NLP(20)--知识图谱+实体抽取
前言
仅记录学习过程,有问题欢迎讨论
基于LLM的垂直领域问答方案:
- 特点:不是通用语料;准确度要求高,召回率可以低(转人工);拓展性和可控性(改变特定内容的回答);确切的评价指标
实现:
传统方法:
- 知识库+文本匹配 (问题转向量找知识库的相似度最高的问题来回答)
基于LLM:
1.直接生成:
- 直接使用LLM获答案,然后使用SFT微调
- 缺点:fine-tune的成本高;模型的泛用性下降;不易调整数据
2.RAG思路(推荐):
- 段落召回+阅读理解(基于获取的信息给模型提示,期望获取一个更好的答案)
- 召回的就是你垂直领域的内容,去给llm提示
- 缺点:对LLM要求高,受召回算法限制(如果正确答案被丢弃,LLM无法挽回);生成结果不可控
3.基于知识体系(图谱)
- 树形结构设置知识体系结构,然后给LLM去匹配最可能的知识点选择项,一级一级往下走
- 缺点:需要大量标注数据,标注数据需要人工标注,标注成本高
知识图谱:
- 知识图谱是图数据库的一种,用于存储和表示知识。
- 如:姚明-身高-226cm(三元组)
- 知识图谱的构建取决于你想要完成的任务,如果想要获取实体之间的关系,就要构建实体关系的图谱
以下为知识图谱的具体内容:
实体抽取:ner任务获取实体属性
关系抽取:
- 限定领域:
- 文本+实体送入模型 预测关系(本质还是分类任务)
- 可以同时训练实体抽取和关系抽取,loss为二者相加
- 开放领域:
基于序列标注 (NER)
属性抽取:同关系抽取
知识融合:
- 实体对齐:通过判断不同来源的属性的相似度
- 实体消歧:根据上下文和语义关系进行实体消歧
- 属性对齐:属性和属性值的相似度计算
知识推理:通过模型来推断两个实体的关系
知识表示:实体关系属性都转化为向量,都可以用id表示某个信息
图数据库的使用:
noe4j
使用NL2SQL把输入的文字变为sql查询
- 方法1:基于模版+文本匹配,输入的文本去匹配对应的问题模版–再去匹配SQL(依赖模版,易于拓展,可以写复杂sql)
- 方法2:semantic parsing(语义解析)–通过训练多个模型来获取sql(不易于拓展)
- 方法3:用LLM写sql
代码展示
构建基于neo4j的知识图谱问答:
这里采用的是方法1,依赖问题模版。
import re
import json
import pandas
import itertools
from py2neo import Graph"""
使用neo4j 构建基于知识图谱的问答
需要自定义问题模板
"""class GraphQA:def __init__(self):# 启动neo4j neo4j consoleself.graph = Graph("http://localhost:7474", auth=("neo4j", "password"))schema_path = "kg_schema.json"templet_path = "question_templet.xlsx"self.load(schema_path, templet_path)print("知识图谱问答系统加载完毕!\n===============")# 对外提供问答接口def query(self, sentence):print("============")print(sentence)# 对输入的句子找和模板中最匹配的问题info = self.parse_sentence(sentence) # 信息抽取print("info:", info)# 匹配模板templet_cypher_score = self.cypher_match(sentence, info) # cypher匹配for templet, cypher, score, answer in templet_cypher_score:graph_search_result = self.graph.run(cypher).data()# 最高分命中的模板不一定在图上能找到答案, 当不能找到答案时,运行下一个搜索语句, 找到答案时停止查找后面的模板if graph_search_result:answer = self.parse_result(graph_search_result, answer)return answerreturn None# 加载模板def load(self, schema_path, templet_path):self.load_kg_schema(schema_path)self.load_question_templet(templet_path)return# 加载模板信息def load_question_templet(self, templet_path):dataframe = pandas.read_excel(templet_path)self.question_templet = []for index in range(len(dataframe)):question = dataframe["question"][index]cypher = dataframe["cypher"][index]cypher_check = dataframe["check"][index]answer = dataframe["answer"][index]self.question_templet.append([question, cypher, json.loads(cypher_check), answer])return# 返回输入中的实体,关系,属性def parse_sentence(self, sentence):# 先提取实体,关系,属性entitys = self.get_mention_entitys(sentence)relations = self.get_mention_relations(sentence)labels = self.get_mention_labels(sentence)attributes = self.get_mention_attributes(sentence)# 然后根据模板进行匹配return {"%ENT%": entitys,"%REL%": relations,"%LAB%": labels,"%ATT%": attributes}# 获取问题中谈到的实体,可以使用基于词表的方式,也可以使用NER模型def get_mention_entitys(self, sentence):return re.findall("|".join(self.entity_set), sentence)# 获取问题中谈到的关系,也可以使用各种文本分类模型def get_mention_relations(self, sentence):return re.findall("|".join(self.relation_set), sentence)# 获取问题中谈到的属性def get_mention_attributes(self, sentence):return re.findall("|".join(self.attribute_set), sentence)# 获取问题中谈到的标签def get_mention_labels(self, sentence):return re.findall("|".join(self.label_set), sentence)# 加载图谱信息def load_kg_schema(self, path):with open(path, encoding="utf8") as f:schema = json.load(f)self.relation_set = set(schema["relations"])self.entity_set = set(schema["entitys"])self.label_set = set(schema["labels"])self.attribute_set = set(schema["attributes"])return# 匹配模板的问题def cypher_match(self, sentence, info):# 根据提取到的实体,关系等信息,将模板展开成待匹配的问题文本templet_cypher_pair = self.expand_question_and_cypher(info)result = []for templet, cypher, answer in templet_cypher_pair:# 求相似度 距离函数score = self.sentence_similarity_function(sentence, templet)# print(sentence, templet, score)result.append([templet, cypher, score, answer])# 取最相似的result = sorted(result, reverse=True, key=lambda x: x[2])return result# 根据提取到的实体,关系等信息,将模板展开成待匹配的问题文本def expand_question_and_cypher(self, info):templet_cypher_pair = []# 模板的数据for templet, cypher, cypher_check, answer in self.question_templet:# 匹配模板cypher_check_result = self.match_cypher_check(cypher_check, info)if cypher_check_result:templet_cypher_pair += self.expand_templet(templet, cypher, cypher_check, info, answer)return templet_cypher_pair# 校验 减少比较次数def match_cypher_check(self, cypher_check, info):for key, required_count in cypher_check.items():if len(info.get(key, [])) < required_count:return Falsereturn True# 对于单条模板,根据抽取到的实体属性信息扩展,形成一个列表# info:{"%ENT%":["周杰伦", "方文山"], “%REL%”:[“作曲”]}def expand_templet(self, templet, cypher, cypher_check, info, answer):# 获取所有组合combinations = self.get_combinations(cypher_check, info)templet_cpyher_pair = []for combination in combinations:# 替换模板中的实体,属性,关系replaced_templet = self.replace_token_in_string(templet, combination)replaced_cypher = self.replace_token_in_string(cypher, combination)replaced_answer = self.replace_token_in_string(answer, combination)templet_cpyher_pair.append([replaced_templet, replaced_cypher, replaced_answer])return templet_cpyher_pair# 对于找到了超过模板中需求的实体数量的情况,需要进行排列组合# info:{"%ENT%":["周杰伦", "方文山"], “%REL%”:[“作曲”]}def get_combinations(self, cypher_check, info):slot_values = []for key, required_count in cypher_check.items():# 生成所有组合slot_values.append(itertools.combinations(info[key], required_count))value_combinations = itertools.product(*slot_values)combinations = []for value_combination in value_combinations:combinations.append(self.decode_value_combination(value_combination, cypher_check))return combinations# 将提取到的值分配到键上def decode_value_combination(self, value_combination, cypher_check):res = {}for index, (key, required_count) in enumerate(cypher_check.items()):if required_count == 1:res[key] = value_combination[index][0]else:for i in range(required_count):key_num = key[:-1] + str(i) + "%"res[key_num] = value_combination[index][i]return res# 将带有token的模板替换成真实词# string:%ENT1%和%ENT2%是%REL%关系吗# combination: {"%ENT1%":"word1", "%ENT2%":"word2", "%REL%":"word"}def replace_token_in_string(self, string, combination):for key, value in combination.items():string = string.replace(key, value)return string# 求相似度 距离函数 Jaccard相似度def sentence_similarity_function(self, sentence1, sentence2):# print("计算 %s %s"%(string1, string2))jaccard_distance = len(set(sentence1) & set(sentence2)) / len(set(sentence1) | set(sentence2))return jaccard_distance# 解析结果def parse_result(self, graph_search_result, answer):graph_search_result = graph_search_result[0]# 关系查找返回的结果形式较为特殊,单独处理if "REL" in graph_search_result:graph_search_result["REL"] = list(graph_search_result["REL"].types())[0]answer = self.replace_token_in_string(answer, graph_search_result)return answerif __name__ == '__main__':graph = GraphQA()res = graph.query("谁导演的不能说的秘密")print(res)res = graph.query("发如雪的谱曲是谁")print(res)代码2
通过联合训练同时实现 属性和实体(关系)的抽取
config
"""
配置参数信息
"""
Config = {"model_path": "./output/","model_name": "model.pt","schema_path": r"schema.json","train_data_path": r"D:\NLP\video\第十四周\week13 知识问答\triplet_data\train_triplet_data.json","valid_data_path": r"D:\NLP\video\第十四周\week13 知识问答\triplet_data\valid_triplet_data.json","vocab_path": r"D:\NLP\video\第九周 序列标注任务\课件\week9 序列标注问题\ner\chars.txt","model_type": "lstm",# 文本向量大小"char_dim": 20,# 文本长度"max_len": 200,# 词向量大小"hidden_size": 64,# 训练 轮数"epoch_size": 15,# 批量大小"batch_size": 32,# 训练集大小"simple_size": 500,# 学习率"lr": 1e-3,# dropout"dropout": 0.5,# 优化器"optimizer": "adam",# 卷积核"kernel_size": 3,# 最大池 or 平均池"pooling_style": "avg",# 模型层数"num_layers": 3,"bert_model_path": r"D:\NLP\video\第六周\bert-base-chinese",# 输出层大小"output_size": 9,# 随机数种子"seed": 987,"attribute_loss_ratio": 0.01
}loader
"""
数据加载
"""
import os
import numpy as np
import json
import re
import os
import torch
import torch.utils.data as Data
from torch.utils.data import Dataset, DataLoader
from transformers import BertTokenizer# 获取字表集
def load_vocab(path):vocab = {}with open(path, 'r', encoding='utf-8') as f:for index, line in enumerate(f):word = line.strip()# 0留给padding位置,所以从1开始vocab[word] = index + 1vocab['unk'] = len(vocab) + 1return vocabclass DataGenerator:def __init__(self, data_path, config):self.data_path = data_pathself.config = configself.schema = self.load_schema(config["schema_path"])if self.config["model_type"] == "bert":self.tokenizer = BertTokenizer.from_pretrained(config["bert_model_path"])self.vocab = load_vocab(config["vocab_path"])self.config["vocab_size"] = len(self.vocab)self.max_len = config["max_len"]# 实体标签self.bio_schema = {"B_object": 0,"I_object": 1,"B_value": 2,"I_value": 3,"O": 4}self.config["label_count"] = len(self.bio_schema)self.config["attribute_count"] = len(self.schema)# 中文的语句list# self.sentence_list = []self.load_data()def __len__(self):return len(self.data)def __getitem__(self, idx):return self.data[idx]def load_schema(self, path):with open(path, encoding="utf8") as f:return json.load(f)def load_data(self):# 储存实体数据 测试使用self.text_data = []# 处理完的数据self.data = []# 是否超长self.exceed_max_length = 0with open(self.data_path, 'r', encoding='utf-8') as f:for line in f:data = json.loads(line.strip())# 文本sentence = data["context"]# 获取实体object = data["object"]attribute = data["attribute"]value = data["value"]if attribute not in self.schema:attribute = "UNRELATED"self.text_data.append([sentence, object, attribute, value])input_id, attribute_label, sentence_label = self.process_sentence(sentence, object, attribute, value)self.data.append([torch.LongTensor(input_id),torch.LongTensor([attribute_label]),torch.LongTensor(sentence_label)])return data# 文本预处理# 转化为向量def sentence_to_index(self, text):input_ids = []vocab = self.vocabif self.config["model_type"] == "bert":# 中文的文本转化为tokenizer的idinput_ids = self.tokenizer.encode(text, padding="max_length", truncation=True,max_length=self.config["max_len"], add_special_tokens=False)else:for char in text:input_ids.append(vocab.get(char, vocab['unk']))# 填充or裁剪input_ids = self.padding(input_ids)return input_ids# 数据预处理 裁剪or填充def padding(self, input_ids, padding_dot=0):length = self.config["max_len"]padded_input_ids = input_idsif len(input_ids) >= length:return input_ids[:length]else:padded_input_ids += [padding_dot] * (length - len(input_ids))return padded_input_ids# 处理数据def process_sentence(self, sentence, object, attribute, value):if len(sentence) > self.max_len:self.exceed_max_length += 1object_start = sentence.index(object)value_start = sentence.index(value)# 文本转向量input_id = self.sentence_to_index(sentence)# 属性转向量attribute_index = self.schema[attribute]# assert len(sentence) == len(input_id)# 构建实体和属性标签 在一句话中 一个变量就可以 初始化要用 Olabel = [self.bio_schema["O"]] * len(input_id)# print(sentence,"======",object,"=====",object_start)if object_start < self.max_len:label[object_start] = self.bio_schema["B_object"]# 标记实体for index in range(object_start + 1, object_start + len(object)):if index >= self.max_len:breaklabel[index] = self.bio_schema["I_object"]# 标记属性if value_start < self.max_len:label[value_start] = self.bio_schema["B_value"]for index in range(value_start + 1, value_start + len(value)):if index >= self.max_len:breaklabel[index] = self.bio_schema["I_value"]if len(input_id) != len(label):label = self.padding(label, -1)return input_id, attribute_index, label# 用torch自带的DataLoader类封装数据
def load_data_batch(data_path, config, shuffle=True):dg = DataGenerator(data_path, config)# DataLoader 类封装数据 dg除了data 还包含其他信息(后面需要使用)dl = DataLoader(dg, batch_size=config["batch_size"], shuffle=shuffle)return dlif __name__ == '__main__':from config import Configdg = DataGenerator(Config["train_data_path"], Config)print(len(dg))print(dg[0])model
import torch
import torch.nn as nn
from torch.optim import Adam, SGD
from transformers import BertModel
from torchcrf import CRF"""
建立网络模型结构
"""class TorchModel(nn.Module):def __init__(self, config):super(TorchModel, self).__init__()hidden_size = config["hidden_size"]vocab_size = config["vocab_size"] + 1output_size = config["output_size"]self.model_type = config["model_type"]num_layers = config["num_layers"]self.pooling_style = config["pooling_style"]# self.use_bert = config["use_bert"]# self.use_crf = config["use_crf"]self.emb = nn.Embedding(vocab_size + 1, hidden_size, padding_idx=0)if self.model_type == 'rnn':self.encoder = nn.RNN(input_size=hidden_size, hidden_size=hidden_size, num_layers=num_layers,batch_first=True)elif self.model_type == 'lstm':# 双向lstm,输出的是 hidden_size * 2(num_layers 要写2)self.encoder = nn.LSTM(hidden_size, hidden_size, num_layers=num_layers, bidirectional=True,batch_first=True)hidden_size = hidden_size * 2elif self.model_type == 'bert':self.encoder = BertModel.from_pretrained(config["bert_model_path"])# 需要使用预训练模型的hidden_sizehidden_size = self.encoder.config.hidden_sizeelif self.model_type == 'cnn':self.encoder = CNN(config)elif self.model_type == "gated_cnn":self.encoder = GatedCNN(config)elif self.model_type == "bert_lstm":self.encoder = BertLSTM(config)# 需要使用预训练模型的hidden_sizehidden_size = self.encoder.config.hidden_size# self.classify = nn.Linear(hidden_size, output_size)# 实体的分类输出self.bio_classifier = nn.Linear(hidden_size, config["label_count"])# 属性的分类输出self.attribute_classifier = nn.Linear(hidden_size, config["attribute_count"])self.pooling_style = config["pooling_style"]# self.crf_layer = CRF(output_size, batch_first=True)# 一起计算loss的权重self.attribute_loss_ratio = config["attribute_loss_ratio"]self.loss = torch.nn.CrossEntropyLoss(ignore_index=-1) # loss采用交叉熵损失def forward(self, x, attribute_target=None, bio_target=None):if self.model_type == 'bert':# 输入x为[batch_size, seq_len]# bert返回的结果是 (sequence_output, pooler_output)# sequence_output:batch_size, max_len, hidden_size# pooler_output:batch_size, hidden_sizex = self.encoder(x)[0]else:x = self.emb(x)x = self.encoder(x)# 判断x是否是tupleif isinstance(x, tuple):x = x[0]# 序列标注(单个字)bio_predict = self.bio_classifier(x) # (batch_size, max_length, 5) (Head-B, Head-I, Tail-B, Tail-I, O)# 文本分类# 池化层if self.pooling_style == "max":# shape[1]代表列数,shape是行和列数构成的元组self.pooling_style = nn.MaxPool1d(x.shape[1])elif self.pooling_style == "avg":self.pooling_style = nn.AvgPool1d(x.shape[1])x = self.pooling_style(x.transpose(1, 2)).squeeze()# 属性分类attribute_predict = self.attribute_classifier(x)if bio_target is not None:bio_loss = self.loss(bio_predict.view(-1, bio_predict.shape[-1]), bio_target.view(-1))# attribute_loss = self.loss(attribute_predict, attribute_target.view(-1))attribute_loss = self.loss(attribute_predict.view(x.shape[0], -1), attribute_target.view(-1))return bio_loss + self.attribute_loss_ratio * attribute_losselse:return attribute_predict, bio_predict# 优化器的选择
