【SQL开发实战技巧】系列(二十四):数仓报表场景☞通过执行计划详解”行转列”,”列转行”是如何实现的
系列文章目录
【SQL开发实战技巧】系列(一):关于SQL不得不说的那些事
【SQL开发实战技巧】系列(二):简单单表查询
【SQL开发实战技巧】系列(三):SQL排序的那些事
【SQL开发实战技巧】系列(四):从执行计划讨论UNION ALL与空字符串&UNION与OR的使用注意事项
【SQL开发实战技巧】系列(五):从执行计划看IN、EXISTS 和 INNER JOIN效率,我们要分场景不要死记网上结论
【SQL开发实战技巧】系列(六):从执行计划看NOT IN、NOT EXISTS 和 LEFT JOIN效率,记住内外关联条件不要乱放
【SQL开发实战技巧】系列(七):从有重复数据前提下如何比较出两个表中的差异数据及对应条数聊起
【SQL开发实战技巧】系列(八):聊聊如何插入数据时比约束更灵活的限制数据插入以及怎么一个insert语句同时插入多张表
【SQL开发实战技巧】系列(九):一个update误把其他列数据更新成空了?Merge改写update!给你五种删除重复数据的写法!
【SQL开发实战技巧】系列(十):从拆分字符串、替换字符串以及统计字符串出现次数说起
【SQL开发实战技巧】系列(十一):拿几个案例讲讲translate|regexp_replace|listagg|wmsys.wm_concat|substr|regexp_substr常用函数
【SQL开发实战技巧】系列(十二):三问(如何对字符串字母去重后按字母顺序排列字符串?如何识别哪些字符串中包含数字?如何将分隔数据转换为多值IN列表?)
【SQL开发实战技巧】系列(十三):讨论一下常用聚集函数&通过执行计划看sum()over()对员工工资进行累加
【SQL开发实战技巧】系列(十四):计算消费后的余额&计算银行流水累计和&计算各部门工资排名前三位的员工
【SQL开发实战技巧】系列(十五):查找最值所在行数据信息及快速计算总和百之max/min() keep() over()、fisrt_value、last_value、ratio_to_report
【SQL开发实战技巧】系列(十六):数据仓库中时间类型操作(初级)日、月、年、时、分、秒之差及时间间隔计算
【SQL开发实战技巧】系列(十七):数据仓库中时间类型操作(初级)确定两个日期之间的工作天数、计算—年中周内各日期出现次数、确定当前记录和下一条记录之间相差的天数
【SQL开发实战技巧】系列(十八):数据仓库中时间类型操作(进阶)INTERVAL、EXTRACT以及如何确定一年是否为闰年及周的计算
【SQL开发实战技巧】系列(十九):数据仓库中时间类型操作(进阶)如何一个SQL打印当月或一年的日历?如何确定某月内第一个和最后—个周内某天的日期?
【SQL开发实战技巧】系列(二十):数据仓库中时间类型操作(进阶)获取季度开始结束时间以及如何统计非连续性时间的数据
【SQL开发实战技巧】系列(二十一):数据仓库中时间类型操作(进阶)识别重叠的日期范围,按指定10分钟时间间隔汇总数据
【SQL开发实战技巧】系列(二十二):数仓报表场景☞ 从分析函数效率一定快吗聊一聊结果集分页和隔行抽样实现方式
【SQL开发实战技巧】系列(二十三):数仓报表场景☞ 如何对数据排列组合去重以及通过如何找到包含最大值和最小值的记录这个问题再次用执行计划给你证明分析函数性能不一定高
【SQL开发实战技巧】系列(二十四):数仓报表场景☞通过案例执行计划详解”行转列”,”列转行”是如何实现的
文章目录
- 系列文章目录
- 前言
- 一、行转列
- 二、列转行
- 三、将结果集反向转置为一列
- 总结
前言
本篇文章讲解的主要内容是:目前Oracle支持的行列互换有两种方式:case when、pivot\unpivot,我将通过几个案例来给大家详解如何通过这两种方式实现“行转列”,“列转行”的需求,并通过执行计划看case when、pivot\unpivot二者的底层逻辑关系以及效率上的影响。
【SQL开发实战技巧】这一系列博主当作复习旧知识来进行写作,毕竟SQL开发在数据分析场景非常重要且基础,面试也会经常问SQL开发和调优经验,相信当我写完这一系列文章,也能再有所收获,未来面对SQL面试也能游刃有余~。
一、行转列
"行转列"的这个写法,在做报表或语句改写时要经常用到,是一个非常重要的语句。
在Oracle中,有CASE WHEN END和Oracle11g新增的pivot函数两种方式。其中:
- CASE WHEN END编写和维护较麻烦,但适合的场景较多。
- PIVOT编写和维护简单,但有较大限制。
下面简单介绍这两种方法。
现在我有这么一个需求:
对emp表按job分组汇总,每个部门显示为一列。首先看一下最常用的CASE WHEN END的方法。
根据不同的条件来取值,就可以把数据分为几列。
SQL> select a.job,2 case when a.deptno= 10 then sal end as d10,3 case when a.deptno= 20 then sal end as d20,4 case when a.deptno= 30 then sal end as d305 from emp a6 order by 1;JOB D10 D20 D30
--------- ---------- ---------- ----------
ANALYST 3000
CLERK 800
CLERK 950
CLERK 1100
MANAGER 2450
MANAGER 2975
MANAGER 2850
MGR
PRESIDENT 5000
SALESMAN 1250
SALESMAN 1600
SALESMAN 1250
SALESMAN 1500
sdf 1300 17 rows selected
只是这样的数据看上去杂乱无章,需要再按job分组汇总,所以一般"行转列"语句里都会有聚集函数,就是为了把同类数据转为一行显示。
另外,要注意最后一列,我们增加了合计工资的显示,这在后面介绍的PIVOT函数中是做不到的,PIVOT 函数只能按同一个规则分类各数据,各列之间的数据不能交叉重复。
SQL> select a.job,2 sum(case when a.deptno= 10 then sal end) as d10,3 sum(case when a.deptno= 20 then sal end) as d20,4 sum(case when a.deptno= 30 then sal end) as d30,5 sum(sal)as sm6 from emp a7 group by job8 order by 1;JOB D10 D20 D30 SM
--------- ---------- ---------- ---------- ----------
