https://gitcode.com/gh_mirrors/do/downr1n 你是否曾想过让旧款iPhone重获新生?是否对苹果系统的版本限制感到困扰&…...

UI-TARS-desktop快速上手:10分钟完成Qwen3-4B多模态Agent桌面版部署与任务验证
UI-TARS-desktop快速上手:10分钟完成Qwen3-4B多模态Agent桌面版部署与任务验证 想体验一个能看懂屏幕、操作软件、帮你完成任务的AI助手吗?今天要介绍的UI-TARS-desktop,就是一个内置了强大视觉理解能力的多模态AI Agent桌面应用。它基于Qwe…...