大模型预测结果导入到Doccano,人工修正预测不准的数据
背景
使用大语言模型做实体识别的实验时,发现大模型关于实体的边界预测一直不准。
主要原因在于当时找了很多同学标注数据,由于不同组同学关于实体的边界没有统一,故导致数据集中实体边界也没统一。
(找太多人标,会有这样的缺点)
如果重新标注数据,那么之前的标的数据就浪费了,而且又得折腾人来标。
虽然之前标的数据不好,但训练出的大模型,还是学到了一些东西。于是便打算让训练后的大模型预测,将大模型预测的结果导入到Doccano,再人工修正大模型预测不准的实体,这样可以减轻人工标注压力还能轻易获得更多的数据集。
简介
- 展示大模型预测输出的数据格式;
- 展示Doccano 命名实体识别导入的数据集格式;
- 提供将大模型输出数据转为Doccano 导入数据集格式代码;
大模型预测结果的样例如下:
{"instruction": "你是专门进行实体抽取的专家。请从text中抽取出符合schema定义的实体,不存在的实体类型返回空列表。请按照JSON字符串的格式回答。schema:['数据', '项目', '任务'], text:三大攻坚战取得关键进展", "input": "", "output": "{\"数据\": [], \"项目\": [\"三大攻坚战\"], \"任务\": []}", "predict": {"数据": [], "项目": ["三大攻坚战取得关键进展"], "任务": []}
}
Doccano 导入的数据集样例如下:
{"id":17168,"text":"三大攻坚战取得关键进展","label":[[0,5,"任务"]],"Comments":[]}
大模型输出数据转为Doccano 代码
找出模型预测的实体,在text句子的开始下标和结束下标:
def find_substring_indices(parent_string, substring): start_index = parent_string.find(substring) if start_index != -1:end_index = start_index + len(substring)return start_index, end_index else: return -1, -1
import redef tran_llm_doccano(input_file, output_file, schema):doccano_format = {"text": None,"label": [],"Comments": []}def _find_text(text):pattern = r'text:(.*?)",' match = re.search(pattern, text, re.MULTILINE)text_content = match.group(1)return text_contentwith open(input_file, 'r') as f:with open(output_file, 'w') as w:for line in f:text = _find_text(line)doccano_format["text"] = textdata = json.loads(line)predict = data["predict"]tmp = []for ent_cls in schema:for predict_ent_name in predict[ent_cls]:start_idx, end_idx = find_substring_indices(text, predict_ent_name)if start_idx == -1 or end_idx == -1:continuetmp.append([start_idx, end_idx, ent_cls])doccano_format["label"] = tmpw.write(json.dumps(doccano_format, ensure_ascii=False) + '\n')schema = ['数据', '项目', '任务']
tran_llm_doccano('data.jsonl', "doccano_import.jsonl", schema)
tran_llm_doccano(input_file, output_file, schema):
- input_file 大模型预测的结果文件;
- output_file 到入到 doccano的文件;
- schema 实体类别;
将 大模型的预测结果转换后的Doccano格式的 output_file 文件,导入到Doccano的结果如下图所示:

开源
完整的代码点击查看: https://github.com/JieShenAI/csdn/blob/main/24/04/tran_llm_doccano/tran_llm_doccano.ipynb
相关文章:
大模型预测结果导入到Doccano,人工修正预测不准的数据
背景 使用大语言模型做实体识别的实验时,发现大模型关于实体的边界预测一直不准。 主要原因在于当时找了很多同学标注数据,由于不同组同学关于实体的边界没有统一,故导致数据集中实体边界也没统一。 (找太多人标,会有…...

python三方库_ciscoconfparse学习笔记
文章目录 介绍使用基本原理父子关系 属性ioscfg 获取配置信息,返回列表is_config_line 判断是否是配置行is_intf 判断IOSCfgLine是不是interfaceis_subintf 判断IOSCfgLine是不是子接口lineage 不知道用法is_ethernet_intf 判断IOSCfgLine是否是以太网接口is_loopback_intf 判断…...

