mysql表字段超过多少影响性能 mysql表多少效率会下降
一直有传言说,MySQL 表的数据只要超过 2000 万行,其性能就会下降。而本文作者用实验分析证明:至少在 2023 年,这已不再是 MySQL 表的有效软限制。
传言
互联网上有一则传言说,我们应该避免单个 MySQL 表中的数据超过 2000 万行,否则表的性能就会下降——当数据量超过这个软限制时,你就会发现 SQL 的查询速度会比平时慢很多。这是多年前针对 HDD 做出的判断。我想知道,时至 2023 年,SSD 上的 MySQL 是否仍然有此限制。如果真的有,那么原因是什么呢?
环境
数据库
▶ MySQL 版本: 8.0.25
▶ 实例类型:AWS db.r5.large(2vCPUs, 16GiB RAM)
▶ EBS 存储类型:General Purpose SSD(gp2)
测试客户端
▶ Linux 内核版本:6.1
▶ 实例类型:AWS t2.micro(1 vCPU, 1GiB RAM)
实验设计
创建具有相同结构、但大小不同的表。我一共创建了 9 个表,数据行数分别为:10 万、20 万、50 万、100 万、200 万、500 万、1000 万、2000 万、3000 万、5000 万和 6000 万。
- 创建几个具有相同结构的表:
CREATE TABLE row_test(
`id` int NOT NULL AUTO_INCREMENT,
`person_id` int NOT NULL,
`person_name` VARCHAR(200),
`insert_time` int,
`update_time` int,
PRIMARY KEY (`id`),
KEY `query_by_update_time` (`update_time`),
KEY `query_by_insert_time` (`insert_time`)
);
- 插入不同的数据。我使用了测试客户端和表复制的方式创建了这些表。脚本可参考:https://github.com/gongyisheng/playground/blob/main/mysql/row_test/insert_data.py。
# test client
INSERT INTO {table} (person_id, person_name, insert_time, update_time) VALUES ({person_id}, {person_name}, {insert_time}, {update_time})
# copy
create table like <table>
insert into (`person_id`, `person_name`, `insert_time`, `update_time`)
