论文阅读:Adversarial Cross-Modal Retrieval对抗式跨模式检索
Adversarial Cross-Modal Retrieval 对抗式跨模式检索
跨模态检索研究的核心是学习一个共同的子空间,不同模态的数据可以直接相互比较。本文提出了一种新的对抗性跨模态检索(ACMR)方法,它在对抗性学习的基础上寻求有效的共同子空间。对抗性学习是作为两个过程的相互作用来实现的。第一个过程,一个特征映射器,试图在公共子空间中生成一个模态不变的表示,并混淆另一个过程,即模态分类器,它试图根据生成的表示来区分不同的模态。我们进一步对特征映射器施加三重约束,以使具有相同语义标签的不同模态项的表示之间的差距最小化,同时使语义不同的图像和文本之间的距离最大化。通过对上述情况的共同利用,当这些数据被投射到共同子空间时,多媒体数据的潜在跨模态语义结构得到了更好的保留。在四个广泛使用的基准数据集上的综合实验结果表明,所提出的ACMR方法在学习有效的子空间表示方面具有优势,并且它明显优于最先进的跨模态检索方法。
介绍
由于不同模态的特征通常具有不一致的分布和表征,因此需要弥合模态差距,也就是说,需要找到评估不同模态项目的语义相似性的方法。弥合模态差距的一个常见方法是表征学习。其目的是找到(即学习)来自不同模态的数据项映射到一个共同的(与模态无关的)特征表示子空间中,在这个子空间中可以直接评估它们之间的相似性。最近提出了各种跨模式检索方法,这些方法提出了学习共同表示子空间的不同方式。例如,早期的工作,如基于CCA的方法和基于图的方法,通过最大限度地提高跨模态成对项的相关性或项目分类的准确性来学习线性映射以生成共同表示。
随着深度神经网络(DNN)模型的快速发展,它为单模态场景(如图像分类)中的有效特征表示提供了可扩展的非线性转换,DNN也越来越多地被部署到跨模态检索中,然后特别是在学习共同子空间时利用非线性相关性。现有的基于DNN的跨媒体检索模型通常只关注于保存耦合的跨模式项(例如,一个图像和一段文本)的成对相似性,这些项目共享语义标签,并作为模型学习过程中的输入。然而,对于一个模态的项目来说,可能存在不止一个同一模态的语义不同的项目,因此,只关注成对的耦合项是远远不够的。因此,以这种方式学习的共同表征不能完全保留数据中潜在的跨模态语义结构。保护这种结构需要将所有具有相同语义标签的不同模态项目的表征之间的差距最小化(例如,将同一主题的任何文本和任何图像联系在一起),而将同一模态的语义不同的项目之间的距离最大化(例如,如果两个图像或两个文本不相关,则将它们分开)。
