大数据技术原理(三):HDFS 最全面的 API 操作,你值得收藏
(实验二 熟悉常用的HDFS操作)
--------------------------------------------------------------------------------------------------------------------------------
一、实验目的
1.理解 HDFS在 Hadoop体系结构中的角色。
HDFS是一个分布式文件系统,设计用来存储大规模数据集(terabytes或petabytes)并运行在商用硬件集群上。它是Hadoop生态系统的核心组件,为上层的大数据处理工具(如MapReduce,Hive,HBase等)提供了数据存储和数据访问功能。
2.熟练使用 HDFS操作常用的 Shell命令。
熟练使用HDFS操作常用的Shell命令:HDFS提供了一套丰富的Shell命令,用于文件系统的操作。这些命令包括创建和删除目录,上传和下载文件,查看文件内容等。通过这个实验,你可以学习和掌握这些命令的使用。
3.熟悉HDFS操作常用的 JavaAPI。
熟悉HDFS操作常用的Java API:除了Shell命令,HDFS提供了一套Java API,开发者通过编程的方式操作HDFS。这套API提供了更灵活强大的功能,例如读写文件,获取文件系统的状态等。通过这个实验,你可以学习如何使用这套API来编写自己的Hadoop程序。
二、实验环境
1. VMware WorkStation Pro 16
2. Jdk 1.8.0_241
3. Hadoop2.7.5
三、实验原理
四、实验步骤与实验结果
(一)启动Hadoop服务,检查伪分布式和编程工具状况。
1.启动Hadoop各个组件的服务。
| # 切换到启动脚本文件的目录 cd /export/server/hadoop-2.7.5/sbin # 启动hadoop各组件服务 ./start-all.sh # 查看服务进程 jps |

2.登录hdfs的UI界面,查看目录li-qi-liang。
| # 在浏览器中输入 192.168.88.100:50070 |
3.在IDEA中导入父工程项目Class_3的pom文件。
| <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.itcast</groupId> <artifactId>Class_3</artifactId> <version>1.0-SNAPSHOT</version> <modules> <module>Experence</module> </modules> <packaging>pom</packaging> <properties> <encoding.version>UTF-8</encoding.version> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <java.version>1.8</java.version> <scala.version>2.11.12</scala.version> <scala.binary.version>2.11</scala.binary.version> <hadoop.version>2.7.5</hadoop.version> <hbase.version>2.1.5</hbase.version> <phoenix.version>5.0.0-HBase-2.0</phoenix.version> <hive.version>2.1.1</hive.version> <flink.version>1.10.0</flink.version> <log4j.version>1.7.7</log4j.version> <logback.version>1.1.3</logback.version> <kafka.version>1.0.0</kafka.version> <json.version>20190722</json.version> <fastjson.version>1.2.78</fastjson.version> <jackson.version>2.10.1</jackson.version> <mysql.version>5.1.47</mysql.version> <mongodb-driver.version>3.4.2</mongodb-driver.version> <jedis.version>2.9.0</jedis.version> <spring-boot.version>2.1.13.RELEASE</spring-boot.version> <mybatis-spring.version>2.1.1</mybatis-spring.version> <lombok.version>1.18.12</lombok.version> <springfox-version>2.9.2</springfox-version> <gson.version>2.8.6</gson.version> <druid.version>1.1.12</druid.version> <httpclient.version>4.5.12</httpclient.version> <httpcore.version>4.4.5</httpcore.version> <httpasyncclient.version>4.1.4</httpasyncclient.version> <geodesy.version>1.1.3</geodesy.version> <guava.version>23.0</guava.version> <scala-maven-plugin.version>4.0.2</scala-maven-plugin.version> <maven-compiler-plugin.version>3.6.1</maven-compiler-plugin.version> <maven-assembly-plugin.version>2.6</maven-assembly-plugin.version> <maven-shade-plugin.version>3.1.1</maven-shade-plugin.version> </properties> </project> |
4.在IDEA中导入子工程项目Experience的pom文件。
| <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>Class_3</artifactId> <groupId>cn.itcast</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>Experence</artifactId> <dependencies> <!-- Flink依赖的java语言环境 --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> </dependency> <!-- 批处理、流式应用程序 --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.11</artifactId> <version>${flink.version}</version> </dependency> <!-- flink jdbc--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-jdbc_2.11</artifactId> <version>${flink.version}</version> </dependency> <!--Hive JDBC--> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>${hive.version}</version> <exclusions> <exclusion> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-1.2-api</artifactId> </exclusion> <exclusion> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-web</artifactId> </exclusion> <exclusion> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-slf4j-impl</artifactId> </exclusion> </exclusions> </dependency> <!-- mysql 连接驱动依赖 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>${mysql.version}</version> </dependency> <!-- mongodb连接驱动依赖 --> <dependency> <groupId>org.mongodb</groupId> <artifactId>mongodb-driver</artifactId> <version>${mongodb-driver.version}</version> </dependency> <!-- Add the two required logback dependencies --> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-core</artifactId> <version>${logback.version}</version> </dependency> <dependency> <groupId>ch.qos.logback</groupId> <artifactId>logback-classic</artifactId> <version>${logback.version}</version> </dependency> <!-- Add the log4j -> sfl4j (-> logback) bridge into the classpath Hadoop is logging to log4j! --> <dependency> <groupId>org.slf4j</groupId> <artifactId>log4j-over-slf4j</artifactId> <version>${log4j.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-yarn-api</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>cn.itcast</groupId> <artifactId>Experence</artifactId> <version>1.0-SNAPSHOT</version> <scope>compile</scope> </dependency> </dependencies> <!-- 项目编译、打包插件配置 --> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>3.1.1</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <artifactSet> <excludes> <exclude>com.google.code.findbugs:jsr305</exclude> <exclude>org.slf4j:*</exclude> <exclude>log4j:*</exclude> </excludes> </artifactSet> <filters> <filter> <!-- Do not copy the signatures in the META-INF folder. Otherwise, this might cause SecurityExceptions when using the JAR. --> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>my.programs.main.clazz</mainClass> </transformer> </transformers> </configuration> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>8</source> <target>8</target> </configuration> </plugin> </plugins> </build> </project> |
5.在Windows中导入Hadoop2.7.5的bin目录文件。
| # A.准备Hadoop2.7.5的windows版本的bin目录文件 # B.配置Hadoop2.7.5的bin目录的系统环境变量 # C.重启windows系统 |



(二)编程实现以下指定功能,并利用Hadoop提供的Shell命令完成相同的任务。
1.向HDFS 中上传任意文本文件,如果指定的文件在 HDFS 中已经存在,由用户指定是追加到原有文件末尾还是覆盖原有的文件。
(1)shell版本
| # A.准备数据 hadoop fs -put ./data.txt /li-qi-liang/ hadoop fs -ls /li-qi-liang |

| # B.文件存在时,覆盖数据 hadoop fs -put -f ./data.txt /li-qi-liang/ hadoop fs -cat /li-qi-liang/data.txt |

| # C.文件存在时,追加数据 hadoop fs -appendToFile ./data.txt /li-qi-liang/ hadoop fs -cat /li-qi-liang/data.txt |

(2)Java版本
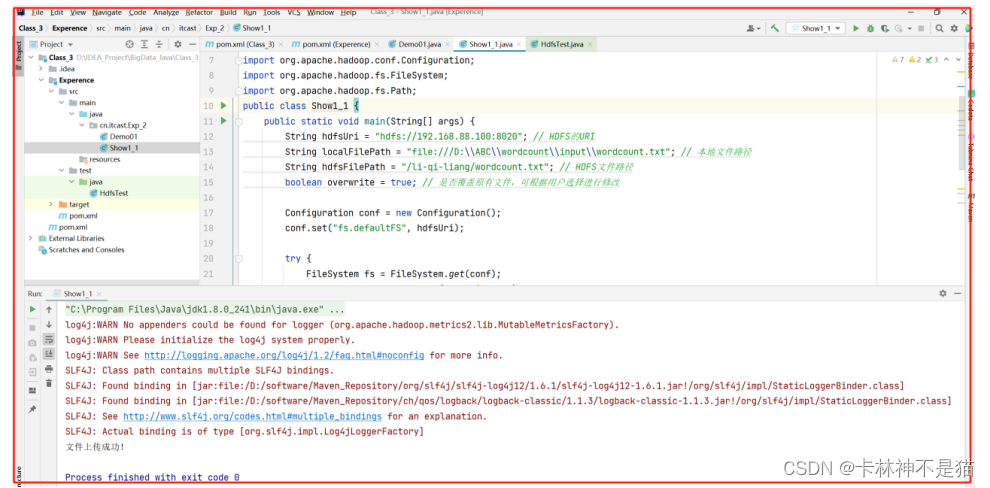
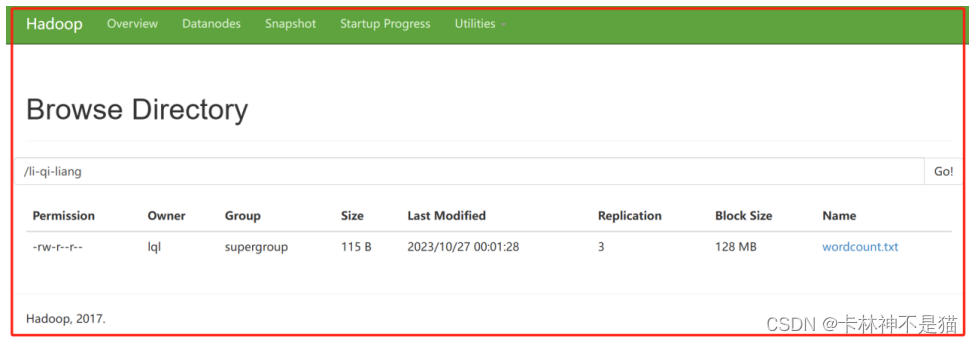
| package cn.itcast.Exp_2; /** * @author lql * @time 2023-10-27 00:05:45 * @description TODO */ import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class Show1_1 { public static void main(String[] args) { String hdfsUri = "hdfs://192.168.88.100:8020"; // HDFS的URI String localFilePath = "file:///D:\\ABC\\wordcount\\input\\wordcount.txt"; // 本地文件路径 String hdfsFilePath = "/li-qi-liang/wordcount.txt"; // HDFS文件路径 boolean overwrite = true; // 是否覆盖原有文件,可根据用户选择进行修改 Configuration conf = new Configuration(); conf.set("fs.defaultFS", hdfsUri); try { FileSystem fs = FileSystem.get(conf); Path localPath = new Path(localFilePath); Path hdfsPath = new Path(hdfsFilePath); if (fs.exists(hdfsPath)) { if (overwrite) { fs.delete(hdfsPath, false); // 覆盖原有文件,删除原有文件 System.out.println("已覆盖原有文件:" + hdfsFilePath); } else { fs.append(hdfsPath); // 追加到原有文件末尾 System.out.println("已追加到原有文件末尾:" + hdfsFilePath); } } fs.copyFromLocalFile(false, true, localPath, hdfsPath); System.out.println("文件上传成功!"); } catch (Exception e) { e.printStackTrace(); } } } |
2.从 HDFS 中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名。
(1)shell版本
| # A.准备数据 hadoop fs -put ./data.txt /li-qi-liang/ hadoop fs -ls /li-qi-liang |

