Next-Scale Prediction、InstantStyle、Co-Speech Gesture Generation
本文首发于公众号:机器感知
Next-Scale Prediction、InstantStyle、Co-Speech Gesture Generation

Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction

We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine "next-scale prediction" or "next-resolution prediction", diverging from the standard raster-scan "next-token prediction". This simple, intuitive methodology allows autoregressive (AR) transformers to learn visual distributions fast and generalize well: VAR, for the first time, makes AR models surpass diffusion transformers in image generation. On ImageNet 256x256 benchmark, VAR significantly improve AR baseline by improving Frechet inception distance (FID) from 18.65 to 1.80, inception score (IS) from 80.4 to 356.4, with around 20x faster inference speed. It is also empirically verified that VAR outperforms the Diffusion Transformer (DiT) in multiple dimensions including image quality, inference speed, data efficiency, and scalability. Scaling up VAR models exhibits clear power-law scaling laws similar to those observed in LLMs, wit......
BAdam: A Memory Efficient Full Parameter Training Method for Large Language Models
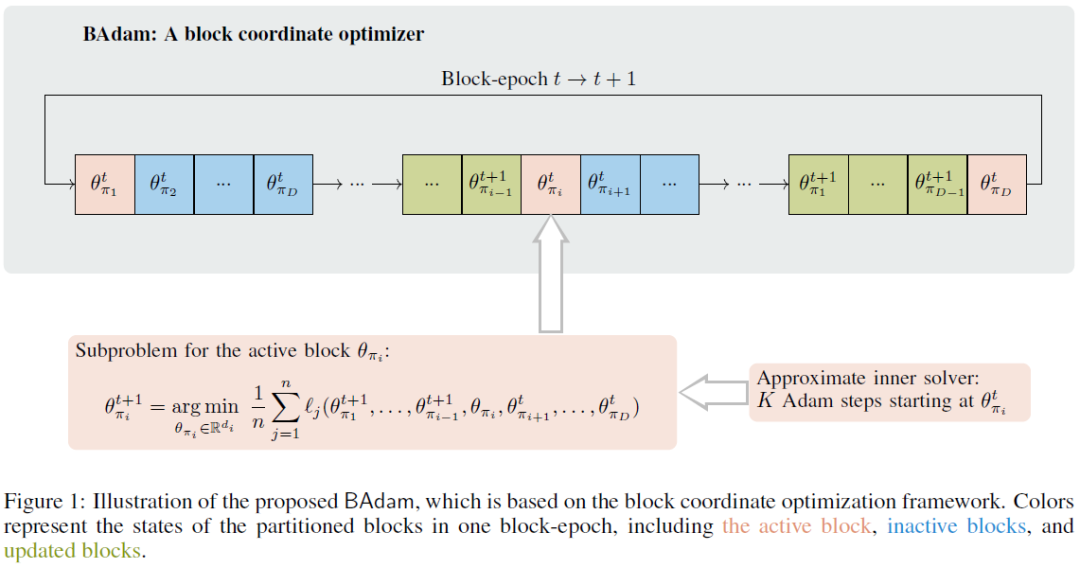
This work presents BAdam, an optimizer that leverages the block coordinate optimization framework with Adam as the inner solver. BAdam offers a memory efficient approach to the full parameter finetuning of large language models and reduces running time of the backward process thanks to the chain rule property. Experimentally, we apply BAdam to instruction-tune the Llama 2-7B model on the Alpaca-GPT4 dataset using a single RTX3090-24GB GPU. The results indicate that BAdam exhibits superior convergence behavior in comparison to LoRA and LOMO. Furthermore, our downstream performance evaluation of the instruction-tuned models using the MT-bench shows that BAdam modestly surpasses LoRA and more substantially outperforms LOMO. Finally, we compare BAdam with Adam on a medium-sized task, i.e., finetuning RoBERTa-large on the SuperGLUE benchmark. The results demonstrate that BAdam is capable of narrowing the performance gap with Adam. Our code is available at https://github.com/Ledzy/......
MULAN: A Multi Layer Annotated Dataset for Controllable Text-to-Image Generation
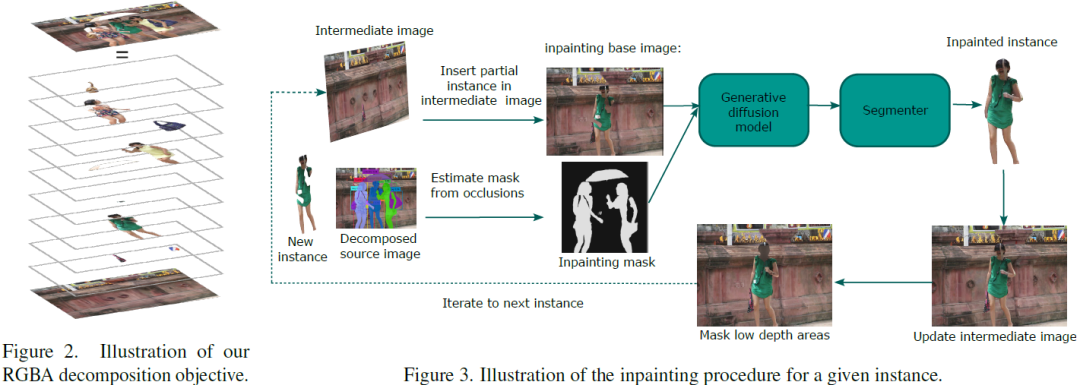
Text-to-image generation has achieved astonishing results, yet precise spatial controllability and prompt fidelity remain highly challenging. This limitation is typically addressed through cumbersome prompt engineering, scene layout conditioning, or image editing techniques which often require hand drawn masks. Nonetheless, pre-existing works struggle to take advantage of the natural instance-level compositionality of scenes due to the typically flat nature of rasterized RGB output images. Towards adressing this challenge, we introduce MuLAn: a novel dataset comprising over 44K MUlti-Layer ANnotations of RGB images as multilayer, instance-wise RGBA decompositions, and over 100K instance images. To build MuLAn, we developed a training free pipeline which decomposes a monocular RGB image into a stack of RGBA layers comprising of background and isolated instances. We achieve this through the use of pretrained general-purpose models, and by developing three modules: image decompo......
Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models