ANALYST 3000 3000
CLERK 1900 950 2850
MANAGER 2450 2975 2850 8275
MGR
PRESIDENT 5000 5000
SALESMAN 5600 5600
sdf 1300 13008 rows selected
下面看一下Oracle11g新增的"行转列"函数PIVOT,对简单的PIVOT环境提供了简单的实现方法。
SQL>
SQL> select * from (2 --先查询出来要进行操作的数据3 select job,sal,deptno from emp4 )pivot(5 sum(sal) as sm /*这里写聚集函数以及起别名,SUM、MAX等聚集函数+列别名,若不设置别名,则后面生成的列名字默认只使用后面in里设的别名,否则两个别名相加*/6 for deptno in(7 10 as d10, /*这里等价于前面的查询:sum(case when deptno =10 then sal end) as d10,列名称为d10_sm,这个sm是前面聚集函数的别名*/8 20 as d20,/*这里等价于前面的查询:sum(case when deptno =20 then sal end) as d20*/9 30 as d30/*这里等价于前面的查询:sum(case when deptno =30 then sal end) as d30*/10 )11 )12 order by 1;JOB D10_SM D20_SM D30_SM
--------- ---------- ---------- ----------
ANALYST 3000
CLERK 1900 950
MANAGER 2450 2975 2850
MGR
PRESIDENT 5000
SALESMAN 5600
sdf 1300 8 rows selected
大家可以看一下两种方式的对比,如果还要增加提成的返回,用PIVOT则只需要增加一个设定即可。
SQL> select * from (2 --先查询出来要进行操作的数据3 select job,sal,comm,deptno from emp4 )pivot(5 sum(sal) as sm,/*这里写聚集函数以及起别名,SUM、MAX等聚集函数+列别名,若不设置别名,则后面生成的列名字默认只使用后面in里设的别名,否则两个别名相加*/6 sum(comm)as sc /*这里写聚集函数以及起别名,SUM、MAX等聚集函数+列别名,若不设置别名,则后面生成的列名字默认只使用后面in里设的别名,否则两个别名相加*/7 for deptno in(8 10 as d10, /*这里等价于前面的查询:sum(case when deptno =10 then sal end) as d10,sum(case when deptno =10 then comm end) as d10,列名称为d10_sc,这个sm是前面聚集函数的别名*/9 20 as d20,/*这里等价于前面的查询:sum(case when deptno =20 then sal end) as d20*/10 30 as d30/*这里等价于前面的查询:sum(case when deptno =30 then sal end) as d30*/11 )12 )13 order by 1;JOB D10_SM D10_SC D20_SM D20_SC D30_SM D30_SC
--------- ---------- ---------- ---------- ---------- ---------- ----------
ANALYST 3000
CLERK 1900 950
MANAGER 2450 2975 2850
MGR
PRESIDENT 5000
SALESMAN 5600 2200
sdf 1300 8 rows selected
如果用CASE WHEN要增加三行语句。
SQL> select a.job,2 sum(case when a.deptno= 10 then sal end) as d10_sm,3 sum(case when a.deptno= 10 then sal end) as d10_sc,4 sum(case when a.deptno= 20 then sal end) as d20_sm,5 sum(case when a.deptno= 20 then sal end) as d20_sc,6 sum(case when a.deptno= 30 then sal end) as d30_sm,7 sum(case when a.deptno= 30 then sal end) as d30_sc8 from emp a9 group by job10 order by 1;JOB D10_SM D10_SC D20_SM D20_SC D30_SM D30_SC
--------- ---------- ---------- ---------- ---------- ---------- ----------
ANALYST 3000 3000
CLERK 1900 1900 950 950
MANAGER 2450 2450 2975 2975 2850 2850
MGR
PRESIDENT 5000 5000
SALESMAN 5600 5600
sdf 1300 1300 8 rows selected
PIVOT一次只能按一个条件来完成"行转列",如果同时把工作与部门都转为列,并汇总为一行时,PIVOT就无能为力了,这时只能用CASE WHEN。
SQL> select2 case when deptno=10 then ename end as d10,3 case when deptno=20 then ename end as d20,4 case when deptno=30 then ename end as d30,5 case when job='ANALYST' then ename end as ANALYST,6 case when job='CLERK' then ename end as CLERK,7 case when job='MANAGER' then ename end as MANAGER,8 case when job='MGR' then ename end as MGR,9 case when job='PRESIDENT' then ename end as PRESIDENT,10 case when job='SALESMAN' then ename end as SALESMAN11 from emp;D10 D20 D30 ANALYST CLERK MANAGER MGR PRESIDENT SALESMAN
