mapreduce中的MapTask工作机制(Hadoop)
MapTask工作机制
MapReduce中的Map任务是整个计算过程的第一阶段,其主要工作是将输入数据分片并进行处理,生成中间键值对,为后续的Shuffle和Sort阶段做准备。
1. 输入数据的划分:
- 输入数据通常存储在分布式文件系统(如HDFS)中,由
InputFormat负责将输入数据划分成若干个InputSplit,每个InputSplit对应一个Mapper任务的输入。 - 输入数据被划分成多个
InputSplit的目的是为了充分利用集群中的计算资源,并实现数据的并行处理。
2. Map任务的启动:
- 一旦MapReduce作业被提交,
Master节点(JobTracker)会将Map任务分配给空闲的Map任务槽(Task Slot)。 - 每个
Map任务槽都运行在集群中的某个节点上,并且能够处理一个或多个Mapper任务。
3. Mapper的初始化:
- 当
Map任务被分配到一个节点上时,该节点会启动一个Mapper实例。 Mapper实例会首先执行初始化操作,包括获取输入数据的位置信息、加载用户自定义的Map函数等。
4. 数据处理:
Mapper开始处理其对应的InputSplit中的数据。- 对于每个输入记录,
Mapper会调用用户定义的Map函数,该函数将输入记录转换成若干个中间键值对(key-value pairs)。 - 这些中间键值对通常表示了对输入数据的处理结果,比如单词计数问题中,键可以是单词,值可以是该单词出现的次数。
在Map任务中,为了提高处理速度和效率,通常会采取一些数据处理优化策略,比如:
-
数据局部性优化:尽可能在处理数据时减少网络通信开销,使得处理同一输入分片的数据的
Mapper任务能够在同一个节点上执行,以减少数据的传输成本。 -
流水线处理:
Map任务可以通过流水线处理来提高吞吐量,即在处理一个输入记录的同时,可以开始处理下一个输入记录,从而减少处理过程中的等待时间。
5. 中间结果的缓存:
Map任务通常会将中间结果缓存在内存中,但如果缓存空间不足以存储所有的中间结果时,会采取一些策略来管理缓存,例如:
-
溢出到磁盘:当内存中的中间结果达到一定阈值时(比如默认的80%),Map任务会将部分中间结果写入磁盘的临时文件中,以释放内存空间,从而继续处理新的输入记录。
-
内存管理算法:
Map任务可能采用LRU(最近最少使用)等算法来管理内存中的中间结果,保留最常使用的数据,释放不常用的数据。在 Map 阶段完成后,中间结果会被写入本地磁盘,但在写入之前,通常会进行本地排序操作。
-
本地排序可以确保相同
key的数据在同一个位置,以便后续的Shuffle阶段更高效地进行数据传输和处理。 -
在必要时,还可以对数据进行合并和压缩操作,以减少存储空间和提高数据传输效率。这些步骤都是为了优化整个
MapReduce作业的性能和效率。
6. 任务状态更新:
-
在
Map任务执行期间,Master节点会周期性地接收来自Map任务的心跳信息,以报告任务的运行状态,并定期更新任务进度。 -
如果
Map任务长时间没有发送心跳信息,Master节点可能会将其标记为失败,并重新分配任务给其他节点执行。 -
Map任务在执行完所有的输入记录后,会向Master节点报告任务完成,并将生成的中间结果的位置信息发送给Master。 -
MapReduce框架具有强大的容错机制,即使Map任务在执行过程中出现失败,Master节点也能够重新分配任务并继续执行,以确保作业的顺利完成。
7. Map任务的结束:
-
当所有数据处理完成后,
MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。 -
当所有数据处理完后,