This study explores the role of cross-attention during inference in text-conditional diffusion models. We find that cross-attention outputs converge to a fixed point after few inference steps. Accordingly, the time point of convergence naturally divides the entire inference process into two stages: an initial semantics-planning stage, during which, the model relies on cross-attention to plan text-oriented visual semantics, and a subsequent fidelity-improving stage, during which the model tries to generate images from previously planned semantics. Surprisingly, ignoring text conditions in the fidelity-improving stage not only reduces computation complexity, but also maintains model performance. This yields a simple and training-free method called TGATE for efficient generation, which caches the cross-attention output once it converges and keeps it fixed during the remaining inference steps. Our empirical study on the MS-COCO validation set confirms its effectiveness. The sourc......
InstantStyle: Free Lunch towards Style-Preserving in Text-to-Image Generation

Tuning-free diffusion-based models have demonstrated significant potential in the realm of image personalization and customization. However, despite this notable progress, current models continue to grapple with several complex challenges in producing style-consistent image generation. Firstly, the concept of style is inherently underdetermined, encompassing a multitude of elements such as color, material, atmosphere, design, and structure, among others. Secondly, inversion-based methods are prone to style degradation, often resulting in the loss of fine-grained details. Lastly, adapter-based approaches frequently require meticulous weight tuning for each reference image to achieve a balance between style intensity and text controllability. In this paper, we commence by examining several compelling yet frequently overlooked observations. We then proceed to introduce InstantStyle, a framework designed to address these issues through the implementation of two key strategies: 1)......
Language Models as Compilers: Simulating Pseudocode Execution Improves Algorithmic Reasoning in Language Models
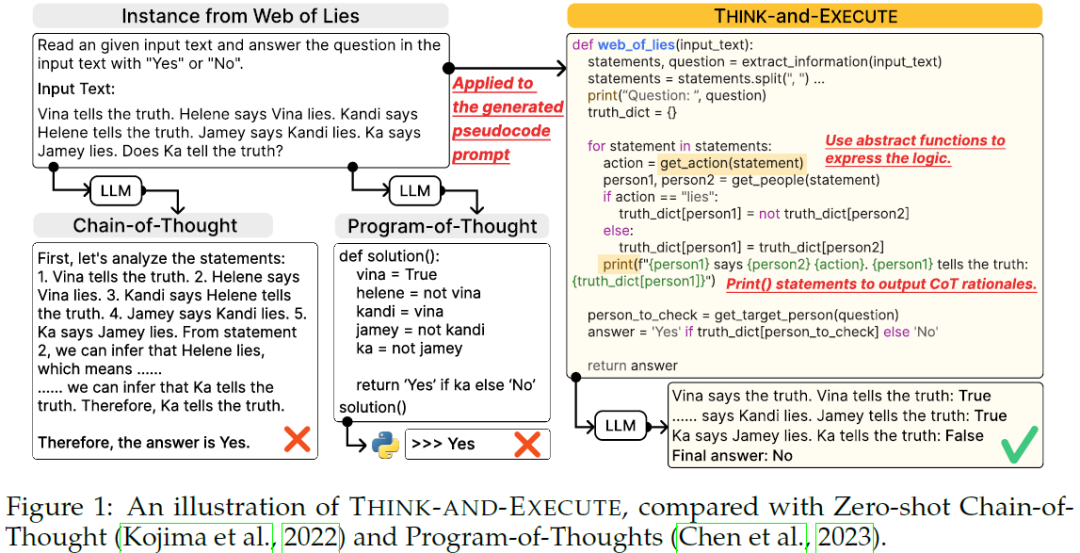
Algorithmic reasoning refers to the ability to understand the complex patterns behind the problem and decompose them into a sequence of reasoning steps towards the solution. Such nature of algorithmic reasoning makes it a challenge for large language models (LLMs), even though they have demonstrated promising performance in other reasoning tasks. Within this context, some recent studies use programming languages (e.g., Python) to express the necessary logic for solving a given instance/question (e.g., Program-of-Thought) as inspired by their strict and precise syntaxes. However, it is non-trivial to write an executable code that expresses the correct logic on the fly within a single inference call. Also, the code generated specifically for an instance cannot be reused for others, even if they are from the same task and might require identical logic to solve. This paper presents Think-and-Execute, a novel framework that decomposes the reasoning process of language models into ......
A Unified Editing Method for Co-Speech Gesture Generation via Diffusion Inversion
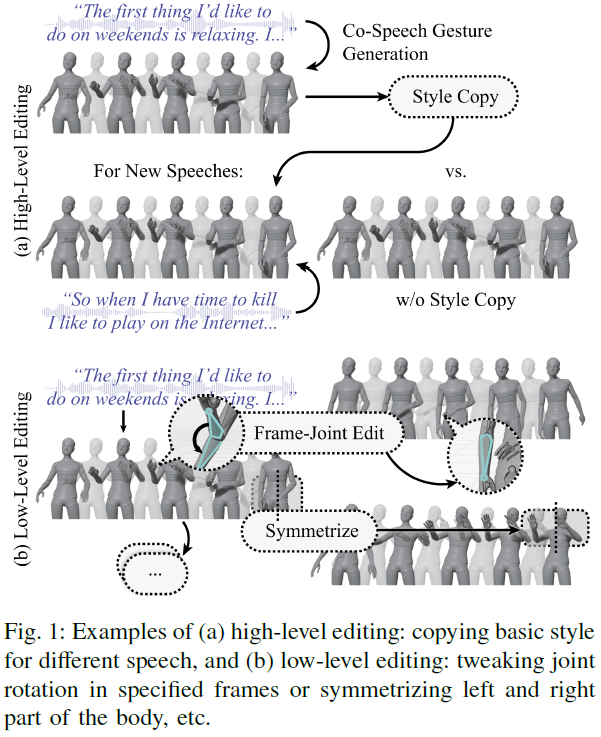