---------- ---------- ---------- ---------- ---------- ---------- ---------- ---------- ----------zhaoyd zhaoyd er er ALLEN ALLENWARD WARDJONES JONES MARTIN MARTINBLAKE BLAKE
CLARK CLARK
KING KING TURNER TURNERADAMS ADAMS JAMES JAMES FORD FORD
sdf 17 rows selectedSQL>
最后分析一下PIVOT的PLAN(用dbms_xplan.display_cursor看):
select/*zydtest*/ * from (
--先查询出来要进行操作的数据
select job,sal,comm,deptno from emp
)pivot(
sum(sal) as sm /*这里写聚集函数以及起别名,SUM、MAX等聚集函数+列别名,若不设置别名,则后面生成的列名字默认只使用后面in里设的别名,否则两个别名相加*/
for deptno in(10 as d10, /*这里等价于前面的查询:sum(case when deptno =10 then sal end) as d10,sum(case when deptno =10 then comm end) as d10,列名称为d10_sc,这个sm是前面聚集函数的别名*/20 as d20,/*这里等价于前面的查询:sum(case when deptno =20 then sal end) as d20*/30 as d30 /*这里等价于前面的查询:sum(case when deptno =30 then sal end) as d30*/)
)
order by 1;
select * from v$sql aa where aa.SQL_TEXT like '%zydtest%';SQL> select * from table(dbms_xplan.display_cursor('5ss3y129x7p0a',0,'advanced')); PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
SQL_ID 5ss3y129x7p0a, child number 0
-------------------------------------
select/*zydtest*/ * from ( --�������������������������� select
job,sal,comm,deptno from emp )pivot( sum(sal) as sm
/*��������������������������SUM��MAX������������������,������������,����
����������������������������in����������,����������������*/ for deptno
in( 10 as d10, /*����������������������sum(case when deptno =10 then
sal end) as d10,sum(case when deptno =10 then comm end) as
d10,��������d10_sc������sm��������������������*/ 20 as
d20,/*����������������������sum(case when deptno =20 then sal end) as
d20*/ 30 as d30 /*��������
Plan hash value: 1018027214
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | | | 4 (100)| |
| 1 | SORT GROUP BY PIVOT| | 19 | 285 | 4 (25)| 00:00:01 |
| 2 | TABLE ACCESS FULL | EMP | 19 | 285 | 3 (0)| 00:00:01 |PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
----------------------------------------------------------------------------
Query Block Name / Object Alias (identified by operation id):
-------------------------------------------------------------1 - SEL$117FC0EF2 - SEL$117FC0EF / EMP@SEL$2
Outline Data
-------------/*+BEGIN_OUTLINE_DATAIGNORE_OPTIM_EMBEDDED_HINTSOPTIMIZER_FEATURES_ENABLE('11.2.0.4')DB_VERSION('11.2.0.4')ALL_ROWSOUTLINE_LEAF(@"SEL$117FC0EF")MERGE(@"SEL$F5BB74E1")OUTLINE(@"SEL$3")OUTLINE(@"SEL$F5BB74E1")PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------MERGE(@"SEL$2")OUTLINE(@"SEL$1")OUTLINE(@"SEL$2")FULL(@"SEL$117FC0EF" "EMP"@"SEL$2")END_OUTLINE_DATA*/
Column Projection Information (identified by operation id):
-----------------------------------------------------------1 - (#keys=2) "JOB"[VARCHAR2,9], "COMM"[NUMBER,22], SUM(CASE WHEN("DEPTNO"=10) THEN "SAL" END )[22], SUM(CASE WHEN ("DEPTNO"=20) THEN"SAL" END )[22], SUM(CASE WHEN ("DEPTNO"=30) THEN "SAL" END )[22]2 - "JOB"[VARCHAR2,9], "SAL"[NUMBER,22], "COMM"[NUMBER,22],"DEPTNO"[NUMBER,22]57 rows selected通过上面PLAN可以看到,PIVOT被转换成了如下语句:
SUM(CASE WHEN("DEPTNO"=10) THEN "SAL" END )[22], SUM(CASE WHEN ("DEPTNO"=20) THEN"SAL" END )[22], SUM(CASE WHEN ("DEPTNO"=30) THEN "SAL" END )[22]
也就是说,PIVOT只是写法简单了一些,实际上仍用的是CASE WHEN语句。
二、列转行
测试数据如下:
drop table test purge;
create table test as
select *from (select deptno, sal from emp)
pivot(count(*) as ct, sum(sal) as sfor deptno in(10 as d10, 20 as d20, 30 as d30));
SQL> select * from test;D10_CT D10_S D20_CT D20_S D30_CT D30_S
---------- ---------- ---------- ---------- ---------- ----------3 8750 5 7875 6 9400SQL>
要求把三个部门的"人次"转为一列显示。以前这种需求一直用UNION ALL来写:
SQL> SELECT'10'AS 部门编码,d10_ct AS 人次 FROM test UNION ALL2 SELECT'20'AS 部门编码,d20_ct AS 人次 FROM test UNION ALL3 SELECT'30'AS 部门编码,d30_ct AS 人次 FROM test4 ;部门编码 人次
---------- ----------
10 3
20 5
30 6
这时PLAN如下:
Plan Hash Value : 2176849128 ---------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost | Time |
---------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 39 | 9 | 00:00:01 |
| 1 | UNION-ALL | | | | | |
| 2 | TABLE ACCESS FULL | TEST | 1 | 13 | 3 | 00:00:01 |
| 3 | TABLE ACCESS FULL | TEST | 1 | 13 | 3 | 00:00:01 |
| 4 | TABLE ACCESS FULL | TEST | 1 | 13 | 3 | 00:00:01 |
---------------------------------------------------------------------Note
-----
- dynamic sampling used for this statement
需要扫描test三次,而且如果列数较多,这种查询编写与维护都比较麻烦,而用UNPIVOT就不一样了。
SQL>
SQL> select * from test unpivot(2 ct for deptno in(d10_ct,d20_ct,d30_ct)3 );D10_S D20_S D30_S DEPTNO CT
---------- ---------- ---------- ------ ----------8750 7875 9400 D10_CT 38750 7875 9400 D20_CT 58750 7875 9400 D30_CT 6SQL>
UNPIYOT函数生成两个新列:“deptno"与"ct”。
而in()中的D10_CT、D20_CT和D30_CT三列,其列名成为行"deptno"的值,原来D10_CT等列中的值分别转为"ct"列中的三行:
那怎么恢复成原来deptno号的样子?只要将语句整理如下:
SQL> select deptno AS lm,substr(deptno,-5, 2)AS deptno,ct2 from test unpivot(3 ct for deptno in(d10_ct,d20_ct,d30_ct)4 );LM DEPTNO CT
------ -------- ----------
D10_CT 10 3
D20_CT 20 5
D30_CT 30 6这时PLAN如下:Plan Hash Value : 734873962 -----------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost | Time |
-----------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 63 | 9 | 00:00:01 |
| * 1 | VIEW | | 3 | 63 | 9 | 00:00:01 |
| 2 | UNPIVOT | | | | | |
| 3 | TABLE ACCESS FULL | TEST | 1 | 39 | 3 | 00:00:01 |
-----------------------------------------------------------------------Predicate Information (identified by operation id):
------------------------------------------
* 1 - filter("unpivot_view_006"."CT" IS NOT NULL)Note
-----
- dynamic sampling used for this statement
可以看到,与PIVOT不一样,UNPIVOT不仅语句简略,而且只需要扫描test一次。我们可以很容易地在后面的unpivot列表里维护要转换的列。当然,UNPIVOT同样有限制。
如果现在有这么一个需求:还是用前面的表test:
SQL> select * from test;D10_CT D10_S D20_CT D20_S D30_CT D30_S
---------- ---------- ---------- ---------- ---------- ----------3 8750 5 7875 6 9400
我们要求将人次和sal聚合的结果恢复成按照部门统计的行列表,也就是下面这样的:
DEPTNO RC SM-------- ---------- ----------10 3 875020 5 787530 6 9400
那我们该怎么实现?
