transformer上手(6)—— 微调预训练模型
1 加载数据集
以同义句判断任务为例(每次输入两个句子,判断它们是否为同义句),构建我们的第一个 Transformers 模型。我们选择蚂蚁金融语义相似度数据集 AFQMC 作为语料,它提供了官方的数据划分,训练集 / 验证集 / 测试集分别包含 34334 / 4316 / 3861 个句子对,标签 0 表示非同义句,1 表示同义句:
{"sentence1": "还款还清了,为什么花呗账单显示还要还款", "sentence2": "花呗全额还清怎么显示没有还款", "label": "1"}
1.1 Dataset
Pytorch 通过 Dataset 类和 DataLoader 类处理数据集和加载样本。同样地,这里我们首先继承 Dataset 类构造自定义数据集,以组织样本和标签。AFQMC 样本以 json 格式存储,因此我们使用 json 库按行读取样本,并且以行号作为索引构建数据集。
from torch.utils.data import Dataset
import jsonclass AFQMC(Dataset):def __init__(self, data_file):self.data = self.load_data(data_file)def load_data(self, data_file):Data = {}with open(data_file, 'rt') as f:for idx, line in enumerate(f):sample = json.loads(line.strip())Data[idx] = samplereturn Datadef __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]train_data = AFQMC('data/afqmc_public/train.json')
valid_data = AFQMC('data/afqmc_public/dev.json')print(train_data[0])# {'sentence1': '蚂蚁借呗等额还款可以换成先息后本吗', 'sentence2': '借呗有先息到期还本吗', 'label': '0'}
可以看到,我们编写的 AFQMC 类成功读取了数据集,每一个样本都以字典形式保存,分别以sentence1、sentence2 和 label 为键存储句子对和标签。
如果数据集非常巨大,难以一次性加载到内存中,我们也可以继承 IterableDataset 类构建迭代型数据集:
from torch.utils.data import IterableDataset
import jsonclass IterableAFQMC(IterableDataset):def __init__(self, data_file):self.data_file = data_filedef __iter__(self):with open(self.data_file, 'rt') as f:for line in f:sample = json.loads(line.strip())yield sampletrain_data = IterableAFQMC('data/afqmc_public/train.json')print(next(iter(train_data)))# {'sentence1': '蚂蚁借呗等额还款可以换成先息后本吗', 'sentence2': '借呗有先息到期还本吗', 'label': '0'}
1.2 DataLoader
接下来就需要通过 DataLoader 库按批 (batch) 加载数据,并且将样本转换成模型可以接受的输入格式。对于 NLP 任务,这个环节就是将每个 batch 中的文本按照预训练模型的格式进行编码(包括 Padding、截断等操作)。
通过手工编写 DataLoader 的批处理函数 collate_fn 来实现。首先加载分词器,然后对每个 batch 中的所有句子对进行编码,同时把标签转换为张量格式:
import torch
from torch.utils.data import DataLoader
from transformers import AutoTokenizercheckpoint = "bert-base-chinese"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)def collote_fn(batch_samples):batch_sentence_1, batch_sentence_2 = [], []batch_label = []for sample in batch_samples:batch_sentence_1.append(sample['sentence1'])batch_sentence_2.append(sample['sentence2'])batch_label.append(int(sample['label']))X = tokenizer(batch_sentence_1, batch_sentence_2, padding=True, truncation=True, return_tensors="pt")y = torch.tensor(batch_label)return X, ytrain_dataloader = DataLoader(train_data, batch_size=4, shuffle=True, collate_fn=collote_fn)batch_X, batch_y = next(iter(train_dataloader))
print('batch_X shape:', {k: v.shape for k, v in batch_X.items()})
print('batch_y shape:', batch_y.shape)
print(batch_X)
print(batch_y)batch_X shape: {'input_ids': torch.Size([4, 39]), 'token_type_ids': torch.Size([4, 39]), 'attention_mask': torch.Size([4, 39])
}
batch_y shape: torch.Size([4])# {'input_ids': tensor([
# [ 101, 5709, 1446, 5543, 3118, 802, 736, 3952, 3952, 2767, 1408, 102,
# 3952, 2767, 1041, 966, 5543, 4500, 5709, 1446, 1408, 102, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0],
# [ 101, 872, 8024, 2769, 6821, 5709, 1446, 4638, 7178, 6820, 2130, 749,
# 8024, 6929, 2582, 720, 1357, 3867, 749, 102, 1963, 3362, 1357, 3867,
# 749, 5709, 1446, 722, 1400, 8024, 1355, 4495, 4638, 6842, 3621, 2582,
# 720, 1215, 102],
# [ 101, 1963, 862, 2990, 7770, 955, 1446, 677, 7361, 102, 6010, 6009,
# 955, 1446, 1963, 862, 712, 1220, 2990, 7583, 2428, 102, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0],
# [ 101, 2582, 3416, 2990, 7770, 955, 1446, 7583, 2428, 102, 955, 1446,
# 2990, 4157, 7583, 2428, 1416, 102, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0]]),
# 'token_type_ids': tensor([
# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1,