select `person_id`, `person_name`, `insert_time`, `update_time` from
person_id、person_name、insert_time 和 update_time 的值是随机的。
- 使用测试客户端执行以下 sql 查询来测试性能。脚本可参考:https://github.com/gongyisheng/playground/blob/main/mysql/row_test/select_test.py。
select count(*) from <table> -- full table scan
select count(*) from <table> where id = 12345 -- query by primary key
select count(*) from <table> where insert_time = 12345 -- query by index
select * from <table> where insert_time = 12345 -- query by index, but cause 2-times index tree lookup
- 查看 innodb 缓冲池状态。
SHOW ENGINE INNODB STATUS
SHOW STATUS LIKE 'innodb_buffer_pool_page%
结果
查询1:select count(*) from
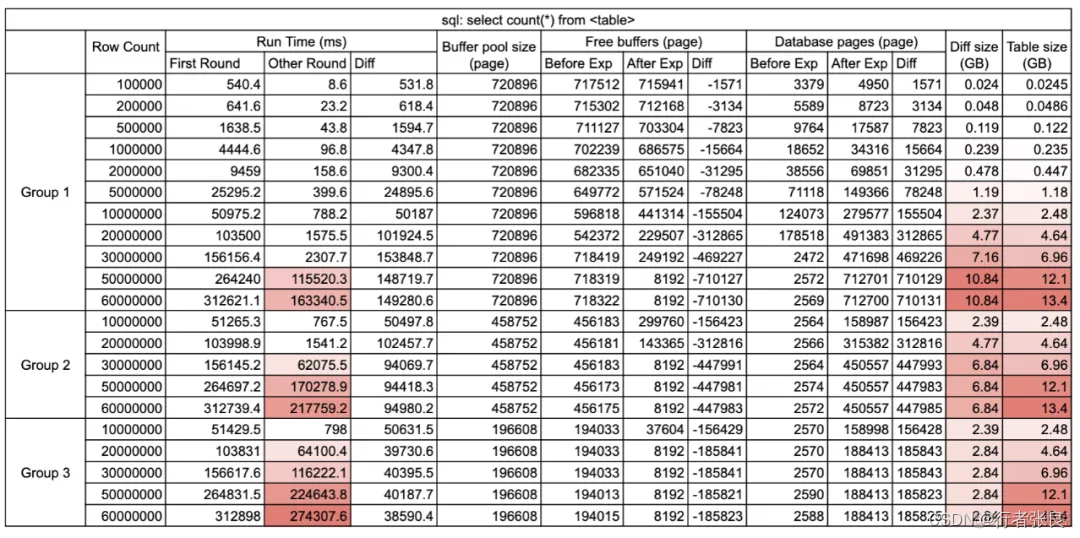
这种查询会执行全表扫描,MySQL 并不擅长这种工作。
▶ 第一轮:没有缓存。第一次执行查询时,缓冲池中没有缓存数据。
▶ 第二轮:有缓存。当缓冲池中已经有数据缓存时执行查询,通常在第一次查询执行完之后。
观察结果:
1. 第一轮查询的执行时间超出了后面几次。
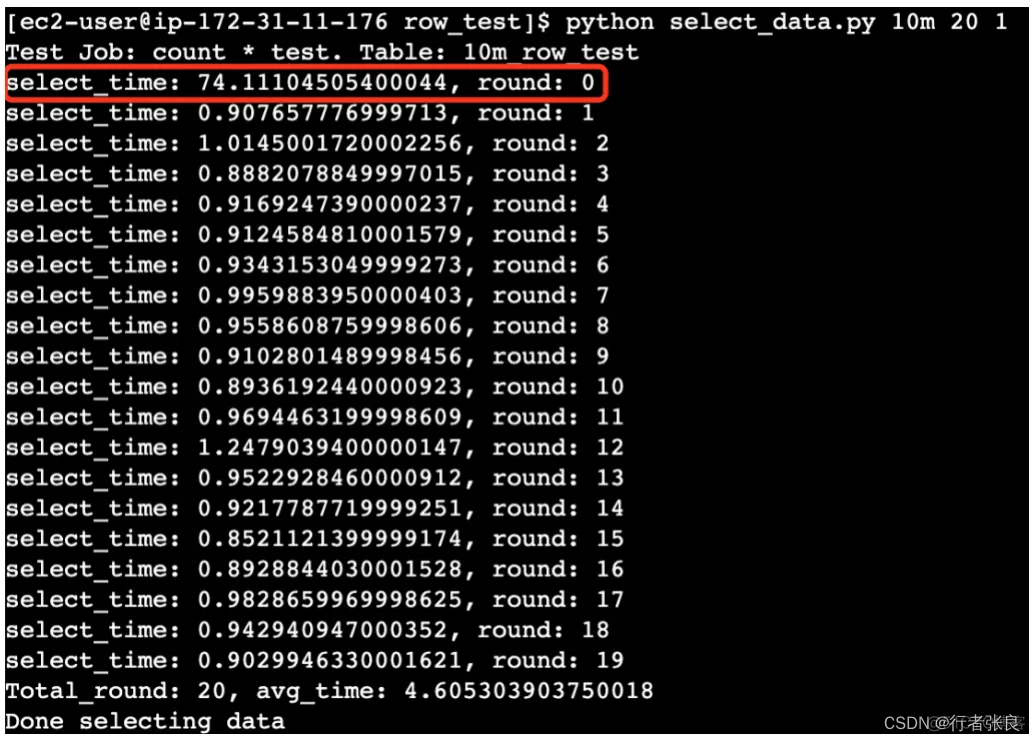
原因是 MySQL 使用了 innodb_buffer_pool 来缓存数据页。在第一次执行查询之前,缓冲池是空的,所以 MySQL 必须进行大量的磁盘 I/O 才能从 .idb 文件加载表。但在第一次执行结束后,缓冲池中存储了数据,后续查询可以直接读取内存,避免磁盘 I/O,因此速度更快。该过程称为 MySQL 缓冲池预热。
2. select count(*) from < table > 会设法将整个表加载到缓冲池。
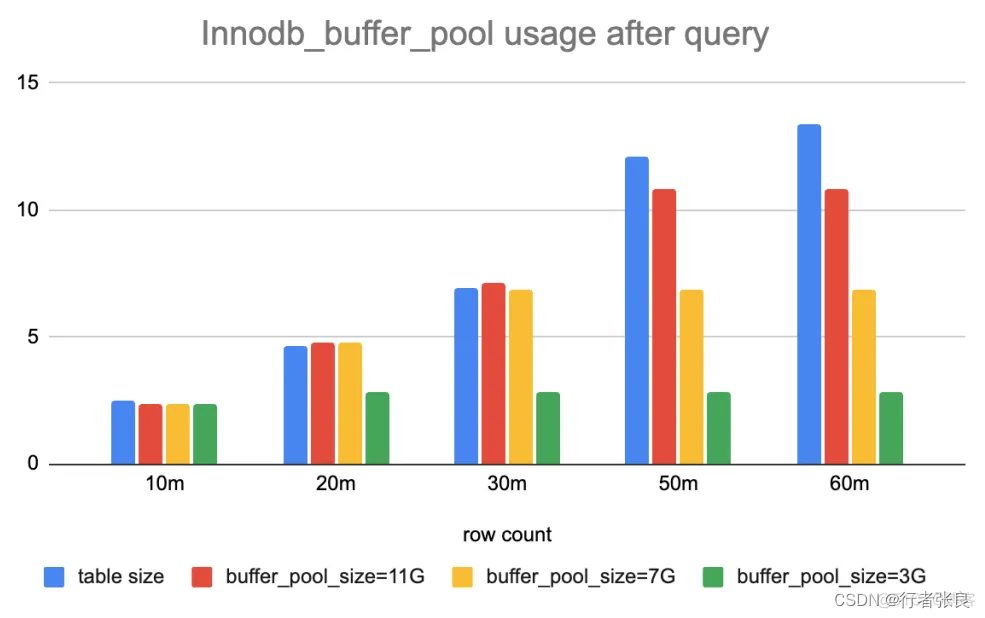
