AI推介-大语言模型LLMs论文速览(arXiv方向):2024.03.31-2024.04.05
文章目录~
- 1.AutoWebGLM: Bootstrap And Reinforce A Large Language Model-based Web Navigating Agent
- 2.Training LLMs over Neurally Compressed Text
- 3.Unveiling LLMs: The Evolution of Latent Representations in a Temporal Knowledge Graph
- 4.Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models
- 5.Evaluating LLMs at Detecting Errors in LLM Responses
- 6.Intent Detection and Entity Extraction from BioMedical Literature
- 7.How does Multi-Task Training Affect Transformer In-Context Capabilities? Investigations with Function Classes
- 8.Evaluating Generative Language Models in Information Extraction as Subjective Question Correction
- 9.Scaling Up Video Summarization Pretraining with Large Language Models
- 10.LongVLM: Efficient Long Video Understanding via Large Language Models
- 11.ALOHa: A New Measure for Hallucination in Captioning Models
- 12.Conifer: Improving Complex Constrained Instruction-Following Ability of Large Language Models
- 13.Automatic Prompt Selection for Large Language Models
- 14.Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
- 15.Min-K%++: Improved Baseline for Detecting Pre-Training Data from Large Language Models
- 16.Enhancing Low-Resource LLMs Classification with PEFT and Synthetic Data
- 17.On Linearizing Structured Data in Encoder-Decoder Language Models: Insights from Text-to-SQL
- 18.LLMs in the Loop: Leveraging Large Language Model Annotations for Active Learning in Low-Resource Languages
- 19.SGSH: Stimulate Large Language Models with Skeleton Heuristics for Knowledge Base Question Generation
- 20.Classifying Cancer Stage with Open-Source Clinical Large Language Models
- 21.Hallucination Diversity-Aware Active Learning for Text Summarization
- 22.Position-Aware Parameter Efficient Fine-Tuning Approach for Reducing Positional Bias in LLMs
- 23.Prior Constraints-based Reward Model Training for Aligning Large Language Models
- 24.Efficiently Distilling LLMs for Edge Applications
- 25.A Survey on Multilingual Large Language Models: Corpora, Alignment, and Bias
- 26.TM-TREK at SemEval-2024 Task 8: Towards LLM-Based Automatic Boundary Detection for Human-Machine Mixed Text
- 27.Training-Free Semantic Segmentation via LLM-Supervision
- 28.LLM meets Vision-Language Models for Zero-Shot One-Class Classification
- 29.WavLLM: Towards Robust and Adaptive Speech Large Language Model
- 30.RQ-RAG: Learning to Refine Queries for Retrieval Augmented Generation
- 31.MetaIE: Distilling a Meta Model from LLM for All Kinds of Information Extraction Tasks
- 32.CoDa: Constrained Generation based Data Augmentation for Low-Resource NLP
- 33.ST-LLM: Large Language Models Are Effective Temporal Learners
- 34.A Comprehensive Study on NLP Data Augmentation for Hate Speech Detection: Legacy Methods, BERT, and LLMs
- 35.Survey on Large Language Model-Enhanced Reinforcement Learning: Concept, Taxonomy, and Methods
- 36.EventGround: Narrative Reasoning by Grounding to Eventuality-centric Knowledge Graphs
1.AutoWebGLM: Bootstrap And Reinforce A Large Language Model-based Web Navigating Agent
标题:AutoWebGLM:引导和强化基于大语言模型的网络导航代理
author:Hanyu Lai, Xiao Liu, Iat Long Iong, Shuntian Yao, Yuxuan Chen, Pengbo Shen, Hao Yu, Hanchen Zhang, Xiaohan Zhang, Yuxiao Dong, Jie Tang
date Time:2024-04-04
paper pdf:http://arxiv.org/pdf/2404.03648v1
摘要:
大型语言模型(LLM)为许多智能代理任务(如网络导航)提供了动力,但由于以下三个因素,大多数现有代理在实际网页中的表现远不能令人满意:(1) 网页上操作的多样性;(2) HTML 文本超出模型处理能力;(3) 由于网页的开放域性质,决策的复杂性。有鉴于此,我们在 ChatGLM3-6B 的基础上开发了自动网页导航代理 AutoWebGLM,它的性能超过了 GPT-4。受人类浏览模式的启发,我们设计了一种 HTML 简化算法来表示网页,简洁地保留重要信息。我们采用人类与人工智能混合的方法来建立用于课程训练的网页浏览数据。然后,我们通过强化学习和拒绝采样对模型进行引导,进一步促进网页理解、浏览器操作和高效的任务分解。为了进行测试,我们为真实世界的网页浏览任务建立了一个双语基准–AutoWebBench。我们在各种网页导航基准中对 AutoWebGLM 进行了评估,发现了它的改进之处,同时也发现了它在应对真实环境时所面临的挑战。相关代码、模型和数据将在(url{https://github.com/THUDM/AutoWebGLM})上发布。
2.Training LLMs over Neurally Compressed Text
标题:通过神经压缩文本训练 LLM
author:Brian Lester, Jaehoon Lee, Alex Alemi, Jeffrey Pennington, Adam Roberts, Jascha Sohl-Dickstein, Noah Constant
date Time:2024-04-04
paper pdf:http://arxiv.org/pdf/2404.03626v1
摘要:
在本文中,我们探讨了在高度压缩文本上训练大型语言模型(LLM)的想法。标准的分词标记器只能将文本压缩一小部分,而神经文本压缩器可以实现更高的压缩率。如果有可能直接在神经压缩文本上训练 LLM,这将在训练和服务效率方面带来优势,并且更容易处理长文本跨度。实现这一目标的主要障碍在于,强压缩往往会产生不透明的输出,不适合学习。特别是,我们发现通过算术编码(Arithmetic Coding)压缩的文本不容易被 LLM 学习。为了克服这一问题,我们提出了 “等信息窗口”(Equal-Info Windows),这是一种新颖的压缩技术,它将文本分割成块,每个块压缩成相同的比特长度。利用这种方法,我们展示了对神经压缩文本的有效学习,学习效果随着规模的扩大而提高,并在易错性和推理速度基准上远远超过了字节级基准。对于使用相同参数数训练的模型,我们的方法比子词标记器的迷惑性更差,但它的优点是序列长度更短。较短的序列长度需要较少的自回归生成步骤,从而减少了延迟。最后,我们对有助于提高可学习性的特性进行了广泛分析,并就如何进一步提高高压缩标记化器的性能提出了具体建议。
3.Unveiling LLMs: The Evolution of Latent Representations in a Temporal Knowledge Graph
标题:揭开 LLM 的面纱:时态知识图谱中潜在表征的演变
author:Marco Bronzini, Carlo Nicolini, Bruno Lepri, Jacopo Staiano, Andrea Passerini
publish:Preprint. Under review. 10 pages, 7 figures
date Time:2024-04-04
paper pdf:http://arxiv.org/pdf/2404.03623v1
摘要:
大型语言模型(LLMs)在回忆大量常见事实知识信息方面表现出令人印象深刻的能力。然而,揭示 LLMs 的基本推理以及解释其利用这些事实知识的内部机制,仍然是我们积极研究的领域。我们的研究分析了当提示评估事实主张的真实性时,编码在 LLMs 潜在表征中的事实知识。我们提出了一个端到端框架,该框架将嵌入在 LLM 潜在空间中的事实知识从向量空间联合解码为一组地面谓词,并使用时态知识图谱表示其在各层中的演变。我们的框架依赖于激活修补技术,该技术通过动态改变模型的潜在表征来干预模型的推理计算。因此,我们既不依赖外部模型,也不依赖训练过程。我们利用两个索赔验证数据集,通过局部和全局可解释性分析展示了我们的框架:FEVER 和 CLIMATE-FEVER。局部可解释性分析暴露了从表征错误到多跳推理错误等不同的潜在错误。另一方面,全局分析揭示了模型事实知识(如存储和搜索事实信息)的基本演变模式。通过对潜在表征进行基于图的分析,这项工作代表着向 LLM 的机制可解释性迈出了一步。
4.Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models
标题:思维可视化激发大型语言模型的空间推理能力
author:Wenshan Wu, Shaoguang Mao, Yadong Zhang, Yan Xia, Li Dong, Lei Cui, Furu Wei
date Time:2024-04-04
paper pdf:http://arxiv.org/pdf/2404.03622v1
摘要:
大型语言模型(LLM)在语言理解和各种推理任务中表现出令人印象深刻的性能。然而,作为人类认知的一个重要方面,大型语言模型在空间推理方面的能力仍相对欠缺。人类拥有一种非凡的能力,即通过一种被称为 “心眼”(textbf{the Mind’s Eye})的过程来创造看不见的物体和行为的心理图像,从而实现对看不见的世界的想象。受这种认知能力的启发,我们提出了思维可视化(\textbf{VoT})提示。VoT 的目的是通过可视化推理轨迹来激发 LLM 的空间推理,从而指导后续的推理步骤。我们将 VoT 用于多跳空间推理任务,包括自然语言导航、视觉导航和二维网格世界中的视觉平铺。实验结果表明,VoT 显著增强了 LLM 的空间推理能力。值得注意的是,VoT 在这些任务中的表现优于现有的多模态大语言模型(MLLM)。虽然VoT在LLMs上的表现令人惊讶,但其生成textit{mental images}以促进空间推理的能力类似于心灵之眼的过程,这表明它在MLLMs上具有潜在的可行性。
5.Evaluating LLMs at Detecting Errors in LLM Responses
标题:评估 LLM 检测 LLM 响应错误的能力
author:Ryo Kamoi, Sarkar Snigdha Sarathi Das, Renze Lou, Jihyun Janice Ahn, Yilun Zhao, Xiaoxin Lu, Nan Zhang, Yusen Zhang, Ranran Haoran Zhang, Sujeeth Reddy Vummanthala, Salika Dave, Shaobo Qin, Arman Cohan, Wenpeng Yin, Rui Zhang
publish:Benchmark and code: https://github.com/psunlpgroup/ReaLMistake
date Time:2024-04-04
paper pdf:http://arxiv.org/pdf/2404.03602v1
摘要:
随着大型语言模型(LLM)在各种任务中的广泛应用,检测其响应中的错误变得越来越重要。然而,有关 LLM 响应错误检测的研究却很少。由于许多 NLP 任务的主观性,收集 LLM 响应中的错误注释具有挑战性,因此之前的研究主要集中在实用价值不高的任务(如单词排序)或有限的错误类型(如摘要中的忠实性)上。这项工作引入了 ReaLMistake,这是第一个错误检测基准,包含客观、真实和多样的 LLM 错误。ReaLMistake 包含三个具有挑战性和意义的任务,在四个类别(推理正确性、指令遵循性、上下文忠实性和参数化知识)中引入了可客观评估的错误,在由专家注释的 GPT-4 和 Llama 2 70B 的回答中引出了自然观察到的各种错误。我们使用 ReaLMistake 评估基于 12 个 LLM 的错误检测器。我们的研究结果表明1) GPT-4 和 Claude 3 等顶级 LLM 以极低的召回率检测出 LLM 所犯的错误,所有基于 LLM 的错误检测器的表现都比人类差很多。2) 基于 LLM 的错误检测器的解释缺乏可靠性。3) 基于 LLMs 的错误检测对提示语的微小变化很敏感,但要改进仍有挑战。4) 改进 LLMs 的常用方法(包括自洽性和多数投票)并不能提高错误检测性能。我们的基准和代码见 https://github.com/psunlpgroup/ReaLMistake。
6.Intent Detection and Entity Extraction from BioMedical Literature
标题:从生物医学文献中进行意图检测和实体提取
author:Ankan Mullick, Mukur Gupta, Pawan Goyal
publish:Accepted to CL4Health LREC-COLING 2024
date Time:2024-04-04
paper pdf:http://arxiv.org/pdf/2404.03598v1
摘要:
生物医学查询在网络搜索中越来越普遍,这反映了人们对获取生物医学文献的兴趣与日俱增。尽管最近对大型语言模型(LLMs)进行了研究,以努力实现通用智能,但它们在替代特定任务和特定领域的自然语言理解方法方面的功效仍然值得怀疑。在本文中,我们通过对生物医学文本中的意图检测和命名实体识别(NER)任务进行全面的实证评估来解决这一问题。我们发现,与通用 LLM 相比,“监督微调”(Supervised Fine Tuned)方法仍然具有相关性,而且更加有效。生物医学转换器模型(如 PubMedBERT)只需 5 个监督示例就能在 NER 任务中超越 ChatGPT。
7.How does Multi-Task Training Affect Transformer In-Context Capabilities? Investigations with Function Classes
标题:多任务训练如何影响变压器的上下文能力?功能类调查
author:Harmon Bhasin, Timothy Ossowski, Yiqiao Zhong, Junjie Hu
publish:Accepted to NAACL 2024
date Time:2024-04-04
paper pdf:http://arxiv.org/pdf/2404.03558v1
摘要:
大型语言模型(LLM)最近显示出了非凡的能力,可以根据文本中提供的少量示例执行未见任务,这也被称为上下文学习(ICL)。虽然最近的研究试图了解驱动 ICL 的机制,但很少有人探索能激励这些模型泛化到多个任务的训练策略。通用模型的多任务学习(MTL)是一个很有前景的方向,它具有迁移学习的潜力,能从较简单的相关任务中训练出大型参数化模型。在这项工作中,我们研究了 MTL 与 ICL 的结合,以建立既能高效学习任务又能对分布外示例保持稳健的模型。我们提出了几种有效的课程学习策略,使 ICL 模型能够实现更高的数据效率和更稳定的收敛。我们的实验表明,ICL 模型可以通过在逐步增加难度的任务上进行训练,同时混合先前的任务(在本文中称为混合课程),从而有效地学习高难度任务。我们的代码和模型可在 https://github.com/harmonbhasin/curriculum_learning_icl 上获取。
8.Evaluating Generative Language Models in Information Extraction as Subjective Question Correction
标题:评估信息提取中的生成语言模型,作为主观问题修正
author:Yuchen Fan, Yantao Liu, Zijun Yao, Jifan Yu, Lei Hou, Juanzi Li
publish:Accepted by LREC-COLING 2024, short paper
date Time:2024-04-04
paper pdf:http://arxiv.org/pdf/2404.03532v1
摘要:
现代大型语言模型(LLM)在各种需要复杂认知行为的任务中表现出了非凡的能力。然而,由于传统评估中存在的两个问题,这些模型在关系提取和事件提取等看似基本的任务中表现不佳。(1) 现有评估指标不精确,难以有效衡量模型输出与地面实况之间的语义一致性;以及 (2) 评估基准固有的不完整性,主要是由于人类注释模式的限制性,导致低估了 LLM 的性能。受主观题修正原则的启发,我们提出了一种新的评估方法 SQC-Score。该方法创新性地利用了通过主观问题修正数据进行微调的 LLM,以完善模型输出与黄金标签之间的匹配。此外,通过结合自然语言推理(NLI)模型,SQC-Score 还丰富了黄金标签,通过确认正确但之前遗漏的答案来解决基准不完整的问题。三项信息提取任务的结果表明,与基准指标相比,SQC-Score 更受人类注释者的青睐。利用 SQC-Score,我们对最先进的 LLM 进行了全面评估,并为未来的信息提取研究提供了启示。数据集和相关代码请访问 https://github.com/THU-KEG/SQC-Score。
9.Scaling Up Video Summarization Pretraining with Large Language Models
标题:利用大型语言模型扩大视频摘要预训练规模
author:Dawit Mureja Argaw, Seunghyun Yoon, Fabian Caba Heilbron, Hanieh Deilamsalehy, Trung Bui, Zhaowen Wang, Franck Dernoncourt, Joon Son Chung
publish:Accepted to CVPR 2024
date Time:2024-04-04
paper pdf:http://arxiv.org/pdf/2404.03398v1
摘要:
长视频内容占互联网流量的很大一部分,因此自动视频摘要成为一个重要的研究课题。然而,现有的视频摘要数据集规模明显有限,制约了最先进方法的概括效果。我们的工作旨在利用大量具有密集语音视频对齐功能的长视频,以及近期大型语言模型(LLM)在总结长文本方面的卓越能力来克服这一局限。我们介绍了一种自动化、可扩展的管道,用于使用 LLM 作为 Oracle 摘要器生成大规模视频摘要数据集。通过利用生成的数据集,我们分析了现有方法的局限性,并提出了一种能有效解决这些问题的新视频摘要模型。为了促进该领域的进一步研究,我们的工作还提出了一个新的基准数据集,该数据集包含 1200 个长视频,每个视频都有由专业人士注释的高质量摘要。广泛的实验清楚地表明,我们提出的方法在多个基准的视频摘要领域达到了新的先进水平。
10.LongVLM: Efficient Long Video Understanding via Large Language Models
