Java中使用FlatBuffers实现序列化
Java 中的 FlatBuffers有助于高速数据序列化/反序列化,消除解析开销。它由 Google 开发,为跨平台数据交换提供无模式、内存高效的解决方案。 Java 开发人员可以利用其直接内存访问来实现最佳性能和最小内存占用,从而提高应用程序速度、可扩展性和互操作性。让我们深入了解 Java FlatBuffers 序列化。
什么是Java中的序列化和FlatBuffers?
在Java编程中,序列化是指将对象转换为字节流的过程。然后可以将该字节流存储在文件中、通过网络发送或保存在数据库中。序列化对于不同系统之间的数据持久性和通信至关重要。
Java 中的序列化
Java 通过 Serialized 接口提供了对序列化的内置支持。实现此接口的类可以使用 Java 的 ObjectOutputStream 和 ObjectInputStream 类进行序列化和反序列化。此外,Java 还提供了一个可外部化的接口,用于对序列化过程进行更细粒度的控制。
Java 中的 FlatBuffer
FlatBuffers是Google开发的一个高效的跨平台序列化库。与传统的序列化方法不同,FlatBuffers 不需要解析。相反,它们提供对序列化数据的直接访问,从而加快序列化和反序列化速度。在 Java 中,FlatBuffers 是通过代码生成器实现的,该代码生成器根据模式定义生成 Java 类。这些生成的类使开发人员能够轻松地序列化和反序列化数据,而无需手动解析或反射。这样可以以最小的开销实现高性能的数据处理。
使用 FlatBuffers 的好处
- 高效的内存使用:与其他序列化格式相比,FlatBuffers 使用内存的效率更高。
- 高速序列化和反序列化:直接访问序列化数据可以加快处理速度。
- 支持架构演变:FlatBuffers 允许架构更改,而不会破坏向后兼容性。
- 平台独立性:序列化数据可以在不同平台和编程语言之间共享。
代码演示:
依赖:
FlatBuffers 结构schema文件 (.fbs)
在 FlatBuffers 中,数据结构是使用扩展名为.fbs.该文件指定数据结构的布局,包括其字段及其类型。让我们看一下定义人员对象的示例模式文件:
// Define schema in a .fbs file
table Person {
name: string;
age: int;
hobbies: [string];
}
在此schema中,我们定义一个名为“Person”的表,其中包含三个字段:字符串类型的“name”、int 类型的“age”和字符串数组的“hobbies”。该模式充当生成代码的蓝图,以便在序列化和反序列化过程中使用定义的数据结构。
使用 FlatBuffers
一旦定义了结构schema,我们就可以使用 FlatBuffers 代码生成器来生成与该结构schema相对应的 Java 类。
-
这些生成的类提供了创建、访问和操作已定义数据结构实例的方法。
-
该类Person将由 FlatBuffer 编译器 ( ) 根据提供的结构schema生成flatc,并将包含操作已定义数据结构所需的类和方法。
值得庆幸的是,所有这些都是由 IDE 自动完成的,因为我们已经在项目中包含了必要的依赖项。
// Java code to serialize and deserializepackage com.jcg.example;
import com.google.flatbuffers.FlatBufferBuilder;
import com.example.Person;
public class Main {
public static void main(String[] args) { // Create FlatBufferBuilder FlatBufferBuilder builder = new FlatBufferBuilder(); // Create hobbies strings int[] hobbies = {
builder.createString("Reading"),
builder.createString("Gaming")
}; // Serialize person object int personOffset = Person.createPerson(builder, builder.createString("John"), 30, Person.createHobbiesVector(builder, hobbies));
builder.finish(personOffset); // Deserialize person object byte[] buf = builder.sizedByteArray();
ByteBuffer bb = ByteBuffer.wrap(buf);
Person person = Person.getRootAsPerson(bb); // Access deserialized data System.out.println("Name: " + person.name());
System.out.println("Age: " + person.age());
for (int i = 0; i < person.hobbiesLength(); i++) {
System.out.println("Hobby " + (i+1) + ": " + person.hobbies(i));
}
}
}
在此代码中,我们使用 FlatBufferBuilder 创建一个 FlatBuffer 实例,表示一个名为““John”, age 30, 爱好hobby是 “Reading” 和“Gaming”的Person人员对象。然后,我们序列化该对象,将其反序列化回来,并访问反序列化的数据进行打印。
代码输出
代码输出显示了使用 FlatBuffers 在 Java 中对人对象进行序列化和反序列化后的反序列化数据。
Name: John
Age: 30
Hobby 1: Reading
Hobby 2: Gaming
使用 FlatBuffers 进行 JSON 转换
将 FlatBuffers 数据转换为 JSON 格式非常简单。 FlatBuffers 提供了直接将 FlatBuffers 对象序列化为 JSON 字符串的方法。这些方法根据模式定义自动生成数据的 JSON 表示形式,从而可以轻松地在 FlatBuffers 应用程序中使用 JSON 数据。