我比较了实验前后 innodb_buffer_pool 的统计数据。运行查询后,如果缓冲池足够大,则其使用量变化等于表的大小。否则,只有部分表会缓存在缓冲池中。原因是查询 select count(*) from table 会做全表扫描,并做逐行统计。如果没有缓存,就需要将完整的表加载到内存中。为什么?因为 Innodb 支持事务,它不能保证事务在不同时间看到同一张表。全表扫描是获得准确行数的唯一安全方法。
3. 如果缓冲池不能容纳全表,则会爆发查询延迟。
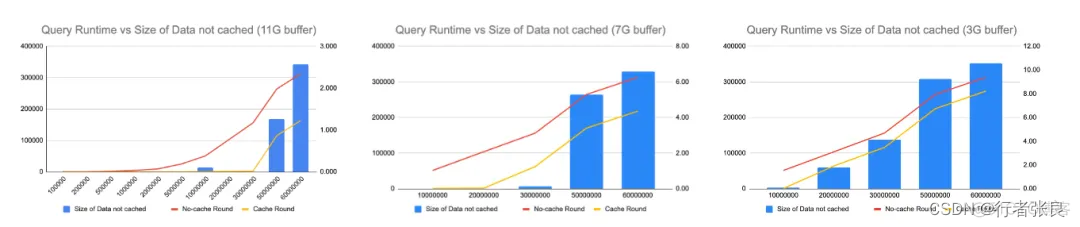
我注意到 innodb_buffer_pool 的大小会极大地影响查询性能,因此我尝试在不同的配置下运行查询。当使用 11G 缓冲区,而表的大小达到 5000 万行时,就会爆发查询延迟。接着,我将缓冲区缩减到 7G,当表的大小达到 3000 万行时,爆发了查询延迟。最后,我将缓冲区缩减到 3G,当表的大小仅为 2000 万行时,就爆发了查询延迟。很明显,如果表中的数据无法缓存在缓冲池中,则 select count(*) from
4. 对于没有缓存的查询,查询花费的时间与表的大小呈线性关系,与缓冲池大小无关。
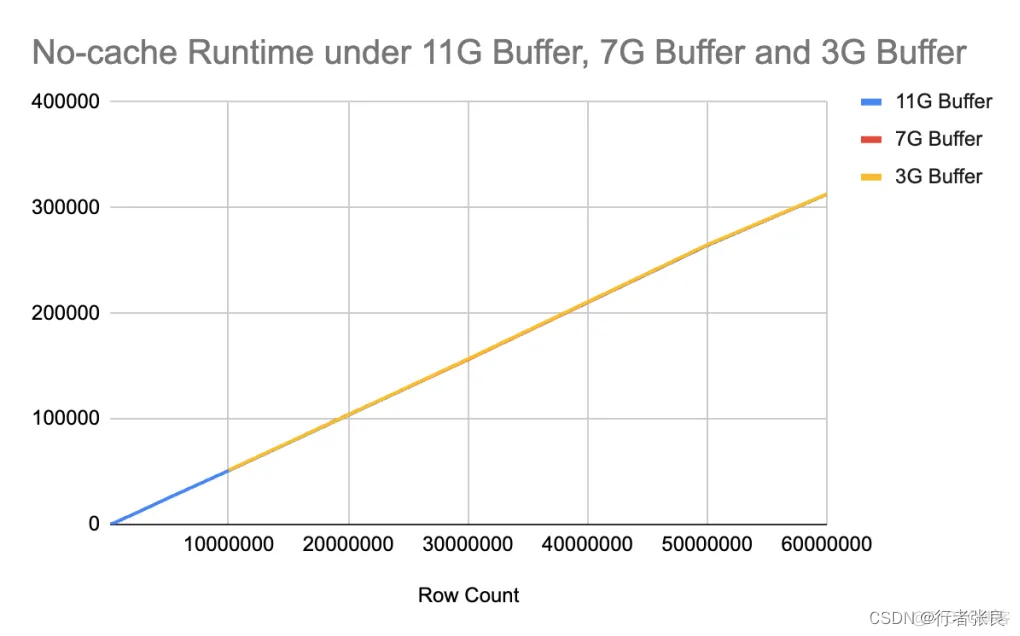
当没有缓存时,查询花费的时间由磁盘 I/O 决定,与缓冲池大小无关。在 IOPS 相同的情况下,是否使用 select count(*) 预热缓冲池并没有区别。
5. 如果无法完整地缓存整个表,则有无缓存的查询运行时间差异是恒定的。
另请注意,如果无法完整地缓存整个表,虽然查询运行时会突然上升,但运行时是可预测的。无论表的大小如何,有无缓存的时间差异是恒定的。原因是表的部分数据缓存在缓冲区中,这里的时间差异来自从缓冲区读取数据节省的时间。
查询2,3:select count(*) from where = 12345
这个查询使用了索引。由于不是范围查询,MySQL 只需要利用 B+ 树的路径从上到下查找页面,并将这些页面缓存到 innodb 缓冲池中即可。
我创建的表的 B+ 树的深度都是 3,因此前面的 3~4 次 I/O 都被拿来预热缓冲区,平均耗时 4~6 毫秒。之后,再次运行相同的查询,MySQL 就会直接从内存中查找结果,耗时为 0.5 毫秒,约等于网络 RTT。如果缓存页面长时间未命中,并从缓冲池中逐出,则必须再次从磁盘加载该页面,这样就需要磁盘 I/O(最多 4 次)。
查询4:select * from where = 12345
这个查询涉及两次索引查找。由于 select * 需要查询获取的 person_name、person_id 字段并不在索引中,因此在查询执行期间,数据库引擎必须查找 2 个 B+ 树。它首先查找 insert_time B+ 树,获取目标行的主键,然后查找主键 B+ 树,获取该行的完整数据,如下图所示:
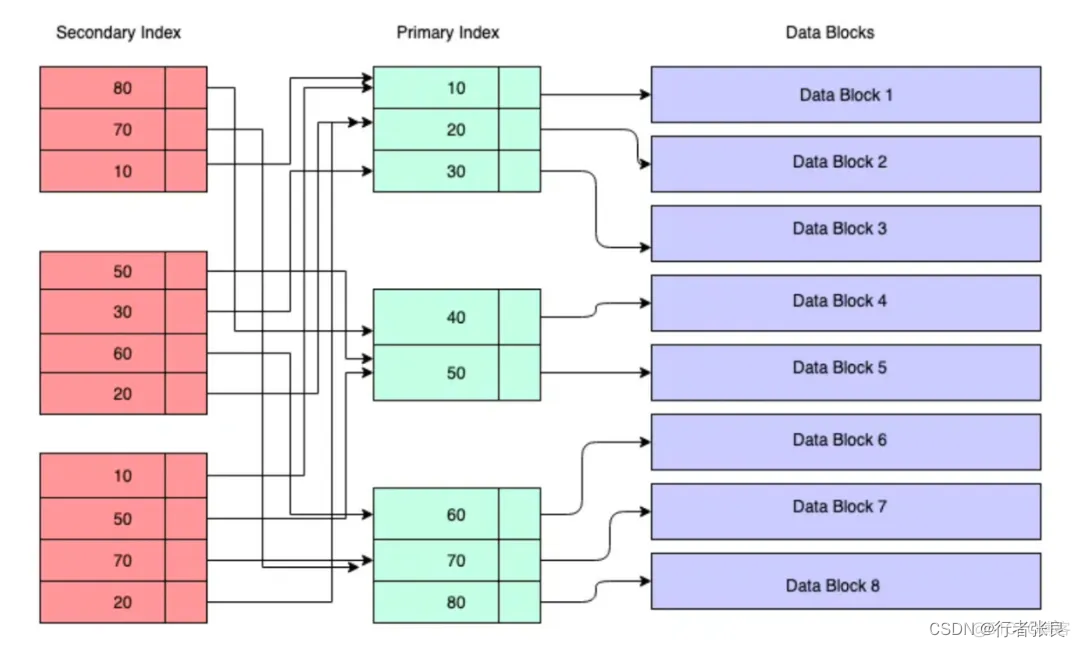
这就是我们应该在生产中避免 select * 的原因。此次实验证实,此查询加载的页面块比查询 2 或 3 多出了 2 倍,且最高可达 8 倍。查询的平均运行时间为 6~10 毫秒,也是查询 2 或 3 的 1.5~2 倍。
传言是怎么来的

首先,我们需要知道 innodb 索引页的物理结构。默认页面大小为 16k,由页眉、系统记录、用户记录、页面导向器和尾部组成。只有剩下的 14~15k 用来存储数据。
假设你使用 INT 作为主键(4 字节),每行 1KB 的有效负载。每个叶页可以存储 15 行,一个指向该页的指针需要 4+8=12 字节。因此,每个非叶页最多可以容纳 15k / 12 字节 = 1280 个指针。如果你有一个 4 层的 B+ 树,它最多可以容纳 1280128015 = 24.6M 行数据。
回到 HDD 占据市场主导地位,且 SSD 对于数据库而言过于昂贵的时代,4 次随机 I/O 可能是我们可以容忍的最坏情况,而使用 2 次索引树查找的查询甚至会使情况变得更糟。当时的工程师想要控制索引树的深度,不希望它们太深。而如今 SSD 越来越流行,随机 I/O 比以前便宜了,因此我们应该反思一下 10 年前的规则。
顺便说一句,5 层 B+ 树可以容纳 128012801280*15 = 31.4B 行数据,超过了 INT 所能容纳的最大数据量。对每行大小的不同假设将导致不同的软限制,或小于或大于 2000 万行。例如,在我的实验中,每一行大约是 816 字节(我使用 utf8mb4 字符集,所以每个字符占用 4 个字节),4 层 B+ 树可以容纳的软限制是 29.5M。
结论
▶ Innodb 缓存池的大小、表的大小决定了是否会出现性能降级。
▶ 判断是否需要拆分 MySQL 表的一个更有意义的指标是查询运行时/缓冲池命中率。如果查询总是命中缓冲区,则不会有任何性能问题。2000 万行只是一个经验值。
▶ 除了拆分 MySQL 表之外,增加 Innodb 缓存池的大小和数据库的内存也是一个选择。
▶ 如果可能,请避免在生产中使用 select *,这类语句在最坏的情况下会导致 2 次索引树查找。
▶ (我个人的意见)考虑到 SSD 现在越来越流行,2000 万行不再是 MySQL 表的有效软限制。
相关文章:
mysql表字段超过多少影响性能 mysql表多少效率会下降
一直有传言说,MySQL 表的数据只要超过 2000 万行,其性能就会下降。而本文作者用实验分析证明:至少在 2023 年,这已不再是 MySQL 表的有效软限制。 传言 互联网上有一则传言说,我们应该避免单个 MySQL 表中的数据超过 …...

