MYSQL开发误区
一、表、列、索引设计误区
1、现象:在线业务系统出现了三张表以上的关联查询
建议:说明业务逻辑在表设计上的实现不合理,需要进行表结构调整,或进行列的冗余,或进行业务改造。
2、现象:大表拆成多张小表之后,表之间通过ID关联,需要关联查询的时候,根据ID到表中再取出对应的值
建议:可在子表适当冗余主表的字段,避免回表查询。
3、误区:表数据一多了,就要拆分表
正解:不能为了拆表而拆表,要与业务切合,我们的设计永远是以符合业务发展为第一出发点。
讨论:是否可以归档,建立历史库?数据是否符合冷热分离? 数据是否可以直接删除?
4、现象:单行太长,即列太多
建议:行长不要超过8K, innodb_page_size的一半,性能最佳,不跨页。
5、现象:非常核心且数据量不大且并发度不高的表,可以建立外键
建议:外键所保证的数据一致性应该由程序来保障,没必要建立外键,外键带来的维护成本很高,也会产生性能问题。
6、现象:两表关联查询,字符集不一致
正解:两表字符集,全库字符集必须保持一致。
7、误区:所有int类型直接使用bigint就行了
正解:同理,如果可能尽量使用TINYINT、SMALLINT、MEDIUM_INT,且加上UNSIGNED。
讨论:是否一刀切会更好?比如两表关键查询,一边是tinyint,一边是int,无法使用索引,而且表join会按照数据类型申请内存。
8、误区:大量使用enum字段,提升性能
正解:enum的兼容性不好,容易插入期望之外的数字,突然出错。使用tinyint代替之 讨论:其实这里最大的出发点是担心开发对此字段的使用不好,产生期望之外的数据错误。
9、误区: timestamp性能更优,时间使用timestamp,而不是datetime
正解:除非有国际化需要,否则不要使用timestamp。且两者性能差异已不明显, datetime多占一倍的存储空间也可以接受,但是datetime比如受控, timestamp如果建表不注意引起数据错乱 。
10、误区:所有字段都使用varchar
正解:定长的字符使用char,性能提升不止一倍。比如身份证号、MD5值 。
11、误区:可以提前预留字段,以防备用
正解:严禁预留字段,无法从流程还是规范上都说不过去,修改列类型更是得不偿失。
12、误区:ID使用uuid
正解:随机字符串会任意分布在很大的空间,导致INSERT和SELECT语句变得很慢,性能也不如整型。
13、现象:关联表的列类型不一致
正解:一定要一致,避免隐式转换。
讨论:其实在一些情况下,是不需要一致的,但为了避免情况复杂化,一刀切有时候更有效。
14、误区:数值类型尤其是涉及资金的列使用float或double类型无所谓
正解:一定要使用decimal类型,避免数值在运算中丢失。
15、误区:表每列都单独建立索引,一列一索引
正解:每个表在查询中只能使用一个索引,这个可以从执行计划中看的出来。
16、现象:一个索引包含的列太多
建议:一个索引包含的列一般不超过3个,最多不超过5个。
17、误区:只需要在where条件上建立索引就行了,不用管查询列
正解:如果可以建立覆盖索引,就建立覆盖索引;如果能打出三星,就一定要打出三星索引。
二、SQL开发误区
1、误区:较多表进行关联查询
正解:严禁超过三以上的表进行关联查询。
2、误区:对更新特别频繁的表进行count(*)
正解:非DA不要对更新频繁的表进行count(*)操作,若不需要特别精确,可以从数据字典表取值。
3、现象:很多返回的结果集其实是不需要排序的
建议:如果order by的列上没有索引,可以加上order by null,提升性能。
4、误区:count(column) 和 count(*) 是一样的
正解:count(column) 是表示结果集中有多少个column字段不为空的记录,而count(*) 是表示整个结果集有多少条记录。
5、误区:大量使用or或union
正解:or的性能比较低下,如果可能,推荐使用union或union all来代替。而如果肯定or的左右结果集没 有交集,可直接使用union all来代替union。
6、误区:子查询和join的性能一样没区别
正解:虽然join性能不佳(相对于Oracle而言),但仍然强于子查询,优先使用等价join的。
update operation o set status = 'applying' where o.id in (select id from (select o.id, o.status from operation o where o.group = 123 and o.status not in ( 'done' ) order by o.parent, o.id limit 1) t); +----+--------------------+-------+-------+---------------+---------+---------+-------+------+-----------------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+--------------------+-------+-------+---------------+---------+---------+-------+------+-----------------------------------------------------+ |1 |PRIMARY |o |index| |PRIMARY|8 | |24 |Using where;Using temporary | | 2 | DEPENDENT SUBQUERY | | | | | | | | Impossible WHERE noticed after reading const tables | |3 |DERIVED |o |ref |idx_2,idx_5 |idx_5 |8 |const|1 |Using where;Using filesort | +----+--------------------+-------+-------+---------------+---------+---------+-------+------+-----------------------------------------------------+ ----- update operation o join (select o.id, o.status from operation o where o.group = 123 and o.status not in ( 'done' ) order by o.parent, o.id limit 1) ton o.id = t.id set status = 'applying'; +----+-------------+-------+------+---------------+-------+---------+-------+------+-----------------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+-------+---------+-------+------+-----------------------------------------------------+ | 1 | PRIMARY | | | | | | | | Impossible WHERE noticed after reading const tables | |2 |DERIVED |o |ref |idx_2,idx_5 |idx_5|8 |const|1 |Using where;Using filesort | +----+-------------+-------+------+---------------+-------+---------+-------+------+-----------------------------------------------------+ |
