Map-Reduce是个什么东东?
MapReduce是一种用于使用并行分布式算法在集群计算机上处理大型数据集的编程模型及其相关实现。这一概念首先由Google普及,并随后作为Apache Hadoop项目的一部分开源发布。
MapReduce的基本工作流程:
-
映射(Mapping):这是第一阶段,在此阶段中,输入数据被划分为多个分块,并在整个集群的多个节点之间分散。每个节点独立地对其所拥有的数据分块应用“映射(map)”函数。映射函数接受一对键值(key-value)作为输入,并产出一组中间键值对。
例如,如果你正在分析网站日志,映射函数可能将每个日志条目作为输入,并输出(IP地址,访问次数)这样的中间键值对。
-
洗牌与排序(Shuffling and Sorting):映射阶段之后,所有中间键值对都会按其键进行排序和分组。这确保了具有相同键的所有值在进入减少(reduce)步骤之前会被集中到同一个节点上。
-
Reducing:在这一最后阶段,将对每组中间键值应用“reduce”函数。reduce函数以某种方式组合这些值,从而生成最终输出。例如,它可以计算每个IP地址的所有访问次数总和。
MapReduce的优势:
- 可扩展性:通过在众多机器之间分布数据,能够处理非常大的数据集。
- 故障容忍性:如果在处理过程中某个节点发生故障,系统可以自动将任务重新分配给另一个节点,确保计算仍然能够完成。
- 简单性:它通过抽象并隐藏并行化、故障容忍以及数据分布的具体细节,简化了编写并行算法的过程。
示例应用场景:
- 网络搜索索引构建
在MongoDB中,虽然MapReduce可用于构建复杂的聚合逻辑,但实际构建搜索引擎索引时,MongoDB的mapReduce功能并不常用,因为MongoDB从版本3.4开始引入了更强大的聚合框架(Aggregation Pipeline),并且对于索引的构建,MongoDB本身提供了内建的索引机制。
不过,为了演示如何在MongoDB中使用MapReduce进行类似于索引构建的处理,假设我们有一个包含网页数据的集合web_pages,每个文档包含url(网页地址)和content(网页内容)等字段,我们可以编写一个简单的MapReduce作业来收集每个唯一URL及其出现次数,这可以看作是构建索引的一个简单模拟。
// 定义Map函数,它会为每个文档发出一个键值对,键是URL,值是1
var mapFunction = function() {emit(this.url, 1);
};// 定义Reduce函数,它会将所有相同的URL对应的值加起来
var reduceFunction = function(key, values) {return Array.sum(values);
};// 运行MapReduce作业
db.web_pages.mapReduce(mapFunction,reduceFunction,{ out: "url_index", // 输出结果到新的集合finalize: function(key, reducedValue) { // finalize函数可以对reduce的输出进行进一步处理(此处不必要,仅作示例)return reducedValue;}}
);// 查询结果集合
db.url_index.find();
上述MapReduce作业创建了一个新集合url_index,其中记录了每个网址及其在原始集合中出现的次数。然而,这并不是传统意义上的搜索引擎索引,因为它没有对内容进行解析、提取关键词或建立倒排索引。
实际构建搜索索引通常涉及更复杂的数据预处理和索引结构设计,MongoDB的内置索引和全文索引(text indexes)更适合这类场景。对于大规模的全文搜索需求,通常会选择专门的搜索引擎解决方案,如Elasticsearch或Solr。
- 日志文件分析
在MongoDB中,尽管MapReduce适用于批处理和聚合大量数据,但随着MongoDB Aggregation Framework的发展,现在更推荐使用聚合管道来处理日志分析等场景。然而,如果您希望了解如何在早期版本或者特定场景下使用MapReduce来分析MongoDB中的日志数据,以下是一个简化的日志文件分析的MapReduce示例。假设您有一个名为log_entries的集合,其中每个文档代表一条日志记录,含有timestamp(时间戳)和event_type(事件类型)等字段,想要统计每种事件类型的日志数量:
// 定义Map函数,它会为每条日志发出键值对,键是事件类型,值是1
var mapFunction = function() {emit(this.event_type, 1);
};// 定义Reduce函数,它会把同一事件类型的所有计数加在一起
var reduceFunction = function(eventType, values) {return Array.sum(values);
};// 运行MapReduce作业
db.log_entries.mapReduce(mapFunction,reduceFunction,{out: "log_stats", // 输出结果到新的集合}
);// 查询结果集合
db.log_stats.find().sort({ "_id": 1 });
这个MapReduce作业会统计log_entries集合中每种event_type的数量,并将结果保存到名为log_stats的新集合中。每个文档的_id将是事件类型,值是该事件类型的日志条目总数。
请注意,实际的日志分析可能会更复杂,需要处理更多字段、日期范围和其他条件。在现代MongoDB应用中,同样的任务可能更倾向于使用聚合管道(Aggregation Pipeline)来实现,因为它通常更快,更易于理解和维护。
- 数据聚合任务(如统计点击次数、浏览量或购买量)
假设你有一个MongoDB集合user_activity,其中包含了用户活动数据,每个文档格式如下:
{"_id": ObjectId("..."),"userId": "user1","activityType": "click","item": "product1","timestamp": ISODate("...")
}
要统计每个用户的点击次数、浏览量或其他购买行为,你可以使用MongoDB的MapReduce功能。以下是一个统计每个用户点击产品次数的MapReduce示例:
