Scrapy框架 进阶
- Scrapy框架基础
- Scrapy框架进阶
【五】持久化存储
- 命令行:json、csv等
- 管道:什么数据类型都可以
【1】命令行简单存储
(1)语法
- Json格式
scrapy crawl 自定义爬虫程序文件名 -o 文件名.json
- CSV格式
scrapy crawl 自定义爬虫程序文件名 -o 文件名.csv -t csv
(2)示例
- 重点是parse函数需要返回保存的数据
# 假设从浏览器拿到了想保存的数据文件
def parse(self, response):items = []for i in range(5):item[f"name{i}"] = f"value{i}"items.append(item)return items
- 保存为json格式文件
scrapy crawl test -o output.json# output.json
[
{"name0": "value{0}"},
{"name1": "value{1}"},
{"name2": "value{2}"},
{"name3": "value{3}"},
{"name4": "value{4}"}
]
【2】管道存储
- 保存在数据库mysql中
- 保存在本地txt文件中
(1)第一步:从前端处理数据并返回
- 这里假设数据是从response中分析出来的
- 注意item要放在循环中
- 注意item要放在循环中
- 注意item要放在循环中
import scrapy
from ..items import ScrapyTestItemclass TestSpider(scrapy.Spider):name = "test"allowed_domains = ["www.test.com"]start_urls = ["https://www.test.com/"]def parse(self, response):for i in range(5):item = ScrapyTestItem()item['name'] = f"bruce{i}"item['avatar'] = f"avatar img src{i}"item['introduce'] = f"long long introduce{i}"yield item
(2)第一步:创建管道数据模型
- 需要在items.py文件中创建一个类
- 类似于Django的模型表
- 这个简单,无论是什么类型字段都是scrapy.Field()
import scrapy
class ScrapyTestItem(scrapy.Item):name = scrapy.Field()avatar = scrapy.Field()introduce = scrapy.Field()
(3)第二步:定义管道数据处理类
-
在Scrapy中,
parse方法返回的数据(无论是Item对象还是其他数据结构)会被Scrapy引擎自动迭代、自动迭代、自动迭代,并逐个传递给Pipeline的process_item方法。 -
需要在pipline.py文件中创建一个类
- open_spider(self, spider):
- 当爬虫开始时,这里会执行一些初始化操作
- 例如,可以建立数据库连接、打开文件等
- spider参数不能少
- close_spider(self, spider):
- 当爬虫结束时,这里会执行一些清理操作
- 例如,可以关闭数据库连接、关闭文件等
- spider参数不能少
- process_item:
- 每次要保存一个对象时,这个方法会被触发
- 在这里可以对item进行进一步的处理,然后保存到数据库或者文件等
- open_spider(self, spider):
-
创建数据库和表
create database scrapyCREATE TABLE `test` (`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(50) DEFAULT NULL,`avatar` varchar(255) DEFAULT NULL,`introduce` text,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;- 创建数据库处理类
import pymysqlclass ScrapyTestMysqlPipeline:def open_spider(self, spider):self.conn = pymysql.connect(user='root',password='000',host='127.0.0.1',port= 3306,database='scrapy',cursorclass=pymysql.cursors.DictCursor,)self.cursor = self.conn.cursor()def close(self, spider):# 关闭句柄self.cursor.close()# 关闭数据库链接self.conn.close()def process_item(self, item, spider):sql_str = """insert INTOtest(name, avatar, introduce)values(%s, %s, %s);"""self.cursor.execute(sql_str, args=(item.get('name'),item.get('avatar'),item.get('introduce'),))self.conn.commit()return item
- 创建本地文件保存类
class ScrapyTestTxtPipeline:def open_spider(self, spider):self.fp = open('output.txt', 'wt', encoding='utf8')def close_spider(self, spider):self.fp.close()def process_item(self, item, spider):# 已经自动迭代self.fp.write(str(item) + '\n')return item
(4)第四步:配置文件中注册管道类
- Pipline的执行顺序会按照
ITEM_PIPELINES字典中的定义顺序执行- 数字越小,优先级越高,执行顺序越靠前
- 建议数字范围0-1000,没有强制规定
ITEM_PIPELINES = {"scrapy_test.pipelines.ScrapyTestMysqlPipeline": 100,"scrapy_test.pipelines.ScrapyTestJsonPipeline": 300,
}
(5)最后:启动项目
- 命令行
scrapy crawl test
- py文件
from scrapy.cmdline import execute
execute(['scrapy', 'crawl', 'test'])
【六】中间件
【1】爬虫中间件
# 爬虫中间件
class Day06StartSpiderMiddleware:@classmethoddef from_crawler(cls, crawler):# 这是一个类方法,Scrapy使用它来创建爬虫中间件实例。# 这个方法通常用于连接中间件到Scrapy的信号。# 在这个例子中,它将spider_opened方法连接到spider_opened信号。s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return sdef process_spider_input(self, response, spider):# 这个方法在每次响应通过爬虫中间件并进入爬虫时被调用。# 它允许修改响应或执行其他操作。# 如果不想修改响应,可以返回None;# 如果想阻止响应继续传递给爬虫,可以抛出一个异常。return Nonedef process_spider_output(self, response, result, spider):# 这个方法在爬虫处理完响应并返回结果后被调用。# 它允许处理或修改爬虫的输出。# 必须返回一个包含请求或项目对象的可迭代对象。# 在这个例子中,它只是简单地返回了原始结果。for i in result:yield idef process_spider_exception(self, response, exception, spider):# 当爬虫或其他爬虫中间件中的process_spider_input方法抛出异常时,这个方法会被调用。# 它允许处理异常,例如记录错误或生成新的请求。# 可以返回None或包含请求或项目对象的可迭代对象。# 在这个例子中,这个方法没有做任何事情。passdef process_start_requests(self, start_requests, spider):# 这个方法在爬虫的起始请求被发送之前被调用。# 它与process_spider_output方法类似,# 但不同之处在于它不与特定的响应相关联。# 必须只返回请求(而不是项目)。# 在这个例子中,它只是简单地返回了原始的起始请求。# Must return only requests (not items).for r in start_requests:yield rdef spider_opened(self, spider):# 这是一个当爬虫被打开时由Scrapy信号触发的方法。# 在这个例子中,它使用爬虫的日志记录器记录一条信息,说明哪个爬虫被打开了。spider.logger.info("Spider opened: %s" % spider.name)【2】下载中间件
