Sqoop详解
目录
一、sqoop基本原理
1.1、何为Sqoop?
1.2、为什么需要用Sqoop?
1.3、关系图
1.4、架构图
二、Sqoop可用命令
2.1、公用参数:数据库连接
2.2、公用参数:import
2.3、公用参数:export
2.4、公用参数:hive
2.3、其他命令
三、Sqoop常用命令
3.1、RDBMS => HDFS (导入重点)
3.1.1、全表导入
3.1.2、查询导入--query
3.1.3、导入指定列 --columns
3.1.4、where语句过滤
3.1.5、①增量导入 append
3.1.5、②增量导入 lastmodified
3.2、RDBMS => HBase
3.3、RDBMS => Hive
3.3.1、导入普通表
3.3.2、导入分区表
3.4、Hive/Hdfs => RDBMS
3.5、Sqoop Job
一、sqoop基本原理
1.1、何为Sqoop?
Sqoop(SQL-to-Hadoop)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导出到关系型数据库中。
1.2、为什么需要用Sqoop?
我们通常把有价值的数据存储在关系型数据库系统中,以行和列的形式存储数据,以便于用户读取和查询。但是当遇到海量数据时,我们需要把数据提取出来,通过MapReduce对数据进行加工,获得更符合我们需求的数据。数据的导入和导出本质上是Mapreduce程序,充分利用了MR的并行化和容错性。为了能够和HDFS系统之外的数据库系统进行数据交互,MapReduce程序需要使用外部API来访问数据,因此我们需要用到Sqoop。
1.3、关系图

1.4、架构图

在 mapreduce 中主要是对 inputformat 和 outputformat 进行定制。
Sqoop工具接收到客户端的shell命令或者Java api命令后,通过Sqoop中的任务翻译器(Task Translator)将命令转换为对应的MapReduce任务,而后将关系型数据库和Hadoop中的数据进行相互转移,进而完成数据的拷贝。
二、Sqoop可用命令
| 命令 | 方法 |
|---|---|
| codegen | 生成与数据库记录交互的代码 |
| create-hive-table | 将表定义导入到Hive中 |
| eval | 评估SQL语句并显示结果 |
| export | 导出一个HDFS目录到一个数据库表 |
| help | 可用命令列表 |
| import | 将一个表从数据库导入到HDFS |
| import-all-tables | 从数据库导入表到HDFS |
| import-mainframe | 从大型机服务器导入数据集到HDFS |
| job | 使用已保存的工作 |
| list-databases | 列出服务器上可用的数据库 |
| list-tables | 列出数据库中可用的表 |
| merge | 合并增量导入的结果 |
| metastore | 运行一个独立的Sqoop转移 |
| version | 显示版本信息 |
对于不同的命令,有不同的参数,这里给大家列出来了一部分Sqoop操作时的常用参数,以供参考,需要深入学习的可以参看对应类的源代码,本文目前介绍常用的导入、导出的一些命令。
2.1、公用参数:数据库连接
| 参数 | 说明 |
|---|---|
| --connect | 连接关系型数据库的URL |
| --connection-manager | 指定要使用的连接管理类 |
| --driver | JDBC的driver class |
| --help | 打印帮助信息 |
| --username | 连接数据库的用户名 |
| --password | 连接数据库的密码 |
| --verbose | 在控制台打印出详细信息 |
2.2、公用参数:import
| 参数 | 说明 |
|---|---|
| --enclosed-by | 给字段值前后加上指定的字符 |
| --escaped-by | 对字段中的双引号加转义符 |
| --fields-terminated-by | 设定每个字段是以什么符号作为结束,默认为逗号 |
| --lines-terminated-by | 设定每行记录之间的分隔符,默认是\n |
| --mysql-delimiters | Mysql默认的分隔符设置,字段之间以逗号分隔,行之间以\n分隔,默认转义符是\,字段值以单引号包裹。 |
| --optionally-enclosed-by | 给带有双引号或单引号的字段值前后加上指定字符。 |
2.3、公用参数:export
| 参数 | 说明 |
|---|---|
| --input-enclosed-by | 对字段值前后加上指定字符 |
| --input-escaped-by | 对含有转移符的字段做转义处理 |
| --input-fields-terminated-by | 字段之间的分隔符 |
| --input-lines-terminated-by | 行之间的分隔符 |
| --input-optionally-enclosed-by | 给带有双引号或单引号的字段前后加上指定字符 |
2.4、公用参数:hive
| 参数 | 说明 |
|---|---|
| --hive-delims-replacement | 用自定义的字符串替换掉数据中的\r\n和\013 \010等字符 |
| --hive-drop-import-delims | 在导入数据到hive时,去掉数据中的\r\n\013\010这样的字符 |
| --map-column-hive < map> | 生成hive表时,可以更改生成字段的数据类型 |
| --hive-partition-key | 创建分区,后面直接跟分区名,分区字段的默认类型为string |
| --hive-partition-value | 导入数据时,指定某个分区的值 |
| --hive-home | hive的安装目录,可以通过该参数覆盖之前默认配置的目录 |
| --hive-import | 将数据从关系数据库中导入到hive表中 |
| --hive-overwrite | 覆盖掉在hive表中已经存在的数据 |
| --create-hive-table | 默认是false,即,如果目标表已经存在了,那么创建任务失败 |
| --hive-table | 后面接要创建的hive表,默认使用MySQL的表名 |
| --table | 指定关系数据库的表名 |
2.3、其他命令
| 命令 | 含义 |
|---|---|
| -m N | 指定启动N个map进程 |
| --num-mappers N | 指定启动N个map进程 |
| --query | 后跟查询的SQL语句 |
| --incremental mode | mode:append或lastmodified |
| --check-column | 作为增量导入判断的列名 |
| --split-by | 按照某一列来切分表的工作单元,不能与–autoreset-to-one-mapper连用 |
| --last-value | 指定某一个值,用于标记增量导入的位置 |
| --target-dir | 指定HDFS路径 |
| --delete-target-dir | 若hdfs存放目录已存在,则自动删除 |
三、Sqoop常用命令
先在mysql中建一张表来使用
create table student(sid int primary key,sname varchar(16) not null,gender enum('女','男') not null default '男',age int not null
);
insert into student(sid,sname,gender,age) values
(1,'孙尚香','女',15),
(2,'貂蝉','女',16),
(3,'刘备','男',17),
(4,'孙二娘','女',16),
(5,'张飞','男',15),
(6,'关羽','男',18),
3.1、RDBMS => HDFS (导入重点)
3.1.1、全表导入
//single为自己虚拟机ip
sqoop import \
--connect jdbc:mysql://single:3306/sqoop_test \
--username root \
--password kb10 \
--table student \
--target-dir /sqooptest/table_all \
--delete-target-dir \
--num-mappers 1 \
--fields-terminated-by ','
- 登录web界面查看/sqooptest/table_all目录下,生成了数据结果
- 或者使用hdfs命令查看数据结果

