flask-slqalchemy使用详解
目录
1、flask-sqlalchemy
1.1、flask_sqlalchemy 与sqlalchemy 的关系
1.1.1、 基本定义与用途
1.2、flask_sqlalchemy 的使用
1.2.1、安装相关的库
1.2.2、项目准备
1.2.3、创建ORM模型
1.2.3.1、使用db.create_all()创建表的示例
1.2.3.2、创建多表关联ORM模型
1.2.4、直接执行SQl语句
1.2.5、新增数据
1.2.6、修改数据
1.2.6、删除数据
1.2.6、查询数据
注:slqalchemy详细使用说明见文章:Python 之SQLAlchemy使用详细说明-CSDN博客
1、flask-sqlalchemy
1.1、flask_sqlalchemy 与sqlalchemy 的关系
1.1.1、 基本定义与用途
- sqlalchemy:
- 是一款Python编程语言下的开源软件,提供了SQL工具包及对象关系映射(ORM)工具。
- 允许开发人员通过Python类与对象来操作数据库,从而避免了直接编写SQL语句的复杂性。
- 支持多种数据库系统,如SQLite、MySQL、PostgreSQL等。
- flask_sqlalchemy:
- 是sqlalchemy的一个扩展或封装,专门用于Flask web框架。
- 简化了在Flask应用中与数据库交互的过程,例如配置、初始化、使用ORM等。
- 使得在Flask中集成数据库变得更为方便和直观。
1.1.2、关系与区别
- 关系:
- flask_sqlalchemy基于sqlalchemy进行了扩展和优化,使其更适应于Flask框架的使用场景。
- 两者都提供了ORM功能,允许通过Python对象来操作数据库。
- 区别:
- 用途:sqlalchemy是一个通用的数据库ORM工具,而flask_sqlalchemy则专门为Flask框架设计。
- 配置:在Flask中使用flask_sqlalchemy时,可以通过Flask的配置文件来配置数据库连接信息,而sqlalchemy则需要单独进行配置。
- 初始化:flask_sqlalchemy在初始化时会与Flask应用对象关联,而sqlalchemy则直接创建引擎和会话。
- 简化操作:flask_sqlalchemy在Flask应用中提供了更简洁的数据库操作方式,如定义模型、查询等。
1.1.3、使用建议
- 如果开发一个基于Flask的web应用,并且需要与数据库进行交互,那么推荐使用flask_sqlalchemy,因为它提供了与Flask框架更好的集成和更简洁的使用方式。
- 如果需要在一个非Flask项目中使用ORM,或者需要更灵活和定制化的数据库操作,那么可以选择直接使用sqlalchemy。
1.2、flask_sqlalchemy 的使用
sqlalchemy官方文档:Session API — SQLAlchemy 2.0 Documentation
falsk-sqlalchemy官方文档:Flask-SQLAlchemy — Flask-SQLAlchemy Documentation (3.1.x)
说明:因为flask-sqlalchemy是基于sqlalchemy扩展与flask集成,所以flask-sqlalchemy的使用很多都是基于sqlalchemy进行封装的,如果了解sqlalchemy那么使用flask-sqlalchemy就会很简单。
1.2.1、安装相关的库
说明:本文中所有的代码示例,相关软件和库的版本如下:
- Python:3.9
- Flask :2.3.3
- Flask-Migrate :4.0.5
- Flask-SQLAlchemy :3.1.1
1、安装flask
pip install flask
2、安装数据库迁移工具Flask-Migrate,安装这个库的同时也会安装Flask-SQLAlchemy
pip install Flask-Migrate
1.2.2、项目准备
说明:下面会通过一些示例来说明flask-sqlalchemy的常见使用。首先需要新建三个py文件,文件目录结构如下:
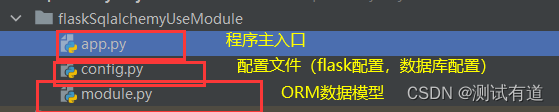
1、app.py
"""
主程序入口
"""
from module import db
from flask_migrate import Migrate
from flask import Flaskimport configapp = Flask(__name__)# 绑定配置文件
app.config.from_object(config)
# 初始化db
db.init_app(app)# 使用数据库迁移来管理数据库模型的更改
# 在Flask中,数据库迁移是对数据库模式或结构进行更改时,通过执行一系列有序的迁移脚本来保持数据的一致性和完整性
# ORM模型映射成数据库表的三步,需要在控制台执行下面命令:
# 1、flask db init : 初始化ORM模型,只需要执行一次即可(即首次执行)
# 2、flask db migrate: 识别ORM模型的改变,生成迁移脚本
# 3、flask db upgrade: 运行迁移脚本,同步到数据库中
migrate = Migrate(app, db)if __name__ == '__main__':app.run(debug=True)2、config.py文件
- 注意:数据库的主机地址,用户密码需要换成自己的
"""配置文件
"""
# 设置秘钥用于session加密,秘钥越长安全性越高
# 在Flask应用中配置一个密钥,用于对会话数据进行加密和签名。密钥的选择很重要,应该是足够随机和安全的。
SECRET_KEY = "asfjlahfdasnflbbFA"# 数据库配置信息
# MySQL所在的主机名
HOSTNAME = "172.22.70.174"
# MySQL监听的端口号,默认3306
PORT = 3306
# 连接MySQL的用户名
USERNAME = "root"
# 连接MySQL的密码
PASSWORD = ""
# MySQL上创建的数据库名称
DATABASE = "test1"
DB_URI = 'mysql+pymysql://{}:{}@{}:{}/{}?charset=utf8'.format(USERNAME,PASSWORD,HOSTNAME,PORT,DATABASE)
SQLALCHEMY_DATABASE_URI = DB_URI
# 数据库连接池的大小,默认为5
SQLALCHEMY_POOL_SIZE = 10
# 等待数据库连接的超时时间(秒),默认为10
SQLALCHEMY_POOL_TIMEOUT = 30