class ScrapyTestDownloaderMiddleware:# Not all methods need to be defined. If a method is not defined,# scrapy acts as if the downloader middleware does not modify the# passed objects.@classmethoddef from_crawler(cls, crawler):# 这个类方法由Scrapy调用,用于创建下载器中间件实例。# 在这个方法中,可以连接中间件到Scrapy的信号,# 例如连接spider_opened信号到spider_opened方法。s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)return sdef process_request(self, request, spider):# 当每个请求通过下载器中间件时,这个方法会被调用。# 可以在这个方法中修改请求,或者返回一个新的请求或响应对象。# 如果返回None,则请求会继续被处理。# 如果返回Request对象,Scrapy会停止处理当前的请求,并开始处理新的请求。# 如果返回Response对象,Scrapy将不会发送请求,而是直接将该响应传递给process_response方法。# 如果抛出IgnoreRequest异常,Scrapy将不会发送请求,并且会调用所有已安装的下载器中间件的process_exception方法。f# installed downloader middleware will be calledreturn Nonedef process_response(self, request, response, spider):# 当下载器返回响应时,这个方法会被调用。# 可以在这里修改响应,或者返回一个新的请求或响应对象。# 如果返回Response对象,该响应将被传递给爬虫。# 如果返回Request对象,Scrapy将停止处理当前的响应,并开始处理新的请求。# 如果抛出IgnoreRequest异常,Scrapy将不会将响应传递给爬虫,并且会调用所有已安装的下载器中间件的process_exception方法。return responsedef process_exception(self, request, exception, spider):# 当下载处理器或process_request方法(来自其他下载器中间件)抛出异常时,这个方法会被调用。# 可以在这里处理异常,例如记录错误、返回一个新的请求或响应对象,或者简单地忽略异常。# 如果返回None,异常会继续被处理。# 如果返回Response或Request对象,Scrapy将停止处理当前的异常,并继续处理返回的响应或请求。passdef spider_opened(self, spider):# 当爬虫被打开时,这个方法会被Scrapy的信号机制调用。# 可以在这里执行一些初始化的工作,或者记录关于哪个爬虫被打开的信息。spider.logger.info("Spider opened: %s" % spider.name)【3】配置文件中注册
SPIDER_MIDDLEWARES = {"scrapy_test.middlewares.ScrapyTestSpiderMiddleware": 543,
}DOWNLOADER_MIDDLEWARES = {"scrapy_test.middlewares.ScrapyTestDownloaderMiddleware": 543,
}
【4】下载中间件案例–修改请求头
class ScrapyTestDownloaderMiddleware:# 从代理池中获取可用代理@staticmethoddef get_proxy(flag):if flag:res = requests.get('http://代理池地址/get/?type=https').json()return "https://" + res.get('proxy')else:res = requests.get('http://代理池地址/get/').json()return "http://" + res.get('proxy')def process_request(self, request, spider):# 自定义代理,根据request.url判断是https还是httpflag = 'https' in request.urlproxy_url = self.get_proxy(flag)if proxy_url:request.meta['proxy'] = proxy_urlprint(f"Using proxy: {proxy_url}")# 添加指定cookierequest.cookies['name'] = 'value'# 或cookies字符串request.headers['Cookie'] = 'name=value; anothername=anothervalue'# 添加源页面地址request.headers['referer'] = 'https://example.com'# 添加随机UA验证from fake_useragent import UserAgentrequest.headers['User-Agent'] = str(UserAgent().random)return Nonedef process_exception(self, request, exception, spider):# 处理由于代理问题引发的异常print(f'下载中间异常: {exception}')# 这里可以添加逻辑来重试请求或更换代理return None
【八】CrawlSpider
【1】介绍
(1)简介
- CrawlSpider是Spider的一个派生类,它继承自Spider类,并在此基础上增加了新的属性和方法。
- 这意味着CrawlSpider拥有Spider的所有功能和特性,并具备一些额外的独特功能。
(2)作用
- 自动跟踪链接:
- CrawlSpider能够自动解析页面中的链接,并根据设定的规则跳转到其他页面,以便爬取整个网站的所有页面。
- 这使得CrawlSpider在处理大型网站或需要深度爬取的场景时非常有效。
- 数据提取规则:
- CrawlSpider提供了一种方便的方式来定义如何从页面中提取数据。
- 通过使用基于XPath或CSS选择器的规则,用户可以轻松地提取所需的目标数据。
- 避免重复爬取:
- CrawlSpider会自动管理已经爬取过的链接,从而避免在爬取过程中重复访问同一个页面。
- 这有助于减少不必要的网络请求和提高爬取效率。
(3)特别之处
- 规则定义:
- CrawlSpider通过其特有的属性“rules”来定义爬取规则。
- 这些规则包括链接提取器(LinkExtractor)和回调函数(callback),它们共同决定了如何提取和处理页面上的链接。
- 这使得CrawlSpider在处理具有特定结构和链接模式的网站时更加灵活和高效。
- 链接提取器:
- CrawlSpider中的链接提取器(LinkExtractor)是其特别之处之一。
- 这个提取器可以自动从页面中识别并提取出符合特定模式的链接,从而极大地简化了链接提取的过程。
- 这使得CrawlSpider在处理大型、复杂的网站时具有更高的效率和准确性。
【2】使用
- 方法名不建议使用parse,用其他名字
(1)创建CrawlSpider
- 和普通的spider差不多
- 这里指定使用crawl基础模板
scrapy genspider -t crawl 自定义爬虫程序文件名 目标地址
(2)使用自定义规则
Rule(LinkExtractor(allow=r"地址正则表达式"), callback="回调函数", follow=False)LinkExtractor:用于从响应中(response)中自动根据allow的正则表达式提取链接callback:回调函数的字符串follow:是否从匹配到的链接继续递归提取链接,即只是爬取一页中可以看到的链接,还是继续递归爬取
- 可以使用多条规则,rules是个元组或者列表
rules = (# 多页资源匹配,提取分页链接,但不跟进 Rule(LinkExtractor(allow=r"https://www.example.com/p/\d+"), callback="parse_page", follow=False),# 详情页面链接匹配,提取详情链接,也不跟进Rule(LinkExtractor(allow=r"https://www.example.com/\w+/p/\d+"), callback="parse_detail", follow=False),
)
(3)多页数据,方法传递
yield scrapy.Request(url=detail_url, callback=self.detail_parse, meta={'item': item})- 这个是将详情页的url地址携带数据meta发送给callback回调函数