Vue进阶之Vue无代码可视化项目(一)
Vue无代码可视化项目 项目搭建初始步骤拓展:工程项目从0-1项目规范化package.jsoncpell.jsoncustom-words.txtts-eslint规则.eslintrc.cjsgit钩子检查有没有问题type-checkspellchecklint:stylehusky操作安装pre-commitpnpm的commit规范package.json:commitlint.config.cjs安装…...
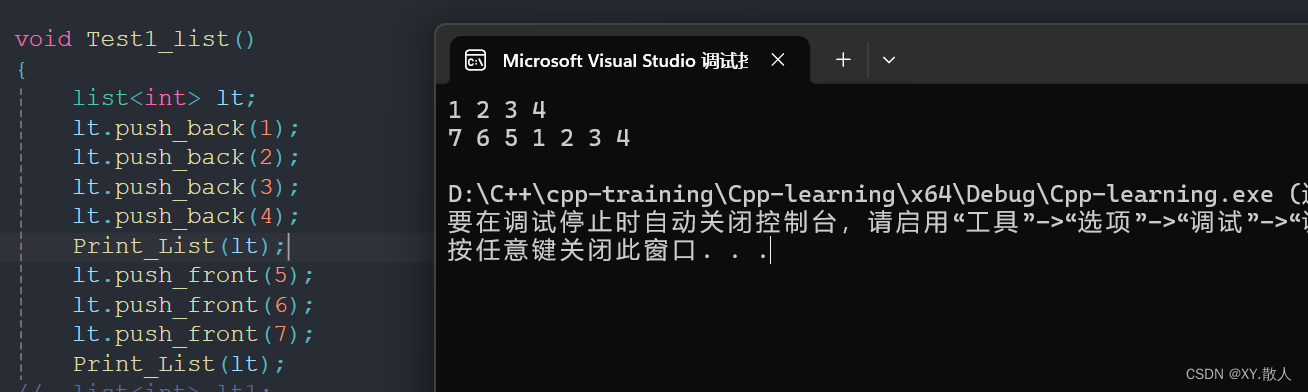
初识C++ · 模拟实现list
目录 前言 1 push_back pop_back 2 迭代器类 2.1 ! 2.2 -- 2.3 * 3 Print_List 4 有关自定义类型 5 有关const迭代器 6 拷贝构造 赋值 析构 Insert erase 前言 有了string,vector的基础,我们模拟实现list还是比较容易的,这里同…...

电商运营-2024年6月1日
作为一名电商运营,针对淘工厂平台,需要具备以下核心技能和素质: 核心技能 新店入驻与产品管理 熟练掌握淘工厂平台的新店入驻流程,包括资质准备、资料提交、审核跟进等。精通产品上架技巧,确保产品信息准确、图片清晰…...
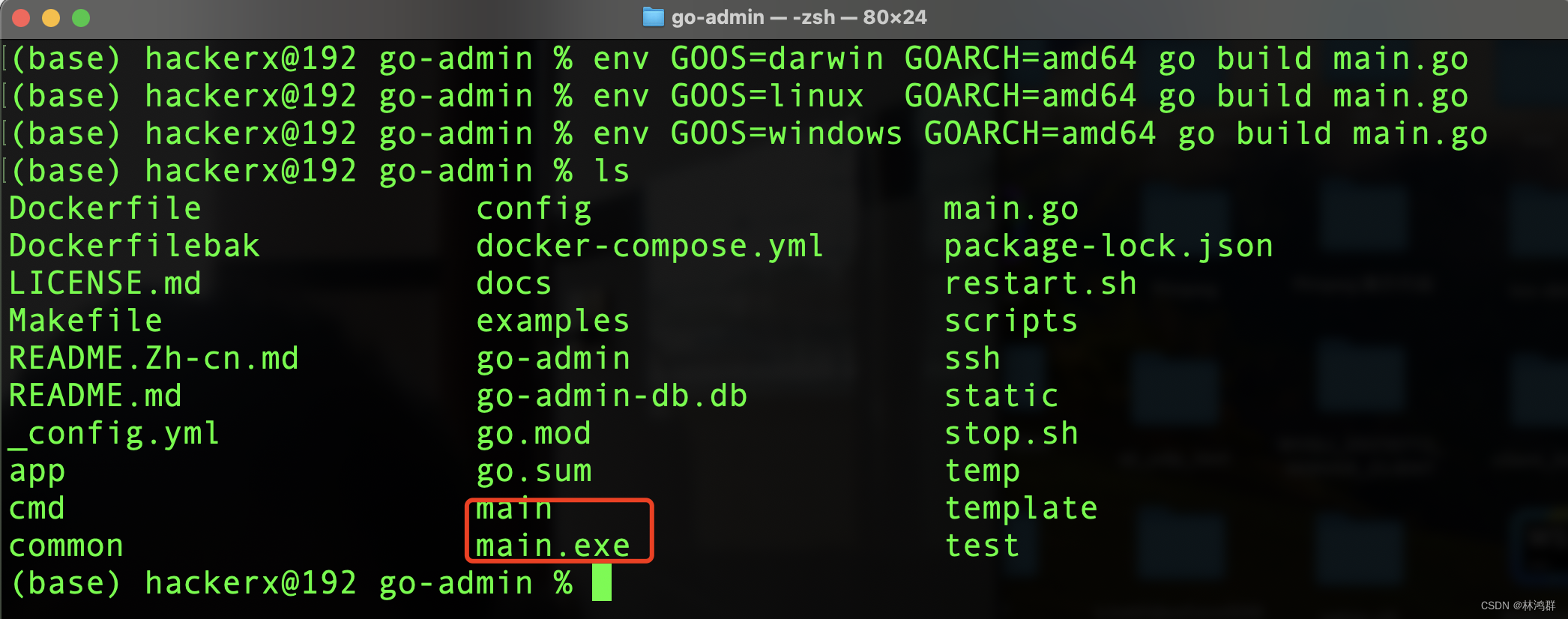
Go跨平台编译
1.编译windows平台运行程序 # windows env GOOSwindows GOARCHamd64 go build main.go2.编译linux平台运行程序 # linux env GOOSlinux GOARCHamd64 go build main.go 3.编译macos平台运行程序 # macos env GOOSdarwin GOARCHamd64 go build main.go 编译结果:...
)
生产计划排产,制定每小时计划产量(“查表法”SQL计算)
根据日生产计划产量排产,制定每2小时理论计划生产产量。 每2小时计划产量 每2小时工作时间(秒)/生产计划节拍(秒)。 假设,生产计划节拍 : 25.0(秒)/台 工厂以每天8点00分钟作为当日工作日的…...
视频汇聚管理安防监控平台EasyCVR程序报错“create jwtSecret del server class:0xf98b6040”的原因排查与解决
