OceanBase V4.X中常用的SQL(一)
整理了一些在OceanBase使用过程中常用的SQL语句,这些语句均适用于4.x版本,并将持续进行更新。后续还将分享一些V4.x版本常用的操作指南,以便更好地帮助大家使用OceanBase数据库。
集群信息
版本查看
show variables like 'version_comment';集群ID和集群名查看
show parameters like '%cluster%';当前服务器信息查看
select * from DBA_OB_SERVERS;集群的zone信息查看
SELECT * FROM dba_ob_zones;集群所支持的字符集列表查看
select * from information_schema.collations;租户信息
查看租户创建基本信息
show create tenant xxx;查看对应 Unit 的配置。
SELECT * FROM oceanbase.dba_ob_units;查看租户对应的资源池(可以加 tenant_id 筛选)。
SELECT * FROM oceanbase.dba_ob_resource_pools;查看租户基本信息。
SELECT * FROM oceanbase.dba_ob_tenants;当前集群内的租户
select tenant_id,tenant_name,primary_zone,compatibility_mode from oceanbase.__all_tenant;RS 相关
切换rs leader
alter system switch rootservice leader zone='z1';查看 RS 任务
select * from __all_rootservice_event_history order by 1 desc limit 10;查看 rs 列表
show parameters like '%rootservice_list%';查看 rs leader,WITH_ROOTSERVER=yes
SELECT * FROM oceanbase.DBA_OB_SERVERS;资源分配
资源分配查询
服务器资源分配
select * from GV$OB_SERVERS;各租户资源分配
select t1.name resource_pool_name, t2.`name` unit_config_name,
t2.max_cpu, t2.min_cpu,
round(t2.memory_size/1024/1024/1024,2) mem_size_gb,
round(t2.log_disk_size/1024/1024/1024,2) log_disk_size_gb, t2.max_iops,
t2.min_iops, t3.unit_id, t3.zone, concat(t3.svr_ip,':',t3.`svr_port`) observer,
t4.tenant_id, t4.tenant_name
from __all_resource_pool t1
join __all_unit_config t2 on (t1.unit_config_id=t2.unit_config_id)
join __all_unit t3 on (t1.`resource_pool_id` = t3.`resource_pool_id`)
left join __all_tenant t4 on (t1.tenant_id=t4.tenant_id)
order by t1.`resource_pool_id`, t2.`unit_config_id`, t3.unit_id;查看 observer 内存、磁盘配置大小
select zone,svr_ip,svr_port,name,value
from __all_virtual_sys_parameter_stat
where
name in ('memory_limit','memory_limit_percentage','system_memory','datafile_size','datafile_disk_percentage')
order by svr_ip,svr_port;容量使用统计
默认情况下统计的是三/多副本的大小,可以通过增加 role 来获取单副本大小。
统计租户的大小
select t.tenant_name,
round(sum(t2.data_size)/1024/1024/1024,2) as data_size_gb,
round(sum(t2.required_size)/1024/1024/1024,2) as required_size_gb
from dba_ob_tenants t,cdb_ob_table_locations t1,cdb_ob_tablet_replicas t2
where t.tenant_id=t1.tenant_id
and t1.svr_ip=t2.svr_ip
and t1.tenant_id=t2.tenant_id
and t1.ls_id=t2.ls_id
and t1.tablet_id=t2.tablet_id
-- and t1.role='leader'
group by t.tenant_name
order by 3 desc;统计库的大小
select t1.database_name,
round(sum(t2.data_size)/1024/1024/1024,2) as data_size_gb,
round(sum(t2.required_size)/1024/1024/1024,2) as required_size_gb
from dba_ob_tenants t,cdb_ob_table_locations t1,cdb_ob_tablet_replicas t2
where t.tenant_id=t1.tenant_id
and t1.svr_ip=t2.svr_ip
and t1.tenant_id=t2.tenant_id
and t1.ls_id=t2.ls_id
and t1.tablet_id=t2.tablet_id
-- and t1.role='leader'
and t.tenant_name='test1'
group by t1.database_name
order by 3 desc;统计表/索引的大小
select t1.table_name,
round(sum(t2.data_size)/1024/1024/1024,2) as data_size_gb,
round(sum(t2.required_size)/1024/1024/1024,2) as required_size_gb
from dba_ob_tenants t,cdb_ob_table_locations t1,cdb_ob_tablet_replicas t2
where t.tenant_id=t1.tenant_id
and t1.svr_ip=t2.svr_ip
and t1.tenant_id=t2.tenant_id
and t1.ls_id=t2.ls_id
and t1.tablet_id=t2.tablet_id
-- and t1.role='leader'
and t.tenant_name='test1'