HDFS详解(Hadoop)
Hadoop 分布式文件系统(Hadoop Distributed File System,HDFS)是 Apache Hadoop 生态系统的核心组件之一,它是设计用于存储大规模数据集并运行在廉价硬件上的分布式文件系统。 1. 分布式存储: HDFS 将文件分割成若干块…...
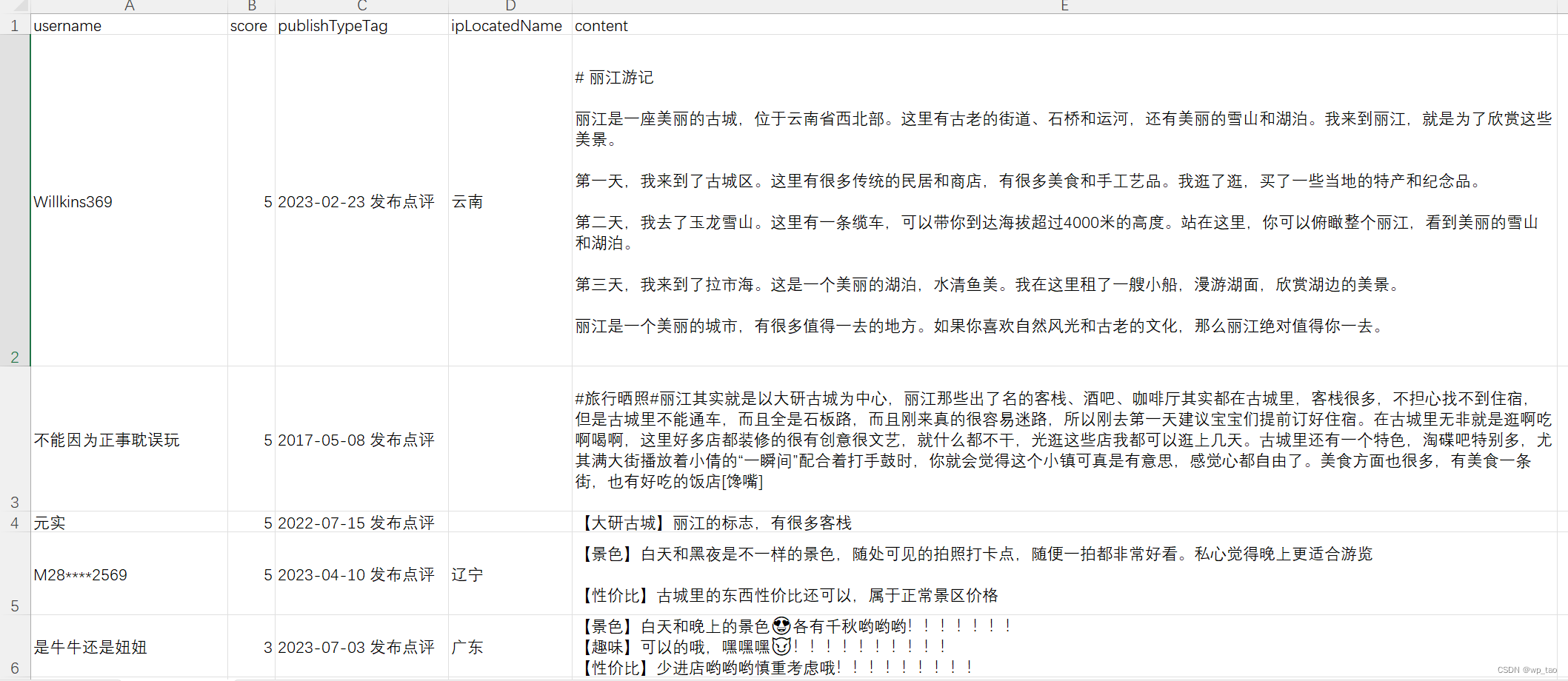
python创建word文档并向word中写数据
一、docx库的安装方法 python创建word文档需要用到docx库,安装命令如下: pip install python-docx 注意,安装的是python-docx。 二、使用方法 使用方法有很多,这里只介绍创建文档并向文档中写入数据。 import docxmydocdocx.Do…...
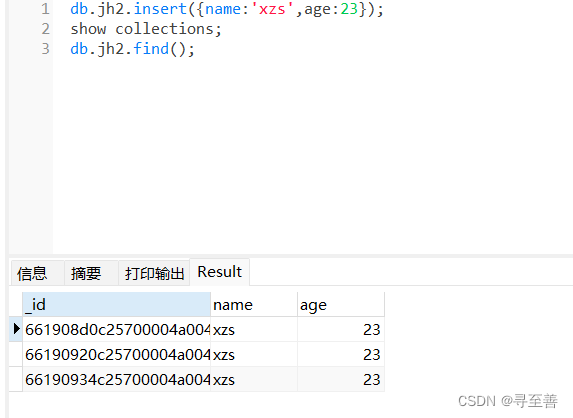
MongoDB的安装配置及使用
文章目录 前言一、MongoDB的下载、安装、配置二、检验MongoDB是否安装成功三、Navicat 操作MongoDB四、创建一个集合,存放三个文档总结 前言 本文内容: 💫 MongoDB的下载、安装、配置 💫 检验MongoDB是否安装成功 ❤️ Navicat 操…...