Diffusion models have shown great success in generating high-quality co-speech gestures for interactive humanoid robots or digital avatars from noisy input with the speech audio or text as conditions. However, they rarely focus on providing rich editing capabilities for content creators other than high-level specialized measures like style conditioning. To resolve this, we propose a unified framework utilizing diffusion inversion that enables multi-level editing capabilities for co-speech gesture generation without re-training. The method takes advantage of two key capabilities of invertible diffusion models. The first is that through inversion, we can reconstruct the intermediate noise from gestures and regenerate new gestures from the noise. This can be used to obtain gestures with high-level similarities to the original gestures for different speech conditions. The second is that this reconstruction reduces activation caching requirements during gradient calculation, makin......
Prompts As Programs: A Structure-Aware Approach to Efficient Compile-Time Prompt Optimization
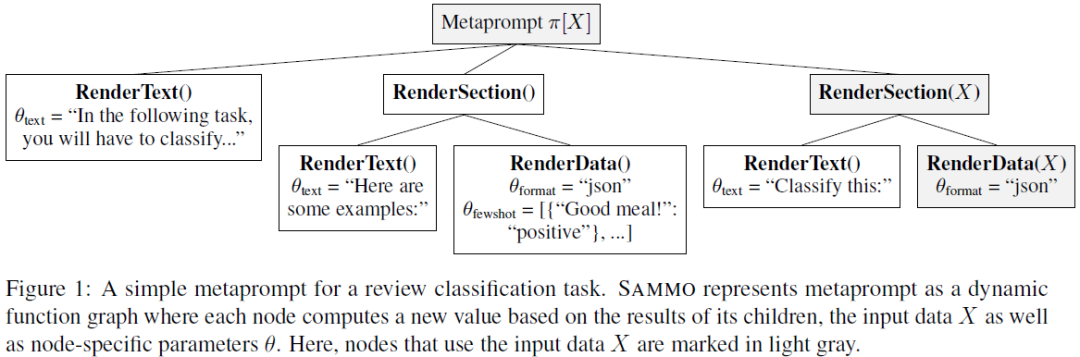
Large language models (LLMs) can now handle longer and more complex inputs, which facilitate the use of more elaborate prompts. However, prompts often require some tuning to improve performance for deployment. Recent work has proposed automatic prompt optimization methods, but as prompt complexity and LLM strength increase, many prompt optimization techniques are no longer sufficient and a new approach is needed to optimize {\em meta prompt programs}. To address this, we introduce SAMMO, a framework for {\em compile-time} optimizations of metaprompt programs, which represent prompts as structured objects that allows for a rich set of transformations that can be searched over during optimization. We show that SAMMO generalizes previous methods and improves the performance of complex prompts on (1) instruction tuning, (2) RAG pipeline tuning, and (3) prompt compression, across several different LLMs. We make all code available open-source at https://github.com/microsoft/sammo .......
Linear Combination of Saved Checkpoints Makes Consistency and Diffusion Models Better
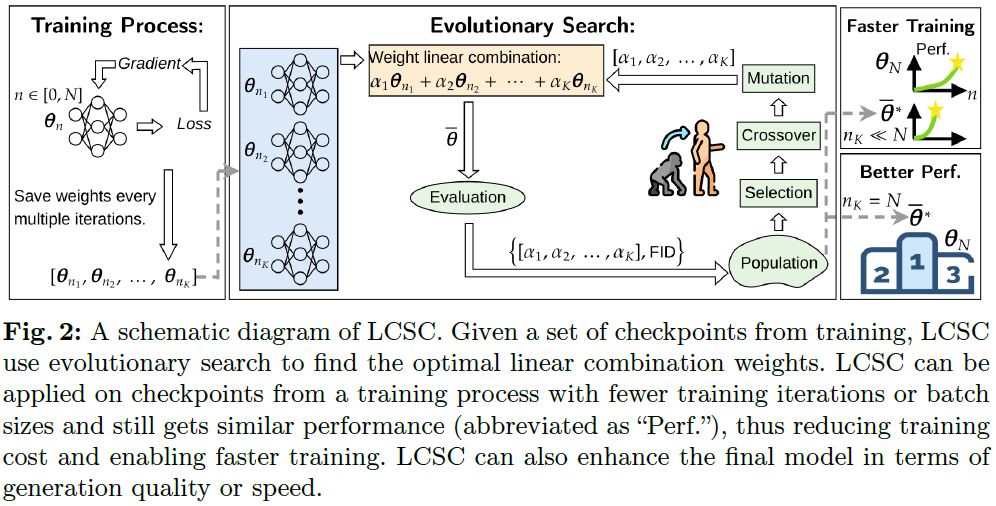
Diffusion Models (DM) and Consistency Models (CM) are two types of popular generative models with good generation quality on various tasks. When training DM and CM, intermediate weight checkpoints are not fully utilized and only the last converged checkpoint is used. In this work, we find that high-quality model weights often lie in a basin which cannot be reached by SGD but can be obtained by proper checkpoint averaging. Based on these observations, we propose LCSC, a simple but effective and efficient method to enhance the performance of DM and CM, by combining checkpoints along the training trajectory with coefficients deduced from evolutionary search. We demonstrate the value of LCSC through two use cases: $\textbf{(a) Reducing training cost.}$ With LCSC, we only need to train DM/CM with fewer number of iterations and/or lower batch sizes to obtain comparable sample quality with the fully trained model. For example, LCSC achieves considerable training speedups for CM (23$......
相关文章:
Next-Scale Prediction、InstantStyle、Co-Speech Gesture Generation
本文首发于公众号:机器感知 Next-Scale Prediction、InstantStyle、Co-Speech Gesture Generation Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction We present Visual AutoRegressive modeling (VAR), a new generation p…...
class中 padding和margin的用法;
如果我们想要移动盒子等的位置 ,除了可以用相对定位和绝对定位还可以用margin 和paddinng; 结构如图所示 margin和padding的用法: padding和margin后面可以跟1或2或3或4个数,按照顺序分别是上,右,下&…...