and t1.database_name='sbtest'
and t1.table_name='sbtest1'
group by t1.table_name
order by 3 desc;统计表对应的分区大小
select t1.table_name,t1.partition_name,
round(sum(t2.data_size)/1024/1024/1024,2) as data_size_gb,
round(sum(t2.required_size)/1024/1024/1024,2) as required_size_gb
from dba_ob_tenants t,cdb_ob_table_locations t1,cdb_ob_tablet_replicas t2
where t.tenant_id=t1.tenant_id
and t1.svr_ip=t2.svr_ip
and t1.tenant_id=t2.tenant_id
and t1.ls_id=t2.ls_id
and t1.tablet_id=t2.tablet_id
and t1.role='leader'
and t.tenant_name='test1'
and t1.database_name='sbtest'
and t1.table_name='sbtest1_part'
group by t1.table_name,t1.partition_name;内存占用
租户内存参数:
show parameters where name in ('memstore_limit_percentage','freeze_trigger_percentage');租户内存持有:
select TENANT_ID,SVR_IP,SVR_PORT,HOLD/1024/1024/1024,FREE/1024/1024/1024
from oceanbase.GV$OB_TENANT_MEMORY
where tenant_id =1002;租户内存模块占用:
select * from V$OB_MEMORY where tenant_id=1002;memstore占用:
select * from V$OB_MEMSTORE where tenant_id=1002;总体实际占用的memory 大小以及大小限制:
select * from oceanbase.GV$OB_SERVERS;memory_limit字段代表实际的memory_limit大小。
MEM_CAPACITY 是 memory_limit - system_memory
- 内存资源:包括两个配置,MIN_MEMORY和MAX_MEMORY,他们含义如下:
- MIN_MEMORY:表示为租户分配的最小内存规格,observer上,所有租户的MIN_MEMORY的总和不能超过物理可用内存大小MEM_CAPACITY
- MAX_MEMORY:表示为租户分配的最大内存规格,observer上,所有租户的MAX_MEMORY的总和不能超过物理可用内存的超卖值:MEM_CAPACITY * resource_hard_limit
表分区和日志流分布
表及分区
查看当前所有表详情
select * from __all_table查看所有分区详情
select * from __all_part查看表及分区leader分布
select * from oceanbase.DBA_OB_TABLE_LOCATIONS where ROLE='LEADER' and table_name='xxx'查看表及分区的预估数据量
select * from OCEANBASE.DBA_TAB_STATISTICS日志流
日志流分布
select SVR_IP,ROLE,count(*) from CDB_OB_LS_LOCATIONS group by SVR_IP,ROLE;查看日志流状态
select * from GV$OB_LOG_STAT;查看日志流详情
select svr_ip,svr_port,tenant_id,ls_id,replica_type,ls_state,tablet_count from __all_virtual_ls_info;常用hint
OceanBase Hint 用法
- 支持不带参数,如 /*+ FUNC */
- 支持带参数,如 /*+ FUNC(param) */
- 多个hint可以写到同一个注释中,用逗号分隔,如/*+ FUNC1, FUNC2(param) */
- SELECT语句的hint必须近接在关键字SELECT之后,其他词之前。如:SELECT /*+ FUNC */ …
- UPDATE, DELETE 语句的 hint 必须紧接在关键字 UPDATE,DELETE 之后
Hint 参数
Hint 相关参数名称、语义和语法如下表所示。
| 名称 | 语法 | 语义 |
| NO_REWRITE | NO_REWRITE | 禁止 SQL 改写。 |
| READ_CONSISTENCY | READ_CONSISTENCY (WEAK[STRONGFROZEN]) | 读一致性设置(弱/强)。 |
| INDEX_HINT | /*+ INDEX(table_name index_name) */ | 设置表索引。 |
| QUERY_TIMEOUT | QUERY_TIMEOUT(INTNUM) | 设置超时时间。 |
| LOG_LEVEL | LOG_LEVEL([']log_level[']) | 设置日志级别,当设置模块级别语句时候,以第一个单引号(')作为开始,第二个单引号(')作为结束;例如'DEBUG'。 |
| LEADING | LEADING([qb_name] TBL_NAME_LIST) | 设置联接顺序。 |
| ORDERED | ORDERED | 设置按照 SQL 中的顺序进行联接。 |
| FULL | FULL([qb_name] TBL_NAME) | 设置表访问路径为主表等价于 INDEX(TBL_NAME PRIMARY)。 |
| USE_PLAN_CACHE | USE_PLAN_CACHE(NONE[DEFAULT]) | 设置是否使用计划缓存:NONE:表示不使用计划缓存。DEFAULT:表示按照服务器本身的设置来决定是否使用计划缓存。 |
| USE_MERGE | USE_MERGE([qb_name] TBL_NAME_LIST) | 设置指定表在作为右表时使用 Merge Join。 |
| USE_HASH | USE_HASH([qb_name] TBL_NAME_LIST) | 设置指定表在作为右表时使用 Hash Join。 |
| NO_USE_HASH | NO_USE_HASH([qb_name] TBL_NAME_LIST) | 设置指定表在作为右表时不使用 Hash Join。 |
| USE_NL | USE_NL([qb_name] TBL_NAME_LIST) | 设置指定表在作为右表时使用 Nested Loop Join。 |
| USE_BNL | USE_BNL([qb_name] TBL_NAME_LIST) | 设置指定表在作为右表时使用 Block Nested Loop Join |