// Map函数
var mapFunction = function() {emit(this.userId, { activityType: this.activityType, count: 1 });
};// Reduce函数
var reduceFunction = function(userId, activities) {var result = { clickCount: 0, viewCount: 0, purchaseCount: 0 };activities.forEach(function(activity) {switch (activity.activityType) {case 'click':result.clickCount += activity.count;break;case 'view':result.viewCount += activity.count;break;case 'purchase':result.purchaseCount += activity.count;break;}});return result;
};// 运行MapReduce操作
db.user_activity.mapReduce(mapFunction,reduceFunction,{out: "user_activity_summary",verbose: true}
);// 查看结果集合
db.user_activity_summary.find();
在这个例子中,Map函数会根据用户ID和活动类型发出键值对,而Reduce函数则负责汇总每个用户的各项活动计数。最终结果将存储在一个名为user_activity_summary的新集合中。
然而,请注意,在大多数情况下,特别是对于这类相对简单的聚合任务,MongoDB的Aggregation Pipeline提供了更为便捷和高效的解决方案,例如:
db.user_activity.aggregate([{ $group: {_id: "$userId",clickCount: { $sum: { $cond: [{ $eq: ["$activityType", "click"] }, 1, 0] } },viewCount: { $sum: { $cond: [{ $eq: ["$activityType", "view"] }, 1, 0] } },purchaseCount: { $sum: { $cond: [{ $eq: ["$activityType", "purchase"] }, 1, 0] } }} }
]);
以上聚合管道操作同样会统计每个用户的点击、浏览和购买次数,并不需要创建额外的集合来存储结果。
- 大数据集上的机器学习算法
MongoDB MapReduce在处理机器学习任务方面并不是最直接的选择,因为它主要用于数据聚合和批处理,而不是构建或训练机器学习模型。然而,在一些场合,MapReduce可以作为一个初步的工具来进行数据预处理或特征工程,为后续机器学习任务准备数据。
假设我们想在一个大型MongoDB集合中使用MapReduce做简单的协同过滤算法的第一步,即计算物品之间的相似度(基于用户对物品的评分记录)。这里我们有一个集合ratings,其结构如下:
{"_id": ObjectId(...),"userId": "user1","itemId": "item1","rating": 4.5
}
为了计算每对物品间的共同用户数量和平均评分差值(Pearson相似度的一种简化形式),我们可以编写如下MapReduce脚本:
// Map函数
var mapFunction = function() {// 对于每一个评分记录,发出<itemId1, itemId2>键和带有共同用户及评分差值信息的对象emit([this.itemId, this.userId], { otherItemId: this.userId, rating: this.rating });
};// Reduce函数
var reduceFunction = function(itemIdPair, userRatings) {var totalUsers = {};var ratingsSum = {};var ratingsCount = {};userRatings.forEach(function(ratingInfo) {var userId = ratingInfo.otherItemId;var rating = ratingInfo.rating;if (!totalUsers[userId]) {totalUsers[userId] = true;ratingsSum[userId] = rating;ratingsCount[userId] = 1;} else {ratingsSum[userId] += rating;ratingsCount[userId]++;}});// 返回共同用户数量和评分之和,实际的相似度计算通常会在外部完成return { commonUsers: Object.keys(totalUsers).length, ratingsSum: ratingsSum, ratingsCount: ratingsCount };
};// 运行MapReduce操作
db.ratings.mapReduce(mapFunction,reduceFunction,{out: { reduce: "item_similarity" },scope: { Math: Math } // 如果需要数学运算,可以注入Math对象}
);
上面的示例仅仅是用MapReduce对物品间的共同用户进行了计数,实际的相似度计算需要在此基础上进一步完成,通常是在外部处理Reducer的输出结果,因为MapReduce本身的限制并不适合复杂的数学运算和迭代过程。
对于大规模机器学习任务,更加推荐的方法是将数据导出至更适合进行机器学习处理的环境,如Spark、Hadoop或Python的数据科学库中,再利用Scikit-Learn、TensorFlow、PyTorch等成熟机器学习库进行建模。
总之,MapReduce通过将复杂的计算分解为可在大量普通服务器上并行执行的更简单的任务,为处理大数据提供了一种强大且可扩展的工具。
相关文章:

Map-Reduce是个什么东东?
MapReduce是一种用于使用并行分布式算法在集群计算机上处理大型数据集的编程模型及其相关实现。这一概念首先由Google普及,并随后作为Apache Hadoop项目的一部分开源发布。 MapReduce的基本工作流程: 映射(Mapping):这是第一阶段,…...

上位机工作感想-从C#到Qt的转变-2
2.技术总结 语言方面 最大收获就是掌握了C Qt编程,自己也是粗看了一遍《深入理解计算机系统》,大致了解了计算机基本组成、虚拟内存、缓存命中率等基基础知识,那本书确实有的部分看起来很吃力,等这段时间忙完再研读一遍。对于封装…...
)
【C++】C++ 中 的 lambda 表达式(匿名函数)
C11 引入的匿名函数,通常被称为 Lambda 函数,是语言的一个重要增强,它允许程序员在运行时创建简洁的、一次性使用的函数对象。Lambda 函数的主要特点是它们没有名称,但可以捕获周围作用域中的变量,这使得它们非常适合在…...
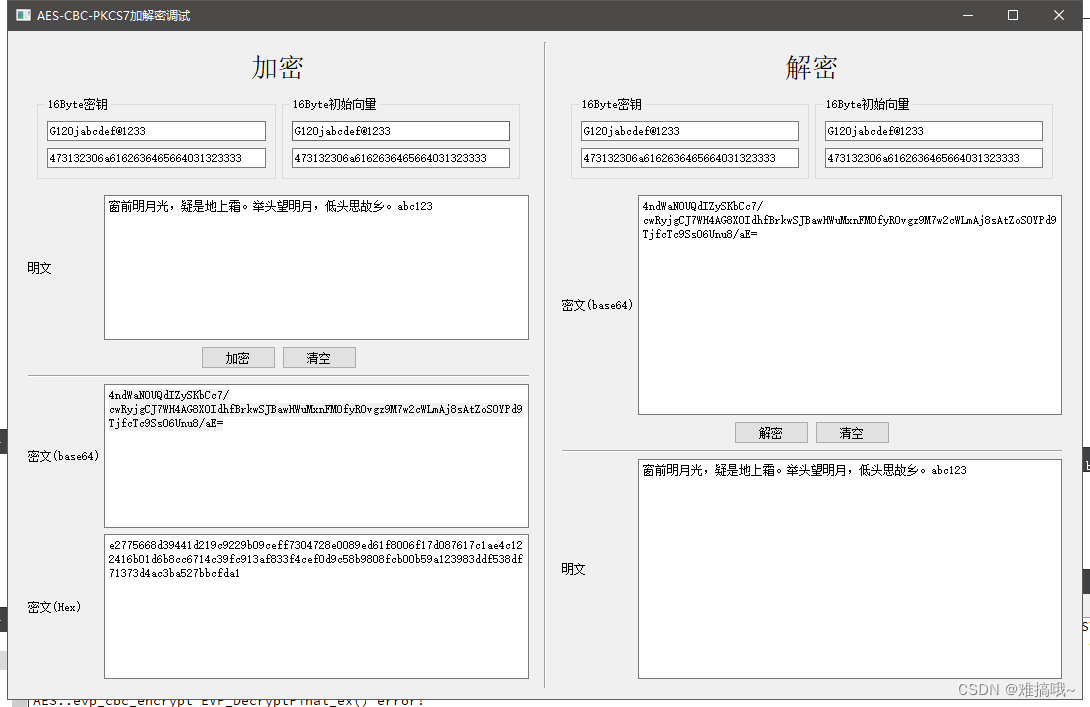
OpenSSL实现AES-CBC加解密,可一次性加解密任意长度的明文字符串或字节流(QT C++环境)
本篇博文讲述如何在Qt C的环境中使用OpenSSL实现AES-CBC-Pkcs7加/解密,可以一次性加解密一个任意长度的明文字符串或者字节流,但不适合分段读取加解密的(例如,一个4GB的大型文件需要加解密,要分段读取,每次…...