# 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
# 'attention_mask': tensor([
# [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
# 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
# [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])}
# tensor([1, 0, 1, 1])
可以看到,DataLoader 按照我们设置的 batch size 每次对 4 个样本进行编码,并且通过设置 padding=True 和 truncation=True 来自动对每个 batch 中的样本进行补全和截断。这里我们选择 BERT 模型作为 checkpoint,所以每个样本都被处理成了“ [ C L S ] s e n 1 [ S E P ] s e n 2 [ S E P ] [CLS] sen1 [SEP] sen2 [SEP] [CLS]sen1[SEP]sen2[SEP]”的形式。
这种只在一个 batch 内进行补全的操作被称为动态补全 (Dynamic padding),Hugging Face 也提供了 DataCollatorWithPadding 类来进行。
2 训练模型
2.1 构建模型
对于分类任务,可以直接使用我们前面介绍过的 AutoModelForSequenceClassification 类来完成。但是在实际操作中,除了使用预训练模型编码文本外,我们通常还会进行许多自定义操作,因此在大部分情况下我们都需要自己编写模型。
最简单的方式是首先利用 Transformers 库加载 BERT 模型,然后接一个全连接层完成分类:
from torch import nn
from transformers import AutoModeldevice = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f'Using {device} device')class BertForPairwiseCLS(nn.Module):def __init__(self):super(BertForPairwiseCLS, self).__init__()self.bert_encoder = AutoModel.from_pretrained(checkpoint)self.dropout = nn.Dropout(0.1)self.classifier = nn.Linear(768, 2)def forward(self, x):bert_output = self.bert_encoder(**x)cls_vectors = bert_output.last_hidden_state[:, 0, :]cls_vectors = self.dropout(cls_vectors)logits = self.classifier(cls_vectors)return logitsmodel = BertForPairwiseCLS().to(device)
print(model)# Using cpu device
# NeuralNetwork(
# (bert_encoder): BertModel(
# (embeddings): BertEmbeddings(...)
# (encoder): BertEncoder(...)
# (pooler): BertPooler(
# (dense): Linear(in_features=768, out_features=768, bias=True)
# (activation): Tanh()
# )
# )
# (dropout): Dropout(p=0.1, inplace=False)
# (classifier): Linear(in_features=768, out_features=2, bias=True)
# )
这里模型首先将输入送入到 BERT 模型中,将每一个 token 都编码为维度为 768 的向量,然后从输出序列中取出第一个 [CLS] token 的编码表示作为整个句子对的语义表示,再送入到一个线性全连接层中预测两个类别的分数。这种方式简单粗暴,但是相当于在 Transformers 模型外又包了一层,因此无法再调用 Transformers 库预置的模型函数。
更为常见的写法是继承 Transformers 库中的预训练模型来创建自己的模型。例如这里我们可以继承 BERT 模型(BertPreTrainedModel 类)来创建一个与上面模型结构完全相同的分类器:
from torch import nn
from transformers import AutoConfig
from transformers import BertPreTrainedModel, BertModeldevice = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f'Using {device} device')class BertForPairwiseCLS(BertPreTrainedModel):def __init__(self, config):super().__init__(config)self.bert = BertModel(config, add_pooling_layer=False)self.dropout = nn.Dropout(config.hidden_dropout_prob)self.classifier = nn.Linear(768, 2)self.post_init()def forward(self, x):bert_output = self.bert(**x)cls_vectors = bert_output.last_hidden_state[:, 0, :]cls_vectors = self.dropout(cls_vectors)logits = self.classifier(cls_vectors)return logitsconfig = AutoConfig.from_pretrained(checkpoint)
model = BertForPairwiseCLS.from_pretrained(checkpoint, config=config).to(device)
print(model)
注意,此时我们的模型是 Transformers 预训练模型的子类,因此需要通过预置的 from_pretrained 函数来加载模型参数。这种方式也使得我们可以更灵活地操作模型细节,例如这里 Dropout 层就可以直接加载 BERT 模型自带的参数值,而不用像上面一样手工赋值。
为了确保模型的输出符合我们的预期,我们尝试将一个 Batch 的数据送入模型:
outputs = model(batch_X)
print(outputs.shape)# torch.Size([4, 2])
可以看到模型输出了一个 4 × 2 4 \times 2 4×2 的张量,符合我们的预期(每个样本输出 2 维的 logits 值分别表示两个类别的预测分数,batch 内共 4 个样本)。
2.2 优化模型参数