要记得如果同时有人次与工资合计要转换,unpivot就不能一次性完成,只有分别转换后再用JOIN连接。
select *from (select substr(deptno, 1, 3) as lm,substr(deptno, -5, 2) AS deptno,rcfrom (select *from test unpivot include nulls(rc for deptno in(d10_ct, d20_ct, d30_ct)))) ainner join (select substr(deptno, 1, 3) as lm,substr(deptno, -4, 2) AS deptno,smfrom (select *from test unpivot include nulls(sm for deptno in(d10_s,d20_s,d30_s)))) bon a.lm = b.lmLM DEPTNO RC LM DEPTNO SM
------------ -------- ---------- ------------ -------- ----------
D10 10 3 D10 10 8750
D20 20 5 D20 20 7875
D30 30 6 D30 30 9400
上面的结果只要去掉几个列名就实现了前面的要求。这里为了让两个结果集一致,使用了参数include nulls这样即使数据为空,也显示一行。
是否有办法只用UNPIVOT,而不用JOIN呢?看下面的示例:
SQL> select *2 from test3 unpivot include nulls(rc for deptno in(d10_ct as 10, d20_ct as 20, d30_ct as 30))4 unpivot include nulls(sm for deptno2 in(d10_s as 10, d20_s as 20, d30_s as 30));DEPTNO RC DEPTNO2 SM
---------- ---------- ---------- ----------10 3 10 875010 3 20 787510 3 30 940020 5 10 875020 5 20 787520 5 30 940030 6 10 875030 6 20 787530 6 30 94009 rows selected
可以看到,当有两个UNPJVOT时,生成的结果是一个笛卡儿积。
上面的语句实际上就是一个嵌套语句,前一个UNPIVOT结果出来后,再执行另一个
SQL> with t as (2 select *3 from test4 unpivot include nulls(rc for deptno in(d10_ct as 10, d20_ct as 20, d30_ct as 30))5 )6 select * from t unpivot include nulls(sm for deptno2 in(d10_s as 10, d20_s as 20, d30_s as 30));DEPTNO RC DEPTNO2 SM
---------- ---------- ---------- ----------10 3 10 875010 3 20 787510 3 30 940020 5 10 875020 5 20 787520 5 30 940030 6 10 875030 6 20 787530 6 30 94009 rows selected
回来继续说,那上面这样的数据就不能用了吗?必须用join吗?
不不不,既然他笛卡尔积了,其实针对需要的数据,在上面的查询上加一个过滤即可。
SQL> select *2 from test3 unpivot include nulls(rc for deptno in(d10_ct as 10, d20_ct as 20, d30_ct as 30))4 unpivot include nulls(sm for deptno2 in(d10_s as 10, d20_s as 20, d30_s as 30))5 where deptno=deptno2;DEPTNO RC DEPTNO2 SM
---------- ---------- ---------- ----------10 3 10 875020 5 20 787530 6 30 9400SQL>
三、将结果集反向转置为一列
有时会要求数据竖向显示,如CLARK的数据显示如下(各行之间用空格隔开):
CLARK
MANAGER
2450
我们使用刚学到的UNPIVOT,再加一点小技巧就可以。
select emps from (
select ename, job, to_char(sal) as sal, null as t_colfrom empwhere deptno = 10)unpivot include nulls(emps for aa in(ename,job,sal,t_col));
EMPS
------
CLARK
MANAGER
2450KING
PRESIDENT
5000sdf
sdf
1300
这里要注意以下两点。
- 与UNION ALL一样,要合并的几列数据类型必须相同,如果sal不用to_char转换,就会报错:
SQL>
SQL> select emps from (2 select ename, job, sal as sal, null as t_col3 from emp4 where deptno = 10)5 unpivot include nulls(emps for aa in(ename,job,sal,t_col));
select emps from (
select ename, job, sal as sal, null as t_colfrom empwhere deptno = 10)unpivot include nulls(emps for aa in(ename,job,sal,t_col))ORA-01790: expression must have same datatype as corresponding expression
- 如果不加include nu11s,将不会显示空行:
select emps from (
select ename, job, to_Char(sal) as sal, null as t_colfrom empwhere deptno = 10)unpivot (emps for aa in(ename,job,sal,t_col));
EMPS
------
CLARK
MANAGER
2450
KING
PRESIDENT
5000
sdf
sdf
1300
总结
本篇文章讲解的主要内容是:目前Oracle支持的行列互换有两种方式:case when、pivot\unpivot,我将通过几个案例来给大家详解如何通过这两种方式实现“行转列”,“列转行”的需求,并通过执行计划看case when、pivot\unpivot二者的底层逻辑关系以及效率上的影响。
相关文章:
:数仓报表场景☞通过执行计划详解”行转列”,”列转行”是如何实现的)
【SQL开发实战技巧】系列(二十四):数仓报表场景☞通过执行计划详解”行转列”,”列转行”是如何实现的
系列文章目录 【SQL开发实战技巧】系列(一):关于SQL不得不说的那些事 【SQL开发实战技巧】系列(二):简单单表查询 【SQL开发实战技巧】系列(三):SQL排序的那些事 【SQL开发实战技巧…...
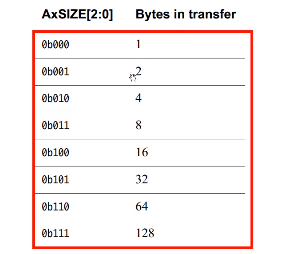
XILINX AXI总线学习
AXI介绍什么是AXI?AXI(高级可扩展接口),是ARM AMBA的一部分;AMBA:高级微控制器总线架构;是1996年首次引入的一组微控制器总线;开放的片内互联的总线标准,能在多主机设计中实现多个控…...