# 用于配置 SQLAlchemy 引擎选项的 Flask 配置参数
# SQLAlchemy 引擎选项允许你控制数据库连接的各种行为,例如连接池的大小、超时设置、SSL 配置等
SQLALCHEMY_ENGINE_OPTIONS = {'pool_size': 10, # 连接池大小'max_overflow': 5, # 当连接池中的连接都被使用时,额外创建的连接数'pool_recycle': 3600, # 多久之后自动回收连接(秒)# 你还可以添加其他 SQLAlchemy 引擎选项,例如 SSL 配置等# 'connect_args': {'sslmode': 'require', ...}}3、module.py
"""
ORM数据模型
"""
from flask_sqlalchemy import SQLAlchemydb = SQLAlchemy()1.2.3、创建ORM模型
db.create_all()创建表和使用Migrate管理迁移数据库的区别:
- db.create_all()
- 通常用于创建新表(如果表存在不会做任何事情,只是创建对应的ORM映射关系,注意:这不会更改已经存在的表结构 )
- Migrate
- 能够跟踪数据库模式的变化,并能够轻松地升级、降级或回滚这些变化。
使用 Flask-Migrate 的命令来创建和管理迁移。这通常涉及以下步骤:
1.初始化迁移仓库:
- 在项目的根目录下运行 flask db init 命令来创建一个迁移仓库。注意:这个只需要运行一次,也就是首次运行的时候。
2.生成迁移脚本
- 当你修改了 Flask-SQLAlchemy 模型(例如添加新表、字段或约束)时,你需要生成一个新的迁移脚本。这可以通过运行 flask db migrate 命令来完成。这个命令会检查当前的模型与上一次迁移之后的数据库状态之间的差异,并生成一个 Python 脚本,该脚本描述了如何将这些差异应用到数据库上。
3.应用迁移
- 一旦你生成了迁移脚本,你就可以通过运行 flask db upgrade 命令来将这些更改应用到数据库上。同样地,你也可以使用 flask db downgrade 命令来撤销最近的迁移。
1.2.3.1、使用db.create_all()创建表的示例
from flask import Flask
from flask_sqlalchemy import SQLAlchemy app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'your_database_uri' # 例如:'sqlite:tmp/test.db'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
db = SQLAlchemy(app) class User(db.Model): id = db.Column(db.Integer, primary_key=True) username = db.Column(db.String(80), nullable=False) email = db.Column(db.String(120), unique=True, nullable=False) # 定义其他方法或关系(如果需要) # 初始化数据库(如果尚未创建)
# 注意:这不会更改已经存在的表结构
with app.app_context(): db.create_all() # 这通常用于创建新表,但在这里不会做任何事情(因为表已经存在) # 接下来,你可以像通常一样使用这个模型来查询数据库
# 例如:users = User.query.all()1.2.3.2、创建多表关联ORM模型
说明:先建立t_emp员工表和t_dept部门表两张表,并插入对应数据
1、在module.py文件中新增ORM模型如下:
from flask_sqlalchemy import SQLAlchemydb = SQLAlchemy()class Departments(db.Model):__tablename__ = "t_dept"id = db.Column(db.Integer, primary_key=True, autoincrement=True)name = db.Column(db.String(50), nullable=False, comment="部门名称")class Employes(db.Model):__tablename__ = "t_emp"id = db.Column(db.Integer, primary_key=True, autoincrement=True)name = db.Column(db.String(50), nullable=False, comment="姓名")age = db.Column(db.Integer, comment="年龄")job = db.Column(db.String(20), comment="职位")salary = db.Column(db.Integer, comment="薪资")entrydate = db.Column(db.DateTime, comment="入职时间")managerid = db.Column(db.Integer, comment="直属领导ID")dept_id = db.Column(db.Integer, db.ForeignKey("t_dept.id"))# 与表t_dept建立反向引用,在Departments模型中将会生成一个名为 "employes" 的属性,可以通过该属性获取该部门的员工的信息departemnt = db.relationship(Departments, backref="employes")注意:
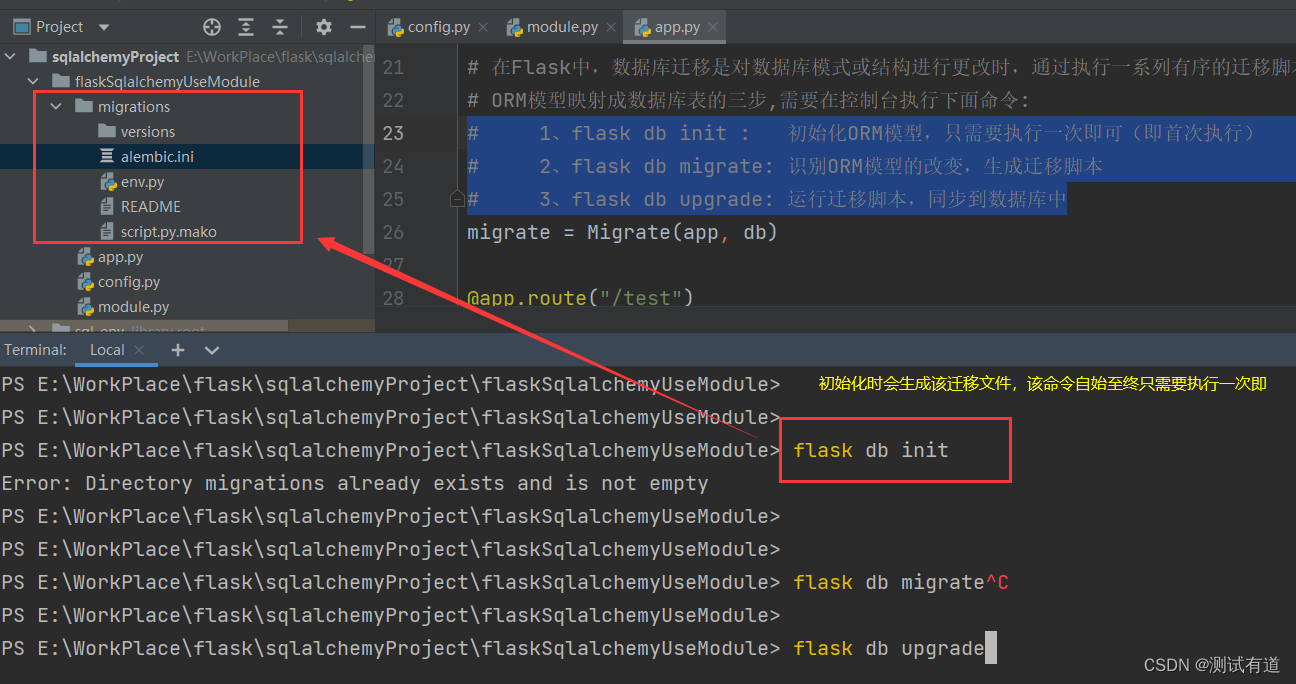
- 如果数据库中没有这两张表,需要先生成迁移脚本,然后执行在数据库中创建表。
- 如果表中的字段或者约束等发生了变化,也是执行下面的第二、三命令(此时命令:flask db init 不需要再执行 )
flask db init
flask db migrate
flask db upgrade
执行演示如下:
注意:如果创建的表的编码不是utf8mb4,需要修改为utf8mb4,不然插入中文的数据会出现编码错误,执行以下SQL语句:
ALTER TABLE t_dept CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
ALTER TABLE t_emp CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
