面试集中营—Redis架构篇
一、Redis到底是多线程还是单线程
1、redis6.0版本之前的单线程,是指网络请求I/O与数据的读写是由一个线程完成的;
2、redis6.0版本升级成了多线程,指的是在网络请求I/O阶段应用的多线程技术;而键值对的读写还是由单线程完成的。所以redis多线程的模型依然是线程安全的。
二、Redis的数据存储结构
redis 存储结构
- redis的存储结构从外层往内层依次是redisDb、dict、dictht、dictEntry。
- redis的Db默认情况下有16个,每个redisDb内部包含一个dict的数据结构。
- redis的dict内部包含dictht的数组,数组个数为2,主要用于hash扩容使用。
- dictht内部包含dictEntry的数组,可以理解就是hash的桶,然后如果冲突通过挂链法解决

下面我们依次来看下每个存储对象的数据结构
redisDb:Redis中存在“数据库”的概念,该结构由redis.h中的redisDb定义。当Redis 服务器初始化时,会预先分配 16 个数据库,所有数据库保存到结构 redisServer 的一个成员 redisServer.db 数组中;redisClient中存在一个名叫db的指针指向当前使用的数据库。
RedisDB结构体源码如下:
DB
typedef struct redisDb {int id; //id是数据库序号,为0-15(默认Redis有16个数据库)long avg_ttl; //存储的数据库对象的平均ttl(time to live),用于统计dict *dict; //存储数据库所有的key-valuedict *expires; //存储key的过期时间dict *blocking_keys;//blpop 存储阻塞key和客户端对象dict *ready_keys;//阻塞后push 响应阻塞客户端 存储阻塞后push的key和客户端对象dict *watched_keys;//存储watch监控的的key和客户端对象
} redisDb;
每个DB维护了多个字典,每个字段存储的内容不同,主要的是存储了value和过期时间。我们看下字典的数据结构
字典
typedef struct dict {dictType *type; // 该字典对应的特定操作函数void *privdata; // 上述类型函数对应的可选参数dictht ht[2]; /* 两张哈希表,存储键值对数据,ht[0]为原生哈希表,ht[1]为 rehash 哈希表 */long rehashidx; /*rehash标识 当等于-1时表示没有在rehash,否则表示正在进行rehash操作,存储的值表示hash表 ht[0]的rehash进行到哪个索引值(数组下标)*/int iterators; // 当前运行的迭代器数量
} dict;
字典当中主要我们要注意两个字段,一个是dictht这是一个hash数组,但是容量只有2,也就是只有两张hash表,数组下标为0的是数据默认存储的位置,如果没有扩容就不会触发rehash,如果出发了rehash就会在数组下标1的位置记录rehash阶段的数据。第二个就是rehashidx,这里是记录了当前rehash的标识,因为redis是渐进式rehash的,所以要有一个类似游标的字段来记录当前rehash到了哪里。
我们进入dictht来看下hash表的数据结构
hash表
typedef struct dictht {dictEntry **table; // 哈希表数组unsigned long size; // 哈希表数组的大小unsigned long sizemask; // 用于映射位置的掩码,值永远等于(size-1)unsigned long used; // 哈希表已有节点的数量,包含next单链表数据
} dictht;
这个结构比较的简单了,主要是维护了一个hash数组,真正存储数据地方;我们要注意这里还维护了一个字段叫size,这个很重要,当我们要统计整个redis中的键的数量时就不需要全部遍历一遍了。
Hash表节点
typedef struct dictEntry {void *key; // 键union { // 值v的类型可以是以下4种类型void *val;uint64_t u64;int64_t s64;double d;} v;struct dictEntry *next; // 指向下一个哈希表节点,形成单向链表 解决hash冲突
} dictEntry;
表节点中的可以就是键值的指针,值v的类型可以是四种类型
数据存储过程
以set为例作为说明,过程如下:
1、从redisDb当中找到dict,每个db就一个dict而已。
2、从dict当中选择具体的dictht对象。
3、首先根据key计算hash桶的位置,也就是index。
4、新建一个DictEntry对象用于保存key/value,将新增的entry挂到dictht的table对应的hash桶当中,每次保存到挂链的头部。
5、dictSetKey的宏保存key
6、dictSetVal的宏保存value
三、Redis的底层数据结构
我们都知道Redis提供了多种数据结构,例如string、hash、list、set、zset等,那么这些数据结构是如果在redis中存储的呢?从第二个问题中,我们可以得到如下这张图。
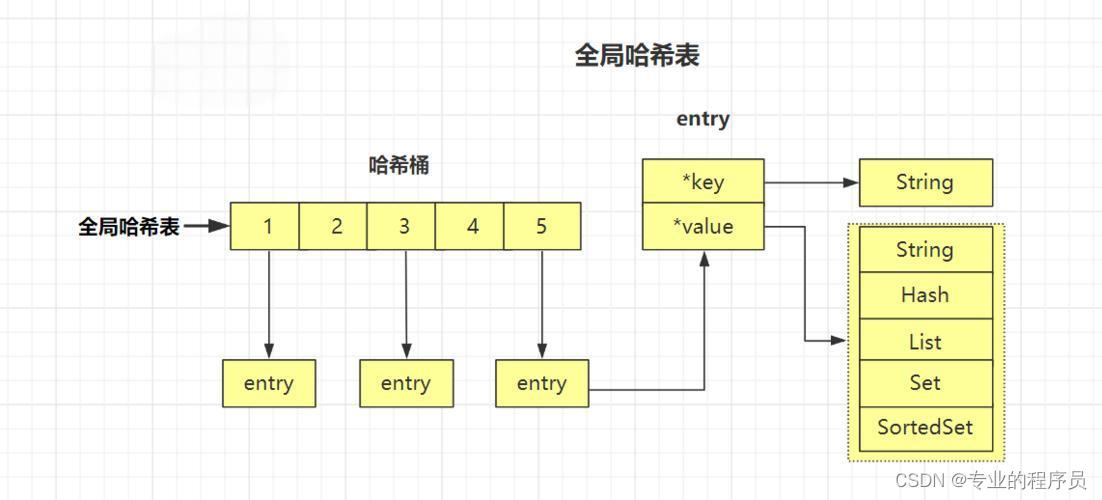
从全局来看,Redis整个数据库是用字典来存储的,就是dict,那么这个字典其实就是一张hash表,那么hash表主要由两个数据结构来组成,一个是桶,也可以理解成是一个数组列表,然后每个桶下面是对应的entry数据,entry数据中有key和value,key默认都是字符串,value就是各种各样的数据类型。
数据类型和底层数据结构
不同的数据类型在redis底层是怎么实现的呢?我们看下这张图。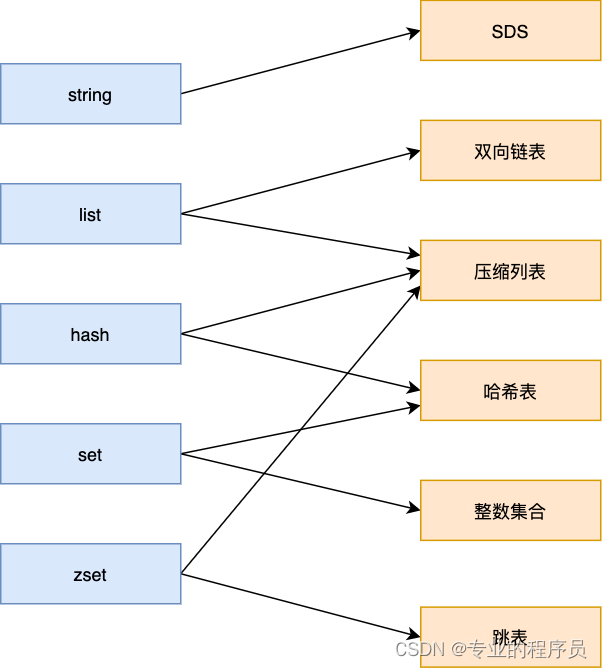
SDS
C语言中的char类型的问题如下:
1、获取字符串的长度要遍历所有的字符,为O(n);
2、追加字符串的时候,比如把"hello" 变成 "hello world",会重新分配内存地址,会造成缓冲区溢出;
3、字符串中不能含有"\0"字符串,不能保存像图像、视频、音频这样的二进制数据;
为此,redis设计了新的数据类型SDS,简单动态字符串,string类型的实现。
// 3.0版本
struct sdshdr {int len; // 记录buf数组中已使用字节的数量int free; // 记录buf数组中未使用字节的数量char buf[]; // 字节数组,用于保存字符串}
// 5.0版本
struct sdshdr {int len; // 记录buf数组中已使用字节的数量int alloc; // 分配给字节数组的大小char *flags; // 类型char buf[]; // 字节数组,用于保存字符串} 1、len,记录了字符串长度。这样获取字符串长度的时候,只需要返回这个成员变量值就行,时间复杂度只需要 O(1)。
2、alloc,分配给字符数组的空间长度。这样在修改字符串的时候,可以通过 alloc - len 计算出剩余的空间大小,可以用来判断空间是否满足修改需求,如果不满足的话,就会自动将 SDS 的空间扩展至执行修改所需的大小,然后才执行实际的修改操作,所以使用 SDS 既不需要手动修改 SDS 的空间大小,也不会出现前面所说的缓冲区溢出的问题。
3、flags,用来表示不同类型的 SDS。一共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64,后面在说明区别之处。
4、buf[],字符数组,用来保存实际数据。不仅可以保存字符串,也可以保存二进制数据。
List
同样的,redis也自己实现了一套链表数据结构,首先定义了一个listNode
typedef struct listNode {//前置节点struct listNode *prev;//后置节点struct listNode *next;//节点的值void *value;
} listNode;
好像也没有什么特别,就是前驱节点,后置节点以及节点的值。为了更好的管理和统计,Redis又抽象出来了一个List数据结构
typedef struct list {//链表头节点listNode *head;//链表尾节点listNode *tail;//节点值复制函数void *(*dup)(void *ptr);//节点值释放函数void (*free)(void *ptr);//节点值比较函数int (*match)(void *ptr, void *key);//链表节点数量unsigned long len;
} list;
list 结构为链表提供了链表头指针 head、链表尾节点 tail、链表节点数量 len、以及可以自定义实现的 dup、free、match 函数。
压缩列表
list结构有一个最大的问题就是内存是不连续的,无法利用CPU的缓存。所以就出现了压缩列表,它被设计成一种内存紧凑型的数据结构,占用一块连续的内存空间,不仅可以利用 CPU 缓存,而且会针对不同长度的数据,进行相应编码,这种方法可以有效地节省内存开销。