MapTask会将所有临时文件合并成一个大文件,并保存到文件output/file.out 中,同时生成相应的索引文件output/file.out.index。 -
在进行文件合并过程中,
MapTask以分区为单位进行合并。对于某个分区,它将采用多轮递归合并的方式。每轮合并mapreduce.task.io.sort.factor(默认 10)个文件,并将产生的文件重新加入待合并列表中,对文件排序后,重复以上过程,直到最终得到一个大文件。 -
让每个 MapTask 最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销。
-
一旦所有的输入记录都被处理完毕,并且中间结果都被写入磁盘,
Map任务就会结束。 -
Map任务会将最终的中间结果的位置信息发送给Master节点,以便后续的Shuffle和Sort阶段能够获取到这些数据。
8.示例
假设我们有一个大的文本文件,其中包含了多篇文章,每篇文章之间由一个或多个空行分隔。Map任务的目标是将输入数据中的每个单词映射成键值对(单词, 1),以便后续的Reduce任务可以统计每个单词的频次。
(1) 输入数据的划分:
- 在
Hadoop中,这个文本文件被分成若干个逻辑块(block),每个逻辑块会被存储在HDFS的不同节点上。当我们提交MapReduce作业时,Hadoop会将这些逻辑块划分成若干个InputSplit,每个InputSplit对应一个Mapper任务的输入。
(2) Map任务的启动:
- 一旦
MapReduce作业被提交,Master节点会启动作业的第一个阶段,即Map阶段。Master节点会根据集群中的可用资源情况,将Map任务分配给空闲的节点上的Map任务槽。
(3) Mapper的初始化:
-
每个
Mapper任务在运行之前都需要进行初始化。这个初始化过程包括获取对应的InputSplit的数据位置信息、加载用户自定义的Map函数等。 -
在我们的例子中,Map函数需要额外的逻辑来识别文章的标题。
(4) 数据处理:
Mapper开始处理其对应的InputSplit中的数据。对于每个InputSplit,Mapper会逐行读取数据。- 在我们的例子中,
Mapper会识别每篇文章的标题,并为每篇文章的每个单词生成键值对。对于每个键值对,键是单词,值是1,表示该单词在文章中出现了一次。
(5) 中间结果的缓存:
Mapper会将生成的中间键值对缓存在内存中。当内存中的数据达到一定阈值时,部分结果会被写入磁盘的临时文件中以释放内存空间。- 在我们的例子中,中间结果包括文章标题和单词出现次数的键值对。
(6)任务状态更新:
- 在
Map任务执行期间,Mapper会定期向Master节点发送心跳信息,以报告任务的运行状态和进度。Master节点会根据这些信息来监控任务的执行情况,并在必要时重新分配任务。
(7) Map任务的结束:
- 当
Mapper处理完其对应的InputSplit中的所有数据,并且中间结果都被写入磁盘后,Map任务结束。 Mapper会将最终的中间结果的位置信息发送给Master节点,以便后续的Shuffle和Sort阶段能够获取到这些数据。
通过Map任务的执行,我们得到了每篇文章中单词的频次统计结果,并且识别出了每篇文章的标题。这些中间结果将被用于后续的Shuffle和Sort阶段,最终得到我们想要的每篇文章中单词的频次统计结果。
相关文章:
)
mapreduce中的MapTask工作机制(Hadoop)
MapTask工作机制 MapReduce中的Map任务是整个计算过程的第一阶段,其主要工作是将输入数据分片并进行处理,生成中间键值对,为后续的Shuffle和Sort阶段做准备。 1. 输入数据的划分: 输入数据通常存储在分布式文件系统(…...

