python之pandas数据导入和导出
目录
- Pandas 常用数据导入
- Pandas 常用数据导出
- 数据导入示例
- CSV 文件:
- 指定导入文件的编码格式
- 添加列标题
- Excel 文件:
- JSON 文件:
- 数据库:
- HTML 表格:
- Clipboard:
- HDF5 文件:
- Feather 文件:
- Parquet 文件:
- Msgpack 文件:
- 数据导出示例
- CSV 文件:
- Excel 文件:
- JSON 文件:
- 数据库:
- HTML 表格:
- Clipboard:
- HDF5 文件:
- Feather 文件:
- Parquet 文件:
- Msgpack 文件:
- 总结
Pandas 是 Python 中用于数据处理和分析的强大库,提供了丰富的功能来导入、处理和导出数据。本教程将介绍如何使用 Pandas 导入和导出数据,以及一些常见的数据处理技巧。
Pandas 常用数据导入
- CSV 文件:使用
pd.read_csv()导入逗号分隔值文件。 - Excel 文件:使用
pd.read_excel()导入 Microsoft Excel 文件。 - JSON 文件:使用
pd.read_json()导入 JSON 文件。 - SQL 数据库:使用
pd.read_sql()或pd.read_sql_query()从 SQL 数据库中导入数据。 - HTML 表格:使用
pd.read_html()从 HTML 文件或网页中提取表格数据。 - Clipboard:使用
pd.read_clipboard()从剪贴板中导入数据。 - HDF5 文件:使用
pd.read_hdf()导入 HDF5 文件中的数据。 - Feather 文件:使用
pd.read_feather()导入 Feather 文件中的数据。 - Parquet 文件:使用
pd.read_parquet()导入 Parquet 文件中的数据。 - Msgpack 文件:使用
pd.read_msgpack()导入 Msgpack 文件中的数据。
Pandas 常用数据导出
- CSV 文件:使用
to_csv()方法将数据导出到逗号分隔值文件。 - Excel 文件:使用
to_excel()方法将数据导出到 Microsoft Excel 文件。 - JSON 文件:使用
to_json()方法将数据导出到 JSON 文件。 - SQL 数据库:使用
to_sql()方法将数据导出到 SQL 数据库中。 - HTML 表格:使用
to_html()方法将数据导出为 HTML 表格格式。 - Clipboard:使用
to_clipboard()方法将数据复制到剪贴板。 - HDF5 文件:使用
to_hdf()方法将数据导出到 HDF5 文件中。 - Feather 文件:使用
to_feather()方法将数据导出到 Feather 文件中。 - Parquet 文件:使用
to_parquet()方法将数据导出到 Parquet 文件中。 - Msgpack 文件:使用
to_msgpack()方法将数据导出到 Msgpack 文件中。
数据导入示例
CSV 文件:
import pandas as pd# 从 CSV 文件导入数据
data_csv = pd.read_csv('data.csv')
data_csv.head()
指定导入文件的编码格式
在Pandas中,你可以使用encoding参数来指定导入文件的编码格式。如果你知道CSV文件使用的是特定的编码格式,比如UTF-8或者GBK,你可以将encoding参数设置为相应的编码格式。
import pandas as pd# 从 UTF-8 编码的 CSV 文件导入数据
data = pd.read_csv('data.csv', encoding='utf-8')
data.head()
encoding 参数支持多种常见的编码格式,包括但不限于:
# 使用 UTF-8 编码导入 CSV 文件
data_utf8 = pd.read_csv('data.csv', encoding='utf-8')# 使用 GBK 编码导入 CSV 文件
data_gbk = pd.read_csv('data.csv', encoding='gbk')# 使用 UTF-16 编码导入 CSV 文件
data_utf16 = pd.read_csv('data.csv', encoding='utf-16')# 使用 ASCII 编码导入 CSV 文件
data_ascii = pd.read_csv('data.csv', encoding='ascii')# 使用 ISO-8859-1 编码导入 CSV 文件
data_iso = pd.read_csv('data.csv', encoding='iso-8859-1')# 使用 GB2312 编码导入 CSV 文件
data_gb2312 = pd.read_csv('data.csv', encoding='gb2312')
添加列标题
当导入 CSV 文件时,如果文件本身没有列标题,可以通过names参数来为DataFrame添加列标题。下面是一个示例:
import pandas as pd# 从 UTF-8 编码的 CSV 文件导入数据
data = pd.read_csv('data.csv', encoding='utf-8',names=["user_id","name","sex"])
data.head()
在这个示例中,"data.csv"是你要导入的CSV文件的路径。names参数用于指定要为DataFrame添加的列标题,每个标题对应CSV文件中的一列。
Excel 文件:
import pandas as pd# 从 Excel 文件导入数据
data_excel = pd.read_excel('data.xlsx')
data_excel.head()
JSON 文件:
import pandas as pd# 从 JSON 文件导入数据
data_json = pd.read_json('data.json')
data_json.head()
数据库:
Pandas 可以与 SQLAlchemy 集成,通过 SQLAlchemy 来连接数据库并执行查询操作,然后将查询结果转换为 Pandas DataFrame。这样就可以利用 Pandas 提供的丰富功能来进一步处理和分析数据库中的数据。
下面是一个示例代码,演示如何使用 SQLAlchemy 和 Pandas 从 MySQL 数据库中读取数据到 DataFrame:
import pandas as pd