7、误区:使用比较多在分页limit,且offset非常大
正解:将数据一次性load到程序中进行排序,让计算的工作交给程序。非用不可,使用子查询代替之。
select *from t1 where ftype=1 order by id desc limit 99999999, 100;
---à select * from (select * from t1 where id > ( select id from t1 where ftype=1 order by id desc limit 99999999, 1) limit 100) t order by id desc;
8、误区: exists性能in高
正解:MySQL中的in语句是把外表和内表作hash 连接,而exists语句是对外表作loop循环,每次loop循环再对内表进行查询。一直大家都认为exists比in语句的效率要高,这种说法其实是不准确的。这个是要看情 况的。如果查询的两个表大小相当,那么用in和exists差别不大。而对于not in 和not exists来说,如果查询语 句使用了not in 那么内外表都进行全表扫描,没有用到索引而not extsts 的子查询依然能用到表上的索引。所以无论那个表大,用not exists都比not in要快。
select * from A where cc in (select cc from B) ----效率低,用到了A表上cc列的索引
select * from A where exists(select cc from B where cc=A.cc) ----效率高,用到了B表上cc列的索引
select * from B where cc in (select cc from A) ----效率高,用到了B表上cc列的索引
select * from B where exists(select cc from A where cc=B.cc) ----效率低,用到了A表上cc列的索引
9、现象:一条SQL返回不知道大约会预期回返回多少行结果,或根本就不需要返回那么多行
建议:很多情况下,可在SQL后面加上limit n,如果明确知道只会返回一行结果,加limit 1。
10、现象:在复杂SQL的最后才加入where条件
建议:子查询中提前加入where条件,提前过滤掉比较多的数据。
select * from my_order o left join my_userinfo u on o.uid = u.uidleft join my_productinfo p on o.pid = p.pid where ( o.display = 0 ) and ( o.ostaus = 1 ) order by o.selltime desc limit 0, 15; +----+-------------+-------+--------+---------------+---------+---------+-----------------+--------+----------------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+--------+---------------+---------+---------+-----------------+--------+----------------------------------------------------+ | 1 | SIMPLE | o | ALL | NULL | NULL | NULL | NULL | 909119 | Using where; Using temporary; Using filesort | | 1 | SIMPLE | u | eq_ref | PRIMARY | PRIMARY | 4 | o.uid | 1 | NULL | | 1 | SIMPLE | p | ALL | PRIMARY | NULL | NULL | NULL | 6 | Using where; Using join buffer (Block Nested Loop) | +----+-------------+-------+--------+---------------+---------+---------+-----------------+--------+----------------------------------------------------+select * from (select * from my_order o where ( o.display = 0 ) and ( o.ostaus = 1 ) order by o.selltime desc limit 0, 15) o left join my_userinfo u on o.uid = u.uid left join my_productinfo p on o.pid = p.pid order by o.selltime desc limit 0, 15; +----+-------------+------------+--------+---------------+---------+---------+-------+--------+----------------------------------------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+------------+--------+---------------+---------+---------+-------+--------+----------------------------------------------------+ | 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 15 | Using temporary; Using filesort | | 1 | PRIMARY | u | eq_ref | PRIMARY | PRIMARY | 4 | o.uid | 1 | NULL | | 1 | PRIMARY | p | ALL | PRIMARY | NULL | NULL | NULL | 6 | Using where; Using join buffer (Block Nested Loop) | | 2 | DERIVED | o | index | NULL | idx_1 | 5 | NULL | 909112 | Using where | +----+-------------+------------+--------+---------------+---------+---------+-------+--------+----------------------------------------------------+ |