本文提出对抗性跨模型检索(ACMR)框架来解决现有的基于DNN的跨媒体检索方法的这个缺点,它是围绕对抗性学习的概念建立的。如图1所示,该框架的核心是两个过程之间的相互作用,一个是特征映射器,一个是模态分类器,以极小化极大博弈的方式进行。特征映射器执行表征学习的主要任务,即为共同子空间中不同模态的项目生成一个模态不变的表征。它的目的是迷惑作为对手的模态分类器。模态分类器试图根据项目的模态来区分它们,并以这种方式引导特征映射器的学习。通过让模态分类器扮演对手的角色,预计可以更有效地达到模态不变性,同时也可以更有效地达到跨模态的项目表征分布的一致性。表征子空间对于跨模态检索来说是最优的,然后通过这个过程的收敛,即当模态分类器失效时,就会产生。此外,特征映射器的学习使其共同执行标签预测并保留数据中潜在的跨模态语义结构。通过这种方式,它可以确保所学到的表征在一个模态内是有辨别力的,在不同模态间是不变的。后者是通过对模态间项关系施加更多的约束来实现的,而之前提出的方法只关注成对项相关性。

图1:ACMR的一般流程图。它是围绕着涉及两个过程(算法模块)的极小化极大博弈而建立的,作为 “博弈者”:一个是模态分类器,根据项目的模态来区分它们,另一个是特征映射器,产生模态不变的和有区别的表示,目的是混淆模态分类器。
提出的ACMR方法在四个(三个小规模和一个相对大规模)基准数据集上进行了评估,并使用许多现有方法作为参考。实验结果表明,它在跨模式检索方面明显优于最先进的方法。
相关工作
本文的主要贡献在于跨模式检索框架的表征学习部分。表征学习有不同的方式,取决于用于学习的信息类型、目标表征的类型和正在部署的学习方法。表征学习方法有两大类,实值和二进制表征学习。二进制方法,也被称为跨模态哈希,更多的是针对检索效率,目的是将不同模态的项目映射到一个共同的二进制汉明空间。由于它的重点在于效率,通常需要对检索的准确性(有效性)做出让步。
本文提出的方法属于实值方法的范畴。在这个类别中,可以区分几个子类的方法:无监督的,配对的,基于排名的和有监督的。通过ACMR,我们首次将跨模态检索的监督表征学习和对抗性学习的概念结合起来。我们的方法一方面是由于我们在大多数(非)监督方法中看到的缺陷,特别是关于他们部署的学习过程(专注于单个样本对)和学习目标(通常是相关损失的变体)的有效性。另一方面,我们的方法受到了一些基于排名的方法的启发,特别是关于部署三重排名损失作为学习目标,这对实现表征学习的主要目标有效,即模内区别性和模间不变性。此外,我们的方法受到了对抗性学习在各种应用中的有效性的启发,比如学习判别图像特征,或者(非)监督性的领域适应性来执行领域不变的特征,以及跨模态项间的正则化相关损失。
所采用的方法
问题的提出
在不丧失一般性的前提下,我们将重点放在双模态数据的跨模态表征学习上,特别是图像和文本。
由于图像特征V和文本特征T通常具有不同的统计属性,并且遵循未知的(复杂的)分布,因此它们不能在跨模式检索中直接相互比较。为了使图像和文本直接可比,我们的目标是找到一个共同的子空间。本文提出的ACMR方法的特点是,我们旨在学习不同模式下更有效的转换特征。正如前面所论证的,我们要求图像和文本的变换特征分布是模态不变和语义区分的,同时也要更好地保留数据中潜在的跨模态相似性结构。
对抗性跨模式检索