hdfs dfs -cat /sqooptest/table_all/part-m-00000
数据结果如下
1,孙尚香,女,15
2,貂蝉,女,16
3,刘备,男,17
4,孙二娘,女,16
5,张飞,男,15
6,关羽,男,18
3.1.2、查询导入--query
//single为虚拟机ip地址
sqoop import \
--connect jdbc:mysql://single:3306/sqoop_test \
--username root \
--password kb10 \
--target-dir /sqooptest/select_test \
--num-mappers 1 \
--query 'select sname,gender from student where $CONDITIONS'
where语句中必须有 $CONDITIONS,表示将查询结果带回。 如果query后使用的是双引号,则 $CONDITIONS前必须加转移符即 \$CONDITIONS,防止shell识别为自己的变量。

hdfs dfs -cat /sqooptest/select_test/part-m-00000
数据结果如下
孙尚香,女
貂蝉,女
刘备,男
孙二娘,女
张飞,男
关羽,男
3.1.3、导入指定列 --columns
sqoop import \
--connect jdbc:mysql://single:3306/sqoop_test \
--username root \
--password kb10 \
--table student \
--columns sid,sname,age \
--target-dir /sqooptest/column_test \
--num-mappers 1 \
--fields-terminated-by "|"
数据结果如下
1|孙尚香|15
2|貂蝉|16
3|刘备|17
4|孙二娘|16
5|张飞|15
6|关羽|18
3.1.4、where语句过滤
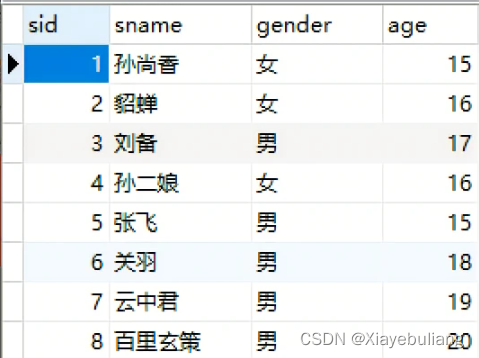
源表数据
sqoop import \
--connect jdbc:mysql://single:3306/sqoop_test \
--username root \
--password kb10 \
--table student \
--where "sid>=6" \
--target-dir /sqooptest/wheretest \
-m 2
得到了如下 “sid>=6” 的数据
[root@single ~]# hdfs dfs -cat /sqooptest/wheretest/*
6,关羽,男,18
7,云中君,男,19
8,百里玄策,男,203.1.5、①增量导入 append
sqoop import \
--connect jdbc:mysql://single:3306/sqoop_test \
--username root \
--password kb10 \
--query "select sid,sname,gender from student where \$CONDITIONS" \
--target-dir /sqooptest/add1 \
--split-by sid \
-m 2 \
--incremental append \
--check-column sid \
--last-value 0
–split-by 和 -m 结合实现numberReduceTasks并行
后面两句
–check-column sid
–last-value 0
结合使用的效果类似于where sid>0
MR过程中部分关键信息如下
--sid界限值是0-6
20/11/20 05:17:42 INFO tool.ImportTool: Incremental import based on column `sid`
20/11/20 05:17:42 INFO tool.ImportTool: Lower bound value: 0
20/11/20 05:17:42 INFO tool.ImportTool: Upper bound value: 6
--条件是where `sid` > 0 AND `sid` <= 6
20/11/20 05:17:48 INFO db.DataDrivenDBInputFormat: BoundingValsQuery: SELECT MIN(sid), MAX(sid) FROM (select sid,sname,gender from student where `sid` > 0 AND `sid` <= 6 AND (1 = 1) ) AS t1
--指定了两个maptask
20/11/20 05:17:48 INFO mapreduce.JobSubmitter: number of splits:2
--提示last-value即sid是6
20/11/20 05:18:06 INFO tool.ImportTool: --incremental append
20/11/20 05:18:06 INFO tool.ImportTool: --check-column sid
20/11/20 05:18:06 INFO tool.ImportTool: --last-value 6
数据结果如下:
1,孙尚香,女
2,貂蝉,女
3,刘备,男
4,孙二娘,女
5,张飞,男
6,关羽,男
此时往mysql中再添加几条数据,再进行一次增量导入
insert into student(sid,sname,gender,age) values(7,'云中君','男',19),(8,'百里玄策','男',20),(9,'裴擒虎','男',17);
再次执行增量导入语句
sqoop import \