压缩列表由于存储尾节点的偏移量,那么获取头尾节点都很简单,但是还是有几个问题。
1、获取中间节点就需要像数组一样一个个遍历,时间复杂度变成了O(N)。
2、插入数据的时候如果内存分配的不够就要重新分配。
3、由于每个entry中存储了上一个节点的长度,默认是使用一个字节(小于254),如果上一个节点的长度大于254就要使用5个字节,此时会出现一个问题,如果上一个节点的长度从小于254变成了大于254,那么后续的所有节点就会出现联动效果都要重新分配内存地址,如果列表很长就会极大的影响性能;
此时为此Redis又推出了新的压缩列表,新增设计了两种数据结构:quicklist(Redis 3.2 引入) 和 listpack(Redis 5.0 引入)。这两种数据结构的设计目标,就是尽可能地保持压缩列表节省内存的优势,同时解决压缩列表的「连锁更新」的问题。
quicklist
quicklist 就是「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表。
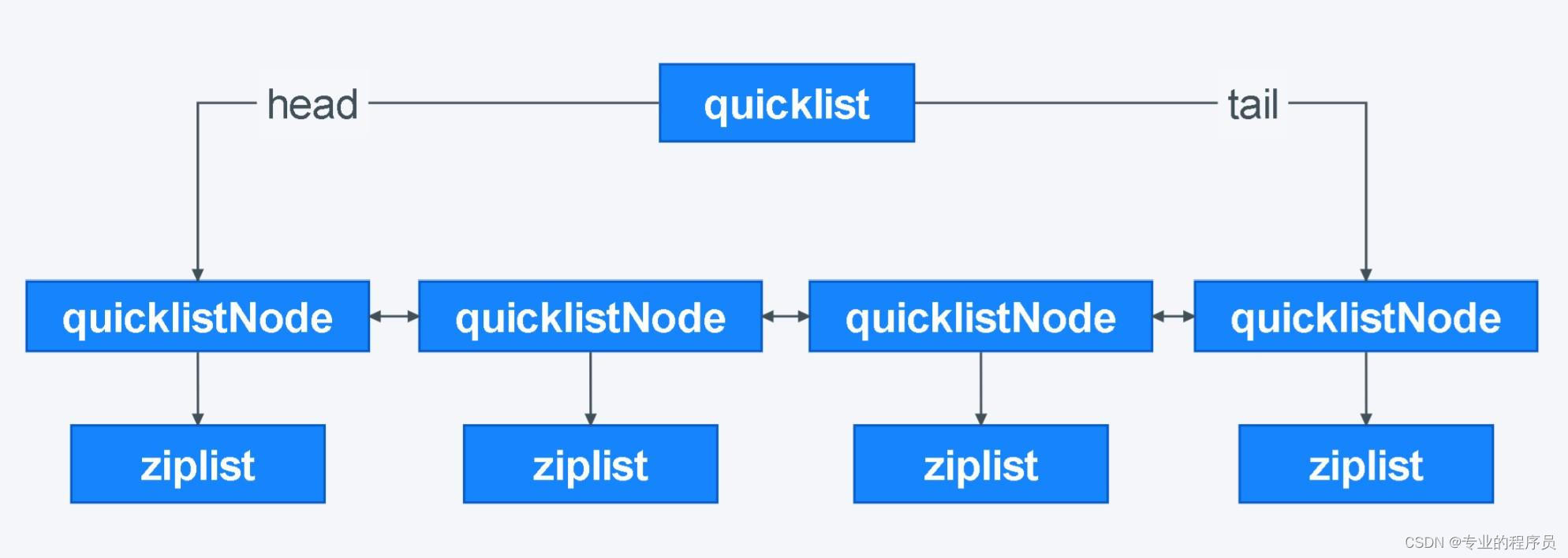
在向 quicklist 添加一个元素的时候,不会像普通的链表那样,直接新建一个链表节点。而是会检查插入位置的压缩列表是否能容纳该元素,如果能容纳就直接保存到 quicklistNode 结构里的压缩列表,如果不能容纳,才会新建一个新的 quicklistNode 结构。
listpack
Redis 在 5.0 新设计一个数据结构叫 listpack,目的是替代压缩列表,它最大特点是 listpack 中每个节点不再包含前一个节点的长度了,压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患。
listpack 还是用一块连续的内存空间来紧凑地保存数据,并且为了节省内存的开销,listpack 节点会采用不同的编码方式保存不同大小的数据。
每个 listpack 节点结构主要包含三个方面内容:
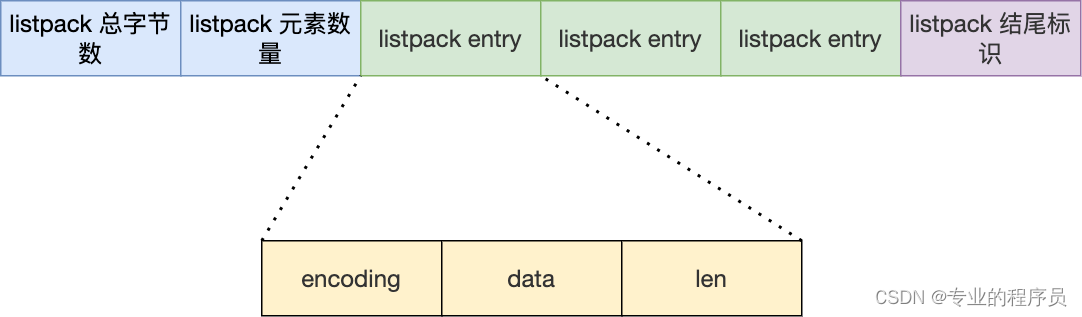
1、encoding,定义该元素的编码类型,会对不同长度的整数和字符串进行编码;
2、data,实际存放的数据;
3、len,encoding+data的总长度;
listpack 没有压缩列表中记录前一个节点长度的字段了,listpack 只记录当前节点的长度,当我们向 listpack 加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。
实际操作如下:
127.0.0.1:6379> lpush list one
(integer) 1
127.0.0.1:6379> lpush list two
(integer) 2
127.0.0.1:6379> type two
none
127.0.0.1:6379> type list
list
127.0.0.1:6379> OBJECT encoding list
"listpack"Set
Set的底层使用的是hash和整数集合,如果Set中存储的都是数字,就使用整数集合。hash我们之前已经讲过了,这里只看整数集合
整数集合
当一个 Set 对象只包含整数值元素,且不相同时,就会使用整数集这个数据结构作为底层实现。整数集合是有序的。
struct intset {//编码方式uint32_t encoding;//集合包含的元素数量uint32_t length;//保存元素的数组int8_t contents[];