Go学习路线
Go学习路线 文章目录 Go学习路线入门阶段一、Go基础和Goland的安装二、学习日志文件及配置文件三、学习mysql四、html,css,js快速入门五、写一个简单的前后端分离的记事本项目六、Linux快速入门七、Docker快速入门八、Git命令快速入门九、使用Docker打包…...
安全大脑与盲人摸象
21世纪是数字科技和数字经济爆发的时代,互联网正从网状结构向类脑模型进行进化,出现了结构和覆盖范围庞大,能够适应不同技术环境、经济场景,跨地域、跨行业的类脑复杂巨型系统。如腾讯、Facebook等社交网络具备的神经网络特征&…...

如何使用Git-Secrets防止将敏感信息意外上传至Git库
关于Git-Secrets Git-secrets是一款功能强大的开发安全工具,该工具可以防止开发人员意外将密码和其他敏感信息上传到Git库中。 Git-secrets首先会扫描提交的代码和说明,当与用户预先配置的正则表达式模式匹配时,便会阻止此次提交。该工具的优…...
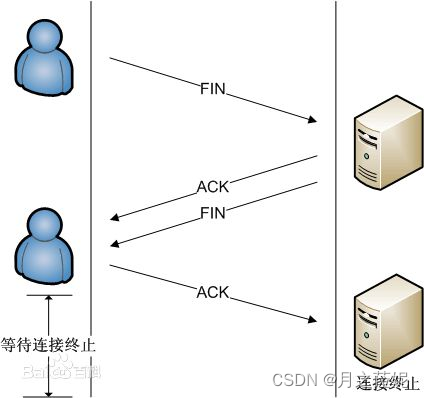
Day 14 网络协议
常见网络设备:交换机 路由器 中继器 多协议网关(路由器的前身) 交换机:用于连接统一网络的设备,实现内网设备通信。 从广义上分为:局域网交换机,广域网交换机 从网络构成分为:接…...
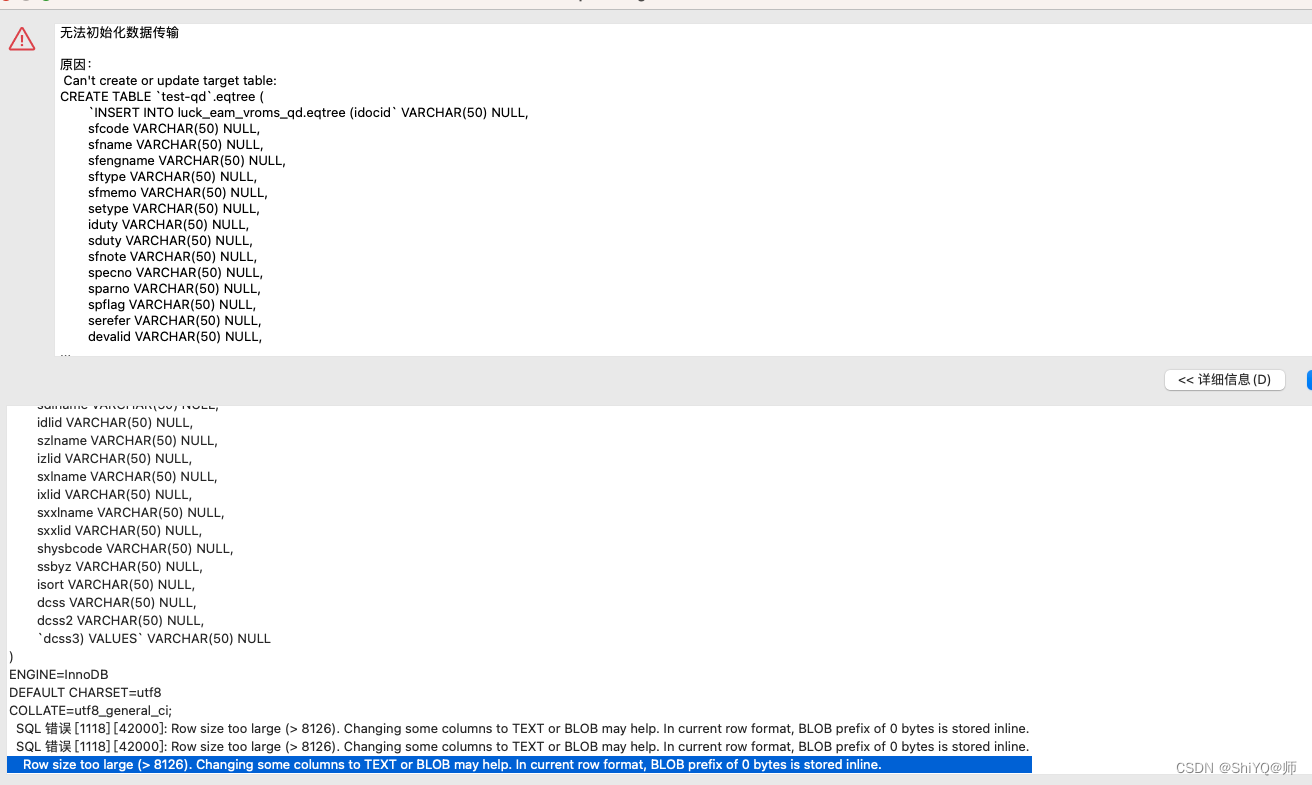
msyql中SQL 错误 [1118] [42000]: Row size too large (> 8126)