url:要爬取的网页内容callback:处理爬取url的响应meta:在请求的生命周期中传递数据
import scrapy class MySpider(CrawlSpider): name = 'test' allowed_domains = ["www.example.com"]start_urls = ['https://example.com'] rules = [Rule(LinkExtractor(allow=r"https://www.example.com/sitehome/p/\d+"), callback="parse_page", follow=False),]def parse_page(self, response): # 获得每个需要的divdiv_list = response.xpath('')for div in div_list: # 假设有一个item对象,用于存储数据 item = MyItem() # 保存这里获得的数据item['title'] = div.xpath('').extract()[0]... # 获得详情页地址detail_url = div.xpath('/@herf').extract()[0]# 生成Request对象,并传递item通过meta yield scrapy.Request(url=detail_url, callback=self.parse_detail, meta={'item': item}) def parse_detail(self, response): # 从meta中获取之前传递的item对象 item = response.meta['item'] # 从响应中继续提取信息item['detail'] = response.xpath('h1::text').extract_first() ...# 返回item,准备交给pipeline处理 yield item
【九】集成selenium
【1】介绍
- scrapy默认使用的是requests模块发送请求
- 无法执行js
- 所以需要使用selenium模块
- 根据scrapy框架可知
- 需要修改下载中间件的入口
- 将需要特殊处理的地址发送给selenium
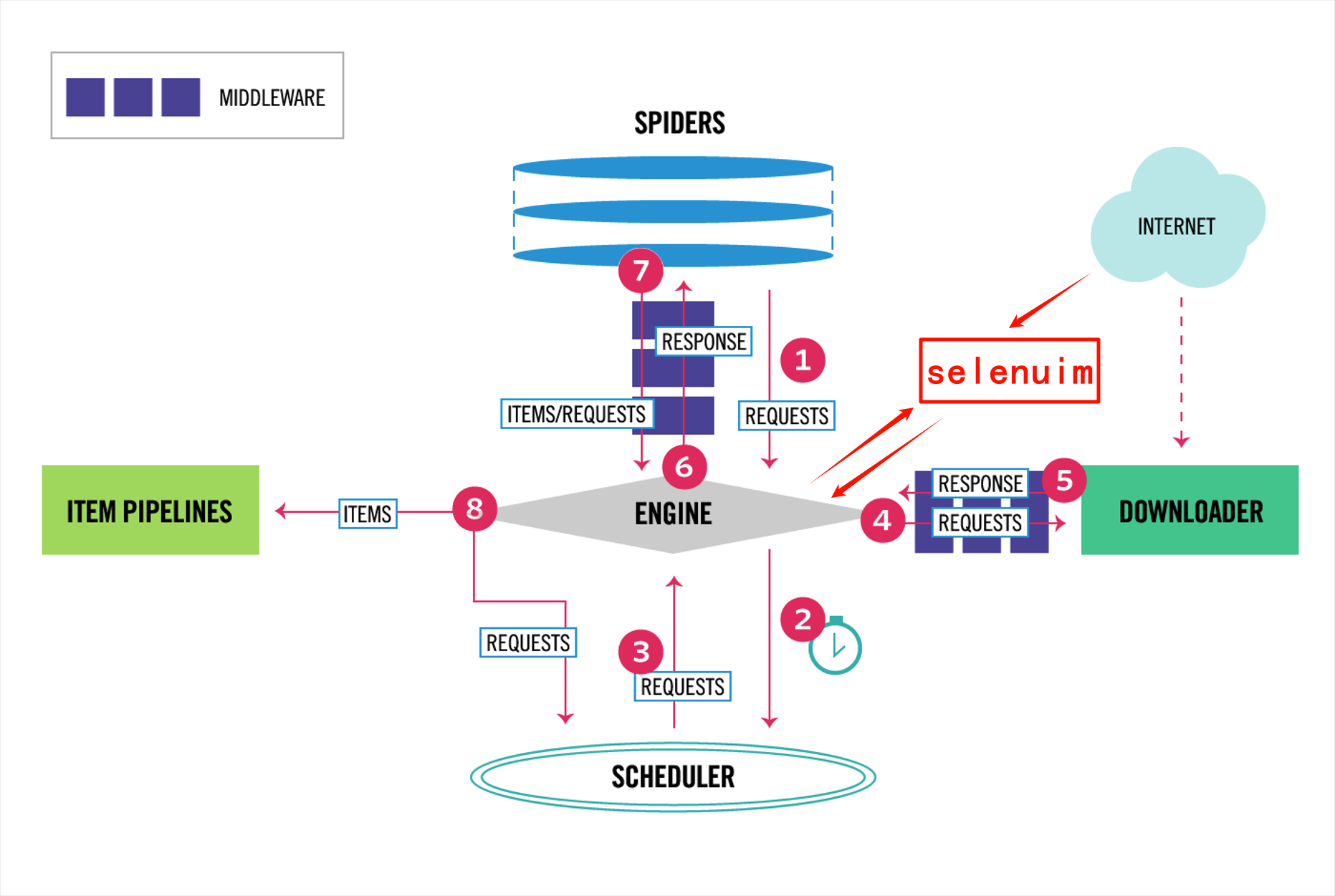
【2】使用方法
-
假设
- 正常请求通过scrapy默认requests获取
- 详情页面需要使用selenium获取
-
如何区分不同的请求
- 根据不同的地址参数,判断是否使用selenium
- 根据request.meta[‘is_selenium’]给定的参数进行判断
- 添加参数:
yield Request(url=url, callback=self.detail_parse, meta={'item': item,'is_selenium':True}) - 获取参数:
request.meta.get('is_selenium')
- 添加参数:
(1)添加自定义的selenium中间件
from scrapy import signalsclass SeleniumMiddleWare:def __init__(self):from selenium import webdriverfrom selenium.webdriver.edge.service import Servicebrowser_path = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'msedgedriver.exe')self.browser = webdriver.Edge(service=Service(browser_path), options=self.make_options())self.browser.implicitly_wait(10)@classmethoddef from_crawler(cls, crawler):s = cls()crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)crawler.signals.connect(s.spider_closed, signal=signals.spider_closed)return s@staticmethoddef make_options():from selenium.webdriver.edge.options import Optionsoptions = Options()options.add_argument("window-size=1920x1080")# options.add_argument('--headless')options.add_argument('--disable-gpu')options.add_experimental_option("excludeSwitches", ["enable-automation"])options.add_experimental_option('useAutomationExtension', False)return optionsdef spider_opened(self, spider):spider.logger.info("Browser Opened")# 将浏览器实例绑定到spider上,方便process_request使用spider.browser = self.browserdef spider_closed(self, spider):spider.logger.info("Browser Closed")spider.browser.quit()def process_request(self, request, spider):# 根据标志判断是否使用selenium# if request.meta.get('is_selenium'):# 根据地址区分是否使用seleniumif 'article' not in request.url:spider.logger.info(f"Using Selenium for Url: {request.url}")spider.browser.get(request.url)from scrapy.http.response.html import HtmlResponseresponse = HtmlResponse(url=request.url, body=bytes(spider.browser.page_source, encoding='utf8')) # 编码可能要调整return response# 使用scrapy默认处理请求return None
(2)注册中间件
- 在配置文件settings中
DOWNLOADER_MIDDLEWARES = {"scrapy_test.middlewares.SeleniumMiddleWare": 555,
}
【十】去重过滤器
- 在scrapy框架中,
- 为了确保爬取到的数据是唯一的
- 避免重复爬取相同的页面或数据
- scrapy默认使用了基于Request指纹的去重机制
- 除了默认的去重规则,scrapy还支持自定义去重规则
【1】基于Request指纹的去重
(1)去重核心代码
- 位置:
from scrapy.core.scheduler import Schedulerdef enqueue_request(self, request: Request) -> bool:def request_seen(self, request: Request) -> bool:class RFPDupeFilter(BaseDupeFilter):def request_seen(self, request: Request) -> bool:
self.fingerprints: Set[str] = set()def request_fingerprint(self, request: Request) -> str:return self.fingerprinter.fingerprint(request).hex() def request_seen(self, request: Request) -> bool:fp = self.request_fingerprint(request)if fp in self.fingerprints:return Trueself.fingerprints.add(fp)if self.file:self.file.write(fp + "\n")return False
- 讲解:
- 在类中定义了一个实例变量
fingerprints- 是一个集合,集合具有去重的功能
- 用于存储已经发送过的
request指纹
- 在类中定义了一个方法
request_fingerprint- 使用fingerprinter对象的fingerprint方法,对request进行计算
- 计算指纹,并将指纹转换为十六进制的字符串
- 在类中定义了方法
request_seen- 首先计算request的指纹
- 判断指纹是否在访问过的集合中
- 为真,那么久说明是已经访问过
- 添加这个请求的指纹到指纹集合中