正如之前介绍的那样,在训练模型时,我们将每一轮 Epoch 分为训练循环和验证/测试循环。在训练循环中计算损失、优化模型的参数,在验证/测试循环中评估模型的性能:
from tqdm.auto import tqdmdef train_loop(dataloader, model, loss_fn, optimizer, lr_scheduler, epoch, total_loss):progress_bar = tqdm(range(len(dataloader)))progress_bar.set_description(f'loss: {0:>7f}')finish_step_num = (epoch-1)*len(dataloader)model.train()for step, (X, y) in enumerate(dataloader, start=1):X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()lr_scheduler.step()total_loss += loss.item()progress_bar.set_description(f'loss: {total_loss/(finish_step_num + step):>7f}')progress_bar.update(1)return total_lossdef test_loop(dataloader, model, mode='Test'):assert mode in ['Valid', 'Test']size = len(dataloader.dataset)correct = 0model.eval()with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)correct += (pred.argmax(1) == y).type(torch.float).sum().item()correct /= sizeprint(f"{mode} Accuracy: {(100*correct):>0.1f}%\n")
最后,将”训练循环”和”验证/测试循环”组合成 Epoch,就可以进行模型的训练和验证了。
与 Pytorch 类似,Transformers 库同样实现了很多的优化器,并且相比 Pytorch 固定学习率,Transformers 库的优化器会随着训练过程逐步减小学习率(通常会产生更好的效果)。例如我们前面使用过的 AdamW 优化器:
from transformers import AdamWoptimizer = AdamW(model.parameters(), lr=5e-5)
默认情况下,优化器会线性衰减学习率,对于上面的例子,学习率会线性地从 5 e − 5 5e-5 5e−5 降到 0。为了正确地定义学习率调度器,我们需要知道总的训练步数 (step),它等于训练轮数 (Epoch number) 乘以每一轮中的步数(也就是训练 dataloader 的大小):
from transformers import get_schedulerepochs = 3
num_training_steps = epochs * len(train_dataloader)
lr_scheduler = get_scheduler("linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps,
)
print(num_training_steps)# 25752
完整的训练过程如下:
from transformers import AdamW, get_schedulerlearning_rate = 1e-5
epoch_num = 3loss_fn = nn.CrossEntropyLoss()
optimizer = AdamW(model.parameters(), lr=learning_rate)
lr_scheduler = get_scheduler("linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=epoch_num*len(train_dataloader),
)total_loss = 0.
for t in range(epoch_num):print(f"Epoch {t+1}/{epoch_num}\n-------------------------------")total_loss = train_loop(train_dataloader, model, loss_fn, optimizer, lr_scheduler, t+1, total_loss)test_loop(valid_dataloader, model, mode='Valid')
print("Done!")# Using cuda device# Epoch 1/3
# -------------------------------
# loss: 0.552296: 100%|█████████| 8584/8584 [07:16<00:00, 19.65it/s]
# Valid Accuracy: 72.1%# Epoch 2/3
# -------------------------------
# loss: 0.501410: 100%|█████████| 8584/8584 [07:16<00:00, 19.66it/s]
# Valid Accuracy: 73.0%# Epoch 3/3
# -------------------------------
# loss: 0.450708: 100%|█████████| 8584/8584 [07:15<00:00, 19.70it/s]
# Valid Accuracy: 74.1%# Done!
2.3 保存和加载模型
在大多数情况下,我们还需要根据验证集上的表现来调整超参数以及选出最好的模型,最后再将选出的模型应用于测试集以评估性能。这里我们在测试循环时返回计算出的准确率,然后对上面的 Epoch 训练代码进行小幅的调整,以保存验证集上准确率最高的模型:
def test_loop(dataloader, model, mode='Test'):assert mode in ['Valid', 'Test']size = len(dataloader.dataset)correct = 0model.eval()with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)correct += (pred.argmax(1) == y).type(torch.float).sum().item()correct /= sizeprint(f"{mode} Accuracy: {(100*correct):>0.1f}%\n")return correcttotal_loss = 0.
best_acc = 0.
for t in range(epoch_num):print(f"Epoch {t+1}/{epoch_num}\n-------------------------------")total_loss = train_loop(train_dataloader, model, loss_fn, optimizer, lr_scheduler, t+1, total_loss)valid_acc = test_loop(valid_dataloader, model, mode='Valid')if valid_acc > best_acc:best_acc = valid_accprint('saving new weights...\n')torch.save(model.state_dict(), f'epoch_{t+1}_valid_acc_{(100*valid_acc):0.1f}_model_weights.bin')