--connect jdbc:mysql://single:3306/sqoop_test \
--username root \
--password kb10 \
--query "select sid,sname,gender,age from student where \$CONDITIONS" \
--target-dir /sqooptest/add1 \
-m 1 \
--incremental append \
--check-column sid \
--last-value 6
hdfs dfs -cat /sqooptest/add1/part-m-*1,孙尚香,女
2,貂蝉,女
3,刘备,男
4,孙二娘,女
5,张飞,男
6,关羽,男
7,云中君,男,19
8,百里玄策,男,20
9,裴擒虎,男,17
3.1.5、②增量导入 lastmodified
先在mysql创建一张新表
create table orderinfo(oid int primary key,oName varchar(10) not null,oPrice double not null,oTime timestamp not null
);insert into orderinfo(oid,oName,oPrice,oTime) values
(1,'爱疯12',6500.0,'2020-11-11 00:00:00'),
(2,'华为xpro',12000.0,'2020-10-1 12:52:33'),
(3,'行李箱',888.8,'2019-5-22 21:56:17'),
(4,'羽绒服',1100.0,'2018-3-7 14:22:31');
将数据传到hdfs
sqoop import \
--connect jdbc:mysql://single:3306/sqoop_test \
--username root \
--password kb10 \
--table orderinfo \
--target-dir /sqooptest/lastmod \
-m 1
往mysql的orderinfo表中新插入几条数据,然后增量导入
insert into orderinfo(oid,oName,oPrice,oTime) values
(5,'帕拉梅拉',1333333.3,'2020-4-7 12:23:34'),
(6,'保温杯',86.5,'2017-3-5 22:52:16'),
(7,'枸杞',46.3,'2019-10-5 11:11:11'),
(8,'电动牙刷',350.0,'2019-9-9 12:21:41');
–incremental lastmodified修改和增加 此时搭配–check-column 必须为timestamp类型
使用lastmodified方式导入数据要指定增量数据是要–append(追加)还是要–merge-key(合并)
sqoop import \
--connect jdbc:mysql://single:3306/sqoop_test \
--username root \
--password kb10 \
--table orderinfo \
--target-dir /sqooptest/lastmod \
-m 1 \
--incremental lastmodified \
--check-column oTime \
--merge-key oid \
--last-value "2019-10-1 12:12:12"
数据结果如下
1,爱疯12,6500.0,2020-11-11 00:00:00.0
2,华为xpro,12000.0,2020-10-01 12:52:33.0
3,行李箱,888.8,2019-05-22 21:56:17.0
4,羽绒服,1100.0,2018-03-07 14:22:31.0
5,帕拉梅拉,1333333.3,2020-04-07 12:23:34.0
7,枸杞,46.3,2019-10-05 11:11:11.0
发现只添加了两条记录,因为序号为6和8的记录的时间不在–last-value的范围内
3.2、RDBMS => HBase
先在hbase中建表
hbase(main):007:0> create 'sqooptest:sqstudent','stuinfo'
使用sqoop开始导入数据
sqoop import \
--connect jdbc:mysql://single:3306/sqoop_test \
--username root \
--password kb10 \
--table student \
--hbase-table sqooptest:sqstudent \
--column-family stuinfo \
--hbase-create-table \
--hbase-row-key sid
–column-family stuinfo
指定列族为stuinfo
–hbase-create-table
若表不存在,则自动创建
–hbase-row-key sid
指定行键为sid
查看hbase表数据
hbase(main):008:0> scan 'sqooptest:sqstudent'
ROW COLUMN+CELL 1 column=stuinfo:age, timestamp=1605958889301, value=15 1 column=stuinfo:gender, timestamp=1605958889301, value=\xE5\xA5\xB3 1 column=stuinfo:sname, timestamp=1605958889301, value=\xE5\xAD\x99\xE5\xB0\x9A\xE9\xA6\x99 2 column=stuinfo:age, timestamp=1605958889301, value=16 2 column=stuinfo:gender, timestamp=1605958889301, value=\xE5\xA5\xB3 2 column=stuinfo:sname, timestamp=1605958889301, value=\xE8\xB2\x82\xE8\x9D\x89