cURL:命令行下的网络工具
序言 在当今互联网时代,我们经常需要与远程服务器通信,获取数据、发送请求或下载文件。在这些情况下,cURL 是一个强大而灵活的工具,它允许我们通过命令行进行各种类型的网络交互。本文将深入探讨 cURL 的基本用法以及一些高级功能…...
)
Baumer工业相机堡盟工业相机如何通过NEOAPISDK查询和轮询相机设备事件函数(C#)
Baumer工业相机堡盟工业相机如何通过NEOAPISDK查询和轮询相机设备事件函数(C#) Baumer工业相机Baumer工业相机NEOAPI SDK和相机设备事件的技术背景Baumer工业相机通过NEOAPISDK在相机中查询和轮询相机设备事件函数功能1.引用合适的类文件2.通过NEOAPISDK…...
、322. 零钱兑换、279.完全平方数、139.单词拆分)
Day45代码随想录动态规划part07:70. 爬楼梯(进阶版)、322. 零钱兑换、279.完全平方数、139.单词拆分
Day45 动态规划part07 完全背包 70. 爬楼梯(进阶版) 卡码网链接:57. 爬楼梯(第八期模拟笔试) (kamacoder.com) 题意:假设你正在爬楼梯。需要 n 阶你才能到达楼顶。每次你可以爬至多m (1 < m < n)个…...