print("Done!")# Using cuda device# Epoch 1/3
# -------------------------------
# loss: 0.556518: 100%|█████████| 8584/8584 [07:51<00:00, 18.20it/s]
# Valid Accuracy: 71.8%# saving new weights...# Epoch 2/3
# -------------------------------
# loss: 0.506202: 100%|█████████| 8584/8584 [07:15<00:00, 19.71it/s]
# Valid Accuracy: 72.0%# saving new weights...# Epoch 3/3
# -------------------------------
# loss: 0.455851: 100%|█████████| 8584/8584 [07:16<00:00, 19.68it/s]
# Valid Accuracy: 74.1%# saving new weights...# Done!
可以看到,随着训练的进行,在验证集上的准确率逐步提升(71.8% -> 72.0% -> 74.1%)。因此,3 轮 Epoch 训练结束后,会在目录下保存下所有三轮模型的权重:
epoch_1_valid_acc_71.8_model_weights.bin
epoch_2_valid_acc_72.0_model_weights.bin
epoch_3_valid_acc_74.1_model_weights.bin
至此,我们手工构建的文本分类模型的训练过程就完成了,完整的训练代码如下:
import random
import os
import numpy as np
import json
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
from transformers import AutoTokenizer, AutoConfig
from transformers import BertPreTrainedModel, BertModel
from transformers import AdamW, get_scheduler
from tqdm.auto import tqdmdef seed_everything(seed=1029):random.seed(seed)os.environ['PYTHONHASHSEED'] = str(seed)np.random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)# some cudnn methods can be random even after fixing the seed# unless you tell it to be deterministictorch.backends.cudnn.deterministic = Truedevice = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f'Using {device} device')
seed_everything(42)learning_rate = 1e-5
batch_size = 4
epoch_num = 3checkpoint = "bert-base-chinese"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)class AFQMC(Dataset):def __init__(self, data_file):self.data = self.load_data(data_file)def load_data(self, data_file):Data = {}with open(data_file, 'rt') as f:for idx, line in enumerate(f):sample = json.loads(line.strip())Data[idx] = samplereturn Datadef __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]train_data = AFQMC('data/afqmc_public/train.json')
valid_data = AFQMC('data/afqmc_public/dev.json')def collote_fn(batch_samples):batch_sentence_1, batch_sentence_2 = [], []batch_label = []for sample in batch_samples:batch_sentence_1.append(sample['sentence1'])batch_sentence_2.append(sample['sentence2'])batch_label.append(int(sample['label']))X = tokenizer(batch_sentence_1, batch_sentence_2, padding=True, truncation=True, return_tensors="pt")y = torch.tensor(batch_label)return X, ytrain_dataloader = DataLoader(train_data, batch_size=batch_size, shuffle=True, collate_fn=collote_fn)
valid_dataloader= DataLoader(valid_data, batch_size=batch_size, shuffle=False, collate_fn=collote_fn)class BertForPairwiseCLS(BertPreTrainedModel):def __init__(self, config):super().__init__(config)self.bert = BertModel(config, add_pooling_layer=False)self.dropout = nn.Dropout(config.hidden_dropout_prob)self.classifier = nn.Linear(768, 2)self.post_init()def forward(self, x):outputs = self.bert(**x)cls_vectors = outputs.last_hidden_state[:, 0, :]cls_vectors = self.dropout(cls_vectors)logits = self.classifier(cls_vectors)return logitsconfig = AutoConfig.from_pretrained(checkpoint)
model = BertForPairwiseCLS.from_pretrained(checkpoint, config=config).to(device)def train_loop(dataloader, model, loss_fn, optimizer, lr_scheduler, epoch, total_loss):progress_bar = tqdm(range(len(dataloader)))progress_bar.set_description(f'loss: {0:>7f}')finish_step_num = (epoch-1)*len(dataloader)model.train()for step, (X, y) in enumerate(dataloader, start=1):X, y = X.to(device), y.to(device)pred = model(X)loss = loss_fn(pred, y)optimizer.zero_grad()loss.backward()optimizer.step()lr_scheduler.step()total_loss += loss.item()progress_bar.set_description(f'loss: {total_loss/(finish_step_num + step):>7f}')progress_bar.update(1)return total_lossdef test_loop(dataloader, model, mode='Test'):assert mode in ['Valid', 'Test']size = len(dataloader.dataset)correct = 0model.eval()with torch.no_grad():for X, y in dataloader:X, y = X.to(device), y.to(device)pred = model(X)correct += (pred.argmax(1) == y).type(torch.float).sum().item()correct /= sizeprint(f"{mode} Accuracy: {(100*correct):>0.1f}%\n")return correctloss_fn = nn.CrossEntropyLoss()
optimizer = AdamW(model.parameters(), lr=learning_rate)
lr_scheduler = get_scheduler("linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=epoch_num*len(train_dataloader),
)total_loss = 0.
best_acc = 0.
for t in range(epoch_num):print(f"Epoch {t+1}/{epoch_num}\n-------------------------------")total_loss = train_loop(train_dataloader, model, loss_fn, optimizer, lr_scheduler, t+1, total_loss)valid_acc = test_loop(valid_dataloader, model, mode='Valid')if valid_acc > best_acc:best_acc = valid_accprint('saving new weights...\n')torch.save(model.state_dict(), f'epoch_{t+1}_valid_acc_{(100*valid_acc):0.1f}_model_weights.bin')
print("Done!")
这里我们还通过 seed_everything 函数手工设置训练过程中所有的随机数种子为 42,从而使得模型结果可以复现,而不是每次运行代码都是不同的结果。
最后,我们加载验证集上最优的模型权重,汇报其在测试集上的性能。由于 AFQMC 公布的测试集上并没有标签,无法评估性能,这里我们暂且用验证集代替进行演示:
model.load_state_dict(torch.load('epoch_3_valid_acc_74.1_model_weights.bin'))
test_loop(valid_dataloader, model, mode='Test')# Test Accuracy: 74.1%
注意:前面我们只保存了模型的权重,因此如果要单独调用上面的代码,需要首先实例化一个结构完全一样的模型,再通过
model.load_state_dict()函数加载权重。
最终在测试集(这里用了验证集)上的准确率为 74.1%,与前面汇报的一致,也验证了模型参数的加载过程是正确的。
相关文章:
transformer上手(6)—— 微调预训练模型
1 加载数据集 以同义句判断任务为例(每次输入两个句子,判断它们是否为同义句),构建我们的第一个 Transformers 模型。我们选择蚂蚁金融语义相似度数据集 AFQMC 作为语料,它提供了官方的数据划分,训练集 / …...