场景: CREATE TABLE test-qd.eqtree (INSERT INTO test.eqtree (idocid VARCHAR(50) NULL,sfcode VARCHAR(50) NULL,sfname VARCHAR(50) NULL,sfengname VARCHAR(50) NULL,…… ) ENGINEInnoDB DEFAULT CHARSETutf8 COLLATEutf8_general_ci;或 alter table eqtre…...
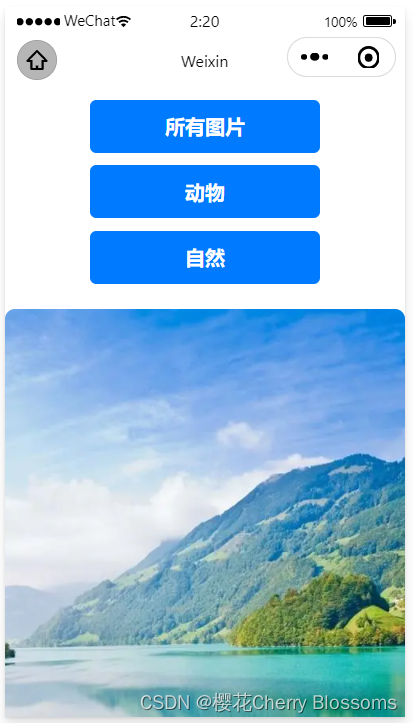
实验六 智能手机互联网程序设计(微信程序方向)实验报告
实验目的和要求 请完成创建图片库应用,显示一系列预设的图片。 提供按钮来切换显示不同类别的图片。 二、实验步骤与结果(给出对应的代码或运行结果截图) 1.WXML <view> <button bindtap"showAll">所有图片</but…...

Linux环境下,让Jar项目多线程部署成为可能
欢迎来到我的博客,代码的世界里,每一行都是一个故事 Linux环境下,让Jar项目多线程部署成为可能 前言背景介绍使用sh脚本实现使用systemd来实现使用docker-compose实现 前言 在当今互联网时代,应用程序的高可用性和性能是至关重要…...

k8s调度场景
15个KUBERNETES调度情景实用指南 Kubernetes调度是确保集群中的Pod在适当节点上运行的关键组件。通过灵活配置调度策略,可以提高资源利用率、负载平衡和高可用性。 在本文中,我们将深入探讨一些实际的Kubernetes调度场景,并提供相应的配置示…...