考虑一个简单的例子,我们有一个包含姓名、年龄和爱好等字段的人的模式。我们可以在文件中定义此模式.fbs并使用 FlatBuffers 代码生成工具生成 Java 类。然后,我们可以使用生成的代码将 JSON 数据解析为 FlatBuffers 对象,反之亦然。
import com.google.flatbuffers.FlatBufferBuilder;
import com.google.flatbuffers.FlexBuffers;
public class Main {
public static void main(String[] args) {
// Define schema for a person String schema = "table Person { name:string; age:int; hobbies:[string]; }"; // Create FlatBufferBuilder FlatBufferBuilder builder = new FlatBufferBuilder(); // Start building FlatBuffer int nameOffset = builder.createString("John");
int[] hobbiesOffsets = { builder.createString("Reading"), builder.createString("Gaming") };
int hobbiesVector = Person.createHobbiesVector(builder, hobbiesOffsets);
Person.startPerson(builder);
Person.addName(builder, nameOffset);
Person.addAge(builder, 30);
Person.addHobbies(builder, hobbiesVector);
int personOffset = Person.endPerson(builder);
Person.finishPersonBuffer(builder, personOffset); // Serialize FlatBuffer to JSON byte[] flatBufferBytes = builder.sizedByteArray();
FlexBuffers.TypedBuffer buffer = FlexBuffers.getRoot(new FlexBuffers.ByteBufferWrapper(flatBufferBytes));
String json = buffer.toJson(schema); // Print JSON representation System.out.println("JSON representation:");
System.out.println(json); // Deserialize JSON to FlatBuffer FlexBuffers.Builder flexBuilder = new FlexBuffers.Builder();
flexBuilder.fromJson(json, schema);
FlexBuffers.TypedBuffer typedBuffer = flexBuilder.finish();
byte[] flatBufferFromJson = typedBuffer.toByteArray(); // Access FlatBuffer data ByteBuffer byteBuffer = ByteBuffer.wrap(flatBufferFromJson);
Person person = Person.getRootAsPerson(byteBuffer);
System.out.println("\nDeserialized data:");
System.out.println("Name: " + person.name());
System.out.println("Age: " + person.age());
System.out.println("Hobbies:");
for (int i = 0; i < person.hobbiesLength(); i++) {
System.out.println("- " + person.hobbies(i));
}
}
}
在此示例中,我们为一个人定义一个schema结构,其中包含姓名、年龄和爱好等字段。然后,我们创建一个 FlatBuffer 来表示具有一些示例数据的人员对象。我们使用 FlexBuffers 将此 FlatBuffer 序列化为 JSON 格式。之后,我们将 JSON 反序列化回 FlatBuffer 并访问数据。
上述代码的输出将是:
JSON representation:
{
"name": "John", "age": 30, "hobbies": ["Reading", "Gaming"]
}
Deserialized data:
Name: John
Age: 30
Hobbies:
- Reading
- Gaming
结论
使用 FlatBuffers 就像拥有在计算机程序中存储和组织数据的超能力。首先描述数据在称为模式的特殊文件中的外观。然后,您使用工具根据该架构生成代码。此代码可帮助您轻松快速地管理数据,而不会牺牲速度。
FlatBuffers 很棒,因为它可以让您直接以紧凑的序列化形式访问数据,从而使其快速高效。另外,它很灵活——即使您稍后更改数据结构,FlatBuffers 也可以顺利处理。
FlatBuffers 的一个很酷的事情是它可以轻松地在自己的格式和 JSON 之间转换数据,JSON 是一种常见的数据表示方式。这意味着您可以使用 FlatBuffers 来处理 JSON 数据,而不会减慢程序速度。
总体而言,FlatBuffers 使程序中的数据处理变得简单。无论您是存储信息还是在不同系统之间共享信息,FlatBuffers 都能以其易于使用的工具和快速的性能满足您的需求。
https://www.jdon.com/73592.html
相关文章:

Java中使用FlatBuffers实现序列化
Java 中的 FlatBuffers有助于高速数据序列化/反序列化,消除解析开销。它由 Google 开发,为跨平台数据交换提供无模式、内存高效的解决方案。 Java 开发人员可以利用其直接内存访问来实现最佳性能和最小内存占用,从而提高应用程序速度、可扩展…...
[图解]SysML和EA建模住宅安全系统-02
1 00:00:00,900 --> 00:00:02,690 这个就是一个块定义图了 2 00:00:03,790 --> 00:00:04,780 简称BDD 3 00:00:05,610 --> 00:00:08,070 实际上就是UML里面的类图 4 00:00:08,080 --> 00:00:09,950 和组件图的一个结合体 5 00:00:13,150 --> 00:00:14,690 我…...

2024年北京服贸会媒体邀约资源有哪些?
传媒如春雨,润物细无声,大家好,我是51媒体网胡老师。 2024年北京服贸会(中国国际服务贸易交易会,简称CIFTIS)作为中国重要的国际性服务贸易盛会,会吸引众多媒体的关注和参与。媒体邀约资源通常…...

大语言模型LLM入门篇
大模型席卷全球,彷佛得模型者得天下。对于IT行业来说,以后可能没有各种软件了,只有各种各样的智体(Agent)调用各种各样的API。在这种大势下,笔者也阅读了很多大模型相关的资料,和很多新手一样&a…...

Alibaba Cloud Linux 安装mysql及注意事项
1.安装mysql #1.运行以下命令,更新YUM源。 sudo rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el7-7.noarch.rpm#2.(可选)当操作系统为Alibaba Cloud Linux 3时,执行如下命令,安装MySQL所需的库文件…...
)
设计模式——工厂模式(Factory)
工厂模式(Factory Pattern)是一种常用的设计模式,它提供了一种封装创建对象过程的方法。通过工厂方法或工厂类,你可以将对象的创建与使用分离,使得代码更加灵活和可维护。工厂模式主要分为三种类型:简单工厂…...

NVIDIA Omniverse Cloud API支持数字孪生开发,可解决复杂AI问题 | 最新快讯
在全球范围内,价值超过 50 万亿美元的重工业市场,正在竞相实现数字化。 基于此,为帮助数字孪生技术更好地赋能千行百业,AI 企业 NVIDIA 在架构底层算力的同时,也搭建了 NVIDIA AI Enterprise 和 Omniverse 两大平台。 …...
智慧电力,山海鲸引领
随着科技的不断进步和电力行业的快速发展,智能化管理已成为电力行业的重要趋势。在这一背景下,山海鲸智慧电力管理系统凭借其卓越的性能和创新的功能,为电力行业带来了革命性的改变。 山海鲸智慧电力管理系统是一套集数据采集、分析、展示于…...

