Python 学习笔记【1】
此笔记仅适用于有任一编程语言基础,且对面向对象有一定了解者观看
文章目录
- 数据类型
- 字面量
- 数字类型
- 数据容器
- 字符串
- 列表
- 元组
- type()方法
- 数据类型强转
- 注释
- 单行注释
- 多行注释
- 输出
- 基本输出
- 连续输出,中间用“,”分隔
- 更复杂的输出格式
- 变量
- 定义
- del方法
- 标识符
- 运算符
- 比较运算符
- 逻辑运算符
- 输入
- input()
- 正常输入
- 连续输入
- 控制语句
- 自上而下的控制语句
- if条件语句
- 循环语句
- for循环
- range()
- for循环临时变量作用域
- while循环
- break
- continue
- else
- 函数
- 定义函数
- 调用函数
- 传参
- 位置参数
- 关键字参数
- 位置参数和关键字参数混用
- 缺省参数
- 可变参数(不定长)
- 位置传递不定长
- 关键字传递不定长
- 多个返回值
- 函数作为传参
- 匿名函数
- 介绍
- 基本语法
- 演示案例
- 数据容器
- 概述
- 列表(list)
- 介绍
- 基本语法
- 列表下标(索引)
- 列表方法
- 查询某元素下标
- 修改对应下标的元素值
- 在指定下标插入新元素
- 追加元素
- 删除指定下标元素
- 删除某元素在列表的第一个匹配项
- 清空列表
- 统计某元素在列表中数量
- 统计列表中所有元素数量
- 排序
- 列表拼接
- 元组(tuple)
- 介绍
- 基本语法
- 元组方法
- 字符串(str)
- 简介
- 基本语法
- 字符串方法
- 数据容器的切片
- 序列
- 切片
- 集合(set)
- 介绍
- 基本语法
- 集合方法
- 遍历集合
- 字典(dict)
- 介绍
- 基本语法
- 常用操作
- 遍历字典
- 容器通用函数
- 迭代器和生成器
- 迭代器
- 简介
- 创建迭代器
- 迭代迭代器
- 生成器
- 简介
- 创建生成器
- 迭代生成器
- Python3 内置函数
- zip
- enumerate
- 文件操作
- 文件编码
- 文件基础操作
- 打开文件
- 关闭文件
- 读操作
- 写操作
- CSV文件
- 异常
- 介绍
- 捕获异常
- 是什么
- 为什么
- 怎么做
- 异常else
- 异常finally
- 异常传递
- 介绍
- 模块
- 介绍
- 导入模块
- name变量
- all变量
- 自定义模块
- 创建
- 导入
- 包
- 介绍
- 创建包
- 导入包
- init.python文件
- 第三方包
- 如何安装第三方包
- pyecharts模块
- 介绍
- 快速入门
- 简单的画一个图
- 全局配置
- Numpy模块
- 基础知识
- 创建数组
- 打印数组
- 基本操作
- 通函数
- 索引、切片和迭代
- datetime包
- 类与对象
- 基本操作
- 构造方法(构造器)
- 魔术方法
- 介绍
- str方法
- lt方法
- le方法
- eq方法
- 封装
- 私有成员
数据类型
字面量
字面量就是非变量,直接以值的方式存在于程序中
数字类型
- 整数
- 浮点
- 复数
- 布尔
数据容器
字符串
三种定义方式
str1 = 'str1'
str2 = "str2"
str3 = """str3"""
列表
在后面列一个章节介绍
元组
在后面列一个章节介绍
type()方法
将变量 or 自变量放入“()”内,type()的返回值就是对应数据类型
数据类型强转
str = "123"# 这时str是字符串类型
str = (int)str# 这句话执行完str就成了int类型
注释
单行注释
# 这是单行注释
# #号和注释间一般用一个空格隔开
多行注释
"""这是多行注释这是多行注释这是多行注释
"""
输出
基本输出
连续输出,中间用“,”分隔
print(1,2,"3",4,5)#输出逗号默认为空格
更复杂的输出格式
-
输出多个结果时,使用“,”分隔符
print(1,2,3,sep=",")# 用分隔符“,”区分输出结果 -
输出不换行
print(x,end="") print(y) -
%d、%s、%e的格式化输出
print('%d'%3.1415926)# 仅输出整数部分 print('%10s'%'Monday')# Monday右对齐,取十位,不够则补位 print('%.3e'%3.1415926)# 3.1415926取3位小数,用科学计数法计数 print('%.2f'%4.1415)# 保留两位小数 -
format的输出格式
print('{}{}{}'.format ('Monday','Tuesday','Wednesday')) # 带关键字 # "and"拼接 -
自动格式化输出
a = 180 b = "roland" print(f"{b}的身高{a}")
变量
定义
变量名 = 变量值
bianliang = 1
del方法
使一个变量恢复到未定义状态
标识符
python中只支持:
- 英文
- 中文
- 数字
- 下划线 “_”
这四类元素
且,
- 不推荐中文
- 数字不能在开头
- 区分大小写
运算符
加:+
减:-
乘:*
除:/ (计算完自动转化成浮点型)
整除://
取余:%
指数:**
比较运算符
| 运算符 | 作用 |
|---|---|
| > | 大于 |
| < | 小于 |
| == | 等于 |
| != | 不等于 |
| >= | 大于等于 |
| <= | 小于等于 |
逻辑运算符
| 逻辑运算符 | 功能 |
|---|---|
| and | 与运算 |
| or | 或运算 |
| not | 非运算 |
输入
input()
传参是字符串,此函数执行时会打印括号内的内容,并等待键盘的输入。接收完输入后会以字符串的形式返回程序
正常输入
x = int (input("请输入梯形的上底长度"))
连续输入
#多数据输入中间用空格间隔
x,y,z=map(int,input(“请输入梯形的上下底长和
高“).split())
#多数据输入中间用逗号间隔
x,y,z=map(int,input(“请输入梯形的上下底长和
高”).split(”,"))
控制语句
缩进为四个空格!!!
自上而下的控制语句
if条件语句
特点:if后条件不需要用空格包住,
用:代替{}
else if 变成elif
if 1>2:print("数学崩塌了")
elif 1>3:print("数学真崩塌了")
else:print("数学还是正常的")
循环语句
for循环
for 临时变量 in 序列类型:
执行语句
序列类型指,其内容可以一个个依次取出的一种类型,包括【字符串 列表 元组 ……】
Python的for循环是一个轮询的机制,轮询 in 后的列表
name = "Roland"
for x in name:print(x)"""输出结果如下:
R
o
l
a
n
d
"""
理论上Python中的for循环无法构成无限循环(序列类型(被处理的数据集)不可能无限大)
range()
-
语法1
range(5)# 获得一个从0到5(不含5)的数字序列(0,1,2,3,4) -
语法2
range(1,5)# 获得一个从1到5(不含5)的数字序列(1,2,3,4) -
语法3
range(1,10,2)# 获得一个从1到10(不含10),步长为2的数字序列(1,3,5,7,9)
将range融合进for循环
for i in range(1,10,2):print (i)
for循环临时变量作用域
实际上可以在外部访问
但在编程规范上,不允许
while循环
i = 6
while(i > 0):print("i = ",i)i--
break
跳出循环
continue
中断本次循环,进入下次循环
如果没有下次了,那就跳出循环
else
在 python 中,while … else 在循环条件为 false 时执行 else 语句块:
count = 0
while count < 5:print count, " is less than 5"count = count + 1
else:print count, " is not less than 5"'''----------------------------------------------'''
# 注意,break退出循环不会触发else
count = 0
while count < 5:print count, " is less than 5"count = count + 1break
else:print count, " is not less than 5"
函数
定义函数
def 函数名 (参数列表):
函数体
return 返回值
# 此函数根据传参大小,打印Hello n次,并返回"Over"
def SayHello(n):# 传参列表可以空着for i in range(n):print("Hello")return "Over" #可以不写return,不写return就是等于写了一个 return None
调用函数
print(SayHello(3))# 打印三次Hello
传参