| # B.本地文件存在data.txt,因此需要自动将文件重命名为data_1.txt hadoop fs -copyToLocal /li-qi-liang/data.txt ./data_1.txt |

(2)Java版本
| package cn.itcast.Exp_2; /** * @author lql * @time 2023-10-27 00:07:59 * @description TODO */ import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.IOException; public class Show1_2 { public static void main(String[] args) { String hdfsUri = "hdfs://192.168.88.100:8020"; // HDFS的URI,指定Hadoop集群的地址和端口 String hdfsFilePath = "/li-qi-liang/wordcount.txt"; // 要下载的文件在HDFS中的路径 String localFilePath = "D:\\ABC\\wordcount\\output\\output.txt"; // 下载后保存到本地的文件路径 String localFileName = "output.txt"; // 下载后保存到本地的文件名 boolean renameIfExists = true; // 如果本地文件与要下载的文件名称相同,是否自动对下载的文件重命名 Configuration conf = new Configuration(); // 创建Hadoop配置对象 conf.set("fs.defaultFS", hdfsUri); // 设置HDFS的URI try { FileSystem fs = FileSystem.get(conf); // 获取FileSystem实例,用于操作HDFS文件系统 Path hdfsPath = new Path(hdfsFilePath); // 创建HDFS文件路径对象 Path localPath = new Path(localFilePath); // 创建本地文件路径对象 String fileName = hdfsPath.getName(); // 获取要下载的文件名 if (renameIfExists && localPath.toUri().getPath().endsWith(fileName)) { // 如果需要重命名,并且本地文件路径与要下载的文件名相同 String nameWithoutExt = fileName.substring(0, fileName.lastIndexOf(".")); // 获取文件名(不包括扩展名) String extension = fileName.substring(fileName.lastIndexOf(".")); // 获取文件的扩展名 localPath = new Path(localPath.getParent(), nameWithoutExt + "_downloaded" + extension); // 生成新的本地文件路径 System.out.println("已将下载的文件重命名为:" + localPath.getName()); // 输出重命名后的文件名 } if (fs.exists(hdfsPath)) { // 检查要下载的文件是否存在于HDFS中 fs.copyToLocalFile(false, hdfsPath, localPath); // 将HDFS文件复制到本地文件系统 System.out.println("文件下载成功,已保存到本地:" + localPath.toUri().getPath()); // 输出下载成功的消息 } else { System.out.println("要下载的文件不存在:" + hdfsFilePath); // 输出文件不存在的消息 } } catch (IOException e) { e.printStackTrace(); } } } |

3.将HDFS中指定文件的内容输出到终端。
(1)shell版本
| # A.准备数据 hadoop fs -put ./data.txt /li-qi-liang/ hadoop fs -ls /li-qi-liang |

| # B.将HDFS指定文件的内容输出到终端 hadoop fs -cat /li-qi-liang/data.txt |

(2)Java版本
| package cn.itcast.Exp_2; /** * @author lql * @time 2023-10-27 00:10:59 * @description TODO */ import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.Path; import java.io.BufferedReader; import java.io.InputStreamReader; public class Show1_3 { public static void main(String[] args) { String hdfsUri = "hdfs://192.168.88.100:8020"; // HDFS的URI,指定Hadoop集群的地址和端口 String hdfsFilePath = "/li-qi-liang/wordcount.txt"; // 要读取的文件在HDFS中的路径 Configuration conf = new Configuration(); // 创建Hadoop配置对象 conf.set("fs.defaultFS", hdfsUri); // 设置HDFS的URI try { FileSystem fs = FileSystem.get(conf); // 获取FileSystem实例,用于操作HDFS文件系统 Path hdfsPath = new Path(hdfsFilePath); // 创建HDFS文件路径对象 if (fs.exists(hdfsPath)) { // 检查要读取的文件是否存在于HDFS中 FSDataInputStream inputStream = fs.open(hdfsPath); // 打开HDFS文件输入流 BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream)); // 创建缓冲读取器 String line; while ((line = reader.readLine()) != null) { // 逐行读取文件内容 System.out.println(line); // 打印每行内容 } reader.close(); // 关闭读取器 inputStream.close(); // 关闭输入流 } else { System.out.println("要读取的文件不存在:" + hdfsFilePath); // 输出文件不存在的消息 } } catch (Exception e) { e.printStackTrace(); } } } |

4.显示 HDFS 中指定的文件读写权限、大小、创建时间、路径等信息。
(1)shell版本
| # A.准备数据 hadoop fs -put ./data.txt /li-qi-liang/ hadoop fs -ls /li-qi-liang |

| # B.显示 HDFS 中指定的文件读写权限、大小、创建时间、路径等信息。 hadoop fs -ls -h /li-qi-liang/data.txt # 或者:查看目录下文件 Hadoop fs -ls /li-qi-liang/ |

(2)Java版本
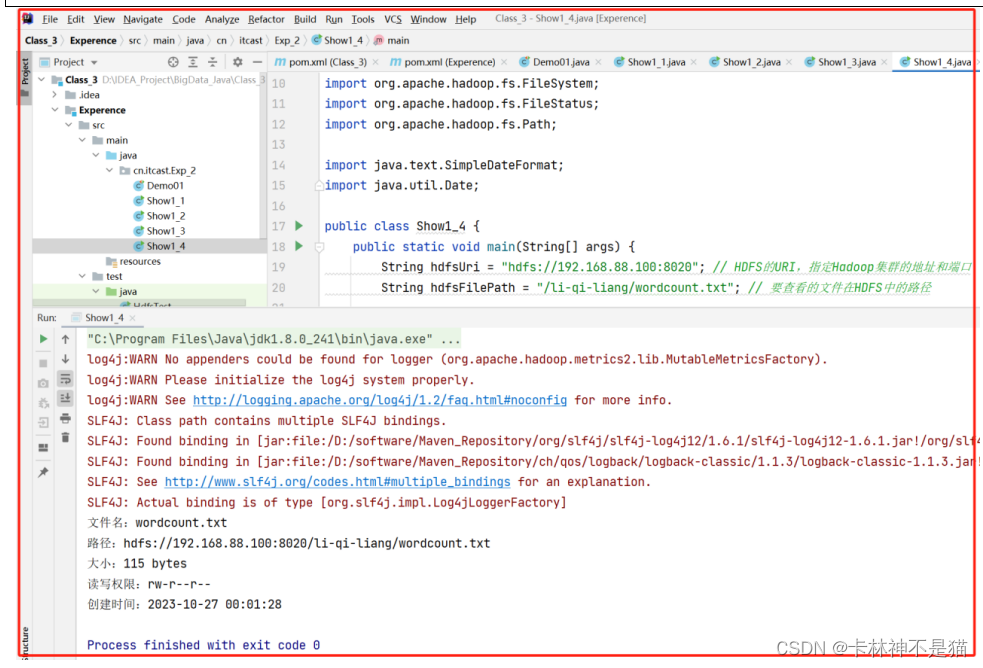
| package cn.itcast.Exp_2; /** * @author lql * @time 2023-10-27 00:26:01 * @description TODO */ import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.Path; import java.text.SimpleDateFormat; import java.util.Date; public class Show1_4 { public static void main(String[] args) { String hdfsUri = "hdfs://192.168.88.100:8020"; // HDFS的URI,指定Hadoop集群的地址和端口 String hdfsFilePath = "/li-qi-liang/wordcount.txt"; // 要查看的文件在HDFS中的路径 Configuration conf = new Configuration(); // 创建Hadoop配置对象 conf.set("fs.defaultFS", hdfsUri); // 设置HDFS的URI try { FileSystem fs = FileSystem.get(conf); // 获取FileSystem实例,用于操作HDFS文件系统 Path hdfsPath = new Path(hdfsFilePath); // 创建HDFS文件路径对象 if (fs.exists(hdfsPath)) { // 检查要查看的文件是否存在于HDFS中 FileStatus status = fs.getFileStatus(hdfsPath); // 获取文件的元数据信息 SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); // 创建日期格式化器 System.out.println("文件名:" + status.getPath().getName()); // 输出文件名 System.out.println("路径:" + status.getPath()); // 输出路径 System.out.println("大小:" + status.getLen() + " bytes"); // 输出文件大小 System.out.println("读写权限:" + status.getPermission()); // 输出文件读写权限 System.out.println("创建时间:" + dateFormat.format(new Date(status.getModificationTime()))); // 输出文件创建时间 } else { System.out.println("要查看的文件不存在:" + hdfsFilePath); // 输出文件不存在的消息 } } catch (Exception e) { e.printStackTrace(); } } } |
5.给定HDFS中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息。
(1)shell版本
| # A.准备数据 hadoop fs -put ./data.txt /li-qi-liang/ hadoop fs -ls /li-qi-liang |
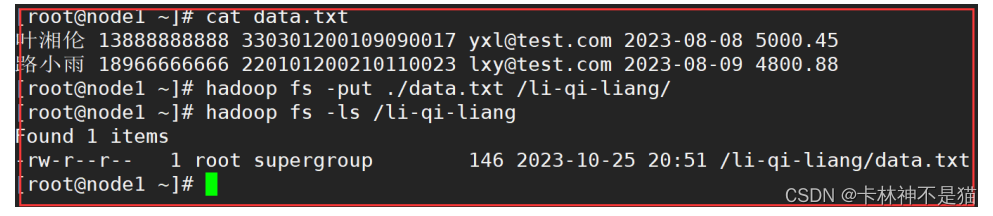
| # B.递归输出hdfs根目录下面所有文件信息 hadoop fs -ls -R -h / |