- 检查
self.file是否存在(打开的文件句柄,用于持久化存储指纹)- 存在就将指纹写入这个文件,并换行
- 最终返回False,说明是一个新的request
- 在类中定义了一个实例变量
(2)测试指纹
-
我们对两个相同请求结果但是不同url进行测试
-
例如:
-
https://www.example.com?keys=154623&value=qbz -
https://www.example.com?value=qbz&keys=154623 -
这两个的地址虽然不同,传递给后端的结果却相同
-
所以这两个的指纹应该是一样的
-
-
示例
from scrapy.utils.request import RequestFingerprinter
from scrapy import Requestfinger_printer = RequestFingerprinter()
request1 = Request(url="https://www.example.com?value=qbz&keys=154623")
request2 = Request(url="https://www.example.com?keys=154623&value=qbz")res1 = finger_printer.fingerprint(request1).hex()
res2 = finger_printer.fingerprint(request2).hex()
print(res2 == res1)
# True
【2】自定义过滤器
(1)布隆过滤器(Bloom Filter)
- 优点:
- 空间效率高:
- 使用位数组存储信息
- 比传统的哈希表或集合数据结构更小
- 时间效率高:
- 查找元素,通过几次简单的位运算
- 适用于大规模数据:
- 高空间和时间效率,所以适用于处理大规模数据
- 支持集合运算:
- 支持并集、交集等集合运算
- 这使得它在某些场景下非常有用
- 具有一定容错能力:
- 布隆过滤器是概率型数据结构,即存在哈希冲突
- 但误报率可以通过调整参数进行控制
- 空间效率高:
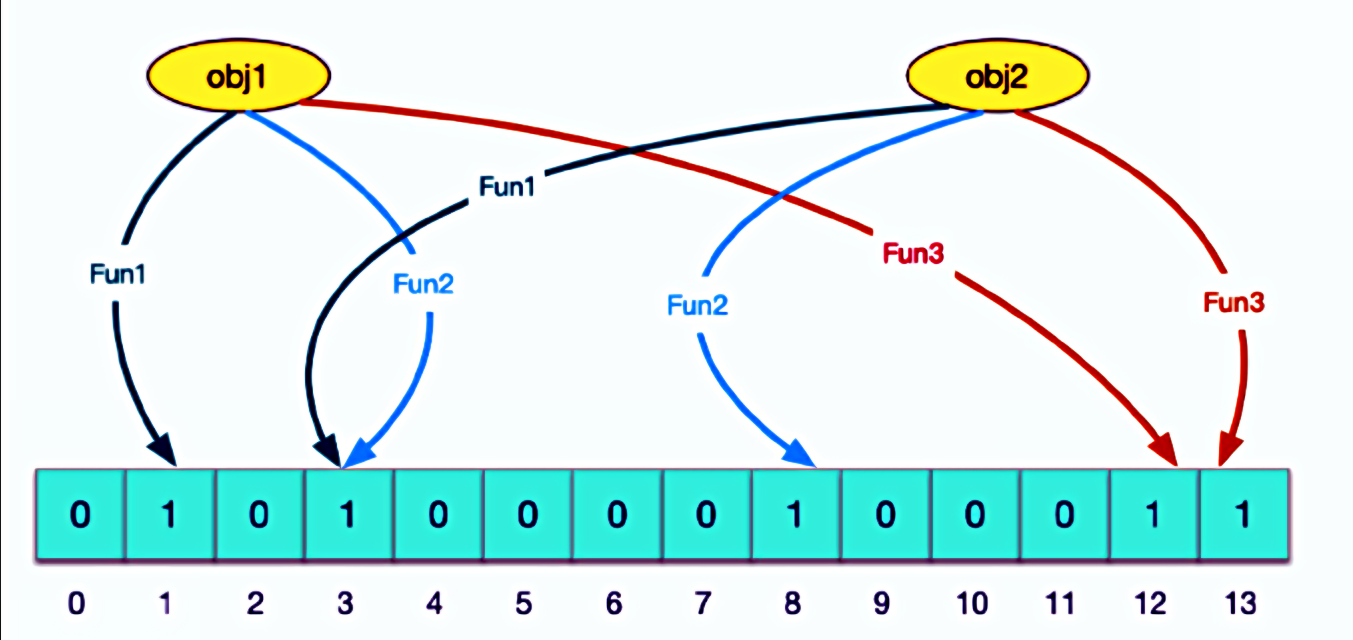
- 原理:
- 布隆过滤器主要由一个位数组和k个哈希函数组成。
- 当需要插入一个元素时,该元素会被k个哈希函数映射到位数组的k个不同位置,并将这些位置上的位设置为1。
- 当需要查询一个元素是否存在于集合中时,同样使用这k个哈希函数找到对应的位,并检查这些位是否都为1。
- 如果都为1,则认为该元素可能存在于集合中;如果有任何一个位为0,则确定该元素不在集合中。
(2)简单使用布隆过滤器
- 首先安装模块
pip install pybloom_live
- 使用示例
from pybloom_live import ScalableBloomFilter, BloomFilter# 创建一个可扩容的布隆过滤器
# initial_capacity容量
# error_rate错误率
bloom = ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH)# 添加元素
url1 = "https://www.example.com?keys=154623&value=qbz"
url2 = "https://www.example.com?value=qbz&keys=154623"
bloom.add(url1)
bloom.add(url2)# 检测结果
print(len(bloom)) # 2
print(url1 in bloom) # True
print(url2 in bloom) # True
- 错误率测试
from pybloom_live import ScalableBloomFilterbloom = ScalableBloomFilter(initial_capacity=1000, error_rate=0.01)for i in range(100000):data = f'example{i}'bloom.add(data)false_list = []
for i in range(1000):data = f'exist{i}'if bloom.__contains__(data):false_list.append(data)print(false_list)
print(f"错误率:>>>{len(false_list)/100}%")
# ['exist29', 'exist49', 'exist53', 'exist118', 'exist144', 'exist196', 'exist215', 'exist219', 'exist235', 'exist259', 'exist293', 'exist331', 'exist339', 'exist377', 'exist404', 'exist421', 'exist451', 'exist494', 'exist551', 'exist615', 'exist665', 'exist750', 'exist760', 'exist821', 'exist831', 'exist832', 'exist983']
# 错误率:>>>0.27%
(3)scrapy自定义过滤器(没有关闭默认的)
- 创建布隆过滤器中间件
from scrapy import signals
from pybloom_live import ScalableBloomFilter
from scrapy.exceptions import IgnoreRequest
import hashlibclass BloomFilterMiddleware:def __init__(self, crawler):self.crawler = crawler# 从Scrapy设置中读取布隆过滤器的配置self.initial_capacity = crawler.settings.getint('BLOOM_FILTER_INITIAL_CAPACITY', 100000)self.error_rate = crawler.settings.getfloat('BLOOM_FILTER_ERROR_RATE', 0.001)# 初始化布隆过滤器self.bloom_filter = ScalableBloomFilter(initial_capacity=self.initial_capacity, error_rate=self.error_rate)@classmethoddef from_crawler(cls, crawler):s = cls(crawler)# 连接信号crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)crawler.signals.connect(s.spider_closed, signal=signals.spider_closed)crawler.signals.connect(s.process_request, signal=signals.request_scheduled)return sdef spider_opened(self, spider):# 可以在这里加载之前保存的布隆过滤器状态(如果需要的话)passdef spider_closed(self, spider):# 可以在这里保存布隆过滤器的当前状态(如果需要的话)passdef process_request(self, request, spider):# 对URL进行哈希处理url_hash = hashlib.sha256(request.url.encode()).hexdigest()# 检查URL是否已经在布隆过滤器中if url_hash in self.bloom_filter:# 如果可能在布隆过滤器中,则忽略请求raise IgnoreRequest("URL already processed")def process_response(self, request, response, spider):# 检查响应是否成功if response.status == 200:# 对URL进行哈希处理url_hash = hashlib.sha256(request.url.encode()).hexdigest()# 将URL添加到布隆过滤器中self.bloom_filter.add(url_hash)return response
- 在配置文件中注册
# 添加自定义中间件
MIDDLEWARES = {'your_project_name.middlewares.BloomFilterMiddleware': 542,
}# 布隆过滤器设置
BLOOM_FILTER_INITIAL_CAPACITY = 10000 # 根据你的需求设置容量
BLOOM_FILTER_ERROR_RATE = 0.01 # 设置误报率
相关文章:
Scrapy框架 进阶
Scrapy框架基础Scrapy框架进阶 【五】持久化存储 命令行:json、csv等管道:什么数据类型都可以 【1】命令行简单存储 (1)语法 Json格式 scrapy crawl 自定义爬虫程序文件名 -o 文件名.jsonCSV格式 scrapy crawl 自定义爬虫程…...