def choose_optimizer(config, model):optimizer = config["optimizer"]learning_rate = config["lr"]if optimizer == "adam":return Adam(model.parameters(), lr=learning_rate)elif optimizer == "sgd":return SGD(model.parameters(), lr=learning_rate)# 定义CNN模型
class CNN(nn.Module):def __init__(self, config):super(CNN, self).__init__()hidden_size = config["hidden_size"]kernel_size = config["kernel_size"]pad = int((kernel_size - 1) / 2)self.cnn = nn.Conv1d(hidden_size, hidden_size, kernel_size, bias=False, padding=pad)def forward(self, x): # x : (batch_size, max_len, embeding_size)return self.cnn(x.transpose(1, 2)).transpose(1, 2)# 定义GatedCNN模型
class GatedCNN(nn.Module):def __init__(self, config):super(GatedCNN, self).__init__()self.cnn = CNN(config)self.gate = CNN(config)# 定义前向传播函数 比普通cnn多了一次sigmoid 然后互相卷积def forward(self, x):a = self.cnn(x)b = self.gate(x)b = torch.sigmoid(b)return torch.mul(a, b)# 定义BERT-LSTM模型
class BertLSTM(nn.Module):def __init__(self, config):super(BertLSTM, self).__init__()self.bert = BertModel.from_pretrained(config["bert_model_path"], return_dict=False)self.rnn = nn.LSTM(self.bert.config.hidden_size, self.bert.config.hidden_size, batch_first=True)def forward(self, x):x = self.bert(x)[0]x, _ = self.rnn(x)return x# if __name__ == "__main__":
# from config import Config
#
# Config["output_size"] = 2
# Config["vocab_size"] = 20
# Config["max_length"] = 5
# Config["model_type"] = "bert"
# Config["use_bert"] = True
# # model = BertModel.from_pretrained(Config["bert_model_path"], return_dict=False)
# x = torch.LongTensor([[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]])
# # sequence_output, pooler_output = model(x)
# # print(x[1], type(x[2]), len(x[2]))
#
# model = TorchModel(Config)
# label = torch.LongTensor([0,1])
# print(model(x, label))main
# -*- coding: utf-8 -*-
import reimport torch
import os
import random
import os
import numpy as np
import logging
from config import Config
from model import TorchModel, choose_optimizer
from loader import load_data_batch
from evaluate import Evaluator# [DEBUG, INFO, WARNING, ERROR, CRITICAL]logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)"""
模型训练主程序
"""
# 通过设置随机种子来复现上一次的结果(避免随机性)
seed = Config["seed"]
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)def main(config):# 保存模型的目录if not os.path.isdir(config["model_path"]):os.mkdir(config["model_path"])# 加载数据dataset = load_data_batch(config["train_data_path"], config)# 加载模型model = TorchModel(config)# 是否使用gpuif torch.cuda.is_available():logger.info("gpu可以使用,迁移模型至gpu")model.cuda()# 选择优化器optim = choose_optimizer(config, model)# 加载效果测试类evaluator = Evaluator(config, model, logger)for epoch in range(config["epoch_size"]):epoch += 1logger.info("epoch %d begin" % epoch)epoch_loss = []# 训练模型model.train()for index, batch_data in enumerate(dataset):if torch.cuda.is_available():batch_data = [d.cuda() for d in batch_data]# x, y = dataiter# 反向传播optim.zero_grad()input_id, attribute_index, label = batch_data # 输入变化时这里需要修改,比如多输入,多输出的情况# 计算梯度loss = model(input_id, attribute_index,label)# 梯度更新loss.backward()# 优化器更新模型optim.step()# 记录损失epoch_loss.append(loss.item())logger.info("epoch average loss: %f" % np.mean(epoch_loss))# 测试模型效果evaluator.eval(epoch)model_path = os.path.join(config["model_path"], "epoch_%d.pth" % epoch)torch.save(model.state_dict(), model_path)return model, datasetif __name__ == "__main__":main(Config)evaluate
"""
模型效果测试
"""
import re
from collections import defaultdictimport numpy as np
import torch