(2)Java版本
| package cn.itcast.Exp_2; /** * @author lql * @time 2023-10-27 00:29:33 * @description TODO */ import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.FileStatus; import org.apache.hadoop.fs.Path; import java.text.SimpleDateFormat; import java.util.Date; public class Show1_5 { public static void main(String[] args) { String hdfsUri = "hdfs://192.168.88.100:8020"; // HDFS的URI,指定Hadoop集群的地址和端口 String hdfsDirPath = "/"; // 要查看的目录在HDFS中的路径 Configuration conf = new Configuration(); // 创建Hadoop配置对象 conf.set("fs.defaultFS", hdfsUri); // 设置HDFS的URI try { FileSystem fs = FileSystem.get(conf); // 获取FileSystem实例,用于操作HDFS文件系统 Path hdfsDir = new Path(hdfsDirPath); // 创建HDFS目录路径对象 if (fs.exists(hdfsDir)) { // 检查要查看的目录是否存在于HDFS中 showDir(fs, hdfsDir); // 输出目录下所有文件的相关信息 } else { System.out.println("要查看的目录不存在:" + hdfsDirPath); // 输出目录不存在的消息 } } catch (Exception e) { e.printStackTrace(); } } private static void showDir(FileSystem fs, Path dir) throws Exception { FileStatus[] statusList = fs.listStatus(dir); // 获取目录下的所有文件和子目录的元数据信息 for (FileStatus status : statusList) { // 遍历目录下的所有文件和子目录 if (status.isDirectory()) { // 如果是子目录 showDir(fs, status.getPath()); // 递归输出子目录下所有文件的相关信息 } else { // 如果是文件 SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); // 创建日期格式化器 System.out.println("文件名:" + status.getPath().getName()); // 输出文件名 System.out.println("路径:" + status.getPath()); // 输出路径 System.out.println("大小:" + status.getLen() + " bytes"); // 输出文件大小 System.out.println("读写权限:" + status.getPermission()); // 输出文件读写权限 System.out.println("创建时间:" + dateFormat.format(new Date(status.getModificationTime()))); // 输出文件创建时间 System.out.println(); // 输出空行,用于分隔不同文件的信息 } } } } |

6.提供一个 HDFS 内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在、则自动创建目录。
(1)shell版本
| # A.准备数据 hadoop fs -put ./data.txt /li-qi-liang/ hadoop fs -ls /li-qi-liang |

| # B.创建文件 hadoop fs -touch /li-qi-liang/data_touch.txt hadoop fs -ls /li-qi-liang/ |

| # C.删除文件 hadoop fs -rm /li-qi-liang/data_touch.txt hadoop fs -ls /li-qi-liang/ # 注意:-rm -rf -skipTrash(这样才可以不走回收站) |

| # D.递归创建目录 hadoop fs -mkdir -p /li-qi-liang/JJ-Lin hadoop fs -ls /li-qi-liang/ |

(2)Java版本
| package cn.itcast.Exp_2; /** * @author lql * @time 2023-10-27 08:17:53 * @description TODO:提供一个 HDFS 内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录存在、则自动创建目录。 */ import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.IOException; public class Show1_6 { public static void main(String[] args) { String hdfsUri = "hdfs://192.168.88.100:8020"; // HDFS的URI,指定Hadoop集群的地址和端口 String filePath = "/li-qi-liang/test.txt"; // 要创建或删除的文件路径 Configuration conf = new Configuration(); // 创建Hadoop配置对象 conf.set("fs.defaultFS", hdfsUri); // 设置HDFS的URI try { FileSystem fs = FileSystem.get(conf); // 获取FileSystem实例,用于操作HDFS文件系统 // 创建文件 createFile(fs, filePath); // 删除文件 deleteFile(fs, filePath); } catch (IOException e) { e.printStackTrace(); } } private static void createFile(FileSystem fs, String filePath) throws IOException { Path file = new Path(filePath); // 创建文件路径对象 if (!fs.exists(file.getParent())) { // 检查文件所在目录是否存在,如果不存在则创建目录 fs.mkdirs(file.getParent()); } fs.create(file).close(); // 创建文件 System.out.println("文件已成功创建:" + filePath); } private static void deleteFile(FileSystem fs, String filePath) throws IOException { Path file = new Path(filePath); // 创建文件路径对象 boolean isDeleted = fs.delete(file, false); // 删除文件,第二个参数指定是否递归删除子目录,默认为false if (isDeleted) { System.out.println("文件已成功删除:" + filePath); } else { System.out.println("文件删除失败:" + filePath); } } } |

7.提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否删除该目录。
(1)shell版本
| # A.准备数据 hadoop fs -put ./data.txt /li-qi-liang/ hadoop fs -ls /li-qi-liang |
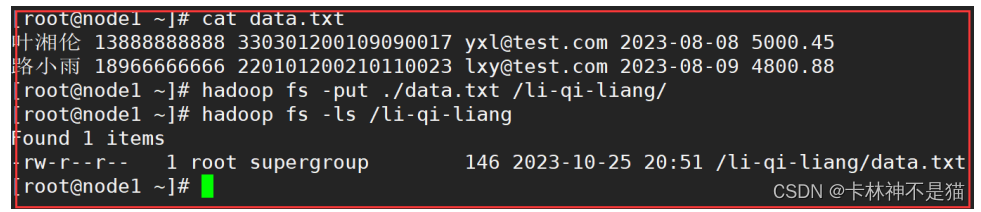
| # B.递归创建目录 hadoop fs -mkdir -p /li-qi-liang/JJ-Lin hadoop fs -ls /li-qi-liang/ |

