MySQL 基础使用
文章目录
- 一、Navicat 工具链接 Mysql
- 二、数据库的使用
- 1.常用数据类型
- 2. 建表 create
- 3. 删表 drop
- 4. insert 插入数据
- 5. select 查询数据
- 6. update 修改数据
- 7. delete 删除记录
- truncate table 删除数据
- 三、字段约束
- 字段
- 1. 主键 + 自增
- delete和truncate自增长字段的影响
- 2. 非空 not null
- 3. 唯一 unique
- 4. 默认值 default
- 5. 别名
- 字段别名
- 表别名
- 6. 过滤 distinct
- 四、条件查询
- 1. where 条件
- 2. 运算符的查询语句
- 比较运算符
- 逻辑运算符
- 3. 模糊查询 like
- 4. 范围查询
- 5. 空判断 is null
- 6. 其他练习
- 五、排序 order by
- 六、聚合函数
- 1. count 总记录数
- 2. max/min 最大/小值
- 3. sum 求和
- 4. avg 平均值
- 七、分组
- 1. 分组 group by
- 2. 分组后筛选 having
- having和where筛选的区别
- 八、数据分页
- 1. limit 显示指定的记录数
- 2. 数据分页显示
- 3. 求总页数
- 九、多表链接查询
- 写SQL三步法
- 1.内连接
- 2.左连接
- 3.右链接
- 4. 自关联
- 5. 子查询
- 6. 练习
- 十、MySQL 内置函数
- 1. 字符串函数
- 1. 拼接字符串 concat
- 2. 字符串长度 length
- 3. 截取字符串
- 练习
- 4. 去空格
- 2. 数学函数
- 1. 四舍五入 round
- 2. 随机数 rand
- 3. 日期、时间函数
- 十一、了解
- 1. 视图
- 2. 事务
- 回滚事务操作
- 提交事务
- 3. 索引
- 创建索引
- 查看索引
- 删除索引
- 索引优缺点
- 十二、基于命令行的mysql
- cmd登录之后的命令
- 在命令行下创建和删除数据库
一、Navicat 工具链接 Mysql
连接到Mysql数据库以后,创建数据库。