位置参数
就是c语言的传参机制
关键字参数
即函数调用时通过 “键 = 值”形式传递参数
作用:可以让函数更加清晰、更容易使用,同时也清除了参数的顺序需求
def user_info(name,age,gender):print(f"您的名字为{name},年龄为{age},性别是{gender}")user_info(name = "Roland", age = 3, gender = "男")
user_info(name = "Roland", gender = "男", age = 3)
user_info(age = 3, gender = "男", name = "Roland")
#上面三次调用都是一样的传参效果
位置参数和关键字参数混用
def user_info(name,age,gender):print(f"您的名字为{name},年龄为{age},性别是{gender}")user_info(name = "Roland", age = 3, gender = "男")
user_info("Roland", gender = "男", age = 3)
#上面三次调用都是一样的传参效果
缺省参数
也叫默认参数,意思就是为参数提供默认值,如果传参没有传该参数,则函数自己使用默认的参数,如果有传,则使用传参
def user_info(name,age,gender = "男"):print(f"您的名字为{name},年龄为{age},性别是{gender}")user_info("Roland",age = 3)
user_info("Rose",18,"女")
可变参数(不定长)
位置传递不定长
def user_info(*args):# 这里注意下,args是一个默认的惯例,可以叫别的,但最好叫这个
传进的参数都会被 *args接收,作为一个元组存储,这也叫做位置传递
关键字传递不定长
def user_info(**kwargs):# 这里注意下,kwargs是一个默认的惯例,可以叫别的,但最好叫这个
传进的参数都会被 **kwargs接收,作为一个字典存储,这也叫做关键字传递,所以传递的参数得以字典的形式
多个返回值
# 此函数根据传参大小,打印Hello n次,并返回"Over"
def SayHello(n):# 传参列表可以空着for i in range(n):print("Hello")return "Over",6 # 多个返回值之间用逗号分隔a,b = SayHello(3)# 接收多个返回值也是用逗号分隔
print(a,b)
函数作为传参
函数1作为参数传递给函数2,其实函数2写来就是为了让使用者传递一个函数1,然后有函数2来调用。
当然,函数1所赋予的传参是由函数2给的,并不是使用者
这算是传入计算逻辑,而非传入数据
挺绕的,自己写了就清楚了
# 对1和2进行计算,至于怎么计算,根据传入的函数决定
def calc_1_and_2(Handle):x = Handle(1,2)return x#计算a+b
def math_plus(a,b):return a+b#计算a-b
def math_minus(a,b):return a-bprint(calc_1_and_2(math_plus))
print(calc_1_and_2(math_minus))
匿名函数
介绍
函数的定义中
- def关键字,可以定义带有名称的函数,可重复使用
- lambda关键字,可以定义匿名函数(无名称),只可临时使用一次
- 可以用来测试某个参数是函数的函数的功能
基本语法
lambda 传入参数:函数体 # 注意函数体内只能写一行
演示案例
def test_func(computer):result = computer(1,2)print(result)test_func(lambda x,y: x + y)# 在这里就是把新定义的匿名函数的逻辑传给了test_func
数据容器
概述
一种可以同时存储多个(种)元素的python数据类型
根据是否支持重复元素、是否可以修改、是否有序等,分为5类:
- 列表(list)
- 元组(tuple)
- 字符串(str)
- 集合(set)
- 字典(dict)
数据容器变量名是指针:也就是先定义了list1,然后list2=list1,则修改list1后,list2内容也是同步变化的
列表(list)
介绍
列表内的每一个数据称为元素
列表中可以存储不同的数据类型
列表中可以存储相同的数据
说白了就是数组Pro
基本语法
# 字面量
# [元素1,元素2,元素……]# 定义变量
# 第一种
myList = [1, 2, 3, 4, 5]
# 第二种
myList = [i for i in range(1, 6)]
# 上面两个结果一致# 定义空列表
myList = []
myList = list()# 列表嵌套
myList = [列表1,列表2]
案例演示
my_list = ["Roland", 3, True]
print(type(my_list))
print(my_list)
my_list_list = [my_list,["Roland", 3, False]]
print(my_list_list)
列表下标(索引)
my_list = ["Roland", 3, True]
# 正向索引
print(my_list[0],my_list[1],my_list[2])
# 反向索引(-1是倒数第一个,-2是倒数第二)
print(my_list[-1],my_list[-2],my_list[-3])
列表方法
查询某元素下标
列表对象.index(元素)
案例演示
my_list = ["Roland", 3, True]
print(my_list.index(3))
修改对应下标的元素值
同数组的修改元素方式,我觉得不应该叫方法
在指定下标插入新元素
列表对象.insert(下标,元素)
案例演示
my_list = ["Roland", 3, True]
my_list.insert(1,2)
print(my_list)
追加元素
列表对象.append(元素)# 将新元素追加到列表尾部
列表对象.extend(其他数据容器)# 将其他数据容器内容取出,依次追加到列表尾部
案例演示
my_list = ["Roland", 3, True]
my_list.append(2)
print(my_list)
my_list2 = ["Steve", 2, False]
my_list.extend(my_list2)
print(my_list)
删除指定下标元素
del 列表[下标]
列表对象.pop(下标)
案例演示
my_list = ["Roland", 3, True]
my_list.pop(2)
print(my_list)my_list2 = ["Steve", 2, False]
del my_list2[0]
print(my_list2)
删除某元素在列表的第一个匹配项
列表对象.remove(元素)
案例演示
my_list = ["Roland", 3, True]
my_list.remove(3)
print(my_list)
清空列表
列表对象.clear()
案例演示
my_list = ["Roland", 3, True]
my_list.clear()
print(my_list)
统计某元素在列表中数量
列表对象.count(元素)
案例演示
my_list = ["Roland", 3, True]
print(my_list.count(True))
统计列表中所有元素数量
len(列表对象)
案例演示
my_list = ["Roland", 3, True]
print(len(my_list))
排序
list.sort(cmp=None, key=None, reverse=False) # reverse=true:降序
列表拼接
元组(tuple)
介绍
元组与列表的唯一区别——不可修改
基本语法
# 定义元组字面量
(元素,元素,……)# 定义元组变量
变量名称 = (元组,元组,……)# 定义单元素元组变量(要写个逗号)
变量名称 = (元组,)# 定义空元组
变量名称 = ()
变量名称 = tuple() # 元组嵌套元组方法
- index
- count
- len
字符串(str)
简介
字符串时字符的数据容器,只能存字符
不可修改的
基本语法
# 通过下标取值
mystr = "Roland"
print(mystr[3])
字符串方法
-
.index 这里注意下,index不只是只能查单个字符的位置,也可以查一个小字符串出现的起始下标
-
.replace(字符串1,字符串2) 将调用此方法的字符串中的字符串1替换成字符串2,并以返回值的方式返回(需要一个新的变量来接收)
-
.split(“分隔符字符串”) 将调用此方法的字符串用分割字符串分割成多个元素,并存入一个列表,并以返回值的方式返回(需要一个新的变量来接收)
# 这个方法不好描述,直接上代码 myStr = "Hello this is Roland" mylist = myStr.split(" ") print(mylist) -
.strip() 字符串规整操作,去除字符串的前后空格。传参还可以传入字符串,意思就是去除原字符串的前后被传入的字符串,当然还是将新字符串以返回值的方式返回