| # C.普通删除目录 hadoop fs -rmdir /li-qi-liang/JJ-Lin(如果非空,提示not empty,不删除) |

| # D.强制删除 hadoop fs -rm -r ls /li-qi-liang/JJ-Lin(强制删除目录) |

(2)Java版本
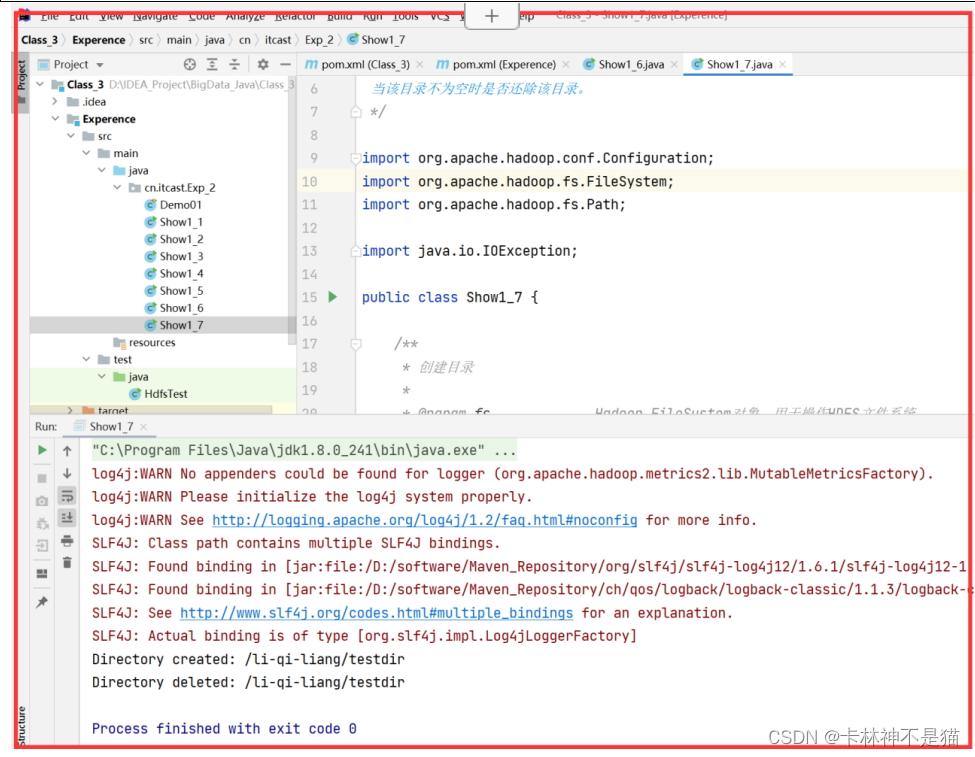
| package cn.itcast.Exp_2; /** * @author lql * @time 2023-10-27 08:25:49 * @description TODO:提供一个HDFS的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目文件所在目录不存在则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还除该目录。 */ import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.IOException; public class Show1_7 { /** * 创建目录 * * @param fs Hadoop FileSystem对象,用于操作HDFS文件系统 * @param directoryPath 要创建的目录路径 * @throws IOException 如果发生I/O错误 */ public static void createDirectory(FileSystem fs, String directoryPath) throws IOException { Path directory = new Path(directoryPath); // 检查目录所在的父目录是否存在,如果不存在则递归地创建父目录 if (!fs.exists(directory.getParent())) { fs.mkdirs(directory.getParent()); } // 如果目录不存在,则创建目录;如果目录已经存在,则不进行任何操作 if (!fs.exists(directory)) { fs.mkdirs(directory); System.out.println("Directory created: " + directoryPath); } else { System.out.println("Directory already exists: " + directoryPath); } } /** * 删除目录 * * @param fs Hadoop FileSystem对象,用于操作HDFS文件系统 * @param directoryPath 要删除的目录路径 * @param recursive 是否递归删除非空目录 * @throws IOException 如果发生I/O错误 */ public static void deleteDirectory(FileSystem fs, String directoryPath, boolean recursive) throws IOException { Path directory = new Path(directoryPath); // 如果目录存在,则删除目录 if (fs.exists(directory)) { boolean deleted = fs.delete(directory, recursive); if (deleted) { System.out.println("Directory deleted: " + directoryPath); } else { System.out.println("Failed to delete directory: " + directoryPath); } } else { System.out.println("Directory does not exist: " + directoryPath); } } public static void main(String[] args) { String hdfsUri = "hdfs://192.168.88.100:8020"; // HDFS的URI,指定Hadoop集群的地址和端口 String directoryPath = "/li-qi-liang/testdir"; // 要创建或删除的目录路径 boolean deleteNonEmptyDirectory = true; // 是否删除非空目录 Configuration conf = new Configuration(); // 创建Hadoop配置对象 conf.set("fs.defaultFS", hdfsUri); // 设置HDFS的URI try { FileSystem fs = FileSystem.get(conf); // 获取FileSystem实例,用于操作HDFS文件系统 // 创建目录 createDirectory(fs, directoryPath); // 删除目录 deleteDirectory(fs, directoryPath, deleteNonEmptyDirectory); } catch (IOException e) { e.printStackTrace(); } } } |
8.向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾。
(1)shell版本
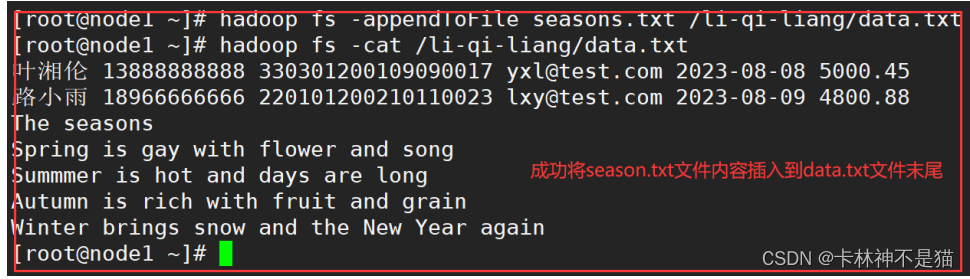
| # A.准备数据(一份本地数据seasons.txt,一份hdfs文件data,txt) hadoop fs -put ./data.txt /li-qi-liang/ hadoop fs -cat /li-qi-liang/data.txt cd ./seasons.txt |

| # B.本地seasons.txt文件追加到hdfs中data.txt文件结尾 hadoop fs -appendToFile seasons.txt /li-qi-liang/data.txt hadoop fs -cat /li-qi-liang/data.txt |
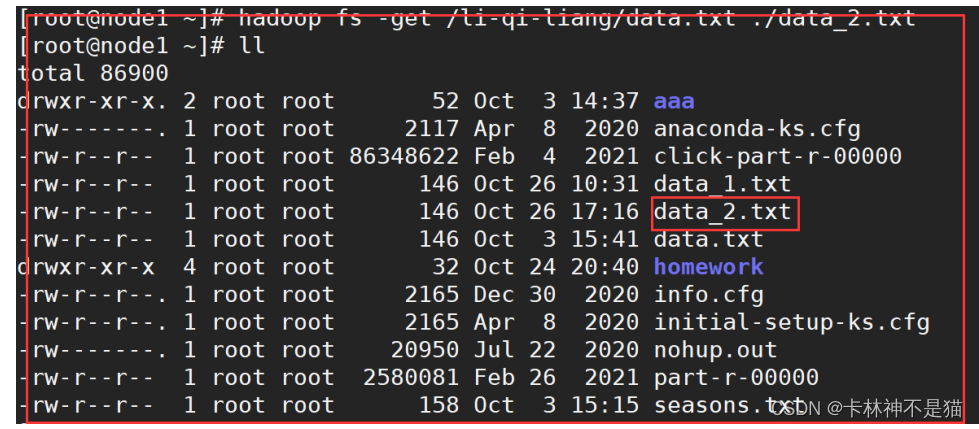
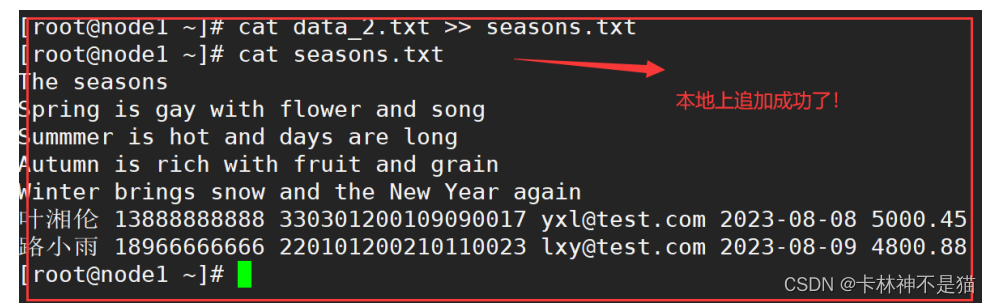
| # C.本地seasons.txt文件追加到hdfs中data.txt文件头部 (思路:a.先将hdfs中文件data.txt下载到本地,作为data_2.txt B.再将本地data_2.txt追加到本地seasons.txt文件末尾, C.然后将本地最新seasons.txt文件覆盖拷贝hdfs文件data.txt中) hadoop fs -get /li-qi-liang/data.txt ./data_2.txt cat ./data_2.txt >> ./seasons.txt hadoop fs -copyFromLocal -f seasons.txt /li-qi-liang/data.txt hadoop fs -cat /li-qi-liang/data.txt(将结果输出到终端检查!) |

(2)Java版本
| package cn.itcast.Exp_2; /** * @author lql * @time 2023-10-27 08:35:08 * @description TODO:向HDFS中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾。 */ import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.IOException; import java.io.InputStreamReader; import java.io.OutputStreamWriter; public class Show1_8 { /** * 向文件开头追加内容 * * @param fs Hadoop FileSystem对象,用于操作HDFS文件系统 * @param filePath 文件路径 * @param content 要追加的内容 * @throws IOException 如果发生I/O错误 */ public static void appendToBeginning(FileSystem fs, String filePath, String content) throws IOException { Path file = new Path(filePath); // 读取原有文件内容 BufferedReader reader = new BufferedReader(new InputStreamReader(fs.open(file))); StringBuilder sb = new StringBuilder(); String line; while ((line = reader.readLine()) != null) { sb.append(line).append("\n"); } reader.close(); // 将要追加的内容添加到原有文件内容的开头 sb.insert(0, content + "\n"); // 写入更新后的内容到文件 BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(fs.create(file, true))); writer.write(sb.toString()); writer.close(); System.out.println("Content appended to beginning of file: " + filePath); } /** * 向文件结尾追加内容 * * @param fs Hadoop FileSystem对象,用于操作HDFS文件系统 * @param filePath 文件路径 * @param content 要追加的内容 * @throws IOException 如果发生I/O错误 */ public static void appendToEnd(FileSystem fs, String filePath, String content) throws IOException { Path file = new Path(filePath); // 写入追加的内容到文件结尾 BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(fs.append(file))); writer.write(content + "\n"); writer.close(); System.out.println("Content appended to end of file: " + filePath); } /** * 打印文件内容 * * @param fs Hadoop FileSystem对象,用于操作HDFS文件系统 * @param filePath 文件路径 * @throws IOException 如果发生I/O错误 */ public static void printFileContent(FileSystem fs, String filePath) throws IOException { Path file = new Path(filePath); BufferedReader reader = new BufferedReader(new InputStreamReader(fs.open(file))); String line; while ((line = reader.readLine()) != null) { System.out.println(line); } reader.close(); } public static void main(String[] args) { String hdfsUri = "hdfs://192.168.88.100:8020"; // HDFS的URI,指定Hadoop集群的地址和端口 String filePath = "/li-qi-liang/wordcount.txt"; // 文件路径 String content = "This is the content to be appended"; // 要追加的内容 Configuration conf = new Configuration(); // 创建Hadoop配置对象 conf.set("fs.defaultFS", hdfsUri); // 设置HDFS的URI conf.set("fs.replication","1");// 设置副本数目为1 conf.set("dfs.client.block.write.replace-datanode-on-failure.policy","NEVER");// 执行永不替换节点 conf.set("dfs.client.block.write.replace-datanode-on-failure.enable","true");//开启替换节点功能 try { FileSystem fs = FileSystem.get(conf); // 获取FileSystem实例,用于操作HDFS文件系统 // 原文件的内容 System.out.println("Original file content:"); printFileContent(fs, filePath); // 向文件开头追加内容 appendToBeginning(fs, filePath, content); System.out.println("File content after appending to beginning:"); printFileContent(fs, filePath); // 向文件结尾追加内容 appendToEnd(fs, filePath, content); System.out.println("File content after appending to end:"); printFileContent(fs, filePath); } catch (IOException e) { e.printStackTrace(); } } } |