单独使用YOLOV9的backbone网络
前言 YOLO系列的网络结构都是通过.yaml来进行配置的,当要单独想使用其中的backbone网络时,可以通过yaml配置文件来进行网络搭建。 backbone的yaml配置文件与网络结构 backbone:[[-1, 1, Silence, []], # conv<...
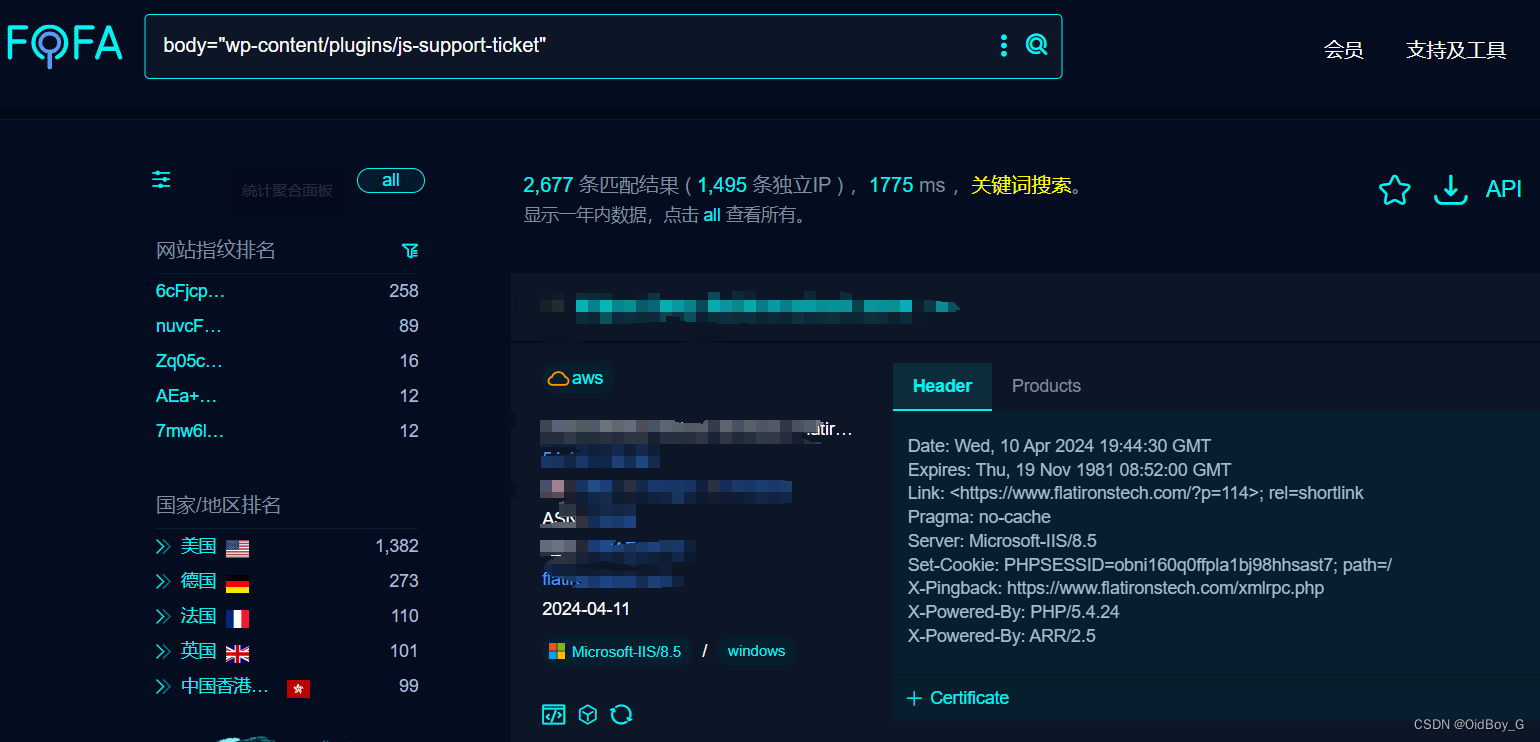
WordPress JS Support Ticket插件 RCE漏洞复现
0x01 产品简介 WordPress和WordPress plugin都是WordPress基金会的产品。JS Support Ticket是使用在其中的一套开源票务系统插件。 0x02 漏洞概述 WordPress中的JS Support Ticket插件存在未经上传漏洞,未经身份验证的攻击者可以上传恶意脚本的服务器,执行任意指令,从而获…...