-
.count
-
len
数据容器的切片
序列
内容连续、有序,可使用下标索引的一类数据容器(列表、元组、字符串)
切片
从一个序列中取出一个子序列
语法:序列[起始下标:结束下标]
序列[起始下标:结束下标:步长]
arr[::-1] # 将数据容器内容倒序
注意:
- 不含结束下标
- 步长为负数表示反向取,呢么起始下标和结束下标也要反向标记
- 是以返回值的方式返回新的序列
- 传参不传步长的话就是默认步长为1
集合(set)
介绍
- 无序、无下标
- 不可重复
- 可不同数据类型
- 可修改
- 支持for循环不支持while循环遍历
基本语法
# 定义集合字面量
{元素,元素,……}# 定义集合变量
变量名称 = {元素,元素,……}# 定义空集合
变量名称 = set()
集合方法
- .add(元素) 将指定元素添加到自身集合内
- .remove(元素) 删除指定元素
- .pop()随机取一个元素通过返回值返回,同时删除此元素
- .clear()
- 集合1.difference(集合2) 取两个集合的差集,将新集合返回,原集合不发生变化
- 集合1.difference_update(集合2) 在集合1内,删除和集合2相同的元素。集合1可能发生变化,集合2不变
- 集合1.union(集合2) 将集合1和集合2合并,并以返回值的方式返回新集合
- len(集合) 统计集合元素数量
遍历集合
由于集合没有下标,所以不能用while()遍历
可以用for循环遍历,但不能保证遍历顺序
myset = {1,2,5,6}
for i in myset:print(i)
字典(dict)
介绍
生活中的字典:【字】:含义
Python中的字典:【Key】:value
- 无序、无下标
- Key 不可重复(重复添加等于覆盖原有数据)
- 值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
- 可修改
- 支持for循环,不支持while循环遍历
基本语法
# 字面量
{key:value, key:value, ……}
# 变量
mydict = {key:value, key:value, ……}
# 空字典
my_dict = {}
my_dict = dict()# 从字典中基于Key获取Value
my_dict = {"Roland":180,3:170,"Rola":160}
print(my_dict["Roland"])# 字典的嵌套(Key不可为字典)
score = {"高数":100,"大英":99,"离散":100}
student = {"Roland":score}
print(student)
print(student["Roland"])
print(student["Roland"]["高数"])
常用操作
-
新增/更新元素
my_dict = { "Roland":180,"Steve":170} my_dict["Rola"] = 160 # 第一次使用表示新增Rola这个Key,Value为160 print(my_dict) my_dict["Rola"] = 150 # 第二次使用表示修改Rola这个Key,Value为150 print(my_dict) -
.pop(key) 获得指定Key的Value,通过返回值返回,同时删除这个key和对应的value
-
.clear() 清空字典
-
.keys() 获取所有的key(不含value)
-
len(字典) 获取字典中key的数量
-
.get(key) 获取key的值
遍历字典
my_dict = { "Roland":180,"Steve":170,"Rola":160}
keys = my_dict.keys()
for key in keys:print(key)
for key in my_dict:# 其实这种写法和上面的的for一样,都是拿出my_dict中的所有keyprint(key)
容器通用函数
- len
- max
- min
迭代器和生成器
迭代器
简介
迭代器(interation)是一个可以记住遍历的位置的对象。
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
创建迭代器
# 使用iter方法创建
myList = [0, 1, 2, 3, 4]
myIter = iter(myList) # 等效下一行代码
myIter = iter([i for i in range(5)]) # 等效上一行代码
迭代迭代器
# 先创建一个迭代器
myIter = iter([i for i in range(5)])# 使用next方法进行迭代,每执行一次next,迭代一次,当超出了迭代返回,会由一个 StopIteration 异常结束程序
print (next(myIter))
print (next(myIter))
print (next(myIter))
print (next(myIter))
print (next(myIter))
print (next(myIter))
生成器
简介
生成器(generator)是使用了 yield 的函数 或是 由循环表达式生成的。
没错,所有函数都能成为生成器,只需要在函数内部写到 yield 关键字
生成器函数还包括以下内容:
- 通用生成器
- 协程生成器
- 委托生成器
- 子生成器
创建生成器
生成器有两种创建方式表示:
-
生成器表达式
# 生成器表达式是用圆括号来创建生成器 myGenerator = (i for i in range(5)) # 与列表的创建很想,是把方括号改成圆括号 -
生成器函数
# 创建 生成器函数 def countdown(n):while n > 0:yield nn -= 1# 创建生成器对象 generator = countdown(5)
迭代生成器
# 创建 生成器函数
def countdown(n):while n > 0:yield nn -= 1# 创建生成器对象
generator = countdown(5)# 通过迭代生成器获取值
print(next(generator)) # 输出: 5
print(next(generator)) # 输出: 4
print(next(generator)) # 输出: 3# 使用 for 循环迭代生成器
for value in generator:print(value) # 输出: 2 1
Python3 内置函数
zip
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象
我们可以使用 list() 转换来输出列表。
enumerate
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
seasons = ['Spring', 'Summer', 'Fall', 'Winter']
print(list(enumerate(seasons)))
print(list(enumerate(seasons, start=1)))# 下标从 1 开始
文件操作
文件编码
编码技术即翻译的规则
如:
-
UTF-8
-
GBK
-
Gig5
文件基础操作
打开文件
"""name:要打开的目标文件名的字符串mode:设置打开文件的模式(访问模式):只读、写入、追加等r:只读w:只写,清空文件,从头开始编辑;如果文件不存在,则创建新文件a:追加新内容写到已有内容之后;如果文件不存在,则创建新文件encoding:编码格式(字符串)
"""
open(name, mode, encoding)# 打开一个已存在的文件,或者创建一个新文件;并返回一个文件对象,可以理解成C语言中的FILE类型变量#示例
f = open("F:\Pyworks\Demo1\demo.txt","r",encoding="UTF-8")# 这里要注意,encoding在函数定义处不是第三位传参,所以要用关键字传参
关闭文件
-
.close()方式
f = open("F:\Pyworks\Demo1\demo.txt","r",encoding="UTF-8") f.close()# 解除文件占用 -
with open语法
with open("F:\Pyworks\Demo1\demo.txt","r") as f:print(f.readlines()) # 通过在with open的语句块中对文件进行操作 # 可以在操作完成后自动close文件,避免遗忘掉close方法
读操作
- 文件对象.read(num) 从文件对象中读取指定长度的内容(num的单位是字符个数,如果不写num,则效果等于readlines() )(这里注意,读取的时候是有个指针的概念的,一开始指针指向第一个字符,假设第一次读取到第4个字符(第4未读出),则下次读取是从第4个字符开始)
- 文件对象.readline() # 按照行的方式对文件内容读取一行,并返回一个字符串