2、插入测试数据
INSERT INTO t_dept (name) VALUES ('研发部'), ('市场部'),('财务部'), ('销售部'), ('总经办'), ('人事部');
INSERT INTO t_emp (id, name, age, job,salary, entrydate, managerid, dept_id) VALUES
(1, '大刘', 28, '总裁',40000, '2000-01-01', null,5),
(2, '夏析', 20, '项目经理',20000, '2005-12-05', 1,1),
(3, '李兴', 33, '开发', 8000,'2000-11-03', 2,1),
(4, '张敏', 30, '开发',11000, '2002-02-05', 2,1),
(5, '林夕', 43, '开发',10500, '2004-09-07', 3,1),
(6, '小美', 19, '程序员鼓励师',6600, '2004-10-12', 2,1),
(7, '林逸', 60, '财务总监',8500, '2002-09-12', 1,3),
(8, '李媛', 19, '会计',48000, '2006-06-02', 7,3),
(9, '林妙妙', 23, '出纳',5250, '2009-05-13', 7,3),
(10, '赵芳', 20, '市场部总监',12500, '2004-10-12', 1,2),
(11, '张三', 56, '职员',3750, '2006-10-03', 10,2),
(12, '李四', 19, '职员',3750, '2007-05-09', 10,2),
(13, '王二', 19, '职员',5500, '2009-02-12', 10,2),
(14, '周鑫', 88, '销售总监',14000, '2004-10-12', 1,4),
(15, '刘达', 38, '销售',4600, '2004-10-12', 14,4),
(16, '老钱', 40, '销售',4600, '2004-10-12', 14,4),
(17, '小六', 42, null,2000, '2011-10-12', 1,null);
1.2.4、直接执行SQl语句
说明:在 Flask-SQLAlchemy 中,虽然推荐使用 ORM(对象关系映射)来进行数据库操作,但有时候你可能需要直接执行 SQL 语句。Flask-SQLAlchemy 提供了 db.session.execute() 方法来执行原生的 SQL 语句。
注意:使用 db.session.execute() 方法执行 SQL 语句时,请确保你的 SQL 语句是安全的,特别是当 SQL 语句中包含用户输入时。防止 SQL 注入的最佳做法是使用参数化查询或 ORM 提供的方法。
示例:
# 直接执行 SQL 语句来更新数据
# 注意:使用 execute 方法时,你需要自己确保 SQL 语句的安全性
update_sql = "UPDATE employees SET name='John Doe Jr.' WHERE id=1"
db.session.execute(update_sql)
db.session.commit() # 直接执行 SQL 语句来查询数据
select_sql = "SELECT * FROM employees WHERE department_id=1"
results = db.session.execute(select_sql).fetchall()
for row in results: print(row) # 输出查询结果 # 如果你想将查询结果映射到模型类,可以使用 Model.query.from_statement()
# 但这通常不如直接使用 ORM 方法来得直观和简单
# # 注意:在使用 text() 函数时,你需要从 sqlalchemy.sql 导入 text
from sqlalchemy.orm import aliased
EmployesAlias = aliased(Employes)
results = Employes.query.from_statement(text(select_sql)).all()
for employee in results: print(employee.name) # 假设查询结果包含了员工的名字 1.2.5、新增数据
需求:演示在t_emp表中插入单条数据和插入多条数据
说明:在app.py文件中进行演示,可以使用函数直接执行的方式,也可以使用请求路由的方式,因为实际使用中都是请求路由,所以这里使用请求路由的方式演示数据的增删改查。
注意:只要涉及到表的数据变化的都需要提交会话
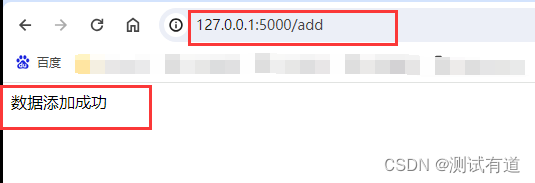
@app.route("/add")
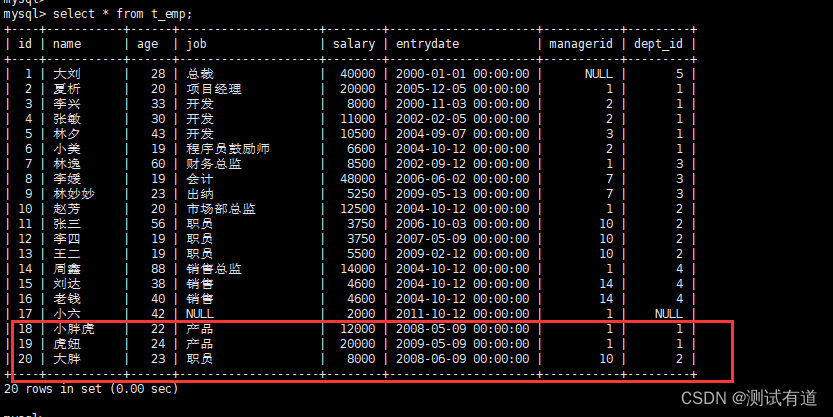
def add():emp1 = Employes(name="小胖虎", age=22, job="产品", salary=12000, entrydate="2008-05-09", managerid=1, dept_id=1)emp2 = Employes(name="虎妞", age=24, job="产品", salary=20000, entrydate="2009-05-09", managerid=1, dept_id=1)emp3 = Employes(name="大胖", age=23, job="职员", salary=8000, entrydate="2008-06-09", managerid=10, dept_id=2)try:# 插入一条数据到数据库中db.session.add(emp1)# 插入多条数据到数据库中db.session.add_all([emp2, emp3])# 提交事务已保存更改到数据库db.session.commit()# 如果在添加过程中发生错误,可以执行回归事务# db.session.rollback()return "数据添加成功"except Exception as e:db.session.rollback()return f"数据添加失败,失败原因:{e}"- 浏览器访问或者使用工具访问接口(如:curl,postman等)
- 数据库查看添加数据是否成功
1.2.6、修改数据
修改数据流程:先查询出数据, 然后修改(想要这些更改被 session 跟踪以便后续可以回滚或提交时使用)。
- 缺点
- 查询和更新分两条语句, 效率低