ACMR方法的总体框架如图1所示。为简单起见,我们假设已经分别从图像和文本中提取了特征V和T。图像和文本特征首先通过各自的变换,这些变换在概念上受到现有的子空间学习方法的启发,在我们的案例中被实现为前馈网络。考虑到图像和文本模态之间的统计属性的较大差距,全连接层有丰富的参数,以确保有足够的表示能力。然后,在第二步中,我们引入了两个过程–特征映射器和模态分类器–之间的极小化极大博弈来引导表征学习。我们对这些过程及其互动进行建模,以有效地满足上述要求。
模态分类器
我们首先定义了一个具有参数θD的模态分类器D,它在GAN中充当鉴别者。来自图像的映射特征被分配为标签01,而来自文本的映射特征被分配为标签10。对于模态分类器来说,目标是在给定未知特征映射的情况下,尽可能可靠地检测物品的模态。对于分类器的实现,我们使用了一个参数为θD的3层前馈神经网络。
在ACDM方法中,模式分类器作为一个对手。因此,我们把这个过程试图最小化的分类损失称为对抗性损失。对抗性损失Ladv现在可以正式定义为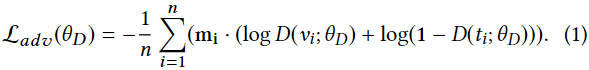
本质上,Ladv表示训练中每次迭代s使用的所有实例oi,i = 1, …, n的模态分类的交叉熵损失。此外,mi是每个实例的真实模态标签,表示为独热向量,而D(. ; θD )是实例oi的每项(图像或文本)生成的模态概率。
特征映射器
像大多数现有的工作一样,相关性损失的目标仅仅是在新的表示子空间中保留各个语义耦合的跨模态项目对的相关性。正如本文前面所讨论的,这并不充分,因为语义匹配可能涉及两个以上的项目。此外,相关性损失也不能区分同一模态的不同语义的项目。这就导致了特征表示没有足够的鉴别力,并将限制跨模态检索的性能。
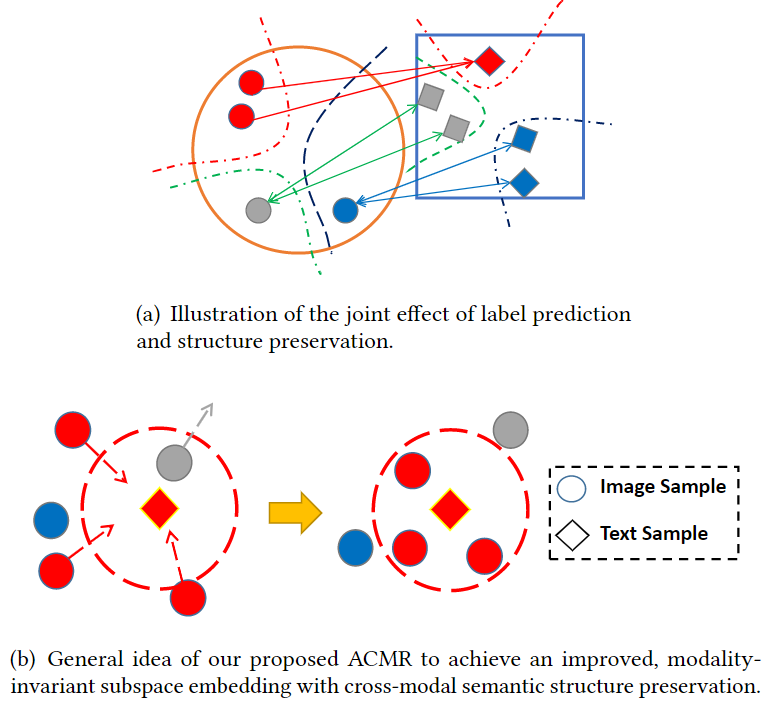
图2:ACMR方法的基本思想说明。图像文本分别用方块和圆圈表示。 语义相关的跨模态项目用相同的颜色表示。(a)标签预测和结构保存的联合效果说明。(b)ACMR的总体思路,以实现改进的、模态不变的子空间嵌入和跨模态语义结构保存。
鉴于上述情况,我们建议对特征映射器进行建模,它体现了将文本和图像嵌入到一个共同的子空间的模态不变的过程,是两个步骤的组合:标签预测和结构保存。标签预测过程使共同子空间中每个模态的映射特征表示在给定的语义标签下具有鉴别性(同一模态语义不同特征不同)。结构保存过程确保属于同一语义标签的特征表征在不同模态下是不变的(不同模态语义相同特征相同)。这两个过程的共同作用在图2(a)中得到了说明。 在这里,每个圆圈代表一个图像,每个矩形代表一个文本项目。此外,相同颜色的圆圈和矩形属于同一语义类别。图2(b)说明了导致这种效果的过程。在本节的其余部分,我们将详细描述标签预测和结构保存模块,它们是子空间嵌入过程的基础。
标签预测
为了确保数据的模内识别在特征映射后得以保留,我们部署了一个分类器来预测在共同子空间中映射的项目的语义标签。为此,在每个子空间嵌入的神经网络之上添加了一个由softmax激活的前馈网络。这个分类器将耦合图像和文本的映射特征作为训练数据,并将每个项目的语义类别的概率分布作为输出。我们使用这些概率分布来制定跨模态辨别损失,具体如下。