...
...
... 9 column=stuinfo:age, timestamp=1605958892765, value=17 9 column=stuinfo:gender, timestamp=1605958892765, value=\xE7\x94\xB7 9 column=stuinfo:sname, timestamp=1605958892765, value=\xE8\xA3\xB4\xE6\x93\x92\xE8\x99\x8E
9 row(s) in 0.1830 seconds
HBase中的数据没有数据类型,统一存储为字节码,是否显示具体的汉字只是前端显示问题,此处没有解决,因此gender和sname字段显示的都是字节码
3.3、RDBMS => Hive
3.3.1、导入普通表
将mysql中retail_db库下的orders表导入hive
sqoop import \
--connect jdbc:mysql://single:3306/retail_db \
--driver com.mysql.jdbc.Driver \
--username root \
--password kb10 \
--table orders \
--hive-import \
--hive-database sqooptest \
--create-hive-table \
--hive-table orders \
--hive-overwrite \
-m 3
3.3.2、导入分区表
sqoop import \
--connect jdbc:mysql://single:3306/retail_db \
--driver com.mysql.jdbc.Driver \
--username root \
--password kb10 \
--query "select order_id,order_status from orders where
order_date>='2014-07-02' and order_date<'2014-07-03' and \$CONDITIONS" \
--hive-import \
--hive-database sqooptest \
--hive-table order_partition \
--hive-partition-key 'order_date' \
--hive-partition-value '2014-07-02' \
-m 1
3.4、Hive/Hdfs => RDBMS
先在mysql中建表
create table hiveTomysql(sid int primary key,sname varchar(5) not null,gender varchar(1) default '男',age int not null
);
我们把刚才在hive中创建的sqstudent表数据再导出到mysql中
sqoop export \
--connect jdbc:mysql://single:3306/sqoop_test \
--username root \
--password kb10 \
--table hiveTomysql \
--num-mappers 1 \
--export-dir /opt/software/hadoop/hive110/warehouse/sqstudent/part-m-00000 \
--input-fields-terminated-by ","
3.5、Sqoop Job
job参数说明
| Argument | Description |
|---|---|
| –create JOB_NAME | 创建job参数 |
| –delete JOB_NAME | 删除一个job |
| –exec JOB_NAME | 执行一个job |
| –help | 显示job帮助 |
| –list | 显示job列表 |
| –help | 显示job帮助 |
| –meta-connect < jdbc-uri> | 用来连接metastore服务 |
| –show JOB_NAME | 显示一个job的信息 |
| –verbose | 打印命令运行时的详细信息 |
创建job
- -和import之间有个空格。这里–空格之后表示给job添加参数,而恰好import又不需要–,所以这个空格很容易被忽略。
sqoop job --create myjob \
-- import \
--connect jdbc:mysql://single:3306/sqoop_test \
--username root \
--password kb10 \
--table student \
--target-dir /sqooptest/myjob \
-m 1 \
--lines-terminated-by '\n' \
--null-string '\\N' \
--null-non-string '\\N'
查看job
sqoop job --list
显示job
sqoop job --show myjob
删除job
sqoop job --delete myjob
执行job
sqoop job --exec pwdjob
相关文章:
Sqoop详解
目录 一、sqoop基本原理 1.1、何为Sqoop? 1.2、为什么需要用Sqoop? 1.3、关系图 1.4、架构图 二、Sqoop可用命令 2.1、公用参数:数据库连接 2.2、公用参数:import 2.3、公用参数:export 2.4、公用参数ÿ…...