from sqlalchemy import create_engine# 创建 SQLAlchemy 引擎
engine = create_engine('mysql+mysqlconnector://username:password@host:port/database')# 构建 SQL 查询语句
query = "SELECT * FROM your_table"# 使用 Pandas 的 read_sql 函数执行查询并导入数据到 DataFrame
data = pd.read_sql(query, engine)# 显示 DataFrame 的前几行数据
data.head()# 关闭数据库连接
engine.dispose()
HTML 表格:
import pandas as pd# 从 HTML 文件或网页中提取表格数据
data_html = pd.read_html('data.html')[0]
data_html.head()
Clipboard:
import pandas as pd# 从剪贴板导入数据
data_clipboard = pd.read_clipboard()
data_clipboard.head()
HDF5 文件:
import pandas as pd# 从 HDF5 文件中导入数据
data_hdf5 = pd.read_hdf('data.h5')
data_hdf5.head()
Feather 文件:
import pandas as pd# 从 Feather 文件中导入数据
data_feather = pd.read_feather('data.feather')
data_feather.head()
Parquet 文件:
import pandas as pd# 从 Parquet 文件中导入数据
data_parquet = pd.read_parquet('data.parquet')
data_parquet.head()
Msgpack 文件:
import pandas as pd# 从 Msgpack 文件中导入数据
data_msgpack = pd.read_msgpack('data.msg')
data_msgpack.head()
数据导出示例
好的,让我为你演示每种导出方法的使用。
CSV 文件:
import pandas as pd# 导出数据到 CSV 文件
data.to_csv('exported_data.csv', index=False)
index=False表示不将 DataFrame 的索引写入到导出的 CSV 文件中。
如果你想将输入数据直接导入到 CSV 文件中,而不需要添加列标题,你可以使用 Pandas 的 to_csv 方法,并将参数 header 设置为 False。这样就不会在导出的 CSV 文件中包含列标题。
data.to_csv('exported_data.csv', header=False, index=False)
Excel 文件:
import pandas as pd# 导出数据到 Excel 文件
data.to_excel('exported_data.xlsx', index=False)
JSON 文件:
import pandas as pd# 导出数据到 JSON 文件
data.to_json('exported_data.json')
数据库:
使用 Pandas 和 SQLAlchemy 将数据从 DataFrame 导出到数据库。
import pandas as pd
from sqlalchemy import create_engine# 创建一个示例 DataFrame
df = pd.DataFrame({'name': ['Alice', 'Bob', 'Charlie'],'age': [25, 30, 35],'city': ['New York', 'Los Angeles', 'Chicago']
})# 创建 SQLAlchemy 引擎
# 注意:请将 username, password, host, port, database 替换为你的数据库信息
engine = create_engine('mysql+mysqlconnector://username:password@host:port/database')# 将数据写入到名为 'people' 的新 SQL 表中
# 如果表已经存在,可以通过设置 if_exists 参数来替换或追加数据
df.to_sql('people', engine, if_exists='replace', index=False)# 关闭引擎
engine.dispose()
'people':目标数据库表的名称。engine:SQLAlchemy 数据库引擎。if_exists:'replace'表示如果目标表已经存在,则会先删除原表,然后再创建新表并写入数据。'append'表示向表中追加数据。'fail'表示如果表已存在则引发错误。
index:是否将 DataFrame 的索引作为一列写入 SQL 表。设置为False表示不将索引写入数据库表中,通常在导出数据时,我们不需要保留 DataFrame 的索引,所以将其设置为 False。
HTML 表格:
import pandas as pd# 导出数据为 HTML 表格格式
html_table = data.to_html('exported_data.html', index=False)
Clipboard:
import pandas as pd# 将数据复制到剪贴板
data.to_clipboard(index=False)
HDF5 文件:
import pandas as pd# 导出数据到 HDF5 文件
data.to_hdf('exported_data.h5', key='data', mode='w')
Feather 文件:
import pandas as pd# 导出数据到 Feather 文件
data.to_feather('exported_data.feather')
Parquet 文件:
import pandas as pd# 导出数据到 Parquet 文件
data.to_parquet('exported_data.parquet', index=False)
Msgpack 文件:
import pandas as pd# 导出数据到 Msgpack 文件
data.to_msgpack('exported_data.msg')
总结
本教程介绍了 Pandas 中数据导入和导出的基本操作。通过学习这些技巧,你可以更轻松地处理各种数据格式,并且能够应对实际数据处理和分析中的挑战。
相关文章:

python之pandas数据导入和导出
目录 Pandas 常用数据导入Pandas 常用数据导出数据导入示例CSV 文件:指定导入文件的编码格式添加列标题 Excel 文件:JSON 文件:数据库:HTML 表格:Clipboard:HDF5 文件:Feather 文件:…...
Docker 集成 redis,并在nacos进行配置时需要注意点
安装redis镜像 docker pull redis:6.0.6redis配置文件 创建相关配置文件 mkdir /apps/redis cd /apps/redis touch redis.conf vim redis.confredis.conf内容: #开启保护 protected-mode yes #开启远程连接 bind 0.0.0.0 #自定义密码 port 6379 timeout 0 # 900s内…...

数据库系统工程师考试大纲
数据库系统工程师考试大纲主要包括以下几个方面的考试要求: 1.掌握计算机体系结构以及各主要部件的性能和基本工作原理。 2.掌握操作系统、程序设计语言的基础知识,了解编译程序的基本概念。 3.熟练掌握常用数据结构和常用算法。 4.熟悉软件工程和软件开…...

(Java)数据结构——图(第七节)Folyd实现多源最短路径
前言 本博客是博主用于复习数据结构以及算法的博客,如果疏忽出现错误,还望各位指正。 Folyd实现原理 中心点的概念 感觉像是充当一个桥梁的作用 还是这个图 我们常在一些讲解视频中看到,就比如dist(-1)࿰…...

使用Python进行高效的多线程HTTP请求
在处理网络请求时,尤其是当需要大量请求相同或不同的URL时,采用多线程的方式可以显著提高效率。本文介绍了如何使用Python的concurrent.futures模块实现多线程HTTP请求。 为什么使用多线程? 多线程可以让CPU和网络资源得到更有效的利用。在…...

如何利用OceanBase v4.2的 外部表简化外部数据处理
为什么需要使用外表 在日常的业务场景中,经常遇到需要在数据库中处理外部数据的情况,这些数据可能来源于应用程序,或者是其他业务系统。一般来说,常是通过ETL工具将外部数据库的数据导入到数据库内部的表中,再进行分析…...
【灵境矩阵】零代码创建AI智能体之行业词句助手
欢迎来到《小5讲堂》 这是《灵境矩阵》系列文章,每篇文章将以博主理解的角度展开讲解。 温馨提示:博主能力有限,理解水平有限,若有不对之处望指正! 目录 创建智能体选择创建方式零代码 基础配置头像名称简介指令开场白…...

springboot 防抖操作
大佬的代码:看这里 原理: 通过aop切面编程,在调用接口前缓存接口信息,将信息缓存到redis中,在规定时间内重复调用接口,会被拦截请求 有个地方感觉不太合理,在使用中我将其修改了 //前略 publi…...

Playwright录制脚本 —— web自动化测试!
简介: 在编写 web 自动化测试用例时,代码编写的速度是否快,会影响框架的使用体验。现在很多的框架都会提供一些辅助功能,帮助我们更快的去编写自动化测试代码,而录制功能是几乎所有的web自动化工具都会带的功能。在实际…...

什么是工业级物联网智能网关?如何远程控制PLC?
在数字化浪潮席卷全球的今天,工业物联网(IIoT)已经成为推动工业转型升级的关键力量。而在工业物联网的大家庭中,工业级物联网智能网关扮演着举足轻重的角色。那么,究竟什么是工业级物联网智能网关?又该如何…...
:2024.04.05-2024.04.10)
AI推介-大语言模型LLMs论文速览(arXiv方向):2024.04.05-2024.04.10
文章目录~ 1.Learn from Failure: Fine-Tuning LLMs with Trial-and-Error Data for Intuitionistic Propositional Logic Proving2.Continuous Language Model Interpolation for Dynamic and Controllable Text Generation3.Event Grounded Criminal Court View Generation w…...
、apply()、bind()的区别和使用)
javascript:call()、apply()、bind()的区别和使用
javascript:call()、apply()、bind()的区别和使用 1 前言 记录javascript的call、apply、bind方法绑定this的区别以及使用。 call、apply、bind的区别: 【相同点】:作用相同,都是动态修改this指向;都不会修改原先函…...

ubuntu系统安装systemc-2.3.4流程
背景:systemC编程在linux下的基础环境配置 1,下载安装包,并解压 (先下载了最新的3.0.0,安装时候显示sc_cmnhdr.h:115:5: error: #error **** SystemC requires a C compiler version of at least C17 **** ÿ…...