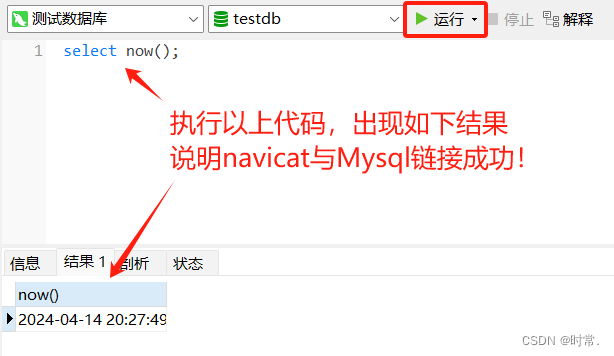
二、数据库的使用
1.常用数据类型
int 整数,有符号范围(-2147483648 ,2147483647),无符号范围(0,4294967295) ,如: int unsigned, 代表设置一个无符号的整数;
tinyint 小整数, 有符号范围(-128,127), 无符号范围(0,255), 如: tinyint unsigned,代表设置一个无符号的小整数
decimal 小数, 如decimal(5,2)表示共存5位数,小数占2位,不能超过2位;整数占3位,不能超过三位;
varchar 字符串, 如 varchar(3)表示最多存3个字符,一个中文或一个字母都占一个字符; .
datetime日期时间,范围(1000-01-01 00:00:00 ~ 9999-12-31 23:59:59),如 ‘2024-04-01 20:46:59’。
tips:
注释:--一般用快捷键ctrl + /
Sql 语言不区分大小写
ctrl + r快捷执行
2. 建表 create
语法:create table 表名(字段名 字段类型,字段名 字段类型,)
-- 例1: 创建表a,字段要求:nane (姓名),数据类型: varchar(字符串),长度为10
create table a(name varchar(10)
)
-- 例2:创建表b,字段要求: name(姓名), 数据类型为,varchar(字符串),长度为10;
-- height(身高),数据类型为decimal (小数),一共5位,其中3位整数,2位小数。
create table b(name varchar(10),height decimal(5,2)
);
-- 例3:创建表c,字段要求如下:id:数据类型为int(整数);
-- name姓名:数据类型为varchar (字符串)长度为20,
-- age年龄:数据类型为tinyint unsiqned (无符号小整数 0-255)
create table c(id int,name varchar(20),age tinyint unsigned
);
3. 删表 drop
语法1:drop table 表名;
语法2:drop table if exists 表名;
-- 删除表a(再执行删除表a会报错)
drop table a;-- 删除表a(如果表a存在,就利除表a,如果不存在,什么也不做)
drop table if exists a;
4. insert 插入数据
语法:insert into 表名 values(值,值,值);
-- 往表c 插入数据
insert into c values(001,'mario',23);
指定字段插入 语法:insert into 表名(字段名,字段名) values(值,值);
-- 表c 插人一条记录,只设置id和姓名name
insert into c(id,name) values(2,'anna');
一条语法插入多条记录:insert into 表名 values(值,值),(值,值),(值,值);
-- 表c插入多条记录,用一条insert语句,数据之间用逗号隔开
insert into c values(3,'jone',19),(4,'kool',21),(5,'amy',27);
5. select 查询数据
语法:select * from 表名;
-- 查询表c的所有字段
select * from c;-- 查询表c的name字段
select name from c;-- 查询表c的字段,顺序可自定义
select name,id,age from c;
6. update 修改数据
语法:update 表名 set 字段=值,字段=值 where 条件;
如果没有where条件代表修改表中所有的记录。
-- 修改表c,所有人的年龄(age字段)改为20
update c set age=20;
如果有where条件修改表中的记录。
-- 修改表c id为3的记录,姓名(name字段)改为 tigger,年龄(age字段)改为25
update c set name='tigger',age=25 where id=3;update c set name='图图' where name='amy';update c set age=age+1 where id=3;
7. delete 删除记录
语句:delete from 表名 where 条件;
--删除所有记录
delete from c;-- 删除表c id=3的记录
delete from c where id=3;delete from c where id>=3;
truncate table 删除数据
语法:truncate table 表名;
-- 删除表c中所有的记录
truncate table c;
delete 和 truncate区别:
在速度上:truncate > delete;
如果想删除部分数据用delete,注意带上where子句;
如果想保留表而将所有数据删除,自增长字段恢复从1开始,用truncate;
三、字段约束
字段
- 主键(primary key): 值不能重复. auto_increment代表值自增长;
- 非空(not null): 此字段不允许填写空值:
- 唯一(unique): 此字段的值不允许重复;
- 默认值(default): 当不填写此值时会使用默认值,如果填写时以填写为准。
1. 主键 + 自增
创建带约束的表和数据:
语法:
-- 创建表的主键 自增长,
create table 表名(字段名 数据类型 primary key auto_increment,字段名 数据类型 约束,...
);
-- 创建表a id自增长,
create table a(id int unsigned primary key auto_increment,name varchar(10),age int
);-- 插入数据
insert into a(name,age) values('brown',28),('green',28),('a',45);-- 插入 指定id值
insert into a values(5,'Jone',34);-- 再插入 不指定id (此时id自增长只看前一条数据的id值)
insert into a(name,age) values('popol',34);
注意:如果不指定字段,
主键自增长字段的值可以用占位符, 0或者null
insert into a values(0,'Jone1',32);
insert into a values(NULL,'Jone2',34);
delete和truncate自增长字段的影响
delete 删除数据:
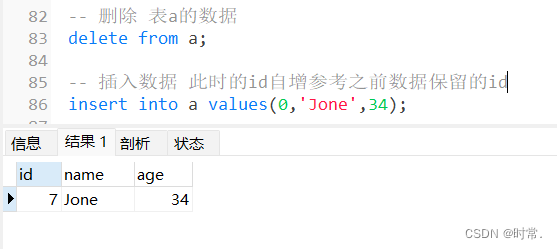
truncate 删除数据:
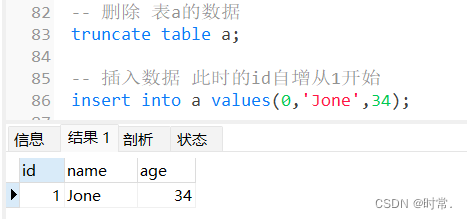
2. 非空 not null
语法:
-- not null 字段不能为空
create table 表名(字段名 数据类型 not null,...
);
create table b(id int unsigned,name varchar(10) not null,age int
);insert into b values(1,'anna',28)-- 报错:name定义非空,如果为空插入失败
insert into b(id,age) values(1,28)
3. 唯一 unique
语法:
-- 创建表a id自增长,
create table 表名(字段名 数据类型 unique,...
);
create table d(id int unsigned,name varchar(10) unique,age int
);insert into d values(1,'anna',28)
-- name 字段unique代表唯一 值不能重复插入
insert into d values(2,'anna',23)
4. 默认值 default
当一个字段有默认值约束插入数据时如果指定了值那么默认值无效;如早没有指定值,会使用默认值xx
语法:
create table 表名(字段名 数据类型 default xx,...
);
create table e(id int unsigned,name varchar(10),age int default 20
);-- 插入 指定age的值
insert into e values(1,'anna',28)
-- 插入 不指定age的值,会使用默认值 20
insert into e(id,name) values(2,'anna')
5. 别名
字段别名
通过字段名 as别名的语法可以给字没起一个别名,别名可以是中文
as可以省略
字段名as别名和 字段名 别名结果是一样的
-- 通过as给字段起一个别名
select name as 姓名,sex as 性别 from students;-- 别名的as可以省略
select name 姓名,sex 性别 from students;
表别名
-- 通过 表名as别名 起一个别名
select * from students as stu;-- 别名的as可以省略
select * from students stu;
6. 过滤 distinct
通过 select distinct 字段名,字段名 from 表名来过滤select查询结果中的重复记录。
select distinct sex,class from students;
四、条件查询
1. where 条件
-- 查询students 表中学号studentNo ="001"的记录
select * from students where studentNo ="001";-- 查询students 表中年龄age等于30的姓名name,班级class
select name,class from students where age=30;
2. 运算符的查询语句
比较运算符
< 小于
<= 小于等于
> 大于
>= 大于等于
!= 和 <> 不等于
-- 查询students 表中name (姓名)等于"小乔学生的age (年龄)
select age from students where name ='小乔';-- 查询students表中30岁和30岁以下的学生记录
select * from students where age <= 30;-- 查询class 班级为"1班"以外的学生记录
select * from students where class!="1班";
逻辑运算符
-- 条件 and 条件(条件都需满足)
-- 查询age年龄小于30, 并且sex 性别为"女"的同学记录
select * from students where age<30 and sex="女";-- 条件 or 条件(条件满足一个即可)
-- 查询sex性别为‘女’或者class班级为”1班’的学生记录
select * from students where sex='女' or class="1班";-- not 条件 (如果条件为满足,not后变为不满足。如果条件为不满足,not后变为满足;)
-- 查询hometown老家非天津的学生记录
select * from students where not hometown='天津';
3. 模糊查询 like
% 代表任意多个字符
_ 代表任意一个字符
-- 查询name姓名中以孙开头的学生记录
select * from students where name like '孙%';
-- 查询name为任意姓,名叫"乔"的学生记录
select * from students where name like '%乔';
-- 查询name姓名有'白"的学生记录
select * from students where name like '%白%';-- 查询name 姓名以"孙"开头,且名后只有一个字的学生记录
select * from students where name like '孙_';
-- 查询name 姓名为两个字的学生记录
select * from students where name like '__';
4. 范围查询
in(值,值,值) -->非连续范围查找
between 开始值 and 结束值 -->连续范围找包含开始值包含结束值
-- 查询hometown 家乡是"北京或"上海"或"广东'的学生记录
select * from students where hometown in('北京','上海','广东');
select * from students where hometown='北京' or hometown='上海' or hometown='广东';-- 查询age年龄为25至30的学生记录