- 如果并发更新, 可能出现更新丢失问题
所以推荐基于过滤条件的更新,也就是使用 update() 方法,这个方法直接对数据库执行操作,不会触发模型的 events 或 session 的变化;具有如下优势:
- 一条语句, 被网络IO影响程度低, 执行效率更高
- 查询和更新在一条语句中完成, 单条SQL具有原子性, 不会出现更新丢失问题
- 会对满足过滤条件的所有记录进行更新, 可以实现批量更新处理
@app.route("/update")
def update():try:# 1、使用先查询后更新的方式# 更新t_emp表中id=11的员工姓名为:弓长张emp = Employes.query.filter_by(id=11).first()emp.name = "弓长张"# 提交会话db.session.commit()# 2、使用update的方式# 更新t_emp表中name=小六的员工姓名为:老六Employes.query.filter(Employes.name == "小六").update({"name": "老六"})# 提交会话db.session.commit()return "数据更新成功"except Exception as e:db.session.rollback()return f"数据更新失败,失败原因:{e}"1.2.6、删除数据
删除数据流程:先查询数据, 再删除
推荐基于过滤条件的删除,也就是使用delete()方法
@app.route("/delete")
def delete():try:# 1、使用先查询后删除的方式# 删除t_emp表中员工姓名为:弓长张 的员工emp = Employes.query.filter_by(name="弓长张").first()# 删除数据db.session.delete(emp)# 提交会话db.session.commit()# 2、使用delete的方式# 删除t_emp表中员工姓名为:老钱 的员工Employes.query.filter(Employes.name == "老钱").delete()db.session.commit()return "数据删除成功"except Exception as e:db.session.rollback()return f"数据删除失败,失败原因:{e}"1.2.6、查询数据
说明:因为flask-sqlalchemy是基于sqlalchemy扩展的,所以flask-sqlalchemy的使用仅仅是在sqlalchemy之前进行封装了一下,本质还是基于sqlalchemy的,这里的查询可以使用flask-sqlalchemy封装的语法,也可以使用sqlalchemy的语法查询。
这里仅仅展示flsk-sqlalchemy的一些基本查询,具体更加全面的可以参考另一篇关于sqlalchemy使用的文章:Python 之SQLAlchemy使用详细说明-CSDN博客
@app.route("/query")
def query():try:# 全表查询t_emp flask-sqlalchemy语法emps = Employes.query.all()# sqlalchemy语法emps_sqlalchemy = db.session.query(Employes).all()# 模糊查询匹配# 查询姓刘的员工res = Employes.query.filter(Employes.name.like("刘%")).all()# 条件查询# 查询李四和王二的工资信息res2 = Employes.query.options(load_only(Employes.name, Employes.salary)).filter(Employes.name == "李四", Employes.name == "王二").all()# 查询年龄等于20或30的员工信息res2_1 = Employes.query.filter(or_(Employes.age == 20, Employes.age == 30)).all()# 或者使用in_()res2_2 = Employes.query.filter(Employes.age.in_([20, 30]))# 聚合函数# 查询每个年龄对应的人数# 对应的SQL:select age, count(id) as "人数" from t_emp group by ageres3 = db.session.query(Employes.age, func.count(Employes.id).label("nums")).group_by(Employes.age).all()# 分组查询# 根据职位分组 , 统计每个职位平均工资# select job, avg(salary) as "平均工资" from t_emp group by jobres4 = db.session.query(Employes.job, func.avg(Employes.salary).label("avg_salary")).group_by(Employes.job).all()# 排序查询# 根据员工年龄从小到大排序,年龄相同的根据工资从高到低排序# select * from t_emp order by age asc, salary decsres5 = Employes.query.order_by(Employes.age, Employes.salary.desc()).all()# 分页查询# 查询员工信息,每页5条数据,查询第2页的数据# res6.pages 总页数 res6.page 当前页码 res6.items 当前页的数据 res6.total 总条数res6 = Employes.query.paginate(page=2, per_page=5)# 或者使用offset和limit实现res6_1 = Employes.query.order_by(Employes.age).offset(5).limit(5).all()return "查询数据成功"except Exception as e:return f"查询数据失败,失败的原因:{e}"相关文章:
flask-slqalchemy使用详解
目录 1、flask-sqlalchemy 1.1、flask_sqlalchemy 与sqlalchemy 的关系 1.1.1、 基本定义与用途 1.2、flask_sqlalchemy 的使用 1.2.1、安装相关的库 1.2.2、项目准备 1.2.3、创建ORM模型 1.2.3.1、使用db.create_all()创建表的示例 1.2.3.2、创建多表关联ORM模型 1.…...

