深度学习中的注意力模块的添加
在深度学习中,骨干网络通常指的是网络的主要结构或主干部分,它负责从原始输入中提取高级特征。骨干网络通常由卷积神经网络(CNN)或者类似的架构组成,用于对图像、文本或其他类型的数据进行特征提取和表示学习。
注意力模块则是一种用于处理序列数据的重要组件,例如在自然语言处理领域中常用的 Transformer 模型中就包含了注意力机制。注意力模块可以让模型更好地关注输入序列中的不同部分,并学习它们之间的相关性,从而提高模型的性能和泛化能力。
骨干网络和注意力模块通常是结合在一起来构建端到端的深度学习模型。这种结合可以通过多种方式实现:
-
注意力机制作为模块插入:在骨干网络的某个特定层或者多个层之间插入注意力模块。这样可以让模型在处理输入数据时更加灵活,可以根据任务的需要更加关注特定的信息或特征。
-
注意力机制与骨干网络并行:将注意力模块与骨干网络的不同部分并行处理输入数据,然后将它们的输出进行合并或者融合。这种方式可以提供更丰富的特征表征,同时保留了骨干网络和注意力模块各自的特点。
-
注意力机制作为整个模型的一部分:有些模型设计中,注意力机制被整合到模型的整个结构中,例如在 Transformer 模型中,注意力机制是模型的核心组件之一,与编码器、解码器等其他模块相互作用,共同完成任务。
总的来说,骨干网络和注意力模块的结合方式取决于具体的任务和模型设计需求。它们相互协作可以提高模型的表现,并且在不同的应用场景中可能会有不同的结合方式和调整方法。
举例:以 ResNet 骨干网络为例,并在其中的一个特定层插入自注意力机制。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models import resnet50class SelfAttention(nn.Module):def __init__(self, in_channels, out_channels):super(SelfAttention, self).__init__()self.query_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)self.key_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)self.value_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)self.gamma = nn.Parameter(torch.zeros(1))def forward(self, x):batch_size, channels, height, width = x.size()proj_query = self.query_conv(x).view(batch_size, -1, width * height).permute(0, 2, 1)proj_key = self.key_conv(x).view(batch_size, -1, width * height)energy = torch.bmm(proj_query, proj_key)attention = F.softmax(energy, dim=-1)proj_value = self.value_conv(x).view(batch_size, -1, width * height)out = torch.bmm(proj_value, attention.permute(0, 2, 1))out = out.view(batch_size, channels, height, width)out = self.gamma * out + xreturn outclass ResNetWithAttention(nn.Module):def __init__(self, num_classes):super(ResNetWithAttention, self).__init__()self.resnet = resnet50(pretrained=True)# Insert attention module after the second convolutional layerself.resnet.layer1.add_module("self_attention", SelfAttention(256, 256))self.fc = nn.Linear(2048, num_classes)def forward(self, x):x = self.resnet(x)x = F.avg_pool2d(x, x.size()[2:]).view(x.size(0), -1)x = self.fc(x)return x# Example usage:
model = ResNetWithAttention(num_classes=1000)
input_tensor = torch.randn(1, 3, 224, 224) # Example input tensor
output = model(input_tensor)
print(output.shape) # Should print: torch.Size([1, 1000])
在这个示例中,我们定义了一个自注意力模块 SelfAttention,并将其插入到了 ResNet 的第一个残差块 layer1 中的第二个卷积层之后。然后我们定义了一个新的模型 ResNetWithAttention,其中包含了 ResNet 的主干部分和我们插入的注意力模块。最后,我们在模型的最后添加了一个全连接层用于分类。
这个示例展示了如何在 PyTorch 中实现将注意力模块插入到现有骨干网络中的过程。通过这种方式,我们可以灵活地设计深度学习模型,以更好地适应不同的任务和数据特点。
举例:在 PyTorch 中实现将注意力机制与骨干网络并行处理输入数据,我们可以在骨干网络的输出上应用注意力机制,然后将其与骨干网络的输出进行合并或融合。下面是一个示例,我们将在 ResNet50 骨干网络的输出上应用自注意力机制,并将其与原始输出进行融合。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision.models import resnet50class SelfAttention(nn.Module):def __init__(self, in_channels, out_channels):super(SelfAttention, self).__init__()self.query_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)self.key_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)self.value_conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)self.gamma = nn.Parameter(torch.zeros(1))def forward(self, x):batch_size, channels, height, width = x.size()proj_query = self.query_conv(x).view(batch_size, -1, width * height).permute(0, 2, 1)proj_key = self.key_conv(x).view(batch_size, -1, width * height)energy = torch.bmm(proj_query, proj_key)attention = F.softmax(energy, dim=-1)proj_value = self.value_conv(x).view(batch_size, -1, width * height)out = torch.bmm(proj_value, attention.permute(0, 2, 1))out = out.view(batch_size, channels, height, width)out = self.gamma * out + xreturn outclass ResNetWithAttentionParallel(nn.Module):def __init__(self, num_classes):super(ResNetWithAttentionParallel, self).__init__()self.resnet = resnet50(pretrained=True)self.attention = SelfAttention(2048, 2048)self.fc = nn.Linear(2048 * 2, num_classes) # Concatenating original and attention-enhanced featuresdef forward(self, x):features = self.resnet(x)attention_out = self.attention(features)combined_features = torch.cat((features, attention_out), dim=1) # Concatenate original and attention-enhanced featuresoutput = self.fc(combined_features.view(features.size(0), -1))return output# Example usage:
model = ResNetWithAttentionParallel(num_classes=1000)
input_tensor = torch.randn(1, 3, 224, 224) # Example input tensor
output = model(input_tensor)
print(output.shape) # Should print: torch.Size([1, 1000])
在这个示例中,我们定义了一个自注意力模块 SelfAttention,并在 ResNet50 的输出上应用了这个注意力机制。然后,我们将注意力机制的输出与原始的骨干网络输出进行了融合,通过将它们连接在一起。最后,我们在融合后的特征上添加了一个全连接层用于分类。
这个示例展示了如何在 PyTorch 中实现将注意力机制与骨干网络并行处理输入数据的方法。通过这种方式,我们可以利用注意力机制来增强骨干网络提取的特征,从而提高模型的性能和泛化能力。
举例:一个自注意力(self-attention)机制作为整个模型一部分的例子,这个例子基于 Transformer 模型的结构。在 Transformer 中,自注意力机制被整合到编码器和解码器中,用于处理序列数据。
下面是一个简化版本的 Transformer 编码器,其中包含自注意力层作为整个模型的一部分:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_sizeself.heads = headsself.head_dim = embed_size // headsassert (self.head_dim * heads == embed_size), "Embedding size needs to be divisible by heads"self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)self.fc_out = nn.Linear(heads * self.head_dim, embed_size)def forward(self, values, keys, query, mask):N = query.shape[0]value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]# Split the embedding into self.heads different piecesvalues = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = query.reshape(N, query_len, self.heads, self.head_dim)values = self.values(values)keys = self.keys(keys)queries = self.queries(queries)# Scaled dot-product attentionenergy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])if mask is not None:energy = energy.masked_fill(mask == 0, float("-1e20"))attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads * self.head_dim)out = self.fc_out(out)return outclass TransformerEncoderLayer(nn.Module):def __init__(self, embed_size, heads, dropout, forward_expansion):super(TransformerEncoderLayer, self).__init__()self.attention = SelfAttention(embed_size, heads)self.norm1 = nn.LayerNorm(embed_size)self.norm2 = nn.LayerNorm(embed_size)self.feed_forward = nn.Sequential(nn.Linear(embed_size, forward_expansion * embed_size),nn.ReLU(),nn.Linear(forward_expansion * embed_size, embed_size),)self.dropout = nn.Dropout(dropout)def forward(self, value, key, query, mask):attention = self.attention(value, key, query, mask)# Add skip connection, run through normalization and finally dropoutx = self.dropout(self.norm1(attention + query))forward = self.feed_forward(x)out = self.dropout(self.norm2(forward + x))return outclass TransformerEncoder(nn.Module):def __init__(self,src_vocab_size,embed_size,num_layers,heads,device,forward_expansion,dropout,max_length,):super(TransformerEncoder, self).__init__()self.embed_size = embed_sizeself.device = deviceself.word_embedding = nn.Embedding(src_vocab_size, embed_size)self.position_embedding = nn.Embedding(max_length, embed_size)self.layers = nn.ModuleList([TransformerEncoderLayer(embed_size,heads,dropout=dropout,forward_expansion=forward_expansion,)for _ in range(num_layers)])self.dropout = nn.Dropout(dropout)def forward(self, x, mask):N, seq_length = x.shapepositions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))for layer in self.layers:out = layer(out, out, out, mask)return out# Example usage:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
src_vocab_size = 1000 # Example vocabulary size
max_length = 100 # Example maximum sequence length
embed_size = 256
heads = 8
num_layers = 6
forward_expansion = 4
dropout = 0.2encoder = TransformerEncoder(src_vocab_size,embed_size,num_layers,heads,device,forward_expansion,dropout,max_length,
)# Example input tensor
input_tensor = torch.randint(0, src_vocab_size, (32, 10)) # Batch size: 32, Sequence length: 10
mask = torch.ones(32, 10) # Example maskoutput = encoder(input_tensor, mask)
print(output.shape) # Should print: torch.Size([32, 10, 256])
在这个例子中,我们定义了一个简化版本的 Transformer 编码器,其中包含自注意力层作为整个模型的一部分。自注意力层用于处理输入序列,并学习序列中不同位置之间的关系。整个模型接受输入序列并输出相应的表示。
相关文章:

深度学习中的注意力模块的添加
在深度学习中,骨干网络通常指的是网络的主要结构或主干部分,它负责从原始输入中提取高级特征。骨干网络通常由卷积神经网络(CNN)或者类似的架构组成,用于对图像、文本或其他类型的数据进行特征提取和表示学习。 注意力…...
Docker 部署开源远程桌面工具 RustDesk
RustDesk是一款远程控制,远程协助的开源软件。完美替代TeamViewer ,ToDesk,向日葵等平台。关键支持自建服务器,更安全私密远程控制电脑!官网地址:https://rustdesk.com/ 环境准备 1、阿里云服务器一 台&a…...
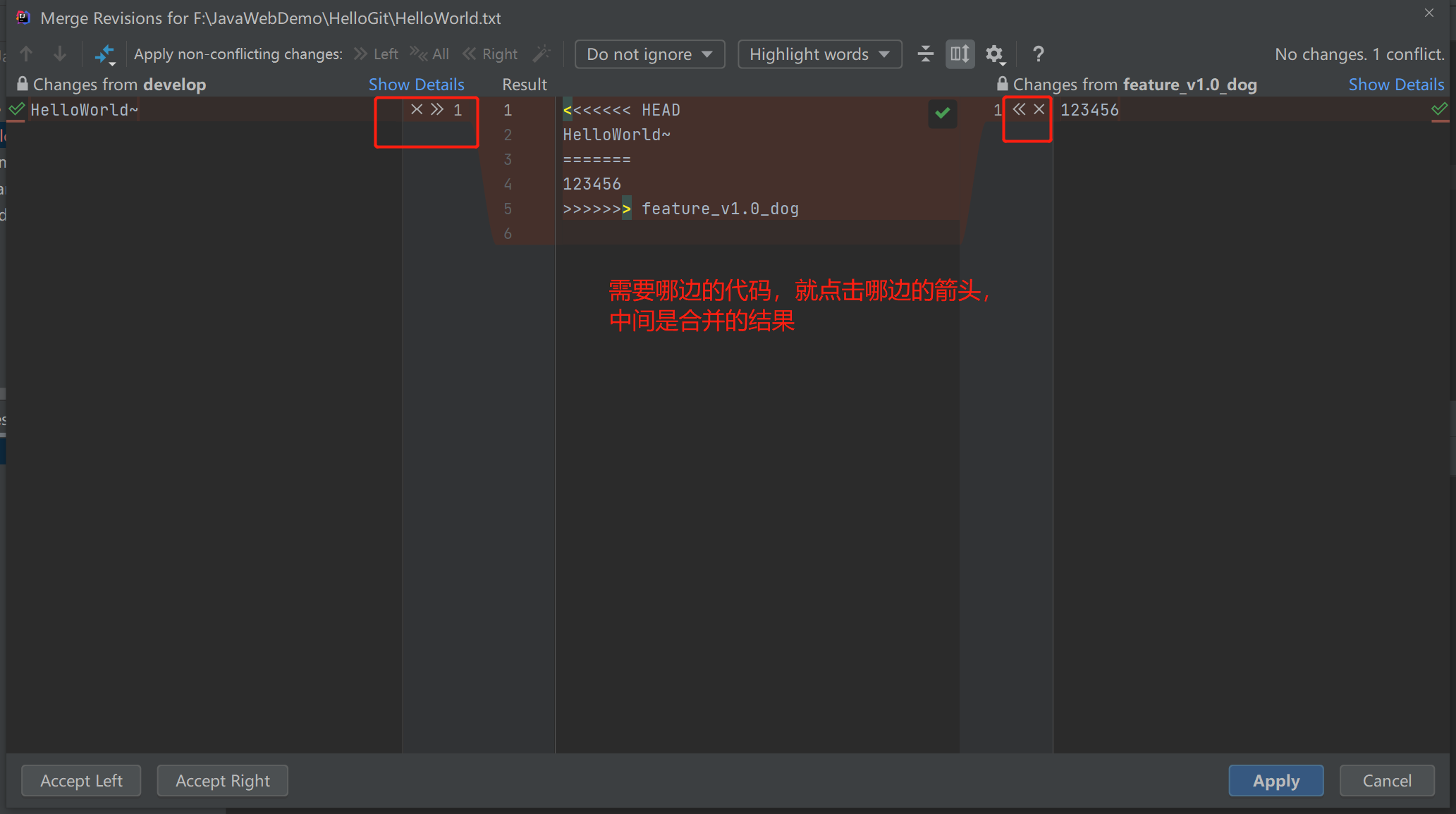
intellij idea 使用git ,快速合并冲突
可以选择左边的远程分支上的代码,也可以选择右边的代码,而中间是合并的结果。 一个快速合并冲突的小技巧: 如果冲突比较多,想要快速合并冲突。也可以直接点击上图中 Apply non-conflicting changes 旁边的 All 。 这样 Idea 就会…...