2022CCPC女生赛(补题)(A,C,E,G,H,I)
迟了好久的补题,,现在真想把当时赛时的我拉出来捶一拳排序大致按照题目难度。C. 测量学思路:直接循环遍历判断即可,注意角度要和2π取个最小值。AC Code:#include <bits/stdc.h>typedef long long ll; const int…...

【Nginx】Nginx的安装配置
环境说明系统:Centos 7一、编译安装Nginx官网下载地址nginx: download#安装依赖 [rootnginx nginx-1.22.1]# yum install gcc pcre pcre-devel zlib zlib-devel -y #从官网下载Nginx安装包,并进行解压、编译、安装 [rootnginx ~]# wget https://nginx.or…...

数学小课堂:统计时有效地筛选数据
文章目录引言I 被爆冷门的原因II 统计时有效地筛选数据2.1 统计数据的常见问题2.2 大数据的特征2.3 有效筛选数据的原则引言 在博弈论中很多结果有发生的概率,而概率这件事只是估计出来的,并不准确。因此,一旦加入博弈的选手多了之后&#x…...

MySQL安装优化
hello,大家好,我是小鱼 本文主要通过针对 MySQL Server(mysqld)相关实现机制的分析,得到一些相应的优化建议。主要 涉及 MySQL 的安装以及相关参数设置的优化,但不包括 mysqld 之外的比如存储引擎相关的参…...

RocketMQ系列开篇
RocketMQ系列开篇 今天开始学习RocketMQ相关系列源码。我会带着自己的目的去学习源码。所以不会像一般的技术博客一样,写一个完整的流程,介绍每一步干了啥。而是提出一个问题,然后去看代码里面是怎么实现的。说明一下,本次系列我…...
logback无法删除太久远的日志文件?logback删除日志文件源码分析
logback无法删除太久远的日志文件?logback删除日志文件源码分析 最近发现logback配置滚动日志,但是本地日志文件甚至还有2年前的日志文件,服务器是却是正常的! 网上搜索了一波没有发现,只找到说不能删除太久远的旧日志…...

【MyBatis-Plus】基于@Version注解的乐观锁实现
引入mybatis-plus依赖,注意这里的版本要求 since 3.4.0;(3.4.1,3.4.2已测) 3.2.0肯定是不支持的,无法引入MybatisPlusInterceptor; 乐观锁 当要更新一条记录的时候,希望这条记录没有被别人更新…...
ubuntu20.04搭建detectron2环境
Ubuntu22.04安装Cuda11.3 Linux下驱动安装 # 以下命令按顺序执行 sudo apt update && sudo apt upgrade -y # or sudo apt update # 查看显卡信息 ubuntu-drivers devices sudo ubuntu-drivers autoinstall # or sudo apt install nvidia-driver-510 reboot nvidia-s…...
Navicate远程连接Linux上docker安装的MySQL容器
Navicate远程连接Linux上docker安装的MySQL容器失败 来自:https://bluebeastmight.github.io/ 问题描述:windows端的navicat远程连接不上Linux上docker安装的mysql(5.7版本)容器,错误代码10060 标注: 1、…...
基于Jetson NX的模型部署
系统安装 系统安装过程分为3步: 下载必要的软件及镜像 Jetson Nano Developer Kit SD卡映像 https://developer.nvidia.com/jetson-nano-sd-card-image Windows版SD存储卡格式化程序 https://www.sdcard.org/downloads/formatter_4/eula_windows/ 镜像烧录工具…...
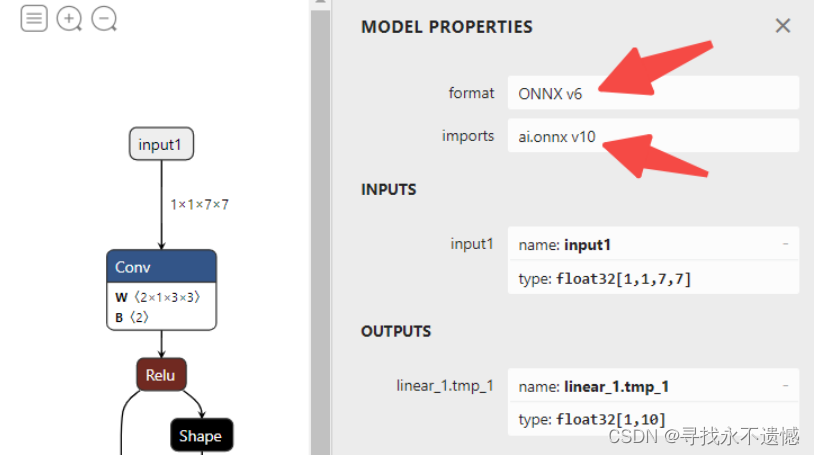
【PaddlePaddle onnx】PaddlePaddle导出ONNX及模型可视化教程
文章目录1 背景介绍2 实验环境3 paddle.onnx.export函数简介4 代码实操4.1 PaddlePaddle与ONNX模型导出4.2 ONNX正确性验证4.3 PaddlePaddle与ONNX的一致性检查4.4 多输入的情况5 ONNX模型可视化6 ir_version和opset_version修改7 致谢原文来自于地平线开发者社区,未…...