Scala学习笔记8: 包
目录 第八章 包1- 包2- 包的作用域3- 串联式包语句4- 包对象5- 引入end 第八章 包 在Scala中, 包(Package) 用于组织和管理代码, 类似与 Java 中的包 ; 包可以包含类、对象、特质等Scala代码, 并通过层次结构来组织代码 ; 可以使用 package 关键字来定义包, 并使用 . 来表示…...

分享一份糟糕透顶的简历,看看跟你写的一样不
最近看了一个人的简历,怎么说呢,前几年这么写没问题,投出去就有回复,但从现在开始,这么写肯定不行了。下面我给大家分享一下内容: 目录 🤦♀️这是简历文档截图 🤷♀️这是基本…...
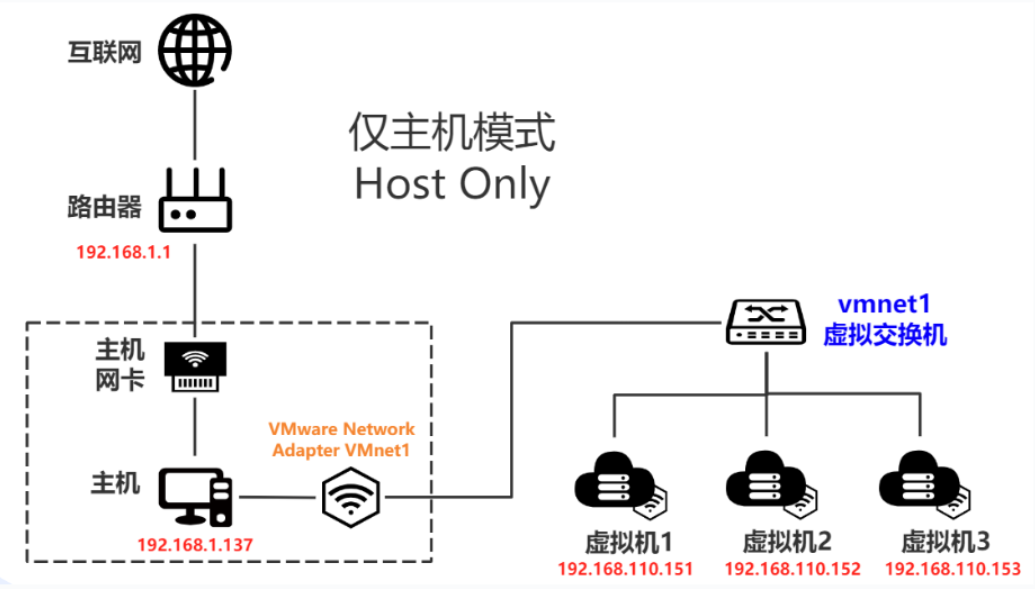
VMware 三种网络模式
目录 一、网卡、路由器、交换机 二、虚拟网络编辑器 三、网络模式 1.桥接模式 通信方式 特点 配置 连通情况 使用场景 2.NAT模式 通信方式 特点 配置 连通情况 使用场景 3.仅主机 通信方式 特点 配置 连通情况 使用场景 一、网卡、路由器、交换机 网卡(Ne…...