select * from students where age between 25 and 30;
select * from students where age >=25 and age <=30;
5. 空判断 is null
注意: null 与' '是不同的
null: 代表什么都没有;
' ':代表长度为0的字符串;
is null: 是否为 null;
is not null: 是否不为null;
-- 空判断 is null
-- 查询card身份证为null的学生记录
select * from students where card is null;-- 非空判断 is not null
-- 查询card身份证非null 的学生记录
select * from students where card is not null;
6. 其他练习
-- 修改age为25, 并且name为"孙尚香"的学生,class 为"2班'
update students set class="2班" where age=25 and name="孙尚香";-- 删除class为"1班",并且age大于30的学生记录
delete from students where class="1班" and age > 30;
五、排序 order by
asc 代表从小到大升序,这可以省略。
desc 代表从大到小降序,不可以省略。
当一条select语句出现了where 和order by
语法:select * from 表名 where 条件 order by 字段1,字段2;
-- 查询所有学生记录,按age年龄从大到小排序,年龄相同时,再按studentNo 学号从小到大排序
select * from students order by age desc, studentNo;-- 查询所有男学生记录,按class班级从小到大排序,班级相同时,再按studentNo 学号再按学号从大到小排序
select * from students where sex="男" order by class,studentNo desc;
六、聚合函数
注意:
聚合函数不能用到 where后面的条件里。
聚合函数不能与普通字段同时出现在查询结果中
1. count 总记录数
count求select返回的记录总数
count(字段名)
-- 查询学生总数(查询stuents表有多少记录)
select count(*) from students;-- 查询女同学数量
select count(*) from students where sex ="女";-- 查询过滤相同性别后的总数
select count(distinct sex) from students;
2. max/min 最大/小值
max(字段名)
min(字段名)
-- 查询最大年龄
select max(age) from students;-- 查询女同学最大的年龄
select max(age) from students where sex ="女";select min(age) from students;
3. sum 求和
sum(字段名)
-- 查询女同学的年龄总和
select sum(age) from students where sex ="女";
4. avg 平均值
avg(字段名)
-- 查询女同学的平均年龄
select avg(age) from students where sex ="女";
avg的字段中如果有null值,这条null数据不参与计算平均值
七、分组
1. 分组 group by
按照字段分组。表示此字段相同的数据会被放到一个组中;
分组的目的是配合聚合函数,聚合函数会对每一组的数据分别进行统计;
语法:
select 字段1,字段2,聚台函数... from 表名 group by 字段1,字段2...
select * from 表名 where 条件 group by 字段 order by 字段;
group by就是配合聚合函数使用的,不然没有意义!
-- 查询 男女同学的数量
select sex,count(*) from students group by sex;-- 分别查询'1班',不同性别同学的数量
select sex,count(*) from students where class="1班" group by sex;
小练习:
统计各个班级学生总数、平均年龄、最大年龄、最小年龄。但不统计'3班",统计结果按班级名称从大到小排序
select class,count(*) 总数,avg(age),max(age),min(age) from students where
class!='3班' group by class order by class desc;
2. 分组后筛选 having
having 总是出现在group by语句之后。
having 后面可以使用聚合函数。
语法:
select字段1,字段2,聚合... from 表名 group by 字段1,字段2,字段3...having 字段1,...聚合...
-- 用where查询男生总数
-- where先筛选复合条件的记录,然后在聚合统计
select count(*) from students where sex="男"-- 用having查询男生总数
-- having先分组聚合统计,在统计的结果中筛选
select count(*) from students group by sex having sex="男";
having配合聚合函数的使用:
-- 求班级人数大于3人的班级名字
select class from students group by class having count(*) > 3;
having和where筛选的区别
where是对表的原始数据进行筛选。
having是对group by之后已经分过组的数据进行筛选。
having可以使用聚合函数,where不能用聚合函数
八、数据分页
1. limit 显示指定的记录数
语法:select * from表名where条件group by字段order by字段limit start, count
limit总是出现在select语句的最后
start代表开始行号,行号从0开始编号
count代表要显示多少行
省略start,默认从0开始,从第一行开始
-- 查询前三行记录
select * from students limit 0,3;
select * from students limit 3;-- 查询从第4条记录开始的三行记录
select * from students limit 3,3;
当有where或者group by或者order by ,limit总是出现在最后
-- 查询年龄最大同学的name
select name from students order by age desc limit 1;-- 查询年龄最小女同学的name
select name from students where sex='女' order by age limit 1;
2. 数据分页显示
m 每页显示多少条记录
n 第n页
把计算结果写到limit后面:imit(n-1)* m, m
-- 每页显示4条记录,第3页的结果
select * from students limit 8,4-- 每页显示4条记录,第2页的结果
select * from students limit 4,4
3. 求总页数
已知每页记录数,求一张表需要几页显示完 ,
。求总页数
。总页数/每页的记录数
。如果结果是整数,那么就是总页数,如果结果有小数,那么就在结果的整数上+1
-- 每页显示5条记录,分别多条select显示每页的记录
select * from students limit 5;
select * from students limit 5,5;
select * from students limit 10,5;
九、多表链接查询
写SQL三步法
- 搭框架
基本的select语句框架搭建起来,如果有多表,把相应的多表也联合进来。 - 看条件
决定where后面的具体条件 - 显示的字段
select后面到底要显示什么字段
1.内连接
把两张表相同的地方查询出来
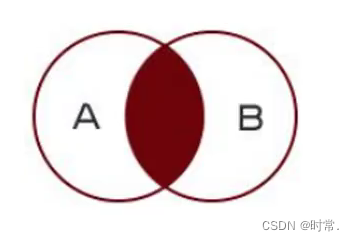
内链接最重要的是找对两张表要关联的字段
语法1:select * from 表1 inner join 表2 on 表1.字段=表2.字段;
语法2:select * from 表1,表2 where 表1.字段=表2.字段;(隐式内连接)
-- students表与socres内连接,只显示name,课程号,成绩
select name 姓名,courseNo 课程号,score 成绩
from students stu
inner join scores sc
on stu.studentNo = sc.studentNo;
- 带有 where条件的内连接
语法:select * from 表1 inner join 表2 on 表1.字段=表2.字段 where 条件;
-- 查询王昭君,并且成绩小于90 的信息,要求只显示姓名、课程号、成绩
select name,courseNo,score from students stu
inner join scores sc on stu.studentNo = sc.studentNo
where name='王昭君' and score < 90;
- 多表内链接
-- 三张表的链接
select * from students stu
inner join scores sc
on stu.studentNo = sc.studentNo
inner join courses cs
on sc.courseNo=cs.courseNo;-- 查询所有学生的" linux"课程成绩,要求只显示姓名、成绩、课程名
select name,score,coursename from students stu
inner join scores sc
on stu.studentNo = sc.studentNo
inner join courses cs
on sc.courseNo=cs.courseNo
where coursename='linux';
- order by内连接
-- 查询成绩最高的男生信息,要求显示姓名、课程名、成绩
select name,score,coursename from students stu
inner join scores sc
on stu.studentNo = sc.studentNo
inner join courses cs
on sc.courseNo=cs.courseNo
where sex='男'
order by score desc limit 1;
2.左连接
包括了内连接,同时还查询左表特有的内容
不存在的数据使用null填充
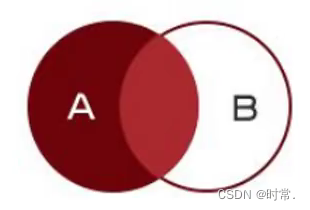
语法1:select * from 表1 left join 表2 on 表1.字段=表2.字段;
3.右链接
包括了内连接,同时还查询右表特有的内容
不存在的数据使用null填充
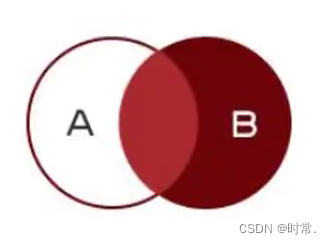
语法1:select * from 表1 right join 表2 on 表1.字段=表2.字段;
4. 自关联
自关联是同一张表做连接查询;
自关联下,一定找到同一张表可关连的不同字段。
-- 查询省的个数
select count(*) from areas where pid is null;-- 查询 广东省有多少个市
select * from areas a1 INNER JOIN areas a2 on a1.id=a2.pid
WHERE a1.name='广东省';
5. 子查询
子查询是嵌套到主查询里面的
子查询做为主查询的数据源或者条件
子查询是独立可以单独运行的查询语句
主查询不能独立独立运行,依赖子查询的结果
-- 查询 年龄比平均年龄大的所有学生
select * from students where age > (select avg(age) from students);
表级子查询:
-- 查询所有女生的信息和成绩
-- 子查询
select * from (select * from students where sex='女') stu
inner join scores sc on stu.studentNo = sc.studentNo-- 内连接
select * from students stu inner join scores sc
on stu.studentNo = sc.studentNo
where sex ='女';
6. 练习
表:
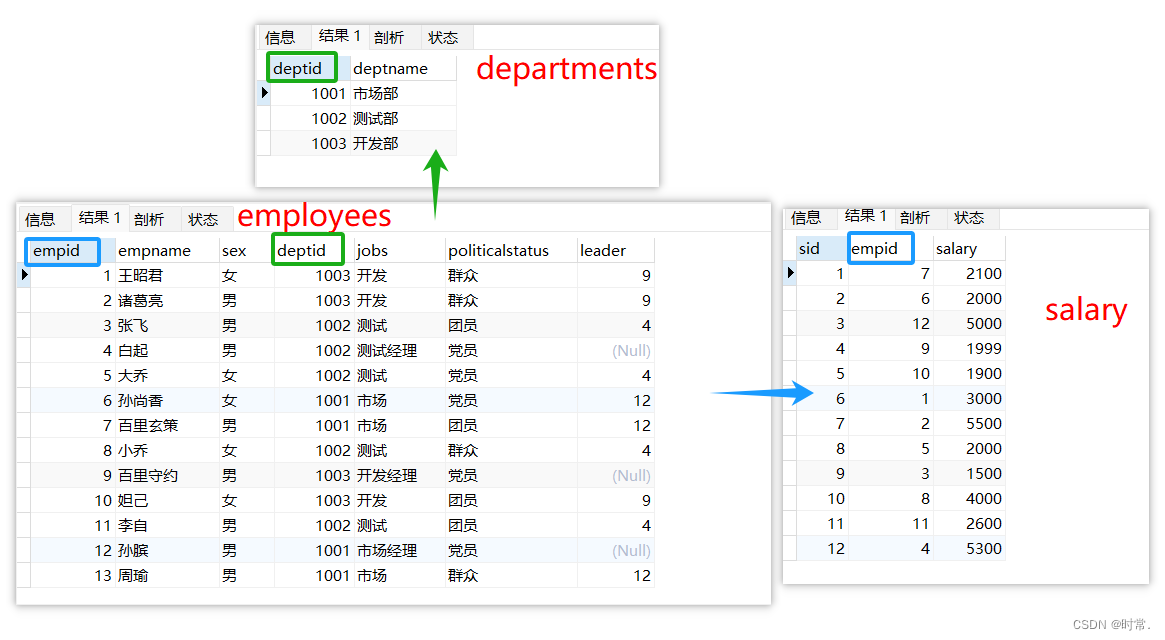
