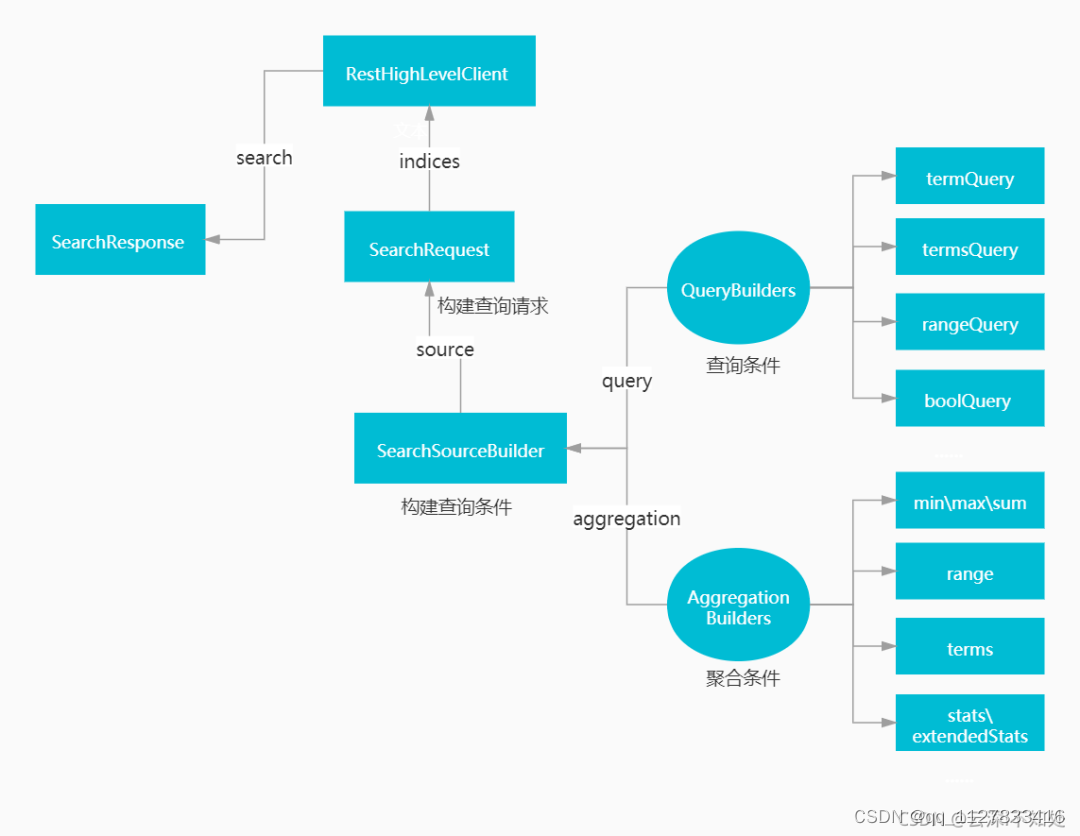
ElasticSearch 在Java中的各种实现

ES JavaAPI的相关体系:
词条查询
所谓词条查询,也就是ES不会对查询条件进行分词处理,只有当词条和查询字符串完全匹配时,才会被查询到。
等值查询-term
等值查询,即筛选出一个字段等于特定值的所有记录。
【SQL】
select * from person where name = '张无忌';【ES】「注意查询字段带上keyword」
GET /person/_search
{"query": {"term": {"name.keyword": {"value": "张无忌","boost": 1.0}}}
}注意⚠️:ElasticSearch 5.0以后,string类型有重大变更,移除了string类型,string字段被拆分成两种新的数据类型: text用于全文搜索的,而keyword用于关键词搜索。
「查询结果:」
{"took" : 0,"timed_out" : false,"_shards" : { // 分片信息"total" : 1, // 总计分片数"successful" : 1, // 查询成功的分片数"skipped" : 0, // 跳过查询的分片数"failed" : 0 // 查询失败的分片数},"hits" : { // 命中结果"total" : {"value" : 1, // 数量"relation" : "eq" // 关系:等于},"max_score" : 2.8526313, // 最高分数"hits" : [{"_index" : "person", // 索引"_type" : "_doc", // 类型"_id" : "1","_score" : 2.8526313,"_source" : {"address" : "光明顶","modifyTime" : "2021-06-29 16:48:56","createTime" : "2021-05-14 16:50:33","sect" : "明教","sex" : "男","skill" : "九阳神功","name" : "张无忌","id" : 1,"power" : 99,"age" : 18}}]}
}「Java中构造ES请求的方式:」(后续例子中只保留SearchSourceBuilder的构建语句)
/*** term精确查询** @throws IOException*/@Autowired
private RestHighLevelClient client;@Test
public void queryTerm() throws IOException {// 根据索引创建查询请求SearchRequest searchRequest = new SearchRequest("person");SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// 构建查询语句searchSourceBuilder.query(QueryBuilders.termQuery("name.keyword", "张无忌"));System.out.println("searchSourceBuilder=====================" + searchSourceBuilder);searchRequest.source(searchSourceBuilder);SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);System.out.println(JSONObject.toJSON(response));
}查看查询结果,会发现ES查询结果中会带有_score这一项,ES会根据结果匹配程度进行评分。打分是会耗费性能的,如果确认自己的查询不需要评分,就设置查询语句关闭评分:
GET /person/_search
{"query": {"constant_score": {"filter": {"term": {"sect.keyword": {"value": "张无忌","boost": 1.0}}},"boost": 1.0}}「Java构建查询语句:」
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 这样构造的查询条件,将不进行score计算,从而提高查询效率
searchSourceBuilder.query(QueryBuilders.constantScoreQuery(QueryBuilders.termQuery("sect.keyword", "明教")));多值查询-terms
多条件查询类似Mysql里的IN查询,例如:
select * from persons where sect in('明教','武当派');「ES查询语句:」
GET /person/_search
{"query": {"terms": {"sect.keyword": ["明教","武当派"],"boost": 1.0}}
}「Java实现:」
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.termsQuery("sect.keyword", Arrays.asList("明教", "武当派")));
}范围查询-range
范围查询,即查询某字段在特定区间的记录。
「SQL:」
select * from pesons where age between 18 and 22;「ES查询语句:」