} 如果 encoding 属性值为 INTSET_ENC_INT16,那么 contents 就是一个 int16_t 类型的数组,数组中每一个元素的类型都是 int16_t;
如果 encoding 属性值为 INTSET_ENC_INT32,那么 contents 就是一个 int32_t 类型的数组,数组中每一个元素的类型都是 int32_t;
如果 encoding 属性值为 INTSET_ENC_INT64,那么 contents 就是一个 int64_t 类型的数组,数组中每一个元素的类型都是 int64_t;
实际操作如下:
127.0.0.1:6379> sadd myset 1
(integer) 1
127.0.0.1:6379> sadd myset 2
(integer) 1
127.0.0.1:6379> type myset
set
127.0.0.1:6379> OBJECT encoding myset
"intset"ZSet
Redis 只有在 Zset 对象的底层实现用到了跳表,跳表的优势是能支持平均 O(logN) 复杂度的节点查找。Zset 对象是唯一一个同时使用了两个数据结构来实现的 Redis 对象,这两个数据结构一个是跳表,一个是哈希表。这样的好处是既能进行高效的范围查询,也能进行高效单点查询
typedef struct zset {dict *dict;zskiplist *zsl;
} zset;
跳表
跳表就是增加了一张跳跃表,这个跳跃表将存储的数据分成了很多个段。或者说分成了几个层,这里有点像B+树的结构。层级为3的跳表大致为
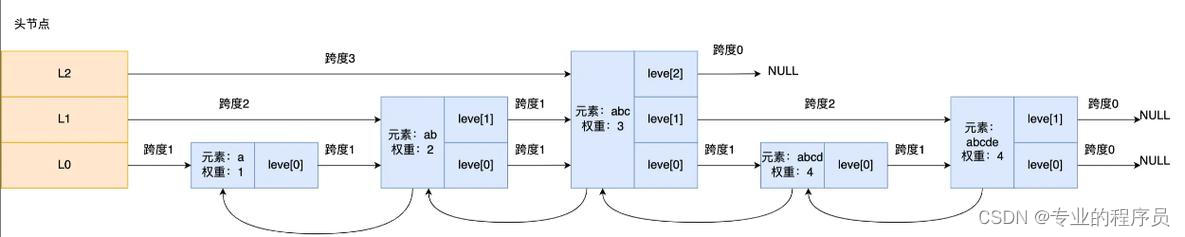
我们可以看到一共有三个头指针L0-L2。
L0层一共是5个节点,也是全部的节点,全量链表;
L1层一共有3个节点,分别是2,3,5;
L2层一共有1个节点,是3。
如果我们要找节点3,从L2层就可以直接获得,时间复杂度是O(1);
如果我们要找节点4,从L2层只有节点3,而4就是3的后置节点,这样查找两次就可以找到;
这种近似二分查找逻辑的存储模式,可以保证跳表的查找复杂度是O(logN);
那么调表是如何实现多层级的呢?我们来看下调表的数据结构。
typedef struct zskiplistNode {//Zset 对象的元素值sds ele;//元素权重值double score;//后向指针struct zskiplistNode *backward;//节点的level数组,保存每层上的前向指针和跨度struct zskiplistLevel {struct zskiplistNode *forward;unsigned long span;} level[];
} zskiplistNode;
可以看到,主要就是依靠level数组来保存每层的数据。比如节点3中,level数组就有三个元素,分别是0级,1级,2级的层数据。
Hash
Hash结构就是我们第二个问题说明的,采用是dict、dictht、dictEntry三层,这里就不多说了。注意,当hash对象的所有键值对字符串长度小于64个字节或者键值对的数量小于512个时,hash结构的数据存储类型依然是压缩列表。
127.0.0.1:6379> hset myhash user liubei
(integer) 1
127.0.0.1:6379> hset myhash user guanyu
(integer) 0
127.0.0.1:6379> hget myhash