虹科案例 | 如何可持续的对变压器进行温度监控?
为了延长变压器的使用寿命,需要一个测量系统来监测内部整个绕组区域的温度。它必须明确温度升高发生的位置及其强度。您可以在此处了解为什么会这样以及如何在实践中实施? PART 1 变压器多点测温问题 变压器的工作温度越高,使用寿命越短。这里主要存在…...
Go之入门(特性、变量、常量、数据类型)
一、Go语言特性 语法简单并发性。Go语言引入了协程goroutine,实现了并发编程内存分配。Go语言为了解决高并发下内存的分配和管理,选择了tcmalloc进行内存分配(为了并发设计的高性能内存分配组件,使用cache为当前线程提供无锁分配…...
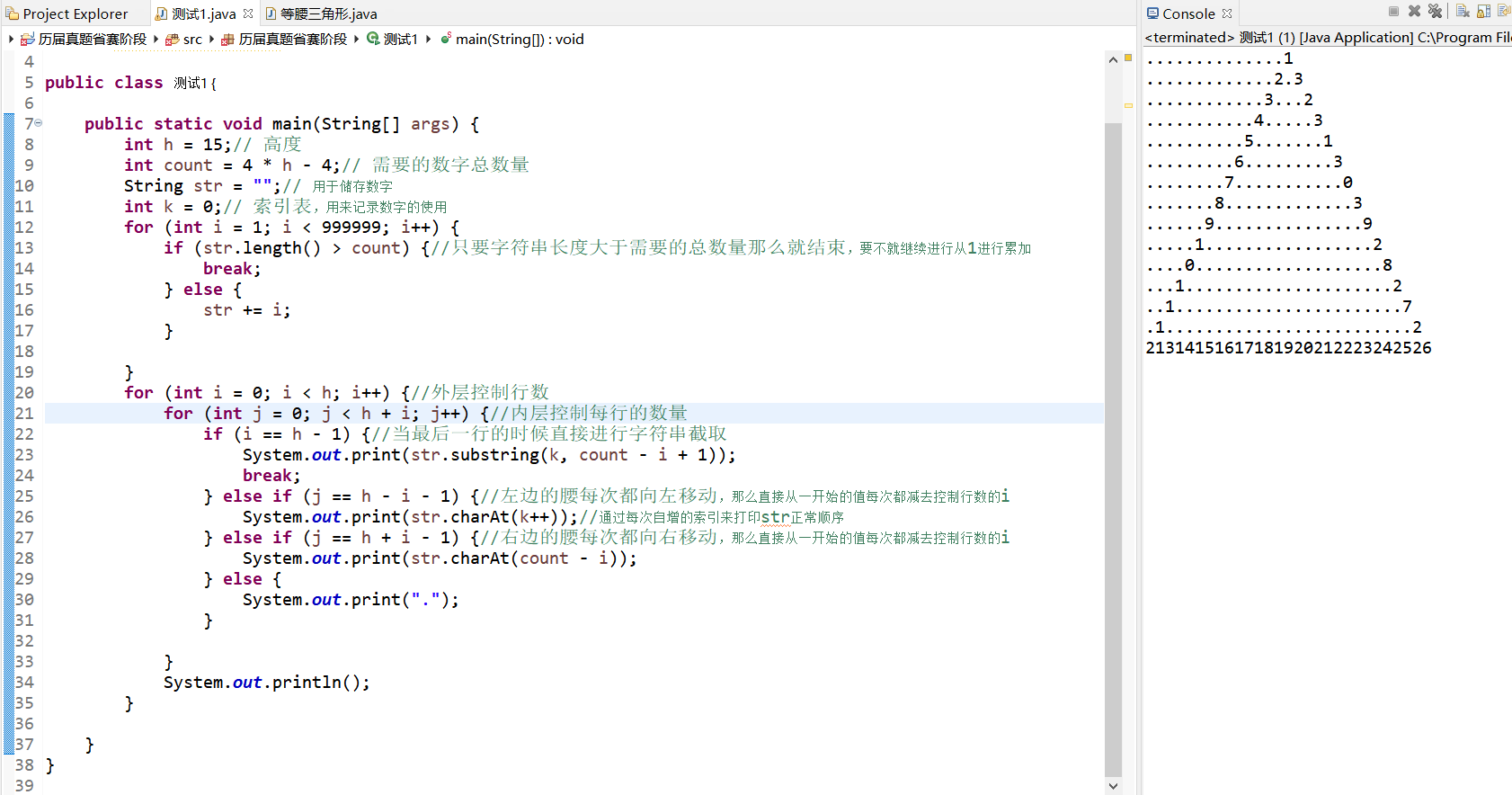
第九届省赛——8等腰三角形(找规律)
题目:本题目要求你在控制台输出一个由数字组成的等腰三角形。具体的步骤是:1. 先用1,2,3,...的自然数拼一个足够长的串2. 用这个串填充三角形的三条边。从上方顶点开始,逆时针填充。比如,当三角形高度是8时:…...