国标GB28181协议EasyCVR安防视频监控平台可以提供实时远程视频监控、视频录像、录像回放与存储、告警、语音对讲、云台控制、平台级联、磁盘阵列存储、视频集中存储、云存储等丰富的视频能力,平台支持7*24小时实时高清视频监控,能同时播放多路监控视频流…...

头歌页面置换算法第2关:计算OPT算法缺页率
2 任务:OPT算法 2.1 任务描述 设计OPT页面置换算法模拟程序:从键盘输入访问串。计算OPT算法在不同内存页框数时的缺页数和缺页率。要求程序模拟驻留集变化过程,即能模拟页框装入与释放过程。 2.2任务要求 输入串长度作为总页框数目,补充程序完成OPT算法。 2.3算法思路 OPT算…...
vscode怎么拷贝插件到另一台电脑
说明 vscode插件默认存放在 C:\Users\用户名\.vscode 目录下的 extensions 文件夹中 方法 拷贝 C:\Users\用户名\.vscode 目录下的 extensions 文件夹到另一台电脑的C:\Users\用户名\.vscode 目录下 C:\Users\用户名\.vscode...
网络协议分析
网络协议分析 网络协议分析概述用IP实现异构网络互联网络协议的分层TCP/IP的分层模型协议分析协议分析应用协议分析任务 常见网络协议PPP协议报文选项IPCP认证协议PAP安全缺陷认证协议CHAPPPPoE协议流程 地址解析协议ARPARP的思想和步骤ARP报文格式及封装 移动IP移动IP的工作机…...

GAMIT目录配置
1打开home,显示隐藏文件,CTRH 2修改目录 #set gamitpath gamitpath/opt/gamit10.7 export PATH$PATH:${gamitpath}/com/:${gamitpath}/gamit/bin:${gamitpath}/kf/bin HELP_DIR${gamitpath}/help export HELP_DIR #set GMT path gmtpath/usr/lib/gmt P…...
基于JSP的九宫格日志网站
你好呀,我是学长猫哥!如果有需求可以文末加我。 开发语言:Java 数据库:MySQL 技术:JSP技术 工具:浏览器/服务器(B/S)结构 系统展示 首页 管理员功能模块 用户功能模块 摘要 本…...

C#中结构struct能否继承于一个类class,类class能否继承于一个struct
C#中结构struct能否继承于一个类class,类class能否继承于一个struct 答案是:都不能。 第一种情行,尝试结构继承类 报错:接口列表中的类型"XX"不是接口interface。 一般来说,都是结构只能实现接口&#x…...