【文章转载】ChatGPT 提示词十级技巧: 从新手到专家
学习了微博网友宝玉xp老师《ChatGPT 提示词十级技巧: 从新手到专家》 个人学习要点: 1、关于提示中避免使用否定句,播主说:“没有人能准确解释为什么,但大语言模型在你告诉它去做某事时,表现似乎比你让它不做某事时更…...
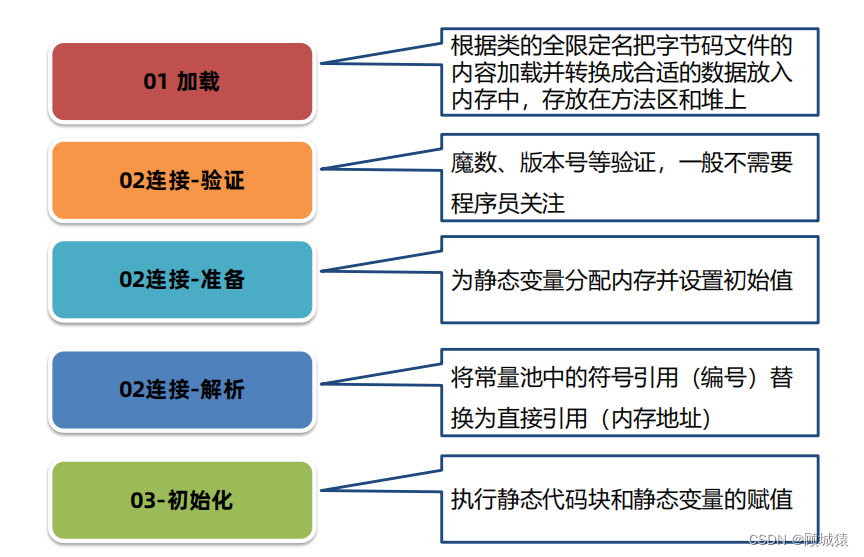
类的生命周期
目录 一、概述 二、加载阶段 三、连接阶段 连接阶段之验证 连接阶段之准备 连接阶段之解析 四、初始化阶段 五、总结 一、概述 类的生命周期描述了一个类加载、使用、卸载的整个过程。 也是其他知识的基础: 类的生命周期: 二、加载阶段 加载(Loading…...

AI赋能分层模式,解构未来,智领风潮
🌈 个人主页:danci_ 🔥 系列专栏:《设计模式》 💪🏻 制定明确可量化的目标,坚持默默的做事。 🚀 转载自热榜文章🔥:探索设计模式的魅力:AI赋能分…...
Linux平台下muduo网络库源码编译安装与测试,包含boost库的安装与测试!!!!
最近在学习muduo网络库,先来记录一下如何在Linux平台下编译安装以及测试muduo网络库源码。 获取源码 muduo库源码github仓库地址: https://github.com/chenshuo/muduo 在linux系统下,输入 git clone https://github.com/chenshuo/muduo.git…...

MATLAB 函数
MATLAB 函数 函数是一起执行任务的一组语句。在MATLAB中,函数是在单独的文件中定义的。文件名和函数名应该相同。 函数在其自己的工作空间(也称为本地工作空间)中对变量进行操作,与在MATLAB命令提示符下访问的工作空间࿰…...
spring高级篇(七)
1、异常处理 在DispatcherServlet中,doDispatch(HttpServletRequest request, HttpServletResponse response) 方法用于进行任务处理: 在捕获到异常后没有立刻进行处理,而是先用一个局部变量dispatchException进行记录,然后统一由…...

根据token获取了username后,能否在其他地方使用这个获取的username,或者在其他地方如何获取username?
当然可以在其他地方使用获取到的用户名。一旦你从token中获取到用户名,你可以将其存储在能够在整个应用程序中访问的地方。 在你的代码中,你从token中获取用户名的地方是这里: String username getUsernameFromToken(token);在这行之后&am…...

值模板参数Value Template Parameters
模板通常使用类型作为参数,但它们也可以使用值。使用类型和可选名称声明一个值模板参数,方式与声明函数参数类似。值模板参数仅限于可以指定编译时常量的类型是bool、char、int等,但不允许使用浮点类型、字符串字面值和类。 #include <io…...