AcWing26. 二进制中1的个数。三种解法Java
输入一个 3232 位整数,输出该数二进制表示中 11 的个数。 注意: 负数在计算机中用其绝对值的补码来表示。 数据范围 −100≤ 输入整数 ≤100 样例1 输入:9 输出:2 解释:9的二进制表示是1001,一共有2个…...
)
【ADB】常见命令汇总(持续更新)
▒ 目录 ▒ 🛫 导读开发环境 1️⃣ 设备连接和识别2️⃣ 应用程序管理3️⃣ 文件传输和管理4️⃣ 设备信息和日志5️⃣ 设备操作和控制6️⃣ 截图相关🛬 文章小结📖 参考资料 🛫 导读 Android调试桥(ADB)是…...

【递归与递推】数的计算|数的划分|耐摔指数
1.数的计算 - 蓝桥云课 (lanqiao.cn) 思路: 1.dfs的变量>每一次递归什么在变? (1)当前数的大小一直在变:sum (2)最高位的数:k 2.递归出口:最高位数字为1 3.注意&#…...
企业案例:金蝶云星空集成钉钉,帆软BI
正文:在数字化转型的大潮中,众多企业开始探索并实践高效的数据流转与集成,以提升内部管理效率和决策质量。本文将以某企业为例,详细介绍如何通过将钉钉审批流程的数据实时同步至金蝶云星空,并进一步在帆软报表平台上实…...

简单设计模式讲解
设计模式是在软件开发中经常使用的最佳实践,用于解决在软件设计中经常遇到的问题。它们提供了可重用的设计,使得代码更加灵活、可维护和可扩展。下面我将为你讲解几种常见的设计模式,并提供相应的C#代码示例。 1. 单例模式(Single…...
基于springboot的社区医疗服务系统
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式 🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 &…...