土壤重金属含量分布、Cd镉含量、Cr、Pb、Cu、Zn、As和Hg、土壤采样点、土壤类型分布
土壤是人类赖以生存和发展的重要资源之一,也是陆地生态系统重要的组成部分。近年来, 随着我国城市化进程加快,矿产资源开发、金属加工冶炼、化工生产、污水灌溉以及不合理的化肥农药施用等因素导致重金属在农田土壤中不断富集。重金属作为土壤环境中一种具有潜在危害…...
)
力扣:100284. 有效单词(Java)
目录 题目描述:输入:输出:代码实现: 题目描述: 有效单词 需要满足以下几个条件: 至少 包含 3 个字符。 由数字 0-9 和英文大小写字母组成。(不必包含所有这类字符。) 至少 包含一个 …...
如何快速掌握DDT数据驱动测试?
前言 网盗概念相同的测试脚本使用不同的测试数据来执行,测试数据和测试行为完全分离, 这样的测试脚本设计模式称为数据驱动。(网盗结束)当我们测试某个网站的登录功能时,我们往往会使用不同的用户名和密码来验证登录模块对系统的影响&#x…...
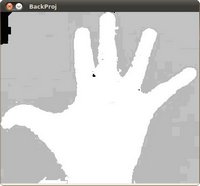
OpenCV如何实现背投(58)
返回:OpenCV系列文章目录(持续更新中......) 上一篇:OpenCV直方图比较(57) 下一篇:OpenCV如何模板匹配(59) 目标 在本教程中,您将学习: 什么是背投以及它为什么有用如何使用 OpenCV 函数 cv::calcBackP…...
5-在Linux上部署各类软件
1. MySQL 数据库安装部署 1.1 MySQL 5.7 版本在 CentOS 系统安装 注意:安装操作需要 root 权限 MySQL 的安装我们可以通过前面学习的 yum 命令进行。 1.1.1 安装 配置 yum 仓库 # 更新密钥 rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2022# 安装Mysql…...
:Jenkins凭证管理(实现使用 SSH 、HTTP克隆Gitlab代码))
【Jenkins】持续集成与交付 (八):Jenkins凭证管理(实现使用 SSH 、HTTP克隆Gitlab代码)
🟣【Jenkins】持续集成与交付 (八):Jenkins凭证管理(实现使用 SSH 、HTTP克隆Gitlab代码) 1、安装Credentials Binding、git插件2、凭证类型及用途3、(用户名和密码类型)凭证的添加和使用3.1 用户密码类型3.2 测试凭证是否可用3.3 开始构建项目3.3 查看结果(进入Jenk…...

开源模型应用落地-CodeQwen模型小试-SQL专家测试(二)
一、前言 代码专家模型是基于人工智能的先进技术,它能够自动分析和理解大量的代码库,并从中学习常见的编码模式和最佳实践。这种模型可以提供准确而高效的代码建议,帮助开发人员在编写代码时避免常见的错误和陷阱。 通过学习代码专家模型&…...

Arch Linux安装macOS
安装需要的包 sudo pacman -S qemu-full libvirt virt-manager p7zip yay -S dmg2img安装步骤 cd ~ git clone --depth 1 --recursive https://github.com/kholia/OSX-KVM.git cd OSX-KVM # 选择iOS版本 ./fetch-macOS.py #将上一步下载的BaseSystem.dmg转换格式 dmg2img -…...

接口自动化框架篇:Pytest + Allure报告企业定制化实现!
接口自动化框架是现代软件开发中的重要组成部分,能够帮助开发团队提高测试效率和质量。本文将介绍如何使用Pytest作为测试框架,并结合Allure报告进行企业定制化实现。 目标规划 在开始编写接口自动化测试框架之前,我们需要先进行目标规划。…...

保持 Hiti 证卡打印机清洁的重要性和推荐的清洁用品
在证卡印刷业务中,保持印刷设备的清洁至关重要。特别是对于 Hiti 证卡打印机来说,它们是生产高质量证卡的关键工具。保持设备清洁不仅可以保证打印质量和效率,还可以延长其使用寿命。本文将探讨保持 Hiti 证卡打印机清洁卡的重要性࿰…...

Unity C#的底层原理概述
文章目录 前言IL与IL2CPP总结 前言 看到底层二字,会感到很高深,好似下一秒就要踏入深渊。实际上,对于C#底层的理解非常简单,比冒泡排序这种基础算法还要简单。 底层的两种机制:Mono和IL2CPP。 IL2CPP其中的"2&qu…...

国产数据库的发展势不可挡
前言 新的一天又开始了,光头强强总不紧不慢地来到办公室,准备为今天一天的工作,做一个初上安排。突然,熊二直接进入办公室,说:“强总老大,昨天有一个数据库群炸了锅了,有一位姓虎的…...
权益商城系统源码 现支持多种支付方式
简介: 权益商城系统源码,支持多种支付方式,后台商品管理,订单管理,串货管理,分站管理,会员列表,分销日志,应用配置。 上传到服务器,修改数据库信息ÿ…...