| USE_HASH_AGGREGATION | USE_HASH_AGGREGATION([qb_name]) | 设置聚合算法为 Hash。例如 Hash Group By 或者 Hash Distinct。 |
| NO_USE_HASH_AGGREGATION | NO_USE_HASH_AGGREGATION([qb_name]) | 设置 Aggregate 方法不使用 Hash Aggregate,使用 Merge Group By 或者 Merge Distinct。 |
| USE_LATE_MATERIALIZATION | USE_LATE_MATERIALIZATION | 设置使用晚期物化。 |
| NO_USE_LATE_MATERIALIZATION | NO_USE_LATE_MATERIALIZATION | 设置不使用晚期物化。 |
| TRACE_LOG | TRACE_LOG | 设置收集 Trace 记录用于 SHOW TRACE 展示。 |
| QB_NAME | QB_NAME( NAME ) | 设置 Query Block 的名称。 |
| PARALLEL | PARALLEL(INTNUM) | 设置分布式执行并行度。 |
| TOPK | TOPK(PRECISION MINIMUM_ROWS) | 设置模糊查询的精度和最小行数。 其中 PRECSION 为整型,取值范围[0,100],表示模糊查询的行数百分比;MINIMUM_ROWS 为最小返回行数。 |
sql audit
查询资源占用最多的SQL
select SQL_ID, avg(ELAPSED_TIME),
avg(QUEUE_TIME),
avg(ROW_CACHE_HIT + BLOOM_FILTER_CACHE_HIT + BLOCK_CACHE_HIT + DISK_READS) avg_logical_read,
avg(execute_time) avg_exec_time,
count(*) cnt,
avg(execute_time - TOTAL_WAIT_TIME_MICRO ) avg_cpu_time,
avg( TOTAL_WAIT_TIME_MICRO ) avg_wait_time,
WAIT_CLASS, avg(retry_cnt) from v$OB_SQL_AUDIT
group by 1
order by avg_exec_time * cnt desc
limit 10;最近100s某个租户的TOP SQL耗时监控
select /*+read_consistency(weak),query_timeout(100000000)*/ SQL_ID,count(1),avg(ELAPSED_TIME),avg(EXECUTE_TIME),avg(QUEUE_TIME),avg(AFFECTED_ROWS),avg(GET_PLAN_TIME)
from gv$ob_sql_audit
where time_to_usec(now(6))-request_time <1000000000
and tenant_name='test_tenant'
group by SQL_ID order by avg(ELAPSED_TIME)*count(1) desc limit 20;某个时间段请求次数排在 TOP-N 的 SQL
select SQL_ID, count(*) as QPS, avg(t1.elapsed_time) RT
from oceanbase.gv$ob_sql_audit t1
where tenant_id = 1001 and IS_EXECUTOR_RPC = 0
and request_time > (time_to_usec(now()) - 10000000)
and request_time < time_to_usec(now())
group by t1.sql_id order by QPS desc limit 10;定位所有SQL中消耗CPU最多的sql(或者不做聚合直接查询)
select sql_id, substr(query_sql, 1, 200) as query_sql, sum(elapsed_time - queue_time) sum_t, count(*) cnt, avg(get_plan_time), avg(execute_time)
from oceanbase.gv$ob_sql_audit
where tenant_id = 1001 and request_time > (time_to_usec(now()) - 10000000) and request_time < time_to_usec(now())
group by sql_id order by sum_t desc limit 10;
巡检、运维相关
自增值
获取每张表的自增值(下一个自增值)
select a.table_name,b.AUTO_INCREMENT_VALUE
from oceanbase.__all_table a, oceanbase.DBA_OB_AUTO_INCREMENT b
where a.table_id=b.AUTO_INCREMENT_KEY and a.autoinc_column_id=b.COLUMN_ID and a.TABLE_NAME='t3';DDL
查询DDL进度
mysql> select * from oceanbase.gv$session_longops\G;- sid:现在没有填值,为默认的 -1。
- trace_id: OBServer 程序日志的ID,可以用该ID来搜索相关的日志文件。
- opname:建索引时,会展示 create index 信息。
- target:建索引时,展示正在创建的索引名。
- svr_ip: 调度任务在哪个 OBServer 执行。
- svr_port:调度任务在哪个 OBServer 执行。
- start_time:索引构建开始时间,这里只精确到日期,跟 Oracle 是兼容的。
- elapsed_seconds: 索引构建执行的时间,单位为秒。
- time_remaining: 兼容 Oracle 的字段,暂时还没有实现剩余时间预测的能力。
- last_update_time: 统计信息收集的时间,也是精确到日期,跟 Oracle 是兼容的。
- message:里面包含了多个信息,ENANT_ID为租户 ID,TASK_ID为DDL 的任务 ID,STATUS 为 DDL 执行到的状态,REPLICA BUILD 指的是数据补全阶段,索引数据补全主要分为扫描主表数据,排序,写入到索引表阶段,三个阶段处理的行数分别对应于ROW_SCANNED, ROW_SORTED 和 ROW_INSERTED,因排序阶段可能会进行多轮归并,所以ROW_SORTED 的行数通常比 ROW_SCANNED 和 ROW_INSERTED 要多。
相关文章:
)
OceanBase V4.X中常用的SQL(一)
整理了一些在OceanBase使用过程中常用的SQL语句,这些语句均适用于4.x版本,并将持续进行更新。后续还将分享一些V4.x版本常用的操作指南,以便更好地帮助大家使用OceanBase数据库。 集群信息 版本查看 show variables like version_comment; …...