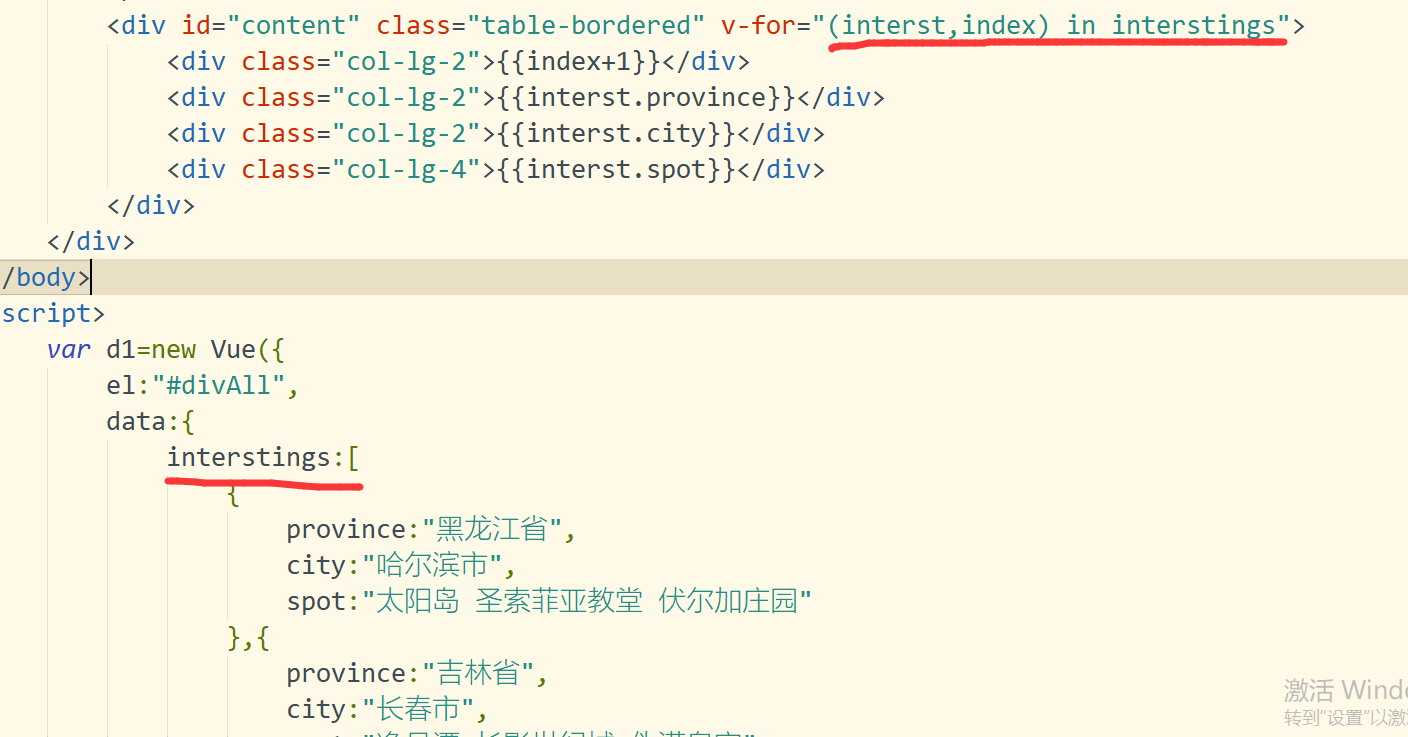
web前端框架设计第四课-条件判断与列表渲染
web前端框架设计第四课-条件判断与列表渲染 一.预习笔记 1.条件判断 1-1:v-if指令:根据表达式的值来判断是否输出DOM元素 1-2:template中使用v-if 1-3:v-else 1-4:v-else-if 1-5:v-show(不支…...
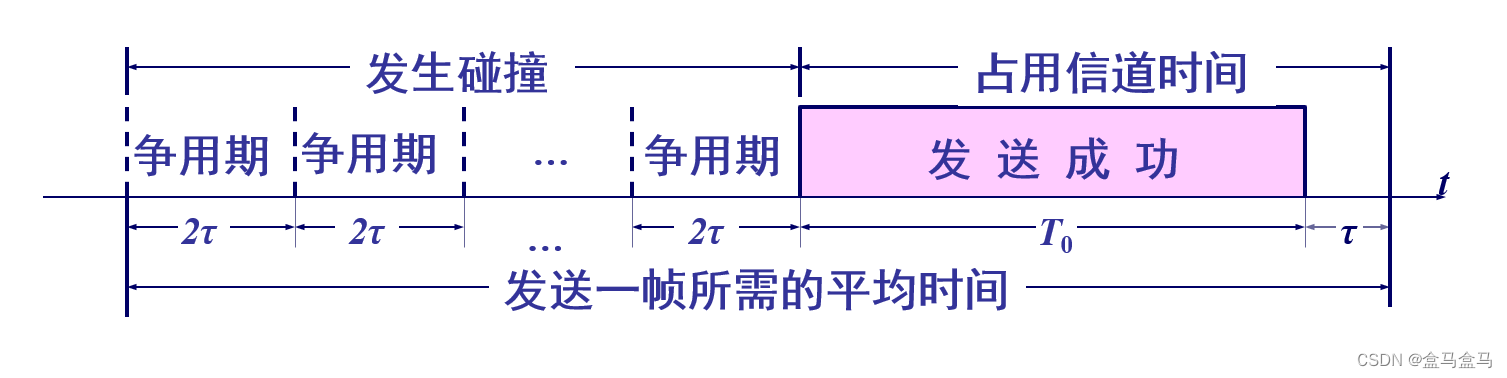
计算机网络:数据链路层 - CSMA/CD协议
计算机网络:数据链路层 - CSMA/CD协议 媒体接入控制CSMA/CD协议截断二进制指数退避算法帧长与帧间间隔信道利用率 媒体接入控制 如图所示,这是一根同轴电缆,有多台主机连接到这根同轴电缆上,他们共享这根传输媒体,形成…...