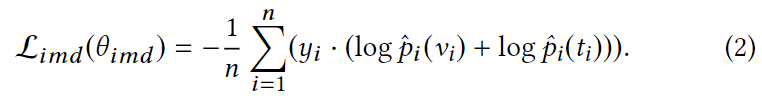
与公式1中的模态间对抗损失类似,Limd表示所有实例oi,i=1,…,n的语义类别分类的交叉熵损失。这里,θimd表示分类器的参数,n是每个小批次中的实例数量,yi是每个实例的基础事实,而ˆpi是实例oi的每项(图像或文本)生成的概率分布。
结构保存
为了保证模态间的不变性,我们的目标是最小化来自不同模态的所有语义相似项的表征之间的差距,同时最大化同一模态的语义不同项目之间的距离。受基于排序的跨媒体检索方法的启发,我们通过一个三联体损失项对嵌入过程进行了强制约束。
我们没有采用在整个实例空间中对三联体进行采样的昂贵方案,而是在每个小批次中从已标记的实例中进行三联体采样。首先,从图像和文本样本的角度来看,所有来自不同模态但具有相同标签的样本被建立为耦合样本。换句话说,我们建立了{(vi, t+ i )}i形式的耦合,其中图像被选为锚,而具有相同标签的文本被指定为正向匹配,还有{(ti, v+ i )}i形式的耦合,其中文本项目为锚,图像为正向匹配。
其次,每个耦合项对的映射表示fV(V;θV)和fT(T;θT)之间的所有距离都被计算出来,并使用ℓ2准则进行排序。
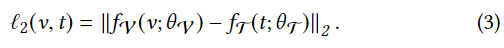
然后,我们还从具有不同语义标签的不匹配的图像-文本对中选择负面样本,以构建每个语义标签li的三联体样本集:{(vi, t+ i , t- j )}i和{(ti, v+ i , v- j )}i。通过这种取样方式,我们可以确保非空的三联体样本集的构建与原始数据集中的样本如何被组织成小批无关。最后,我们使用以下表达式计算跨图像和文本模式的模态不变性损失,这些表达式分别将样本集{(vi, t+ j , t- k )}i和{(ti, v+ j , v- k )}i作为输入。
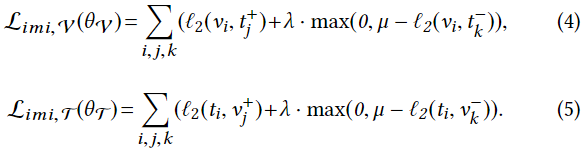
那么整体的模间不变性损失现在可以被建模为Limi, V (θV , θ T)和Limi, T~(θV , θ T)的组合。
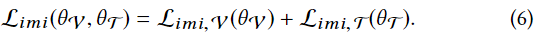
此外,下面的正则化项是为了防止学习到的参数过拟合,其中F表示弗罗贝尼乌斯范数,W l v, W l t代表DNN的层级参数。
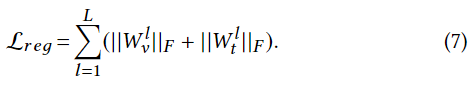
特征映射器
在此基础上,特征映射器的损失函数被称为嵌入损失,它是由模内辨别损失和模间不变性损失与正则化的组合。
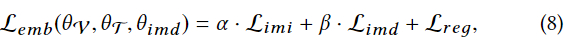
其中超参数α和β控制着两个项的贡献。
对抗性学习:优化
学习最佳特征表征的过程是通过联合最小化对抗性损失和嵌入损失来进行的,分别由公式1和公式8得到。由于这两个目标函数的优化目标是相反的,该过程作为两个并发的子过程的极小化极大博弈运行。