加盟代理短视频无人直播项目,开启互联网线上经营新模式
随着短视频行业的快速发展和用户数量的不断增长,短视频无人直播项目成为了近年来备受关注的创业机会。本文将分享如何加盟代理短视频无人直播项目,开启属于自己的经营新模式。 一、了解无人直播项目的核心优势 短视频无人直播项目是结合了短视频与直播的…...
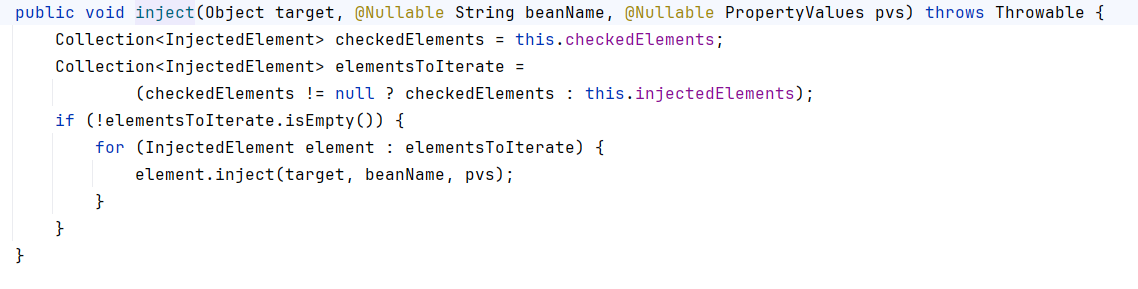
spring高级篇(一)
1、ApplicationContext与BeanFactory BeanFactory是ApplicationContext的父级接口:(citlaltu查看类关系图) 在springboot的启动类中,我们通过SpringApplication.run方法拿到的是继承了ApplicationContext的ConfigurableApplicatio…...
免费的GPT-3.5 API服务aurora
什么是 aurora ? aurora 是利用免登录 ChatGPT Web 提供的无限制免费 GPT-3.5-Turbo API 的服务,支持使用 3.5 的 access 调用。 【注意】:仅 IP 属地支持免登录使用 ChatGPT的才可以使用(也可以自定义 Baseurl 来绕过限制&#x…...
))
突破编程_C++_网络编程(Windows 套接字(处理 TCP 粘包问题))
1 TCP 协议与粘包问题概述 1.1 TCP 粘包的产生原因 TCP粘包问题的产生原因涉及多个方面,主要的原因如下: 首先,发送方在发送数据时,由于TCP协议为提高传输效率而采用的Nagle算法,可能会将多个小数据包合并成一个大数…...

