爬取89ip代理、 爬取豆瓣电影
1 爬取89ip代理
2 爬取豆瓣电影
1 爬取89ip代理
import requests
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
from requests.exceptions import ProxyErrorclass SpiderIP:def __init__(self):# 定义目标地址哦self.tag_url = "https://www.89ip.cn/"self.headers = {"User-Agent": UserAgent().random}def spider_index_response(self):response = requests.get(url=self.tag_url, headers=self.headers)return response.textdef create_soup(self):return BeautifulSoup(self.spider_index_response(), 'lxml')def spider_ip_port(self):soup = self.create_soup()tr_list = soup.select('div.layui-row.layui-col-space15 > div.layui-col-md8 > div > div.layui-form > table > tbody > tr')data_list = []for tr in tr_list:td_list = tr.find_all("td")ip = td_list[0].text.strip()port = td_list[1].string.strip()store = td_list[3].get_text().strip()# {"http":"http://IP:PORT"}data_list.append({"store": store, "proxies": {"http": f"http://{ip}:{port}"}})return data_listdef __spider_baidu(self, proxies):try:response = requests.get("http://httpbin.org/get", headers=self.headers, proxies=proxies, timeout=2)# 检查请求是否成功if response.status_code == 200:# 处理响应内容response.encoding = 'utf-8' # 设置响应内容的编码格式为utf-8# 解析JSON结果data = response.text # 获取响应信息print(data)else:print("请求失败:", response.status_code)except ProxyError:passdef test_ip(self):data_list = self.spider_ip_port()for index, data in enumerate(data_list, start=1):store = data.get("store")proxies = data.get("proxies")print(f"这是第 {index} 条数据! 运营商是 :>>> {store}")proxies = self.__spider_baidu(proxies=proxies)if proxies:print(f"当前代理可用")else:print(f"已废除")def main(self):self.test_ip()if __name__ == '__main__':s = SpiderIP()s.main()2 爬取豆瓣电影
import requests
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
from lxml import etreeclass SpiderBase:def __init__(self):self.tag_url_list = []self.headers = {"User-Agent": UserAgent().random}class SpiderTopSoup(SpiderBase):def __init__(self):super().__init__()self.tag_url_list = self.__create_tag_url_list()def __create_tag_url_list(self):tag_url_list = []for i in range(0, int(250 / 25)):if i == 0:tag_url = "https://movie.douban.com/top250"tag_url_list.append(tag_url)else:tag_url = f"https://movie.douban.com/top250?start={i * 25}"tag_url_list.append(tag_url)return tag_url_listdef __create_soup(self, page_text):return BeautifulSoup(page_text, 'lxml')def __spider_detail_data(self, soup):data_list = []div_list = soup.find_all("div", class_="item")for div in div_list:#pic_div = div.find("div", class_="pic")# 封面图链接地址img_url = pic_div.a.img.get("src")# 排名level = pic_div.em.text# 详情链接detail_url = pic_div.a.get("href")bd_a_span_list = div.find("div", class_="info").find("div", class_="hd").a.find_all("span")try:title = bd_a_span_list[0].textexcept:title = ""try:title_eg = bd_a_span_list[1].textexcept:title_eg = ""try:title_desc = bd_a_span_list[2].textexcept:title_desc = ""bd_div = div.find("div", class_="info").find("div", class_="bd")# 导演和上映日期action, publish_date = [data.replace("\xa0", "").strip() for data in bd_div.p.text.strip().split("\n")]# 评分 和 评价span_list = bd_div.find("div", class_="star").find_all("span")score = span_list[1].textcomment_num = span_list[-1].text[0:-3]# 格言try:quote = bd_div.find("p", class_="quote").span.textexcept:quote = ""data_list.append({"title": title,"title_eg": title_eg,"title_desc": title_desc,"img_url": img_url,"level": level,"detail_url": detail_url,"action": action,"publish_date": publish_date,"score": score,"comment_num": comment_num,"quote": quote,})print(data_list)return data_listdef spider_index_data(self, tag_url):response = requests.get(url=tag_url, headers=self.headers)soup = self.