-- 1.1列出男职工的总数和女职工总数
select count(*) from employees group by sex;-- 1.2列出非党员职工的总数
select count(*) 总数 from employees where politicalstatus!='党员';-- 1.3列出所有职工工号,姓名以及所在部门名称
select employees.deptid,employees.empname,departments.deptname from employees
inner join departments on employees.deptid=departments.deptid;-- 1.4列出所有职工工号,姓名和对应工资
select employees.deptid,employees.empname,salary.salary from employees
inner join salary on employees.empid=salary.empid;-- 1.5列出领导岗的姓名以及所在部门名称
select employees.empname,departments.deptname from employees
inner join departments on employees.deptid=departments.deptid
where employees.leader is null;-- 1.6列出职工总人数大于4的部门号和总人数
select count(*) 总人数,departments.deptid from employees
inner join departments on employees.deptid=departments.deptid
group by employees.deptid
having count(*) > 4;-- 1.7列出职工总人数大于4的部门号和部门名称
select count(*) 总人数,departments.deptname from employees
inner join departments on employees.deptid=departments.deptid
group by employees.deptid
having count(*) > 4;-- 1.8列出开发部和测试部的职工号,姓名
select employees.empname,departments.deptid from employees
inner join departments on employees.deptid=departments.deptid
where departments.deptname in('开发部','测试部');-- 1.9列出市场部所有女职工的姓名和政治面貌
select e.empname,d.deptid from employees e
inner join departments d on e.deptid=d.deptid
where d.deptname='市场部' and e.sex='女';-- 1.10显示所有职工姓名和工资,包括没有工资的职工姓名
select e.empname,s.salary from employees e
left join salary s on e.empid=s.empid;-- 1.11求不姓孙的所有职工工资总和
select sum(salary) from employees e
inner join salary s on e.empid=s.empid
where not e.empname like '孙%';
十、MySQL 内置函数
内置函数可以用在 where条件后面,聚合函数一定不可以!
1. 字符串函数
1. 拼接字符串 concat
concat(参数1,参数2,参数3,参数n)
参数可以是数字,也可以是字符串
把所有的参数连接成一个完整的字符串
select concat(11,'sj21','000') -- 11sj21000
2. 字符串长度 length
注意:一个utf8格式的汉字,length返回3
select length('sj21000') -- 7
select length('我是猪猪') -- 12-- 查询表students 中name长度等于9 (三个utf8格式的汉字)的学生信息
select * from students where length(name) = 9;
3. 截取字符串
汉字、字母不区分
left(str,n)从左截取 n个字符
select left('是猪猪ooo',4) -- 是猪猪o
right(str,n)从右截取 n个字符
select right('是猪猪ooo',4) -- 猪ooo
substring(str,star,n)从star截取 n个字符
select substring('是猪猪ooo',2,3) -- 猪猪o
练习
-- 截取students 表中所有学生的姓
select left(name,1) from students;
select substring(name,1,1) from students;-- 查询students 表的card 字段,截取出生年月日,显示李白的生日
select name,substring(card,7,8) from students where name='李白';-- 查询students 表的所有学生信息,按生日从大到小排序
select * from students order by substring(card,7,8);
4. 去空格
ltrim(str)去除左边空格rtrim(str)去除右边空格trim(str)去除两边空格
select ltrim(' 是猪猪ooo ')
select rtrim(' 是猪猪ooo ')
select trim(' 是猪猪ooo ')
2. 数学函数
1. 四舍五入 round
round(n,d) n表示原数,d表示小数位置,默认为0
-- 四舍五入,保留整数位
select round(1.658) -- 2
-- 四舍五入,保留小数点后2位
select round(1.658,2) -- 1.66-- 查询students表中学生的平均年龄,并四舍五入
select round(avg(age)) from students;
2. 随机数 rand
round(); 每次运行会产生一个从0-1之间的浮点数
经常用rand进行随机排序: order by rand()
select rand();-- 从学生表中随机抽出一个学生
select name from students order by rand() limit 1;
3. 日期、时间函数
-- current date返回系统日期
select current_date();-- current time返回系统时间
select current_time();-- 返回系统日期与时间
select now();-- 插入当前时间
insert into a values(1,now())
十一、了解
1. 视图
视图就是对select语句的封装
视图可以理解为一张只读的表,针对视图只能用select,不能用delete和update
-- 创建一个视图,查询所有男生信息
create VIEW stu_male as
select * from students where sex='男';-- 使用视图
select * from stu_male INNER JOIN scores
on stu_male.studentNo = scores.studentNo;-- 删除视图
drop VIEW stu_male;
drop VIEW if EXISTS stu_male;
2. 事务
事务广泛的运用于订单系统、银行系统等多种场景;
事务是多条更改数据操作sql语句集合
一个集合数据有一致性,要么就都失败,要么就都成功
- begin --开始事务
- rollback --回滚事务,放弃对表的修改
- commit --提交事务,对表的修改生效
没有写begin代表没有事务,没有事务的表操作都是实时生效。
如果只写了begin,没有rollback,也没有commit,系统退出,结果是rollback
回滚事务操作
-- 开启事务,
-- 删除students 表中studentNo 为001 的记录,
-- 同时删除scores 表中studentNo 为001 的记录,
-- 回滚事务,两个表的删除同时放弃-- 开始事务
begin;
delete from students where studentNo='001';
delete from scores where studentNo='001';
-- 回滚事务,放弃更改
rollback;select * from students;
select * from scores;
提交事务
-- 开启事务,
-- 删除students 表中studentNo 为001 的记录,
-- 同时删除scores 表中studentNo 为001 的记录,
-- 提交事务,两个表的删除同时生效-- 开始事务
begin;
delete from students where studentNo='001';
delete from scores where studentNo='001';
-- 提交事务,一旦提交,两个删除操作同时生效
commit;select * from students;
select * from scores;
3. 索引
index
给表建立索引,目的是加快select查询的速度
如果一个表记录很少,几十条,或者几百条,不用索引
表的记录特别多,如果没有索引I,select语句效率会非常低
创建索引
语法:create index 索引名称 on 表名(字段名称(长度);
如果指定字段是字符串,需要指定长度,建议长度与定义字段时的长度一致;
字段类型如果不是字符串, 可以不填写长度部分。
-- 例1:为表students的age字段创建索引,名为age_ index
create index age_index on students(age);
-- 例2:为表students的name字段创建索引,名为name_ index
create index name_index on students(name(10);-- 查询表中age等于30的学生
-- 这里会自动调用age_index
select * from students where age=30;
-- 不会调用任何索引,因为sex字段没有索引
select * from students where sex='女';
查看索引
语法:show index from 表名;
show index from students;
删除索引
语法:drop index 索引名 on 表名;
drop index age_index on students;
索引优缺点
提高select的查询速度;
降低update,delete和insert语句的执行速度;
项目中80%以上是select,所以index必须的;
在实际工作中如果涉及到大量的数据修改操作,修改之前可以把索弓|删除修改完成后再把索引建立起来。
十二、基于命令行的mysql
mysql -h mysql的服务器的地址 -u 用户名 -p
如果是使用本机的mysql: mysql -u root -p
cmd登录之后的命令
show databases显示系统所有的数据库;- use 数据库名:使用指定的一个数据库
使用mydb数据库:use mydb show tables查看指定数据库有多少表
如果命令行默认字符集与数据库默认字符集不同
在windows默认字符集是gbk:set names gbk;
告诉mysql,客户端用的字符集是gbk
选择了数据库以后就可以查看数据库有多少表
在命令行中每条sgl语句用;结尾
可以通过desc表名查看一个表的字段结构:
desc students- 查看students每个字段的定义
在命令行下创建和删除数据库
create database 数据库名 default charset 字符集
--创建一个数据库mytest ,默认字符集为utf8
create database mytest default charset utf8;
-- 删除数据库mytest
drop database mytest
drop database if exists mytest;
相关文章:
MySQL 基础使用
文章目录 一、Navicat 工具链接 Mysql二、数据库的使用1.常用数据类型2. 建表 create3. 删表 drop4. insert 插入数据5. select 查询数据6. update 修改数据7. delete 删除记录truncate table 删除数据 三、字段约束字段1. 主键 自增delete和truncate自增长字段的影响 2. 非空…...