(error) ERR wrong number of arguments for 'hget' command
127.0.0.1:6379> hget myhash user
"guanyu"
127.0.0.1:6379> hset myhash pass 123
(integer) 1
127.0.0.1:6379> type myhash
hash
127.0.0.1:6379> OBJECT encoding myhash
"listpack"当我们新增一个字段,值超过了64个字节后
127.0.0.1:6379> hset myhash address Hash结构就是我们第二个问题说明的,采用是dict、dictht、dictEntry三层,这里就不多说了。注意,当hash对象的所有键值对字符串长度小于64个字节或者键值对的数量小于512个时,hash结构的数据存储类型依然是压缩列表C
127.0.0.1:6379> OBJECT encoding myhash
"hashtable"
redis存储对象也一般使用hash
限于篇幅,关于底层数据结构更加详细的内容请阅读这两篇文章:为了拿捏 Redis 数据结构,我画了 40 张图(完整版)-CSDN博客
源码篇--Redis 底层数据结构_redis 字符串存储结构-CSDN博客
四、渐进式扩容
为了实现从键到值的快速访问,前面的章节已经讲到Redis使用了一张Hash表来快速地定位数据。哈希表让我们可以用 O(1) 的时间复杂度来快速查找到键值对——我们只需要计算键的哈希值,就可以知道它所对应的哈希桶位置,然后就可以访问相应的 entry 元素。
key-value 访问过程:
- 通过 key 计算出对应的哈希值
- 根据哈希值计算出对应的哈希桶索引
- 根据索引找到对应 entry,如果是哈希链则挨个查找到对应的 entry
- String 类型则 entry 中的 value 就是要查找的值,集合类型则需要在 value 中进一步查找
那么就必定会出现hash冲突的问题,解决问题的方法就是挂链表。同一个hash桶中的元素用一个链表来串起来,这就是为什么dictEntry数据结构中有一个next指针。但是如果链表过长那么查询的效率就会降低,此时就会触发redis的rehash,rehash 也就是增加现有的哈希桶数量,让逐渐增多的 entry 元素能在更多的桶之间分散保存,减少单个桶中的元素数量,从而减少单个桶中的冲突。
Rehash
一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash,这个过程分为三步:
- 给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;
- 把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;
- 释放哈希表 1 的空间。
到此,我们就可以从哈希表 1 切换到哈希表 2,用增大的哈希表 2 保存更多数据,而原来的哈希表 1 留作下一次 rehash 扩容备用。
渐进式Rehash
rehash有一个问题,就是如果数据量过大,可能rehash的过程很长,那么就会造成一段时间的服务不可用,这是无法承受的。那么渐进式Rehash就出现了,其实也比较容易理解,一次时间太长就分散到多次。简单来说就是在第二步拷贝数据时,Redis 仍然正常处理客户端请求。
1、每处理一个请求时,从哈希表1中的第一个索引位置开始,顺带着将这个索引位置上的所有entries拷贝到哈希表2中;
2、等处理下一个请求的,再顺带拷贝哈希表1中的下一个索引位置的entries。