11、现象:in (....)中的值的个数过多
建议:不要超过500个,超过500个性能会剧烈下降
12、误区:无脑进行order by,不管列是否可以使用其他的列代替
正解:可以使用具备等同业务逻辑含义的、已经建立索引的列代替。比如order by adtime; 但是在adtime列此时没有加入索引,现在的order by 必须要引起非常大的磁盘排序,但是有时候我们的ID列是具备时间属性的,因此可以使用order by primaryid; 来代替之。
13、现象:不了解order by中null的前面顺序
正解:Oracle和MySQL对比一下:
Oracle:
order by colum asc 时,null默认被放在最后
order by colum desc 时,null默认被放在最前
nulls first 时,强制null放在最前,不为null的按声明顺序[asc|desc]进行排序
nulls last 时,强制null放在最后,不为null的按声明顺序[asc|desc]进行排序
MySQL:
order by colum asc 时,null默认被放在最前
order by colum desc 时,null默认被放在最后
ORDER BY IF(ISNULL(update_date),0,1) null被强制放在最前,不为null的按声明顺序[asc|desc]进行排序
ORDER BY IF(ISNULL(update_date),1,0) null被强制放在最后,不为null的按声明顺序[asc|desc]进行排序
14、现象:大量使用not in
建议:使用left join代替
原SQL: select col1, col2 from table where col3 not in (select col4 from table2);
改写成:select col1, col2 from table a left join table2 b where a.col3 = b.col4 and b.col4 is null;
15、现象:SQL中时间范围不合理
建议:很久之前的时间其中明显不应该再存在有用的数据,比如每天跑批,如果有,早就应该跑出来了。
可以纪录一下上次成功的时间点,把此点带进去,减少扫描范围
select * from abc where change_time <‘2017-08-01’;
-----> select * from abc where change_time <‘2017-08-01’and change_time >‘2017-07-01’;
16、误区:无脑使用between或范围区间
正解:这样容易导致索引失效,有的时候,between可以转换为in。比如索引建在id,a列上。
原SQL: select * from abc where a=‘b’and id between 7 and 10;
改写成 :select * from abc where a=‘b’and id in (7,8,9,10);
17、误区:防止隐式转换只能通过修改列的类型转换完成
正解:如果不方便修改列类型,可以通过函数在等式右边完成转换。
18、查询语句只要完成功能就行,带不带条件不影响
正解:查询语句要带上条件
SELECT `model`,`hwversion`,`version`,`day`,`createtime` FROM `rpt_upgrade_model_ver_daily` ORDER BY createtime DESC LIMIT 1; |
上面的查询查询createtime最新的一条,没有带where条件,表数据行1千多万行,查询耗时20s左右,这种一定要加上where createtime>current_time-10*60(最近10分钟)。
19.批量插入没什么影响
正解:批量插入使用不当会长时间的锁等待。
insert into t_rank_result (id,version_id,rank_no,intervention_rank_no,res_id,begin_time,end_time,intervention_time,final_rank_no ) SELECT NULL,43797777,(@row := @row + 1),t1.rank_no AS intervention_rank_no,t.res_id,t1.begin_time,t1.end_time, t1.intervention_time, ifnull(t1.rank_no,@row) FROM t_resource_sort_mapping t LEFT JOIN t_rank_intervention t1 ON t.res_id = t1.res_id and t1.rank_type = 2 AND (t1.category=1 or t1.category=3) AND t1.rank_subtype = '2' , (select @row := ifnull(max(rank_no),0) from t_rank_result where version_id = 43797777) t3 WHERE t.del_flag=0 AND t.sort_id = 2 and not exists(select 1 from t_rank_result t2 where version_id = 43797777 and t.res_id = t2.res_id); |
上面这个是insert inot ..... 复杂查询; 这种是典型的"Bulk Insert",会导致表t_rank_result自增锁长时间等待。
以下几种bulk insert 尽量不要在线上业务使用:
1)insert into .... select ...;
2)repalce into ... select ...;
3)load data ....
20.批量更新(update/delete)很随意,不用考虑数据库是不是有问题
正解:批量更新(update/delete)一定记得批量做,不要一次一条sql直接update或delete 全表/超过10w行数据,导致数据库负载直接飙高,性能受到影响。
同理:线上业务不要使用大事务,大事务产生长时间的锁等待,导致从库延迟,严重会导致binlog的单个事务超过1G,从库复制中断。
delete from t_ssp_non_audit_ad_info where launch_time < ‘${sixHourBefore}’; |
相关文章:

MYSQL开发误区
一、表、列、索引设计误区 1、现象:在线业务系统出现了三张表以上的关联查询 建议:说明业务逻辑在表设计上的实现不合理,需要进行表结构调整,或进行列的冗余,或进行业务改造。 2、现象:大表拆成多张小表之…...
k8s学习之路 | k8s 工作负载 DaemonSet
文章目录1. DaemonSet 基础1.1 什么是 DS1.2 DS 的典型用法1.3 如何编写 DS 资源1.4 DS 示例文件1.5 DS Pod 是如何被调度的1.6 更新 DS1.7 DS 替代方案1.8 DS 工作负载字段描述2. DaemonSet 的使用2.1 每个节点运行一个2.2 DS 更新策略2.3 滚动更新2.4 OnDelete 更新2.6 更新回…...
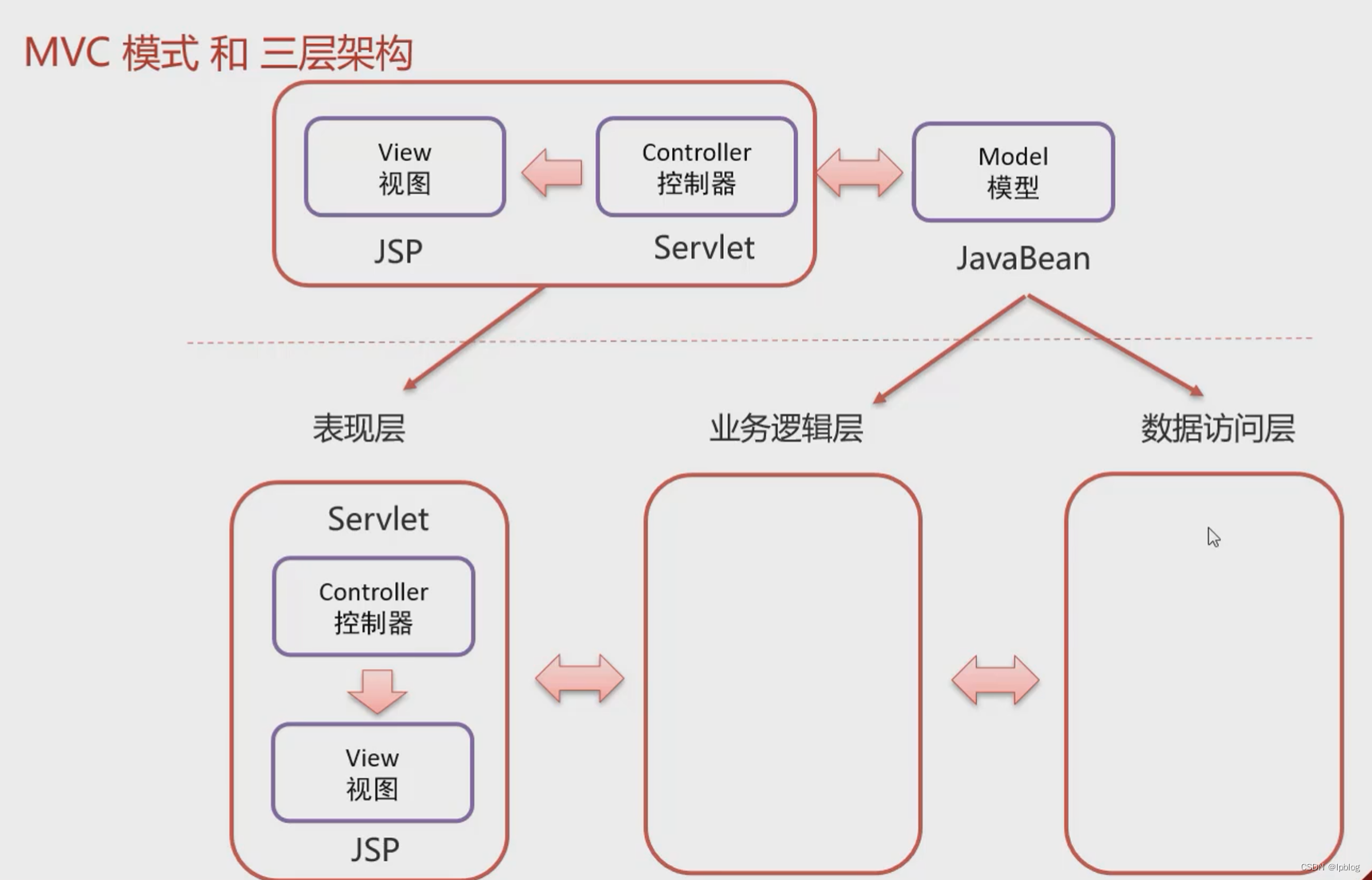
Javaweb MVC模式和三层架构
MVC 模式和三层架构是一些理论的知识,将来我们使用了它们进行代码开发会让我们代码维护性和扩展性更好。 7.1 MVC模式 MVC 是一种分层开发的模式,其中: M:Model,业务模型,处理业务 V:View&am…...