标题:LongVLM:通过大型语言模型高效理解长视频
author:Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, Bohan Zhuang
date Time:2024-04-04
paper pdf:http://arxiv.org/pdf/2404.03384v1
摘要:
在大型语言模型(LLM)的推动下,视频语言模型(VideoLLM)的最新进展推动了各种视频理解任务的进展。这些模型通过对大量视觉标记进行池化或查询聚合来编码视频表示,从而降低了计算和内存成本。尽管成功地提供了对视频内容的整体理解,但由于忽略了长期视频中的局部信息,现有的 VideoLLM 在实现对视频的详细理解方面仍然面临挑战。长视频通常由连续的关键事件、复杂的动作和摄像机运动组成,为了应对这一挑战,我们推出了用于长视频理解的简单而强大的视频LLM–LongVLM。我们的方法建议将长视频分解为多个短期片段,并通过分层标记合并模块为每个局部片段编码局部特征。这些特征按时间顺序串联起来,以在连续的短期片段中保持故事情节。此外,我们还建议将全局语义整合到每个局部特征中,以增强对上下文的理解。这样,我们就能编码出同时包含本地和全局信息的视频表征,使 LLM 能够为长期视频生成全面的响应。在 VideoChatGPT 基准数据集和零镜头视频问题解答数据集上的实验结果表明,我们的模型比以往最先进的方法更胜一筹。定性实例表明,我们的模型能更精确地回答对长视频的理解。代码见 \url{https://github.com/ziplab/LongVLM}。
11.ALOHa: A New Measure for Hallucination in Captioning Models
标题:ALOHa:衡量字幕模型中幻觉的新标准
author:Suzanne Petryk, David M. Chan, Anish Kachinthaya, Haodi Zou, John Canny, Joseph E. Gonzalez, Trevor Darrell
publish:To appear at NAACL 2024
date Time:2024-04-03
paper pdf:http://arxiv.org/pdf/2404.02904v1
摘要:
尽管最近在视觉描述的多模态预训练方面取得了进展,但最先进的模型仍然会产生包含错误的字幕,例如幻觉出场景中不存在的物体。现有的著名物体幻觉度量标准 CHAIR 仅限于一组固定的 MS COCO 物体和同义词。在这项工作中,我们提出了一种现代化的开放词汇度量方法 ALOHa,它利用大型语言模型(LLM)来测量物体幻觉。具体来说,我们使用 LLM 从候选标题中提取可定位对象,从标题和对象检测中测量它们与参考对象的语义相似性,并使用匈牙利语匹配得出最终的幻觉得分。我们的研究表明,在 HAT(注释了幻觉的 MS COCO 字幕的新黄金标准子集)上,ALOHa 比 CHAIR 多正确识别了 13.6% 的幻觉对象;在 nocaps(对象超出了 MS COCO 类别)上,ALOHa 比 CHAIR 多正确识别了 30.8% 的幻觉对象。我们的代码见 https://davidmchan.github.io/aloha/。
12.Conifer: Improving Complex Constrained Instruction-Following Ability of Large Language Models
标题:Conifer:提高大型语言模型的复杂受限指令跟踪能力
author:Haoran Sun, Lixin Liu, Junjie Li, Fengyu Wang, Baohua Dong, Ran Lin, Ruohui Huang
date Time:2024-04-03
paper pdf:http://arxiv.org/pdf/2404.02823v1
摘要:
大型语言模型(LLM)遵从指令的能力对现实世界的应用至关重要。尽管最近取得了一些进展,但一些研究强调,大型语言模型在面对具有挑战性的指令时,尤其是那些包含复杂约束的指令时,会陷入困境,从而影响其在各种任务中的效率。为了应对这一挑战,我们引入了一种新型指令调整数据集–Conifer,旨在提高 LLM 遵循具有复杂约束条件的多级指令的能力。利用 GPT-4,我们通过一系列 LLM 驱动的完善过程来管理数据集,以确保高质量。我们还提出了一种渐进式学习方案,强调从易到难的渐进过程,以及从过程反馈中学习。使用 Conifer 训练的模型在指令跟踪能力方面有显著提高,尤其是对于具有复杂约束条件的指令。在多个指令跟随基准测试中,我们的 7B 模型都优于最先进的开源 7B 模型,在某些指标上甚至超过了 10 倍以上的模型。所有代码和 Conifer 数据集可在 https://www.github.com/ConiferLM/Conifer 上获取。
13.Automatic Prompt Selection for Large Language Models
标题:大型语言模型的自动提示选择
author:Viet-Tung Do, Van-Khanh Hoang, Duy-Hung Nguyen, Shahab Sabahi, Jeff Yang, Hajime Hotta, Minh-Tien Nguyen, Hung Le
publish:preprint
date Time:2024-04-03
paper pdf:http://arxiv.org/pdf/2404.02717v1
摘要:
大型语言模型(LLM)可以通过适当的指令提示执行各种自然语言处理任务。然而,手动设计有效的提示语既具有挑战性又耗费时间。现有的自动提示优化方法要么缺乏灵活性,要么缺乏效率。在本文中,我们提出了一种有效的方法,可从有限的合成候选提示中自动为给定输入选择最佳提示。我们的方法包括三个步骤:(1) 对训练数据进行聚类,并使用基于 LLM 的提示生成器为每个聚类生成候选提示;(2) 合成输入-提示-输出元组数据集,用于训练提示评估器,以便根据提示与输入的相关性对提示进行排序;(3) 在测试时使用提示评估器为新输入选择最佳提示。我们的方法兼顾了提示的通用性和特定性,并消除了对资源密集型训练和推理的需求。它在零次答题数据集上表现出了极具竞争力的性能:GSM8K、MultiArith 和 AQuA。
14.Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
标题:将口语理解系统扩展到新语言的大型语言模型
author:Jakub Hoscilowicz, Pawel Pawlowski, Marcin Skorupa, Marcin Sowański, Artur Janicki
publish:Code and info on model checkpoint are available at
https://github.com/Samsung/MT-LLM-NLU
date Time:2024-04-03
paper pdf:http://arxiv.org/pdf/2404.02588v1
摘要:
口语理解(SLU)模型是 Alexa、Bixby 和 Google Assistant 等语音助手(VA)的核心组成部分。在本文中,我们介绍了一个旨在将 SLU 系统扩展到新语言的管道,利用大型语言模型 (LLM),我们对其进行了微调,以便对槽注释的 SLU 训练数据进行机器翻译。我们的方法在云场景中使用 mBERT 模型改进了 MultiATIS++ 基准(一种主要的多语言 SLU 数据集)。具体来说,与现有的最先进方法–细粒度和粗粒度多任务学习框架(FC-MTLF)相比,我们的总体准确率指标从 53% 提高到 62.18%。在设备上场景(微小且未经预训练的 SLU)中,与基线全局-局部对比学习框架(GL-CLeF)方法相比,我们的方法将总体准确率从 5.31% 提高到 22.06%。与 FC-MTLF 和 GL-CLeF 相反,我们基于 LLM 的机器翻译不需要改变 SLU 的生产架构。此外,我们的管道与插槽类型无关:它不需要任何插槽定义或示例。
15.Min-K%++: Improved Baseline for Detecting Pre-Training Data from Large Language Models
标题:Min-K%++:从大型语言模型中检测预训练数据的改进基线
author:Jingyang Zhang, Jingwei Sun, Eric Yeats, Yang Ouyang, Martin Kuo, Jianyi Zhang, Hao Yang, Hai Li
publish:Work in progress; project page is available at
https://zjysteven.github.io/mink-plus-plus/
date Time:2024-04-03
paper pdf:http://arxiv.org/pdf/2404.02936v1
摘要:
大型语言模型(LLM)的预训练数据检测问题因其对侵犯版权和测试数据污染等关键问题的影响而受到越来越多的关注。目前最先进的方法 Min-K% 测量的是原始标记概率,我们认为这可能不是信息量最大的信号。取而代之的是,我们提出了 Min-K%++,利用整个词汇的分类分布统计数据对标记概率进行归一化处理,从而准确反映目标标记与词汇中其他候选标记相比的相对可能性。在理论上,我们证明了我们的方法在 LLM 训练过程中对其估计的统计量进行了明确的优化,从而成为检测训练数据的可靠指标。从经验上看,在 WikiMIA 基准上,Min-K%++ 的检测 AUROC(五个模型的平均值)比 SOTA Min-K% 高出 6.2% 到 10.5%。在更具挑战性的 MIMIR 基准测试中,尽管不需要额外的参考模型,Min-K%++ 始终优于 Min-K%,与基于参考的方法表现相当。
16.Enhancing Low-Resource LLMs Classification with PEFT and Synthetic Data
标题:利用 PEFT 和合成数据加强低资源 LLMs 分类
author:Parth Patwa, Simone Filice, Zhiyu Chen, Giuseppe Castellucci, Oleg Rokhlenko, Shervin Malmasi
publish:Accepted at LREC-COLING 2024
date Time:2024-04-03
paper pdf:http://arxiv.org/pdf/2404.02422v1
摘要:
大型语言模型(LLMs)可在 "0-shot "或 "少-shot "设置下运行,在文本分类任务中取得具有竞争力的结果。文本内学习(ICL)通常比 0 次拍摄设置获得更高的准确率,但由于输入提示时间较长,因此在效率方面要付出代价。在本文中,我们提出了一种策略,使 LLM 与 0 次文本分类器一样高效,同时获得与 ICL 相当或更高的准确率。我们的解决方案针对低资源环境,即每类只有 4 个示例可用的情况。通过使用单个 LLM 和少量真实数据,我们执行了一系列生成、过滤和参数高效微调步骤,从而创建了一个稳健高效的分类器。实验结果表明,我们的方法在多个文本分类数据集上都取得了有竞争力的结果。