9.删除HDFS中指定的文件。
(1)shell版本
| # A.准备数据 hadoop fs -put ./data.txt /li-qi-liang/ hadoop fs -ls /li-qi-liang/ |
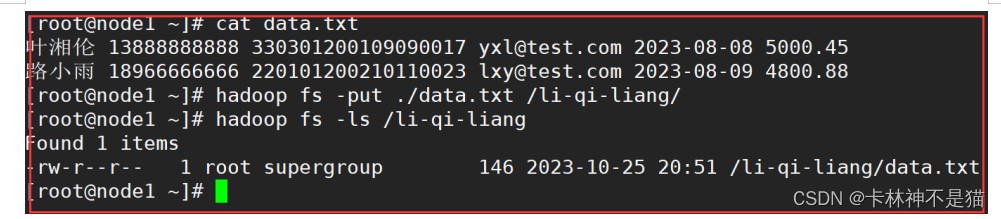
| # B.删除hdfs中指定文件 hadoop fs -rm -f /li-qi-liang/data.txt hadoop fs -ls /li-qi-liang/ # 或者:强制删除不走回收站(-rm -f -skipTrash) |

(2)Java版本
| package cn.itcast.Exp_2; /** * @author lql * @time 2023-10-27 09:18:31 * @description TODO:删除HDFS中指定的文件。 */ import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class Show1_9 { public static void main(String[] args) { // 创建Hadoop配置对象 Configuration conf = new Configuration(); try { // 设置HDFS的URI conf.set("fs.defaultFS", "hdfs://192.168.88.100:8020"); // 创建FileSystem对象 FileSystem fs = FileSystem.get(conf); // 要删除的文件路径 Path filePath = new Path("/li-qi-liang/wordcount.txt"); // 删除文件 boolean deleted = fs.delete(filePath, false); // 第二个参数表示是否递归删除目录 if (deleted) { System.out.println("文件删除成功!"); } else { System.out.println("文件删除失败或文件不存在!"); } // 关闭FileSystem连接 fs.close(); } catch (Exception e) { e.printStackTrace(); } } } |

10.在 HDFS中将文件从源路径移动到目的路径。
(1)shell版本
| # A.准备数据 hadoop fs -put ./data.txt /li-qi-liang/ hadoop fs -put ./seasons.txt /BigData/ hadoop fs -ls /li-qi-liang/ hadoop fs -ls /BigData/ |

| # B.移动数据到同一目录(更改文件名) hadoop fs -mv /BigData/wordcount.txt /BigData/words.txt hadoop fs -ls /BigData/ |

| # C.移动数据到不同目录(文件移动) hadoop fs -mv /BigData/seasons.txt /li-qi-liang/ hadoop fs -ls /li-qi-liang/ |

(2)Java版本
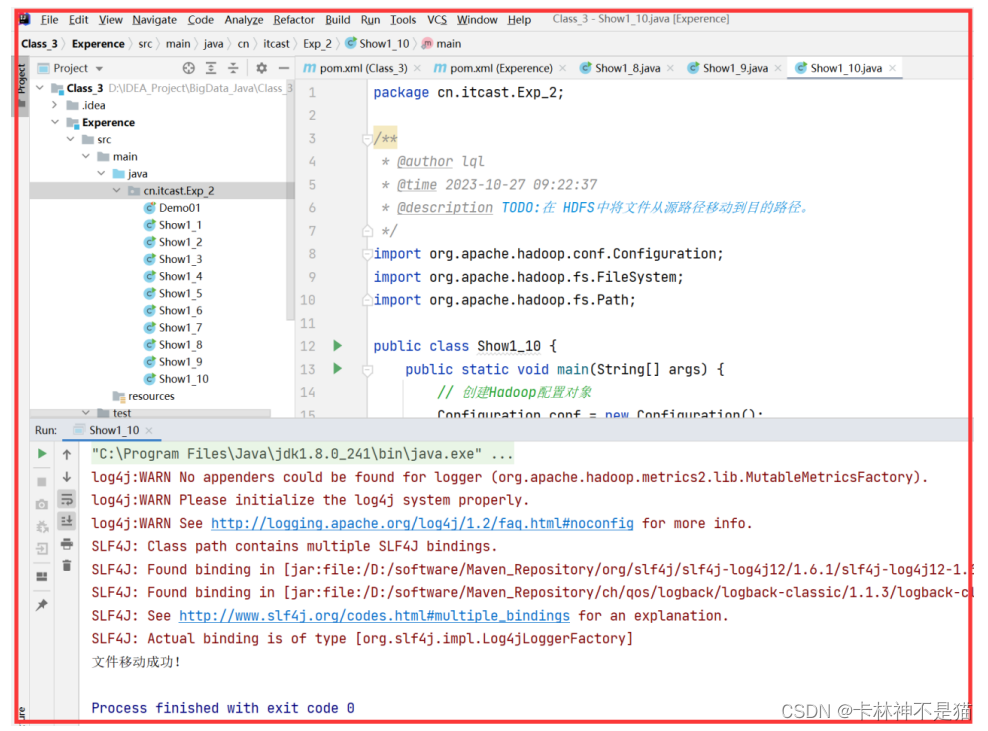
| package cn.itcast.Exp_2; /** * @author lql * @time 2023-10-27 09:22:37 * @description TODO:在 HDFS中将文件从源路径移动到目的路径。 */ import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class Show1_10 { public static void main(String[] args) { // 创建Hadoop配置对象 Configuration conf = new Configuration(); try { // 设置HDFS的URI conf.set("fs.defaultFS", "hdfs://192.168.88.100:8020"); conf.set("fs.replication","1"); // 创建FileSystem对象 FileSystem fs = FileSystem.get(conf); // 源文件路径 Path sourcePath = new Path("/BigData/words.txt"); // 目标文件路径 Path destinationPath = new Path("/li-qi-liang/dest.txt"); // 移动文件(相当于剪切文件) boolean moved = fs.rename(sourcePath, destinationPath); if (moved) { System.out.println("文件移动成功!"); } else { System.out.println("文件移动失败或源文件不存在!"); } // 关闭FileSystem连接 fs.close(); } catch (Exception e) { e.printStackTrace(); } } } |
(二)编程实现一个类“MyFSDataInputStream”,该类继承“org.apache.hadoop.fs.FSDataInpuStream”
1.实现按行读取HDFS中指定文件的方法“readLine()",如果读到文件末尾,则返回空,否则返回文件一行的文本。
实现缓存功能,即利用“MyFSDataInputStream”读取若干字节数据时,首先查找缓存,如果缓存中有所需数据,则直接由缓存提供,否则向 HDFS读取数据。
| package cn.itcast.Exp_2; /** * @author lql * @time 2023-10-27 09:38:28 * @description TODO:实现按行读取HDFS中指定文件的方法“readLine()",如果读到文件末尾,则返回空,否则返回文件一行的文本。实现缓存功能,即利用“MyFSDataInputStream”读取若干字节数据时,首先查找缓存,如果缓存中有所需数据,则直接由缓存提供,否则向 HDFS读取数据。 */ import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.IOException; import java.util.ArrayList; import java.util.List; public class MyFSDataInputStream extends FSDataInputStream { private static final int BUFFER_SIZE = 1024; private List<String> cache; private long currentPosition; public MyFSDataInputStream(FileSystem fs, Path file) throws IOException { super(fs.open(file)); this.cache = new ArrayList<>(); this.currentPosition = 0; } /** * 读取文件的下一行内容 * * @return 下一行的内容,如果已经到达文件末尾则返回null * @throws IOException 如果读取文件内容失败 */ public String readNextLine() throws IOException { if (super.available() <= 0) { return null; // 已到达文件末尾 } if (cache.isEmpty() || currentPosition >= cache.size()) { fillCache(); // 填充缓存 } return cache.get((int) currentPosition++); } private void fillCache() throws IOException { cache.clear(); byte[] buffer = new byte[BUFFER_SIZE]; StringBuilder line = new StringBuilder(); int bytesRead; while ((bytesRead = read(buffer)) != -1) { for (int i = 0; i < bytesRead; i++) { char c = (char) buffer[i]; if (c == '\n') { cache.add(line.toString()); // 将一行文本添加到缓存 line.setLength(0); // 清空StringBuilder } else { line.append(c); // 继续构建一行文本 } } } if (line.length() > 0) { cache.add(line.toString()); // 添加最后一行文本到缓存 } } public static void main(String[] args) { String hdfsUri = "hdfs://192.168.88.100:8020"; // HDFS的URI String filePath = "/li-qi-liang/dest.txt"; // HDFS中的文件路径 Configuration conf = new Configuration(); conf.set("fs.defaultFS", hdfsUri); try { FileSystem fs = FileSystem.get(conf); Path file = new Path(filePath); MyFSDataInputStream inputStream = new MyFSDataInputStream(fs, file); String line; int lineNumber = 1; while ((line = inputStream.readNextLine()) != null) { System.out.println("Line " + lineNumber++ + ": " + line); // 逐行打印文件内容 } if (lineNumber == 1) { System.out.println("The file is empty."); // 文件为空 } inputStream.close(); fs.close(); } catch (IOException e) { e.printStackTrace(); } } } |

