hadoop学习笔记
hadoop集群搭建
hadoop摘要
Hadoop 是一个开源的分布式存储和计算框架,旨在处理大规模数据集并提供高可靠性、高性能的数据处理能力。它主要包括以下几个核心组件:
-
Hadoop 分布式文件系统(HDFS):HDFS 是 Hadoop 的分布式文件存储系统,用于存储大规模数据,并通过数据的副本和自动故障恢复机制来提供高可靠性和容错性。
-
YARN(Yet Another Resource Negotiator):YARN 是 Hadoop 的资源管理平台,用于调度和管理集群中的计算资源,支持多种数据处理框架的并行计算,如 MapReduce、Spark 等。
-
MapReduce:MapReduce 是 Hadoop 最初提出的一种分布式计算编程模型,用于并行处理大规模数据集。它将计算任务分解为 Map 和 Reduce 两个阶段,充分利用集群的计算资源进行并行计算。
-
Hadoop 生态系统:除了上述核心组件外,Hadoop 还包括了一系列相关项目和工具,如 HBase(分布式列存数据库)、Hive(数据仓库基础设施)、Spark(快速通用的集群计算系统)等,构成了完整的大数据处理生态系统。
总的来说,Hadoop 提供了一套强大的工具和框架,使得用户能够在分布式环境下高效地存储、处理和分析大规模数据,是大数据领域的重要基础设施之一。
基础环境
规划
| hadoop001 | hadoop02 | hadoop003 | |
|---|---|---|---|
| HDFS | NameNode | DataNode | SecondaryNameNode DateNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
关闭防火墙 安全模块
systemctl disable --now firewalld
#关闭并且禁止防火墙自启动
setenforce 0
#关闭增强模块
sed -i 's/SELINUX=enforcing/SELINUX=permissive/g' /etc/selinux/config
#禁止自启动
添加主机地址映射
cat >> /etc/hosts << lxf
192.168.200.41 hadoop001
192.168.200.42 hadoop002
192.168.200.43 hadoop003
lxf
传递软件包
#最好创建一个独立目录存放软件包
#
[root@hadoop001 ~]# mkdir -p /export/{data,servers,software}
[root@hadoop001 ~]# tree /export/
/export/
├── data #存放数据
├── servers #安装服务
└── software #存放服务的软件包3 directories, 0 files
[root@hadoop001 ~]#
配置ssh免密
master 和两台slave都要配置免密
#在hadoop001节点
[root@hadoop001 ~]#
[root@hadoop001 ~]# ssh-keygen -t rsa
[root@hadoop001 ~]#
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:2AY6p3kFWziXFmXH7e/PHgrAVZ9H7hkCWAtCc19UwZw root@hadoop001
The key's randomart image is:
+---[RSA 2048]----+
| .+.+=+o=+o+|
| .+=o.* oE.|
| = = + o +o|
| . @. . o.+|
| o + So o.|
| = o . .|
| o . . o |
| . . ..o|
| . .=|
+----[SHA256]-----+
[root@hadoop001 ~]#
[root@hadoop001 ~]# hosts=("hadoop001" "hadoop002" "hadoop003"); for host in "${hosts[@]}"; do echo "将公钥分发到 $host"; ssh-copy-id $host; done
将公钥分发到 hadoop001
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop001's password: Number of key(s) added: 1Now try logging into the machine, with: "ssh 'hadoop001'"
and check to make sure that only the key(s) you wanted were added.将公钥分发到 hadoop002
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host 'hadoop002 (192.168.200.42)' can't be established.
ECDSA key fingerprint is SHA256:ADFjDGD2MxgCqL5fQuWhn+0T5drPiTXERvlMiu/QXjA.
ECDSA key fingerprint is MD5:d2:2b:06:cb:13:48:e0:87:d7:f3:87:8b:2c:56:e4:da.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop002's password: Number of key(s) added: 1Now try logging into the machine, with: "ssh 'hadoop002'"
and check to make sure that only the key(s) you wanted were added.将公钥分发到 hadoop003
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop003's password: Number of key(s) added: 1Now try logging into the machine, with: "ssh 'hadoop003'"
and check to make sure that only the key(s) you wanted were added.
[root@hadoop001 ~]#
[root@hadoop001 ~]#
#在hadoop002和hadoop003重复操作 使得三台节点可以互相通信安装服务
安装java hadoop
[root@hadoop001]# tree -L 2 /export/
/export/
├── data #因为还没有启动服务所以没有数据文件
├── servers
│ ├── hadoop-3.3.6
│ └── jdk1.8.0_221
└── software├── hadoop-3.3.6-aarch64.tar.gz└── jdk-8u221-linux-x64.tar.gz5 directories, 2 files
[root@hadoop001 export]#
#同样在另外两个节点分别解压到对应目录
配置环境变量
#/etc/profile.d/my_env.sh 我们可以专门为hadoop设置一个环境变量文件夹用作修改,而不去直接修改/etc/profile文件,这样在系统启动时或者用户登录时会自动加载这些环境变量。[root@hadoop001 ~]# cat >> /etc/profile.d/my_env.sh << lxf
> #JAVA_HOME
> export JAVA_HOME=/export/servers/jdk1.8.0_221
> export PATH=$PATH:$JAVA_HOME/bin