Splashtop 荣获 TrustRadius 颁发的“2024年度最受欢迎奖”
2024年5月8日 加利福尼亚州库比蒂诺 Splashtop 在全球远程访问和支持解决方案领域处于领先地位,该公司正式宣布将连续第三年荣获远程桌面和远程支持类别的“TrustRadius 最受欢迎奖”。Splashtop 的 trScore 评分高达8.6分(满分10分)&#x…...
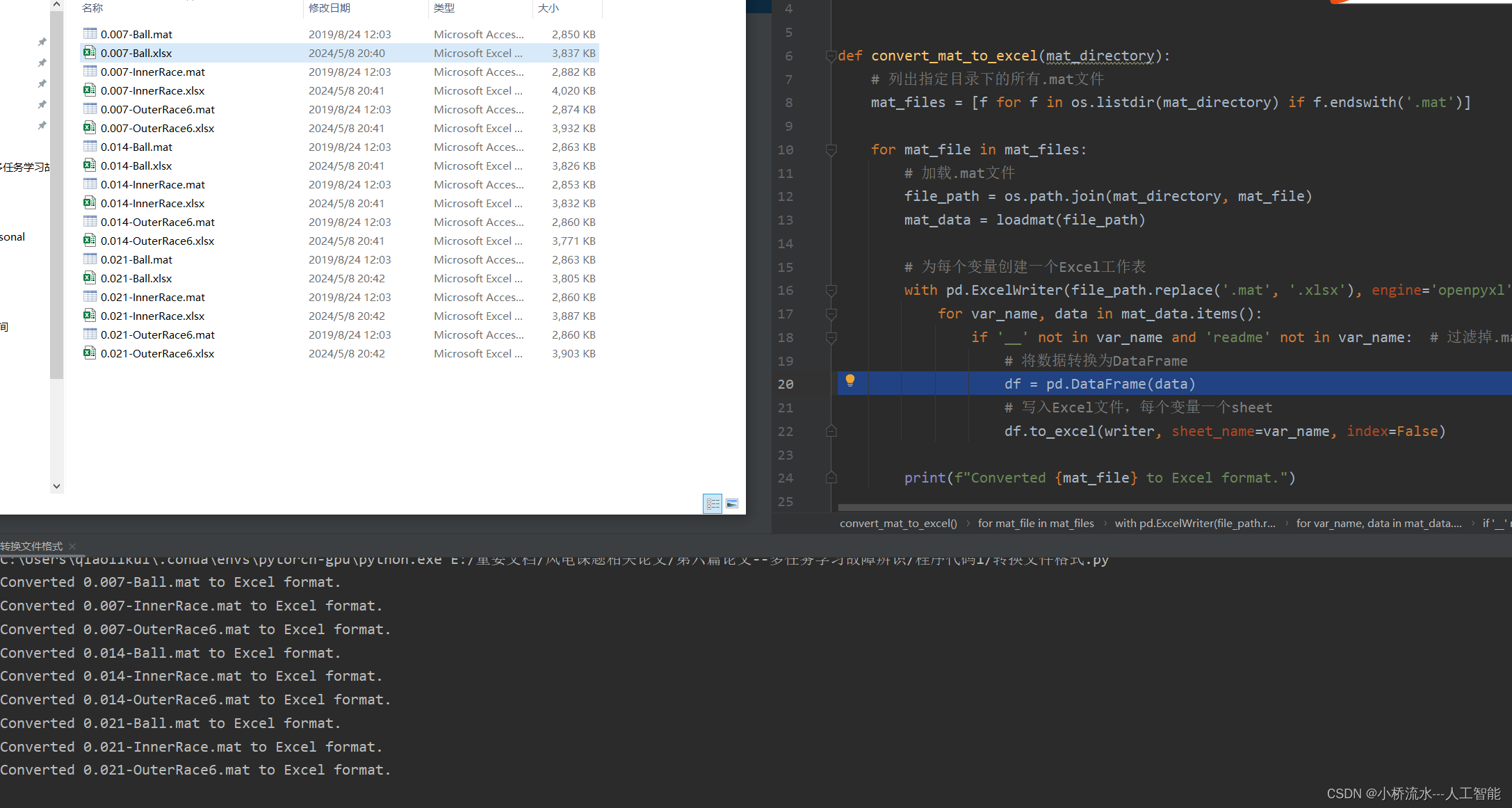
使用python将`.mat`文件转换成`.xlsx`格式的Excel文件!!
要将.mat文件转换成.xlsx格式的Excel文件 第一步:导入必要的库第二步:定义函数来转换.mat文件第三步:调用函数注意事项 要将.mat文件转换成.xlsx格式的Excel文件,并保持文件名一致,你可以使用scipy.io.loadmat来读取.m…...

python基础 面向练习学习python1
python基础 面向练习学习python1 1. 电话查询问题描述1. 问题分析1. 输入输出分析2. 需求分析:将题目的数据存储并查询2. 所需知识: python 数据存储的类型3. 确定数据存储类型4. 如何书写代码拓展 从键盘中添加或删除联系人5. 回到数据查询 代码拓展 功…...