综合考虑,在客户端程序中嵌入网页程序,首选CefSharp。
综合考虑,在客户端程序中嵌入网页程序,首选CefSharp。 CefSharp 是一种将全功能符合标准的 Web 浏览器嵌入 C# 或 VB.NET 应用程序的简单方法。 https://www.jianshu.com/p/3f50cc747606 WinForm嵌入Web网页的解决方案 Microsoft Edge WebView2诞生较晚…...

【Java基础 下】 030 -- 网络编程
目录 一、什么是网络编程 1、常见的软件架构(CS & BS) ①、BS架构的优缺点 ②、CS架构的优缺点 2、小结 二、网络编程三要素 1、IP ①、IPv4 ②、IPv6 ③、小结 ④、IPv4的一些细节 ⑤、InetAddress的使用 2、端口号 3、协议 ①、TCP & UDP 三、…...
 T3打拳)
2021牛客OI赛前集训营-提高组(第三场) T3打拳
2021牛客OI赛前集训营-提高组(第三场) 题目大意 有2n2^n2n个选手参加拳击比赛,每个人都有一个实力,所有选手的实力用一个111到2n2^n2n的排列表示。 淘汰赛的规则是:每次相邻的两个选手进行比赛,实力值大…...

C++面向对象编程之四:成员变量和成员函数分开存储、this指针、const修饰成员和对象
在C中,成员变量和成员函数是分开存储的,只有非静态成员变量才存储在类中或类的对象上。通过该类创建的所有对象都共享同一个函数#include <iostream> using namespace std;class Monster {public://成员函数不占对象空间,所有对象共享同…...
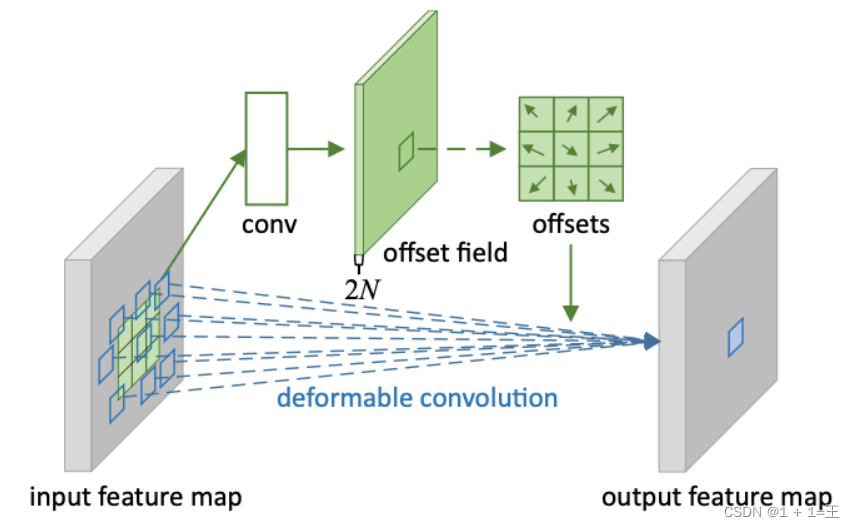
卷积神经网络(CNN)基础知识
文章目录CNN的组成层卷积层卷积运算卷积的变种分组卷积转置卷积空洞卷积可变形卷积卷积层的输出尺寸和参数量CNN的组成层 在卷积神经⽹络中,⼀般包含5种类型的⽹络层次结构:输入层、卷积层、激活层、池化层和输出层。 输入层(input layer&a…...