GET /person/_search
{"query": {"range": {"age": {"from": 10,"to": 20,"include_lower": true,"include_upper": true,"boost": 1.0}}}
}「Java构建查询条件:」
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.rangeQuery("age").gte(10).lte(30));
}前缀查询-prefix
前缀查询类似于SQL中的模糊查询。
「SQL:」
select * from persons where sect like '武当%';「ES查询语句:」
{"query": {"prefix": {"sect.keyword": {"value": "武当","boost": 1.0}}}
}「Java构建查询条件:」
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.prefixQuery("sect.keyword","武当"));通配符查询-wildcard
通配符查询,与前缀查询类似,都属于模糊查询的范畴,但通配符显然功能更强。
「SQL:」
select * from persons where name like '张%忌';「ES查询语句:」
{"query": {"wildcard": {"sect.keyword": {"wildcard": "张*忌","boost": 1.0}}}
}「Java构建查询条件:」
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.wildcardQuery("sect.keyword","张*忌"));复合查询
前面的例子都是单个条件查询,在实际应用中,我们很有可能会过滤多个值或字段。先看一个简单的例子:
select * from persons where sex = '女' and sect = '明教';这样的多条件等值查询,就要借用到组合过滤器了,其查询语句是:
{"query": {"bool": {"must": [{"term": {"sex": {"value": "女","boost": 1.0}}},{"term": {"sect.keywords": {"value": "明教","boost": 1.0}}}],"adjust_pure_negative": true,"boost": 1.0}}
}Java构造查询语句:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("sex", "女")).must(QueryBuilders.termQuery("sect.keyword", "明教"))
);布尔查询
布尔过滤器(bool filter)属于复合过滤器(compound filter)的一种 ,可以接受多个其他过滤器作为参数,并将这些过滤器结合成各式各样的布尔(逻辑)组合。
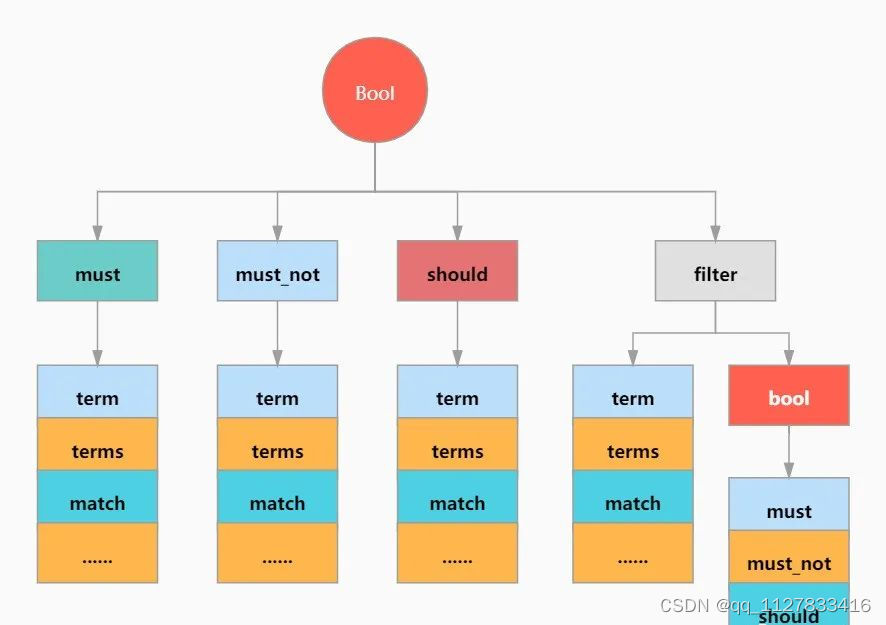
bool 过滤器下可以有4种子条件,可以任选其中任意一个或多个。
{"bool" : {"must" : [],"should" : [],"must_not" : [],}
}-
**
must**:所有的语句都必须匹配,与 ‘=’ 等价。 -
**
must_not**:所有的语句都不能匹配,与 ‘!=’ 或 not in 等价。 -
**
should**:至少有n个语句要匹配,n由参数控制。
「精度控制:」
所有 must 语句必须匹配,所有 must_not 语句都必须不匹配,但有多少 should 语句应该匹配呢?默认情况下,没有 should 语句是必须匹配的,只有一个例外:那就是当没有 must 语句的时候,至少有一个 should 语句必须匹配。
我们可以通过 minimum_should_match 参数控制需要匹配的 should 语句的数量,它既可以是一个绝对的数字,又可以是个百分比:
GET /person/_search
{"query": {"bool": {"must": [{"term": {"sex": {"value": "女","boost": 1.0}}}],"should": [{"term": {"address.keyword": {"value": "峨眉山","boost": 1.0}}},{"term": {"sect.keyword": {"value": "明教","boost": 1.0}}}],"adjust_pure_negative": true,"minimum_should_match": "1","boost": 1.0}}
}
「Java构建查询语句:」
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("sex", "女")).should(QueryBuilders.termQuery("address.word", "峨眉山")).should(QueryBuilders.termQuery("sect.keyword", "明教")).minimumShouldMatch(1)
);最后,看一个复杂些的例子,将bool的各子句联合使用:
select *
frompersons
where sex = '女'
andage between 30 and 40
and sect != '明教'