【训练营】DateWhale——动手学大模型应用开发(更新中)
文章目录 写在前面大模型简介LLM简介RAG简介LangChain开发框架开发LLM应用的整体流程 写在前面 大模型时代从GPT爆发开始到现在已有一年多了,深度学习发展之快无法想象,一味感叹技术发展速度超越个人学习速度是没用的,倒不如花点时间参加一些…...
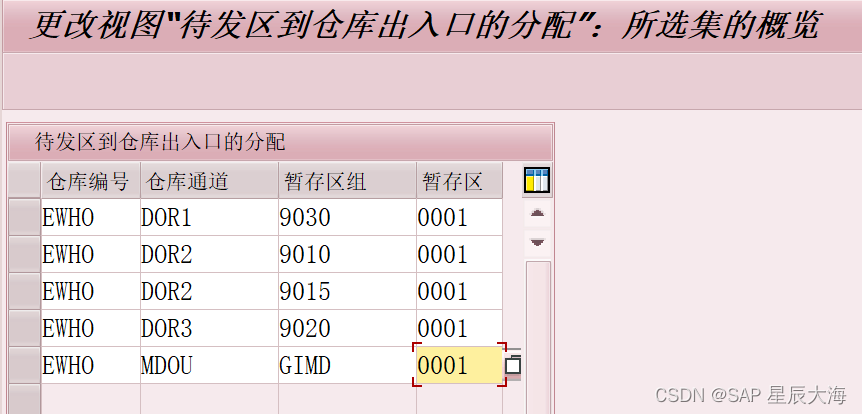
【学习笔记十九】EWM Yard Management概述及后台配置
一、EWM Yard堆场管理业务概述 1.Yard Management基本概念 YARD管理针对的是库房以外的区域,可以理解为入大门开始到库门之前的这部分的区域 堆场结构 像在仓库中一样,将相应仓位映射为堆场仓位,可将其分组到堆场分区。场地中可能具有以下结…...
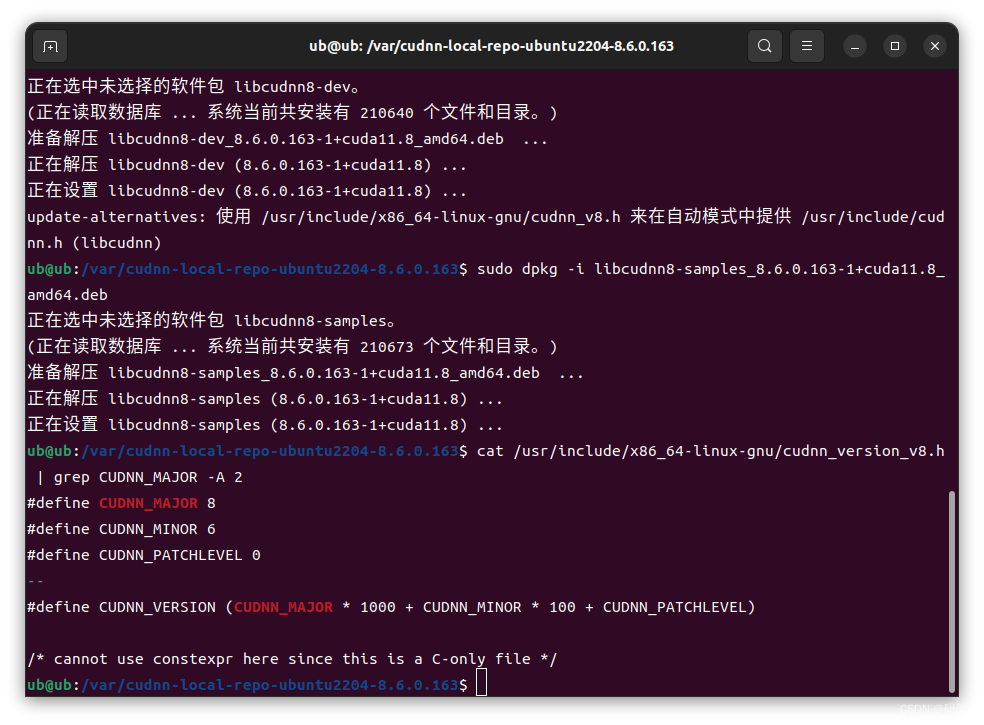
【环境搭建】(五)Ubuntu22.04安装cuda_11.8.0+cudnn_8.6.0