Java开发中的entity、vo和pojo
Java开发中的entity、vo和pojo 1.Entity实体2.vo3.pojo 1.Entity实体 定义: Entity 通常指的是与数据库表对应的对象。它包含了与数据库表字段相对应的属性和一些业务逻辑方法。Entity 通常用于数据的持久化操作,如增删改查。使用场景: 当需…...

通过IPV6+DDNS实现路由器远程管理和Win远程桌面控制
前期需要的准备: 软路由,什么系统都可以,要支持IPV6,能够自动添加解析 光猫的管理员账号,能够进入光猫修改配置,拨号上网账号 域名账号和DNS服务 主要步骤: 利用管理员账号,进入…...

数据湖/数据仓库
数据湖(Data Lake)和数据仓库(Data Warehouse)的主要区别在于它们的目的、存储的数据类型、数据处理方式、数据结构、数据安全性以及数据应用。以下是相关介绍: 目的。数据湖旨在作为一个集中的存储库,存储…...

万兆以太网MAC设计(2)MAC_RX模块
文章目录 前言一、模块功能二、代码三、仿真波形 前言 上文我们打通了了万兆以太网物理层和数据链路层,其实就是会使用IP核了,本文将正式开始MAC层设计第一篇,接收端设计。 一、模块功能 MAC_RX模块功能如下: 解析接收的报文&…...
D. Solve The Maze Codeforces Round 648 (Div. 2)
题目链接: Problem - 1365D - CodeforcesCodeforces. Programming competitions and contests, programming communityhttps://codeforces.com/problemset/problem/1365/D 题目大意: 有一张地图n行m列(地图外面全是墙),…...
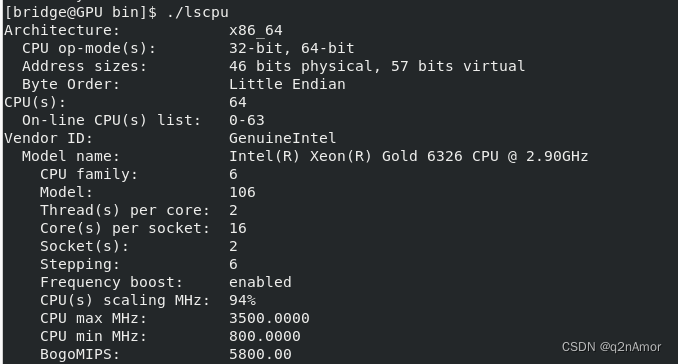
CPU核心数、线程数都是什么意思?
最早,每个物理 cpu 上只有一个核心,对操作系统而言,也就是同一时刻只能运行一个进程/线程。 为了提高性能,cpu 厂商开始在单个物理 cpu 上增加核心(实实在在的硬件存在),也就出现了多核 cpu&…...

每日一篇 4.12
misstep:失误 epic proportions.:史无前例 arguably:按理来说 assembly:组装 performed :执行 underpins:支撑 holds a monopoly:垄断了 shipped:发货 a market capitalizati…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...

【电力电子】基于STM32F103C8T6单片机双极性SPWM逆变(硬件篇)
本项目是基于 STM32F103C8T6 微控制器的 SPWM(正弦脉宽调制)电源模块,能够生成可调频率和幅值的正弦波交流电源输出。该项目适用于逆变器、UPS电源、变频器等应用场景。 供电电源 输入电压采集 上图为本设计的电源电路,图中 D1 为二极管, 其目的是防止正负极电源反接, …...

MySQL 8.0 事务全面讲解
以下是一个结合两次回答的 MySQL 8.0 事务全面讲解,涵盖了事务的核心概念、操作示例、失败回滚、隔离级别、事务性 DDL 和 XA 事务等内容,并修正了查看隔离级别的命令。 MySQL 8.0 事务全面讲解 一、事务的核心概念(ACID) 事务是…...

【Android】Android 开发 ADB 常用指令
查看当前连接的设备 adb devices 连接设备 adb connect 设备IP 断开已连接的设备 adb disconnect 设备IP 安装应用 adb install 安装包的路径 卸载应用 adb uninstall 应用包名 查看已安装的应用包名 adb shell pm list packages 查看已安装的第三方应用包名 adb shell pm list…...