from loader import load_data_batchclass Evaluator:def __init__(self, config, model, logger):self.config = configself.model = modelself.logger = logger# 选择验证集合self.dataset = load_data_batch(config["valid_data_path"], config, shuffle=False)# 获取loader时的字符集self.bio_schema = self.dataset.dataset.bio_schemaself.attribute_schema = self.dataset.dataset.schemaself.text_data = self.dataset.dataset.text_data# 将index转换为标签self.index_to_label = dict((y, x) for x, y in self.attribute_schema.items())def eval(self, epoch):self.logger.info("开始测试第%d轮模型效果:" % epoch)# 测试模式self.model.eval()self.stats_dict = {"object_acc": 0, "attribute_acc": 0, "value_acc": 0, "full_match_acc": 0}# 遍历验证集for index, batch_data in enumerate(self.dataset):# 分割为一个batch 因为text_data是没分割batch的 所以评估数据集shuffle = Falsetext_data = self.text_data[index * self.config["batch_size"]: (index + 1) * self.config["batch_size"]]if torch.cuda.is_available():batch_data = [d.cuda() for d in batch_data]# 这里只取input_id (32*200)input_id = batch_data[0] # 输入变化时这里需要修改,比如多输入,多输出的情况with torch.no_grad():attribute_pred, bio_pred = self.model(input_id) # 不输入labels,使用模型当前参数进行预测self.write_stats(attribute_pred, bio_pred, text_data)self.show_stats()returndef write_stats(self, attribute_pred, bio_pred, text_data):attribute_pred = torch.argmax(attribute_pred, dim=-1)bio_pred = torch.argmax(bio_pred, dim=-1)for attribute_p, bio_p, info in zip(attribute_pred, bio_pred, text_data):context, object, attribute, value = infobio_p = bio_p.cpu().detach().tolist()# 获取实体的预测值pred_object, pred_value = self.decode1(bio_p, context)# 获取属性的预测值pred_attribute = self.index_to_label[int(attribute_p)]self.stats_dict["object_acc"] += int(pred_object == object)self.stats_dict["attribute_acc"] += int(pred_attribute == attribute)self.stats_dict["value_acc"] += int(pred_value == value)if pred_value == value and pred_attribute == attribute and pred_object == object:self.stats_dict["full_match_acc"] += 1return# 打印结果def show_stats(self):for key, value in self.stats_dict.items():self.logger.info("%s : %s " % (key, value / len(self.text_data)))self.logger.info("--------------------")return# 相当于截取对应的句子def decode1(self, labels, sentence):labels = "".join([str(i) for i in labels])pred_obj, pred_value = "", ""# * 表示0 or d多个for location in re.finditer("(01*)", labels):s, e = location.span()pred_obj = sentence[s:e]breakfor location in re.finditer("(23*)", labels):s, e = location.span()pred_value = sentence[s:e]breakreturn pred_obj, pred_valuedef decode(self, pred_label, context):pred_label = "".join([str(i) for i in pred_label])pred_obj = self.seek_pattern("01*", pred_label, context)pred_value = self.seek_pattern("23*", pred_label, context)return pred_obj, pred_valuedef seek_pattern(self, pattern, pred_label, context):pred_obj = re.search(pattern, pred_label)if pred_obj:s, e = pred_obj.span()pred_obj = context[s:e]else:pred_obj = ""return pred_objpredict
# -*- coding: utf-8 -*-
import torch
import re
import json
import numpy as np
from collections import defaultdict
from config import Config
from model import TorchModel"""
模型效果测试
"""class SentenceLabel:def __init__(self, config, model_path):self.config = configself.bio_schema = {"B_object": 0,"I_object": 1,"B_value": 2,"I_value": 3,"O": 4}self.attribute_schema = json.load(open(config["schema_path"], encoding="utf8"))self.index_to_label = dict((y, x) for x, y in self.attribute_schema.items())self.config["label_count"] = len(self.bio_schema)self.config["attribute_count"] = len(self.attribute_schema)self.vocab = self.load_vocab(config["vocab_path"])self.config["vocab_size"] = len(self.vocab)self.model = TorchModel(config)self.model.load_state_dict(torch.load(model_path))self.model.eval()print("模型加载完毕!")# 加载字表或词表def load_vocab(self, path):vocab = {}with open(path, 'r', encoding='utf-8') as f:for index, line in enumerate(f):word = line.strip()# 0留给padding位置,所以从1开始vocab[word] = index + 1vocab['unk'] = len(vocab) + 1return vocabdef decode(self, attribute_label, bio_label, context):pred_attribute = self.index_to_label[int(attribute_label)]bio_label = "".join([str(i) for i in bio_label.detach().tolist()])pred_obj = self.seek_pattern("01*", bio_label, context)pred_value = self.seek_pattern("23*", bio_label, context)return pred_obj, pred_attribute, pred_valuedef seek_pattern(self, pattern, pred_label, context):pred_obj = re.search(pattern, pred_label)if pred_obj:s, e = pred_obj.span()pred_obj = context[s:e]else:pred_obj = ""return pred_objdef predict(self, sentence):input_id = []for char in sentence:input_id.append(self.vocab.get(char, self.vocab["[UNK]"]))with torch.no_grad():attribute_pred, bio_pred = self.model(torch.LongTensor([input_id]))attribute_pred = torch.argmax(attribute_pred)bio_pred = torch.argmax(bio_pred[0], dim=-1)object, attribute, value = self.decode(attribute_pred, bio_pred, sentence)return object, attribute, valueif __name__ == "__main__":sl = SentenceLabel(Config, "output/epoch_15.pth")sentence = "浙江理工大学是一所以工为主,特色鲜明,优势突出,理、工、文、经、管、法、艺术、教育等多学科协调发展的省属重点建设大学。"res = sl.predict(sentence)print(res)sentence = "出露地层的岩石以沉积岩为主(其中最多为碳酸盐岩),在受到乌江的切割下,由内外力共同作用,形成沟壑密布、崎岖复杂的地貌景观。"res = sl.predict(sentence)print(res)相关文章:
--知识图谱+实体抽取)
NLP(20)--知识图谱+实体抽取
前言 仅记录学习过程,有问题欢迎讨论 基于LLM的垂直领域问答方案: 特点:不是通用语料;准确度要求高,召回率可以低(转人工);拓展性和可控性(改变特定内容的回答…...