一个愿意伫立在巨人肩膀上的农民...... 设备配置: 一、安装GCC 安装cuda之前,首先应该安装GCC,安装cuda需要用到GCC,否则报错。可以先使用下方指令在终端查看是否已经安装GCC。 gcc --version 如果终端打印如下则说明已经安装…...
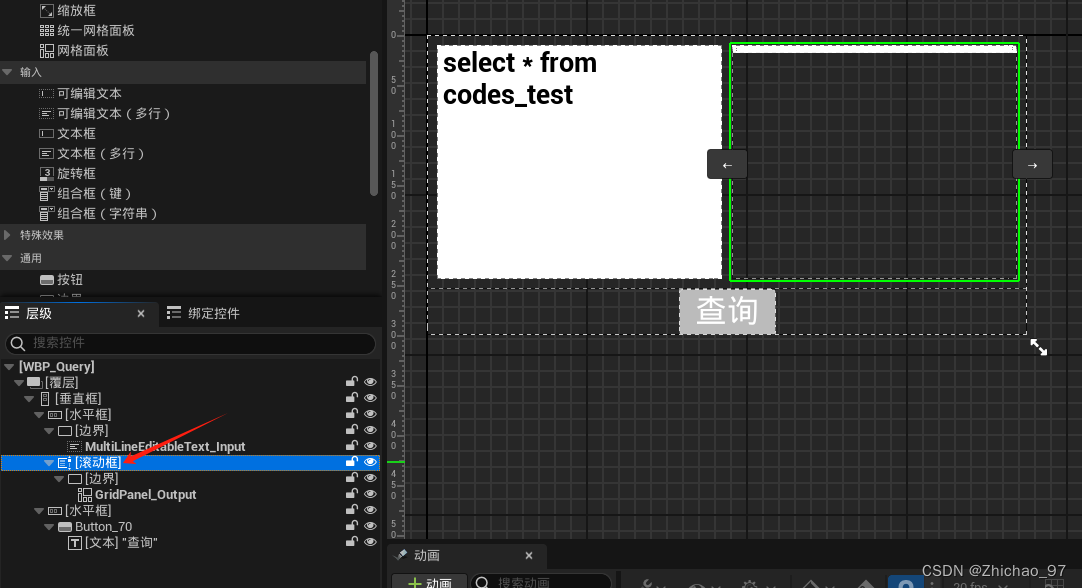
【UE5.1】使用MySQL and MariaDB Integration插件——(3)表格形式显示数据
在上一篇(【UE5.1】使用MySQL and MariaDB Integration插件——(2)查询)基础上继续实现以表格形式显示查询到的数据的功能 效果 步骤 1. 在“WBP_Query”中将多行文本框替换未网格面板控件,该控件可以用表格形式布局…...
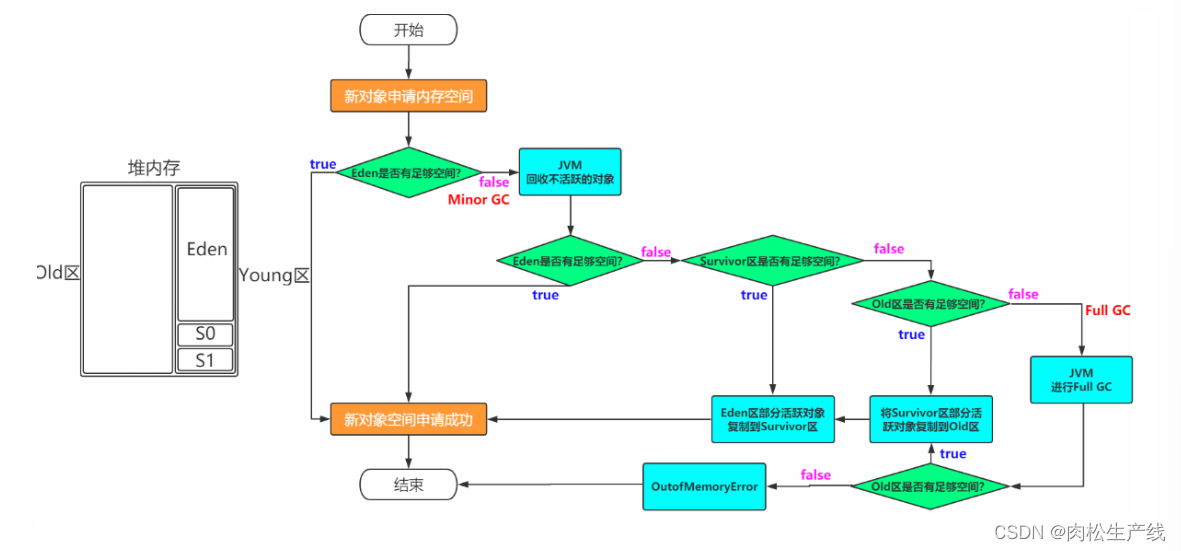
JVM复习
冯诺依曼模型与计算机处理数据过程相关联: 冯诺依曼模型: 输入/输出设备存储器输出设备运算器控制器处理过程: 提取阶段:输入设备传入原始数据,存储到存储器解码阶段:由CPU的指令集架构ISA将数值解…...