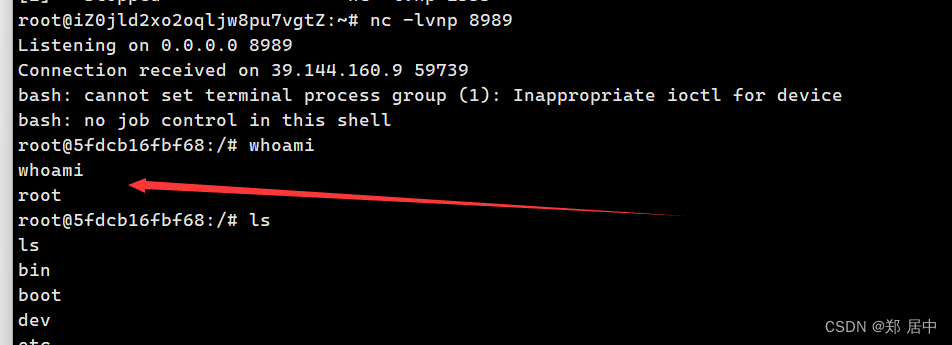
【Vulhub】Fastjson 1.2.24_rce复现
文章目录 一,Fastjson是什么?二,fastjson漏洞原理三,判断是否有fastjson反序列化四,复现Fastjson 1.2.24_rce(vulhub)环境配置1.判断是否存在Fastjson反序列化2.反弹shell3.启动RMI服务器4.构造恶意POST请求 一&#x…...

【iconv】UTF-8字符串转换为UTF-16字符串
使用<iconv.h>来进行字符串编码的转换 #include <iconv.h> #include <iostream> #include <string.h> #include <unistd.h> #include <memory> #include <fcntl.h>// 需要链接iconv库// iconv -l 命令可列出所有支持的格式 // exam…...

AI技术的未来展望:重塑人类社会的智能革命
一、引言 随着技术的飞速发展,人工智能(AI)已经不再是科幻小说中的概念,而是成为了我们生活中不可或缺的一部分。从简单的智能助手到复杂的自动化生产线,AI技术正在以前所未有的速度改变着世界。本文将对AI技术的未来…...

掘金AI 商战宝典-系统班:2024掘金AIGC课程(30节视频课)
课程目录 1-第一讲学会向Al提问:万能提问公式_1.mp4 2-第二讲用AI写视频脚本_1.mp4 3-第三讲用AI写视频口播文案_1.mp4 4-第四讲用AI自动做视频(上)_1.mp4 5-第五讲用AI自动做视频(中)_1.mp4 6-第六讲用AI自动做视…...
C# WinForm —— 26 ImageList 介绍
1. 简介 图片集合,用于存储图像的资源,并在关联控件中显示出来 可以通过 索引、键名 访问每张图片 没有事件 2. 属性 属性解释(Name)控件ID,在代码里引用的时候会用到,一般以 imgList 开头ClolorDepth用于呈现图像的颜色数,默…...

Vue:现代前端开发的首选框架-【声明周期钩子详解】
引言 Vue.js 是一个流行的前端框架,它通过组件化的开发方式,让开发者能够构建出高效且可维护的应用程序。在Vue中,生命周期钩子(Lifecycle Hooks)是理解组件行为的关键概念。本文将深入探讨Vue生命周期钩子࿰…...
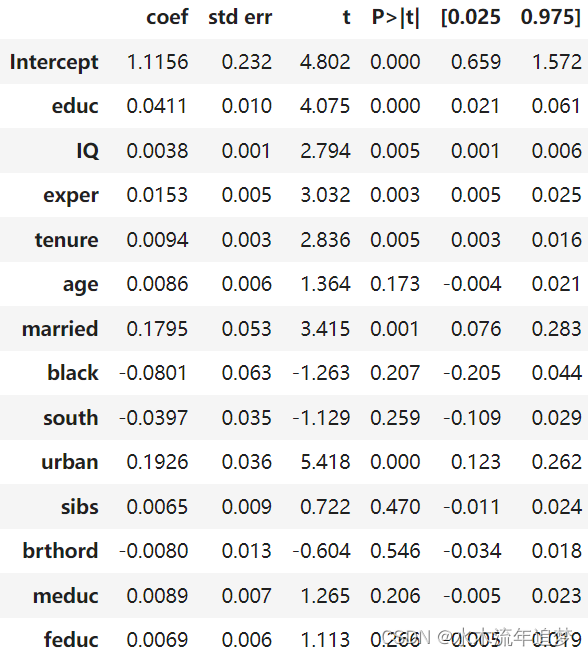
【因果推断python】8_线性回归模型2
目录 回归理论 非随机数据的回归 回归理论 我不打算深入研究线性回归是如何构建和估计的。然而,一点点理论将有助于解释它在因果推断中的力量。首先,回归解决了理论上的最佳线性预测问题。令 是一个参数向量: 线性回归找到最小化均方误差 (…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

Java - Mysql数据类型对应
Mysql数据类型java数据类型备注整型INT/INTEGERint / java.lang.Integer–BIGINTlong/java.lang.Long–––浮点型FLOATfloat/java.lang.FloatDOUBLEdouble/java.lang.Double–DECIMAL/NUMERICjava.math.BigDecimal字符串型CHARjava.lang.String固定长度字符串VARCHARjava.lang…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...