景区文旅剧本杀小程序亲子公园寻宝闯关系统开发搭建
要开发景区文旅剧本杀小程序亲子公园寻宝闯关系统,您需要考虑以下步骤: 1. 设计游戏场景和规则:根据亲子公园的主题和特点,设计适合亲子游玩的游戏场景和规则。您需要考虑游戏的安全性、趣味性和互动性,确保孩子们能够…...

性能优化---webpack优化
1、如何提高webpack打包速度 a、优化Loader--影响Loader打包速度的首要元素是Babel,Babel 会将代码转为字符串生成 AST,然后对 AST 继续进行转变最后再生成新的代码,项目越大,转换代码越多,效率就越低。先优化 Loader …...

YOLOv9改进策略 | 损失函数篇 | EIoU、SIoU、WIoU、DIoU、FocusIoU等二十余种损失函数
一、本文介绍 这篇文章介绍了YOLOv9的重大改进,特别是在损失函数方面的创新。它不仅包括了多种IoU损失函数的改进和变体,如SIoU、WIoU、GIoU、DIoU、EIOU、CIoU,还融合了“Focus”思想,创造了一系列新的损失函数。这些组合形式的…...

贪心算法-跳跃游戏
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。 示例 1: 输…...

sql知识总结二
一.报错注入 1.什么是报错注入? 这是一种页面响应形式,响应过程如下: 用户在前台页面输入检索内容----->后台将前台输入的检索内容无加区别的拼接成sql语句,送给数据库执行------>数据库将执行的结果返回给后台ÿ…...

VSCode和CMake实现C/C++开发
VSCode和CMake实现Ubuntu下C/C++开发总结 目录 0.简介1.Linux系统介绍2.开发环境搭建2.1 编译器,调试器安装2.2 CMake安装3.GCC编译器3.1 编译过程3.2 g++重要编译参数4.g++编译实战4.0 编译前4.1 直接编译4.2 生成库文件并编译4.3 编译后4.3.1 编译完成后的目录结构4.3.2 运行…...
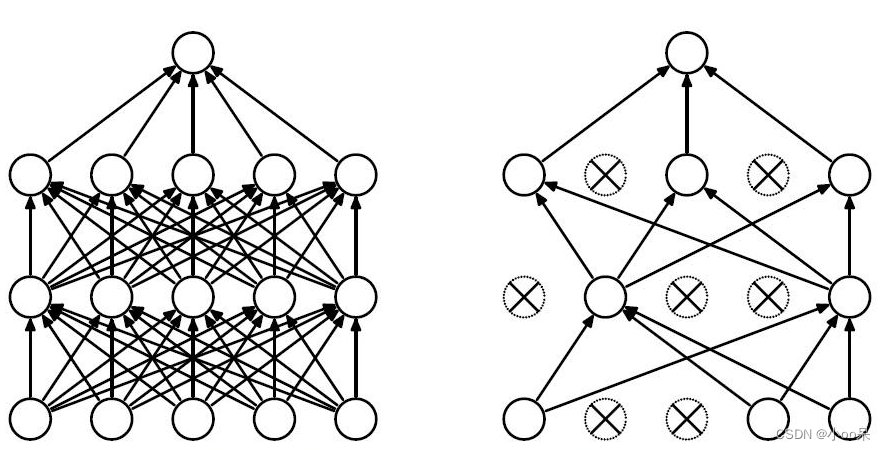
【机器学习300问】74、如何理解深度学习中L2正则化技术?
深度学习过程中,若模型出现了过拟合问题体现为高方差。有两种解决方法: 增加训练样本的数量采用正则化技术 增加训练样本的数量是一种非常可靠的方法,但有时候你没办法获得足够多的训练数据或者获取数据的成本很高,这时候正则化技…...
)
C语言程序设计每日一练(4)
完全平方数 首先,我们需要明确什么是完全平方数。完全平方数是指一个整数,它可以表示为另一个整数的平方。例如,1、4、9、16等都是完全平方数,因为它们分别是1、2、3、4的平方。 现在,让我们回到这个问题。我们知道这…...