__create_soup(page_text=response.text)return self.__spider_detail_data(soup=soup)def main(self):data_list_all = []for tag_url in self.tag_url_list:data_list = self.spider_index_data(tag_url=tag_url)data_list_all.extend(data_list)print(len(data_list_all))if __name__ == '__main__':s = SpiderTopSoup()s.main()版本2(建议用这个)
import requests
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
from lxml import etreemovie_dict = {"title": '电影名',"title_eg": '英文名',"title_desc": '简介',"img_url": '图片链接',"level": '级别',"detail_url": '播放地址',"action": '导演和演员',"publish_date": '播放日期',"score": '评分',"comment_num": '评论数',"quote": '格言',
}class SpiderBase:def __init__(self):self.tag_url_list = []self.headers = {"User-Agent": UserAgent().random}class SpiderTopSoup(SpiderBase):def __init__(self):super().__init__()self.tag_url_list = self.__create_tag_url_list()def __create_tag_url_list(self):tag_url_list = []for i in range(0, int(250 / 25)):if i == 0:tag_url = "https://movie.douban.com/top250"tag_url_list.append(tag_url)else:tag_url = f"https://movie.douban.com/top250?start={i * 25}"tag_url_list.append(tag_url)return tag_url_listdef __create_soup(self, page_text):return BeautifulSoup(page_text, 'lxml')def __spider_detail_data(self, soup):data_list = []div_list = soup.find_all("div", class_="item")for div in div_list:#pic_div = div.find("div", class_="pic")# 封面图链接地址img_url = pic_div.a.img.get("src")# 排名level = pic_div.em.text# 详情链接detail_url = pic_div.a.get("href")bd_a_span_list = div.find("div", class_="info").find("div", class_="hd").a.find_all("span")try:title = bd_a_span_list[0].textexcept:title = ""try:title_eg = bd_a_span_list[1].textexcept:title_eg = ""try:title_desc = bd_a_span_list[2].textexcept:title_desc = ""bd_div = div.find("div", class_="info").find("div", class_="bd")# 导演和上映日期action, publish_date = [data.replace("\xa0", "").strip() for data in bd_div.p.text.strip().split("\n")]# 评分 和 评价span_list = bd_div.find("div", class_="star").find_all("span")score = span_list[1].textcomment_num = span_list[-1].text[0:-3]# 格言try:quote = bd_div.find("p", class_="quote").span.textexcept:quote = ""data_dict = {"title": title,"title_eg": title_eg,"title_desc": title_desc,"img_url": img_url,"level": level,"detail_url": detail_url,"action": action,"publish_date": publish_date,"score": score,"comment_num": comment_num,"quote": quote,}for key, value in movie_dict.items():new_dict = f"{value}: {data_dict[key]}"data_list.append(new_dict)print(data_list)return data_listdef spider_index_data(self, tag_url):response = requests.get(url=tag_url, headers=self.headers)soup = self.__create_soup(page_text=response.text)return self.__spider_detail_data(soup=soup)def main(self):data_list_all = []for tag_url in self.tag_url_list:data_list = self.spider_index_data(tag_url=tag_url)data_list_all.extend(data_list)print(len(data_list_all))if __name__ == '__main__':s = SpiderTopSoup()s.main()相关文章:

爬取89ip代理、 爬取豆瓣电影
1 爬取89ip代理 2 爬取豆瓣电影 1 爬取89ip代理 import requests from fake_useragent import UserAgent from bs4 import BeautifulSoup from requests.exceptions import ProxyErrorclass SpiderIP:def __init__(self):# 定义目标地址哦self.tag_url "https://www.89i…...

XBoot:基于Spring Boot 2.x的一站式前后端分离快速开发平台
XBoot:基于Spring Boot 2.x的一站式前后端分离快速开发平台 摘要 随着信息技术的迅速发展,快速构建高质量、高可靠性的企业级应用成为了迫切需求。XBoot,作为一个基于Spring Boot 2.x的一站式前后端分离快速开发平台,通过整合微信…...

24年最新抖音、视频号0成本挂机,单号每天收益上百,可无限挂
详情介绍 这次给大家带来5月份最新的短视频挂机项目,简单易上手,而且不需要任何投入,经过测试收益非常可观,软件完全免费,特别适合没有时间但是想做副业的家人们...

Day31:单元测试、项目监控、项目部署、项目总结、常见面试题
单元测试 保证独立性。 Assert:断言,一般用来比较是否相等,比如 Assert.assertEquals 在JUnit测试框架中,BeforeClass,Before,After和AfterClass是四个常用的注解,它们的作用如下: …...

Flutter笔记:使用Flutter私有类涉及的授权协议问题
Flutter笔记 使用Flutter私有类涉及的授权协议问题 - 文章信息 - Author: 李俊才 (jcLee95) Visit me at CSDN: https://jclee95.blog.csdn.netMy WebSite:http://thispage.tech/Email: 291148484163.com. Shenzhen ChinaAddress of this article:https://blog.cs…...

面试过程种遇到的面试题收集
文章目录 讲一讲这个项目是干什么的?需求规格说明书有哪些章节?职工部门层级如何显示在一张SQL表上?需求开发用到了哪些技术?HashMap 底层数据结构说一下?介绍一下红黑树?HashMap是线程不安全的,…...

Vue学习:21.mixins混入
在Vue中,mixins(混入)是一种用于分发Vue组件中可复用功能的灵活机制。它们允许你抽取组件中的共享功能,如数据、计算属性、方法、生命周期钩子等,并将其作为单独的模块复用到多个组件中。这种方式有助于保持代码的DRY&…...
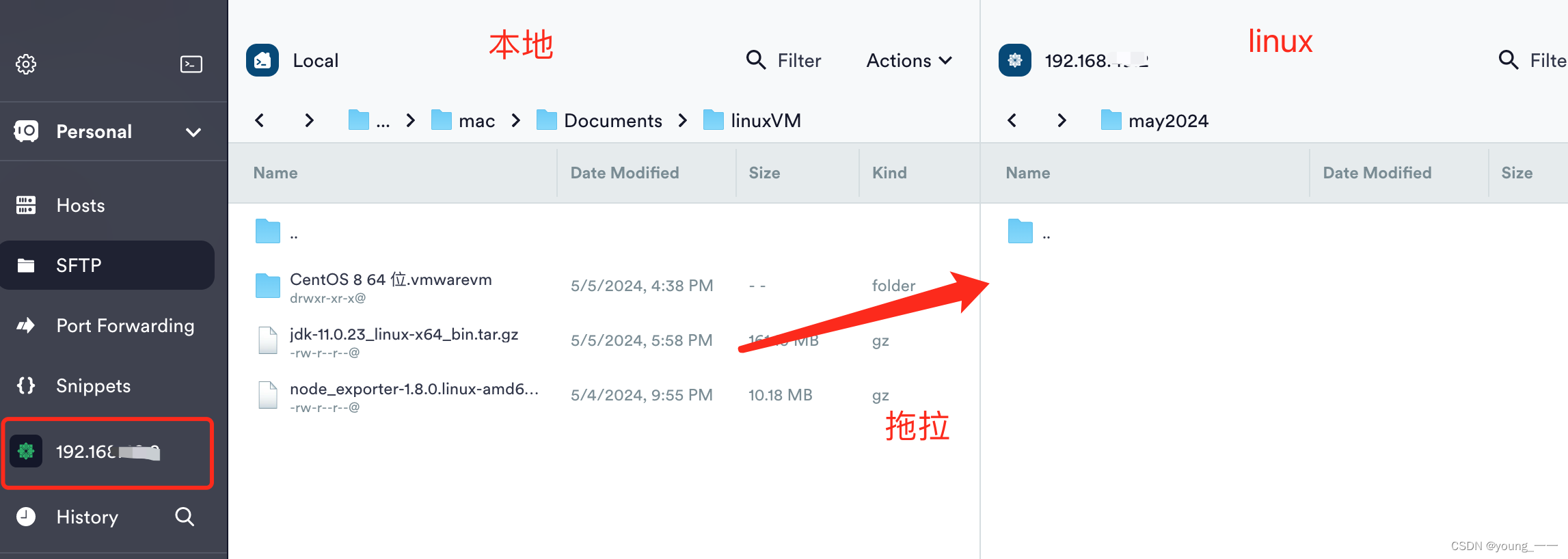
上传文件到 linux
一、mac 法一:scp 先进入mac的 Node_exporter文件(要上传的文件)目录下 输入scp -P 端口号 文件名 rootIP:/存放路径 scp -P 22 node_exporter-1.8.0.linux-amd64.tar.gz root192.***.2:/root 法二、 rz mac 安装 lrzsz,然后…...