✌粤嵌—2024/4/3—合并K个升序链表✌
代码实现: /*** Definition for singly-linked list.* struct ListNode {* int val;* struct ListNode *next;* };*/ struct ListNode* merge(struct ListNode *l1, struct ListNode *l2) {if (l1 NULL) {return l2;}if (l2 NULL) {return l1;}struct Lis…...
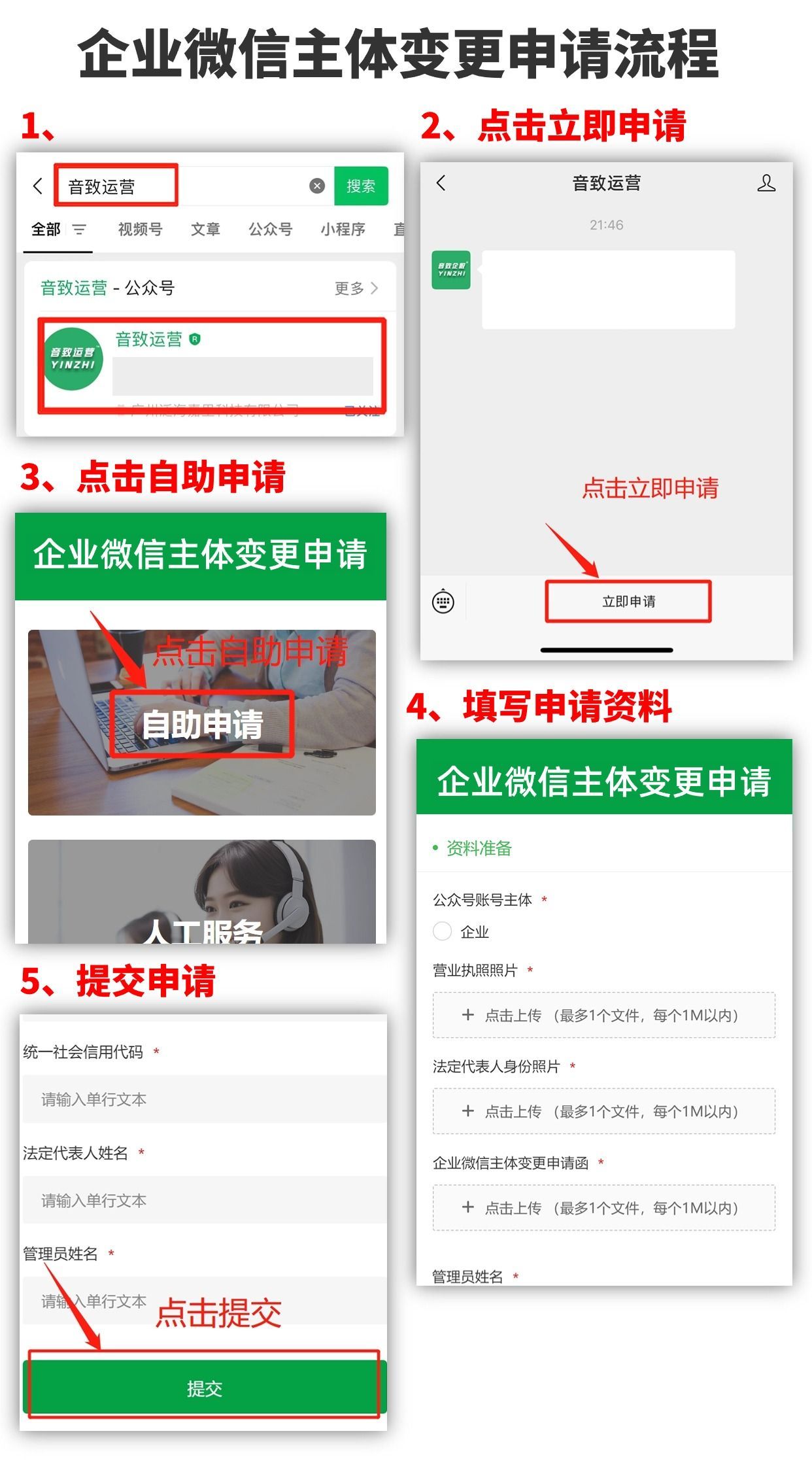
企业微信主体的修改方法
企业微信变更主体有什么作用?当我们的企业因为各种原因需要注销或已经注销,或者运营变更等情况,企业微信无法继续使用原主体继续使用时,可以申请企业主体变更,变更为新的主体。企业微信变更主体的条件有哪些࿱…...
:数据和代码分离)
C++的封装(十):数据和代码分离
封装的好处当然是非常多的。就不一一例举了。但封装也制造了访问壁垒。如果你是初学者,当你面对一堆封装好的C类一筹莫展,不知道从哪里下手时… 可以试试这个方法,数据和代码分离。 就是说,class只写方法,数据都放到…...