C++ 之指针
文章目录参考描述指针运算符地址运算符奇偶分体指针的创建间接寻址运算符句点运算符运算符优先级问题箭头运算符运算符优先级指针野指针空指针通用指针解引用分析指针的算术运算加减运算自增运算与自减运算比较运算指针与常量指针常量常量指针指向常量的指针常量指针与数组数组…...

数据结构与算法---JS与栈
前言js里,是没有栈这种原生的数据结构。但是我们可以通过自定义创建栈类,来实现对添加/删除元素时更多的控制。创建栈类// 初始化一个基于数组的栈类 class Stack {constructor() {this.items [];} }为什么我们要选择数组作为栈类的存储数据类型&#x…...
HDLBits: 在线学习 SystemVerilog(二十三)-Problem 158-162(找BUG)
HDLBits: 在线学习 SystemVerilog(二十三)-Problem 158-162(找BUG)HDLBits 是一组小型电路设计习题集,使用 Verilog/SystemVerilog 硬件描述语言 (HDL) 练习数字硬件设计~网址如下:https://hdlbits.01xz.ne…...

国外SEO升级攻略:如何应对搜索引擎算法变化?
搜索引擎优化(SEO)是一个动态的领域,搜索引擎的算法经常会发生变化,这意味着SEO专业人员需要保持更新的技术知识和策略, 以适应变化并提高网站的排名。 以下是一些应对搜索引擎算法变化的升级攻略: 创造…...

X.509证书
证书格式ASN.1是一种抽象的数据结构,描述了复杂的对象,以及对象之间的关系。证书本质上是一个文件,需要一种专门的格式,才能在互联网中传输,证书需要通过一个规则将ASN.1转换为二进制文件,这就需要对证书以…...

高等数学——微分方程
文章目录概念一阶微分方程可降阶的微分方程高阶线性微分方程线性微分方程解的结构常系数齐次线性微分方程常系数非齐次线性微分方程概念 微分方程:含有未知函数的导数或微分的方程称为微分方程。微分方程的阶:微分方程中所出现的未知函数最高阶导数的阶…...

JAVA小记-生成PDF文件
项目场景: 例如:项目中需要生成PDF文件 项目使用情况 1、引入pom.xml <!--pdf相关依赖--> <dependency><groupId>com.itextpdf</groupId><artifactId>itextpdf</artifactId><version>5.5.13</version> </dependency>…...
Noah-MP陆面过程模型建模方法与站点、区域模拟
陆表过程的主要研究内容以及陆面模型在生态水文研究中的地位和作用 熟悉模型的发展历程,常见模型及各自特点; Noah-MP模型的原理 Noah-MP模型所需的系统环境与编译环境的搭建方法您都了解吗?? linux系统操作环境您熟悉吗&…...