影院座位选择简易实现(uniapp)
界面展示 主要使用到uniap中的movable-area,和movable-view组件实现。 代码逻辑分析 1、使用movable-area和movea-view组件,用于座位展示 <div class"ui-seat__box"><movable-area class"ui-movableArea"><movab…...
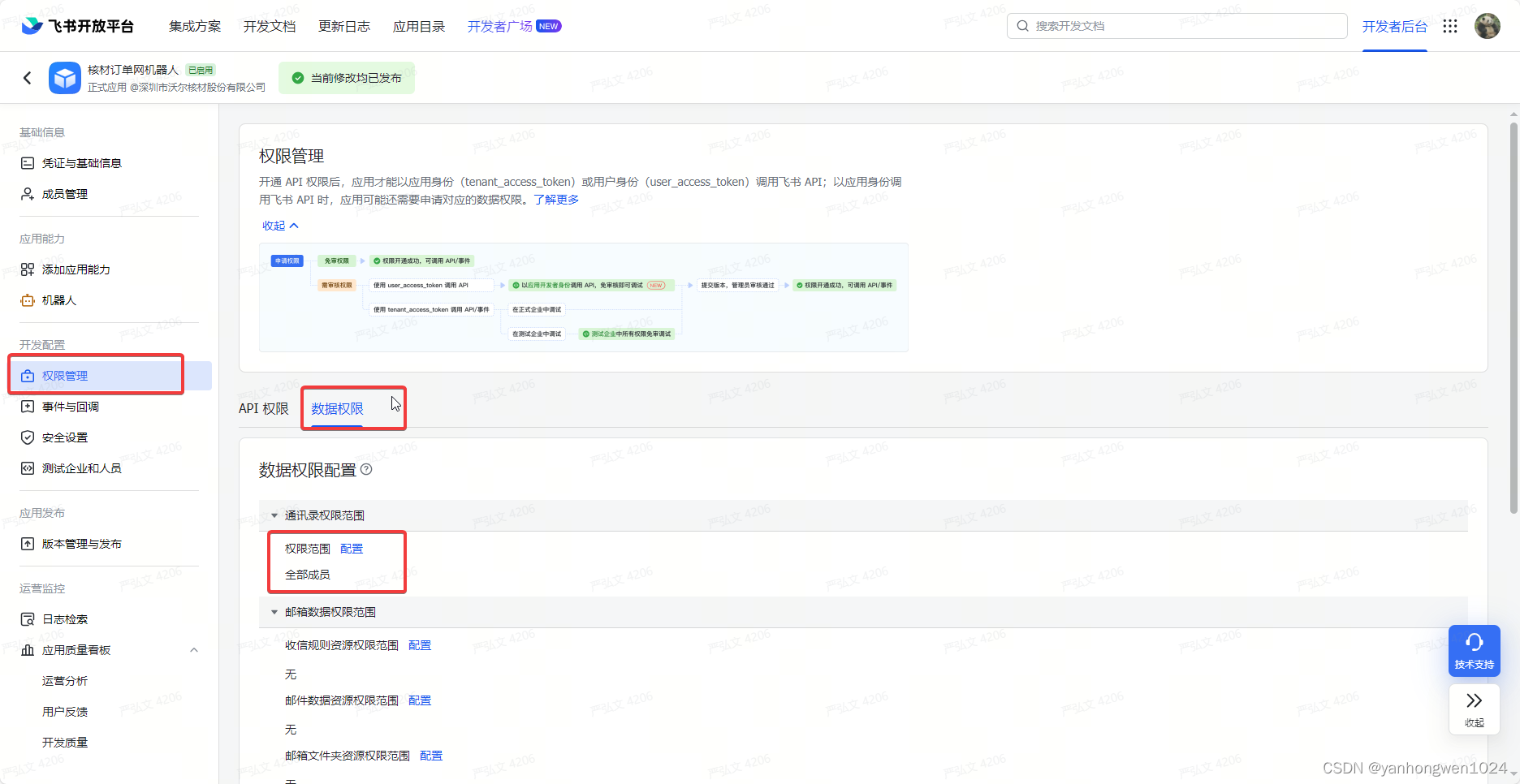
调用飞书获取用户Id接口成功,但是没有返回相应数据
原因: 该自建应用没有开放相应的数据权限。 解决办法: 在此处配置即可。...

STM32 GPIO输入检测——按键
前言 在嵌入式系统开发中,对GPIO输入进行检测是一项常见且关键的任务。STM32微控制器作为一款功能强大的处理器,具有丰富的GPIO功能,可以轻松实现对外部信号的检测和处理。在本文中,我们将深入探讨如何在STM32微控制器上进行GPIO…...
Rustdesk二次编译,新集成AI功能开源Gpt小程序为远程协助助力,全网首发
环境: Rustdesk1.1.9 sciter版 问题描述: Rustdesk二次编译,新集成AI功能开源Gpt小程序为远程协助助力,全网首发 解决方案: Rustdesk二次编译,新集成开源AI功能Gpt小程序,为远程协助助力,…...
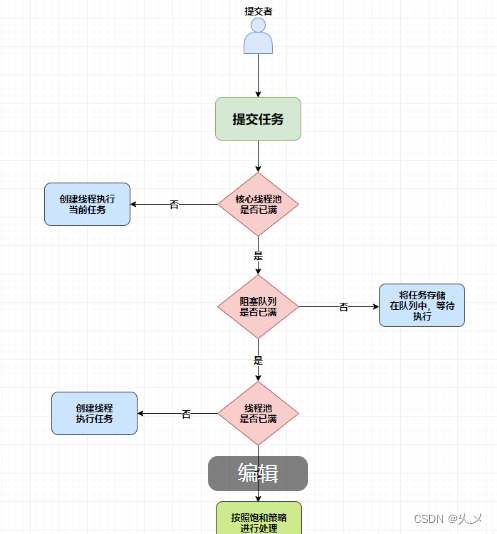
面试(03)————多线程和线程池
一、多线程 1、什么是线程?线程和进程的区别? 2、创建线程有几种方式 ? 3、Runnable 和 Callable 的区别? 4、如何启动一个新线程、调用 start 和 run 方法的区别? 5、线程有哪几种状态以及各种状态之间的转换? 6、线程…...