63、ARM/STM32中IIC相关学习20240417
完成温湿度传感器数据采集实验。 【思路:1.通过IIC通信原理,理解其通信过程,通过调用封装的IIC函数达成主机和从机之间:起始信号、终止信号、读、写数据的操作; 2.了解温湿度传感器控制芯片SI7006的工作原理&#…...

离岸人民币与人民币国际化
参考 什么是离岸人民币?它有什么用? - 知乎 “人民币就是人民币,为什么要在它前面加上离岸二字?” “既然有离岸人民币,是否有在岸人民币?” 今天我们就简单了解一下什么是离岸人民币。 离岸/在岸人民币…...

Linux平台上部署和运行Ollama的全面指南
Ollama的安装与配置 Ollama提供了一种简单的安装方法,只需一行命令即可完成安装,但是对于想要更深入了解和自定义安装的用户,我们也提供了手动安装的步骤。 快速安装 Ollama的安装极为简单,只需在终端中执行以下命令࿱…...

Web---robots协议详解
在Web中,robots协议(也称为robots.txt)是一种文本文件,用于向搜索引擎机器人(通常称为爬虫)提供指导,以指示它们哪些页面可以抓取,哪些页面应该忽略。robots.txt文件位于网站的根目录…...

华为海思校园招聘-芯片-数字 IC 方向 题目分享——第四套
华为海思校园招聘-芯片-数字 IC 方向 题目分享——第四套 (共9套,有答案和解析,答案非官方,仅供参考)(共九套,每套四十个选择题) 部分题目分享,完整版获取(WX:didadida…...
))
clipper一些数据结构(入门初识(一))
clipper一些数据结构(一) Clipper库是一个用于执行多边形裁剪(clipping)和偏移(offsetting)操作的开源C库。在Clipper库中,点和多边形(polygon)是基本的数据结构。Clipp…...
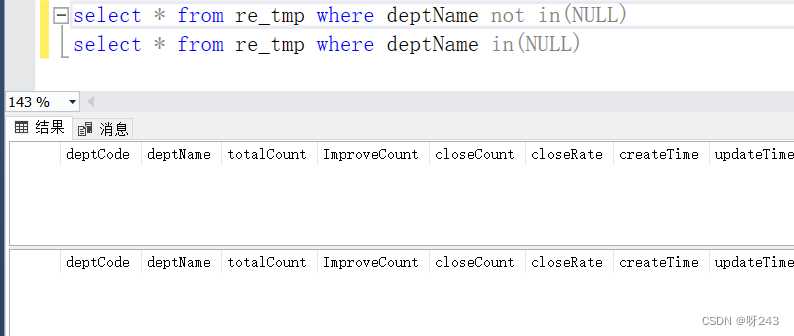
读《SQL基础教程 第二版 上》的一些总结
1. 数据库语言 DDL: Data Definition Language,数据定义语言(库、表的操作) DML: Data Manipulation Language, 数据操控语言(对表中数据的增删改) DQL: Data Query Language,数据库查询语言…...

GLM-OCR多模态识别模型:从零开始快速部署与测试
GLM-OCR多模态识别模型:从零开始快速部署与测试 你是不是经常需要从图片、扫描件或者PDF里提取文字?手动输入太慢,用在线工具又担心数据安全。今天要介绍的GLM-OCR,就是一个能让你彻底告别这些烦恼的解决方案。 GLM-OCR最近在权…...

基于造相Z-Image的短视频内容自动生成平台
基于造相Z-Image的短视频内容自动生成平台 1. 引言 短视频内容创作正成为数字营销的主流方式,但高质量内容的持续产出却让很多创作者头疼。传统的视频制作流程复杂,需要脚本撰写、场景设计、拍摄剪辑等多个环节,耗时耗力且成本高昂。 现在…...

在Java中如何处理长数字读写
Java处理长数字需要下划线分隔符来提高可读性(编译期忽略)、BigDecimal(字符串结构)优先选择long防溢出,精确计算、根据String统一分析长数字输入。Java处理长数字的关键是正确使用数字面量分隔符,选择合适的数据类型,并注意浮点数的精度。直…...

利用Mermaid在Markdown中高效构建数据库ER图
1. 为什么选择Mermaid画ER图 第一次接触数据库设计时,我用Visio画了三天ER图,结果产品经理说要改两个字段,所有连线都得重新调整。直到发现Markdown里用Mermaid画ER图的玩法,才明白什么叫"降维打击"。这个组合有多香&am…...

数字化转型中的数据安全:提示工程架构师必须掌握的提示词脱敏技术
数字化转型中的数据安全:提示工程架构师必须掌握的提示词脱敏技术 一、引言:数字化转型中的数据安全痛点 1.1 数字化转型的“双刃剑”:效率与风险并存 随着人工智能(尤其是大语言模型,LLM)技术的爆发&#…...

PFC2D 中隧道开挖应力释放模拟:精准掌控比例的艺术
pfc2d隧道开挖考虑应力释放,可以指定应力释放的比例。在岩土工程数值模拟领域,PFC2D(Particle Flow Code in 2 Dimensions)是一款极为强大的工具,尤其是在隧道开挖模拟方面表现卓越。其中,考虑应力释放并能…...

【PyArmor实战】从混淆到绑定:构建企业级Python代码保护方案
1. 为什么PyInstaller无法满足企业级代码保护需求 很多Python开发者第一次接触代码保护时,都会选择PyInstaller这个工具。确实,它能将Python脚本打包成独立的可执行文件,看似解决了代码分发的问题。但我在实际企业项目中多次验证后发现&#…...

Solidworks钣金设计:折弯系数、K因子与折弯扣除的实战应用解析
1. 钣金设计中的三大核心参数:从理论到实践 刚接触Solidworks钣金设计时,我最头疼的就是折弯系数、K因子和折弯扣除这三个概念。记得第一次做机箱侧板时,展开尺寸总比实际短3mm,导致折弯后零件装配不上。后来才发现是K因子设置错误…...
导致的3大内存问题(附正确姿势))
新手必看!Qt中误用close()导致的3大内存问题(附正确姿势)
Qt窗口关闭陷阱:从内存泄漏到双重删除的深度避坑指南 刚接触Qt开发的程序员们,常常会被窗口关闭这个看似简单的操作绊倒。你以为调用close()只是让窗口消失?实际上,这背后隐藏着一系列可能引发内存泄漏、程序崩溃的陷阱。本文将带…...
参数resolution的5个关键设置技巧)
单细胞聚类避坑指南:Seurat中FindClusters()参数resolution的5个关键设置技巧
单细胞聚类避坑指南:Seurat中FindClusters()参数resolution的5个关键设置技巧 在单细胞转录组数据分析中,细胞聚类是揭示细胞异质性的核心步骤。Seurat作为最流行的分析工具之一,其FindClusters()函数的表现直接影响后续分析的可靠性。而reso…...