红绿二分查找
《英雄算法零基础》之 二分查找 https://articles.zsxq.com/id_ib4xgs0cogic.html 在写模版之前我们先搞清楚二分查找是怎样运行的,我们把一个数组分成红绿两种颜色,可以理解为绿色就是符合情况的,红色就是不符合情况的(类似红绿灯…...
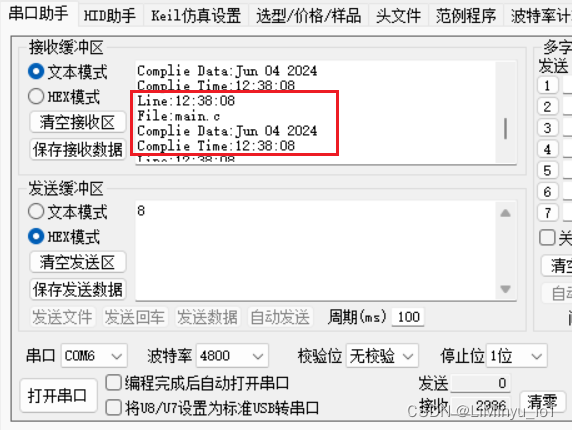
C51单片机 串口打印printf重定向
uart.c文件 #include "uart.h"void UartInit(void) //4800bps11.0592MHz {PCON | 0x80; //使能波特率倍速位SMODSCON 0x50; //8位数据,可变波特率。使能接收TMOD & 0x0F; //清除定时器1模式位TMOD | 0x20; //设定定时器1为8位自动重装方式TL1 0xF4; //设…...
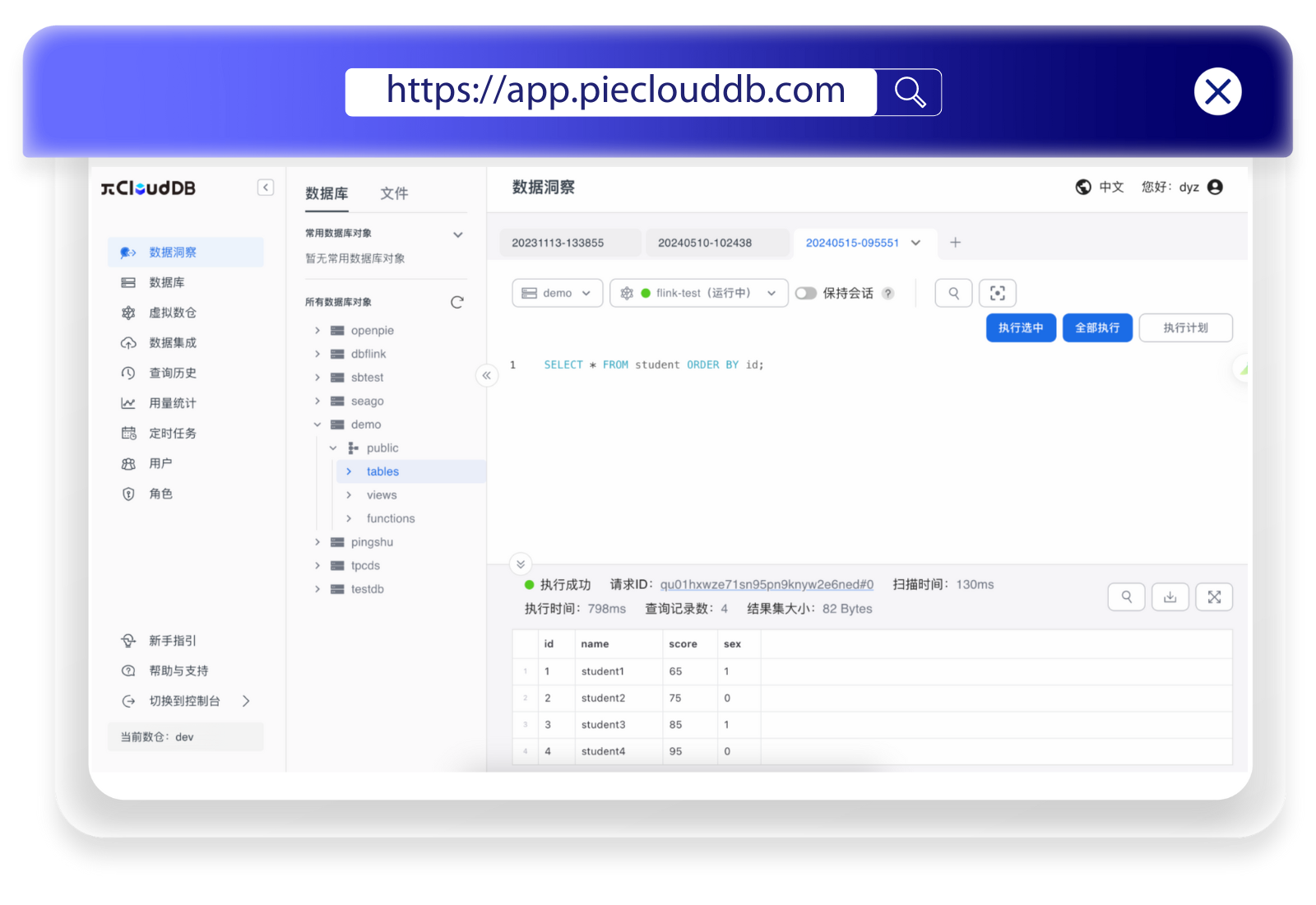
PieCloudDB Database Flink Connector:让数据流动起来
面对客户环境中长期运行的各种类型的传统数据库,如何优雅地设计数据迁移的方案,既能灵活地应对各种数据导入场景和多源异构数据库,又能满足客户对数据导入结果的准确性、一致性、实时性的要求,让客户平滑地迁移到 PieCloudDB 数据…...