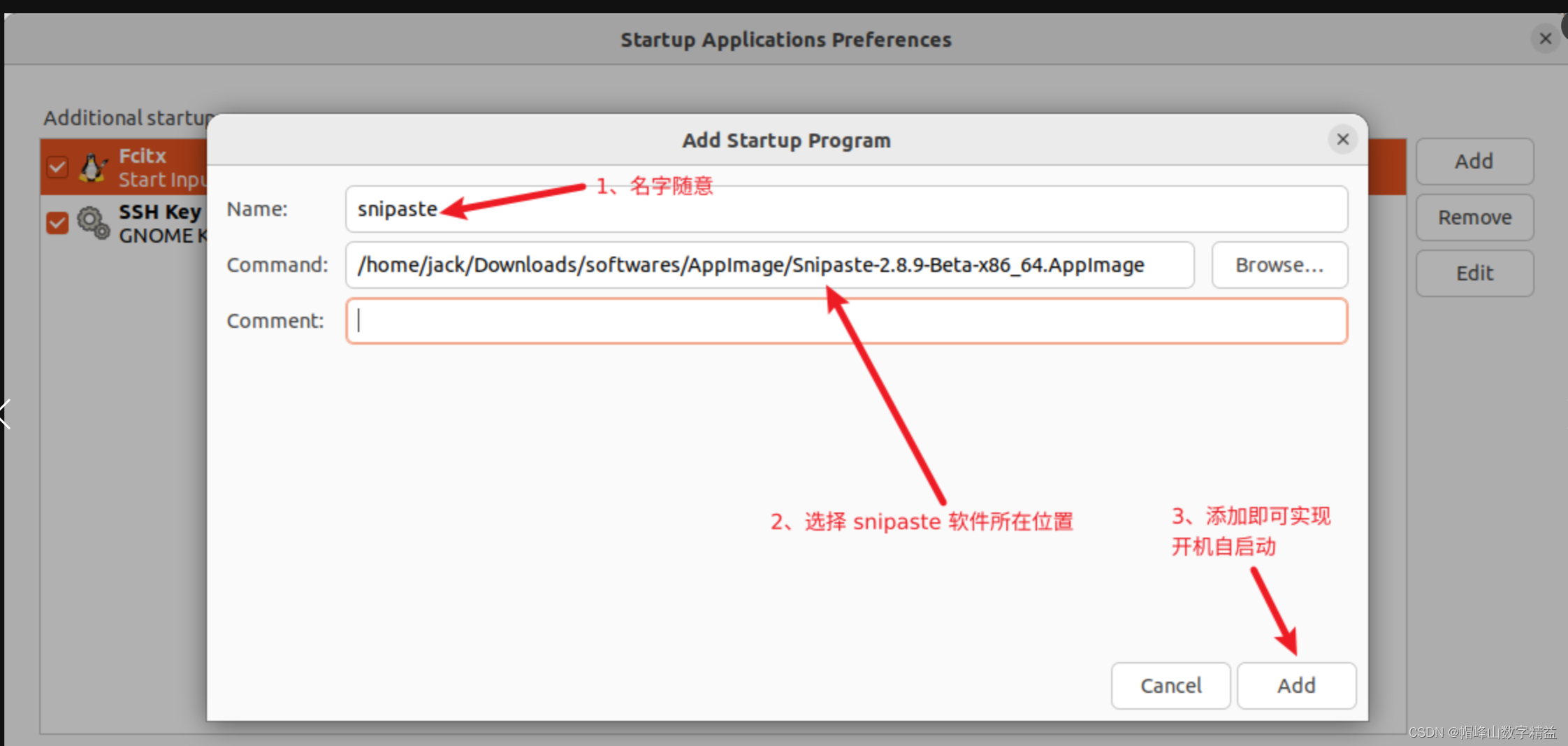
ubuntu22安装snipaste
Ubuntu 22.04 一、Snipaste 介绍和下载 Snipaste 官网下载链接: Snipaste Downloads 二、安装并使用 Snipaste # 1、进入Snipaste-2.8.9-Beta-x86_64.AppImage 目录(根据自己下载目录) cd /home/jack/Downloads/softwares/AppImage# 2、Snipaste-2.8.9-…...
spring-cloud微服务openfeign
Spring Cloud openfeign对Feign进行了增强,使其支持Spring MVC注解,另外还整合了Ribbon和Nacos,从而使得Feign的使用更加方便 优势,openfeign可以做到使用HTTP请求远程服务时就像洞用本地方法一样的体验,开发者完全感…...