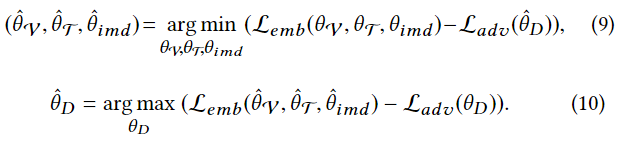
这种极小化极大博弈可以使用随机梯度下降优化算法来实现,如Adam。通过加入梯度反转层(GRL)可以有效地进行极小化极大优化,GRL在前向传播时是透明的,但在反向传播时它的值会乘以-1。如果在模态分类器的第一层之前加入梯度反转层,就可以同时进行极小化极大优化,如算法1所示。

算法1:优化ACMR的伪代码
实验
我们在四个广泛使用的跨模态数据集上进行了实验。维基百科数据集,NUS-WIDE-10k数据集,帕斯卡尔句子数据集,以及MSCOCO数据集。对于前三个数据集,每个图像-文本对由一个单一的类标签连接,文本模态由离散的标签组成。在最后一个数据集MSCOCO中,每个图像-文本对都与多个类标签相关,文本模态由句子组成。在下面的实验首先将我们提出的ACMR方法与最先进的方法进行比较,以验证其有效性。然后,我们进行了额外的评估,以更详细地研究ACMR的性能。
实验设置
数据集和特征
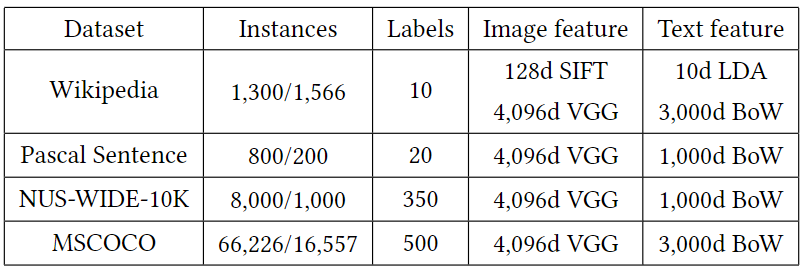
表1:在我们的实验中使用的四个数据集的一般统计数据,其中Instances一栏中的*/*代表了训练/测试图像-文本对的数量
由于从CNN中提取的图像特征已被广泛用于图像表示,我们也采用这种深度特征来表示我们实验中所有数据集的图像。具体来说,采用的深度特征是由VGGNet的fc7层提取的4,096d向量。为了表示文本实例,使用词包(BoW)向量,采用TF-IDF加权方案,每个数据集的维度如表1所示。此外,为了能够与早期在维基百科数据集上评估的几种跨模式检索方法进行公平的比较,我们还采用了公开的128d SIFT特征用于图像,10d LDA特征用于文本表示。
实施细节
我们部署了由tanh函数激活的三层前馈神经网络,将原始图像和文本特征非线性地映射到一个共同的子空间,即(V→2000→200,图像模态和T→500→200文本模态)。对于模态分类器,我们坚持使用三个全连接层(f→50→2)。此外,在语义分类器和模态分类器的最后一层之后加入了Softmax激活。
关于算法1的参数,batch size被设置为64,k被经验性地设置为5。在将λ的值固定为0.05后,我们使用网格搜索来调整模型参数α和β(在这两种情况下,从0.01到100,每步10次)。α和β的分析显示在图6(a)中。对于每个数据集的α和β的最佳值,得到了ACMR的最佳报告结果。此外,为了与最先进的方法进行公平的比较,我们不仅参考了相应论文中发表的结果,而且还用提供的实现代码对其中的一些方法进行了重新评估,以实现全面的评估。
评价指标
对所有实验结果的评价都是以平均精度(mAP)为标准,这是跨模式检索研究中一个经典的性能评价标准。具体来说计算了两个不同任务的检索结果的排序列表的平均精度:使用图像查询检索文本样本(Img2Txt)和使用文本查询检索图像(Txt2Img)。此外,我们还展示了提出的ACMR方法和所有参考方法的精度-范围曲线,其中范围由呈现给用户的排名靠前的文本/图像的数量指定,从1到1000不等。