【产品设计】ToB 增删改查显算传
入职培训时技术leader说:“我不需要你们太聪明,做好基础的增删改查就可以了。”看似很简单的活,要做好并不容易。基础的坑在哪里呢? 一、 增(新增、创建、导入) 1. 明确表字段类型 新增的业务是由不同类型…...
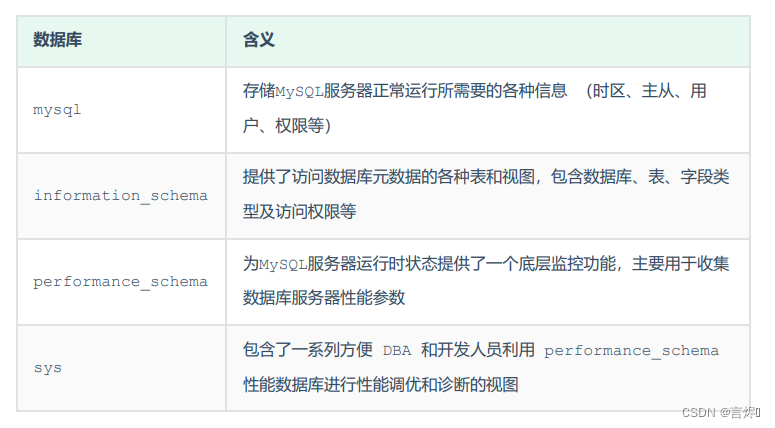
MySQL(二)视图、锁、存储过程、触发器、锁以及常用工具
MySQL进阶视图检查选项视图的更新存储过程存储过程基本语法变量系统变量用户自定义变量局部变量if判断参数casewhile循环repeat循环loop循环cursor游标handler条件处理程序存储函数触发器锁全局锁表级锁表锁元数据锁意向锁行级锁行锁间隙锁&临键锁InnoDB引擎逻辑存储结构事…...

CorelDRAW Graphics Suite2023更新内容介绍
懂设计的职场人都知道这款软件,CorelDRAW是一款非常高效的矢量图形设计软件。CorelDRAW操作界面简洁易懂,能够为用户提供精确地创建物体的尺寸和位置的功能,减少点击步骤,提高设计效率,节省设计时间。功能比普通的美图…...
 T1变幻)
2021牛客OI赛前集训营-提高组(第三场) T1变幻
2021牛客OI赛前集训营-提高组(第三场) 题目大意 对于一个大小为nnn的数组aaa的任意一点iii,若满足ai−1>aia_{i-1}>a_iai−1>ai且ai<ai1a_i<a_{i1}ai<ai1,则称iii为山谷点。111和nnn不可能为山谷点。…...

Admin.Net中的消息通信SignalR解释
定义集线器接口 IOnlineUserHub public interface IOnlineUserHub {/// 在线用户列表Task OnlineUserList(OnlineUserList context);/// 强制下线Task ForceOffline(object context);/// 发布站内消息Task PublicNotice(SysNotice context);/// 接收消息Task ReceiveMessage(…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

基于数字孪生的水厂可视化平台建设:架构与实践
分享大纲: 1、数字孪生水厂可视化平台建设背景 2、数字孪生水厂可视化平台建设架构 3、数字孪生水厂可视化平台建设成效 近几年,数字孪生水厂的建设开展的如火如荼。作为提升水厂管理效率、优化资源的调度手段,基于数字孪生的水厂可视化平台的…...

高等数学(下)题型笔记(八)空间解析几何与向量代数
目录 0 前言 1 向量的点乘 1.1 基本公式 1.2 例题 2 向量的叉乘 2.1 基础知识 2.2 例题 3 空间平面方程 3.1 基础知识 3.2 例题 4 空间直线方程 4.1 基础知识 4.2 例题 5 旋转曲面及其方程 5.1 基础知识 5.2 例题 6 空间曲面的法线与切平面 6.1 基础知识 6.2…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

搭建DNS域名解析服务器(正向解析资源文件)
正向解析资源文件 1)准备工作 服务端及客户端都关闭安全软件 [rootlocalhost ~]# systemctl stop firewalld [rootlocalhost ~]# setenforce 0 2)服务端安装软件:bind 1.配置yum源 [rootlocalhost ~]# cat /etc/yum.repos.d/base.repo [Base…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...