17.On Linearizing Structured Data in Encoder-Decoder Language Models: Insights from Text-to-SQL
标题:关于编码器-解码器语言模型中结构化数据的线性化:文本到 SQL 的启示
author:Yutong Shao, Ndapa Nakashole
publish:to appear at NAACL 2024
date Time:2024-04-03
paper pdf:http://arxiv.org/pdf/2404.02389v1
摘要:
结构化数据普遍存在于表格、数据库和知识图谱中,对其表示提出了巨大挑战。随着大型语言模型(LLMs)的出现,人们开始转向基于线性化的方法,这种方法将结构化数据作为连续的标记流来处理,而不是将结构(通常是图)明确建模。至关重要的是,我们对这些基于线性化的方法如何处理结构化数据的理解仍然存在差距,因为结构化数据本身就是非线性的。这项工作研究了编码器-解码器语言模型(特别是 T5)对结构化数据的线性处理。我们的研究结果表明,该模型能够模仿人类设计的流程,如模式链接和语法预测,这表明除了简单的标记排序外,该模型还能对结构进行深入、有意义的学习。我们还揭示了该模型的内部机制,包括结构节点编码以自我为中心的性质,以及模态融合冗余导致模型压缩的可能性。总之,这项工作揭示了基于线性化方法的内部运作机制,并有可能为未来的研究提供指导。
18.LLMs in the Loop: Leveraging Large Language Model Annotations for Active Learning in Low-Resource Languages
标题:循环中的 LLMs:在低资源语言中利用大型语言模型注释进行主动学习
author:Nataliia Kholodna, Sahib Julka, Mohammad Khodadadi, Muhammed Nurullah Gumus, Michael Granitzer
publish:19 pages, 6 tables. The source code related to this paper is
available at https://anonymous.4open.science/r/llms-in-the-loop-4E32
date Time:2024-04-02
paper pdf:http://arxiv.org/pdf/2404.02261v1
摘要:
由于语言资源和数据标注方面的专业知识有限,低资源语言在人工智能发展中面临巨大障碍,使其变得稀缺和昂贵。数据的稀缺和现有工具的缺乏加剧了这些挑战,特别是因为这些语言可能无法在各种 NLP 数据集中得到充分体现。为了弥补这一不足,我们建议在数据标注的主动学习环路中利用 LLM 的潜力。首先,我们会进行评估,以评估注释者之间的一致性和连贯性,从而帮助选择合适的 LLM 注释者。然后,将选定的注释器集成到使用主动学习范式的分类器训练环中,最大限度地减少所需的查询数据量。经验评估(特别是使用 GPT-4-Turbo 评估)表明,与人工标注相比,该方法的性能接近最先进水平,对数据的要求大幅降低,估计可节省成本至少 42.45 倍。我们提出的解决方案有望大幅降低低资源环境下与自动化相关的货币和计算成本。通过缩小低资源语言与人工智能之间的差距,这种方法促进了更广泛的包容性,并显示出在不同语言环境中实现自动化的潜力。
19.SGSH: Stimulate Large Language Models with Skeleton Heuristics for Knowledge Base Question Generation
标题:SGSH:利用骨架启发法刺激大型语言模型,实现知识库问题生成
author:Shasha Guo, Lizi Liao, Jing Zhang, Yanling Wang, Cuiping Li, Hong Chen
publish:Accepted by NAACL 2024 Findings
date Time:2024-04-02
paper pdf:http://arxiv.org/pdf/2404.01923v1
摘要:
知识库问题生成(KBQG)的目的是从知识库中提取的三元组事实中生成自然语言问题。凭借丰富的语义知识,现有方法通过预训练语言模型(PLM)大大提高了知识库问题生成的性能。随着预训练技术的发展,大型语言模型(LLM)(如 GPT-3.5)无疑拥有更多的语义知识。因此,如何有效地组织和利用丰富的知识进行 KBQG 成为我们研究的重点。在这项工作中,我们提出了 SGSH–一个简单有效的框架,即用骨架启发法刺激 GPT-3.5,以增强 KBQG。更具体地说,我们设计了一种自动数据构建策略,利用 ChatGPT 构建骨架训练数据集,并在此基础上采用软提示方法训练 BART 模型,专门生成与每个输入相关的骨架。随后,骨架启发式方法被编码到提示中,以激励 GPT-3.5 生成所需的问题。广泛的实验证明,SGSH 在 KBQG 任务中取得了新的一流性能。
20.Classifying Cancer Stage with Open-Source Clinical Large Language Models
标题:利用开源临床大语言模型对癌症分期进行分类
author:Chia-Hsuan Chang, Mary M. Lucas, Grace Lu-Yao, Christopher C. Yang
publish:accepted in the IEEE International Conference on Healthcare
Informatics (IEEE ICHI 2024)
date Time:2024-04-02
paper pdf:http://arxiv.org/pdf/2404.01589v1
摘要:
癌症分期对于制定肿瘤患者的治疗和护理管理计划非常重要。分期信息通常以非结构化的形式包含在电子健康记录系统中的临床、病理、放射和其他自由文本报告中,需要进行大量的解析和获取工作。为了便于提取这些信息,以往的 NLP 方法依赖于贴有标签的训练数据集,而准备这些数据集需要耗费大量人力物力。在本研究中,我们证明了开源临床大语言模型(LLM)无需任何标注训练数据,就能从真实世界的病理报告中提取病理肿瘤-结节-转移(pTNM)分期信息。我们的实验比较了 LLM 和使用标记数据微调的基于 BERT 的模型。我们的研究结果表明,虽然 LLMs 在肿瘤(T)分类方面仍然表现不佳,但如果适当采用提示策略,它们在转移(M)分类方面可以达到相当的性能,而在结节(N)分类方面的性能则有所提高。
21.Hallucination Diversity-Aware Active Learning for Text Summarization
标题:面向文本摘要的幻觉多样性感知主动学习
author:Yu Xia, Xu Liu, Tong Yu, Sungchul Kim, Ryan A. Rossi, Anup Rao, Tung Mai, Shuai Li
publish:Accepted to NAACL 2024
date Time:2024-04-02
paper pdf:http://arxiv.org/pdf/2404.01588v1
摘要:
大型语言模型(LLM)有产生幻觉输出的倾向,即与事实不符或无据可循的文本。现有的减少幻觉的方法通常需要昂贵的人工注释,以识别和纠正 LLM 输出中的幻觉。此外,这些方法大多侧重于特定类型的幻觉,如实体或标记错误,这限制了它们在处理 LLM 输出中各种类型幻觉时的有效性。据我们所知,我们在本文中提出了第一个主动学习框架,以减轻 LLM 的幻觉,减少幻觉所需的高成本人工注释。通过测量文本摘要中语义框架、话语和内容可验证性错误产生的细粒度幻觉,我们提出了 “幻觉多样性感知采样”(HAllucination Diversity-Aware Sampling,HADAS),以在主动学习中选择不同的幻觉进行注释,从而对 LLM 进行微调。在三个数据集和不同骨干模型上进行的广泛实验证明了我们的方法在有效和高效地减轻 LLM 幻觉方面的优势。
22.Position-Aware Parameter Efficient Fine-Tuning Approach for Reducing Positional Bias in LLMs
标题:减少 LLM 中位置偏差的位置感知参数高效微调方法
author:Zheng Zhang, Fan Yang, Ziyan Jiang, Zheng Chen, Zhengyang Zhao, Chengyuan Ma, Liang Zhao, Yang Liu
date Time:2024-04-01
paper pdf:http://arxiv.org/pdf/2404.01430v1
摘要:
大型语言模型(LLM)的最新进展增强了其处理长输入上下文的能力。这种发展对于涉及从外部数据仓库检索知识的任务尤为重要,因为这种任务可能会产生较长的输入。然而,最近的研究表明,LLMs 存在位置偏差,其性能因有用信息在输入序列中的位置而异。在本研究中,我们进行了广泛的实验来研究位置偏差的根本原因。我们的研究结果表明,造成 LLM 位置偏差的主要原因是不同模型固有的位置偏好。我们证明,仅仅采用基于提示的解决方案不足以克服位置偏好。为了解决预训练 LLM 的位置偏差问题,我们开发了一种位置感知参数高效微调(PAPEFT)方法,该方法由数据增强技术和参数高效适配器组成,增强了整个输入上下文的统一注意力分布。我们的实验证明,所提出的方法有效地减少了位置偏差,提高了 LLM 在处理需要外部检索知识的各种任务的长上下文序列时的有效性。
23.Prior Constraints-based Reward Model Training for Aligning Large Language Models
标题:基于先验约束的奖励模型训练,用于对齐大型语言模型
author:Hang Zhou, Chenglong Wang, Yimin Hu, Tong Xiao, Chunliang Zhang, Jingbo Zhu
date Time:2024-04-01
paper pdf:http://arxiv.org/pdf/2404.00978v1
摘要:
然而,该训练过程存在一个固有的问题:在强化学习过程中,由于缺乏训练奖励模型时的约束条件,奖励分数的缩放不受控制。本文提出了一种基于先验约束的奖励模型(即 PCRM)训练方法来缓解这一问题。PCRM 在奖励模型训练过程中加入了先验约束,特别是每对比较的输出长度比和余弦相似度,以调节优化幅度和控制分数余量。我们通过研究 PCRM 与人类偏好的等级相关性及其通过 RL 匹配 LLM 的有效性,对 PCRM 进行了全面评估。实验结果表明,PCRM 通过有效限制奖励分值的缩放,显著提高了配准性能。另外,我们的方法很容易集成到任意基于等级的配准方法中,如直接偏好优化,并能产生持续的改进。
24.Efficiently Distilling LLMs for Edge Applications
标题:为边缘应用高效蒸馏 LLM