NEO 学习之session7
文章目录 选项 A:它涉及学习标记数据。 选项 B:它需要预定义的输出标签进行训练。 选项 C:它涉及在未标记的数据中寻找模式和关系。 选项 D:它专注于根据输入-输出对进行预测。 答案:选项 C 描述了无监督学习的本质&am…...
毕业设计uniapp+vue有机农产品商城系统 销售统计图 微信小程序
本人在网上找了一下这方面的数据发现农村中的信心普及率很是低农民们都不是怎么会用手机顶多就是打打电话发发短信,平时不太会上网更不会想到通过网络手段去卖出自己的劳作成果—农产品,这无疑大大浪费了农民的劳动成果和国家资源也大大打击了人们的生产…...
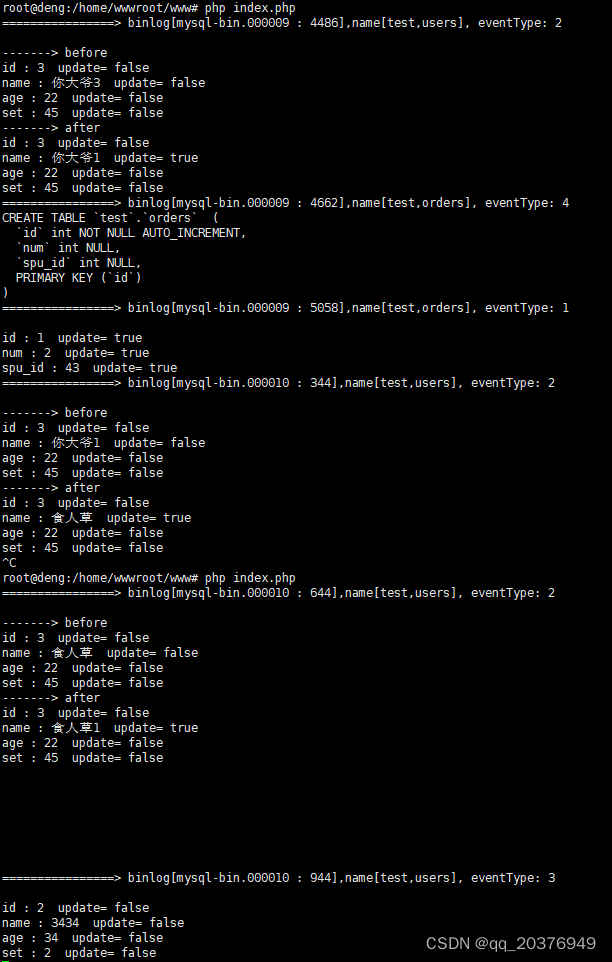
php使用Canal监听msyql
canal需要java8 去官网下载java8 安装JAVA #创建目录 mkdir -p /usr/local/java/ #解压到目录 tar zxvf jdk-8u411-linux-x64.tar.gz -C /usr/local/java/配置环境变量在 /etc/profile 最后加入 export JAVA_HOME/usr/local/java/jdk1.8.0_411 export CLASSPATH.:$JAVA_HOM…...
metabase部署与实践
1. 项目目标 (1)了解metabase特点 (2)熟练部署metabase工具 (3)掌握metabase基本使用 2. 项目准备 2.1. 规划节点 主机名 主机IP 节点规划 metabase 10.0.1.141 metabase 2.2. 基础准备 系统镜…...