- 文件对象.readlines() # 按照行的方式对文件内容进行一次性读取,并返回一个列表,文件中每行数据作为一个元素
# 示例1
f = open("F:\Pyworks\Demo1\demo.txt","r",encoding="UTF-8")
print(f.read(10))# 示例2
f = open("F:\Pyworks\Demo1\demo.txt","r",encoding="UTF-8")
print(f.readlines())for循环遍历文件内容
f = open("F:\Pyworks\Demo1\demo.txt","r",encoding="UTF-8")
for line in f: # 每次循环会从文件中拿一行数据以字符串形式给到lineprint(line)
写操作
# 只写的方式打开文件
f = open("F:\Pyworks\Demo1\demo.txt","w",encoding="UTF-8")
# 写入文件
f.write("你好世界")# 写入Python程序缓冲区
# 内容刷新(即Ctrl-S保存操作),可以不要这个内存刷新,当f.close被执行后或者程序关闭了,也是会自动刷新的
f.flush()# 真正写入文件中
# 追加的方式打开文件
f = open("F:\Pyworks\Demo1\demo.txt","a",encoding="UTF-8")
# 写入文件
f.write("你好世界")# 写入Python程序缓冲区
# 内容刷新(即Ctrl-S保存操作),可以不要这个内存刷新,当f.close被执行后或者程序关闭了,也是会自动刷新的
f.flush()# 真正写入文件中
CSV文件
import csvfilename='C:\\Users\\lenovo\\Desktop\\parttest.csv'
data = []
with open(filename) as csvfile:csv_reader = csv.reader(csvfile) # 使用csv.reader读取csvfile中的文件#header = next(csv_reader) # 读取第一行每一列的标题for row in csv_reader: # 将csv 文件中的数据保存到data中data.append(row[5]) # 选择某一列加入到data数组中
异常
介绍
即bug,程序跑到某个位置时,编译器无法继续运行下去
捕获异常
是什么
世上没有完美的程序
我们要做的,不是力求程序完美运行,而是在力所能及的范围内,对可能出现的bug进行提前准备、提前处理
这种行为称为:异常处理:(捕获异常)
为什么
当程序遇到BUG时,接下来有两种情况:
- 整个程序停止
- 对BUG进行提醒,整个程序继续运行
没有捕获异常的时候,程序是以 情况1 的方式处理bug的
但是在真实应用场景时,不可能因为一个bug就让程序停了,所以我们就需要捕获异常来实现 情况2
怎么做
-
基本捕获语法
try:可能发生错误的代码 except:如果出现异常 执行的代码 -
捕获指定的异常
try:print(a) except NameError as e:# 这个e就是异常的对象,也就是系统自带的异常解释信息;可以不写as e,就是不接收异常对象罢了print("出现了变量未定义的异常")print(e) -
捕获多个异常
try:print(1/0) except(NameError,ZeroDivisionError):print("ZeroDivision错误…") -
捕获所有异常并获取异常信息
try:print(1/0) except Exception as e:print(e)
异常else
else表示没有异常的话要执行的代码
try:print(1/0)
except Exception as e:print(e)
else:print("没有异常~")
异常finally
finally表示无论有没有异常都要执行里面的代码
try:print(1/0)
except Exception as e:print(e)
else:print("没有异常~")
finally:print("离开异常判断区域")
异常传递
介绍
异常是具有传递性的
看看代码
def func1():return 1/0def func2():return func1()try:print(func2())
except:print("发现异常")
上述代码中func1中 0 作为除数会报异常,如果func1中没有处理这个异常的话,异常会传递到func2;如果func2也没有捕获异常的话,异常最终会传递到主程序中,如果主程序也没有捕获,那程序就停止了
模块
介绍
就是C语言的.c文件,在python中是一个.python文件,里面有定义好的函数,类,变量。
就是个工具包,直接拿过来用
导入模块
[from 模块名] import [模块 | 类 | 变量 | 函数 | *|] [as 别名]
“[]”括起来的是可选的意思 “|” 是选其一的意思
常见的组合形式:
- import 模块名
- import 模块名1,模块名2
- import 模块名 as 别名
- from 模块名 import 类|变量|方法
- form 模块名 import *
- form 模块名 import 类|变量|方法 as 别名
使用import导入需要通过 . 才能使用全部功能,比如time.sleep()
使用from导入直接就能使用全部功能,比如sleep()
当导入不同模块的时候,如果有重名的函数之类的,程序会优先调用最后一次导入的
name变量
如果导入的模块内有可立即执行代码,则程序运行import的时候就会直接执行模块内的代码,如下
"""这是模块文件.python"""
def test(a,b):return a+btest(a+b)
"""主程序文件.python"""
import 这是模块文件print("主程序")
如果不想执行模块内的代码呢?
这里就需要在模块内部的可执行代码前加东西了
"""这是模块文件.python"""
def test(a,b):return a+bif __name__ == '__main__': # __name__ 是一个Python内置变量,当我们运行某个.python文件是,该.python文件内的 __name__ 就会被赋值为 '__main__' 可以理解成Python的入口文件,很类似c语言的int main(){}test(a+b)
"""主程序文件.python"""
import 这是模块文件print("主程序")
all变量
如果一个模块文件中有 all 变量,当使用 from xxx import * 导入的时候,只能导入在这个列表中的元素
"""这是模块文件.python"""
__all__ = ['test_a'] # 这时候如果 from 这是模块文件 import * 的话,只能使用test_a函数,用其他导入语句的话就没关系,不用看这个all
def test_a(a,b):return a+bdef test_b(a,b):return a-b"""主程序文件.python"""
import 这是模块文件print("主程序")
test_a(1,2)
test_b(1,2)
自定义模块
创建
只需要新建.python文件,定义对应函数,就可以了
导入
在同一个文件夹直接import或者from文件名就可以
包
介绍
模块可以理解成文件,包就是文件夹
相较于文件夹,包还多了一个叫 __init__.python 的文件,有了这个文件,文件夹才叫做包
创建包
- 新建文件夹
- 新建文件 __init__.python
- 好了
导入包
-
方式一
import 包名.模块名# 导入 包名.模块名.目标 # 使用 -
方式二
from 包名 import 模块名# 导入 模块名.目标# 使用
init.python文件
__all__ = ['my_module1']#此时如果使用import *这个包时,就只能使用my_module1这个模块
第三方包
如何安装第三方包
- 进入cmd
- 输入pip install 包名
也可以pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名
没有科学上网的话第二个可以改善下载速度
pyecharts模块
介绍
可以做出数据可视化效果图的一个模块
本体是 Echarts 框架,Echarts是百度开源的数据可视化框架,而pyecharts模块是专为Python设计的模块
官方网站
安装:pip install pyecharts
快速入门
简单的画一个图
# 导包,导入Line功能构建折线图对象
from pyecharts.charts import Line# 得到折线图对象
line = Line()# 添加x轴数据
line.add_xaxis(["中国","美国","日本"])# 添加y轴数据
line.add_yaxis("GDP",[30,20,10])#生成图标
line.render()
全局配置
set_global_opts()
该方法可配置的基础配置(所谓基础配置即无论是什么图都会有的配置)如下:

不学了,没用
Numpy模块
[官方链接](NumPy 介绍 | NumPy)
基础知识
NumPy的主要对象是同构多维数组。它是一个元素表(通常是数字),所有类型都相同,由非负整数元组索引。在NumPy维度中称为轴 。
NumPy的数组类ndarray被调用。它也被别名 array所知。请注意,numpy.array这与标准Python库array.array类不同,后者只处理一维数组并提供较少的功能。ndarray对象更重要的属性是:
- ndarray.ndim - 数组的轴(维度)的个数。在Python世界中,维度的数量被称为rank
- ndarray.shape - 数组的维度。这是一个整数的元组,表示每个维度中数组的大小。对于有 n 行和 m 列的矩阵,
shape将是(n,m)。因此,shape元组的长度就是rank或维度的个数ndim - ndarray.size - 数组元素的总数。这等于
shape的元素的乘积 - ndarray.dtype - 一个描述数组中元素类型的对象。可以使用标准的Python类型创建或指定dtype。另外NumPy提供它自己的类型。例如numpy.int32、numpy.int16和numpy.float64。
- ndarray.itemsize - 数组中每个元素的字节大小。例如,元素为
float64类型的数组的itemsize为8(=64/8),而complex32类型的数组的itemsize为4(=32/8)。它等于ndarray.dtype.itemsize。 - ndarray.data - 该缓冲区包含数组的实际元素。通常,我们不需要使用此属性,因为我们将使用索引访问数组中的元素
创建数组
# 使用array函数从常规Python列表或元组中创建数组
import numpy as npy# 一维数组
a = npy.array([2,3,4])
print(a)# 二维数组
b = npy.array([[1,2,3],[4,5,6],[7,8,9]])
print(b)# 在创建时显示指定数组的类型
c = npy.array([6,6,6], dtype=complex)# complex是虚数
print(c)# 创建一个全是0的数组
d = npy.zeros([3,4])
print(d)# 创建一个全是1的数组
e = npy.ones([3,4], dtype=npy.int16)
print(e)# 创建一个数组,其初始内容是随机的,取决于内存的状态。(dtype默认是float64)
f = npy.empty([3,4])
print(f)# 创建整数组成的数组
g = npy.arange(10,100,20) #从10到100,步长为20
print(g)# 创建浮点数组成的数组
h = npy.linspace(0,2,9) # 获取0到2之间的9个数# 根据π做一些操作
from numpy import pi
i = npy.linspace(0,2*pi,100) # 获取0到2π间的100个数
print(i)
j = npy.sin(i) # 将数组i中的所有元素进行正弦转化
print(j)
打印数组
numpy中的数组有一定的固定布局:
- 最后一个轴从左到右打印,
- 倒数第二个轴从上到下打印,
- 其余轴也从上到下打印,每个切片用空行分隔
即
[[[ 0 1 2 3][ 4 5 6 7][ 8 9 10 11]][[12 13 14 15][16 17 18 19][20 21 22 23]]]
如果数组太大而无法打印,NumPy会自动跳过数组的中心部分并仅打印角点:
>>> print(np.arange(10000))
[ 0 1 2 ..., 9997 9998 9999]
>>>
>>> print(np.arange(10000).reshape(100,100))
[[ 0 1 2 ..., 97 98 99][ 100 101 102 ..., 197 198 199][ 200 201 202 ..., 297 298 299]...,[9700 9701 9702 ..., 9797 9798 9799][9800 9801 9802 ..., 9897 9898 9899][9900 9901 9902 ..., 9997 9998 9999]]
要禁用此行为并强制NumPy打印整个数组,可以使用更改打印选项set_printoptions。
>>> np.set_printoptions(threshold=sys.maxsize)
基本操作
数组上的算术运算符会应用到 元素 级别。即所有的元素都会收到运算符的影响
>>> a = np.array( [20,30,40,50] )
>>> b = np.arange( 4 )
>>> b
array([0, 1, 2, 3])
>>> c = a-b
>>> c
array([20, 29, 38, 47])
>>> b**2
array([0, 1, 4, 9])
>>> 10*np.sin(a)
array([ 9.12945251, -9.88031624, 7.4511316 , -2.62374854])
>>> a < 35 # 比较运算符都可以
array([ True, True, False, False])>>> A = np.array( [[1,1],
... [0,1]] )
>>> B = np.array( [[2,0],
... [3,4]] )
>>> A * B # 乘积运算符
array([[2, 0],[0, 4]])
与许多矩阵语言不同,乘积运算符*在NumPy数组中按元素进行运算。即 aij * bij
而矩阵乘积是使用@或者 dot函数
>>> A = np.array( [[1,1],
... [0,1]] )
>>> B = np.array( [[2,0],
... [3,4]] )>>> A @ B # matrix product
array([[5, 4],[3, 4]])
>>> A.dot(B) # another matrix product
array([[5, 4],[3, 4]])
当使用不同类型的数组进行操作时,结果数组的类型对应于更一般或更精确的数组(称为向上转换的行为)。
许多一元操作,例如计算数组中所有元素的总和,都是作为ndarray类的方法实现的。
- 注意,以下几个方法有个传参叫axis,axis = 0表示对列进行操作,axis = 1表示对行进行操作
- .sum
- .min
- .cumsum
- 等……
通函数
如sin,cos,exp……这些函数也都是在数组上按元素进行运算,产生一个数组作为输出
索引、切片和迭代
一维的数组可以进行索引、切片和迭代操作的,就像 列表 和其他Python数据容器类型一样
多维的数组每个轴可以有一个索引。这些索引以逗号分隔的元组给出:
array([[ 0, 1, 2, 3],[10, 11, 12, 13],[20, 21, 22, 23],[30, 31, 32, 33],[40, 41, 42, 43]])
>>> b[2,3]
23
当提供的索引少于轴的数量时,缺失的索引被认为是完整的切片 :
>>> b[-1] # the last row. Equivalent to b[-1,:]
array([40, 41, 42, 43])
如果想要对数组中的每个元素执行操作,可以使用flat属性,该属性是数组的所有元素的迭代器
for element in b.flat:print(i)
datetime包
示例代码
import numpy as np
import pandas as pd
from datetime import *# 输入2个日期
date1 = "2022.05.11 13:30:00"
date2 = "2022.05.10 12:00:00"# 创建时间点对象(不能进行减法运算)
realTime = datetime.time(10, 30, 0) # 10:30:00# 创建具体时间对象(可以进行减法运算)
realTime_dt = datetime.datetime(2021, 1, 1, realTime.hour, realTime.minute, realTime.second)# 将输入的日期转换为“datetime.datetime”类型
# 由于日期的类型是字符串,因此不能直接进行计算,会报错
date1 = datetime.strptime(date1, "%Y.%m.%d %H:%M:%S")
date2 = datetime.strptime(date2, "%Y.%m.%d %H:%M:%S")
print(" date1:", date1, "\n" ,"date2:", date2)
print(" 2个日期的类型分别是:\n", type(date1), type(date2))# 计算时间差:时间差的类型为“datetime.timedelta”类型
duration = date1 - date2
duration# 对计算差值进行天数(days)和秒数(seconds)的提取,并将秒数转换为小时数
day = duration.days
hour = duration.seconds/3600
print("days:", day)
print("hours:", hour)
类与对象
基本操作
主要要了解self
"""设计类"""
class Student:"""类的属性(变量)"""name = Noneage = None"""类的行为(方法)"""def say_hi(self,myname):# self关键字必须存在,其余定义方式和普通的函数一样print(f"hi,大家好,我是{self.name}")# 如果成员方法要直接使用成员变量,也需要在变量前加上self.print(f"hi,大家好,主人也叫我{myname}")"""创建对象"""
stu1 = Student()
stu2 = Student()"""为对象赋值"""
stu1.name = "Roland"
stu2.name = "Rola""""获取对象信息"""
print(stu1.name)"""调用成员方法"""
stu1.say_hi("Steve")# self虽然是定义法时的形参,但是调用方法时完全可以忽略这个形参
构造方法(构造器)
类中如果有了构造方法,那么可以实现:
- 在创建类对象 (构造类) 的时候,会自动执行
- 在创建类对象(构造类) 的时候——new,将传入参数自动传递给构造方法使用
# 在Python中,__init__()就是构造方法也就是java中的构造器
class Student:"""类的属性(变量)"""name = Noneage = None"""构造方法"""def __init__(self,name,age):self.name = nameself.age = age"""类的行为(方法)"""def say_hi(self,myname):# self关键字必须存在,其余定义方式和普通的函数一样print(f"hi,大家好,我是{self.name}")# 如果成员方法要直接使用成员变量,也需要在变量前加上self.print(f"hi,大家好,主人也叫我{myname}")"""创建对象"""
stu1 = Student("Roland",18)
# stu2 = Student()"""获取对象信息"""
print(stu1.name)
stu1.say_hi("Steve")
魔术方法
介绍
Python类中有很多内置方法,即无论是什么类,都会有的方法,上面所说的 init 构造方法就是魔术方法
魔术方法的命名规范:方法单词前后都有两个 “_”
有:
- init——构造方法
- str——字符串方法
- lt——小于、大于符号比较
- le——小于等于、大于等于符号比较
- eq——==符号比较
- 等等……
str方法
字符串方法
当类对象需要被转换为字符串时,会调用str方法,而str方法实际上就是返回一串字符串。
如果没有重写方法的话,Python内置的是返回对象的内存地址,如果重写了,那么会返回重写方法中return 的值
"""这是没有重写str方法时"""
class Student:"""类的属性(变量)"""name = Noneage = None"""构造方法"""def __init__(self,name,age):self.name = nameself.age = age"""创建对象"""
stu1 = Student("Roland",18)"""输出对象信息(两个语句等价)"""
print(stu1)
print(str(stu1))
"""这是重写str方法时"""
class Student:"""类的属性(变量)"""name = Noneage = None"""构造方法"""def __init__(self,name,age):self.name = nameself.age = agedef __str__(self):return f"这个对象的name={self.name},age={self.age}"
"""创建对象"""
stu1 = Student("Roland",18)"""输出对象信息"""
print(stu1)
print(str(stu1))
lt方法
支持小于或大于符号( “<、>” )比较方法
即使两个对象可以进行比较,这个是需要我们自己写的,程序内没有内置。如果没有写这个方法,但是还是使用小于号比较了两个对象,则会报错
"""案例演示"""
class Student:"""类的属性(变量)"""name = Noneage = None"""构造方法"""def __init__(self,name,age):self.name = nameself.age = agedef __lt__(self,other):# 这里other代表着另一个对象return self.age < other.agestu1 = Student("Roland",18)
stu2 = Student("Steve",19)print(stu1 < stu2)
le方法
将我对lt方法的描述中的“小于或大于”替换成“小于等于或大于等于”
eq方法
将我对lt方法的描述中的“小于或大于”替换成“等于”
封装
封装是一个思想,就是下列代码
class Student:"""类的属性(变量)"""name = Noneage = None"""构造方法"""def __init__(self,name,age):self.name = nameself.age = agedef __lt__(self,other):# 这里other代表着另一个对象return self.age < other.age
私有成员
封装一个类时,有时会有一些变量,不公开给外部使用,只给内部的方法自己调用,这时就需要私有成员的形式
相关文章:
Python 学习笔记【1】
此笔记仅适用于有任一编程语言基础,且对面向对象有一定了解者观看 文章目录 数据类型字面量数字类型数据容器字符串列表元组 type()方法数据类型强转 注释单行注释多行注释 输出基本输出连续输出,中间用“,”分隔更复杂的输出格式 变量定义del方法 标识符…...