【mysql数据库】mycat中间件
MyCat 简介 Mycat 是数据库 中间件 。 1、 数据库中间件 中间件 是一类连接软件组件和应用的计算机软件, 以便于软件各部件之间的沟通 。 例子 Tomcat web 中间件 。 数据库 中间件 连接 java 应用程序和数据库 2、 为什么要用 Mycat ① Java 与数据库紧耦合 …...

满帮集团 Eureka 和 ZooKeeper 的上云实践
作者:胡安祥 满帮集团,作为“互联网物流”的平台型企业,一端承接托运人运货需求,另一端对接货车司机,提升货运物流效率。2021 年美股上市,成为数字货运平台上市第一股。根据公司年报,2021 年&a…...

ubuntu中彻底删除mysql (配置文件删除可选)
ubuntu中彻底删除mysql (配置文件删除可选) 对于此类即搜即用的分享文章,也不过多赘述,直接依次按照下面的操作执行即可: 一、删除 mysql 数据文件 sudo rm /var/lib/mysql/ -R二、删除 mysql 配置文件 sudo rm /etc/mysql/ -R三、查看 m…...

根据模板和git commit自动生成日·周·月·季报
GitHub - qiaotaizi/dailyreport: 日报生成器 GitHub - yurencloud/daily: 程序员专用的日报、周报、月报、季报自动生成器! config.json: { "Author": "gitname", "Exclude": ["update:", "add:", "…...