> #HADOOP_HOME
> export HADOOP_HOME=/export/servers/hadoop-3.3.6
> export PATH=$PATH:$HADOOP_HOME/bin
> export PATH=$PATH:$HADOOP_HOME/sbin
> lxf
[root@hadoop001 ~]# source /etc/profile
[root@hadoop001 ~]# echo $HADOOP_HOME
/export/servers/hadoop-3.3.6
[root@hadoop001 ~]# echo $JAVA_HOME
/export/servers/jdk1.8.0_221
[root@hadoop001 ~]# #测试环境变量
[root@hadoop001 ~]# hadoop version
Hadoop 3.3.6
Source code repository https://github.com/apache/hadoop.git -r 1be78238728da9266a4f88195058f08fd012bf9c
Compiled by ubuntu on 2023-06-18T23:15Z
Compiled on platform linux-aarch_64
Compiled with protoc 3.7.1
From source with checksum 5652179ad55f76cb287d9c633bb53bbd
This command was run using /export/servers/hadoop-3.3.6/share/hadoop/common/hadoop-common-3.3.6.jar
[root@hadoop001 ~]# java -version
java version "1.8.0_221"
Java(TM) SE Runtime Environment (build 1.8.0_221-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.221-b11, mixed mode)
[root@hadoop001 ~]#
#分发环境配置文件
scp /etc/profile.d/my_env.sh hadoop002:/etc/profile.d/my_env.sh
scp /etc/profile.d/my_env.sh hadoop003:/etc/profile.d/my_env.sh
#分发完成后注意测试环境变量是否成功配置
修改Hadoop配置文件
[root@hadoop001 hadoop]# pwd
/export/servers/hadoop-3.3.6/etc/hadoop
[root@hadoop001 hadoop]# grep '^export' hadoop-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_221
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
[root@hadoop001 hadoop]# 修改core-site.xml文件
<configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop001:9000</value></property><property><name>hadoop.tmp.dir</name><value>/export/data/hadoop/tmp</value></property>
</configuration>
修改hdfs-site.xml文件
<configuration><property><name>dfs.relication</name><value>2</value></property><property><name>dfs.namenode.name.dir</name><value>/export/data/hadoop/name</value></property><property><name>dfs.namenode.secondary.http-address</name><value>hadoop002:50090</value></property><property><name>dfs.namenode.data.dir</name><value>/export/data/hadoop/data</value></property>
</configuration>修改mapred-site.xml文件
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
修改yarn-site.xml文件
<configuration>
<!-- Site specific YARN configuration properties --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>hadoop001</value></property>
</configuration>
修改workers文件
[root@hadoop001 hadoop]# cat >> workers << lxf
> hadoop001
> hadoop002
> hadoop003
> lxf
[root@hadoop001 hadoop]# 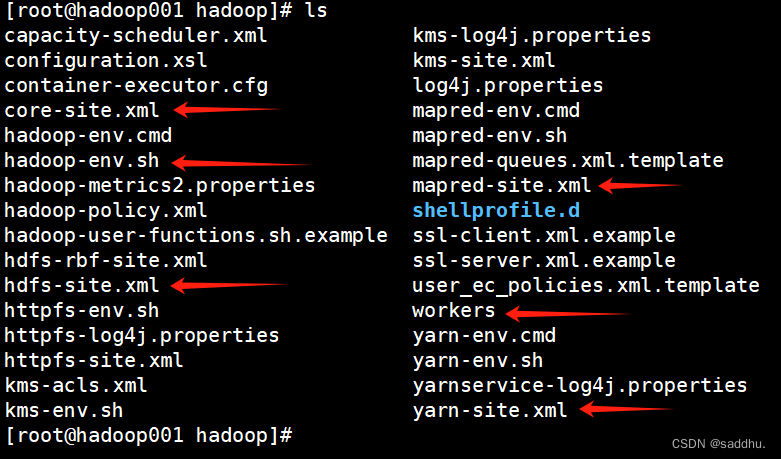
向集群分发配置文件
#开始分发
#向hadoop002
scp /export/servers/hadoop-3.3.6/etc/hadoop hadoop002:/export/servers/hadoop-3.3.6/etc/hadoop
#向hadoop003
scp /export/servers/hadoop-3.3.6/etc/hadoop hadoop002:/export/servers/hadoop-3.3.6/etc/hadoophadoop集群
hadoop集群文件系统初始化
Hadoop集群的初始化是非常重要的,它确保了集群的各个组件在启动时处于正确的状态,并且能够正确地协调彼此的工作。在第一次启动Hadoop集群时,初始化是必需的,具体原因如下:
- 文件系统初始化:Hadoop的分布式文件系统(HDFS)需要在启动时进行初始化,这包括创建初始的目录结构、设置权限和准备必要的元数据等操作。
- 元数据准备:Hadoop的各个组件(比如NameNode、ResourceManager等)需要进行元数据的准备工作,包括创建必要的数据库表、清理日志文件等。
- 配置检查:初始化过程还会对各个节点的配置进行检查,确保配置的正确性和一致性,以避免在后续运行中出现问题。
- 启动必要的服务:在初始化过程中,Hadoop会启动各个必要的服务,比如NameNode、DataNode、ResourceManager、NodeManager等,以确保集群的核心组件都能够正常运行。
#在启动hadoop集群之前,需要对主节点hadoop001进行格式化
[root@hadoop001 ~]# hadoop namenode -format
.......
......启动
分布启动
启动hdfs
[root@hadoop001 ~]# start-dfs.sh
启动yarn
[root@hadoop001 ~]# start-yarn.sh
集群一键启动
[root@hadoop001 ~]# start-all.sh
关闭
分布关闭
关闭hdfs
[root@hadoop001 ~]# stop-dfs.sh
启动yarn
[root@hadoop001 ~]# stop-yarn.sh
集群一键启动
[root@hadoop001 ~]# stop-all.sh
测试
查看hadoop的WebUI