opencv+python 常见图像预处理
import os import cv2 import numpy as np import pandas as pd from PIL import Image import matplotlib.pylab as plt """图像预处理"""#缩放 #灰度化 #二值化-otsu,自定义,自适应 #均值滤波 #中值滤波 #自定义滤波 #高斯/双倍滤波…...

如何实现一个单例模式
目录 前言 1.饿汉式 2.懒汉式 3.双重检测 4.静态内部类 5.枚举 总结: 前言 单例模式是我们日常开发过程中,遇到的最多的一种设计模式。通过这篇文章主要分享是实现单例的几种实现方式。 1.饿汉式 饿汉式的实现方式比较简单。在类加载的时候&#…...
传输线的物理基础(四):传输线的驱动和返回路径
驱动一条传输线对于将信号发射到传输线的高速驱动器,传输线在传输时间内的输入阻抗将表现得像一个电阻,相当于线路的特性阻抗。鉴于此等效电路模型,我们可以构建驱动器和传输线的电路,并计算发射到传输线中的电压。等效电路如下图…...

Java多态性
文章目录对象的多态性多态的理解举例7.2 多态的好处和弊端7.3 虚方法调用(Virtual Method Invocation)7.4 成员变量没有多态性7.5 向上转型与向下转型7.6 为什么要类型转换呢?7.7 如何向上转型与向下转型7.8 instanceof关键字7.9 复习:类型转换7.10 练习…...

