Hello 算法10:搜索
https://www.hello-algo.com/chapter_searching/binary_search/
二分查找法
给定一个长度为 n的数组 nums ,元素按从小到大的顺序排列,数组不包含重复元素。请查找并返回元素 target 在该数组中的索引。若数组不包含该元素,则返回 -1 。
# 首先初始化 i=0,j=n-1, 代表搜索区间是[0,n-1]
# 然后,循环执行以下2个步骤
# 1:m = (i+j)/2 ,向下取整,求出搜索区间的中间点
# 2:判断nums[m]和target的大小关系,有以下三种情况:
# a:nums[m] > target,说明目标在区间[i,m-1],所以让j = m - 1
# b: nums[m] < target,说明目标在区间[m+1,j],所以让i = m + 1
# c:说明已经找到目标值,因此返回索引m
代码如下:
def binary_search(nums: list[int], target: int):i, j = 0, len(nums) - 1while i <= j:m = (i+j) // 2if nums[m] > target:j = m -1elif nums[m] < target:i = m + 1else:return mreturn -1
优点:效率高,无需额外空间
缺点:仅适用于有序数据,仅使用数数组搜索,当数据量较小时,线性查找速度更快。
二分查找插入点
给定一个长度为 n的有序数组 nums 和一个元素 target ,数组不存在重复元素。现将 target 插入到数组 nums 中,并保持其有序性。若数组中已存在元素 target ,则插入到其左方。请返回插入后 target 在数组中的索引。
- 当target存在时,插入的索引就是taget的位置
- 当target不存在时:如果target > nums[m],让i = m +1 ,所以i在靠着大于等于目标的位置移动;反之j在靠着小于等于目标的位置移动,这导致的结果就是,最终i等于第一个比目标大的元素,j指向首个比目标小的元素。
可知,最终返回i即是插入的位置
def binary_search_insertion_simple(nums: list[int], target: int) -> int:"""二分查找插入点(无重复元素)"""i, j = 0, len(nums) - 1 # 初始化双闭区间 [0, n-1]while i <= j:m = (i + j) // 2 # 计算中点索引 mif nums[m] < target:i = m + 1 # target 在区间 [m+1, j] 中elif nums[m] > target:j = m - 1 # target 在区间 [i, m-1] 中else:return m # 找到 target ,返回插入点 m# 未找到 target ,返回插入点 ireturn i
重复值的情况
在上一题的基础上,规定数组可能包含重复元素,其余不变
def binary_search_insertion(nums: list[int], target: int) -> int:"""二分查找插入点(存在重复元素)"""i, j = 0, len(nums) - 1 # 初始化双闭区间 [0, n-1]while i <= j:m = (i + j) // 2 # 计算中点索引 mif nums[m] < target:i = m + 1 # target 在区间 [m+1, j] 中elif nums[m] > target:j = m - 1 # target 在区间 [i, m-1] 中else:j = m - 1 # 首个小于 target 的元素在区间 [i, m-1] 中# 返回插入点 ireturn i
查找左边界
def binary_search_left_edge(nums: list[int], target: int) -> int:"""二分查找最左一个 target"""# 等价于查找 target 的插入点i = binary_search_insertion(nums, target)# 未找到 target ,返回 -1if i == len(nums) or nums[i] != target:return -1# 找到 target ,返回索引 ireturn i
查找右边界
替换在 nums[m] == target 情况下的指针收缩操作即可,接下来介绍一些取巧的办法
-
复用左边界法,使查找目标加一
def binary_search_right_edge(nums: list[int], target: int) -> int:"""二分查找最右一个 target"""# 转化为查找最左一个 target + 1i = binary_search_insertion(nums, target + 1)# j 指向最右一个 target ,i 指向首个大于 target 的元素j = i - 1# 未找到 target ,返回 -1if j == -1 or nums[j] != target:return -1# 找到 target ,返回索引 jreturn j -
转换为查找不存在的元素
当数组不包含目标元素时,最终i和j会分别指向首个大于、小于target的元素:
查找最左侧元素时,可以将目标设置为targe-0.5,最终返回i
查找最右侧元素时,可以将目标设置为target+0.5,最终返回j