Ubuntu安装Docker和Docker Compose
文章目录 Docker安装Docker Compose安装示例前端Dockerfile示例 Docker官网: https://docs.docker.com/ Docker镜像仓库: https://hub.docker.com/ Docker安装 安装curl(可选) 如果已经安装了curl,则跳过此步骤 # 更新包缓存 sudo apt u…...

C++引用:高效编程的技巧
C引用的本质与特性 引用是已存在变量的别名,与变量共享同一内存地址。声明时必须初始化且不可更改绑定对象: int x 10; int& ref x; // ref成为x的别名 ref 20; // 修改x的值引用与指针的核心区别 初始化要求:引用必须声明时初始…...
)
告别GitHub下载卡顿:手把手教你配置Electron国内镜像(npmrc文件详解)
告别Electron下载困境:深度解析.npmrc配置与国内镜像实战指南 每次执行npm install electron时,看着进度条卡在node install.js阶段一动不动,或是突然蹦出RequestError: connect ETIMEDOUT的红色报错——这种体验对于国内开发者来说再熟悉不过…...

OpenClaw技能开发入门:为Qwen3-4B定制专属自动化模块
OpenClaw技能开发入门:为Qwen3-4B定制专属自动化模块 1. 为什么需要自定义OpenClaw技能 去年夏天,我接手了一个重复性极高的周报生成工作。每周都要从十几个PDF报告中提取关键数据,整理成固定格式的Excel表格,再转成PPT汇报。当…...

三次握手,四次挥手速记版
本文同步发表于微信公众号,微信搜索 程语新视界 即可关注,每个工作日都有文章更新 三次握手和四次挥手是 TCP 协议中建立与关闭连接的关键机制,常因流程抽象而难以记忆。结合权威资料和通俗类比,以下是清晰、易记的要点&#…...
:Chat Memory对话记忆实战,基于Redis实现持久化多轮对话)
Spring AI实战系列(七):Chat Memory对话记忆实战,基于Redis实现持久化多轮对话
一、系列回顾与本篇定位1.1 系列回顾第一篇:完成Spring AI与阿里云百炼的基础集成,基于ChatModel 实现同步对话与API Key安全注入。第二篇:解锁ChatClient,实现全局统一配置与链式调用,告别重复样板代码。第三篇&#…...

OpenClaw技能扩展实战:安装Phi-3-vision-128k-instruct专用图文处理模块
OpenClaw技能扩展实战:安装Phi-3-vision-128k-instruct专用图文处理模块 1. 为什么需要专用技能模块? 上周我在整理技术文档时遇到一个典型场景:需要将十几份混杂着截图和文字说明的会议纪要,自动转换成结构化的Markdown文件。当…...
)
用Python写AI版石头剪刀布:教你用机器学习预测对手出拳(TensorFlow实战)
用Python构建AI驱动的石头剪刀布游戏:从数据收集到模型部署全流程 石头剪刀布这个看似简单的游戏,实际上蕴含着丰富的决策模式和人类行为规律。作为一名长期研究游戏AI的开发者,我发现用机器学习预测玩家出拳模式远比随机选择有趣得多。本文将…...

《B3845 [GESP样题 二级] 勾股数》
题目背景 对应的选择、判断题:https://ti.luogu.com.cn/problemset/1102 题目描述 勾股数是很有趣的数学概念。如果三个正整数 a,b,c,满足 a2b2c2,而且 1≤a≤b≤c,我们就将 a,b,c 组成的三元组 (a,b,c) 称为勾股数。你能通过编…...

雷小兔:让学术论文排版变得简单高效
产品概述 雷小兔是一款专门为学生和研究人员设计的学术论文辅助工具。无论你是在准备毕业论文、学位论文还是学术发表,雷小兔都能为你提供全面的支持和帮助。 论文排版方面的核心优势 1. 模板齐全,开箱即用 雷小兔内置了数十种符合国内外高校标准的论…...

Geoserver空间查询全解析:从基础bbox到高级CQL_FILTER的完整指南
Geoserver空间查询全解析:从基础bbox到高级CQL_FILTER的完整指南 当你面对海量地理空间数据时,如何快速准确地提取所需信息?Geoserver作为开源地理信息系统(GIS)的中枢神经,其强大的空间查询能力往往被开发…...