nacos v2.2.3 docker简单安装使用
nacos v2.2.3 docker简单安装使用 Nacos 官方文档: https://nacos.io/zh-cn/docs/v2/quickstart/quick-start.html 控制台: http://127.0.0.1:8848/nacos/ 初始用户名、密码: 账号:nacos 密码:nacos 启动docker…...

java设计模式-生成器模式
文章目录 生成器模式(Builder)1、目的和适用场景2、角色和职责3、实现步骤4、示例15、示例26、优点7、示例场景 生成器模式(Builder) 生成器模式(Builder Pattern)是一种创建型设计模式,它用于…...

《前端面试题》- TypeScript - TypeScript的优/缺点
问题 简述TypeScript的优/缺点 答案 优点 增强了代码的可读性和可维护性包容性,js可以直接改成ts,ts编译报错也可以生成js文件,兼容第三方库,即使不是ts编写的社区活跃,完全支持es6 缺点 增加学习成本增加开发成…...
微服务---feign调用服务
目录 Feign简介 Feign的作用 Feign的使用步骤 引入依赖 具体业务逻辑 配置日志 在其它服务中使用接口 接着上一篇博客,我们讲过了nacos的基础使用,知道它是注册服务用的,接下来我们我们思考如果一个服务需要调用另一个服务的接口信息&…...

刷题笔记 - 滑动窗口
文章目录 滑动窗口最长无重复子串最小覆盖子串串联所有单词的子串长度最小的子数组滑动窗口最大值字符串的排列最小区间 滑动窗口 所有题目来自leetcode的回答:https://leetcode.cn/problems/longest-substring-without-repeating-characters/solutions/3982/hua-d…...
Docker搭建LNMP+Wordpress的实验
目录 一、项目的介绍 1、项目需求 2、服务器环境 3、任务需求 二、Linux系统基础镜像 三、部署Nginx 1、建立工作目录 2、编写Dockerfile 3、准备nginx.conf配置文件 4、设置自定义网段和创建镜像和容器 5、启动镜像容器 6、验证nginx 三、Mysql 1、建立工作目录…...