author:Achintya Kundu, Fabian Lim, Aaron Chew, Laura Wynter, Penny Chong, Rhui Dih Lee
publish:This paper has been accepted for publication in NAACL 2024 (Industry
Track)
date Time:2024-04-01
paper pdf:http://arxiv.org/pdf/2404.01353v1
摘要:
LLM 的超网络训练在工业应用中具有重大意义,因为它能以恒定的成本生成一系列较小的模型,而不管生成的模型数量(大小/延迟不同)如何。我们提出了一种名为 "超级变换器多级低阶微调(MLFS)"的新方法,用于参数高效的超级网训练。我们的研究表明,有可能获得适合商业边缘应用的高质量编码器模型,而且虽然纯解码器模型也能抵御同等程度的压缩,但解码器可以有效地切片,从而显著减少训练时间。
25.A Survey on Multilingual Large Language Models: Corpora, Alignment, and Bias
标题:多语言大型语言模型调查:语料库、对齐和偏差
author:Yuemei Xu, Ling Hu, Jiayi Zhao, Zihan Qiu, Yuqi Ye, Hanwen Gu
date Time:2024-04-01
paper pdf:http://arxiv.org/pdf/2404.00929v1
摘要:
在大语言模型(LLMs)的基础上,多语言大语言模型(MLLMs)被开发出来,以应对多语言自然语言处理任务的挑战,希望实现从高资源语言到低资源语言的知识转移。然而,目前仍存在语言不平衡、多语言对齐和固有偏差等重大限制和挑战。在本文中,我们旨在对 MLLMs 进行全面分析,深入探讨围绕这些关键问题的讨论。首先,我们概述了 MLLM,包括其演变、关键技术和多语言能力。其次,我们探讨了用于 MLLMs 训练的广泛使用的多语言语料库和面向下游任务的多语言数据集,这些任务对于增强 MLLMs 的跨语言能力至关重要。第三,我们调查了现有的多语言表征研究,并研究了当前的 MLLM 是否能够学习通用语言表征。第四,我们讨论了 MLLM 的偏差,包括其类别和评估指标,并总结了现有的去偏差技术。最后,我们讨论了现有的挑战,并指出了有前景的研究方向。通过展示这些方面,本文旨在促进对 MLLMs 及其在各个领域的潜力的深入理解。
26.TM-TREK at SemEval-2024 Task 8: Towards LLM-Based Automatic Boundary Detection for Human-Machine Mixed Text
标题:SemEval-2024 上的 TM-TREK 任务 8:实现基于 LLM 的人机混合文本自动边界检测
author:Xiaoyan Qu, Xiangfeng Meng
publish:1st place at SemEval-2024 Task 8, Subtask C, to appear in
SemEval-2024 proceedings
date Time:2024-04-01
paper pdf:http://arxiv.org/pdf/2404.00899v1
摘要:
随着由大型语言模型(LLM)生成的文本越来越普遍,人们越来越关注如何区分 LLM 生成的文本和人工撰写的文本,以防止 LLM 被滥用,如传播误导性信息和学术不端行为。以往的研究主要侧重于将文本划分为完全由人工撰写或由 LLM 生成,而忽略了对包含两种内容的混合文本的检测。本文探讨了 LLM 识别人类撰写和机器生成的混合文本界限的能力。我们将这一任务转化为标记分类问题,并将标签转折点视为边界。值得注意的是,我们的 LLM 集合模型在 SemEval’24 竞赛任务 8 的 "人机混合文本检测 "子任务中获得了第一名。此外,我们还研究了影响 LLMs 在混合文本中检测边界能力的因素,包括在 LLMs 上加入额外层、分割损失的组合以及预训练的影响。我们的研究结果旨在为这一领域的未来研究提供有价值的见解。
27.Training-Free Semantic Segmentation via LLM-Supervision
标题:通过 LLM 监督实现免训练语义分割
author:Wenfang Sun, Yingjun Du, Gaowen Liu, Ramana Kompella, Cees G. M. Snoek
publish:22 pages,10 figures, conference
date Time:2024-03-31
paper pdf:http://arxiv.org/pdf/2404.00701v1
摘要:
开放词汇模型(如 CLIP)的最新进展是利用自然语言进行特定类别嵌入,从而显著推进了零镜头分类和分割。然而,大多数研究都侧重于通过提示工程、提示学习或利用有限的标注数据进行微调来提高模型的准确性,从而忽略了完善类描述符的重要性。本文介绍了一种使用大语言模型(LLM)监督文本监督语义分割的新方法,这种方法不需要额外的训练。我们的方法从 GPT-3 等 LLM 开始,生成一组详细的子类,以获得更准确的类表示。然后,我们采用先进的文本监督语义分割模型,将生成的子类作为目标标签,从而根据每个子类的独特特征得出不同的分割结果。此外,我们还提出了一种将来自不同子类描述符的分割图进行合并的方法,以确保更全面地呈现测试图像中的不同方面。通过对三个标准基准的综合实验,我们的方法明显优于传统的文本监督语义分割方法。
28.LLM meets Vision-Language Models for Zero-Shot One-Class Classification
标题:LLM 满足零镜头单类分类的视觉语言模型
author:Yassir Bendou, Giulia Lioi, Bastien Pasdeloup, Lukas Mauch, Ghouthi Boukli Hacene, Fabien Cardinaux, Vincent Gripon
date Time:2024-03-31
paper pdf:http://arxiv.org/pdf/2404.00675v2
摘要:
我们考虑的是零镜头单类视觉分类问题。在这种情况下,只有目标类别的标签可用,目标是在不需要目标任务的任何验证示例的情况下,区分正向和负向查询样本。我们提出了一种分两步走的解决方案,首先查询视觉混淆对象的大型语言模型,然后依靠视觉语言预训练模型(如 CLIP)进行分类。通过调整大规模视觉基准,我们证明了所提出的方法在这种情况下优于调整后的现成替代方法的能力。也就是说,我们提出了一个现实的基准,其中负查询样本与正查询样本来自相同的原始数据集,包括一个粒度受控的 iNaturalist 版本,其中负样本与正样本在分类树中的距离是固定的。我们的工作表明,仅使用一个类别的标签,就可以区分该类别和其他语义相关的类别。
29.WavLLM: Towards Robust and Adaptive Speech Large Language Model
标题:WavLLM:实现鲁棒性和自适应语音大语言模型
author:Shujie Hu, Long Zhou, Shujie Liu, Sanyuan Chen, Hongkun Hao, Jing Pan, Xunying Liu, Jinyu Li, Sunit Sivasankaran, Linquan Liu, Furu Wei
date Time:2024-03-31
paper pdf:http://arxiv.org/pdf/2404.00656v1
摘要:
近年来,大型语言模型(LLMs)的发展给自然语言处理领域带来了革命性的变化,其范围逐渐扩大到多模态感知和生成。然而,如何有效地将听觉功能集成到 LLM 中,尤其是在不同语境下的泛化和执行复杂的听觉任务方面,提出了巨大的挑战。在这项工作中,我们引入了 WavLLM,这是一种具有双编码器和提示感知 LoRA 权重适配器的鲁棒自适应语音大语言模型,通过两阶段课程学习方法进行了优化。利用双编码器,我们将不同类型的语音信息解耦,利用 Whisper 编码器处理语音的语义内容,利用 WavLLM 编码器捕捉说话者身份的独特特征。在课程学习框架内,WavLLM 首先通过优化混合初级单一任务来建立其基础能力,然后在更复杂的任务(如初级任务的组合)上进行高级多任务训练。为了提高灵活性并适应不同的任务和指令,在第二个高级多任务训练阶段引入了提示感知的 LoRA 权重适配器。我们在通用语音基准(包括 ASR、ST、SV、ER 等任务)上验证了所提出的模型,并将其应用于专业数据集,如用于 SQA 的高考英语听力理解集和语音思维链(CoT)评估集。实验证明,在相同的模型规模下,所提出的模型在一系列语音任务中都达到了最先进的性能,在使用 CoT 方法执行复杂任务时表现出了强大的泛化能力。此外,我们的模型无需专门训练即可成功完成高考任务。代码、模型、音频和高考评估集可在\url{aka.ms/wavllm}访问。
30.RQ-RAG: Learning to Refine Queries for Retrieval Augmented Generation
标题:RQ-RAG:学习完善检索增强生成查询
author:Chi-Min Chan, Chunpu Xu, Ruibin Yuan, Hongyin Luo, Wei Xue, Yike Guo, Jie Fu
date Time:2024-03-31
paper pdf:http://arxiv.org/pdf/2404.00610v1
摘要:
大型语言模型(LLMs)具有非凡的能力,但容易产生不准确或幻觉性的反应。这种局限性源于它们对大量预训练数据集的依赖,这使它们容易在未见过的场景中出错。为了应对这些挑战,检索增强生成(RAG)通过将外部相关文档纳入响应生成过程来解决这一问题,从而利用非参数知识和 LLM 的上下文学习能力。然而,现有的 RAG 实现主要侧重于上下文检索的初始输入,忽略了模糊或复杂查询的细微差别,而这些查询需要进一步澄清或分解才能得到准确的回复。为此,我们在本文中提出了 “为检索增强生成精炼查询”(RQ-RAG)的学习方法,努力通过为模型配备明确的重写、分解和消歧义功能来增强模型。我们的实验结果表明,当我们的方法应用于 7B Llama2 模型时,在三个单跳 QA 数据集上平均超越了之前最先进的方法(SOTA)1.9%,而且在处理复杂的多跳 QA 数据集时也表现出了更强的性能。我们的代码见 https://github.com/chanchimin/RQ-RAG。
31.MetaIE: Distilling a Meta Model from LLM for All Kinds of Information Extraction Tasks
标题:MetaIE:从 LLM 中提炼出适用于各种信息提取任务的元模型
author:Letian Peng, Zilong Wang, Feng Yao, Zihan Wang, Jingbo Shang
date Time:2024-03-30
paper pdf:http://arxiv.org/pdf/2404.00457v1
摘要:
信息提取(IE)是自然语言处理的一个基本领域,在这一领域中,即使使用上下文示例,大型语言模型(LLM)也无法打败在极小的 IE 数据集上调整的小型语言模型。我们注意到,命名实体识别和关系提取等 IE 任务都侧重于提取重要信息,这些信息可以形式化为标签到跨度的匹配。在本文中,我们提出了一个新颖的框架 MetaIE,通过学习提取 “重要信息”(即对 IE 的元理解)来建立一个小型 LM 元模型,从而使该元模型能够有效、高效地适应各种 IE 任务。具体来说,MetaIE通过从LLM中按照标签到跨度方案进行符号蒸馏来获得小型LM。我们通过从语言模型预训练数据集(例如我们实现中的 OpenWebText)中抽取句子来构建提炼数据集,并提示 LLM 识别 "重要信息 "的类型跨度。我们评估了少量适应设置下的元模型。在来自 6 个 IE 任务的 13 个数据集上的广泛结果证实,MetaIE 可以为 IE 数据集上的少量调整提供一个更好的起点,并优于其他元模型:(1)虚构语言模型预训练;(2)使用人类注释的多 IE 任务预训练;(3)来自 LLM 的单 IE 任务符号提炼。此外,我们还对 MetaIE 进行了全面分析,例如蒸馏数据集的大小、元模型架构和元模型的大小。
32.CoDa: Constrained Generation based Data Augmentation for Low-Resource NLP
标题:CoDa:基于约束生成的低资源 NLP 数据扩充
author:Chandra Kiran Reddy Evuru, Sreyan Ghosh, Sonal Kumar, Ramaneswaran S, Utkarsh Tyagi, Dinesh Manocha
publish:Accepted to NAACL 2024 Findings
date Time:2024-03-30
paper pdf:http://arxiv.org/pdf/2404.00415v1
摘要:
我们提出了 CoDa(基于约束生成的数据增强),这是一种可控、有效、无需训练的数据增强技术,适用于低资源(数据稀缺)的 NLP。我们的方法基于提示现成的遵循指令的大型语言模型(LLM),以生成满足一系列约束条件的文本。确切地说,我们从低资源数据集中的每个实例中提取了一组简单的约束条件,并将其口头化,以促使 LLM 生成新颖多样的训练实例。我们的研究结果表明,在下游数据集中遵循简单约束的合成数据可以起到高效增强的作用,CoDa 可以做到这一点,而无需复杂的解码时间限制生成技术,也无需使用复杂算法进行微调,因为复杂算法最终会使模型偏向于少量的训练实例。此外,CoDa 还是首个能让用户明确控制增强生成过程的框架,因此也能轻松适应多个领域。我们在横跨 3 个任务和 3 个低资源环境的 11 个数据集上展示了 CoDa 的有效性。CoDa在定性和定量方面都优于我们的所有基线,提高了0.12%-7.19%。代码可在此处获取:https://github.com/Sreyan88/CoDa
33.ST-LLM: Large Language Models Are Effective Temporal Learners
标题:ST-LLM:大型语言模型是有效的时态学习器
author:Ruyang Liu, Chen Li, Haoran Tang, Yixiao Ge, Ying Shan, Ge Li
date Time:2024-03-30
paper pdf:http://arxiv.org/pdf/2404.00308v1
摘要:
大型语言模型(LLM)在文本理解和生成方面展现出了令人印象深刻的能力,这促使人们努力研究视频 LLM,以促进视频层面的人机交互。然而,如何在基于视频的对话系统中有效地编码和理解视频仍有待解决。在本文中,我们研究了一个直接但尚未探索的问题:我们能否将所有时空标记输入 LLM,从而将视频序列建模的任务委托给 LLM?令人惊讶的是,这种简单的方法却能显著提高视频理解能力。在此基础上,我们提出了 ST-LLM,一种在 LLM 中进行空间-时间序列建模的有效视频-LLM 基线。此外,为了解决 LLM 中未压缩视频标记带来的开销和稳定性问题,我们开发了一种具有定制训练目标的动态屏蔽策略。对于特别长的视频,我们还设计了一个全局-本地输入模块,以平衡效率和效果。因此,我们利用 LLM 进行了熟练的时空建模,同时保持了效率和稳定性。广泛的实验结果证明了我们方法的有效性。通过更简洁的模型和训练管道,ST-LLM 在 VideoChatGPT-Bench 和 MVBench 上取得了新的一流成果。代码已发布在 https://github.com/TencentARC/ST-LLM 网站上。
34.A Comprehensive Study on NLP Data Augmentation for Hate Speech Detection: Legacy Methods, BERT, and LLMs
标题:仇恨言论检测的 NLP 数据增强综合研究:传统方法、BERT 和 LLM
author:Md Saroar Jahan, Mourad Oussalah, Djamila Romaissa Beddia, Jhuma kabir Mim, Nabil Arhab
publish:31 page, Table 18, Figure 14
date Time:2024-03-30
paper pdf:http://arxiv.org/pdf/2404.00303v1
摘要:
由于需要应对仇恨言论领域带来的挑战、社交媒体词汇的动态性质以及需要大量训练数据的大规模神经网络的需求,NLP 领域对数据扩增的兴趣激增。然而,在数据扩增中普遍使用的词汇替换引起了人们的关注,因为它可能会无意中改变预期的含义,从而影响监督机器学习模型的功效。为了寻求合适的数据扩增方法,本研究探索了既有的传统方法和当代实践,如大语言模型(LLM),包括仇恨言论检测中的 GPT。此外,我们还提出了一种基于 BERT 的编码器模型与上下文余弦相似性过滤的优化利用方法,揭示了先前同义词替换方法的重大局限性。我们的比较分析包括五种流行的增强技术:WordNet 和 Fast-Text 同义词替换、反向翻译、BERT-掩码上下文增强和 LLM。我们对五个基准数据集的分析表明,传统方法(如回译)的标签更改率较低(0.3%-1.5%),而基于 BERT 的上下文同义词替换虽然能提供句子多样性,但代价是标签更改率较高(超过 6%)。我们提出的基于 BERT 的上下文余弦相似性过滤方法显著降低了标签改动率,使其仅为 0.05%,这表明它能有效地将 F1 性能提高 0.7%。然而,使用 GPT-3 增加数据不仅避免了数据增加七倍后的过度拟合,还将嵌入空间覆盖率提高了 15%,分类 F1 分数比传统方法提高了 1.4%,比我们的方法提高了 0.8%。
35.Survey on Large Language Model-Enhanced Reinforcement Learning: Concept, Taxonomy, and Methods
标题:大型语言模型增强强化学习调查:概念、分类和方法
author:Yuji Cao, Huan Zhao, Yuheng Cheng, Ting Shu, Guolong Liu, Gaoqi Liang, Junhua Zhao, Yun Li
publish:16 pages (including bibliography), 6 figures
date Time:2024-03-30
paper pdf:http://arxiv.org/pdf/2404.00282v1
摘要:
大语言模型(LLMs)具有广泛的预训练知识和高级通用能力,在多任务学习、样本效率和任务规划等方面成为增强强化学习(RL)的一个前景广阔的途径。在这份调查报告中,我们全面回顾了 t e x t i t L L M − e n h a n c e d R L textit{LLM-enhanced RL} textitLLM−enhancedRL的现有文献,并总结了其与传统RL方法相比的特点,旨在明确未来的研究范围和方向。利用经典的代理-环境交互范式,我们提出了一种结构化分类法,系统地划分了 LLM 在 RL 中的功能,包括四个角色:信息处理器、奖励设计器、决策者和生成器。此外,针对每种角色,我们都总结了相关方法,分析了可减轻的特定 RL 挑战,并对未来发展方向提出了见解。最后,我们讨论了 t e x t i t L L M − e n h a n c e d R L textit{LLM-enhanced RL} textitLLM−enhancedRL的潜在应用、未来机遇和挑战。
36.EventGround: Narrative Reasoning by Grounding to Eventuality-centric Knowledge Graphs
标题:EventGround:通过以事件为中心的知识图谱为基础进行叙事推理
author:Cheng Jiayang, Lin Qiu, Chunkit Chan, Xin Liu, Yangqiu Song, Zheng Zhang
date Time:2024-03-30
paper pdf:http://arxiv.org/pdf/2404.00209v1
摘要:
叙事推理依赖于对故事情境中可能发生情况的理解,这需要丰富的背景世界知识。为了帮助机器利用这些知识,现有的解决方案可分为两类。一些解决方案侧重于通过预训练具有事件感知目标的语言模型(LMs)来隐式建模事件知识。然而,这种方法会破坏知识结构,缺乏可解释性。其他一些方法则显式地将世界偶发事件知识收集到以偶发事件为中心的结构化知识图谱(KGs)中。然而,现有关于利用这些知识源进行自由文本的研究十分有限。在这项工作中,我们提出了一个名为 EventGround 的初步综合框架,旨在解决将自由文本建立在以偶发事件为中心的知识图谱上的问题,以实现上下文化的叙述推理。在这个方向上,我们发现了两个关键问题:事件表示和稀疏性问题。我们提供了简单而有效的解析和部分信息提取方法来解决这些问题。实验结果表明,当结合基于图神经网络(GNN)或大语言模型(LLM)的图推理模型时,我们的方法始终优于基准模型。我们的框架结合了基础知识,在提供可解释证据的同时实现了最先进的性能。
相关文章:
:2024.03.31-2024.04.05)
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.03.31-2024.04.05
文章目录~ 1.AutoWebGLM: Bootstrap And Reinforce A Large Language Model-based Web Navigating Agent2.Training LLMs over Neurally Compressed Text3.Unveiling LLMs: The Evolution of Latent Representations in a Temporal Knowledge Graph4.Visualization-of-Thought …...
使用详解)
性能测试工具 ab(Apache Bench)使用详解
Apache Bench (ab) 是一个由 Apache 提供的非常流行的、简单的性能测试工具,用于对 HTTP 服务器进行压力测试。下面是 ab 工具的一些基本使用方法。 安装 在大多数 Unix 系统中,ab 通常作为 Apache HTTP 服务器的一部分预装在系统中。你可以通过在终端…...