Git系列:rev-parse 使用技巧
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「stormsha的主页」…...

【Java数据结构】详解LinkedList与链表(一)
🔒文章目录: 1.❤️❤️前言~🥳🎉🎉🎉 2.ArrayList的缺陷 3.链表的概念及结构 4.无头单向非循环链表的实现 4.1成员属性 4.2成员方法 createList display——打印链表 addFirst——头插 addLast…...
PDF高效编辑器革新:一键智能转换PDF至HTML,轻松开启文件处理全新时代!
信息爆炸的时代,PDF文件因其跨平台、不易修改的特性,成为了商务、教育、出版等领域不可或缺的文件格式。然而,PDF文件的固定性也带来了诸多不便,特别是在需要对其内容进行编辑或格式转换时。这时,一款高效、易用的PDF编…...
JDBC知识
JDBC是什么? 这工作中我们针对数据库的操作,实际上很少会用到SQL语句,通过命令行/图形化来操作数据库,更多的是通过主流的编程语言来对数据库进行操作,即使通过代码来操作数据,我们还是会使用到SQL语句,所以掌握SQL语句也是很重要的. 如何通过代码操作数据库? 通过代码操作…...

C++操纵符用法
C中的操纵符(Manipulators)是用于格式化输入输出的特殊工具。它们可以在输出流中控制各种格式,如设置字段宽度、精度、填充字符等。以下是一些常用的操纵符及其用法: setw(int width): 设置字段宽度为width个字符。 cout <<…...