力扣LeetCode138. 复制带随机指针的链表 两种解法(C语言实现)
目录 题目链接 题目分析 题目定位: 解题思路 解题思路1(粗暴但是复杂度高) 解题思路2(巧妙并且复杂度低) 题目链接 138. 复制带随机指针的链表https://leetcode-cn.com/problems/copy-list-with-random-pointer/ …...

强大的压缩和解压缩工具 Keka for Mac
Keka for Mac是一款功能强大的压缩和解压缩工具,专为Mac用户设计。它支持多种压缩格式,包括7z、Zip、Tar、Gzip和Bzip2等,无论是发送电子邮件、备份文件还是节省磁盘空间,Keka都能轻松满足用户需求。 这款软件的操作简单直观&…...
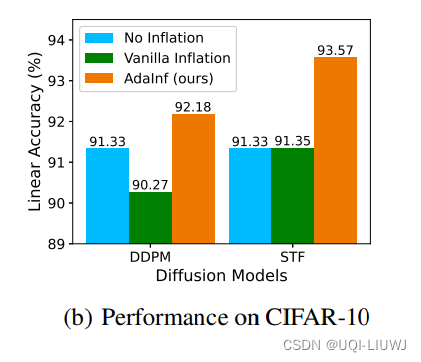
论文速读:Do Generated Data Always Help Contrastive Learning?
在对比学习领域,最近很多研究利用高质量生成模型来提升对比学习 给定一个未标记的数据集,在其上训练一个生成模型来生成大量的合成样本,然后在真实数据和生成数据的组合上执行对比学习这种使用生成数据的最简单方式被称为“数据膨胀”这与数据…...
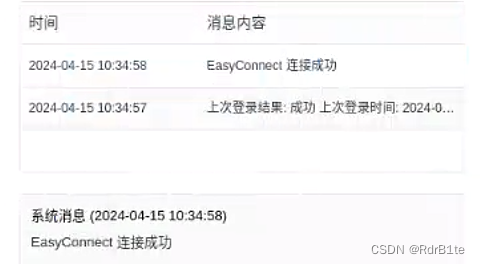
华为欧拉系统(openEuler-22.03)安装深信服EasyConnect软件(图文详解)
欧拉镜像下载安装 iso镜像官网下载地址 选择最小化安装,标准模式 换华为镜像源 更换华为镜像站,加速下载: sed -i "s#http://repo.openeuler.org#https://mirrors.huaweicloud.com/openeuler#g" /etc/yum.repos.d/openEuler.r…...

git commit --amend用法
一、git commit --amend 修改提交信息:您可以使用 git commit --amend 命令来修改最新提交的提交信息。执行该命令后,Git 将会打开文本编辑器(通常是的默认文本编辑器),以便编辑提交信息。完成编辑后保存并关闭编辑器…...