智能网联汽车自动驾驶数据记录系统DSSAD数据元素
目录 第一章 数据元素分级 第二章 数据元素分类 第三章 数据元素基本信息表 表1 车辆及自动驾驶数据记录系统基本信息 表2 车辆状态及动态信息 表3 自动驾驶系统运行信息 表4 行车环境信息 表5 驾驶员操作及状态信息 第一章 数据元素分级 自动驾驶数据记录系统记录的数…...

Ubuntu 20.04.06 PCL C++学习记录(十八)
[TOC]PCL中点云分割模块的学习 学习背景 参考书籍:《点云库PCL从入门到精通》以及官方代码PCL官方代码链接,,PCL版本为1.10.0,CMake版本为3.16 学习内容 PCL中实现欧式聚类提取。在点云处理中,聚类是一种常见的任务,它将点云数据划分为多…...

细雨踏春日,新会公安护平安
春雨起,清明至。又是一年春草绿,又是一年清明时。细雨踏春日,思怀故人时,是哀思,亦是相聚。新会公安一抹抹葵乡春日“警”色坚守岗位,确保清明祭扫平稳有序,为人民群众的平安保驾护航。 为确保2…...

3d怎么在一块模型上开个孔---模大狮模型网
在进行3D建模时,有时候需要在模型上创建孔,以实现特定的设计需求或功能。无论是为了添加细节,还是为了实现功能性的要求,创建孔都是常见的操作之一。本文将介绍在3D模型上创建孔的几种常用方法,帮助您轻松实现这一目标…...
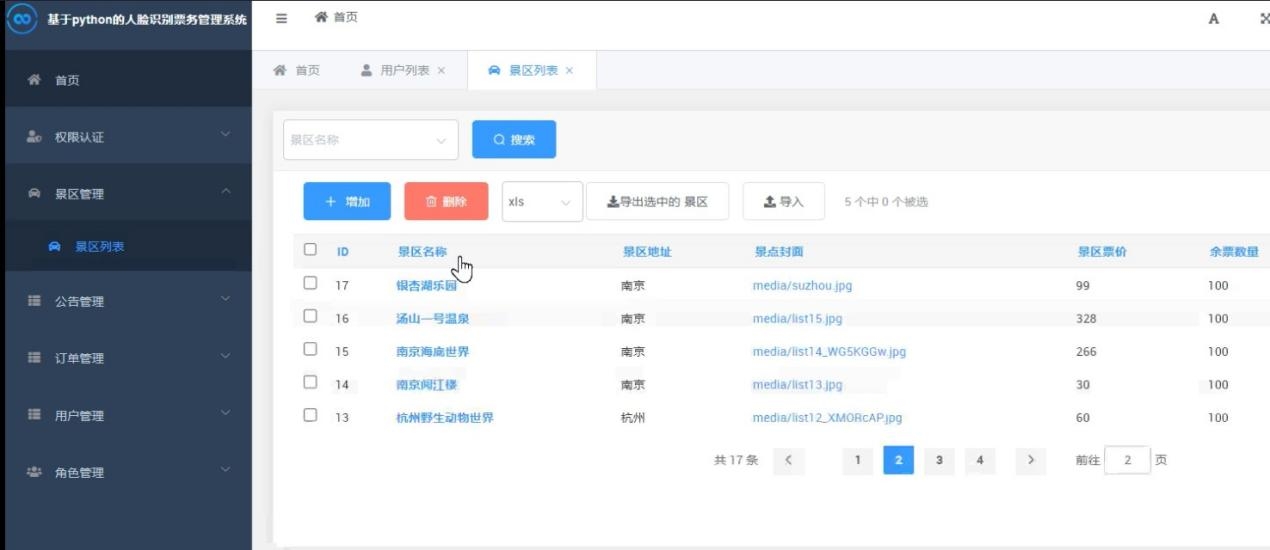
Python景区票务人脸识别系统(V2.0),附源码
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专栏推荐订阅👇…...