全国青少年软件编程(Scratch)等级考试一级真题——2019.9
青少年软件编程(Scratch)等级考试试卷(一级)分数:100 题数:37一、单选题(共25题,每题2分,共50分)1.小明在做一个采访的小动画,想让主持人角色说“大家好!”3秒…...
第十四届蓝桥杯三月真题刷题训练——第 6 天
目录 第 1 题:星期计算 问题描述 运行限制 代码: 第 2 题:考勤刷卡 问题描述 输入格式 输出格式 样例输入 样例输出 评测用例规模与约定 运行限制 代码: 第 3 题:卡片 问题描述 输入格式 输出格式 样…...

安装MySQL数据库8.0服务实例
前言 之前尝试去安装了MySQL5.7的社区版本,今天来安装MySQL8.0的版本,并且以两种方式进行安装,一个是通过RPM包的安装,另一个则是编译的方式。 一. 前期准备 查看服务器IP [rootlocalhost ~]# hostname -I 192.168.161.166 19…...
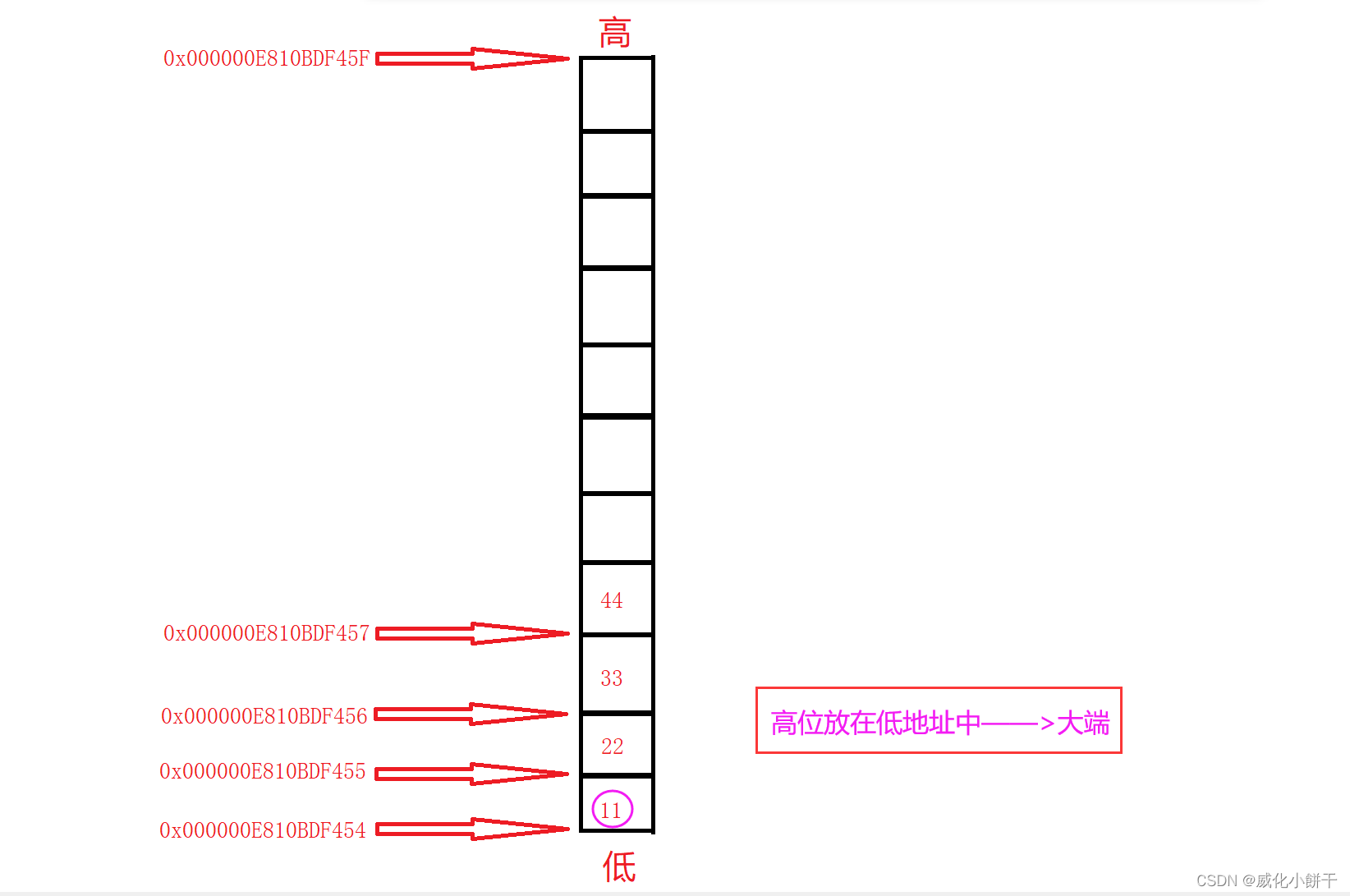
数据的存储--->【大小端字节序】(Big Endian)(Little Endian)
⛩️博主主页:威化小餅干📝系列专栏:【C语言】藏宝图🎏 ✨绳锯⽊断,⽔滴⽯穿!一个编程爱好者的学习记录!✨前言计算机硬件有两种存储数据的方式:大端字节序——Big Endian小端字节序——Little …...