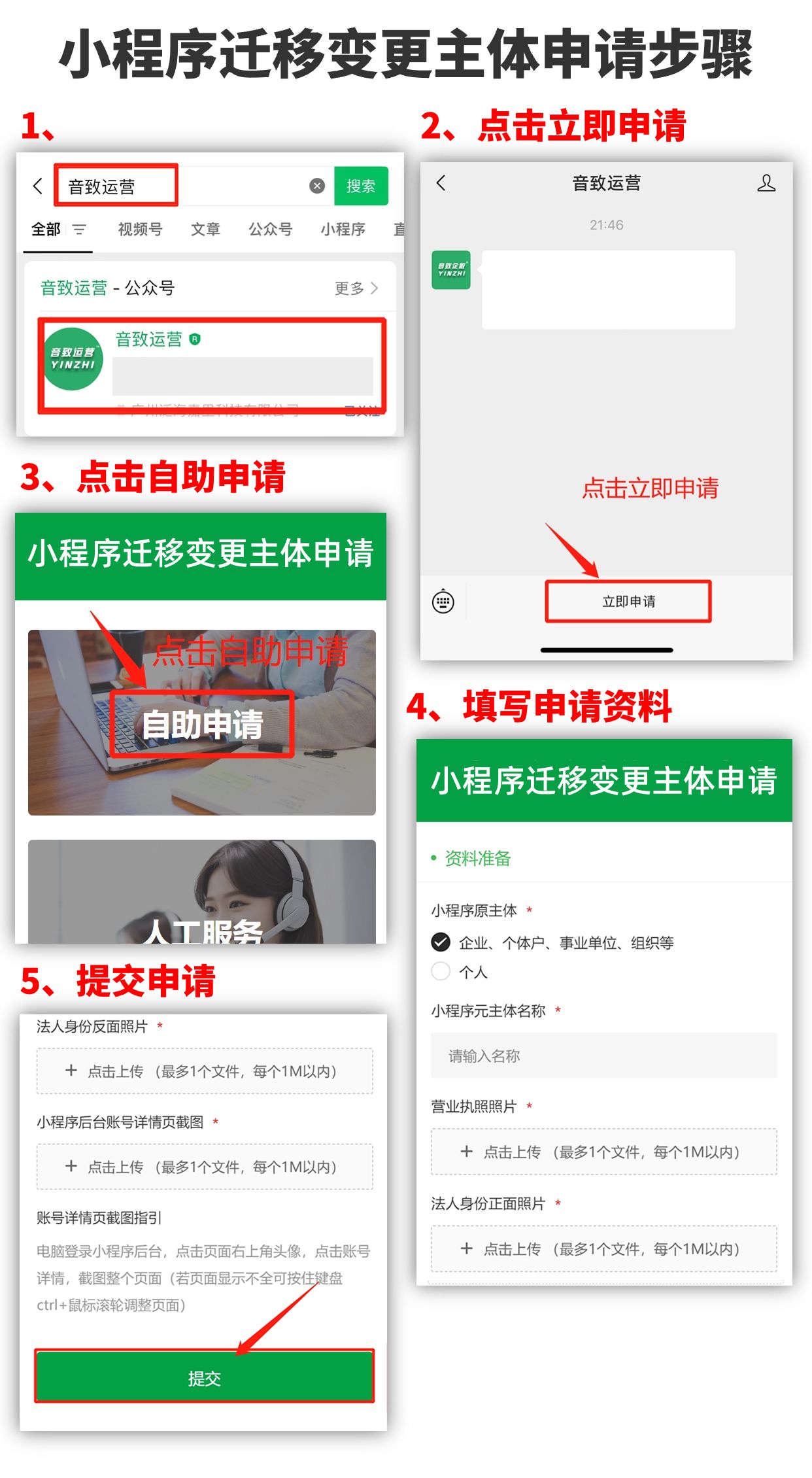
小程序变更主体需要多久?
小程序迁移变更主体有什么作用?小程序迁移变更主体的好处有很多哦!比如可以获得更多权限功能、公司变更或注销时可以保证账号的正常使用、收购账号后可以改变归属权或使用权等等。小程序迁移变更主体的条件有哪些?1、新主体必须是企业主体&am…...

19 Games101 - 笔记 - 相机与透镜
**19 ** 相机与透镜 目录 摘要一 照相机主要部分二 小孔成像与视场(FOV)三 曝光(Exposure)四 景深(Depth of Field)总结 摘要 虽说照相机与透镜属于相对独立的话题,但它们的确是计算机图形学当中的一部分知识。在过往的十多篇笔记中,我们学习的都是如…...

Flink入门学习 | 大数据技术
⭐简单说两句⭐ ✨ 正在努力的小新~ 💖 超级爱分享,分享各种有趣干货! 👩💻 提供:模拟面试 | 简历诊断 | 独家简历模板 🌈 感谢关注,关注了你就是我的超级粉丝啦! &…...

Arthas实战教程:定位Java应用CPU过高与线程死锁
引言 在Java应用开发中,我们可能会遇到CPU占用过高和线程死锁的问题。本文将介绍如何使用Arthas工具快速定位这些问题。 准备工作 首先,我们创建一个简单的Java应用,模拟CPU过高和线程死锁的情况。在这个示例中,我们将编写一个…...

HTML制作跳动的心形网页
作为一名码农 也有自己浪漫的小心思嗷~ 该网页 代码整体难度不大 操作性较强 祝大家都幸福hhhhh 效果成品: 全部代码: <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.0 Transitional//EN"> <HTML><HEAD><TITLE> 一个…...
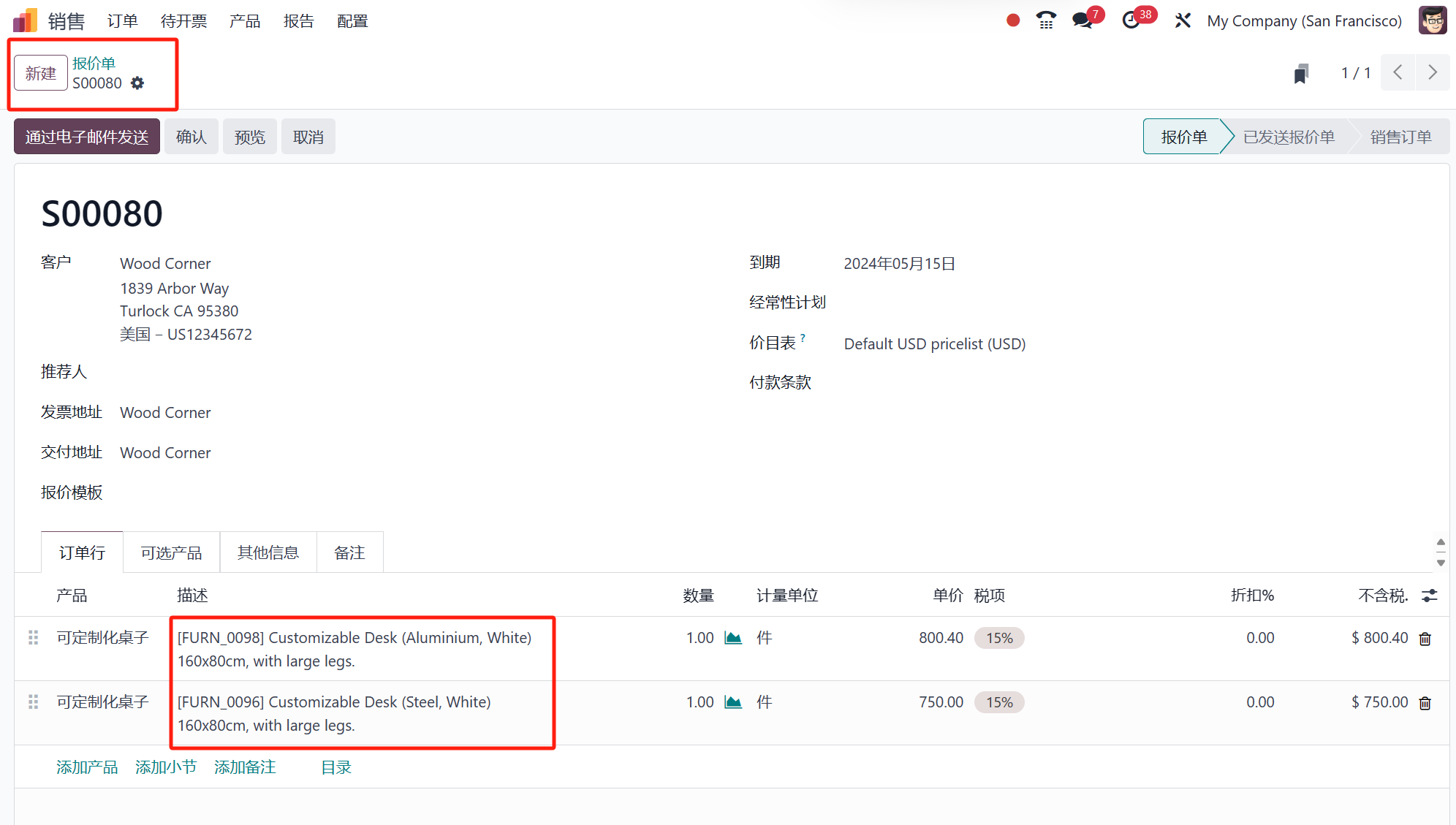
如何在Odoo 17 销售应用中使用产品目录添加产品
Odoo,作为一个知名的开源ERP系统,发布了其第17版,新增了多项功能和特性。Odoo 17包中的一些操作简化了,生产力提高了,用户体验也有了显著改善。为了为其用户提供新的和改进的功能,Odoo不断进行改进和增加新…...