因为在进行渐进式 rehash 的过程中, 字典会同时使用 ht[0] 和 ht[1] 两个哈希表, 所以在渐进式 rehash 进行期间, 字典的删除(delete)、查找(find)、更新(update)等操作会在两个哈希表上进行: 比如说, 要在字典里面查找一个键的话, 程序会先在 ht[0] 里面进行查找, 如果没找到的话, 就会继续到 ht[1] 里面进行查找, 诸如此类。
另外, 在渐进式 rehash 执行期间, 新添加到字典的键值对一律会被保存到 ht[1] 里面, 而 ht[0] 则不再进行任何添加操作: 这一措施保证了 ht[0] 包含的键值对数量会只减不增, 并随着 rehash 操作的执行而最终变成空表。
rehash 触发条件
rehash 的触发条件跟负载因子(load factor)有关系,负载因子=哈希表已保存节点的数量/哈希表的大小。触发 rehash 操作的条件,主要有两个:
1、当负载因子大于等于 1 ,并且 Redis 没有在执行 bgsave 命令或者 bgrewiteaof 命令,也就是没有执行 RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作;
2、当负载因子大于等于 5 时,此时说明哈希冲突非常严重了,不管有没有有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作;
五、架构演进
单机版的Redis
一个应用服务对应单个数据库(mysql)+单机Redis,这种架构比较简单,应对普通的低并发低数据存储要求的应用足够了。
主从模式
一个master+多个slave,一主多从的模式,主从节点直接通过psync命令来完成数据复制,具体过程概括为:
- 建立连接。从节点启动时,通过配置文件中的信息连接到主节点,并发送SYNC命令请求同步数据。
- 数据同步。主节点在接收到SYNC命令后,开始进行数据快照的创建(RDB文件)并通过psync命令将快照发送给从节点。从节点接收并加载这个快照,从而获得与主节点的初始数据一致性。
- 增量同步。初始同步完成后,主节点开始将新的写入操作发送给从节点,以保持从节点数据的实时性。从节点接收并应用这些写入命令。
- 复制数据。主节点持续将写入命令发送给所有连接的从节点,从节点接收到这些命令后,将它们应用到本地数据集,以维持与主节点的数据一致性。
- 主从切换。如果主节点发生故障,管理员可以手动或自动将一个从节点提升为新的主节点。其他从节点将连接到新的主节点以获取数据复制。
- 部分重同步。如果从节点在断线后重新连接主节点,主节点会根据复制偏移量和复制积压缓冲区决定是否执行部分重同步或全量重同步。部分重同步用于补偿从节点在断线期间丢失的数据。
详细可以参考- Redis 主从复制原理分析,这篇就够了_redis主从复制原理-CSDN博客
哨兵模式
主从模式解决了Redis数据安全的问题,一旦主节点挂了,数据不会丢失,启动一个从节点即可(所以如果有两个或两个以上的从节点,可以使用主从从的模式,像链条一样后一个节点复制前一个节点的数据,这样只需要把主节点后面连接的从节点升级为主节点即可)。可以这样的切换还需要人工的干预同时还得时刻关注redis的状态。
哨兵模式就是在主从节点之外又新增加了一个角色,这个哨兵节点顾名思义就是监控主节点的状态,主节点如果挂了,就自动的选择一个从节点,将其升级为主节点;但是哨兵也会有单节点的问题,故而哨兵也做了集群,哨兵之间通过共识算法进行统一操作。
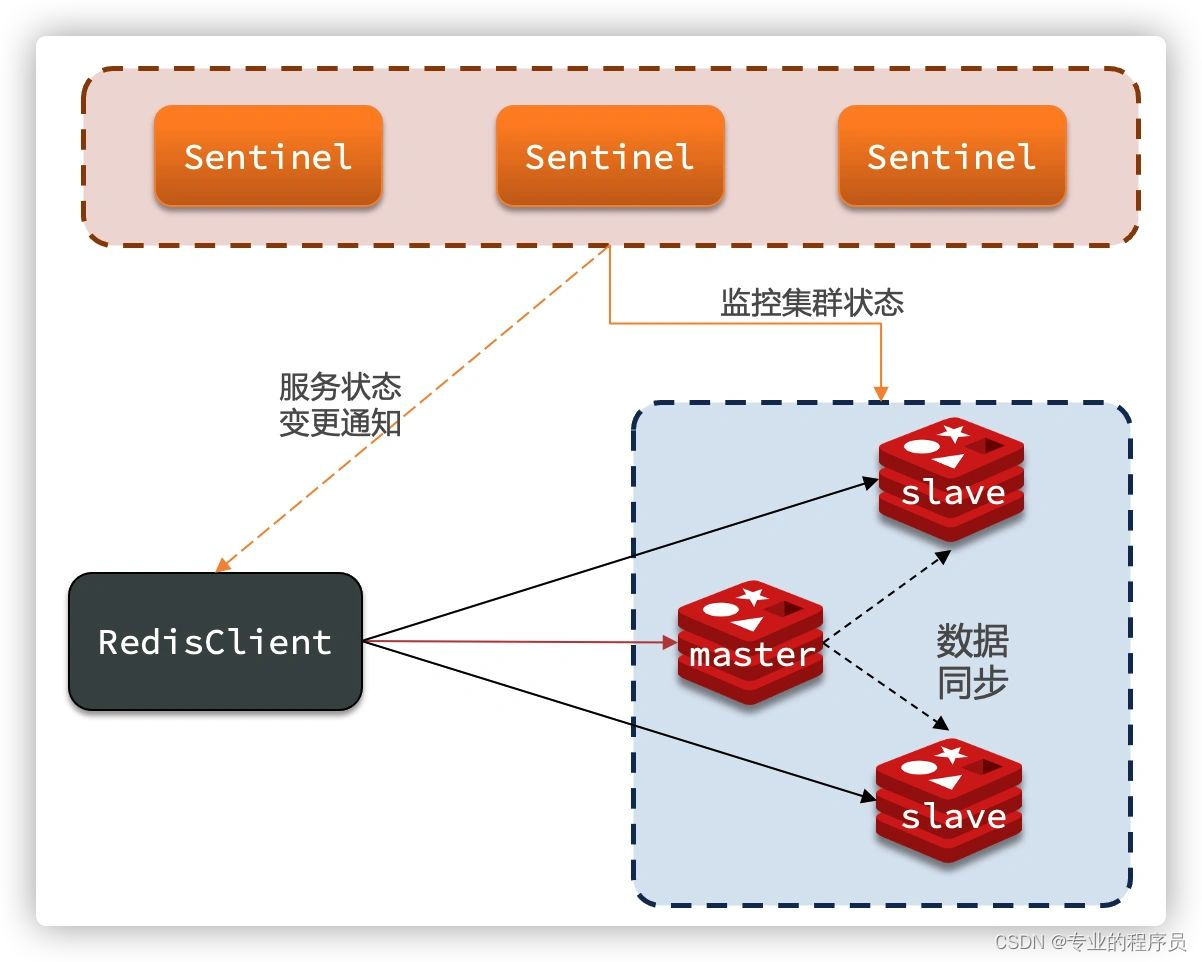