软件测试备战近三银四--面试心得
自信即巅峰,对待面试官就像和儿子一样,耐心!耐心!耐心!...
《Linux运维实战:ansible中的变量定义及以及变量的优先级》
一、配置文件优先级 Ansible配置以ini格式存储配置数据,在Ansible中⼏乎所有配置都可以通过Ansible的Playbook或环境变量来重新赋值。在运⾏Ansible命令时,命令将会按照以下顺序查找配置⽂件。 # ⾸先,Ansible命令会检查环境变量,…...
 监听 Form表单变化)
useEffect 通过 form.getFieldValue(‘xxx‘) 监听 Form表单变化
场景 子组件中,某一个表格的数据需要依赖于上级组件的某一个表单元素值进行计算。 毫无疑问,首先想到的肯定是监听 form 表单中元素的值,使用 useEffect 监听表单的变化,当值发生变化时,重新计算渲染。 首先说下我的…...
【晓龙oba出品 - 黑科技解题系列】- 最小操作次数使数组元素相等
思路 算法归根到底就是找规律的游戏,我们首先来看一个现象: 以数组nums [1,2,3,4,5]为例 当我们将数组排序后,可以知道最小值为1,最大值为5,此时我们需要四次运算可以使最小值与最大值相等: 第一次:2,3,4,…...
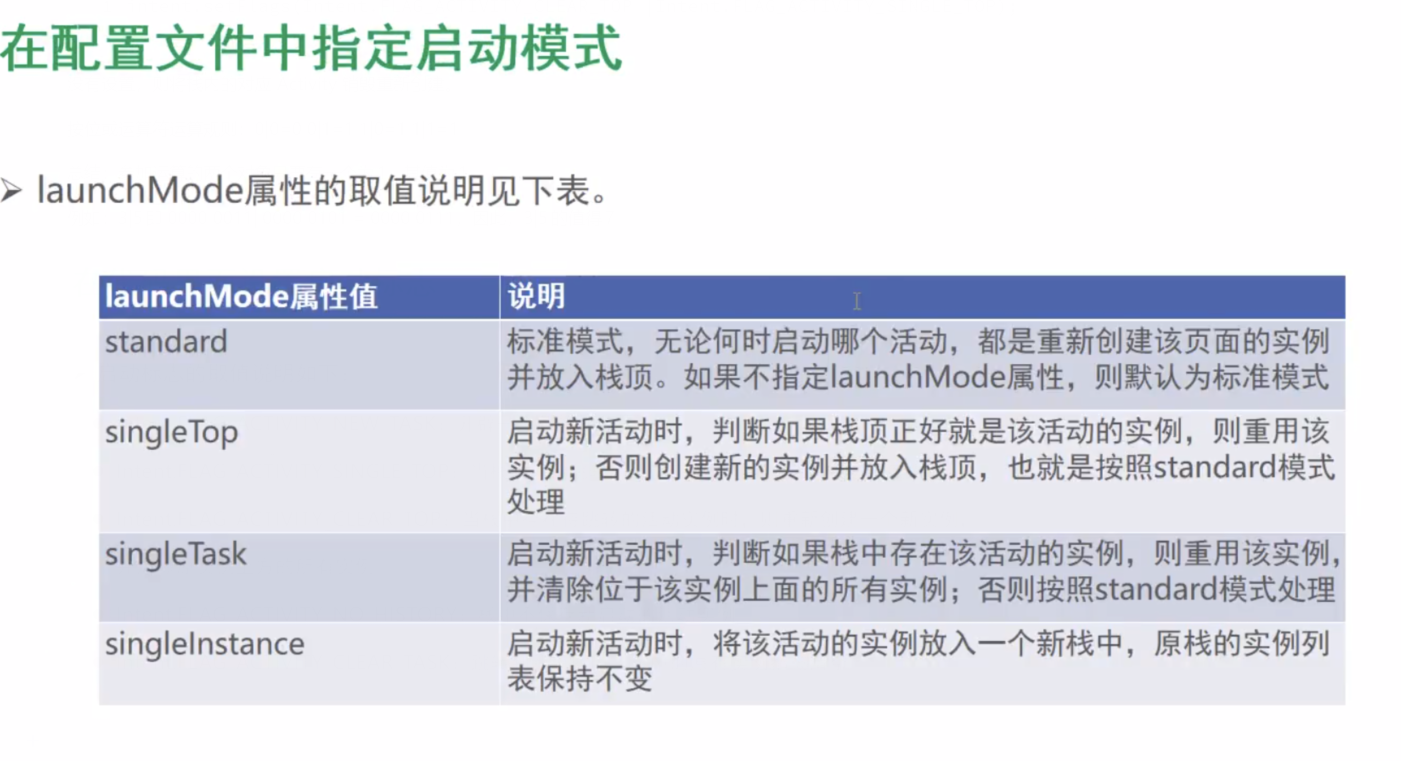
Activity的启动和结束
onCreate:创建活动。此时会把页面布局加载进内存,进入了初始状态。onStart:开启活动。此时会把活动页面显示在屏幕上,进入了就绪状态。onResume:恢复活动。此时活动页面进入活跃状态,能够与用户正常交互&am…...