代码随想录算法训练营第五十天|123.买卖股票的最佳时机III 188.买卖股票的最佳时机IV
123.买卖股票的最佳时机III 这道题一下子就难度上来了,关键在于至多买卖两次,这意味着可以买卖一次,可以买卖两次,也可以不买卖。 视频讲解:https://www.bilibili.com/video/BV1WG411K7AR https://programmercarl.com…...
)
Composer安装与配置:简化PHP依赖管理的利器(包括加速镜像设置)
在现代的PHP开发中,我们经常会使用许多第三方库和工具来构建强大的应用程序。然而,手动管理这些依赖项可能会变得复杂和耗时。为了解决这个问题,Composer应运而生。Composer是一个PHP的依赖管理工具,它可以帮助我们轻松地安装、更…...

灯塔:抽象类和接口笔记
什么是构造方法 构造方法是一种特殊的方法,它是一个与类同名且没有返回值类型的方法。 构造方法的功能主要是完成对象的初始化。当类实例化一个对象时会自动调用构造方法,且构造方法和其他方法一样也可以重载 继承抽象类需要实现所有的抽象方法吗 继…...

mybatis 入门
MyBatis是一款持久层框架,免除了几乎所有的JDBC代码、参数及获取结果集工作。可以通过简单的XML或注解来配置和映射原始类型、接口和Java POJO为数据库中的记录。 1 无框架下的JDBC操作 1)加载驱动:Class.forName(“com.mysql.cj.jdbc.Driv…...

Spring-AI-上下文记忆
引入依赖 pom文件 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/P…...