成功访问
可以在C:\Windows\System32\drivers\etc\hosts下面修改hosts主机地址映射然后在宿主机的浏览器中就可以使用主机名:端口号去访问
如果没有设置就只能使用ip:端口号去访问
关闭hdfs
[root@hadoop001 ~]# stop-dfs.sh
启动yarn
[root@hadoop001 ~]# stop-yarn.sh
集群一键启动
[root@hadoop001 ~]# stop-all.sh
测试
查看hadoop的WebUI
成功访问
可以在C:\Windows\System32\drivers\etc\hosts下面修改hosts主机地址映射然后在宿主机的浏览器中就可以使用主机名:端口号去访问
如果没有设置就只能使用ip:端口号去访问
相关文章:
hadoop学习笔记
hadoop集群搭建 hadoop摘要 Hadoop 是一个开源的分布式存储和计算框架,旨在处理大规模数据集并提供高可靠性、高性能的数据处理能力。它主要包括以下几个核心组件: Hadoop 分布式文件系统(HDFS):HDFS 是 Hadoop 的分布…...

使用dockerfile快速构建一个带ssh的docker镜像
不多说先给代码 FROM ubuntu:22.04 # 基础镜像 可替换为其他镜像 USER root RUN echo root:root |chpasswd RUN apt-get update -y \&& apt-get install -y git wget curl RUN apt-get install -y openssh-server vim && apt clean \&& rm -rf /tmp/…...
linux部署运维1——centos7.9离线安装部署涛思taos2.6时序数据库TDengine
在实际项目开发过程中,并非一直都使用关系型数据库,对于工业互联网类型的项目来说,时序型数据库也是很重要的一种,因此掌握时序数据库的安装配置也是必要的技能,不过对于有关系型数据库使用的开发工作者来说࿰…...