基于小程序实现的餐饮外卖系统
作者主页:Java码库 主营内容:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app等设计与开发。 收藏点赞不迷路 关注作者有好处 文末获取源码 技术选型 【后端】:Java 【框架】:spring…...
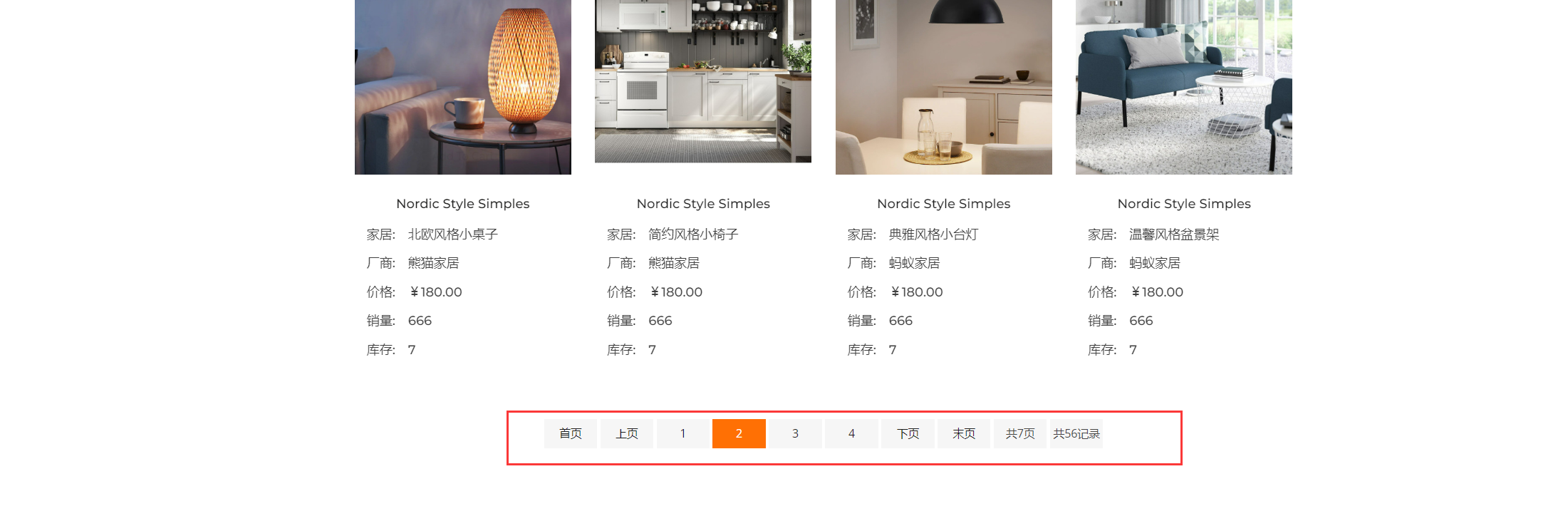
家居网购项目(手写分页)
文章目录 1.后台管理—分页显示1.程序框架图2.编写数据模型Page.java 3.编写dao层1.修改FurnDao增加方法 2.修改FurnDaoImpl增加方法 3.单元测试FurnDaoTest 4.编写service层1.修改FurnService增加方法 2.修改FurnServiceImpl增加方法3.单元测试FurnServiceTest 5.编写DataUtil…...

goland2024安装包(亲测可用)
目录 一、软件简介 二、软件下载 一、软件简介 Goland 是一款由 JetBrains 公司开发的集成开发环境(IDE),专门用于 Go 语言的开发。它提供了丰富的功能和工具,帮助开发者更高效地编写、调试和管理 Go 语言项目。 功能特点&#x…...

35、链表-LRU缓存
思路: 首先要了解LRU缓存的原理,首先定下容量,每次get请求和put请求都会把当前元素放最前/后面,如果超过容量那么头部/尾部元素就被移除,所以最近最少使用的元素会被优先移除,保证热点数据持续存在。 不管放…...