内存函数memcpy、mommove、memset、memcmp
目录 1、memcpy函数 memcpy函数的模拟实现 2、memmove函数 memmove函数的模拟实现 3、memset函数 4、memcmp函数 1、memcpy函数 描述: C 库函数 void *memcpy(void *str1, const void *str2, size_t n) 从存储区 str2 复制 n 个字节到存储区 str1。 声明&…...

symfony框架介绍
Symfony是一个功能强大的PHP框架,它提供了丰富的组件和工具来简化Web开发过程。以下是一些关于Symfony的主要特点: 可重用性: Symfony提供了一系列可重用的PHP组件,这些组件可以用于任何PHP应用程序中。灵活性: Symfony允许开发者根据项目需求灵活选择使用哪些组件,而不是强…...
【计算机毕业设计】游戏售卖网站——后附源码
🎉**欢迎来到琛哥的技术世界!**🎉 📘 博主小档案: 琛哥,一名来自世界500强的资深程序猿,毕业于国内知名985高校。 🔧 技术专长: 琛哥在深度学习任务中展现出卓越的能力&a…...
LabVIEW电信号傅里叶分解合成实验
LabVIEW电信号傅里叶分解合成实验 电信号的分析与处理在科研和工业领域中起着越来越重要的作用。系统以LabVIEW软件为基础,开发了一个集电信号的傅里叶分解、合成、频率响应及频谱分析功能于一体的虚拟仿真实验系统。系统不仅能够模拟实际电路实验箱的全部功能&…...

Docker 学习笔记(六):挑战容器数据卷技术一文通,实战多个 MySQL 数据同步,能懂会用,初学必备
一、前言 记录时间 [2024-4-11] 系列文章简摘: Docker学习笔记(二):在Linux中部署Docker(Centos7下安装docker、环境配置,以及镜像简单使用) Docker 学习笔记(三)&#x…...

csdn怎么变得这么恶心,自动把一些好的文章分享改成了vip可见
刚刚发现以前发的一些文章未经过我同意,被csdn自动改成了VIP可见,这也太恶心了,第一你没分钱给我,第二我记录下一些问题也不是为了赚钱,而是为了提升自己和帮助别人,这样搞是想逼更多人走是吗?...

自然语言处理NLP:文本预处理Text Pre-Processing
大家好,自然语言处理(NLP)是计算机科学领域与人工智能领域中的一个重要方向,其研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。本文将介绍文本预处理的本质、原理、应用等内容,助力自然语言处理和模型的生成使用。 1.文本…...
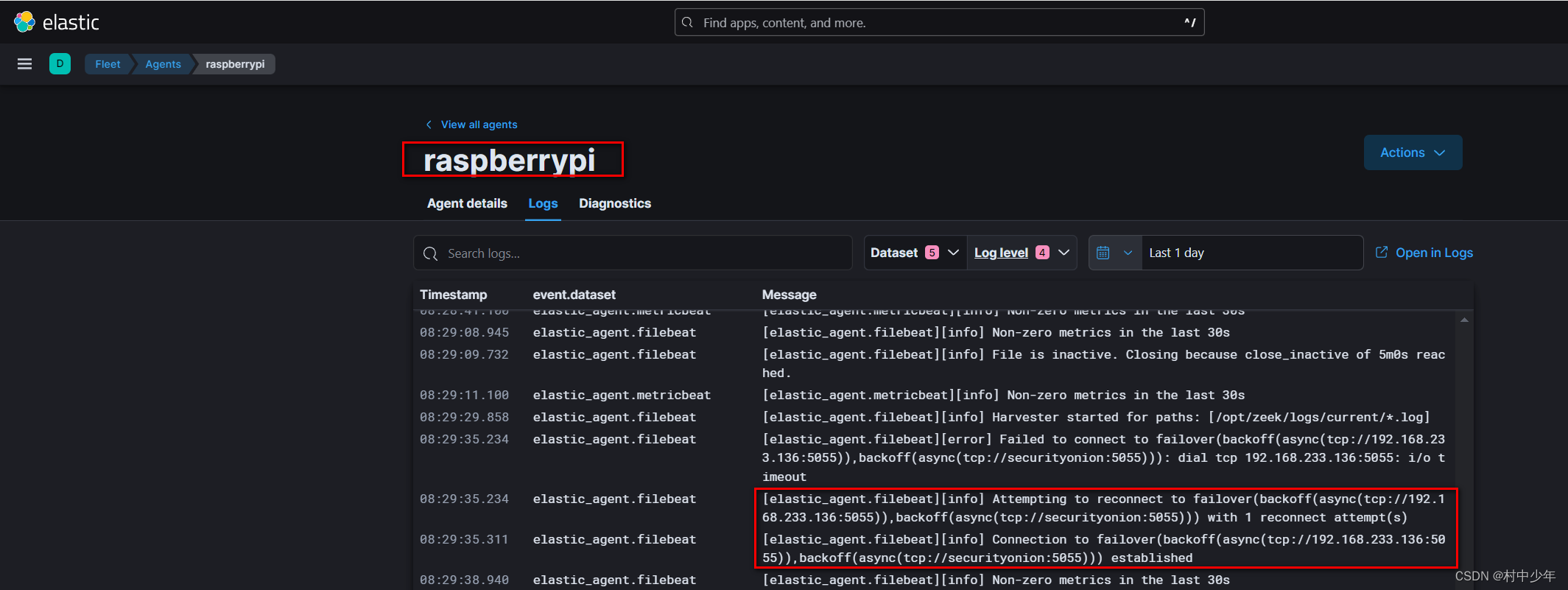
家庭网络防御系统搭建-虚拟机安装siem/securityonion网络连接问题汇总
由于我是在虚拟机中安装的security onion,在此过程中,遇到很多的网络访问不通的问题,通过该文章把网络连接问题做一下梳理。如果直接把securityonion 安装在物理机上,网络问题则会少很多。 NAT无法访问虚拟机 security onion虚拟…...
2024年外贸行业营销神器推荐
2024年外贸行业营销神器推荐:外贸人每天面对的不是国内客户,而是全球客户,相对于国内来说,会更加麻烦和繁琐,今天就码一篇2024年外贸行业营销神器的推荐文章,希望可以减轻各位外贸人的负担! 1、…...