and (address = '峨眉山' OR skill = '暗器')用 Elasticsearch 来表示上面的 SQL 例子:
GET /person/_search
{"query": {"bool": {"must": [{"term": {"sex": {"value": "女","boost": 1.0}}},{"range": {"age": {"from": 30,"to": 40,"include_lower": true,"include_upper": true,"boost": 1.0}}}],"must_not": [{"term": {"sect.keyword": {"value": "明教","boost": 1.0}}}],"should": [{"term": {"address.keyword": {"value": "峨眉山","boost": 1.0}}},{"term": {"skill.keyword": {"value": "暗器","boost": 1.0}}}],"adjust_pure_negative": true,"minimum_should_match": "1","boost": 1.0}}
}「用Java构建这个查询条件:」
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery().must(QueryBuilders.termQuery("sex", "女")).must(QueryBuilders.rangeQuery("age").gte(30).lte(40)).mustNot(QueryBuilders.termQuery("sect.keyword", "明教")).should(QueryBuilders.termQuery("address.keyword", "峨眉山")).should(QueryBuilders.rangeQuery("power.keyword").gte(50).lte(80)).minimumShouldMatch(1); // 设置should至少需要满足几个条件// 将BoolQueryBuilder构建到SearchSourceBuilder中
searchSourceBuilder.query(boolQueryBuilder);Filter查询
query和filter的区别:query查询的时候,会先比较查询条件,然后计算分值,最后返回文档结果;而filter是先判断是否满足查询条件,如果不满足会缓存查询结果(记录该文档不满足结果),满足的话,就直接缓存结果,「filter不会对结果进行评分,能够提高查询效率」。
filter的使用方式比较多样,下面用几个例子演示一下。
「方式一,单独使用:」
{"query": {"bool": {"filter": [{"term": {"sex": {"value": "男","boost": 1.0}}}],"adjust_pure_negative": true,"boost": 1.0}}
}单独使用时,filter与must基本一样,不同的是「filter不计算评分,效率更高」。
Java构建查询语句:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.boolQuery().filter(QueryBuilders.termQuery("sex", "男"))
);「方式二,和must、must_not同级,相当于子查询:」
select * from (select * from persons where sect = '明教')) a where sex = '女';ES查询语句:
{"query": {"bool": {"must": [{"term": {"sect.keyword": {"value": "明教","boost": 1.0}}}],"filter": [{"term": {"sex": {"value": "女","boost": 1.0}}}],"adjust_pure_negative": true,"boost": 1.0}}
}
Java语句构建:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("sect.keyword", "明教")).filter(QueryBuilders.termQuery("sex", "女"))
);「方式三,将must、must_not置于filter下,这种方式是最常用的:」
{"query": {"bool": {"filter": [{"bool": {"must": [{"term": {"sect.keyword": {"value": "明教","boost": 1.0}}},{"range": {"age": {"from": 20,"to": 35,"include_lower": true,"include_upper": true,"boost": 1.0}}}],"must_not": [{"term": {"sex.keyword": {"value": "女","boost": 1.0}}}],"adjust_pure_negative": true,"boost": 1.0}}],"adjust_pure_negative": true,"boost": 1.0}}
}Java语句构建:
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 构建查询语句