Linux shell编程学习笔记51: cat /proc/cpuinfo:查看CPU详细信息
0 前言 2024年的网络安全检查又开始了,对于使用基于Linux的国产电脑,我们可以编写一个脚本来收集系统的有关信息。对于中央处理器CPU比如,我们可以使用cat /proc/cpuinfo命令来收集中央处理器CPU的信息。 1. /proc/cpuinfo 保存了系统的cpu…...

Ps:调整画笔工具
调整画笔工具 Adjustment Brush Tool可以将选区、创建蒙版和应用调整的传统工作流程合并为一个步骤,简化了对图像进行非破坏性局部调整的操作。 快捷键:B 调整画笔工具是 Photoshop 2024 年 5 月版(25.9 版)新增的工具。 ◆ ◆ …...
香橙派 AIpro上手体验并验证车道线识别算法
香橙派 AIpro上手体验并验证车道线识别算法 1.前言 最近入手了一块香橙派AIpro,体验了一下,感觉还不错,在这里分享给大家,大家可以做个参考。 2.开箱 整套产品包含一块主板、一个电源插头和一条双端Type-C的数据线,…...

为啥装了erlang,还报错erl: command not found?
转载说明:如果您喜欢这篇文章并打算转载它,请私信作者取得授权。感谢您喜爱本文,请文明转载,谢谢。 问题背景: 在一台不通外网的服务器上装rabbitmq,然后在启动的时候,遇到了报错 “/usr/lib/…...

容器技术基础理论与常用命令:必知必会,效率翻倍!
如何利用容器技术提升你的工作效率?掌握基础理论和常用命令是必不可少的,本文将为你全面介绍容器技术,并教你必知必会的技能,让你工作、学习效率翻倍,对于网络安全工作者也是必不可少的技能! 0. 引言 学习…...

ChatGPT Edu版本来啦:支持GPT-4o、自定义GPT、数据分析等
5月31日,OpenAI在官网宣布,推出ChatGPT Edu版本。 据悉,这是一个专门为大学校园提供的ChatGTP,支持GPT-4o、网络搜索、自定义GPT、数据分析、代码生成等功能,可以极大提升学生、老师的学习质量和教学效率。 目前&…...

Spark RDD案例
Apache Spark中的RDD(Resilient Distributed Dataset)是一个不可变、分布式对象集合,它允许用户在大型集群上执行并行操作。虽然RDD在Spark的早期版本中非常核心,但随着DataFrame和Dataset的引入,RDD的使用在某些场景下…...

【线性表 - 数组和矩阵】
数组是一种连续存储线性结构,元素类型相同,大小相等,数组是多维的,通过使用整型索引值来访问他们的元素,数组尺寸不能改变。 知识点数组与矩阵相关题目 # 知识点 数组的优点: 存取速度快 数组的缺点: 事先必须知道…...