纯CSS实现未读消息显示99+
在大佬那看到这个小技巧,我觉得这个功能点还挺常用,所以给大家分享下具体的实现。当未读消息数小于100的时候显示准确数值,大于99的时候显示99。 1. 实现效果 2. 组件封装 <template><span class"col"><sup :styl…...

【C++】C++ primer plus 第十二章--类和动态内存分配
动态内存和类 关于静态数据成员 类之作声明,不分配内存,因此静态成员变量在类中不能进行初始化,需要在类外进行。特殊情况: 存在可以在类中声明静态成员并初始化的情况,成员类型为const整型或者const枚举类型。 特殊…...

分类预测 | Matlab实现GWO-LSSVM灰狼算法优化最小二乘支持向量机数据分类预测
分类预测 | Matlab实现GWO-LSSVM灰狼算法优化最小二乘支持向量机数据分类预测 目录 分类预测 | Matlab实现GWO-LSSVM灰狼算法优化最小二乘支持向量机数据分类预测分类效果基本介绍程序设计参考资料 分类效果 基本介绍 1.Matlab实现GWO-LSSVM灰狼算法优化最小二乘支持向量机数据…...

使用PHP进行极验验证码动态参数提取与逆向分析
在网络安全领域,逆向工程和验证码破解是常见的技术挑战之一。极验验证码作为一种常见的人机验证工具,其动态参数的提取和逆向分析对于验证码的破解至关重要。本文将介绍如何使用PHP语言进行极验验证码动态参数的提取与逆向分析。 1. 准备工作 在开始之前…...
43.1k star, 免费开源的 markdown 编辑器 MarkText
43.1k star, 免费开源的 markdown 编辑器 MarkText 分类 开源分享 项目名: MarkText -- 简单而优雅的开源 Markdown 编辑器 Github 开源地址: https://github.com/marktext/marktext 官网地址: MarkText 支持平台: Linux, macOS 以及 Win…...
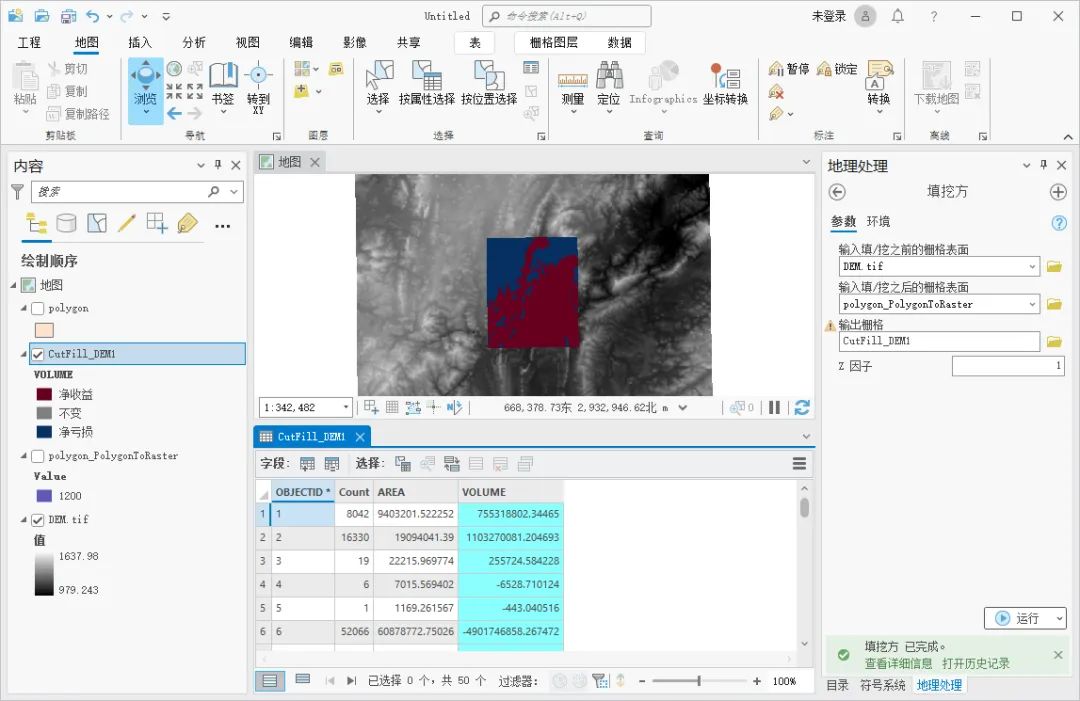
ArcGIS Pro怎么进行挖填方计算
在工程实施之前,我们需要充分利用地形,结合实际因素,通过挖填方计算项目的标高,以达到合理控制成本的目的,这里为大家介绍一下ArcGIS Pro中挖填方计算的方法,希望能对你有所帮助。 数据来源 教程所使用的…...