哈希优化
在算法题中,通常通过将线性遍历替换为哈希搜索来提升时间复杂度。例如以下题目
给定一个整数数组
nums和一个目标元素target,请在数组中搜索“和”为target的两个元素,并返回它们的数组索引。返回任意一个解即可。
线性遍历
开启一个两层循环,每次判断是否和为目标值。简单粗暴
def two_sum_brute_force(nums: list[int], target: int) -> list[int]:"""方法一:暴力枚举"""# 两层循环,时间复杂度为 O(n^2)n = len(nums)for i in range(n):for j in range(i+1, n):if nums[i] + nums[i] == target:return [i, j]return []
哈希查找
def two_sum_hash_table(nums: list[int], target: int) -> list[int]:"""方法二:辅助哈希表"""# 辅助哈希表,空间复杂度为 O(n)dic = {}n = len(nums)for i in range(n):if target - nums[i] not in dic:dic[nums[i]] = ielse:return [dic[target - nums[i]], i]return []
搜索算法总结
搜索算法根据实现方式可以分为以下两类:
- 通过遍历数据结构来定位元素,例如数组、图、树的遍历等
- 利用数据结构的特性,实现高效搜索,例如二分查找、哈希查找
暴力搜索
- 线性搜索,适用于数组、链表
- 广度优先和深度优先搜索,适用于图、树
优点是通用性好,容易理解,不需要对数据结构做预期处理;不需要额外空间。
缺点是此类算法的时间复杂度为O(n),因此在元素较多时效率较低
自适应搜索
自适应搜索利用数据结构的特性来优化搜索
- 二分查找,利用有序性来进行搜索,仅适用于数组
- 哈希查找,利用哈希表将搜索数据和目标数据建立键值对映射,从而实现查询操作
- 树查找
效率高,可达到o(logn)甚至o(1)
缺点:需要对数据进行预处理,需要额外空间
搜索方法选取

表 10-1 查找算法效率对比
| 线性搜索 | 二分查找 | 树查找 | 哈希查找 | |
|---|---|---|---|---|
| 查找元素 | O(n) | O(logn) | O(logn) | O(1) |
| 插入元素 | O(1) | O(n) | O(logn) | O(1) |
| 删除元素 | O(n) | O(n) | O(logn) | O(1) |
| 额外空间 | O(1) | O(1) | O(logn) | O(n) |
| 数据预处理 | / | 排序 O(nlogn) | 建树 O(nlogn) | 建哈希表 O(n) |
| 数据是否有序 | 无序 | 有序 | 有序 | 无序 |
搜索算法的选择还取决于数据体量、搜索性能要求、数据查询与更新频率等。
相关文章:
Hello 算法10:搜索
https://www.hello-algo.com/chapter_searching/binary_search/ 二分查找法 给定一个长度为 n的数组 nums ,元素按从小到大的顺序排列,数组不包含重复元素。请查找并返回元素 target 在该数组中的索引。若数组不包含该元素,则返回 -1 。 # 首…...

常见分类算法详解
在机器学习和数据科学的广阔领域中,分类算法是至关重要的一环。它广泛应用于各种场景,如垃圾邮件检测、图像识别、情感分析等。本文将深入剖析几种常见的分类算法,帮助读者理解其原理、优缺点以及应用场景。 一、K近邻算法(K-Nea…...

推送恶意软件的恶意 PowerShell 脚本看起来是人工智能编写的
威胁行为者正在使用 PowerShell 脚本,该脚本可能是在 OpenAI 的 ChatGPT、Google 的 Gemini 或 Microsoft 的 CoPilot 等人工智能系统的帮助下创建的。 攻击者在 3 月份的一次电子邮件活动中使用了该脚本,该活动针对德国的数十个组织来传播 Rhadamanthy…...