searchSourceBuilder.query(QueryBuilders.boolQuery().filter(QueryBuilders.boolQuery().must(QueryBuilders.termQuery("sect.keyword", "明教")).must(QueryBuilders.rangeQuery("age").gte(20).lte(35)).mustNot(QueryBuilders.termQuery("sex.keyword", "女")))
);聚合查询
最值、平均值、求和
「案例:查询最大年龄、最小年龄、平均年龄。」
「SQL:」
select max(age) from persons;「ES:」
GET /person/_search
{"aggregations": {"max_age": {"max": {"field": "age"}}}
}「Java:」
@Autowired
private RestHighLevelClient client;@Test
public void maxQueryTest() throws IOException {// 聚合查询条件AggregationBuilder aggBuilder = AggregationBuilders.max("max_age").field("age");SearchRequest searchRequest = new SearchRequest("person");SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// 将聚合查询条件构建到SearchSourceBuilder中searchSourceBuilder.aggregation(aggBuilder);System.out.println("searchSourceBuilder----->" + searchSourceBuilder);searchRequest.source(searchSourceBuilder);// 执行查询,获取SearchResponseSearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);System.out.println(JSONObject.toJSON(response));
}使用聚合查询,结果中默认只会返回10条文档数据(当然我们关心的是聚合的结果,而非文档)。返回多少条数据可以自主控制
GET /person/_search
{"size": 20,"aggregations": {"max_age": {"max": {"field": "age"}}}
}
而Java中只需增加下面一条语句即可:
searchSourceBuilder.size(20);与max类似,其他统计查询也很简单:
AggregationBuilder minBuilder = AggregationBuilders.min("min_age").field("age");
AggregationBuilder avgBuilder = AggregationBuilders.avg("min_age").field("age");
AggregationBuilder sumBuilder = AggregationBuilders.sum("min_age").field("age");
AggregationBuilder countBuilder = AggregationBuilders.count("min_age").field("age");去重查询
「案例:查询一共有多少个门派。」
「SQL:」
select count(distinct sect) from persons;【ES:】
{"aggregations": {"sect_count": {"cardinality": {"field": "sect.keyword"}}}
}Java:
@Test
public void cardinalityQueryTest() throws IOException {// 创建某个索引的requestSearchRequest searchRequest = new SearchRequest("person");// 查询条件SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// 聚合查询AggregationBuilder aggBuilder = AggregationBuilders.cardinality("sect_count").field("sect.keyword");searchSourceBuilder.size(0);// 将聚合查询构建到查询条件中searchSourceBuilder.aggregation(aggBuilder);System.out.println("searchSourceBuilder----->" + searchSourceBuilder);searchRequest.source(searchSourceBuilder);// 执行查询,获取结果SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);System.out.println(JSONObject.toJSON(response));
}分组聚合
单条件分组
「案例:查询每个门派的人数」
「SQL:」
select sect,count(id) from mytest.persons group by sect;「ES:」