m4p转换mp3格式怎么转?3个Mac端应用~
M4P文件格式的诞生伴随着苹果公司引入FairPlay版权管理系统,该系统旨在保护音频的内容。M4P因此而生,成为受到FairPlay系统保护的音频格式,常见于苹果设备的iTunes等平台。 MP3文件格式的多个优点 MP3格式的优点显而易见。首先,其…...
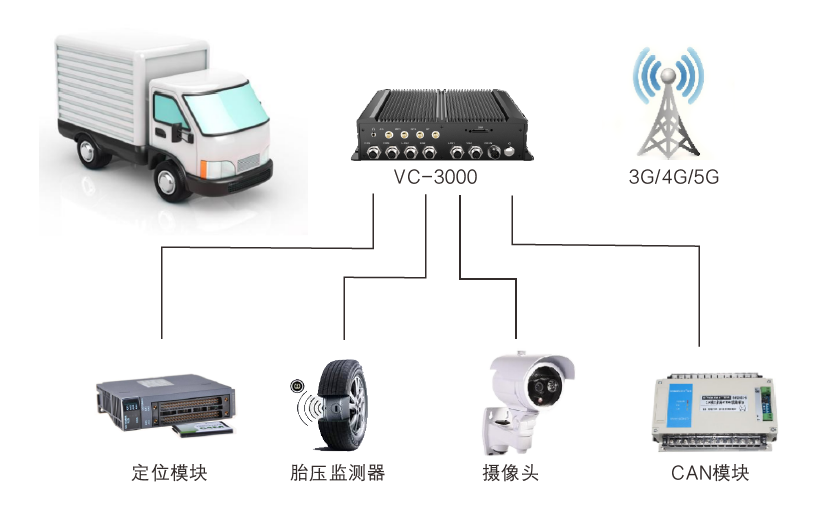
全国产化无风扇嵌入式车载电脑在车队管理嵌入式车载行业应用
车队管理嵌入式车载行业应用 车队管理方案能有效解决车辆繁多管理困难问题,配合调度系统让命令更加精确有效执行。实时监控车辆状况、行驶路线和位置,指导驾驶员安全有序行驶,有效降低保险成本、事故概率以及轮胎和零部件的磨损与损坏。 方…...