matlab GUI界面设计
【实验内容】 用MATLAB的GUI程序设计一个具备图像边缘检测功能的用户界面,该设计程序有以下基本功能: (1)图像的读取和保存。 (2)设计图形用户界面,让用户对图像进行彩色图像到灰度图像的转换…...

MyBatis 面试题
一、什么是 Mybatis? 1、Mybatis 是一个半 ORM(对象关系映射)框架,它内部封装了 JDBC,开发时 只需要关注 SQL 语句本身,不需要花费精力去处理加载驱动、创建连接、创建 statement 等繁杂的过程。程序员直接编写原生态 sql,可以严格控制 sql 执行性 能,灵活度高。 …...
C#根据数据量自动排版标签的样例
这是一个C#根据数据量自动排版标签的样例 using System; using System.Collections.Generic; using System.Data.SqlClient; using System.Drawing; using System.Text; using System.Threading; using System.Threading.Tasks; using System.Windows.Forms; using HslCommuni…...

【网络安全】Web安全基础 - 第一节:使用软件及环境介绍
VMware VMware,是全球云基础架构和移动商务解决方案的佼佼者。 VMware可是一个总部位于美国加州帕洛阿尔托的计算机虚拟化软件研发与销售企业呢。简单来说,它就是通过提供虚拟化解决方案,让企业在数据中心改造和公有云整合业务上更加得心应…...
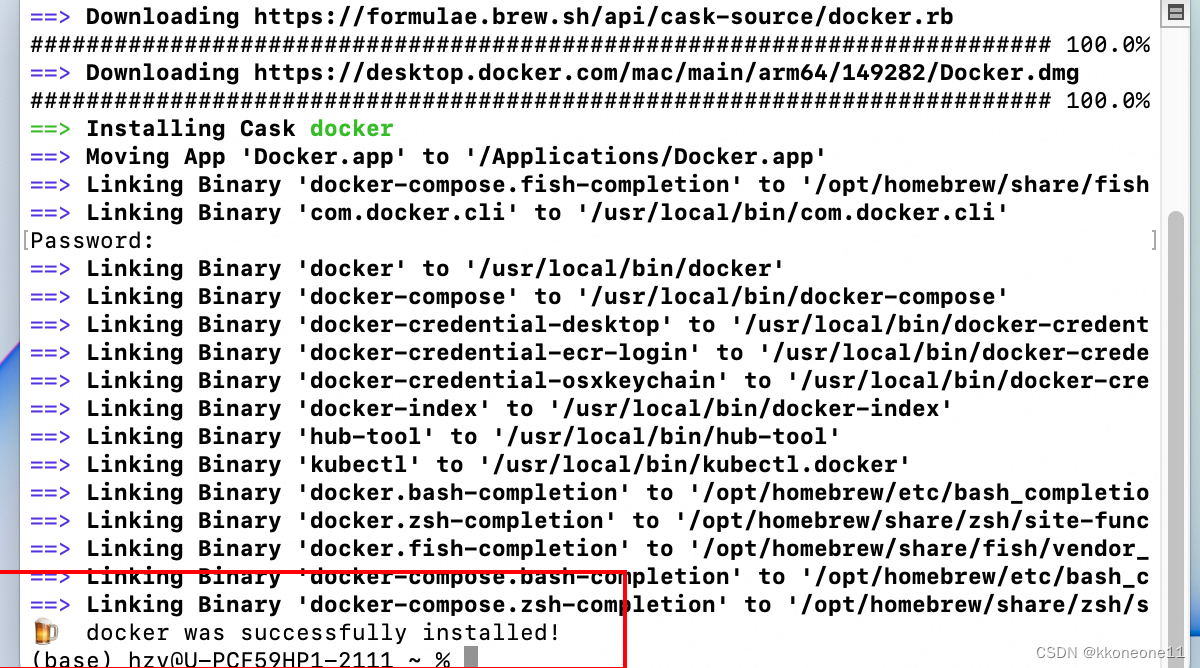
Mac下载docker
先安装homebrew Mac下载Homebrew-CSDN博客 然后输入以下命令安装docker brew install --cask --appdir/Applications docker 期间需要输入密码。输入完等待即可...

k8s_设置dns
配置k8s dns 在 Kubernetes 集群中,CoreDNS 是默认的 DNS 服务器,它负责处理集群内所有的 DNS 请求。 kubectl edit cm coredns -n kube-system (此命令修改coredns 配置) kubectl describe cm coredns -n kube-system(此命令查看coredns 配…...
翻译《The Old New Thing》- What a drag: Dragging a virtual file (HGLOBAL edition)
What a drag: Dragging a virtual file (HGLOBAL edition) - The Old New Thing (microsoft.com)https://devblogs.microsoft.com/oldnewthing/20080318-00/?p23083 Raymond Chen 2008年03月18日 拖拽虚拟文件(HGLOBAL 版本) 现在我们已经对简单的数据…...
SA316系列音频传输模块-传输距离升级音质不打折
SA316是思为无线研发的一款远距离音频传输模块,音频采样率为48K,传输距离可达200M。为了满足更多用户需求,思为无线在SA316基础上进一步增加传输距离推出SA316F30。相比SA316性能,同样其采用48K采样,-96dBm灵敏度&…...

【机器学习】智能选择的艺术:决策树在机器学习中的深度剖析
在机器学习的分类和回归问题中,决策树是一种广泛使用的算法。决策树模型因其直观性、易于理解和实现,以及处理分类和数值特征的能力而备受欢迎。本文将解释决策树算法的概念、原理、应用、优化方法以及未来的发展方向。 🚀时空传送门 &#x…...
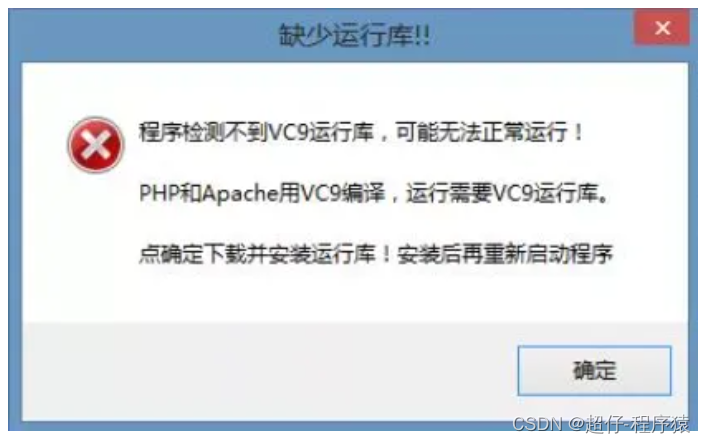
电脑缺少运行库,无法启动程序
在我们使用一些软件的时候,由于电脑缺少一些运行库,导致无法启动应用软件,此时需要我们安装缺少的运行库。 比如当电脑提示: Cannot load library Qt5Xlsx.dll 我们就需要下载C得运行库,以满足软件运行需要。 下载链…...