k8s高可用集群部署介绍 -- 理论
部署官网参考文档 负载均衡参考 官网两种部署模式拓扑图和介绍 介绍两种高可用模式 堆叠 拓扑图如下(图片来自k8s官网): 特点:将etcd数据库作为控制平台的一员,由于etcd的共识算法,所以集群最少为3个&…...

【GDAL-Python】1-在Python中使用GDAL读写栅格文件
文章目录 1-概要2.代码实现 1-概要 提示:本教程介绍如何使用 Python 中的 GDAL 库将栅格数据读取为数组并将数组另存为GeoTiff 文件 视频地址:B站对应教程 目标: (1)读写GeoTiff影像; (2&…...

【C++】explicit关键字详解(explicit关键字是什么? 为什么需要explicit关键字? 如何使用explicit 关键字)
目录 一、前言 二、explicit关键字是什么? 三、构造函数还具有类型转换的作用 🍎单参构造函数 ✨引出 explicit 关键字 🍍多参构造函数 ✨为什么需要explicit关键字? ✨怎么使用explicit关键字? 四、总结 五…...
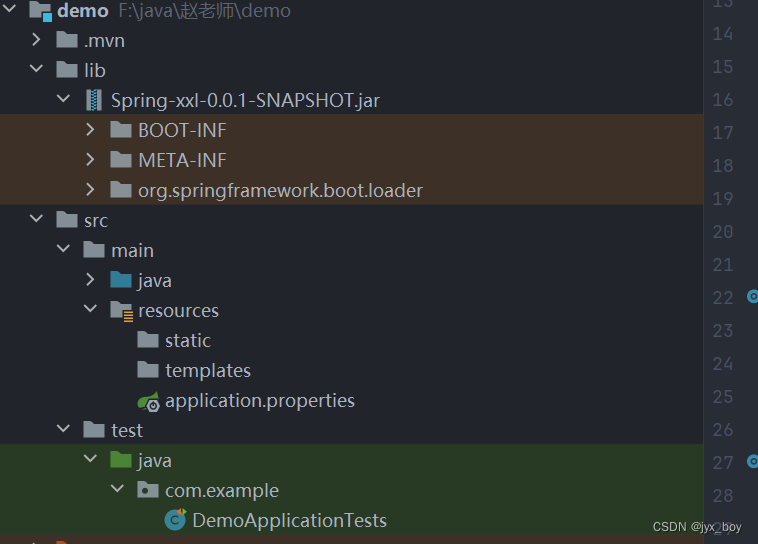
maven引入外部jar包
将jar包放入文件夹lib包中 pom文件 <dependency><groupId>com.jyx</groupId><artifactId>Spring-xxl</artifactId><version>1.0-SNAPSHOT</version><scope>system</scope><systemPath>${project.basedir}/lib/Spr…...