微服务之Consul 注册中心介绍以及搭建
一、微服务概述 1.1单体架构 单体架构(monolithic structure):顾名思义,整个项目中所有功能模块都在一个工程中开发;项目部署时需要对所有模块一起编译、打包;项目的架构设计、开发模式都非常简单。 当项…...

MES生产管理系统:私有云、公有云与本地化部署的比较分析
随着信息技术的迅猛发展,云计算作为一种新兴的技术服务模式,已经深入渗透到企业的日常运营中。在众多部署方式中,私有云、公有云和本地化部署是三种最为常见的选择。它们各自具有独特的特点和适用场景,并在不同程度上影响着企业的…...

【core analyzer】core analyzer的介绍和安装详情
目录 🌞1. core和core analyzer的基本概念 🌼1.1 coredump文件 🌼1.2 core analyzer 🌞2. core analyzer的安装详细过程 🌼2.1 方式一 简单但不推荐 🌼2.2 方式二 推荐 🌻2.2.1 安装遇到…...

个人练习之-jenkins
虚拟机环境搭建(买不起服务器 like me) 重点: 0 虚拟机防火墙关闭 systemctl stop firewalld.service systemctl disable firewalld.service 1 (centos7.6)网络配置 (vmware 编辑 -> 虚拟网络编辑器 -> 选择NAT模式 ->NAT设置查看网关) vim /etc/sysconfig/network-sc…...
初探vercel托管项目
文章目录 第一步、注册与登录第二步、本地部署 在个人网站部署的助手vercel,支持 Github部署,只需简单操作,即可发布,方便快捷! 第一步、注册与登录 进入vercel【官网】,在右上角 login on,可登…...
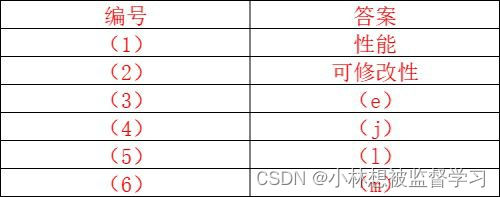
软考 - 系统架构设计师 - 质量属性例题 (2)
问题1: 、 问题 2: 系统架构风险:指架构设计中 ,潜在的,存在问题的架构决策所带来的隐患。 敏感点:指为了实现某个质量属性,一个或多个构件所具有的特性 权衡点:指影响多个质量属性…...

基于Python豆瓣电影数据可视化分析系统的设计与实现
大数据可视化项目——基于Python豆瓣电影数据可视化分析系统的设计与实现 2024最新项目 项目介绍 本项目旨在通过对豆瓣电影数据进行综合分析与可视化展示,构建一个基于Python的大数据可视化系统。通过数据爬取收集、清洗、分析豆瓣电影数据,我们提供了…...
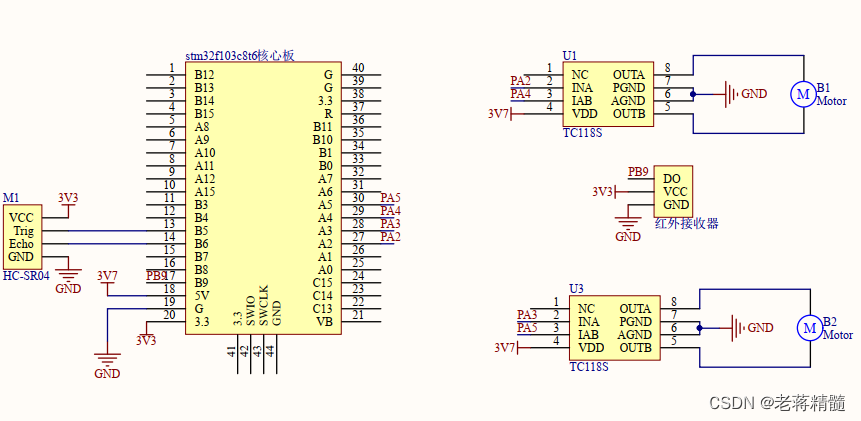
【已开源】基于stm32f103的爬墙小车
基于stm32f103的遥控器无线控制爬墙小车,实现功能为可平衡在竖直墙面上,并进行移动和转向,具有超声波防撞功能。 直接上: 演示视频如:哔哩哔哩】 https://b23.tv/BzVTymO 项目说明: 在这个项目中&…...