为什么pdf拆分出几页之后大小几乎没有变化
PDF 文件的大小在拆分出几页之后几乎没有变化可能有几个原因: 图像压缩: 如果 PDF 文件中包含图像,而这些图像已经被压缩过,拆分后的页面依然会保留这些压缩设置,因此文件大小可能不会显著变化。 文本和矢量图形: PDF 文件中的文…...
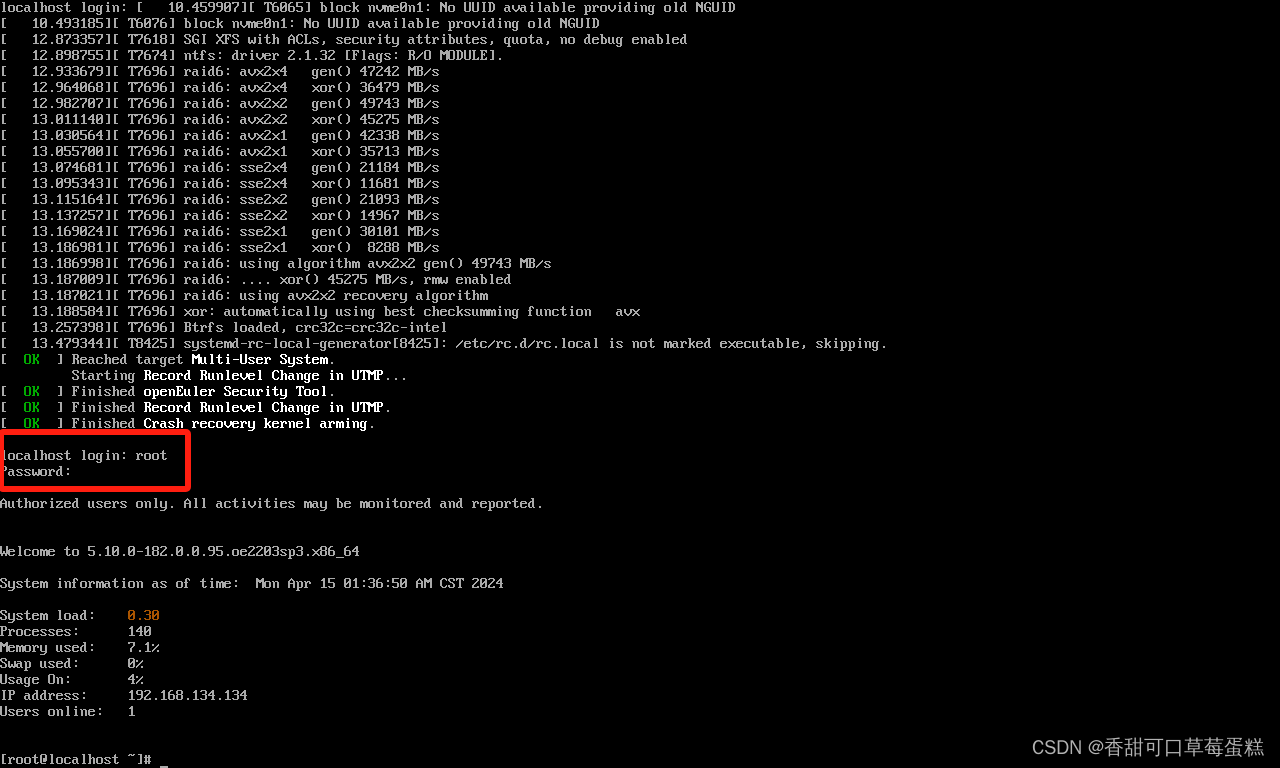
如何在 VM 虚拟机中安装 OpenEuler 操作系统保姆级教程(附链接)
一、VMware Workstation 虚拟机 若没有安装虚拟机的可以参考下篇文章进行安装: 博客链接https://eclecticism.blog.csdn.net/article/details/135713915 二、OpenEuler 镜像 点击链接前往官网 官网 选择第一个即可 三、安装 OpenEuler 打开虚拟机安装 Ctrl …...

(六)PostgreSQL的组织结构(3)-默认角色和schema
PostgreSQL的组织结构(3)-默认角色和schema 基础信息 OS版本:Red Hat Enterprise Linux Server release 7.9 (Maipo) DB版本:16.2 pg软件目录:/home/pg16/soft pg数据目录:/home/pg16/data 端口:57771 默认角色 Post…...

DockerFile定制镜像
dockerfile 简介 Dockerfile 是⼀个⽤来构建镜像的⽂本⽂件,⽂本内容包含了⼀条条构建镜像所需的指令和 说明,每条指令构建⼀层,最终构建出⼀个新的镜像。 docker镜像的本质是⼀个分层的⽂件系统 centos的iso镜像⽂件是包含bootfs和rootfs…...

Java8中JUC包同步工具类深度解析(Semaphore,CountDownLatch,CyclicBarrier,Phaser)
个人主页: 进朱者赤 阿里非典型程序员一枚 ,记录平平无奇程序员在大厂的打怪升级之路。 一起学习Java、大数据、数据结构算法(公众号同名) 引言 在Java中,并发编程一直是一个重要的领域,而JDK 8中的java.u…...
)
岛屿个数(dfs)
[第十四届蓝桥杯省B 岛屿个数] 小蓝得到了一副大小为 M N MN MN 的格子地图,可以将其视作一个只包含字符 0 0 0(代表海水)和 1 1 1(代表陆地)的二维数组,地图之外可以视作全部是海水,每个岛…...