爬虫入门——Request请求
目录 前言 一、Requests是什么? 二、使用步骤 1.引入库 2.请求 3.响应 三.总结 前言 上一篇爬虫我们已经提及到了urllib库的使用,为了方便大家的使用过程,这里为大家介绍新的库来实现请求获取响应的库。 一、Requests是什么࿱…...
创建一个javascript公共方法的npm包,js-tool-big-box,发布到npm上,一劳永逸
前端javascript的公共方法太多了,时间日期的,数值的,字符串的,搞复制的,搞网络请求的,搞数据转换的,几乎就是每个新项目,有的拷一拷,没有的继续写,放个utils目…...
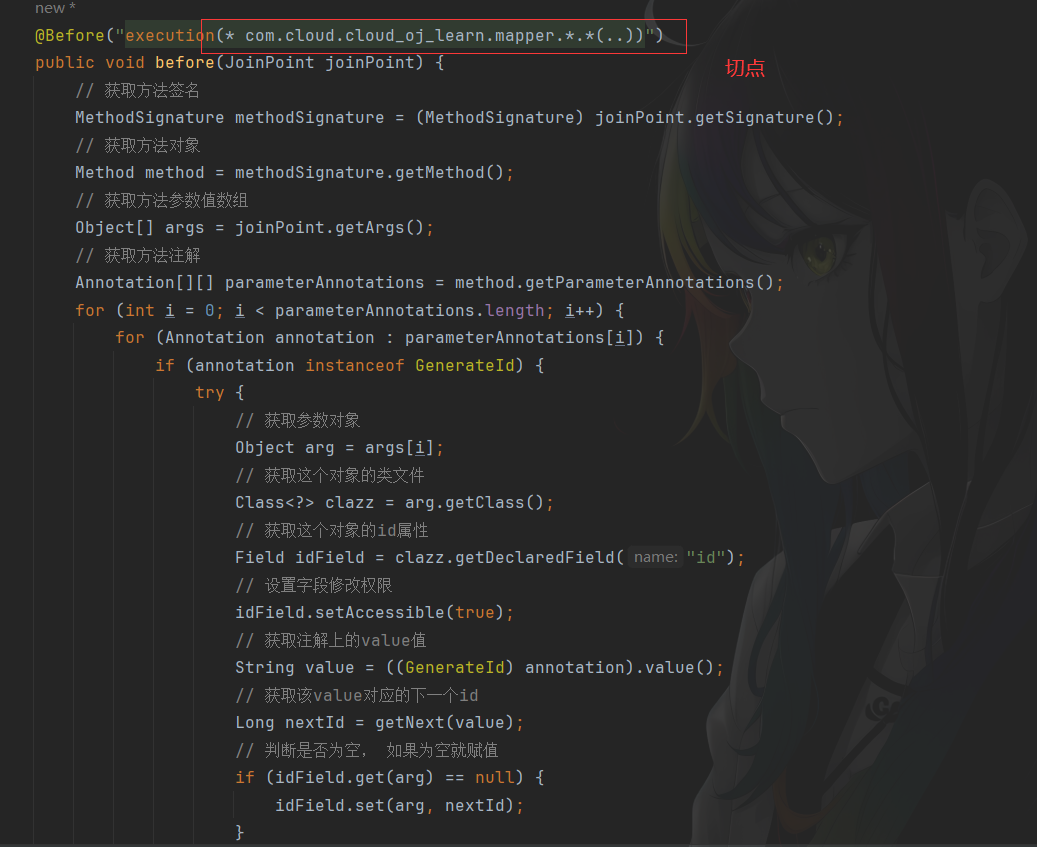
【在线OJ系统】自定义注解实现分布式ID无感自增
实现思路 首先自定义参数注解,然后根据AOP思想,找到该注解作用的切点,也就是mapper层对于mapper层的接口在执行前都会执行该aop操作:获取到对于的方法对象,根据方法对象获取参数列表,根据参数列表判断某个…...
35. UE5 RPG制作火球术技能
接下来,我们将制作技能了,总算迈进了一大步。首先回顾一下之前是如何实现技能触发的,然后再进入正题。 如果想实现我之前的触发方式的,请看此栏目的31-33篇文章,讲解了实现逻辑,这里总结一下: …...
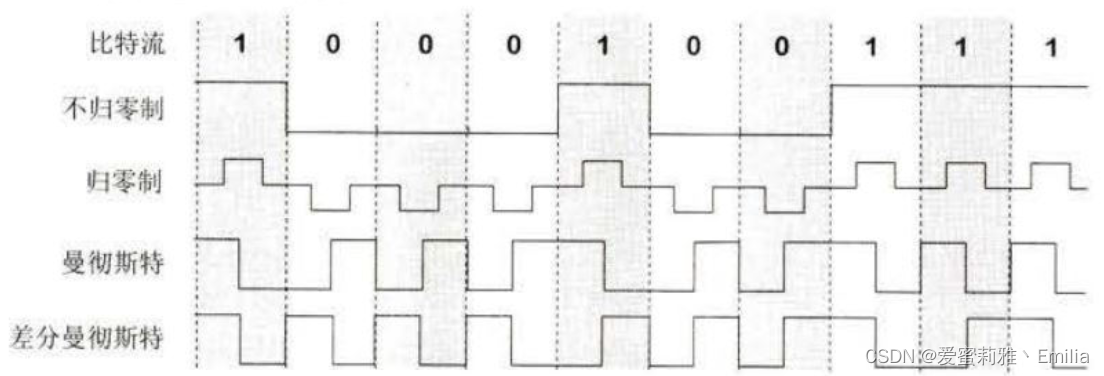
计算机网络 TCP/IP体系 物理层
一. TCP/IP体系 物理层 1.1 物理层的基本概念 物理层作为TCP/IP网络模型的最低层,负责直接与传输介质交互,实现比特流的传输。 要完成物理层的主要任务,需要确定以下特性: 机械特性:物理层的机械特性主要涉及网络…...
微服务相关
1. 微服务主要七个模块 中央管理平台:生产者、消费者注册,服务发现,服务治理,调用关系生产者消费者权限管理流量管理自定义传输协议序列化反序列化 2. 中央管理平台 生产者A在中央管理平台注册后,中央管理平台会给他…...
虚拟机下如何使用Docker(完整版)
Docker详细介绍: Docker 是一款开源的应用容器引擎,由Docker公司最初开发并在2013年发布。Docker的核心理念源自于操作系统级别的虚拟化技术,尤其是Linux上的容器技术(如LXC),它为开发人员和系统管理员提供…...

asp.net core 依赖注入后的服务生命周期
ASP.NET Core 依赖注入(DI)容器支持三种服务的生命周期选项,它们定义了服务实例的创建和销毁的时机。理解这三种生命周期对于设计健壯且高效的应用程序非常重要: 瞬时(Transient): 瞬时服务每次…...