2.查看Java帮助手册或其他资料,用"java.net.URL”和“org.apache.hadoop.fs.FsURLStreamHandlerFactory”编程来输出HDFS中指定文件的文本到终端中。
| package cn.itcast.Exp_2; /** * @author lql * @time 2023-10-27 14:00:00 * @description TODO:实查看Java帮助手册或其他资料,用"java.net.URL”和“org.apache.hadoop.fs.FsURLStreamHandlerFactory”编程来输出HDFS中指定文件的文本到终端中。 */ import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.URL; import java.net.URLConnection; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FsUrlStreamHandlerFactory; public class HDFSFileReader { public static void main(String[] args) { // 注册Hadoop的URL处理程序工厂 URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory()); String hdfsUri = "hdfs://192.168.88.100:8020"; // HDFS的URI String filePath = "/li-qi-liang/dest.txt"; // HDFS中的文件路径 Configuration conf = new Configuration(); conf.set("fs.defaultFS", hdfsUri); try { URL url = new URL(hdfsUri + filePath); URLConnection connection = url.openConnection(); BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream())); String line; while ((line = reader.readLine()) != null) { System.out.println(line); // 输出文件内容到终端 } reader.close(); } catch (IOException e) { e.printStackTrace(); } } } |

五、实验总结
(一)发现问题与解决问题
1.软件IDEA终端出现SLF4J警告消息

根据警告信息,属于少了log4j依赖,缺失配置log4j.properties文件,以及jar包冲突。
解决方法如下:
| # 引入log4j依赖 <!-- Add the log4j -> sfl4j (-> logback) bridge into the classpath Hadoop is logging to log4j! --> <dependency> <groupId>org.slf4j</groupId> <artifactId>log4j-over-slf4j</artifactId> <version>${log4j.version}</version> </dependency> |
| # 而在父工程pom包引入版本号 <log4j.version>1.7.7</log4j.version> |
| # 在log4j.properties文件中配置 log4j.rootLogger=debug, stdout, R log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout # Pattern to output the caller's file name and line number. log4j.appender.stdout.layout.ConversionPattern=%5p [%t] (%F:%L) - %m%n log4j.appender.R=org.apache.log4j.RollingFileAppender log4j.appender.R.File=example.log log4j.appender.R.MaxFileSize=100KB # Keep one backup file log4j.appender.R.MaxBackupIndex=5 log4j.appender.R.layout=org.apache.log4j.PatternLayout log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n |

2.在windows平台编译的Hadoop,报以下的错误:
| 缺少winutils.exe Could not locate executable null \bin\winutils.exe in the hadoop binaries 缺少hadoop.dll Unable to load native-hadoop library for your platform using builtin-Java classes where applicable 或者: java.io.IOException: (null) entry in command string: null chmod 0644 |
搭建步骤:
第一步:将已经编译好的Windows版本Hadoop解压到到一个没有中文没有空格的路径下面
第二步:在windows上面配置hadoop的环境变量: HADOOP_HOME,并将%HADOOP_HOME%\bin添加到path中

第三步:把hadoop2.7.5中bin下的hadoop.dll文件放到系统盘: C:\Windows\System32 目录下
第四步:关闭windows重启
3.客户端连接hadoop连接不上
| # 测试代码 /** * @author lql * @time 2023-10-26 08:10:02 * @description TODO */ import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; public class HdfsTest { public static void main(String[] args) { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://192.168.88.100:8020"); // 设置HDFS主机地址 try { FileSystem fs = FileSystem.get(conf); System.out.println("Connected to HDFS successfully."); fs.close(); } catch (Exception e) { System.out.println("Failed to connect to HDFS: " + e.getMessage()); } } } |
| # 出现报错 Call From LAPTOP-0S4T2RHI/10.107.100.56 to 192.168.88.100:9000 failed on connection exception: java.net.ConnectException: Connection refused: no further information; |
原因是:hadoop的通信端口号9000出现问题,在Hadoop集群中,NameNode和DataNode之间的通信端口号需要和配置文件中一致。
| # 查看hadoop中core-site.xml文件 <!-- 用于设置Hadoop的文件系统,由URI指定 --> <property> <name>fs.defaultFS</name> <value>hdfs://node1:8020</value> </property> |
最后将java代码中的9000更改为8020,即可运行连接成功!

4.copyFromLocalFile(false,true,localPath,hdfsPath)参数缺失
| # 参数说明: // boolean delSrc:指定是否删除源文件。如果设置为 true,则在复制完成后删除本地文件;如果设置为 false,则保留本地文件。 //boolean overwrite:指定是否覆盖目标文件。如果设置为 true,则如果目标文件已存在,则会被覆盖; // 如果设置为 false,则如果目标文件已存在,则会抛出异常。 //Path src:指定要复制的本地文件的路径。 //Path dst:指定要复制到的HDFS中的目标路径。 |
解决方法:在hdfsPath书写的时候,最后一级需要写上文件名,不然无法写入成功!
| # 正确书写路径参数范例 String localFilePath = "file:///D:\\ABC\\wordcount\\input\\wordcount.txt"; // 本地文件路径 String hdfsFilePath = "/li-qi-liang/wordcount.txt"; // HDFS文件路径 |
5.编程追加文件操作时报错不能增加其他DataNode
| java.io.IOException: Failed to replace a bad datanode on the existing pipeline due to no more good datanodes being available to try. (Nodes: current=[192.168.88.100:50010], original=[192.168.88.100:50010]). The current failed datanode replacement policy is DEFAULT, and a client may configure this via 'dfs.client.block.write.replace-datanode-on-failure.policy' in its configuration.at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer. findNewDatanode(DFSOutputStream.java:1040) at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer. addDatanode2ExistingPipeline(DFSOutputStream.java:1106) at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer. setupPipelineForAppendOrRecovery(DFSOutputStream.java:1253) at org.apache.hadoop.hdfs. DFSOutputStream$DataStreamer.run(DFSOutputStream.java:594) |
观察报错信息,联想伪分布式中replication只有1个,因此将core-site.xml,hdfs-site.xml和yarn-site.xml文件复制到IDEA中的resources文件中。
得到主要原因:没有可以拓展的node节点。而所有的这些配置相当于设置为NEVER之后,就不会添加新的DataNode。
| # 在java代码中添加配置项 conf.set("fs.replication","1"); // 设置副本数目 conf.set("fs.replication","1");// 设置副本数目为1 conf.set("dfs.client.block.write.replace-datanode-on-failure.policy","NEVER");// 执行永不替换节点 conf.set("dfs.client.block.write.replace-datanode-on-failure.enable","true");//开启替换节点功能 |
| # 在hadoop的/export/server/hadoop2.7.5/etc/hadoop/hdfs-site.xml文件中添加 <property> <name>dfs.support.append</name> <value>true</value> </property> <property> <name>dfs.client.block.write.replace-datanode-on-failure.policy</name> <value>NEVER</value> </property> <property> <name>dfs.client.block.write.replace-datanode-on-failure.enable</name> <value>true</value> </property> |
配置以上各项后,就可以进行程序正常运行了!(此时文件操作就是1个副本)
如果没有配置,默认程序是按照3个副本进行文件操作的。

6.编程题目中readLine过期失效

解决方法:通过查阅资料,发现readNextLine可以替换readLine进行使用。
7.在MyFSDataInputStream类的readNextLine一直显示文件是空的
| # 源文件的主函数: public static void main(String[] args) { String hdfsUri = "hdfs://192.168.88.100:8020"; // HDFS的URI String filePath = "/li-qi-liang/dest.txt"; // HDFS中的文件路径 Configuration conf = new Configuration(); conf.set("fs.defaultFS", hdfsUri); try { FileSystem fs = FileSystem.get(conf); Path file = new Path(filePath); MyFSDataInputStream inputStream = new MyFSDataInputStream(fs, file); String line; int lineNumber = 1; while ((line = inputStream.readNextLine()) != null) { System.out.println("Line " + lineNumber++ + ": " + line); // 逐行打印文件内容 } if (lineNumber == 1) { System.out.println("The file is empty."); // 文件为空 } inputStream.close(); fs.close(); } catch (IOException e) { e.printStackTrace(); } } |
| # 原来的readNextLine()方法书写: public String readNextLine() throws IOException { if (currentPosition >= getPos()) { return null; // 已到达文件末尾 } if (cache.isEmpty() || currentPosition >= cache.size()) { fillCache(); // 填充缓存 } return cache.get((int) currentPosition++); } |
分析原因:
在MyFSDataInputStream类的readNextLine()方法中,由于使用了currentPosition >= getPos()来判断是否已经到达文件末尾。
然而,getPos()方法返回的是当前读取位置的偏移量,而不是文件的总长度。
因此,即使没有读取到文件末尾,也可能会返回null,导致一直打印"The file is empty."。
为了解决这个问题,可以修改readNextLine()方法的判断条件为super.available() > 0,表示只有在底层输入流还有数据可读时才继续读取下一行。这样可以确保在读取完整个文件后返回null。
| # 修改后的代码如下: public String readNextLine() throws IOException { if (super.available() <= 0) { return null; // 已到达文件末尾 } if (cache.isEmpty() || currentPosition >= cache.size()) { fillCache(); // 填充缓存 } return cache.get((int) currentPosition++); } |
(二)总结实验与思考感悟
本次实验主要围绕HDFS在Hadoop体系结构中的角色展开,通过编程实现常用的HDFS操作功能,并使用Hadoop提供的Shell命令完成相同任务。同时还实现了一个自定义的类MyFSDataInputStream,继承自org.apache.hadoop.fs.FSDataInpuStream,实现了按行读取HDFS文件的功能。
在实验过程中,学习到了HDFS的基本概念和特点,了解了其在Hadoop分布式系统中的重要作用。通过编程实现HDFS操作,熟悉了HDFS的Java API以及常用的Shell命令,掌握了上传、下载、输出文件内容、查看文件信息、创建和删除文件/目录等操作。
通过实验,还深入思考了以下几个方面:
1.HDFS的设计理念
HDFS采用分布式存储和容错机制,将大文件拆分成多个块并存储在不同的节点上,通过冗余备份保证数据的可靠性。这种设计使得HDFS适合处理大规模数据和高并发访问。
2.HDFS的优缺点
HDFS的优点包括高容错性、高可靠性、高吞吐量等,适用于大数据处理。然而,由于其设计目标是批处理和顺序读写,对于小文件和随机读写的性能较差,不适合低延迟的交互式应用。本次实验让我们更深入地了解了HDFS的特点和使用方法,加深了对分布式文件系统的理解。在实验过程中,我们不仅学习了HDFS的Java API和Shell命令的使用,还体会到了分布式存储与处理的优势和挑战。
3.HDFS与本地文件系统的比较
HDFS与传统的本地文件系统有很大的区别,包括数据分布、容错机制、并发访问等方面。理解HDFS与本地文件系统的差异有助于我们合理选择存储方案。通过实验,我们认识到HDFS在大数据处理中的重要性,它为我们提供了高可靠、高扩展性的存储和访问解决方案。同时,我们也意识到HDFS并非适用于所有场景,对于小文件和随机读写等场景,需要根据实际需求选择合适的存储方案。
4.自定义类的实现
通过编写MyFSDataInputStream类,了解到如何继承Hadoop提供的相关类,并实现自己的功能。这个类利用缓存技术提高了读取效率,同时还探索了使用java.net.URL和org.apache.hadoop.fs.FsURLStreamHandlerFactory输出HDFS文件内容到终端的方法。此外,通过自定义类的实现,我们深入学习了Java的继承机制和类的设计思路。这对我们进一步理解和应用Hadoop提供的API有很大帮助,并培养了我们设计和开发自己功能的能力。
5.总结思考
总而言之,本次实验让我们在理论和实践中更好地掌握了HDFS的使用,加深了对分布式存储和处理系统的认识。这对我们今后在大数据领域的学习和工作具有重要意义。
相关文章:
大数据技术原理(三):HDFS 最全面的 API 操作,你值得收藏
(实验二 熟悉常用的HDFS操作) -------------------------------------------------------------------------------------------------------------------------------- 一、实验目的 1.理解 HDFS在 Hadoop体系结构中的角色。 HDFS是一个分布式文件系…...