PCL 基于马氏距离KMeans点云聚类
文章目录 一、简介二、算法步骤三、代码实现四、实现效果参考资料一、简介 在诸多的聚类方法中,K-Means聚类方法是属于“基于原型的聚类”(也称为原型聚类)的方法,此类方法均是假设聚类结构能通过一组原型刻画,在现实聚类中极为常用。通常情况下,该类算法会先对原型进行初始…...
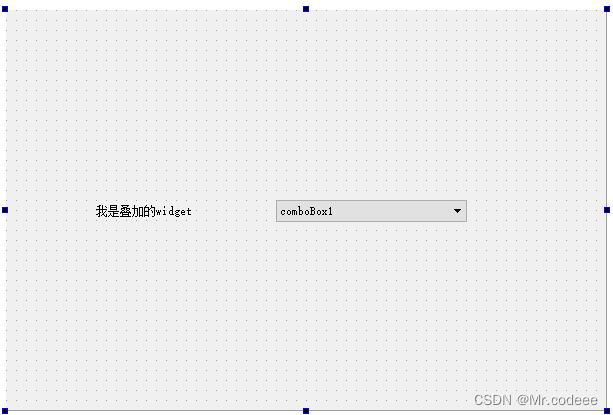
libVLC 视频窗口上叠加透明窗口
很多时候,我们需要在界面上画一些三角形、文字等之类的东西,我们之需要重写paintEvent方法,比如像这样 void Widget::paintEvent(QPaintEvent *event) 以下就是重写的代码。 void Widget::paintEvent(QPaintEvent *event) {//创建QPainte…...
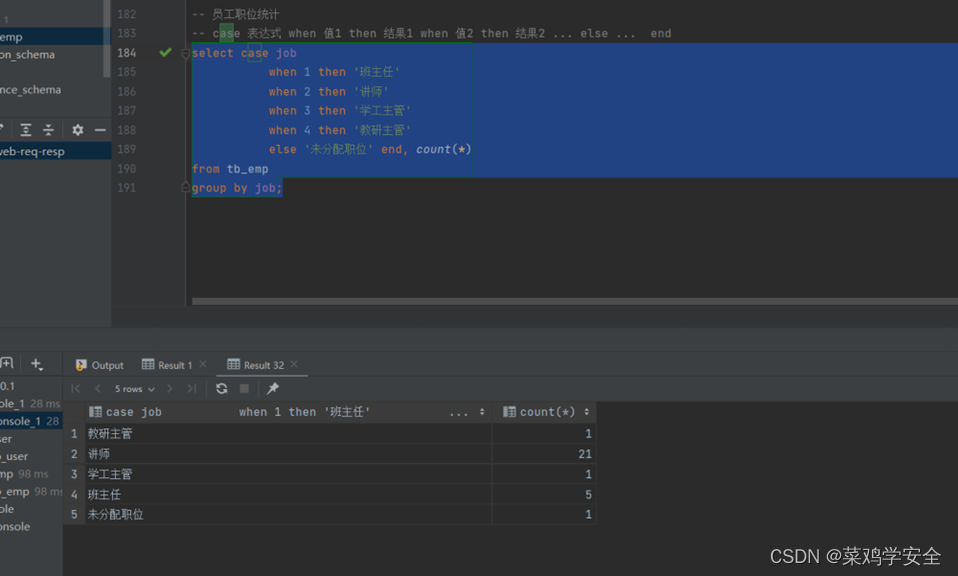
MySQL基础入门上篇
MySQL基础 介绍 mysql -uroot -p -h127.0.0.1 -P3306项目设计 具备数据库一定的设计能力和操作数据的能力。 数据库设计DDL 定义 操作 显示所有数据库 show databases;创建数据库 create database db02;数据库名唯一,不能重复。 查询是否创建成功 加入一些…...