第十五届蓝桥杯大赛软件赛省赛 C/C++ 大学 B 组(基础题)
试题 C: 好数 时间限制 : 1.0s 内存限制: 256.0MB 本题总分:10 分 【问题描述】 一个整数如果按从低位到高位的顺序,奇数位(个位、百位、万位 )上 的数字是奇数,偶数位(十位、千位、十万位 &…...

模板的进阶
目录 非类型模板参数 C11的静态数组容器-array 按需实例化 模板的特化 函数模板特化 类模板特化 全特化与偏特化 模板的分离编译 总结 非类型模板参数 基本概念:模板参数类型分为类类型模板参数和非类类型模板参数 类类型模板参数:跟在class…...

微服务中Dubbo通俗易懂讲解及代码实现
当你在微服务架构中需要不同服务之间进行远程通信时,Dubbo是一个优秀的选择。Dubbo是一个高性能的Java RPC框架,它提供了服务注册、发现、调用、负载均衡等功能,使得微服务之间的通信变得简单而高效。 让我们来看一下Dubbo的通俗易懂的解释和…...

Unity HDRP Release-Notes
🌈HDRP Release-Notes 收集的最近几年 Unity各个版本中 HDRP的更新内容 信息收集来自自动搜集工具👈 💡HDRP Release-Notes 2023 💡HDRP Release-Notes 2022 💡HDRP Release-Notes 2021...