Taurus多执行器对比实战:JMeter/Gatling/Locust统一压测方案
1. 为什么选Taurus做多执行器对比——不是为了炫技,而是为了少踩坑在性能测试领域,我见过太多团队卡在“选型”这一步:刚招来一个会写JMeter脚本的工程师,项目突然要压测WebSocket接口,发现JMeter原生支持弱、插件维护…...

Android 11开发避坑:为什么你的App获取的Wifi MAC地址总是变?手把手教你配置固定MAC
Android 11开发实战:彻底解决Wifi MAC地址随机化问题最近在开发一个设备管理系统时,遇到了一个棘手的问题:我们的App在Android 11设备上获取的Wifi MAC地址每次都不一样,导致基于MAC地址的设备识别功能完全失效。经过一周的深入研…...

C语言双端队列完整实现:一行代码吃透头尾操作,算法效率拉满
一、为什么C语言实现双端队列,是数据结构的必学天花板?在C语言数据结构里,队列、栈都是基础中的基础,但真正能把灵活度、效率、内存管理三者揉到一起的,还得是双端队列(deque)。普通队列只能一头…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

飞书远程控机:OpenClaw配置全攻略
本文详细介绍如何通过 OpenClaw 工具对接飞书开放平台,配置智能机器人实现 Windows 电脑的远程控制。主要内容涵盖文件管理和程序启动等核心功能的实现方法,并提供完整的配置指南与常见问题解决方案。 一、使用前提说明 1. 系统要求 仅适用于 Windows…...
:这份内部测试SOP已被3家头部科技公司紧急采购)
DeepSeek-R1补全能力封测倒计时(仅剩72小时开放API灰度权限):这份内部测试SOP已被3家头部科技公司紧急采购
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-R1代码补全能力封测全景概览 DeepSeek-R1 是深度求索(DeepSeek)推出的高性能开源推理模型,在代码补全场景中展现出显著的上下文理解力与多语言泛化能力。本…...

基于Arduino与nRF24L01+的无线传感器平台设计与部署指南
1. 项目概述与设计思路如果你和我一样,喜欢在阳台或者小院子里种点蔬菜瓜果,那你肯定也遇到过这样的烦恼:出门几天,心里总惦记着家里的番茄苗是不是缺水了,小温室里的温度会不会太高。传统的温湿度计只能让你在现场读数…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

Hindsight API参考:REST接口完整文档
Hindsight API参考:REST接口完整文档 【免费下载链接】hindsight Hindsight: Agent Memory That Learns 项目地址: https://gitcode.com/GitHub_Trending/hindsight2/hindsight Hindsight是一个强大的Agent Memory系统,提供了全面的REST API接口&…...

真可用!美团数字人模型开源,MV、电商等统统拿下
美团开源的数字人视频生成框架 LongCat-Video-Avatar 刚刚更新到 1.5 版本。是真能用。这版更新把音频编码器换了,推理步数砍到8步,在770人、13240条主观评分的大规模评测里,雷达图面积全面领先。音频编码器换血,8步出图LongCat-V…...