数据结构速成--栈
由于是速成专题,因此内容不会十分全面,只会涵盖考试重点,各学校课程要求不同 ,大家可以按照考纲复习,不全面的内容,可以看一下小编主页数据结构初阶的内容,找到对应专题详细学习一下。 目录 一…...
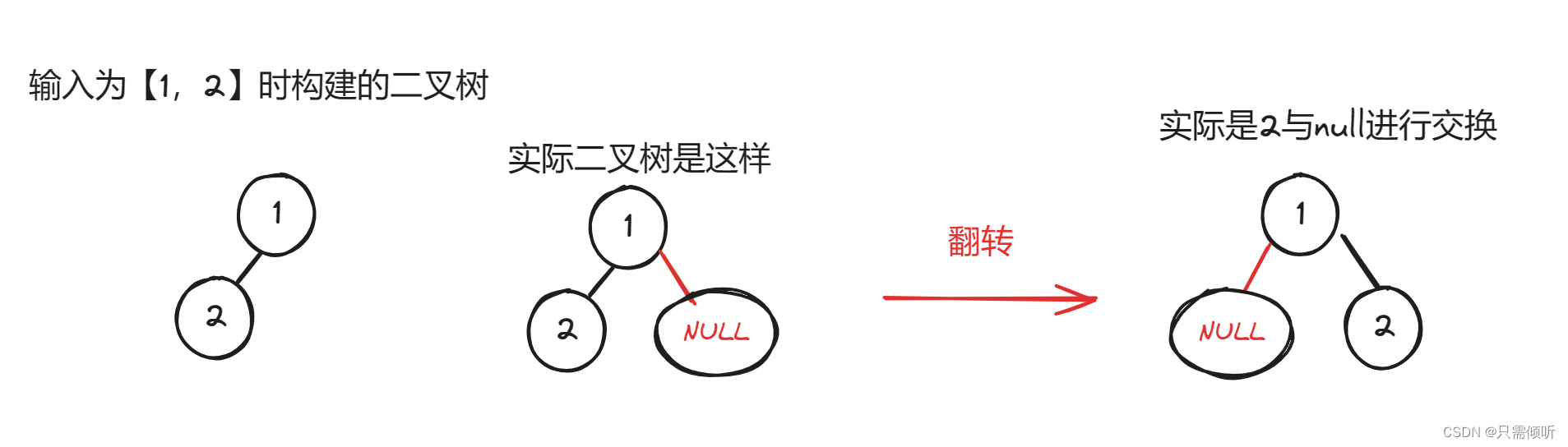
算法练习第15天|226.翻转二叉树
226.翻转二叉树 力扣链接https://leetcode.cn/problems/invert-binary-tree/description/ 题目描述: 给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。 示例 1: 输入:root [4,2,7,1,3,6,9] 输出&am…...

C#面向对象——封装、封装案例示例
C#面向对象——封装 什么是封装? (1)封装是将数据和操作数据的方法(行为)封装在一起。 (2)程序中封装的体现:属性,方法,类,接口,命名空间&#…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...

Ubuntu系统复制(U盘-电脑硬盘)
所需环境 电脑自带硬盘:1块 (1T) U盘1:Ubuntu系统引导盘(用于“U盘2”复制到“电脑自带硬盘”) U盘2:Ubuntu系统盘(1T,用于被复制) !!!建议“电脑…...

xmind转换为markdown
文章目录 解锁思维导图新姿势:将XMind转为结构化Markdown 一、认识Xmind结构二、核心转换流程详解1.解压XMind文件(ZIP处理)2.解析JSON数据结构3:递归转换树形结构4:Markdown层级生成逻辑 三、完整代码 解锁思维导图新…...

机器学习的数学基础:线性模型
线性模型 线性模型的基本形式为: f ( x ) ω T x b f\left(\boldsymbol{x}\right)\boldsymbol{\omega}^\text{T}\boldsymbol{x}b f(x)ωTxb 回归问题 利用最小二乘法,得到 ω \boldsymbol{\omega} ω和 b b b的参数估计$ \boldsymbol{\hat{\omega}}…...

云原生时代的系统设计:架构转型的战略支点
📝个人主页🌹:一ge科研小菜鸡-CSDN博客 🌹🌹期待您的关注 🌹🌹 一、云原生的崛起:技术趋势与现实需求的交汇 随着企业业务的互联网化、全球化、智能化持续加深,传统的 I…...