交换排序:冒泡排序和快速排序
冒泡排序 思路 通过多次遍历数组,比较相邻的元素,并交换它们,使得每次遍历结束后,最大(或最小)的元素都“冒泡”到数组的末尾 实现 public class Main {public static void main(String[] args) {int[] …...

OpenClaw健康检查套件:ollama-QwQ-32B驱动的系统状态报告
OpenClaw健康检查套件:ollama-QwQ-32B驱动的系统状态报告 1. 为什么需要智能化的系统健康报告? 去年我管理的一台开发服务器突然宕机,排查时才发现磁盘早已悄悄占满。传统监控工具虽然能采集数据,但需要人工反复检查仪表盘——这…...

北大数字普惠金融指数省市县2011-2024面板数据
北大数字普惠金融指数简介北大数字普惠金融指数由北京大学数字金融研究中心编制,旨在衡量中国各地区数字普惠金融发展水平。该指数覆盖省、市、县三级行政区,时间跨度为2011年至2024年,包含总指数及多个分维度指标(如覆盖广度、使…...
C++ 中指针和引用的区别)
单片机/C/C++八股:(十七)C++ 中指针和引用的区别
上一篇下一篇C 中 malloc/free 和 C 中 new/delete 有什么区别?C 中指针和引用的区别 指针(Pointer)和引用(Reference)是 C 中两种用于间接访问对象的机制,但它们在本质、行为和使用规则上有根本区别。 本质…...

## 22|Python gRPC 微服务治理:超时、重试与接口兼容策略
22|Python gRPC 微服务治理:超时、重试与接口兼容策略 文章目录 22|Python gRPC 微服务治理:超时、重试与接口兼容策略 摘要 SEO 摘要 目录 gRPC 线上常见故障 治理策略 Python 代码示意 案例复盘 案例复盘二 架构权衡对比表(A/B/C) 可执行实验步骤 发布后7天观察指标模板…...

RMBG-2.0一文详解:从模型结构、推理流程到WebUI交互逻辑全梳理
RMBG-2.0一文详解:从模型结构、推理流程到WebUI交互逻辑全梳理 1. 背景去除新选择:为什么RMBG-2.0值得关注 在图像处理领域,背景去除一直是个高频需求。无论是电商商品图处理、证件照制作,还是短视频内容创作,都需要…...

Kafka-King:企业级高性能分布式Kafka图形化管理平台技术深度解析
Kafka-King:企业级高性能分布式Kafka图形化管理平台技术深度解析 【免费下载链接】Kafka-King A modern and practical kafka GUI client 项目地址: https://gitcode.com/gh_mirrors/ka/Kafka-King Kafka-King是一款基于Go语言与Vue.js构建的企业级高性能分布…...

AIVideo高级应用:使用PID算法优化视频生成流程
AIVideo高级应用:使用PID算法优化视频生成流程 1. 引言 视频创作者们经常面临一个两难选择:想要高质量的视频效果,就得承受漫长的生成时间和巨大的计算资源消耗;想要快速出片,又不得不接受画质和细节的妥协。传统的视…...

网安密码学是学啥的?黑客应用方向及方法,学了就业怎么样_网络空间安全专业学习密码学
网安密码学,或称网络安全中的密码学,是指在网络安全领域应用密码学的理论和技术来保护信息免受未授权访问和篡改。密码学是网络安全的一个重要组成部分,它涵盖了信息加密、身份验证、数据完整性和数字签名等多个方面。 密码学是什么ÿ…...

基于springboot3 vue3 设备管理系统 开发实践 文末 有免费的下载地址
博主介绍:专注于Java(springboot ssm 等开发框架) vue .net php phython node.js uniapp 微信小程序 等诸多技术领域和毕业项目实战、企业信息化系统建设,从业十五余年开发设计教学工作 ☆☆☆ 精彩专栏推荐订阅☆☆☆☆☆不…...

如何高效集成Gson与Scala:Java JSON库的函数式编程适配指南
如何高效集成Gson与Scala:Java JSON库的函数式编程适配指南 【免费下载链接】gson A Java serialization/deserialization library to convert Java Objects into JSON and back 项目地址: https://gitcode.com/gh_mirrors/gs/gson Gson作为Google开发的Java…...