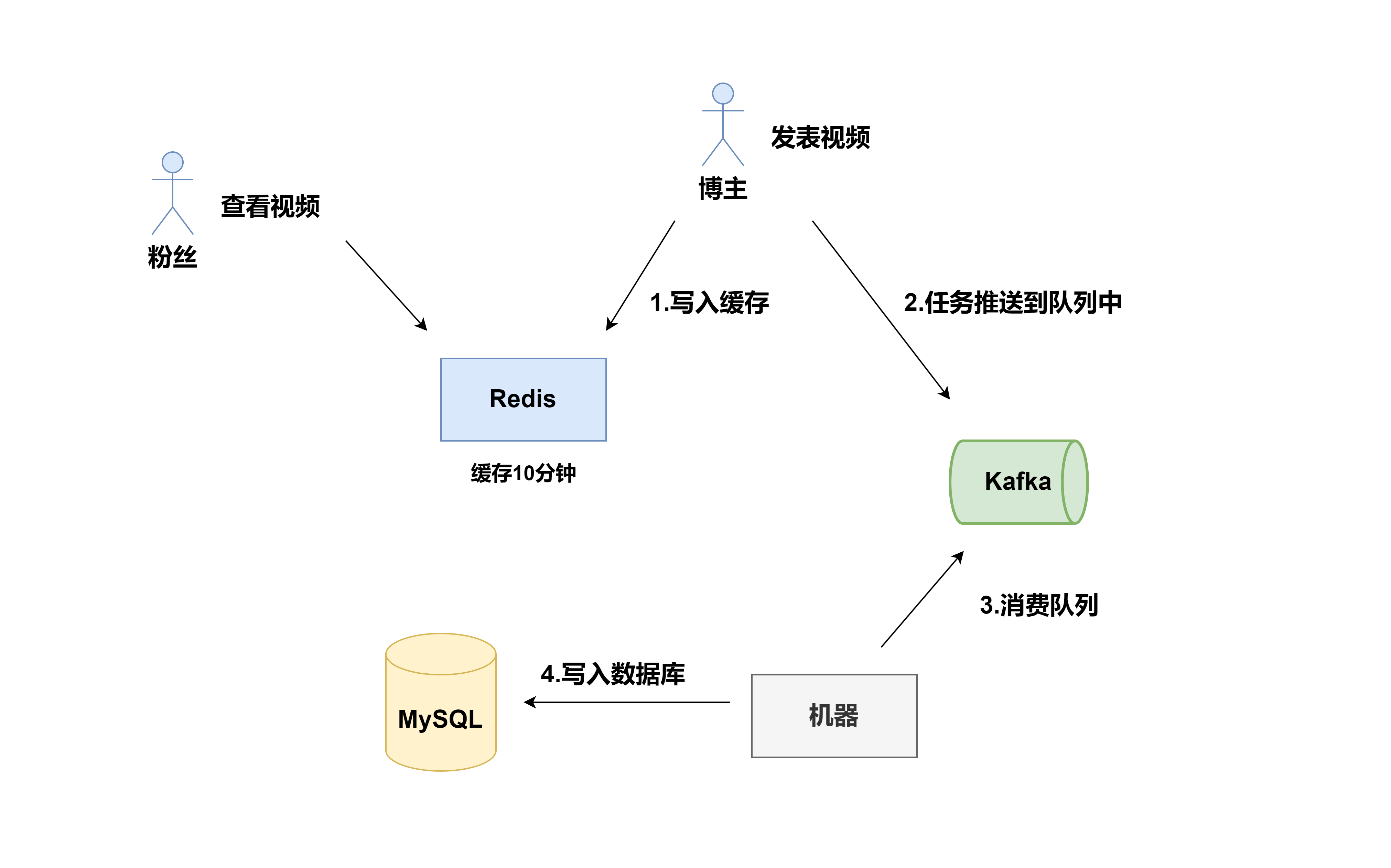
分布式系统:缓存与数据库一致性问题
前言 缓存设计是应用系统设计中重要的一环,是通过空间换取时间的一种策略,达到高性能访问数据的目的;但是缓存的数据并不是时刻存在内存中,当数据发生变化时,如何与数据库中的数据保持一致,以满足业务系统…...

JavaEE企业开发新技术5
目录 2.18 综合应用-1 2.19 综合应用-2 2.20 综合应用-3 2.21 综合应用-4 2.22 综合应用-5 Synchronized : 2.18 综合应用-1 反射的高级应用 DAO开发中,实体类对应DAO的实现类中有很多方法的代码具有高度相似性,为了提供代码的复用性,降低…...

mysql dump导出导入数据
前言 mysqldump是MySQL数据库中一个非常有用的命令行工具,用于备份和还原数据库。它可以将整个数据库或者特定的表导出为一个SQL文件,以便在需要时进行恢复或迁移。 使用mysqldump可以执行以下操作: 备份数据库:可以使用mysqld…...

刷题记录3
# 10 字符个数统计 描述 编写一个函数,计算字符串中含有的不同字符的个数。字符在 ASCII 码范围内( 0~127 ,包括 0 和 127 ),换行表示结束符,不算在字符里。不在范围内的不作统计。多个相同的字符只计算一次 例如,对…...
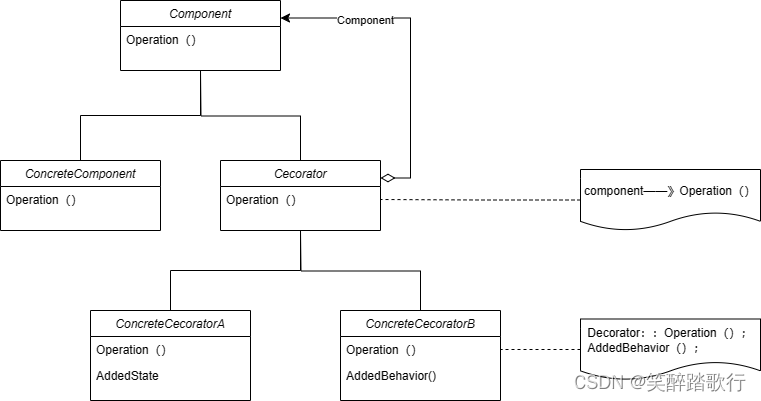
Decorator 装饰
意图 动态的给一个对象添加一些额外的职责。就增加功能而言,Decorator模式比生成子类更加灵活 结构 其中: Component定义一个对象接口,可以给这些对象动态的添加职责。ConcreteComponent定义一个对象,可以给这个对象添加一些职…...

SpringMVC:搭建第一个web项目并配置视图解析器
👉需求:用spring mvc框架搭建web项目,通过配置视图解析器达到jsp页面不得直接访问,实现基本的输出“hello world”功能。👩💻👩💻👩💻 1 创建web项目 1…...