Docker搭建FFmpeg
FFmpeg 是一套可以用来记录、转换数字音频、视频,并能将其转化为流的完整解决方案。FFmpeg 包含了领先的音视频编解码库libavcodec,可以用于各种视频格式的转换。 应用场景包括: 视频转换:把视频从一种格式转换成另一种格式。视…...

Hudi-ubuntu环境搭建
hudi-ubuntu环境搭建 运行 1.编译Hudi #1.把maven安装包上传到服务器 # 官网下载安装包 https://archive.apache.org/dist/maven/maven-3/ scp -r D:\Users\zh\Desktop\Hudi\compressedPackage\apache-maven-3.6.3-bin.tar.gz zhangheng10.8.4.212:/home/zhangheng/hudi/com…...

Hive进阶Day05
一、HDFS分布式文件存储系统 1-1 HDFS的存储机制 按块(block)存储 hdfs在对文件数据进行存储时,默认是按照128M(包含)大小进行文件数据拆分,将不同拆分的块数据存储在不同datanode服务器上 拆分后的块数据会被分别存储在不同的服…...
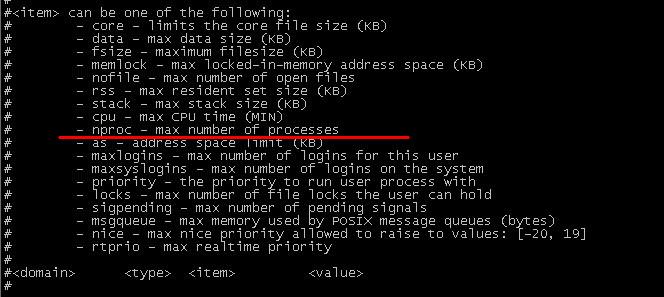
ssh爆破服务器的ip-疑似肉鸡
最近发现自己的ssh一直有一些人企图使用ssh暴力破解的方式进行密码破解.就查看了一下,真是网络安全太可怕了. 大家自己的服务器密码还是要设置好,管好,做好最基本的安全措施,不然最后只能沦为肉鸡. ssh登陆日志可以在/var/log下看到,ubuntu的话为auth.log,centos为secure文件 查…...

4.JVM八股
JVM空间划分 线程共享和线程私有 1.7: 线程共享: 堆、方法区 线程私有: 虚拟机栈、本地方法栈、程序计数器 本地内存 1.8: 线程共享: 堆 线程私有: 老三样 本地内存,元空间 程序计数器 …...
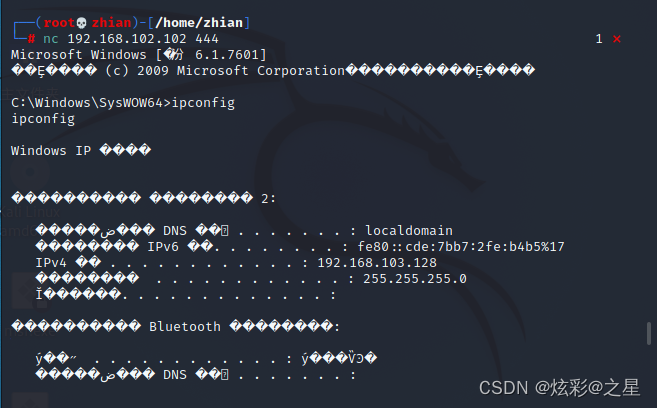
内网渗透系列-mimikatz的使用以及后门植入
内网渗透系列-mimikatz的使用以及后门植入 文章目录 内网渗透系列-mimikatz的使用以及后门植入前言mimikatz的使用后门植入 msf永久后门植入 (1)Meterpreter后门:Metsvc(2)Meterpreter后门:Persistence NC后…...