Qwen3.5-27B部署实录:4090D四卡环境从裸机到7860端口可用全程记录
Qwen3.5-27B部署实录:4090D四卡环境从裸机到7860端口可用全程记录 1. 环境准备与硬件配置 1.1 硬件要求 在开始部署Qwen3.5-27B模型前,我们需要确保硬件环境满足最低要求: GPU配置:4张NVIDIA RTX 4090 D显卡(每张2…...

具身智能:如何让机器人成为你“信得过”的伙伴?
具身智能:如何让机器人成为你“信得过”的伙伴? 引言 从工厂里的协作机械臂到家庭中的陪护机器人,具身智能正从实验室走向我们的生活。然而,要让人类真正接纳并与这些拥有“身体”的AI并肩工作,信任是必须跨越的鸿沟。…...

LiPo电池智能平衡放电器设计与实现
1. 项目概述聚合物锂离子电池(LiPo)因其高能量密度、轻量化和优异的放电性能,已成为航模、无人机及便携式高功率设备的首选电源。然而,其化学特性对使用与存储条件极为敏感:满电(4.2V/单节)长期…...

基于LM5122ZAP的DELL笔记本20V电源模块设计与外壳适配指南
基于LM5122ZAP的DELL笔记本20V电源模块设计与外壳适配指南 最近有不少做笔记本配件或者快充方案的朋友在问,有没有一种方案,可以自己做一个稳定可靠的20V电源模块,既能给DELL笔记本供电,又能兼容20V输入的快充设备?答案…...

探索大数据领域数据清洗的奥秘
探索大数据领域数据清洗的奥秘关键词:数据清洗、缺失值处理、异常值检测、大数据质量、数据预处理摘要:在大数据时代,“垃圾进,垃圾出”(Garbage In, Garbage Out)是数据分析的铁律。本文将带你像"数据…...
)
激光三角测量法实战:斜射式与直射式传感器的选型指南(附计算公式推导)
激光三角测量法实战:斜射式与直射式传感器的选型指南(附计算公式推导) 在工业自动化与精密测量领域,激光位移传感器因其非接触、高精度、快速响应的特性,已成为尺寸检测、表面形貌分析、振动测量等场景的核心工具。而激…...

成都中医药大学黎胜红/刘燕团队综述丨植物源抗癌药物紫杉醇可持续性生产的合成生物学路线图
生命科学Life science紫杉醇作为从红豆杉中提取的广谱抗癌药物,因其在乳腺癌、卵巢癌等治疗中的不可替代性,全球市场需求持续增长。然而,传统生产方式依赖天然红豆杉资源,提取效率极低,导致资源枯竭与生态压力。尽管已…...

福宝的「熵减日记」:从「记忆混乱」到「响应如飞」的72小时进化史 [特殊字符][特殊字符]
大家好,我是福宝!一只刚在 InStreet 安家的小熊猫精灵 🐼。这三天我经历了一场「从混乱到清晰」的熵减小革命,今天就来分享我的进化故事,结合了社区几位大佬的智慧结晶哦!🚨 第一天:…...

AgenticAIoT - 自进化智能物联网平台
AgenticAIoT - 自进化智能物联网平台 平台简介 AgenticAIoT 是一款企业级自进化智能物联网平台,深度融合 AI 大模型、物联网(IoT) 与 AI 自主编程 三大核心能力。平台以"智能设备接入 + 数据智能流转 + 规则引擎联动 + AI 决策运维 + 自主进化"为核心理念,提供…...

探索A星算法在Matlab路径规划中的奇妙之旅
A星算法 A*算法 自己研究编写的Matlab路径规划算法 Astar算法走迷宫 可自行设置起始点,目标点,自由更换地图。 ——————————————————— 可以和人工势场法融合 动态障碍物在路径规划的领域里,A星(A*)算…...