主机CPU访问PCIe设备内存空间和PCIe设备访问主机内存空间
在x86体系架构中,主机CPU访问PCIe设备内存空间和PCIe设备访问主机内存空间的过程涉及多个层次的地址映射和转换。以下是详细的解释: 主机CPU访问PCIe设备内存空间 1. CPU生成虚拟地址(Virtual Address, VA): 在x86架构中&#…...

在家AIAA(美国航空航天学会)文献如何查找下载
今天有位同学的求助文献来自AIAA(美国航空航天学会),下面就讲一下不用求助他人自己就可搞定文献下载的途径并实例操作演示。 首先我们先对AIAA(美国航空航天学会)数据库做个简单的了解: 美国航空航天学会…...

dnf手游版游玩感悟
dnf手游于5月21号正式上线,作为一个dnf端游老玩家,并且偶尔上线ppk,自然下载了手游版,且玩了几天。 不得不说dnf手游的优化做到了极好的程度。 就玩法系统这块,因为dnf属于城镇地下城模式,相比…...
安卓如何书写注册和登录界面
一、如何跳转一个活动 左边的是本活动名称, 右边的是跳转界面活动名称 Intent intent new Intent(LoginActivity.this, RegisterActivity.class); startActivity(intent); finish(); 二、如果在不同的界面传递参数 //发送消息 SharedPreferences sharedPreferen…...

黄仁勋的AI时代:英伟达GPU革命的狂欢与挑战
在最近的COMPUTEX 2024大会上,英伟达创始人黄仁勋发布了最新的Blackwell GPU。这次发布不仅标志着英伟达在AI领域的又一次飞跃,也展示了其对未来技术发展的战略规划。本文将详细解析英伟达最新技术的亮点,探讨其在AI时代的市场地位和未来挑战…...

Linux云计算架构师涨薪班课程内容包含哪些?
第一阶段:Linux云计算运维初级工程师 目标 云计算工程师,Linux运维工程师都必须掌握Linux的基本功,这是一切的根本,必须全部掌握,非常重要,有了这些基础,学习上层业务和云计算等都非常快&#x…...
c语言:自定义类型(枚举、联合体)
前言: c语言中中自定义类型不仅有结构体,还有枚举、联合体等类型,上一期我们详细讲解了结构体的初始化,使用,传参和内存对齐等知识,这一期我们来介绍c语言中的其他自定义类型枚举和联合体的知识。 1.位段 …...