{"size": 0,"aggregations": {"sect_count": {"terms": {"field": "sect.keyword","size": 10,"min_doc_count": 1,"shard_min_doc_count": 0,"show_term_doc_count_error": false,"order": [{"_count": "desc"},{"_key": "asc"}]}}}
}「Java:」
SearchRequest searchRequest = new SearchRequest("person");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.size(0);
// 按sect分组
AggregationBuilder aggBuilder = AggregationBuilders.terms("sect_count").field("sect.keyword");
searchSourceBuilder.aggregation(aggBuilder);多条件分组
「案例:查询每个门派各有多少个男性和女性」
「SQL:」
select sect,sex,count(id) from mytest.persons group by sect,sex;「ES:」
{"aggregations": {"sect_count": {"terms": {"field": "sect.keyword","size": 10},"aggregations": {"sex_count": {"terms": {"field": "sex.keyword","size": 10}}}}}
}
过滤聚合
前面所有聚合的例子请求都省略了 query ,整个请求只不过是一个聚合。这意味着我们对全部数据进行了聚合,但现实应用中,我们常常对特定范围的数据进行聚合,例如下例。
「案例:查询明教中的最大年龄。」 这涉及到聚合与条件查询一起使用。
「SQL:」
select max(age) from mytest.persons where sect = '明教';「ES:」
GET /person/_search
{"query": {"term": {"sect.keyword": {"value": "明教","boost": 1.0}}},"aggregations": {"max_age": {"max": {"field": "age"}}}
}
「Java:」
SearchRequest searchRequest = new SearchRequest("person");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 聚合查询条件
AggregationBuilder maxBuilder = AggregationBuilders.max("max_age").field("age");
// 等值查询
searchSourceBuilder.query(QueryBuilders.termQuery("sect.keyword", "明教"));
searchSourceBuilder.aggregation(maxBuilder);另外还有一些更复杂的查询例子。
「案例:查询0-20,21-40,41-60,61以上的各有多少人。」
【SQL:】
select sum(case when age<=20 then 1 else 0 end) ageGroup1,sum(case when age >20 and age <=40 then 1 else 0 end) ageGroup2,sum(case when age >40 and age <=60 then 1 else 0 end) ageGroup3,sum(case when age >60 and age <=200 then 1 else 0 end) ageGroup4
from mytest.persons;【ES:】
{"size": 0,"aggregations": {"age_avg": {"range": {"field": "age","ranges": [{"from": 0.0,"to": 20.0},{"from": 21.0,"to": 40.0},{"from": 41.0,"to": 60.0},{"from": 61.0,"to": 200.0}],"keyed": false}}}
}【Java:】
查询结果:
"aggregations" : {"age_avg" : {"buckets" : [{"key" : "0.0-20.0","from" : 0.0,"to" : 20.0,"doc_count" : 3},{"key" : "21.0-40.0","from" : 21.0,"to" : 40.0,"doc_count" : 13},{"key" : "41.0-60.0","from" : 41.0,"to" : 60.0,"doc_count" : 4},{"key" : "61.0-200.0","from" : 61.0,"to" : 200.0,"doc_count" : 1}]}
}相关文章:
ElasticSearch 在Java中的各种实现
ES JavaAPI的相关体系: 词条查询 所谓词条查询,也就是ES不会对查询条件进行分词处理,只有当词条和查询字符串完全匹配时,才会被查询到。 等值查询-term 等值查询,即筛选出一个字段等于特定值的所有记录。 【SQL】 s…...