Springboot 开发 -- 跨域问题技术详解
一、跨域的概念 跨域访问问题指的是在客户端浏览器中,由于安全策略的限制,不允许从一个源(域名、协议、端口)直接访问另一个源的资源。当浏览器发起一个跨域请求时,会被浏览器拦截,并阻止数据的传输。 这…...
)
【Qt】之【项目】整理可参考学习的git项目链接(持续更新)
Tcp 通信相关 IM即时通讯设计 高并发聊天服务:服务器 qt客户端(附源码) - DeRoy - 博客园 未使用protobuf通讯协议格式 github:GitHub - ADeRoy/chat_room: IM即时通讯设计 高并发聊天服务:服务器 qt客户端 QT编…...

2024年5月个人工作生活总结
本文为 2024年5月工作生活总结。 研发编码 golang 多个defer函数执行顺序 golang 函数中如有多个defer,倒序执行。示例代码: func foo() {defer func() {fmt.Println("111")}()defer func() {fmt.Println("2222")}()defer func()…...
Kafka Java API
1、增加依赖 <dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>1.0.0</version> </dependency>2、三个案例 案例1:生产数据 import org.apache.kafka.clients.p…...

pushd: not found
解决方法: pushd 比 cd 命令更高效的切换命令,非默认,可在脚本开头添加: #! /bin/bash ubuntu 编译时出现/bin/sh: 1: pushd: not found的问题-CSDN博客...
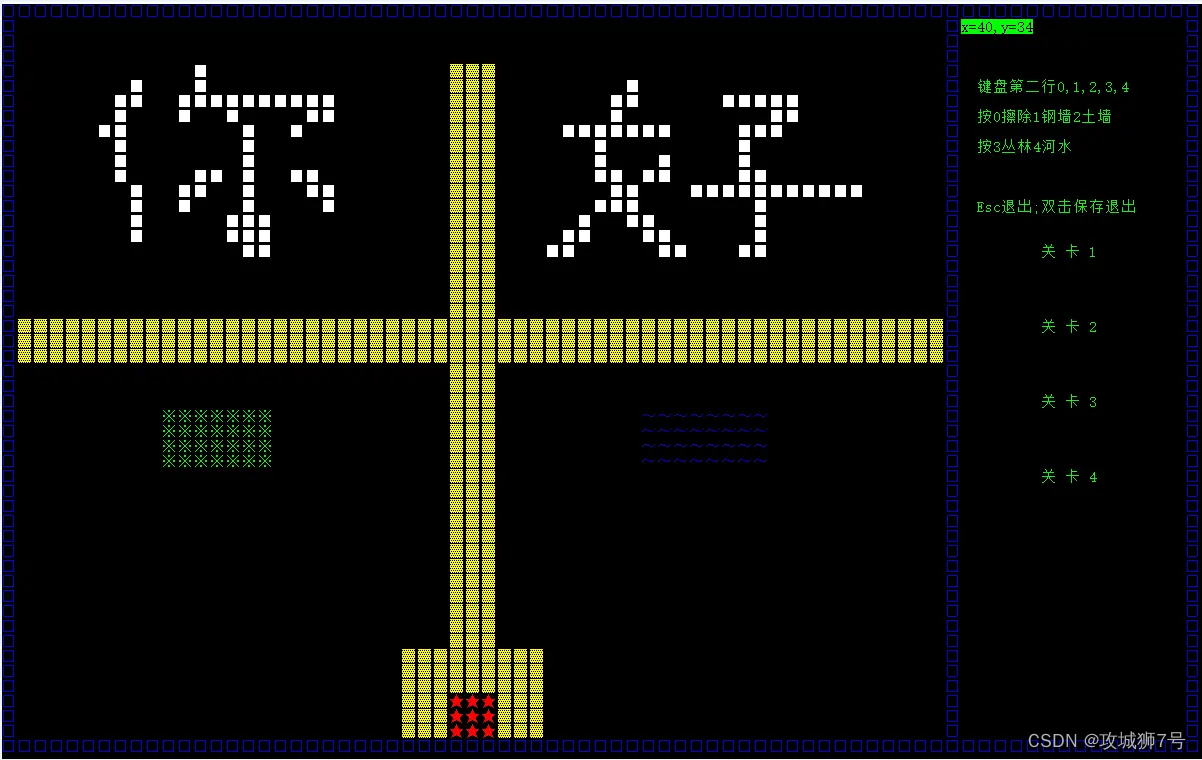
【第十三节】C++控制台版本坦克大战小游戏
目录 一、游戏简介 1.1 游戏概述 1.2 知识点应用 1.3 实现功能 1.4 开发环境 二、项目设计 2.1 类的设计 2.2 各类功能 三、程序运行截图 3.1 游戏主菜单 3.2 游戏进行中 3.3 双人作战 3.4 编辑地图 一、游戏简介 1.1 游戏概述 本项目是一款基于C语言开发的控制台…...