关于共识算法,可以参考笔者的另一篇文章:面试题集中营—分布式共识算法-CSDN博客
Redis Cluster
哨兵模式有一个问题,就是master节点只有一个,也就是说对外提供服务的永远只有一个节点,我们部署了一个主节点两个从节点三个哨兵节点却只有一个节点提供服务好像有点浪费资源的意思。那么能不能多部署几个master节点呢?这就是Redis官方提供的Redis Cluster方案。
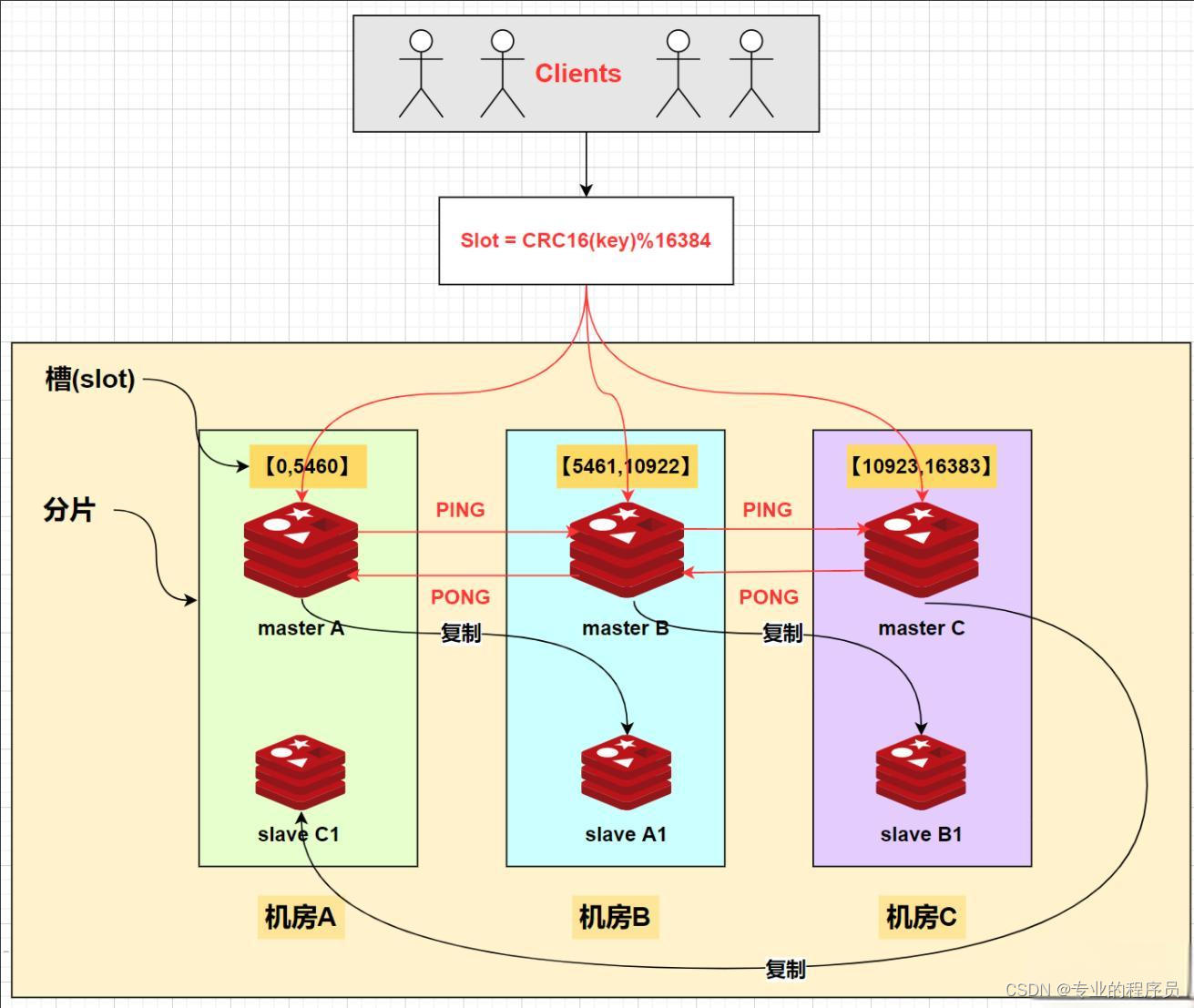
Redis Cluster 内置了哨兵逻辑,无需再部署哨兵。对于客户端来说也不需要关心数据存储在哪一个master节点上,因为我们使用的sdk内置了proxy逻辑。
六、数据备份与恢复
6.1 备份
RDB与AOF
redis提供了两种备份方式。默认是RDB(Redis DataBase)的备份方式。
RDB:只持久化某一时刻的数据快照到磁盘上(创建一个子进程来做)
AOF:每一次写操作都持久到磁盘(主线程写内存,根据策略可以配置由主线程还是子线程进行数据持久化)
1、RDB 采用二进制 + 数据压缩的方式写磁盘,这样文件体积小,数据恢复速度也快
2、AOF 记录的是每一次写命令,数据最全,但文件体积大,数据恢复速度慢
AOF rewrite
由于 AOF 文件中记录的都是每一次写操作,但对于同一个 key 可能会发生多次修改,我们只保留最后一次被修改的值,是不是也可以?是的,这就是我们经常听到的AOF rewrite,我们可以对 AOF 文件定时 rewrite,避免这个文件体积持续膨胀,这样在恢复时就可以缩短恢复时间了。
混合持久化
当 AOF rewrite 时,Redis 先以 RDB 格式在 AOF 文件中写入一个数据快照,再把在这期间产生的每一个写命令,追加到 AOF 文件中。因为 RDB 是二进制压缩写入的,这样 AOF 文件体积就变得更小了。
6.2 恢复
RDB数据恢复
Redis启动后会读取RDB快照文件,将数据从硬盘载入到内存,根据数据量大小与结构和服务器性能不同,通常将一个记录一千万个字符串类型键、大小为1GB的快照文件载入到内存中需花费20~30秒钟。
AOF数据恢复
重新启动Redis后Redis会使用AOF文件来恢复数据,因为AOF方式的持久化可能丢失的数据更少,可以在redis.conf中通过appendonly参数开启Redis AOF全持久化模式。
七、Redis为什么这么快
1、所有操作都是在内存中进行,没有磁盘的I/O开销,键值对的读写都是纳秒级别的速度;
2、单线程操作,没有线程的切换造成的开销,更不需要考虑多线程死锁的问题;
3、使用了多路复用的机制提升了I/O的利用率;
4、高效的数据存储结构。
5、渐进式rehash
参考:
Redis底层数据结构_redisdb结构-CSDN博客
详解Redis内部数据结构——Dict_redis dict entry_ptr_mask的作用-CSDN博客
为了拿捏 Redis 数据结构,我画了 40 张图(完整版)-CSDN博客
16张图吃透 Redis 架构演进全过程_redis mysql 架构图 redis架构原理-CSDN博客
redis详解之数据备份与恢复_redis备份和恢复-CSDN博客
相关文章:
面试集中营—Redis架构篇
一、Redis到底是多线程还是单线程 1、redis6.0版本之前的单线程,是指网络请求I/O与数据的读写是由一个线程完成的; 2、redis6.0版本升级成了多线程,指的是在网络请求I/O阶段应用的多线程技术;而键值对的读写还是由单线程完成的。所…...