使用Python Pandas实现两表对应列相加(即使表头不同)
目录 引言 Pandas库简介 实现对应列相加 步骤一:加载数据 步骤二:重命名列 步骤三:对应列相加 步骤四:保存结果 案例分析 结论 引言 在数据分析和处理的日常工作中,我们经常会遇到需要将来自不同数据源的数据…...
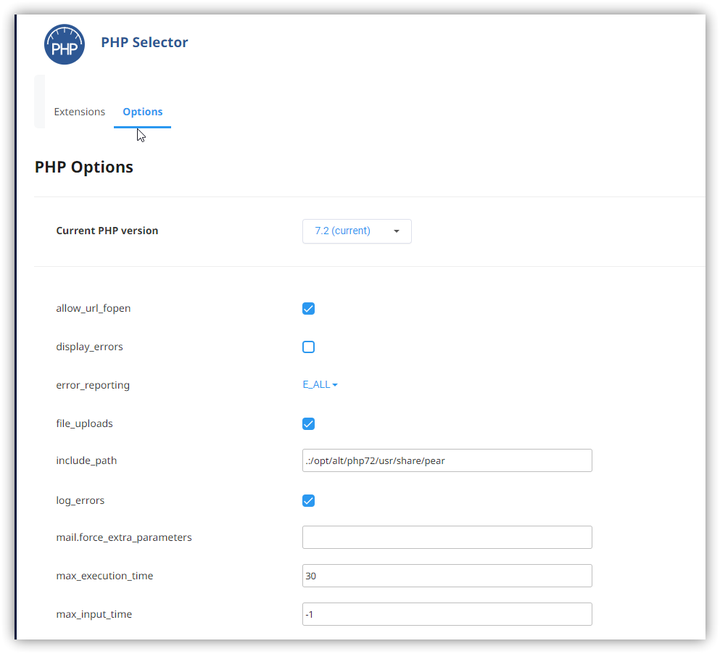
Linux 虚拟主机切换php版本及参数
我使用的Hostease的Linux虚拟主机产品,由于网站程序需要支持高版本的PHP,程序已经上传到主机,但是没有找到切换PHP以及查看PHP有哪些版本的位置,因此咨询了Hostease的技术支持,寻求帮助了解到可以实现在cPanel面板上找到此切换PHP版本的按钮&…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...

从RD、CS到WK:一文讲透SAR主流成像算法的演进与选型实战
从RD、CS到WK:SAR成像算法选型实战指南 当无人机掠过灾区上空,或卫星扫描地球表面时,合成孔径雷达(SAR)正通过电磁波穿透云层和黑暗,将地面信息转化为高分辨率图像。而决定图像质量的关键,在于工…...

Veo 2提示词性能瓶颈诊断:基于1726组AB测试的token敏感度热力图与阈值红线预警
更多请点击: https://kaifayun.com 第一章:Veo 2提示词编写最佳实践总览 Veo 2 是 Google 推出的高性能视频生成模型,其对提示词(prompt)的语义精度、结构清晰度和上下文控制能力高度敏感。高质量提示词并非简单堆砌关…...

MobX社区资源大全:10个必备工具、插件和扩展库推荐 [特殊字符]
MobX社区资源大全:10个必备工具、插件和扩展库推荐 🚀 【免费下载链接】MobX-Docs-CN MobX 中文文档 项目地址: https://gitcode.com/gh_mirrors/mo/MobX-Docs-CN MobX作为一个简单、可扩展的状态管理库,已经成为React开发者不可或缺的…...

GEO优化可以覆盖哪些搜索平台
这是一个非常现实的问题。企业投放资源做GEO,当然希望覆盖面越广越好。那么GEO优化到底能覆盖哪些平台?覆盖到什么程度?不同平台的GEO逻辑有什么差异?GEO平台覆盖的三个层级第一层级:通用大模型AI平台(核心…...

LPCM框架:大模型驱动的计算机架构设计革命
1. LPCM框架:计算机系统架构设计的范式革命计算机系统架构设计正站在历史性的转折点上。过去八十年来,从ENIAC的真空管到现代7纳米制程的异构计算芯片,架构设计始终遵循着"专家经验EDA工具"的传统范式。但随着摩尔定律逼近物理极限…...

WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求?
WMPFDebugger与微信开发者工具对比:哪个更适合你的调试需求? 【免费下载链接】WMPFDebugger Yet another WeChat miniapp debugger on Windows 项目地址: https://gitcode.com/gh_mirrors/wm/WMPFDebugger 在Windows平台的微信小程序开发中&#…...

如何快速定制Office界面:终极开源工具使用指南
如何快速定制Office界面:终极开源工具使用指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-editor O…...

解决claude code频繁封号与token不足的taotoken接入方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code频繁封号与Token不足的Taotoken接入方案 1. 问题背景:Claude Code用户面临的挑战 对于依赖Claude Cod…...