Flink系列二:DataStream API中的Source,Transformation,Sink详解(^_^)
在上面篇文章中已经对flink进行了简单的介绍以及了解了Flink API 层级划分,这一章内容我们主要介绍DataStream API 流程图解: 一、DataStream API Source Flink 在流处理和批处理上的 source 大概有 4 类: (1)基于本…...
最好的电脑数据恢复软件是什么
由于硬件故障、恶意软件攻击或意外删除而丢失文件可能会造成巨大压力。数据丢失会扰乱日常运营,造成宝贵的业务时间和资源损失。在这些情况下,数据恢复软件是检索丢失或损坏数据的最简单方法。 数据恢复软件何时起作用? 对于 Windows 数据恢…...
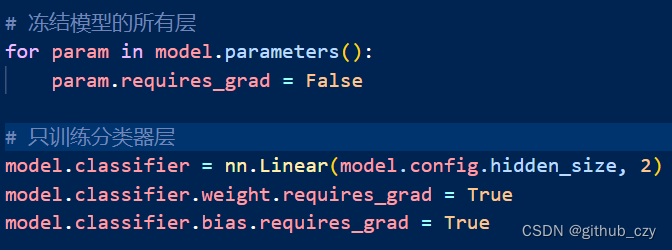
机器学习模型调试学习总结
1.学习内容 模型调试方法:冻结部分层,训练剩余层 实践:在一个预训练的 BERT 模型上冻结部分层,并训练剩余的层 模型调试方法:线性探测(Linear Probe) 实践:在一个预训练的 BERT …...

文明互鉴促发展——2024“国际山地旅游日”主题活动在法国启幕
5月29日,2024“国际山地旅游日”主题活动在法国尼斯市成功举办。中国驻法国使领馆、法国文化旅游部门、地方政府、国际组织、国际山地旅游联盟会员代表、旅游机构、企业、专家、媒体等围绕“文明互鉴的山地旅游”大会主题和“气候变化与山地旅游应对之策”论坛主题展…...

【C++进阶】深入STL之string:掌握高效字符串处理的关键
📝个人主页🌹:Eternity._ ⏩收录专栏⏪:C “ 登神长阶 ” 🤡往期回顾🤡:C模板入门 🌹🌹期待您的关注 🌹🌹 ❀STL之string 📒1. STL基本…...
一、初识Qt 之 Hello world
一、初识Qt 之 Hello world 提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 初识Qt 之 Hello world文章目录 一、Qt 简介二、Qt 获取安装三、Qt 初步使用四、Qt 之 Hello world1.新建一个项目 总结 一、Qt 简介 C …...
nginx搭建简单负载均衡demo(springboot)
目录 1 安装nignx 1.1 执行 brew install nginx 命令(如果没安装brew可百度搜索如何安装brew下载工具。类似linux的yum命令工具)。 1.2 安装完成会有如下提示:可以查看nginx的配置文件目录。 1.3 执行 brew services start nginx 命令启动…...
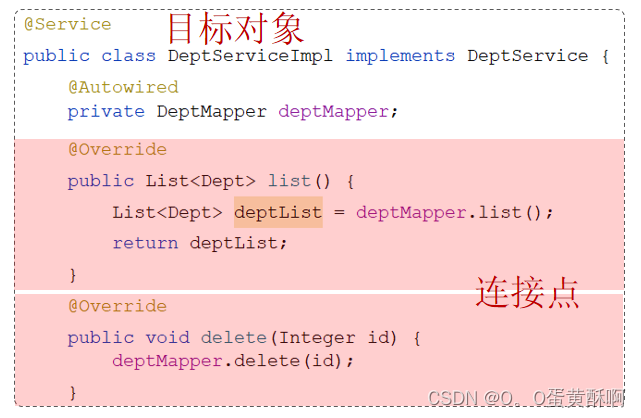
SpringBoot的第二大核心AOP系统梳理
目录 1 事务管理 1.1 事务 1.2 Transactional注解 1.2.1 rollbackFor 1.2.2 propagation 2 AOP 基础 2.1 AOP入门 2.2 AOP核心概念 3. AOP进阶 3.1 通知类型 3.2 通知顺序 3.3 切入点表达式 execution切入点表达式 annotion注解 3.4 连接点 1 事务管理 1.1 事务…...
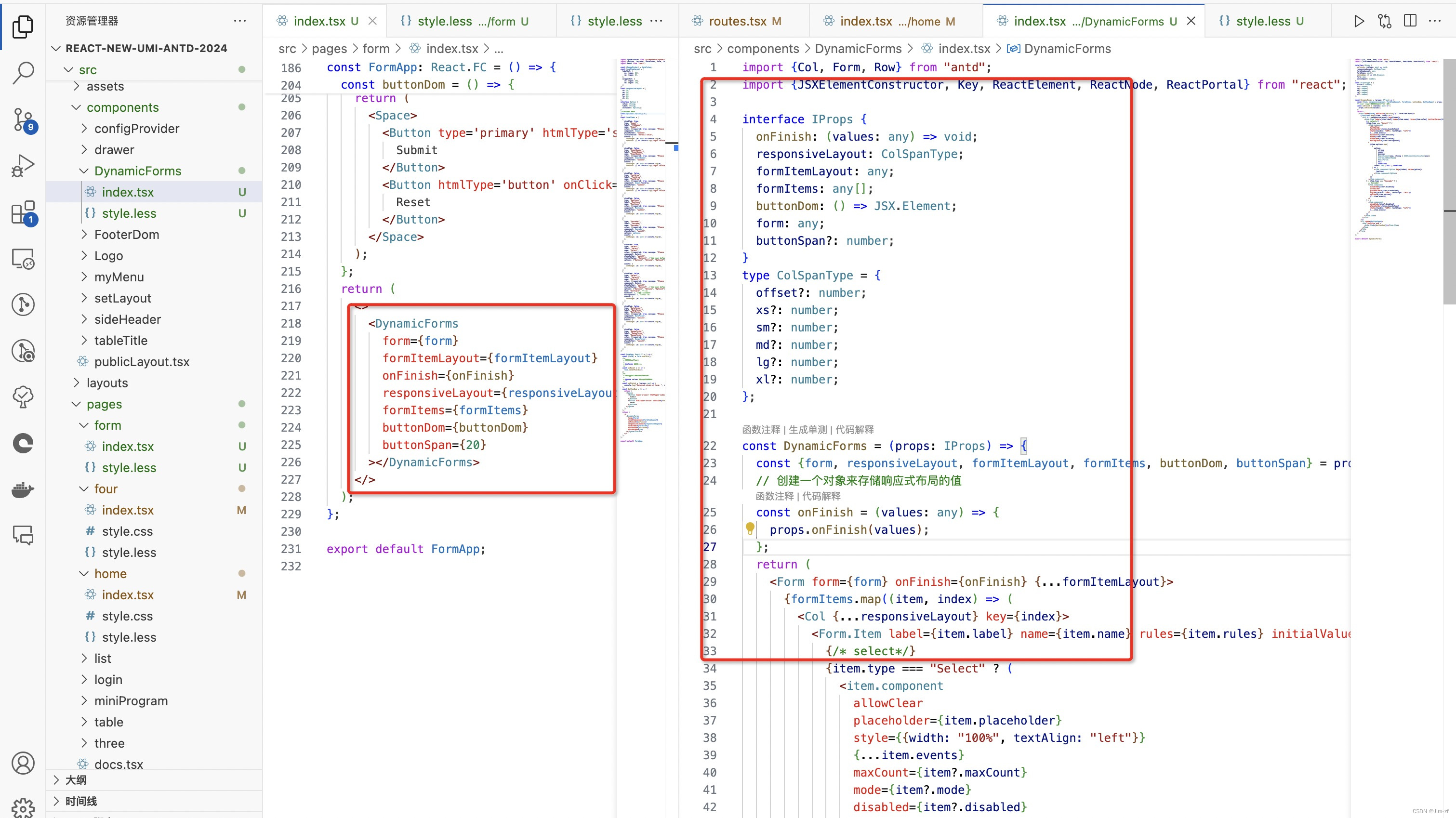
react、vue动态form表单
需求在日常开发中反复写form 是一种低效的开发效率,布局而且还不同这就需要我们对其封装 为了简单明了看懂代码,我这里没有组件,都放在一起,简单抽离相信作为大佬的你,可以自己完成, 一、首先我们做动态f…...
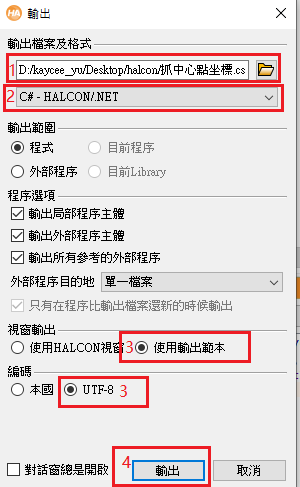
halcon程序如何导出C#文件
1.打开halcon文件; 2.写好需要生成C#文件的算子或函数; 3.找到档案-输出,如下图; 4.点击输出,弹出如下窗口 (1)可以修改导出文件的存储路径 (2)选择C#-HALCON/.NET &…...