与现有方法的比较
我们首先在维基百科数据集上将我们的ACMR方法与9种最先进的方法进行比较,维基百科在文献中被广泛采用为基准数据集。所比较的方法有1)CCA、CCA-3V、LCFS、JRL和JFSSL,它们是传统的跨模式检索方法;2)Multimodal-DBN、Bimodal-AE、Corr-AE和CMDN,它们是基于DNN。
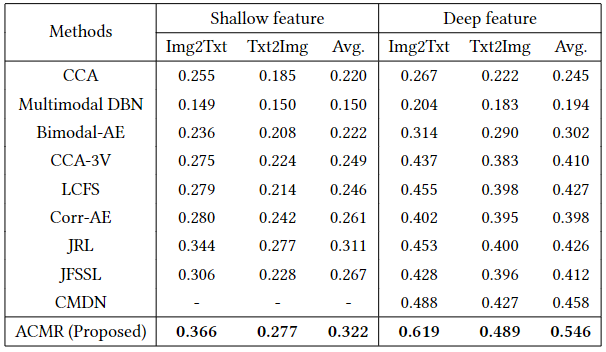
表2:维基百科数据集上的跨模态检索性能比较。这里,"-"表示没有相同设置的实验结果。
表2显示了我们的ACMR和使用浅层和深层特征的维基百科数据集上的比较方法的mAP。从表2中,我们可以得出以下结论:
(1)我们的ACMR明显优于传统和基于DNN的跨模式检索方法。特别是,ACMR在使用浅层和深层特征时,比最好的竞争者CMDN平均高出20.6%和19.2%。虽然CMDN也在一个多任务学习框架中对模间不变性和模内辨别力进行了联合建模,但这一性能改进清楚地表明了对抗性学习的优势。
(2)我们的ACMR优于CCA、Bimodal-AE、Corr-AE、CMDL和CMDN,它们使用基于耦合样本的相关损失来模拟模态间的项目相似度。这表明在学习表征子空间时,使用所提出的三重约束来利用相似和不相似的项目对的线索的优势。
(3) 我们的ACMR优于LCFS、CDLFM、LGCFL、JRL、JFSSL,它们也是利用类标签信息来模拟模内区分损失。我们认为,这是因为ACMR使用的是嵌入损失,它共同模拟了模态间的不变性和模态内的辨别力。
Pascal Sentences数据集和NUSWIDE-10k数据集的检索结果见表3。我们可以看到,与同类产品相比,ACMR始终取得了最好的性能。对于NUSWIDE-10k数据集,我们的ACMR在图像和文本查询检索任务中的表现分别优于同行10.6%和4.47%,平均为7.34%。结果还表明,在多标签情况下(NUS-WIDE-10k数据集)使用三重约束的好处,因为之前在那里测试的方法只采用了配对相似性来保留模式间的相似性。我们的方法对Pascal Sentences数据集的改进是有限的,因为该数据集是小规模的(只有来自20个类别的800个图片-文本对)。尽管我们利用了一些策略来缓解过拟合问题(如正则化项、dropout和提前停止),但仍不足以训练出一个表现优异的深度模型。
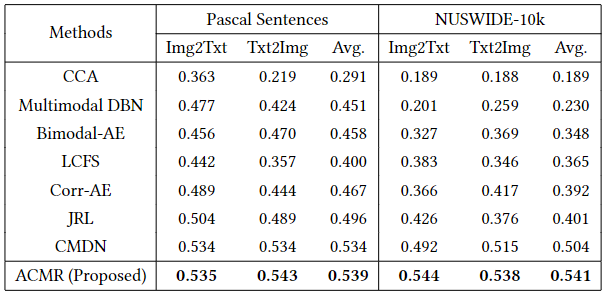
表3:在Pascal句子和NUSWIDE-10k数据集上的mAP方面的跨模态检索比较
除了在mAP得分方面的评估,我们还画出了精度-范围曲线来进行额外的比较。图3显示了ACMR以及CCA、LCFS、JRL、MultimodalDBN、Bimodal-AE、Corr-AE和CMDN使用浅层图像特征的曲线。精度范围的评估与图像和文本查询任务的mAP分数一致,我们的ACMR明显优于其对应的任务。