SpringBoot整合Knife4j
文章目录前言一、Knife4j是什么?二、使用步骤1.导入依赖2.编写配置文件3.编写controller和实体类4.测试总结前言 接上篇整合Swagger链接奉上http://t.csdn.cn/9mXSu 一、Knife4j是什么? 官方文档:https://doc.xiaominfo.com/ knife4j可以理解…...

MyISAM和InnoDB存储引擎的区别
目录前言存储引擎区别事务外键表单的存储数据查询效率数据更新效率如何选择前言 MyISAM和InnoDB是使用MySQL最常用的两种存储引擎,在5.5版本之前默认采用MyISAM存储引擎,从5.5开始采用InnoDB存储引擎。 存储引擎 存储引擎是:数据库管理系统…...

SpringMVC自定义处理多种日期格式的格式转换器
package cn.itcast.utils;import org.springframework.core.convert.converter.Converter;import java.text.DateFormat;import java.text.SimpleDateFormat;import java.util.Date;/*** 把字符串转换日期*/public class StringToDateConverter implements Converter<String…...
NYUv2生成边界GT(1)
看了cityscape和NYUv2生成边界GT的代码后,因为自己使用的是NYUv2数据集,所以需要对自己的数据集进行处理。CASENet生成边界GT所使用的代码是MATLAB,所以又重新看了一下MATLAB的代码,并进行修改,生成了自己的边界代码。…...
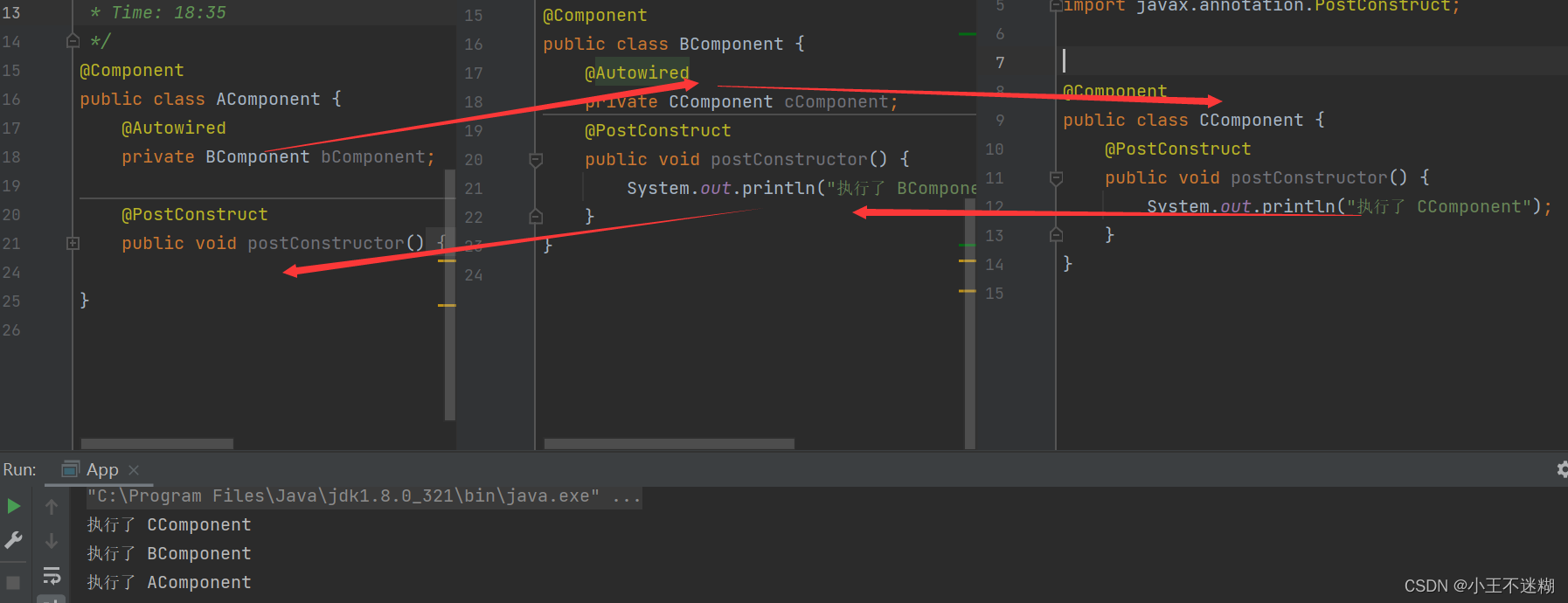
Spring基本概念与使用
文章目录一、Spring概念1.容器2.IoC3.DI4.Ioc与DI的关系二、Spring创建与使用1.Maven2.添加Spring框架支持注:国内的Maven源配置3.简单实例(1)创建一个Bean对象。(2)将Bean对象存储到Spring当中(3ÿ…...