Mac下Android Studio扫描根目录卡死问题记录
环境信息 操作系统: macOS 15.5 (Apple M2芯片)Android Studio版本: Meerkat Feature Drop | 2024.3.2 Patch 1 (Build #AI-243.26053.27.2432.13536105, 2025年5月22日构建) 问题现象 在项目开发过程中,提示一个依赖外部头文件的cpp源文件需要同步,点…...

代码随想录刷题day30
1、零钱兑换II 给你一个整数数组 coins 表示不同面额的硬币,另给一个整数 amount 表示总金额。 请你计算并返回可以凑成总金额的硬币组合数。如果任何硬币组合都无法凑出总金额,返回 0 。 假设每一种面额的硬币有无限个。 题目数据保证结果符合 32 位带…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...
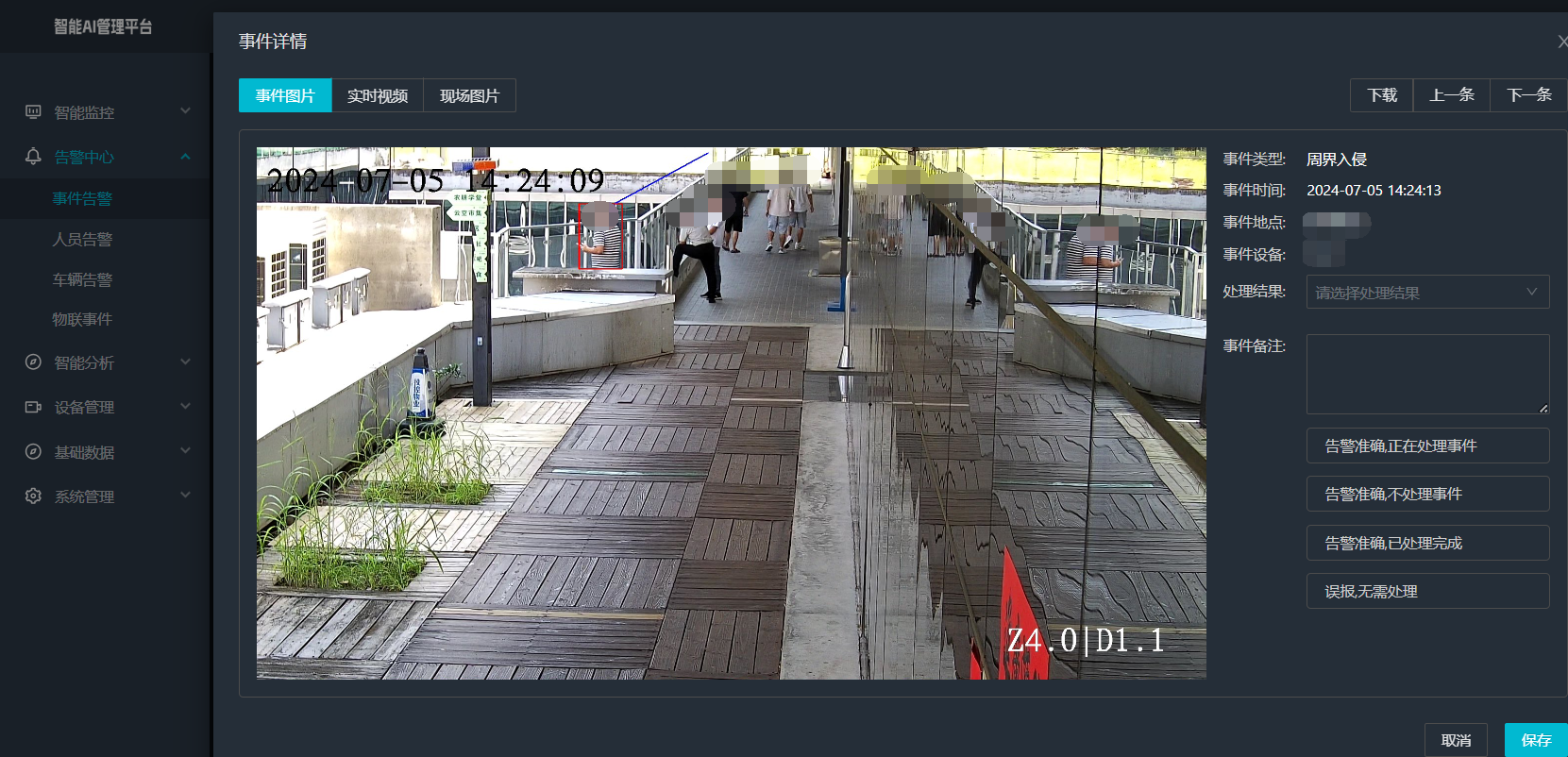
打手机检测算法AI智能分析网关V4守护公共/工业/医疗等多场景安全应用
一、方案背景 在现代生产与生活场景中,如工厂高危作业区、医院手术室、公共场景等,人员违规打手机的行为潜藏着巨大风险。传统依靠人工巡查的监管方式,存在效率低、覆盖面不足、判断主观性强等问题,难以满足对人员打手机行为精…...