【一步一步了解Java系列】:子类继承以及代码块的初始化
看到这句话的时候证明:此刻你我都在努力 加油陌生人 个人主页:Gu Gu Study专栏:一步一步了解Java 喜欢的一句话: 常常会回顾努力的自己,所以要为自己的努力留下足迹 喜欢的话可以点个赞谢谢了。 作者:小闭 …...

探索Expect Python用法:深入解析与实战挑战
探索Expect Python用法:深入解析与实战挑战 在自动化和脚本编写领域,Expect Python已经成为了一种强大的工具组合。它结合了Expect的交互式会话处理能力和Python的编程灵活性,为开发者提供了一种全新的方式来处理复杂的自动化任务。然而&…...

【PostgreSQL17新特性之-explain命令新增选项】
EXPLAIN是一个用于显示语句执行计划的命令,可用于显示以下语句类型之一的执行计划: - SELECT - INSERT - UPDATE - DELETE - VALUES - EXECUTE - DECLARE - CREATE TABLE AS - CREATE MATERIALIZED VIEWPostgreSQL17-beta1版本近日发布了,新…...
JAVA实现人工智能,采用框架SpringAI
文章目录 JAVA实现人工智能,采用框架SpringAISpring AI介绍使用介绍项目前提项目结构第一种方式采用openai1. pom文件: 2. application.yml 配置3.controller 实现层 项目测试 JAVA实现人工智能,采用框架SpringAI Spring AI介绍 Spring AI是AI工程师的一个应用框架…...
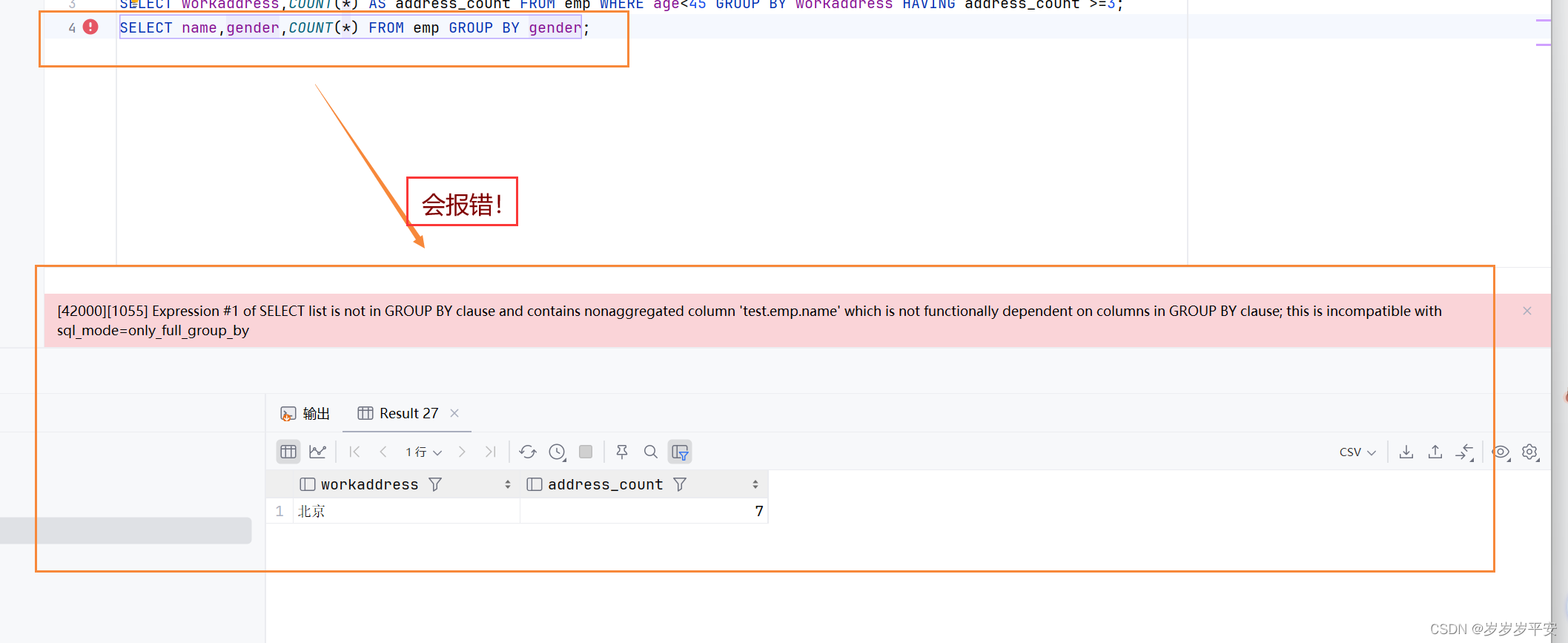
基础—SQL—DQL(数据查询语言)分组查询
一、引言 分组查询的关键字是:GROUP BY。 二、DQL—分组查询 1、语法 SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组后过滤条件 ]; 注意: 1、[ ] 里的内容可以有可以没有。 2、这条SQL语句有两块指定条件的地方&#…...