安恒信息java实习面经
目录1.Java ME、EE、SE的区别,Java EE相对于SE多了哪些东西?2.jdk与jre的区别3.说一下java的一些命令,怎么运行一个jar包4.简单说一下java数据类型及使用场景5.Map跟Collection有几种实现?6.面向对象的特性7.重载和重写的区别8.重…...

第八章:枚举类与注解
第八章:枚举类与注解 8.1:枚举类的使用 类的对象只有有限个,确定的。我们称此类为枚举类。当需要定义一组常量是,强烈建议使用枚举类。如果枚举类中只有一个对象,则可以作为单例模式的实现方式。 如何定义枚举类 …...
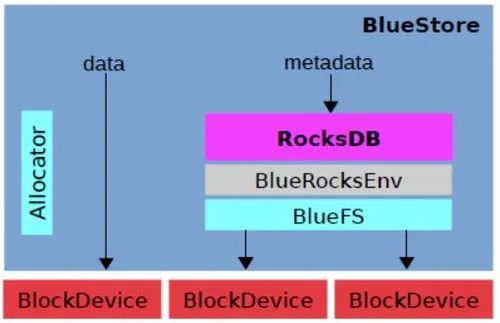
Ceph介绍
分布式存储概述 常用的存储可以分为DAS、NAS和SAN三类 DAS:直接连接存储,是指通过SCSI接口或FC接口直接连接到一台计算机上,常见的就是服务器的硬盘NAS:网络附加存储,是指将存储设备通过标准的网络拓扑结构ÿ…...

remove 和 erase 的区别
remove 和 erase 的区别 以容器vector来说明remove和erase的区别 在STL中,vector容器也提供了remove()和erase()函数,用于从vector中删除元素。虽然这两个函数都可以实现删除元素的功能,但是它们之间还是有一些区别的。 remove() remove(…...
NFTScan:怎么使用 NFT API 开发一个 NFT 数据分析平台?
对很多开发者来说,在 NFT 数据海洋中需要对每个 NFT 进行索引和筛选是十分困难且繁琐的,NFT 数据获取仍是一大问题。而数据平台提供的 API 使得开发者可以通过接口获取区块链上 NFT 的详细信息,并对其进行分析、处理、统计和可视化。在本篇文…...

ECOLOY直接更换流程表单后导致历史流程中数据为空白的解决方案
用户反馈流历史流程打开是空白了没有内容。 一、问题调查分析: 工作流“XX0204 员工培训协议审批流程”workflowId37166产生的7个具体流程中,创建日期为2021年的4个具体流程原先引用的数据库表单应该是“劳动合同签订审批表”(formtable_main_190)&…...