一文了解HTTPS的加密原理
HTTPS是一种安全的网络通信协议,用于在互联网上提供端到端的加密通信,确保数据在客户端(如Web浏览器)与服务器之间传输时的机密性、完整性和身份验证。HTTPS的加密原理主要基于SSL/TLS协议,以下详细阐述其工作过程&…...

Ubuntu系统空间整理
查看文件大小命令 查看文件以及文件夹大小 ls -hl #查看文件大小,-h 表示Human-Readable ll -h #查看文件夹的大小 #du命令查看文件或文件夹的磁盘使用空间,–max-depth 用于指定深入目录的层数。#查看当前目录已经使用总大小及当前目录下一级文件或…...

PHP Storm 2024.1使用
本文讲的是phpstorm 2024.1最新版本激活使用教程,本教程适用于windows操作系统。 1.先去idea官网下载phpstorm包,我这里以2023.2最新版本为例 官网地址:https://www.jetbrains.com/zh-cn/phpstorm/ 2.下载下来后安装,点下一步 …...

王东岳-知鱼之乐【边读边记】1
2024-04-15 21:00 终于打算开始读这本书了,作者王东岳,第一次听到这个名字,是因为传说王东岳是李善友的师父,我是先从混沌学院知道的李善友,因为李善友还是有东西的,所以我对王东岳起步也是非常尊敬的。所以…...
迁移docker部署的GitLab
目录 1. 背景2. 参考3. 环境4. 过程4.1 查看原docker启动命令4.2 打包挂载目录传至新宿主机并创建对应目录4.3 保存镜像并传至新宿主机下4.4 新宿主机启动GitLab容器 5 故障5.1 容器不断重启5.2 权限拒绝5.3 容器内错误日志 6 重启容器服务正常7 总结 1. 背景 最近接到一个任务…...

今年消费新潮流:零元购商业模式
今天给大家推荐一种极具创新的电子商务模式:零元购商业模式 这个模式支持消费者以零成本或极低成本购买商品。这种模式主要通过返现、积分、优惠券等方式来减少支付金额,使消费者实现“零成本”购物的目标。 人民网在去年发表了一篇文章。 总结了一下&a…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

Device Mapper 机制
Device Mapper 机制详解 Device Mapper(简称 DM)是 Linux 内核中的一套通用块设备映射框架,为 LVM、加密磁盘、RAID 等提供底层支持。本文将详细介绍 Device Mapper 的原理、实现、内核配置、常用工具、操作测试流程,并配以详细的…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

Selenium常用函数介绍
目录 一,元素定位 1.1 cssSeector 1.2 xpath 二,操作测试对象 三,窗口 3.1 案例 3.2 窗口切换 3.3 窗口大小 3.4 屏幕截图 3.5 关闭窗口 四,弹窗 五,等待 六,导航 七,文件上传 …...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...
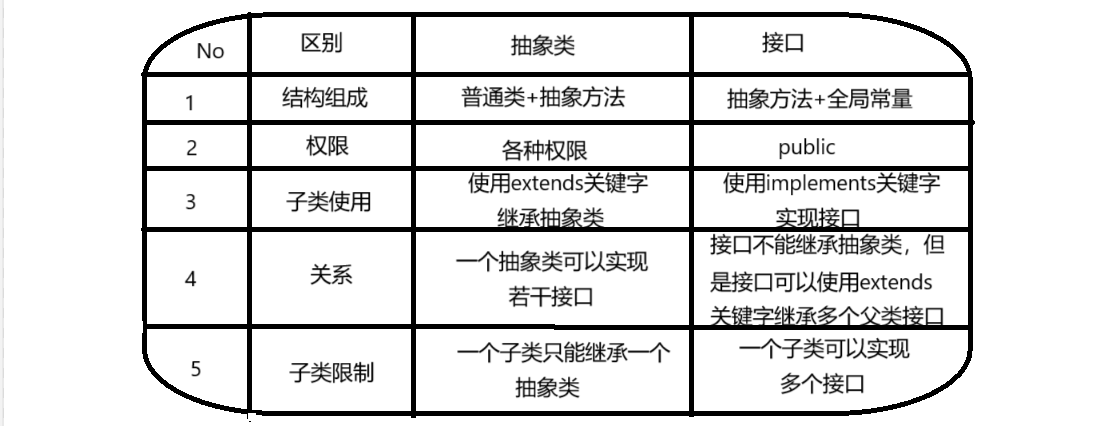
抽象类和接口(全)
一、抽象类 1.概念:如果⼀个类中没有包含⾜够的信息来描绘⼀个具体的对象,这样的类就是抽象类。 像是没有实际⼯作的⽅法,我们可以把它设计成⼀个抽象⽅法,包含抽象⽅法的类我们称为抽象类。 2.语法 在Java中,⼀个类如果被 abs…...

go 里面的指针
指针 在 Go 中,指针(pointer)是一个变量的内存地址,就像 C 语言那样: a : 10 p : &a // p 是一个指向 a 的指针 fmt.Println(*p) // 输出 10,通过指针解引用• &a 表示获取变量 a 的地址 p 表示…...