05_kafka-整合springboot
文章目录 kafka 整合 springboot pom.xml <parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.1.5.RELEASE</version> </parent> <dependencies>&…...

论UML在学情精准测评系统中的应用
摘要简介 项目背景: 随着教育改革的不断深入,对学生学情的精准测评成为教育教学工作中的重要环节。为了解决传统学情测评方式主观性强、效率低、反馈不及时等问题,我们团队受教育主管部门委托,承担了中小学学情精准测评系统&…...

Day23 代码随想录打卡|字符串篇---重复的子字符串
题目(leecode T459): 给定一个非空的字符串 s ,检查是否可以通过由它的一个子串重复多次构成。给定的字符串只含有小写英文字母,并且长度不超过10000。fang 移动匹配。分析可以由自己的子串构成的字符串,肯…...

【win10 文件夹数量和看到不一致查看隐藏文件已经打开,Thumb文件作妖】
目录 任务介绍:重命名规则修改前修改后 实现思路VB代码实现BUG犯罪现场(眼见不一定为实)破案1:抓顶风作案的反贼!!!破案2:破隐身抓刺客!!!杀器&am…...
ctfshow web入门 sql注入 web224--web233
web224 扫描后台,发现robots.txt,访问发现/pwdreset.php ,再访问可以重置密码 ,登录之后发现上传文件 检查发现没有限制诶 上传txt,png,zip发现文件错误了 后面知道群里有个文件能上传 <? _$GET[1]_?>就是0x3c3f3d60245…...
「Java开发指南」如何用MyEclipse搭建GWT 2.1和Spring?(一)
本教程将指导您如何生成一个可运行的Google Web Toolkit (GWT) 2.1和Spring应用程序,该应用程序为域模型实现了CRUD应用程序模式。在本教程中,您将学习如何: 安装Google Eclipse插件为GWT配置一个项目搭建从数据库表到一个现有的项目GWT编译…...