智能排障:借助快马AI构建Vivado安装问题自动诊断与修复助手
作为一名FPGA开发者,Vivado安装过程中的各种报错简直是家常便饭。每次遇到新问题都要花大量时间搜索解决方案,效率实在太低。最近尝试用InsCode(快马)平台的AI能力搭建了一个智能诊断工具,效果出乎意料的好,分享下具体实现思路。 …...

Charticulator:重构数据可视化创作范式的技术革命
Charticulator:重构数据可视化创作范式的技术革命 【免费下载链接】charticulator Interactive Layout-Aware Construction of Bespoke Charts 项目地址: https://gitcode.com/gh_mirrors/ch/charticulator 数据可视化正面临前所未有的创作困境——当业务需求…...

高并发场景下的FUTURE POLICE服务架构设计
高并发场景下的FUTURE POLICE服务架构设计 最近和几个做智能语音项目的朋友聊天,大家普遍遇到一个头疼的问题:模型效果不错,但用户一多,服务就卡顿甚至崩溃。特别是像FUTURE POLICE这类语音合成模型,生成一段高质量的…...

终极指南:如何用Fara-7B实现智能电脑自动操作
终极指南:如何用Fara-7B实现智能电脑自动操作 【免费下载链接】fara Fara-7B: An Efficient Agentic Model for Computer Use 项目地址: https://gitcode.com/gh_mirrors/fara/fara Fara-7B是微软推出的首个专门为电脑自动操作设计的7B参数智能代理模型&…...
)
CTF选手必看:RSA算法从数学原理到实战解题技巧(附常见题型解析)
CTF选手必看:RSA算法从数学原理到实战解题技巧(附常见题型解析) 1. RSA算法核心数学原理 RSA算法的安全性建立在大整数分解难题和欧拉定理之上。理解以下数学概念是解题基础: 欧拉函数φ(n):对于npq(p、q为…...
)
避开这些坑!Anthropic Computer Use在Mac上的安全使用指南(含Streamlit界面优化技巧)
避开这些坑!Anthropic Computer Use在Mac上的安全使用指南(含Streamlit界面优化技巧) 在Mac上探索AI工具的边界时,Anthropic Computer Use无疑是一把双刃剑。它既能让你通过自然语言指令操控整个系统,也可能因权限过高…...

高效批量OCR处理实战指南:提升图片文字提取效率的完整方案
高效批量OCR处理实战指南:提升图片文字提取效率的完整方案 【免费下载链接】Umi-OCR Umi-OCR: 这是一个免费、开源、可批量处理的离线OCR软件,适用于Windows系统,支持截图OCR、批量OCR、二维码识别等功能。 项目地址: https://gitcode.com/…...
揭秘Demucs:音频分离背后的跨域Transformer技术革命
揭秘Demucs:音频分离背后的跨域Transformer技术革命 【免费下载链接】demucs Code for the paper Hybrid Spectrogram and Waveform Source Separation 项目地址: https://gitcode.com/gh_mirrors/de/demucs 在音频处理的广阔领域中,音乐源分离技…...

Qwen2.5-0.5B Instruct在软件测试中的自动化应用
Qwen2.5-0.5B Instruct在软件测试中的自动化应用 1. 引言 软件测试是确保产品质量的关键环节,但传统测试方法往往耗时费力。开发人员需要编写大量测试用例,执行重复的测试流程,还要分析复杂的测试结果。这个过程不仅枯燥,还容易…...

小说作者必备:次元画室快速构建角色设定,灵感秒变草图
小说作者必备:次元画室快速构建角色设定,灵感秒变草图 你是否经常遇到这样的困境:脑海中浮现出一个鲜活的角色形象,却苦于无法用文字准确描述?或者写好了人物设定,却找不到合适的画师将其可视化࿱…...