【计算机软考_初级篇】每日十题2
各位老师大家好,软考对于日常的知识储备和企业中的考试,或者说在校大学生来说,那用处是非常大的!!那么下面我们进入正题,软考呢是分两种语言,java和C,对于其他语言目前还没ÿ…...
HR人才测评,如何做营销人员岗位素质测评?
营销人员是企业中的重要角色,他们直接负责企业产品或服务的销售和推广,是企业中最直接影响销售业绩的人才之一。因此,营销人员的基本素质测评非常重要,能够有效评估营销人员的能力和潜力,为企业招聘和培养优秀的营销人…...
LabVIEW调用第三方硬件DLL常见问题及开发流程
在LabVIEW中调用第三方硬件DLL时,除了技术问题,还涉及开发流程、资料获取及与厂家的沟通协调。常见问题包括函数接口不兼容、数据类型转换错误、内存管理问题、线程安全性等。解决这些问题需确保函数声明准确、数据类型匹配、正确的内存管理及线程保护。…...

datax实现MySQL数据库迁移shell自动化脚本
datax实现MySQL数据库迁移 (1)生成python脚本 # codingutf-8 import json import getopt import os import sys import MySQLdb#MySQL相关配置,需根据实际情况作出修改 mysql_host "xxxx" mysql_port "3306" mysql_u…...
PostgreSQL的学习心得和知识总结(一百四十四)|深入理解PostgreSQL数据库之sendTuples的实现原理及功能修改
目录结构 注:提前言明 本文借鉴了以下博主、书籍或网站的内容,其列表如下: 1、参考书籍:《PostgreSQL数据库内核分析》 2、参考书籍:《数据库事务处理的艺术:事务管理与并发控制》 3、PostgreSQL数据库仓库…...

Leather Dress Collection 一键部署效果实测:开箱即用,快速验证模型生成质量
Leather Dress Collection 一键部署效果实测:开箱即用,快速验证模型生成质量 最近在星图GPU平台上闲逛,发现了一个名字挺有意思的镜像——Leather Dress Collection。这名字听起来不像个技术产品,倒像个时尚单品合集。出于好奇&a…...

嵌入式TFTP客户端实现与工业级加固策略
1. TFTP协议在嵌入式系统中的工程化实现与应用TFTP(Trivial File Transfer Protocol,简单文件传输协议)作为轻量级UDP-based文件传输协议,在嵌入式固件升级、配置文件加载、日志导出等场景中具有不可替代的工程价值。其RFC 1350定…...

Lychee模型在金融领域的应用:财报图文智能分析
Lychee模型在金融领域的应用:财报图文智能分析 1. 引言 金融分析师每天都要面对海量的财报文档,其中包含大量的表格、图表和文字说明。传统的人工分析方式不仅效率低下,还容易因为疲劳导致关键信息遗漏。一份典型的上市公司年报可能包含上百…...

SeqGPT轻量化生成模型在客服系统的实战应用
SeqGPT轻量化生成模型在客服系统的实战应用 1. 当客服团队每天被重复问题淹没时,我们试了这个新办法 上周跟一家做智能硬件的客户聊完,他们客服主管说了句让我印象很深的话:“我们30人的客服团队,有22个人每天80%的时间都在回答…...

OpenClaw怎么部署?OpenClaw龙虾AI阿里云7分钟安装新手流程2026年
OpenClaw怎么部署?OpenClaw龙虾AI阿里云7分钟安装新手流程2026年。OpenClaw怎么部署?本文面向零基础用户,完整说明在轻量服务器与本地Windows11、macOS、Linux系统中部署OpenClaw(Clawdbot)的流程,包含环境…...

iOS微信聊天记录备份完全指南:使用WeChatExporter永久保存你的数字回忆
iOS微信聊天记录备份完全指南:使用WeChatExporter永久保存你的数字回忆 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾经因为手机存储空间不足而不得…...

驱动管理与系统优化:Driver Store Explorer全方位空间清理指南
驱动管理与系统优化:Driver Store Explorer全方位空间清理指南 【免费下载链接】DriverStoreExplorer Driver Store Explorer [RAPR] 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否遇到过系统C盘空间莫名减少的情况?即…...

微信小程序2MB限制避坑指南:从分包策略到HBuilder发行全流程解析
微信小程序2MB体积限制全攻略:从分包设计到发行优化的实战手册 每次真机调试时弹出"main package source size exceed max limit 2MB"的红色警告,都让开发者们头疼不已。这个看似简单的体积限制背后,实际上考验的是对小程序架构设计…...

Qwen3-0.6B-FP8作品集:FP8模型在正则表达式生成任务准确率
Qwen3-0.6B-FP8作品集:FP8模型在正则表达式生成任务准确率 正则表达式,这个让无数程序员又爱又恨的工具。爱它,是因为它能用一行代码解决复杂的文本匹配问题;恨它,是因为它的语法晦涩难懂,写起来像在解谜。…...

07-大模型微调-LLama Factor微调Qwen -- 局部微调/训练医疗问答模型
课前小知识 显卡占用 有时候LLama Factor,点击卸载模型之后,显卡占用还是很高,这个时候将服务停止后重启 停止,重启 权重保存位置 大模型微调 瓶颈结构 神经网络有很多层,每一层参数对模型的影响是不同的(…...