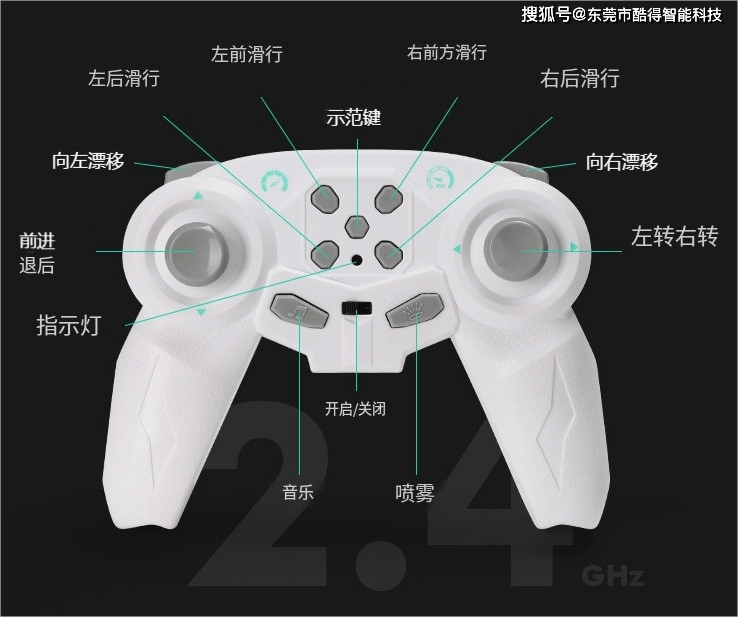
酷得单片机方案 2.4G儿童遥控漂移车
电子方案开发定制,我们是专业的 东莞酷得智能单片机方案之2.4G遥控玩具童车具有以下比较有特色的特点: 1、内置充电电池:这款小车配备了可充电的电池,无需频繁更换电池,既环保又方便。充电方式可能为USB充电或者专用…...

【为什么 Google Chrome 打开网页有时极慢?尤其是国内网站,如知网等】
要通过知网搜一点资料,发现怎么都打不开。而且B站,知乎这些速度也变慢了!已经检查过确定不是网络的问题。 清空了记录,清空了已接受Cookie,清空了缓存内容……没用!!! 不断搜索&am…...

FastAPI - 数据库操作5
先安装mysql驱动程序 pipenv install pymysql安装数据库ORM库SQLAlchemy pipenv install SQLAlchemy修改文件main.py文件内容 设置数据库连接 # -*- coding:utf-8 –*- from fastapi import FastAPIfrom sqlalchemy import create_engineHOST 192.168.123.228 PORT 3306 …...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

Python ROS2【机器人中间件框架】 简介
销量过万TEEIS德国护膝夏天用薄款 优惠券冠生园 百花蜂蜜428g 挤压瓶纯蜂蜜巨奇严选 鞋子除臭剂360ml 多芬身体磨砂膏280g健70%-75%酒精消毒棉片湿巾1418cm 80片/袋3袋大包清洁食品用消毒 优惠券AIMORNY52朵红玫瑰永生香皂花同城配送非鲜花七夕情人节生日礼物送女友 热卖妙洁棉…...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...