【C++造神计划】运算符
1 赋值运算符 赋值运算符的功能是将一个值赋给一个变量 int a 5; // 将整数 5 赋给变量 a 运算符左边的部分叫作 lvalue(left value),右边的部分叫作 rvalue(right value) 左边 lvalue 必须是一个变量 右边 rval…...
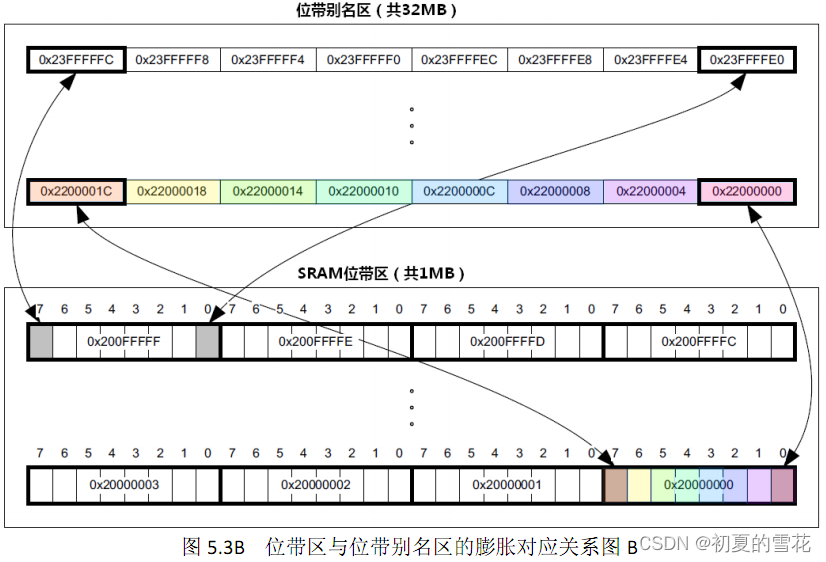
Cortex-M3/M4处理器的bit-band(位带)技术
ARM Cortex-M3/M4的位带(Bit-Band)技术是一种内存映射技术,它允许对单个位进行直接操作,而不需要对整个字(通常是32位)进行操作。这项技术主要用于对特定的位进行高效的读写,特别是在需要对GPIO…...

【TOP】IEEE旗下1区,影响因子将破8,3个月录用,CCF推荐,性价比高!
计算机类 ● 好刊解读 IEEE出版社、中科院2区TOP,CCF推荐,今天推荐的期刊可谓buff叠满,好刊质量靠谱,有意向评职晋升毕业作者可重点关注: 01 期刊简介 ✅出版社:IEEE ✅影响因子:7.5-8.0 ✅…...
)
赚钱游戏 2.0.1 版 (资源免费)
没有c编辑器的可以直接获取资源来玩 #include <iostream> #include <string> #include <windows.h> #include <conio.h> #include <fstream> #include <ctime> #include <time.h> #include <stdio.h> #include <cstring&g…...
服务调用-微服务小白入门(4)
背景 各个服务应用,有很多restful api,不论是用哪种方式发布,部署,注册,发现,有很多场景需要各个微服务之间进行服务的调用,大多时候返回的json格式响应数据多,如果是前端直接调用倒…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

大数据零基础学习day1之环境准备和大数据初步理解
学习大数据会使用到多台Linux服务器。 一、环境准备 1、VMware 基于VMware构建Linux虚拟机 是大数据从业者或者IT从业者的必备技能之一也是成本低廉的方案 所以VMware虚拟机方案是必须要学习的。 (1)设置网关 打开VMware虚拟机,点击编辑…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

中医有效性探讨
文章目录 西医是如何发展到以生物化学为药理基础的现代医学?传统医学奠基期(远古 - 17 世纪)近代医学转型期(17 世纪 - 19 世纪末)现代医学成熟期(20世纪至今) 中医的源远流长和一脉相承远古至…...

【学习笔记】erase 删除顺序迭代器后迭代器失效的解决方案
目录 使用 erase 返回值继续迭代使用索引进行遍历 我们知道类似 vector 的顺序迭代器被删除后,迭代器会失效,因为顺序迭代器在内存中是连续存储的,元素删除后,后续元素会前移。 但一些场景中,我们又需要在执行删除操作…...
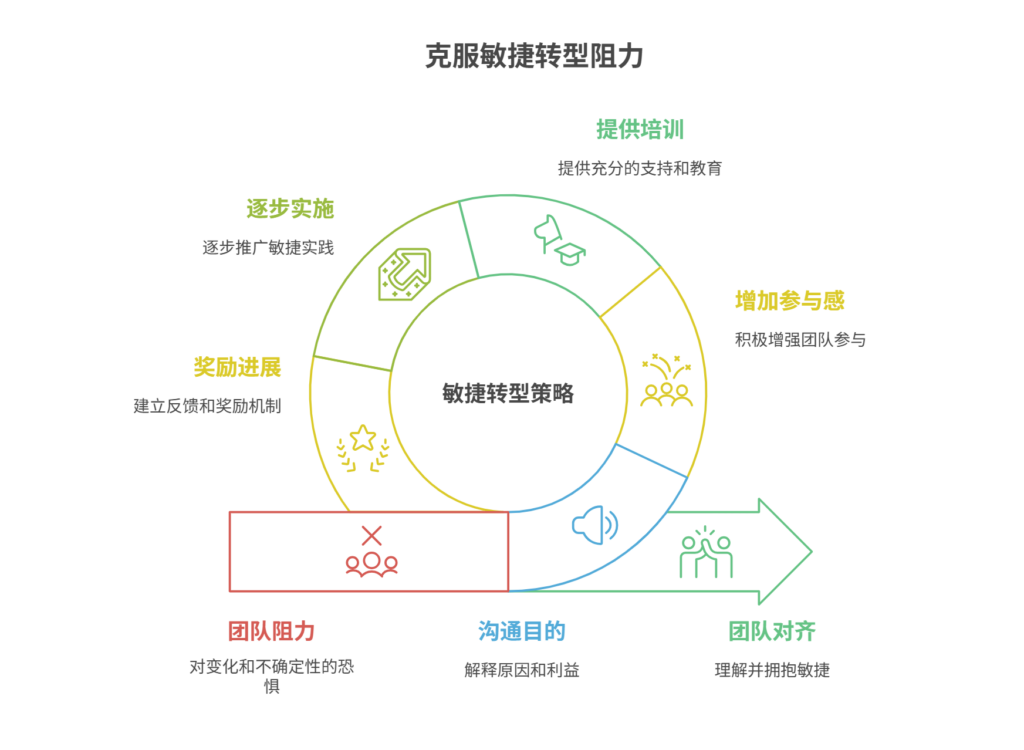
如何应对敏捷转型中的团队阻力
应对敏捷转型中的团队阻力需要明确沟通敏捷转型目的、提升团队参与感、提供充分的培训与支持、逐步推进敏捷实践、建立清晰的奖励和反馈机制。其中,明确沟通敏捷转型目的尤为关键,团队成员只有清晰理解转型背后的原因和利益,才能降低对变化的…...