RabbitMQ三、springboot整合rabbitmq(消息可靠性、高级特性)
一、springboot整合RabbitMQ(jdk17)(创建两个项目,一个生产者项目,一个消费者项目) 上面使用原生JAVA操作RabbitMQ较为繁琐,很多的代码都是重复书写的,使用springboot可以简化代码的…...
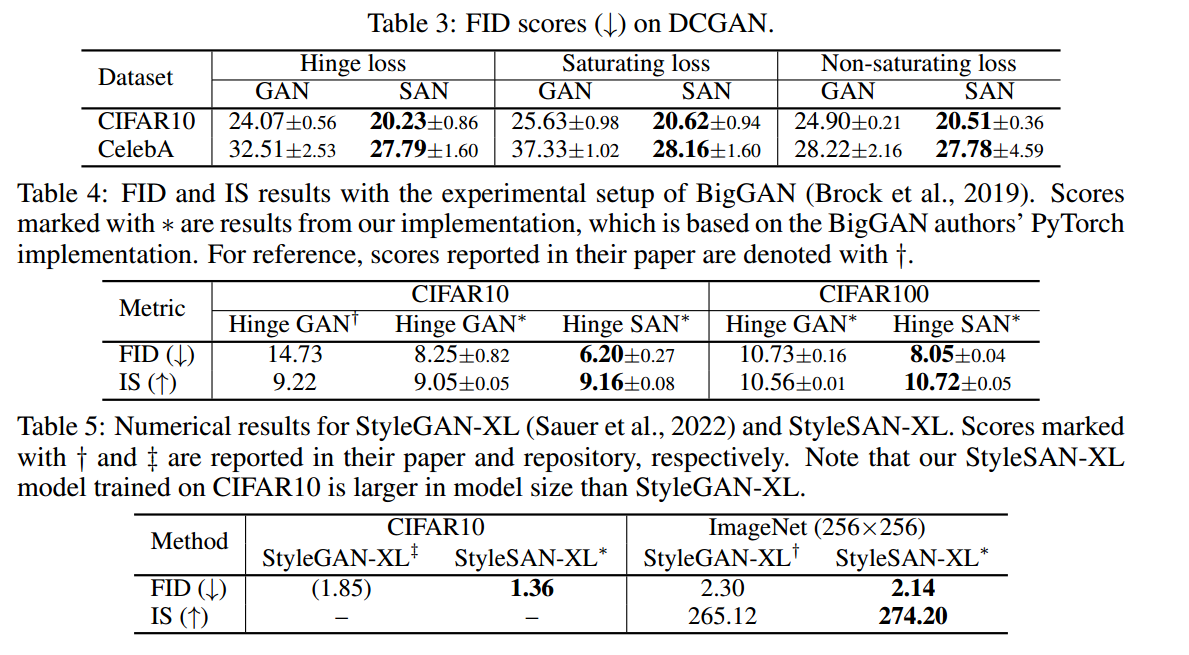
第八十九周周报
学习目标: 论文 学习时间: 2024.05.25-2024.05.31 学习产出: 一、论文 SAN: INDUCING METRIZABILITY OF GAN WITH DISCRIMINATIVE NORMALIZED LINEAR LAYER 将GAN与切片最优输运联系起来,提出满足方向最优性、可分离性和单射…...

Centos升级Openssh版本至openssh-9.3p2
一、启动Telnet服务 为防止升级Openssh失败导致无法连接ssh,所以先安装Telnet服务备用 1.安装telnet-server及telnet服务 yum install -y telnet-server* telnet 2.安装xinetd服务 yum install -y xinetd 3.启动xinetd及telnet并做开机自启动 systemctl enable…...

茉莉香飘,奶茶丝滑——周末悠闲时光的绝佳伴侣
周末的时光总是格外珍贵,忙碌了一周的我们,终于迎来了难得的闲暇。这时,打开喜欢的综艺,窝在舒适的沙发里,再冲泡一杯香飘飘茉莉味奶茶,一边沉浸在剧情的海洋中,一边品味着香浓丝滑的奶茶&#…...
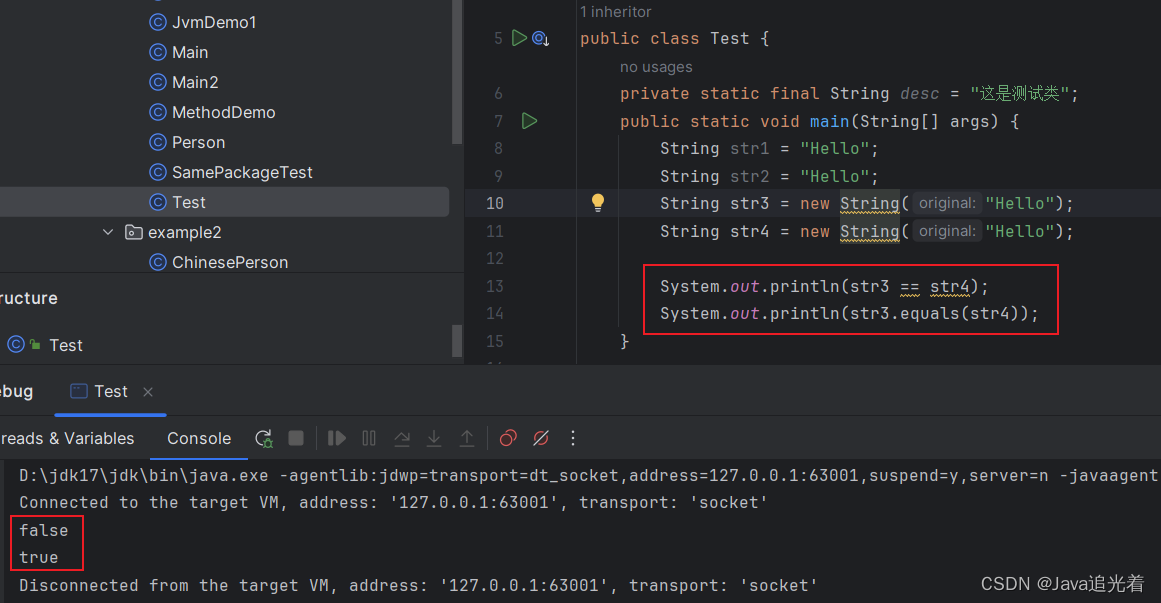
揭秘:Java字符串对象的内存分布原理
先来看看下面寄到关于String的真实面试题,看看你废不废? String str1 "Hello"; String str2 "Hello"; String str3 new String("Hello"); String str4 new String("Hello");System.out.println(str1 str2)…...

Vue.js - 生命周期与工程化开发【0基础向 Vue 基础学习】
文章目录 Vue 的生命周期Vue 生命周期的四个阶段Vue 生命周期函数(钩子函数 工程化开发 & 脚手架 Vue CLI**开发 Vue 的两种方式:**脚手架目录文件介绍项目运行流程组件化开发 & 根组件App.vue 文件(单文件组件)的三个组成…...

Element-UI 快速入门指南
Element-UI 快速入门指南 Element-UI 是一套基于 Vue.js 的桌面端组件库,由饿了么前端团队开发和维护。它提供了丰富的 UI 组件,帮助开发者快速构建美观、响应式的用户界面。本篇文章将详细介绍 Element-UI 的安装、配置和常用组件的使用方法,帮助你快速上手并应用于实际项…...
)
2024华为OD机试真题-整型数组按个位值排序-C++(C卷D卷)
题目描述 给定一个非空数组(列表),其元素数据类型为整型,请按照数组元素十进制最低位从小到大进行排序, 十进制最低位相同的元素,相对位置保持不变。 当数组元素为负值时,十进制最低位等同于去除符号位后对应十进制值最低位。 输入描述 给定一个非空数组,其元素数据类型…...

善听提醒遵循易经原则。世界大同只此一路。
如果说前路是一个大深坑,那必然是你之前做的事情做的不太好,当坏的时候,坏的结果来的时候,是因为你之前的行为,你也就不会再纠结了,会如何走出这个困境,是好的来了,不骄不躁…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...

在Mathematica中实现Newton-Raphson迭代的收敛时间算法(一般三次多项式)
考察一般的三次多项式,以r为参数: p[z_, r_] : z^3 (r - 1) z - r; roots[r_] : z /. Solve[p[z, r] 0, z]; 此多项式的根为: 尽管看起来这个多项式是特殊的,其实一般的三次多项式都是可以通过线性变换化为这个形式…...