利用业务逻辑+OB分布式特性优化SQL
最近某人社局核心数据库上了OB,经常出现性能问题 某人社与我司合作多年,非常信任我司在数据库的专业能力,邀请我司过去看看能否提供帮助 与OB驻场工程师合作,抓取了一天的TOP SQL,跑得慢的SQL有几十条(注意只是某一天的…...

哈希表
文章目录什么是哈希问题引入哈希函数直接定址法除留余数法 (常用、重点)哈希冲突哈希冲突的解决方法闭散列开散列unordered_map && unordered_set 封装实现哈希的应用位图布隆过滤器哈希经典面试题哈希切分位图应用布隆过滤器什么是哈希 在上一…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

稳定币的深度剖析与展望
一、引言 在当今数字化浪潮席卷全球的时代,加密货币作为一种新兴的金融现象,正以前所未有的速度改变着我们对传统货币和金融体系的认知。然而,加密货币市场的高度波动性却成为了其广泛应用和普及的一大障碍。在这样的背景下,稳定…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

mac 安装homebrew (nvm 及git)
mac 安装nvm 及git 万恶之源 mac 安装这些东西离不开Xcode。及homebrew 一、先说安装git步骤 通用: 方法一:使用 Homebrew 安装 Git(推荐) 步骤如下:打开终端(Terminal.app) 1.安装 Homebrew…...
)
C#学习第29天:表达式树(Expression Trees)
目录 什么是表达式树? 核心概念 1.表达式树的构建 2. 表达式树与Lambda表达式 3.解析和访问表达式树 4.动态条件查询 表达式树的优势 1.动态构建查询 2.LINQ 提供程序支持: 3.性能优化 4.元数据处理 5.代码转换和重写 适用场景 代码复杂性…...

Webpack性能优化:构建速度与体积优化策略
一、构建速度优化 1、升级Webpack和Node.js 优化效果:Webpack 4比Webpack 3构建时间降低60%-98%。原因: V8引擎优化(for of替代forEach、Map/Set替代Object)。默认使用更快的md4哈希算法。AST直接从Loa…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...

wpf在image控件上快速显示内存图像
wpf在image控件上快速显示内存图像https://www.cnblogs.com/haodafeng/p/10431387.html 如果你在寻找能够快速在image控件刷新大图像(比如分辨率3000*3000的图像)的办法,尤其是想把内存中的裸数据(只有图像的数据,不包…...