算法拾遗二十七之窗口最大值或最小值的更新结构
算法拾遗二十七之窗口最大值或最小值的更新结构滑动窗口题目一题目二题目三题目四滑动窗口 第一种:R,R右动,数会从右侧进窗口 第二种:L,L右动,数从左侧出窗口 题目一 arr是N,窗口大小为W&…...

【带你搞定第二、三、四层交换机】
01 第二层交换机 OSI参考模型的第二层叫做数据链路层,第二层交换机通过链路层中的MAC地址实现不同端口间的数据交换。 第二层交换机主要功能,就包括物理编址、错误校验、帧序列以及数据流控制。 因为这是最基本的交换技术产品,目前桌面…...

C++基础了解-22-C++ 重载运算符和重载函数
C 重载运算符和重载函数 一、C 重载运算符和重载函数 C 允许在同一作用域中的某个函数和运算符指定多个定义,分别称为函数重载和运算符重载。 重载声明是指一个与之前已经在该作用域内声明过的函数或方法具有相同名称的声明,但是它们的参数列表和定义…...
BatchNormalization
目录 Covariate Shift Internal Covariate Shift BatchNormalization Q1:BN的原理 Q2:BN的作用 Q3:BN的缺陷 Q4:BN的均值、方差的计算维度 Q5:BN在训练和测试时有什么区别 Q6:BN的代码实现 Covariate Shift 机器学习中&a…...

vue 中安装插件实现 rem 适配
vue 中实现 rem 适配vue 项目实现页面自适应,可以安装插件实现。 postcss-pxtorem 是 PostCSS 的插件,用于将像素单元生成 rem 单位。 autoprefixer 浏览器前缀处理插件。 amfe-flexible 可伸缩布局方案替代了原先的 lib-flexible 选用了当前众多浏览…...
Hadoop学习
1.分布式与集群 hosts文件: 域名映射文件 2.Linux常用命令 ls -a:查看当前目录下所有文件mkdir -p:如果没有对应的父文件夹,会自动创建rm -rf:-f:强制删除 -r:递归删除cp -r:复制文…...

Golang反射源码分析
在go的源码包及一些开源组件中,经常可以看到reflect反射包的使用,本文就与大家一起探讨go反射机制的原理、学习其实现源码 首先,了解一下反射的定义: 反射是指计算机程序能够在运行时,能够描述其自身状态或行为、调整…...

Qt之悬浮球菜单
一、概述 最近想做一个炫酷的悬浮式菜单,考虑到菜单展开和美观,所以考虑学习下Qt的动画系统和状态机内容,打开QtCreator的示例教程浏览了下,大致发现教程中2D Painting程序和Animated Tiles程序有所帮助,如下图所示&a…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

HTML前端开发:JavaScript 常用事件详解
作为前端开发的核心,JavaScript 事件是用户与网页交互的基础。以下是常见事件的详细说明和用法示例: 1. onclick - 点击事件 当元素被单击时触发(左键点击) button.onclick function() {alert("按钮被点击了!&…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...

中医有效性探讨
文章目录 西医是如何发展到以生物化学为药理基础的现代医学?传统医学奠基期(远古 - 17 世纪)近代医学转型期(17 世纪 - 19 世纪末)现代医学成熟期(20世纪至今) 中医的源远流长和一脉相承远古至…...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

如何更改默认 Crontab 编辑器 ?
在 Linux 领域中,crontab 是您可能经常遇到的一个术语。这个实用程序在类 unix 操作系统上可用,用于调度在预定义时间和间隔自动执行的任务。这对管理员和高级用户非常有益,允许他们自动执行各种系统任务。 编辑 Crontab 文件通常使用文本编…...

(12)-Fiddler抓包-Fiddler设置IOS手机抓包
1.简介 Fiddler不但能截获各种浏览器发出的 HTTP 请求,也可以截获各种智能手机发出的HTTP/ HTTPS 请求。 Fiddler 能捕获Android 和 Windows Phone 等设备发出的 HTTP/HTTPS 请求。同理也可以截获iOS设备发出的请求,比如 iPhone、iPad 和 MacBook 等苹…...