从CSV到数据库(简易)
需求:客户上传CSV文档,要求CSV文档内容查重/插入/更新相关数据。 框架:jdbcTemplate、commons-io、 DB:oracle 相关依赖: 这里本来打算用的2.11.0,无奈正式项目那边用老版本1.3.1,新版本对类型…...

K210视觉识别模块学习笔记3:内存卡写入拍摄图片_LED三色灯的操作_按键操作_定时器的配置使用
今日开始学习K210视觉识别模块: LED三色灯的操作_按键操作_定时器的配置使用_内存卡写入拍摄图片 亚博智能的K210视觉识别模块...... 固件库版本: canmv_yahboom_v2.1.1.bin 本文最终目的是编写一个按键拍照的例程序: 为以后的专用场景的模型训练做准备…...
如何定义“智慧校园”这个概念
在信息爆炸的时代,教育面临着前所未有的挑战:如何让每个学生在海量知识中找到属于自己的路径?如何让教师的智慧与科技的力量相得益彰?如何让校园成为培养创新思维的摇篮?智慧校园,这一概念的提出࿰…...

OpenSSL自签名证书
文章目录 生成1. 生成根证书的私钥(root_private_key.pem)2. 创建根证书的CSR和自签名证书(root_csr.pem)3. 生成服务器证书的私钥(server_private_key.pem)4. 创建服务器证书的CSR(server_priv…...

QtCreator调试运行工程报错,无法找到相关库的的解决方案
最新在使用国产化平台做qt应用开发时,总是遇到qtcreator内调试运行 找不到动态库的问题,为什么会出现这种问题呢?明明编译的时候能够正常通过,运行或者调试的时候找不到相关的库呢?先说结论,排除库本身的问…...

【Python系列】Python 元组(Tuple)详解
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

特征融合篇 | YOLOv8 引入动态上采样模块 | 超过了其他上采样器
1. 介绍 本篇介绍了一种将动态上采样模块引入 YOLOv8 目标检测算法的新方法,该方法在 COCO 数据集上获得了 55.7% 的 mAP,超越了其他上采样器。该方法将动态上采样模块引入到 YOLOv8 的特征融合阶段,能够根据输入图像的特征分辨率动态调整上…...
Beyond Compare 3密钥被撤销的解决办法
首先,BCompare3的链接如下 链接:https://pan.baidu.com/s/1vuSxY0cVQCt0-8CpFzUhvg 提取码:8888 --来自百度网盘超级会员V7的分享 1.问题现象 激活之后在使用过程中有时候会出现密钥被撤销的警告,而且该工具无法使用ÿ…...

知识见闻 - 人和动物的主要区别
人类和动物的主要区别之一确实在于理性,但这只是众多区别中的一个方面。以下是一些更全面的比较,突出人类和动物之间的主要区别: 理性和抽象思维: 人类:人类具有高度发展的理性能力,可以进行抽象思维、逻辑…...

Subtitle Edit:免费开源字幕编辑器的完整使用指南
Subtitle Edit:免费开源字幕编辑器的完整使用指南 【免费下载链接】subtitleedit the subtitle editor :) 项目地址: https://gitcode.com/gh_mirrors/su/subtitleedit 想要为视频添加专业字幕却苦于找不到合适的工具?Subtitle Edit作为一款功能强…...

3分钟解锁Windows触控板三指拖拽:告别繁琐操作,提升效率300%
3分钟解锁Windows触控板三指拖拽:告别繁琐操作,提升效率300% 【免费下载链接】ThreeFingersDragOnWindows Enables macOS-style three-finger dragging functionality on Windows Precision touchpads. 项目地址: https://gitcode.com/gh_mirrors/th/T…...

保姆级教程:用Python脚本将JD9365A初始化代码一键转为RK3568设备树格式
Python脚本自动化转换:将JD9365A初始化代码高效转为RK3568设备树格式 在嵌入式Linux驱动开发中,屏幕初始化代码的转换工作常常让工程师们头疼不已。面对供应商提供的长达数百行的寄存器配置数组,手动转换为设备树格式不仅耗时费力,…...

Taotoken 用量看板如何帮助开发者清晰掌握月度支出
Taotoken 用量看板如何帮助开发者清晰掌握月度支出 1. 用量看板的核心功能 Taotoken 用量看板为开发者提供了多维度的 API 调用数据分析能力。在控制台首页的用量统计区域,系统会实时展示当前计费周期内的总 token 消耗量、预估费用以及各模型调用占比的环形图。这…...

【R 4.5边缘部署黄金标准】:IEEE IoT Journal认证的7项延迟/精度/功耗平衡指标及达标检测脚本
更多请点击: https://intelliparadigm.com 第一章:R 4.5边缘部署黄金标准的演进与IEEE IoT Journal认证背景 R 4.5标志着统计计算环境向轻量化、低延迟、高可信边缘推理场景的关键跃迁。其核心突破在于将完整的CRAN生态压缩至<12MB运行时镜像&#x…...

小米开源实时视觉语言动作模型Xiaomi-Robotics-0解析
1. 项目背景与技术定位小米机器人实验室最新开源的Xiaomi-Robotics-0项目,本质上是一个面向具身智能(Embodied AI)领域的多模态决策系统。这个实时视觉语言动作模型(Real-time Vision-Language-Action Model)的发布&am…...

KubeSphere Helm Charts 仓库深度解析:生产级Chart设计与高级模板技巧
1. 项目概述与核心价值 如果你正在或计划在 Kubernetes 上构建应用,那么“Helm”这个名字对你来说一定不陌生。它被称作 Kubernetes 的“包管理器”,就像 Ubuntu 里的 apt 或 CentOS 里的 yum,能让你用一条命令就部署起一套复杂的应用。但 H…...

UniFusion多模态生成框架:统一编码与实战优化
1. 项目背景与核心价值最近在AIGC领域出现了一个很有意思的技术方向——UniFusion。这个框架的核心创新点在于用统一的视觉语言编码器来处理多模态生成任务。传统方案通常需要为不同模态训练独立的编码器,不仅计算资源消耗大,而且跨模态对齐效果往往不理…...

D3.js 分组条形图动态更新的艺术
在数据可视化领域,D3.js 无疑是创建动态、交互式图表的强大工具。今天,我们将探讨如何使用 D3.js 创建一个动态更新的分组条形图,并解决常见的问题,如旧数据的堆叠和新数据的显示。 问题背景 假设我们有两个不同的测试结果数据集&…...

二进制文件瘦身实战:bfc工具原理、优化策略与工程实践
1. 项目概述:一个为二进制文件“瘦身”的瑞士军刀如果你经常和编译后的二进制文件打交道,尤其是那些用Go、Rust或者C写的大型项目,肯定对最终产物体积的“膨胀”深有体会。一个简单的命令行工具,动辄几十兆,分发起来麻…...