李沐37_微调——自学笔记
标注数据集很贵 网络架构 1.一般神经网络分为两块,一是特征抽取原始像素变成容易线性分割的特征,二是线性分类器来做分类 微调 1.原数据集不能直接使用,因为标号发生改变,通过微调可以仍然对我数据集做特征提取 2.pre-train源…...

赣州琴行哪家最可靠
在赣州,选择一家可靠的琴行对于孩子的钢琴启蒙和成长至关重要。今天我们就来聊聊赣州的几家知名琴行,看看哪家最适合您的孩子。1. 可六琴行:专注儿童钢琴启蒙,天天练琴模式为什么选择可六琴行?1.1 专注儿童钢琴启蒙具体…...

3步彻底解决Visual C++运行库问题:告别DLL缺失和应用崩溃
3步彻底解决Visual C运行库问题:告别DLL缺失和应用崩溃 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist Visual C Redistributable(微软Vi…...
:函数进阶:作用域与闭包)
Python从入门到精通(第11章):函数进阶:作用域与闭包
Python从入门到精通(第11章):函数进阶:作用域与闭包 开头导语 这是本系列第11章。前面你已经掌握函数的基本定义和调用方式,这一章在此基础上向前一步,解决三个实际问题:变量名冲突时 Python 到…...

s2-pro音色复用效果实测:同一参考音频在不同文本长度下的泛化能力
s2-pro音色复用效果实测:同一参考音频在不同文本长度下的泛化能力 1. 测试背景与目的 s2-pro作为Fish Audio开源的专业级语音合成模型镜像,其核心亮点之一是支持通过参考音频复用音色。这项功能在实际应用中极为实用,比如: 企业…...
】自注意力与多头机制:QKV、缩放与因果掩码)
【大语言模型基础(2)】自注意力与多头机制:QKV、缩放与因果掩码
文章目录摘要1. 为什么需要自注意力2. Q、K、V 到底是什么一个具体例子3. Attention 公式在干什么第一步:计算相似度第二步:做缩放第三步:softmax\mathrm{softmax}softmax 归一化第四步:对 ValueValueValue 做加权平均4. 为什么 G…...
)
ThinkPHP6+UniApp实战:手把手教你用宝塔面板部署Niushop V5.5.0多门店商城(含全插件配置)
ThinkPHP6UniApp实战:宝塔面板部署Niushop V5.5.0多门店商城全流程解析 在数字化转型浪潮中,电商系统的快速部署能力已成为技术团队的核心竞争力之一。本文将带您深入实战,从零开始完成Niushop V5.5.0多门店商城系统的完整部署。不同于基础教…...

数据库课程设计实战:构建文本分割结果的管理系统
数据库课程设计实战:构建文本分割结果的管理系统 每次做数据库课程设计,你是不是也头疼?选题要么太简单,像学生信息管理,做出来感觉没深度;要么太复杂,比如电商系统,光表关系就画晕…...

AI净界-RMBG-1.4企业落地:制造业产品手册高清图自动透明化处理
AI净界-RMBG-1.4企业落地:制造业产品手册高清图自动透明化处理 1. 引言:从“手动抠图”到“一键透明”的制造业痛点 在制造业,产品手册、宣传图册、官网详情页是展示企业实力的重要窗口。一张清晰、专业、背景干净的产品图,往往…...

Agentic Workflow与Workflow的协同之道——RAGFlow 0.20.0企业级实践解析
1. Agentic Workflow与Workflow的协同价值 企业级AI应用开发正面临一个关键矛盾:业务逻辑的确定性需求与LLM带来的灵活性优势如何平衡?RAGFlow 0.20.0给出的答案是让Workflow和Agentic Workflow在统一编排引擎中协同工作。这就像建筑行业中的预制构件与现…...

本地数据库工具革新:浏览器应用如何3分钟解决SQLite查看难题
本地数据库工具革新:浏览器应用如何3分钟解决SQLite查看难题 【免费下载链接】sqlite-viewer View SQLite file online 项目地址: https://gitcode.com/gh_mirrors/sq/sqlite-viewer 在数字化开发的日常工作流中,SQLite数据库文件查看往往成为效率…...