mysql中的共享锁,排他锁,间隙锁,意向锁及死锁机制
一、前言(以下均为读完 高性能Mysql第四版 后的个人理解,建议阅读,挺不错的)在写锁机制前先简单贴出mysql InnoDB引擎中的事务特性与隔离级别:事务的ACID标准(1)原子性-atomicity:一个事务作为一个不可分割…...
SpringBoot整合MybatisPlus
文章目录前言一、MybatisPlus是什么?二、使用步骤1.导入依赖2.编写配置文件3.编写Controller和实体类4.编写持久层接口mapper5.启动类加包扫描注解6.测试总结前言 本篇记录一下SpringBoot整合MybatisPlus 一、MybatisPlus是什么? MyBatis-Plusÿ…...

中电金信Gien享汇・大数据专题|金融行业数据架构及模型演进
本期嘉宾 陈子刚 中电金信商业分析事业部华南区总经理 毕业于复旦大学,硕士研究生;拥有16年以上金融行业商业智能领域从业经验;曾就职于中国工商银行、Teradata、东亚银行,服务于平安银行、广发银行、招商银行、广东农信、招商…...

Cadence Allegro 导出Design Cross Section报告详解
⏪《上一篇》 🏡《上级目录》 ⏩《下一篇》 目录 1,概述2,Design Cross Section作用3,Design Cross Section示例4,Component Report导出方法4.1,方法14.2,方法2B站关注“硬小二”浏览更多演示视频 1,概述 <...
【LeetCode】剑指 Offer 23. 链表中环的入口节点 p139 -- Java Version
题目链接:https://leetcode.cn/problems/c32eOV/ 1. 题目介绍(23. 链表中环的入口节点) 给定一个链表,返回链表开始入环的第一个节点。 从链表的头节点开始沿着 next 指针进入环的第一个节点为环的入口节点。如果链表无环&#x…...

LeetCode-96. 不同的二叉搜索树
题目来源 96. 不同的二叉搜索树 递归 1.我们要知道二叉搜索树的性质,对于一个二叉搜索树,其 【左边的节点值 < 中间的节点值 < 右边的节点值】,也就是说,对于一个二叉搜索树,其中序遍历之后形成的数组应该是一…...

JavaWeb基础
Servlet 是在服务器上运行的小程序。这个词是在 Java applet的环境中创造的,Java applet 是一种当作单独文件跟网页一起发送的小程序,它通常用于在客户端运行,结果得到为用户进行运算或者根据用户互作用定位图形等服务。服务器上需要一些程序…...
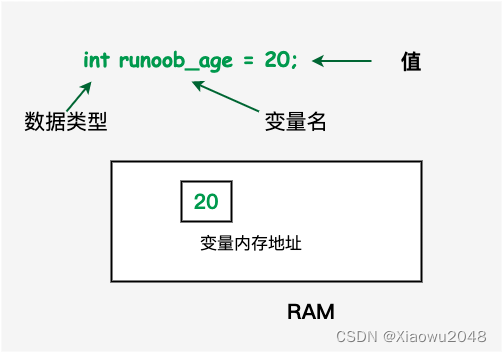
C++基础了解-03-C++变量类型
C变量类型 一、变量类型 变量其实只不过是程序可操作的存储区的名称。C 中每个变量都有指定的类型,类型决定了变量存储的大小和布局,该范围内的值都可以存储在内存中,运算符可应用于变量上。 变量的名称可以由字母、数字和下划线字符组成。…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

Device Mapper 机制
Device Mapper 机制详解 Device Mapper(简称 DM)是 Linux 内核中的一套通用块设备映射框架,为 LVM、加密磁盘、RAID 等提供底层支持。本文将详细介绍 Device Mapper 的原理、实现、内核配置、常用工具、操作测试流程,并配以详细的…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

Yolov8 目标检测蒸馏学习记录
yolov8系列模型蒸馏基本流程,代码下载:这里本人提交了一个demo:djdll/Yolov8_Distillation: Yolov8轻量化_蒸馏代码实现 在轻量化模型设计中,**知识蒸馏(Knowledge Distillation)**被广泛应用,作为提升模型…...