Chrome将网页保存为PDF的实战教程
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...

zotero7+Chat GPT实现ai自动阅读论文
关于这一部分的内容我在哔哩哔哩上发布了视频教程 视频链接见: zotero7GPT AI快速阅读文献_哔哩哔哩_bilibili 相关下载的官方链接如下: 1、zotero7 测试版官方下载链接: https://www.zotero.org/support/beta_builds 2、 InfiniCLOUD 云…...
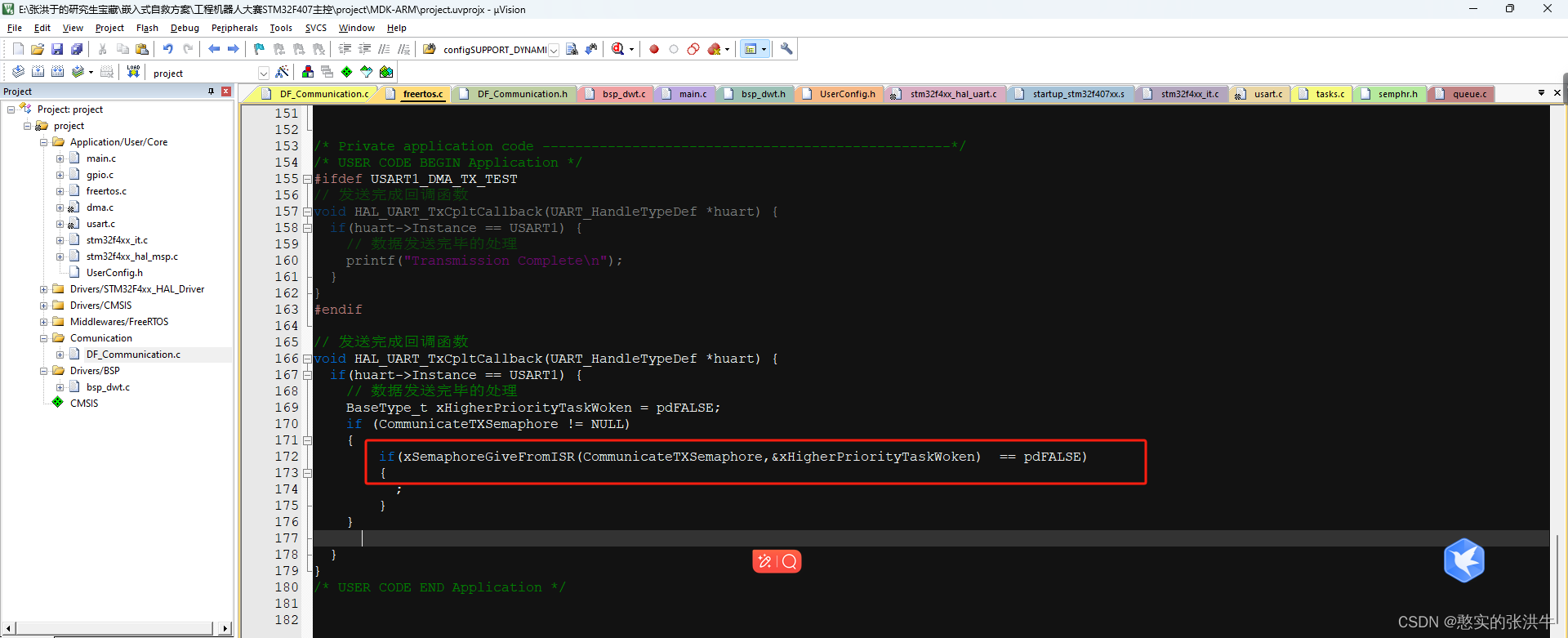
STM32外设配置以及一些小bug总结
USART RX的DMA配置 这里以UART串口1为例,首先点ADD添加RX和TX配置DMA,然后模式一般会选择是normal,这个模式是当DMA的计数器减到0的时候就不做任何动作了,还有一种循环模式,是计数器减到0之后,计数器自动重…...
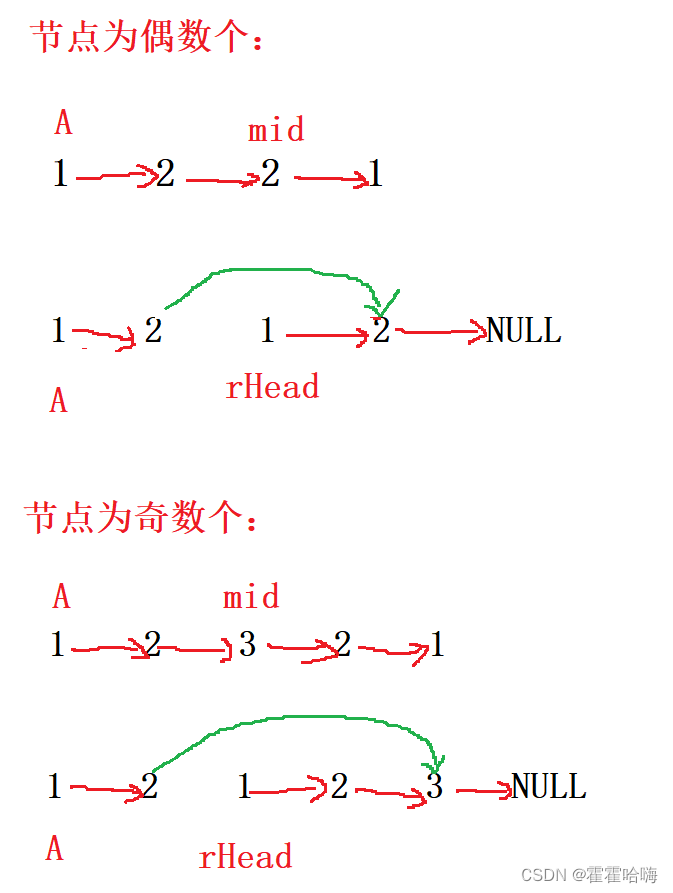
【数据结构与算法】:10道链表经典OJ
目录 1. 移除链表元素2. 反转链表2.1反转指针法2.2 头插法 3. 合并两个有序链表4. 分隔链表5. 环形链表6. 链表的中间节点7. 链表中倒数第K个节点8. 相交链表9. 环形链表的约瑟夫问题10. 链表的回文结构 1. 移除链表元素 思路1:遍历原链表,将 val 所在的…...

Python SQL解析和转换库之sqlglot使用详解
概要 Python SQLGlot是一个基于Python的SQL解析和转换库,可以帮助开发者更加灵活地处理和操作SQL语句。本文将介绍SQLGlot库的安装、特性、基本功能、高级功能、实际应用场景等方面。 安装 安装SQLGlot库非常简单,可以使用pip命令进行安装: pip install sqlglot安装完成后…...

NULL—0—nullptr 三者关系
1.概述 NULL,0,nullptr值都是0,但是类型不同,但是由于C头文件中NULL定义宏混乱,可能是int 0,也可能是(void*)0; 所以在C11及以后的标准中引入新的空指针nullptr,nullptr就是(void*)0ÿ…...

Nginx 请求的 匹配规则 与 转发规则
博文目录 文章目录 URL 与 URI匹配规则案例说明 转发规则响应静态资源案例说明 转发动态代理案例说明案例说明 URL 与 URI 通常, 一个 URL 由以下部分组成 scheme://host:port/path?query#fragment scheme: 协议, 如 http, https, ftp 等host; 主机名或 IP 地址post: 端口…...