2024年适合GISer参加的全国性比赛
作为一名GISer,在校期间参加GIS比赛,不仅能够锻炼和提升自己的GIS专业水平,例如软件操作、开发能力等;还能加强自己团队协作能力、组织能力和沟通能力,此外,还可以给简历加分,增强职场竞争力。 …...
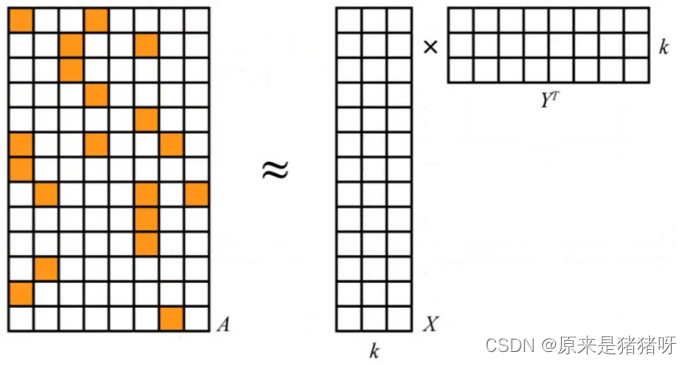
番外篇-用户购物偏好标签BP-推荐算法ALS
引言 推荐系统式信息过载所采用的措施,面对海量的数据信息,从中快速推荐出符合用户特点的物品。 推荐系统是自动化的通过分析用户对历史行为数据,完成用户的个性化建模,从而主动给用户推荐能够满足他们兴趣和需求的软件系统。 数…...

气膜体育馆的防火性能分析—轻空间
随着现代体育事业的蓬勃发展,气膜体育馆因其建设快捷、成本低廉、使用灵活等优势,逐渐在全球范围内受到广泛关注。然而,对于这种新型建筑形式,防火性能一直是人们关注的焦点之一。轻空间将详细探讨气膜体育馆的防火性能࿰…...

什么台灯对眼睛好?一文给你分享具体什么台灯对眼睛好!
什么台灯对眼睛好?随着学生们最近陆续返校,家长们和孩子们都忙于开学初的准备工作,而眼睛的健康自然也是他们考虑的一部分。这也是护眼台灯在近年来变得非常普及的原因之一。我自己一直是一个近视的人,而且日常用眼时间也相当长。…...

python-bert模型基础笔记0.1.00
python-bert模型基础笔记0.1.00 bert的适合的场景bert多语言和中文模型bert模型两大类官方建议模型模型中名字的含义标题bert系列模型包含的文件bert系列模型参数参考链接bert的适合的场景 裸跑都非常优秀,句子级别(例如,SST-2)、句子对级别(例如MultiNLI)、单词级别(例…...
STM32G030C8T6:EEPROM读写实验(I2C通信)--M24C64
本专栏记录STM32开发各个功能的详细过程,方便自己后续查看,当然也供正在入门STM32单片机的兄弟们参考; 本小节的目标是,系统主频64 MHZ,采用高速外部晶振,实现PB11,PB10 引脚模拟I2C 时序,对M24C08 的EEPRO…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

基于Flask实现的医疗保险欺诈识别监测模型
基于Flask实现的医疗保险欺诈识别监测模型 项目截图 项目简介 社会医疗保险是国家通过立法形式强制实施,由雇主和个人按一定比例缴纳保险费,建立社会医疗保险基金,支付雇员医疗费用的一种医疗保险制度, 它是促进社会文明和进步的…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

[ICLR 2022]How Much Can CLIP Benefit Vision-and-Language Tasks?
论文网址:pdf 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用 目录 1. 心得 2. 论文逐段精读 2.1. Abstract 2…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...
相比,优缺点是什么?适用于哪些场景?)
Redis的发布订阅模式与专业的 MQ(如 Kafka, RabbitMQ)相比,优缺点是什么?适用于哪些场景?
Redis 的发布订阅(Pub/Sub)模式与专业的 MQ(Message Queue)如 Kafka、RabbitMQ 进行比较,核心的权衡点在于:简单与速度 vs. 可靠与功能。 下面我们详细展开对比。 Redis Pub/Sub 的核心特点 它是一个发后…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...

C#中的CLR属性、依赖属性与附加属性
CLR属性的主要特征 封装性: 隐藏字段的实现细节 提供对字段的受控访问 访问控制: 可单独设置get/set访问器的可见性 可创建只读或只写属性 计算属性: 可以在getter中执行计算逻辑 不需要直接对应一个字段 验证逻辑: 可以…...

Webpack性能优化:构建速度与体积优化策略
一、构建速度优化 1、升级Webpack和Node.js 优化效果:Webpack 4比Webpack 3构建时间降低60%-98%。原因: V8引擎优化(for of替代forEach、Map/Set替代Object)。默认使用更快的md4哈希算法。AST直接从Loa…...