全球化业务的网络安全挑战
随着企业业务的全球化,跨国数据传输和用户跨地域访问成为常态。这不仅带来了巨大的商业机会,也带来了以下网络安全挑战: 数据泄露风险:跨国数据传输增加了数据被截获和泄露的风险。访问限制:某些地区可能对互联网内容…...

SQL简单优化思路
在编写SQL查询时,优化查询性能是一个重要的考虑因素,特别是在处理多表连接(JOIN)和子查询时。以下是一些具体的技巧和最佳实践,可以帮助你在保持相同返回值的前提下,降低SQL执行速度: 明确连接顺…...

外包干了25天,技术倒退明显
先说情况,大专毕业,18年通过校招进入湖南某软件公司,干了接近6年的功能测试,今年年初,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落! 而我已经在一个企业干了四年的功能…...
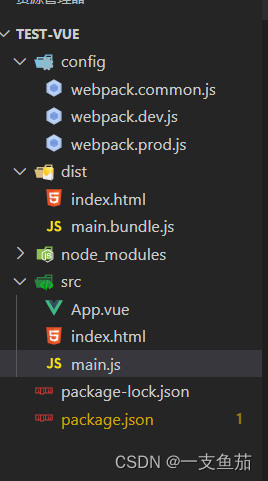
webpack环境配置分类结合vue使用
文件目录结构 按照目录结构创建好文件 控制台执行: npm install /config/webpack.common.jsconst path require(path) const {merge} require(webpack-merge) const {CleanWebpackPlugin} require(clean-webpack-plugin) const { VueLoaderPlugin } require(vue-loader); c…...

【蓝桥杯嵌入式】第十三届省赛(第二场)
目录 0 前言 1 展示 1.1 源码 1.2 演示视频 1.3 题目展示 2 CubeMX配置(第十三届省赛第二场真题) 2.1 设置下载线 2.2 HSE时钟设置 2.3 时钟树配置 2.4 生成代码设置 2.5 USART1 2.5.1 基本配置 2.5.2 NVIC 2.5.3 DMA 2.6 TIM 2.6.1 TIM2 2.6.2 TIM4 2.6.3 …...

maya节点绕轴旋转
目录 旋转后并尝试冻结变换 绕x轴旋转90度 使用Python脚本 使用图形界面 使用MEL脚本 绕y轴旋转90度 使用Python脚本 ok 旋转后并尝试冻结变换 import maya.cmds as cmdsdef adjust_root_rotation_for_export(joint_name):# 选择根节点cmds.select(joint_name)# 应用旋…...

如何水出第一篇SCI:SCI发刊历程,从0到1全过程经验分享!!!
如何水出第一篇SCI:SCI发刊历程,从0到1全路程经验分享!!! 详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:Ai学术叫叫兽e…...

SpringBoot表单防止重复提交
哪些因素会引起重复提交? 开发的项目中可能会出现下面这些情况: 前端下单按钮重复点击导致订单创建多次 网速等原因造成页面卡顿,用户重复刷新提交请求 黑客或恶意用户使用postman等http工具重复恶意提交表单 重复提交会带来哪些问题&…...
)
java面向对象.day17(什么是面向对象)
先认识:面向过程思想,面向对象思想 面向过程思想(具体) 步骤清晰简单,第一步做什么,第二步做什么.... 面对过程适合处理一些较为简单的问题 面向对象思想(抽象) 物以类聚&#x…...

mysql处理并发简单示例
处理并发的基本思路是使用锁来控制对共享资源的访问。在MySQL中,可以使用事务和行级锁来处理并发。 具体处理方式如下: 创建一个用于存储并发任务的MySQL表,该表包含一个自增的ID字段和任务名称字段。设置一个最大并发数量,用来…...

顺序表——功能实现
✨✨欢迎👍👍点赞☕️☕️收藏✍✍评论 个人主页:秋邱博客 所属栏目:C语言 (感谢您的光临,您的光临蓬荜生辉) 目录 1.0 前言 2.0 线性表 2.1 顺序表 2.2 顺序表的分类 2.3 顺序表功能的实现…...

达梦导出工具dexp
基础环境 操作系统:Red Hat Enterprise Linux Server release 7.9 (Maipo) 数据库版本:DM Database Server 64 V8 架构:单实例dexp 逻辑导出 dexp 工具可以对本地或者远程数据库进行数据库级、用户级、模式级和表级的逻辑备份。备份的内容非…...

Ubuntu 22.04安装新硬盘并启动时自动挂载
方法一 要在Ubuntu 22.04系统中安装一个新硬盘、对其进行格式化并实现启动时自动挂载,需要按以下步骤操作: 1. 安装硬盘 - 确保你的硬盘正确连接到计算机上(涉及硬件安装)。 2. 发现新硬盘 - 在系统启动后,打开终端…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...