OWASP发布10大开源软件风险清单
3月20日,xz-utils 项目被爆植入后门震惊了整个开源社区,2021 年 Apache Log4j 漏洞事件依旧历历在目。倘若该后门未被及时发现,那么将很有可能成为影响最大的软件供应链漏洞之一。近几年爆发的一系列供应链漏洞和风险,使得“加强开…...

大学生前端学习第一天:了解前端
引言: 哈喽,各位大学生们,大家好呀,在本篇博客,我们将引入一个新的板块学习,那就是前端,关于前端,GPT是这样描述的:前端通常指的是Web开发中用户界面的部分,…...
公安机关人民警察证照片采集规范及自拍制作电子版指南
在当今社会,证件照的拍摄已成为我们生活中不可或缺的一部分。无论是办理身份证、驾驶证还是护照,一张规范的证件照都是必需的。而对于公安机关的人民警察来说,证件照片的采集更是有着严格的规范和要求。本文将为您详细介绍公安机关人民警察证…...

使用Python插入100万条数据到MySQL数据库并将数据逐步写出到多个Excel
Python插入100万条数据到MySQL数据库 步骤一:导入所需模块和库 首先,我们需要导入 MySQL 连接器模块和 Faker 模块。MySQL 连接器模块用于连接到 MySQL 数据库,而 Faker 模块用于生成虚假数据。 import mysql.connector # 导入 MySQL 连接…...

【备忘录】openssl记录
openssl genrsa -out ca.key 2048 openssl req -x509 -new -nodes -key ca.key -days 10000 -out ca.crt -subj “/CCN/STBeijing/LBeijing/Okubernetes/OUKubernetes-manual/CNkubernetes-ca” openssl genrsa -out etcd-ca.key 2048 openssl req -x509 -new -nodes -key etc…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...
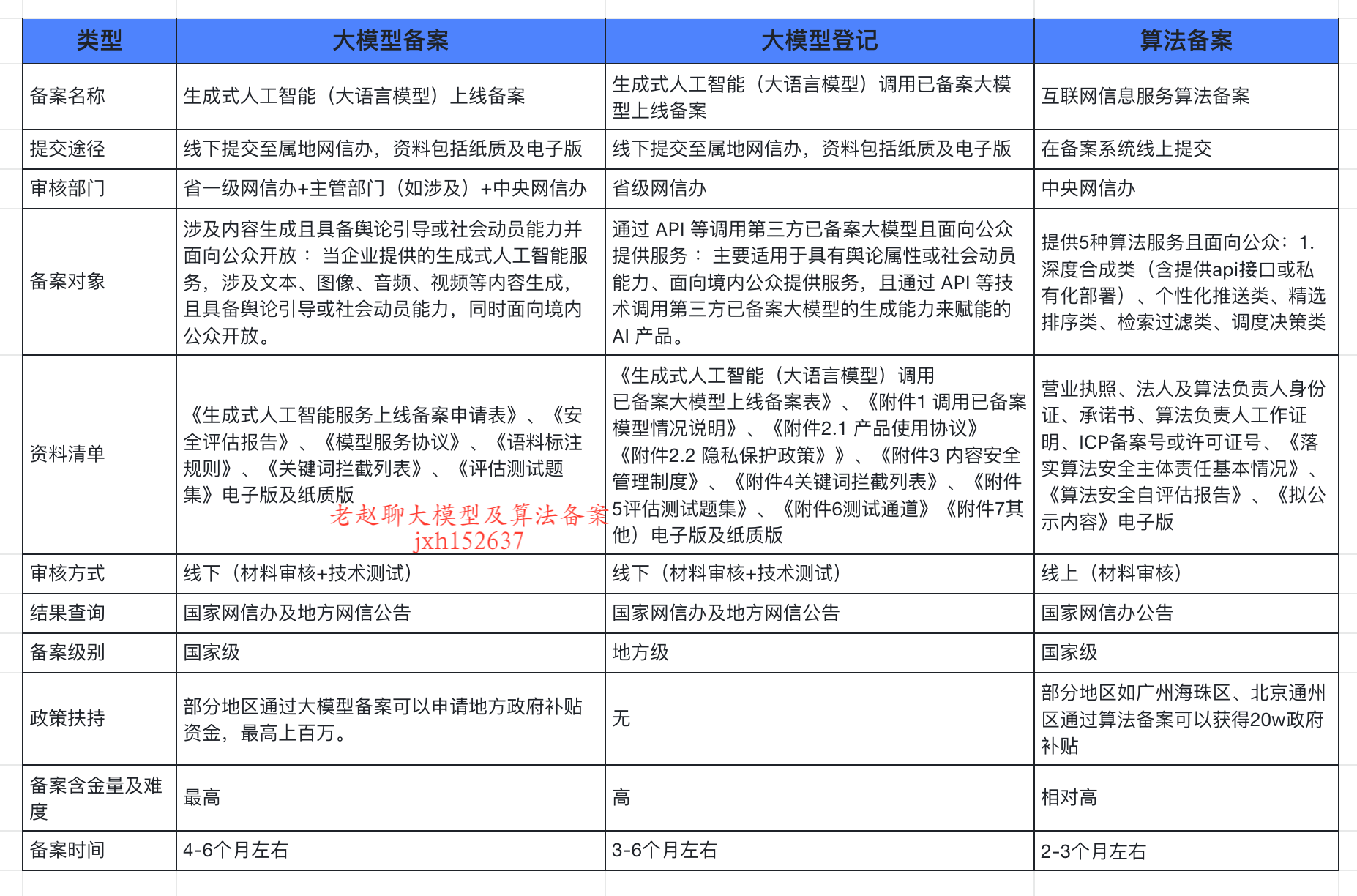
企业大模型服务合规指南:深度解析备案与登记制度
伴随AI技术的爆炸式发展,尤其是大模型(LLM)在各行各业的深度应用和整合,企业利用AI技术提升效率、创新服务的步伐不断加快。无论是像DeepSeek这样的前沿技术提供者,还是积极拥抱AI转型的传统企业,在面向公众…...

Matlab实现任意伪彩色图像可视化显示
Matlab实现任意伪彩色图像可视化显示 1、灰度原始图像2、RGB彩色原始图像 在科研研究中,如何展示好看的实验结果图像非常重要!!! 1、灰度原始图像 灰度图像每个像素点只有一个数值,代表该点的亮度(或…...