python同时进行字符串的多种替换
一些常见的方法: 使用str.replace()方法:这是一种简单的方法,但是如果你有多个替换需要进行,可能会变得很繁琐。 text "This is a sample text with some words." text text.replace("sample", "exa…...
)
【Java基础题型】用筛法求之N内的素数(老题型)
输入格式 N输出格式 0~N的素数样例输入 100样例输出 2 3 5 7 11 13 17 19 23 29 31 37 老朋友素数了属于是! 方法1:(穷举法) 通过遍历 i 的所有除数,如果除以除数后商变成了0,那么把布尔值变成假的。表示不是素数 【…...

Linux进程——Linux环境变量
前言:在结束完上一篇的命令行参数时,我们简单的了解了一下Linux中的环境变量PATH,而环境变量不只有PATH,关于更多环境变量的知识我们将在本篇展开! 本篇主要内容: 常见的环境变量 获取环境变量的三种方式 本…...

SRM系统供应链库存协同提升企业服务水平
SRM系统供应链库存协同是一种以提高供应链整体效率和竞争力为目标的管理方法。它涉及到企业与供应商之间的紧密合作,以实现库存优化、成本降低、风险分担和灵活响应市场变化等目标。 一、SRM供应链库存协同的概念和特点 SRM供应链库存协同是指企业与供应商之间通过…...
Windows安全加固-账号与口令管理
在当今日益增长的网络安全威胁中,Windows系统的安全加固显得尤为重要。其中,账号与口令管理作为系统安全的第一道防线,其重要性不言而喻。本文将深入探讨Windows安全加固中的账号与口令管理策略,以确保系统的安全性和稳定性。 账…...
【数据库原理及应用】期末复习汇总高校期末真题试卷03
试卷 一、选择题 1 数据库中存储的基本对象是_____。 A 数字 B 记录 C 元组 D 数据 2 下列不属于数据库管理系统主要功能的是_____。 A 数据定义 B 数据组织、存储和管理 C 数据模型转化 D 数据操纵 3 下列不属于数据模型要素的是______。 A 数据结构 B 数据字典 C 数据操作 D…...
数据库加密数据模糊匹配查询技术方案
文章目录 前言沙雕方案内存加载解密密文映射表 常规做法实现数据库加密算法参考 分词组合加密(推荐) 超神方案总结个人简介 前言 在数据安全性和查询效率之间找到平衡是许多数据管理系统所面临的挑战之一。特别是在涉及加密数据的情况下,如何…...

jsSPA应用如何实现动态内容更新
JS SPA(单页面应用)应用的原理、优势以及例子如下: 原理: SPA应用的核心原理在于,它使用JavaScript动态地创建和更新DOM结构,而非通过传统的多页面跳转来呈现内容。当用户与应用程序交互时,SP…...

C++学习笔记——仿函数
文章目录 仿函数——思维导图仿函数是什么仿函数的优势理解仿函数仿函数的原理举例 仿函数——思维导图 仿函数是什么 使用对象名调用operator()函数看起来像是在使用函数一样,因此便有了仿函数的称呼;仿函数存在的意义是&#x…...

python 中如何匹配字符串
python 中如何匹配字符串? 1. re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。 import re line"this hdr-biz 123 model server 456" patternr"123" matchObj re.matc…...

Windows 系统运维常用命令
目标:通过本文可以快速实现windows 网络问题定位。 ipconfig:查看本机网络配置情况 C:\Users\zzg>ipconfigWindows IP 配置以太网适配器 以太网:媒体状态 . . . . . . . . . . . . : 媒体已断开连接连接特定的 DNS 后缀 . . . . . . . :无线局域网适配器 本地…...

Springboot监听ConfigMap配置文件自动更新配置
背景: 最近调研使用k8s的ConfigMap来作为springboot项目的配置中心,需要实现热更新机制,避免pod重启影响业务。 ConfigMap作为挂载卷使用的时候可以更新pod中的配置内容,但是业务应用需要能监听并处理这些变更。我在测试的时候已…...

API安全机制
API安全机制包括两部分:数字签名、敏感信息加密。 一、数字签名 服务端使用客户端的消息签名验证客户端的身份。如果一个请求不包含签名或者签名验证失败,服务端将返回身份验证错误。它背后的技术是:数字签名技术。 1、待签参数准备 待签…...

(LeetCode 每日一题) 3442. 奇偶频次间的最大差值 I (哈希、字符串)
题目:3442. 奇偶频次间的最大差值 I 思路 :哈希,时间复杂度0(n)。 用哈希表来记录每个字符串中字符的分布情况,哈希表这里用数组即可实现。 C版本: class Solution { public:int maxDifference(string s) {int a[26]…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...