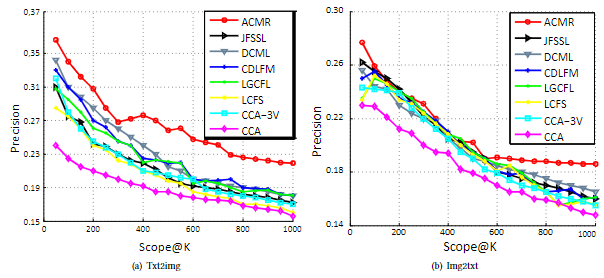
图3:Img2Txt和Txt2Img实验在Wiki数据集上的精度-范围曲线,K范围从50到1000
MSCOCO数据集最近被用于图像-句子(Img2Txt)和句子-图像(Txt2Img)检索。我们用它来比较我们的ACMR方法和最近为上述两个任务提出的几个方法,包括传统的方法CCA和基于DNN的方法,如DVSA、m-RNN、m-CNN和DSPE。ACMR和参考方法的检索结果列于表4。值得注意的是,表现最好的参考方法DSPE也使用了三联体约束来保留共同子空间中的模态间数据结构。这进一步加强了我们的信念,即选择三联体替换成对相关损失的约束是正确的。有理由指出,与DSPE相比,ACMR的性能提高又是由于部署的对抗性学习框架,它促进了更有效的子空间表示的学习,但也是由于整合了模态间不变性和模态内识别的三重约束。
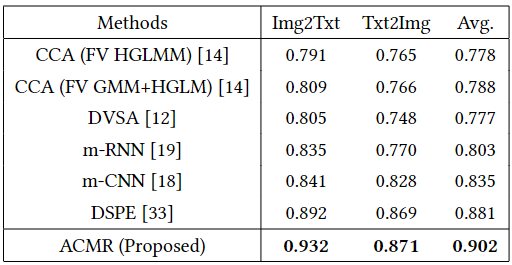
表4:在MSCOCO数据集上的mAP方面的跨模态检索比较
对ACMR的进一步分析
学习对抗性表征的可视化
为了研究我们ACMR的跨模态表征的有效性,我们使用t-SNE工具(每种模态有1000个样本点)可视化了我们在维基百科数据集上的训练模型的转换表示的分布。图4(a)和图4(b)的比较显示,对抗性学习有能力最小化模态差距,并使不同模态的分布一致,即图4(b)中文本和图像模态的分布更好地混合在一起,相互之间的区别较小。此外,我们对模态内判别性建模的努力也显示出进一步提升了性能。如图4(b)和图4( c)所示,所提出的模型不仅保证了来自两种模态的分布的一致性,而且还有效地将样本点分离成几个语义上有区别的聚类,使每个聚类中来自不同模态的样本保持良好的一致性。
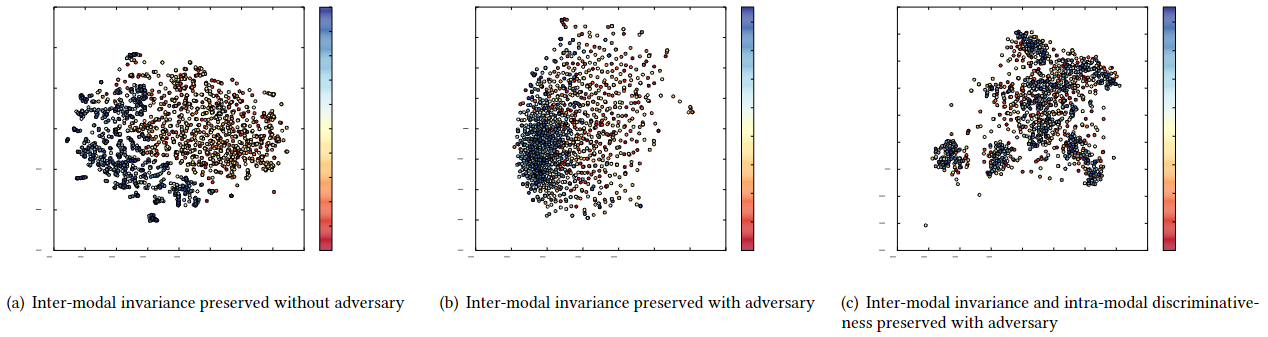
图4:维基百科数据集中测试数据的t-SNE可视化。红色代表视觉特征,蓝色代表文本特征
对抗性学习的作用
在我们的ACMR方法中,当联合优化目标函数中的嵌入损失和对抗性损失时,我们部署了对抗性原则。为了进一步探索ACMR中对抗性学习的效果,我们对嵌入损失和对抗性损失的值从epoch1到200取样,并显示在图5中。图中显示,在整个训练过程中,嵌入损失几乎是单调地减少并平稳地收敛,而对抗性损失先是振动(在最初的10个epoch中),然后稳定下来。值得注意的是,当对抗性损失发生振动时,mAP得分持续增加,当对抗性的效果被完全利用时,mAP得分保持不变。图5中的结果符合预期,即我们的ACMR框架中的模态分类器作为子空间嵌入过程的方向性指导,被纳入特征映射器中。如果对抗性损失的值会爆炸,模态分类器将无法指导子空间嵌入的过程。与此相反,如果对抗性损失被优化为零,模态分类器将赢得极小化极大博弈,这将意味着嵌入层无法生成模态不变的子空间表征,使得跨模态检索无法进行。
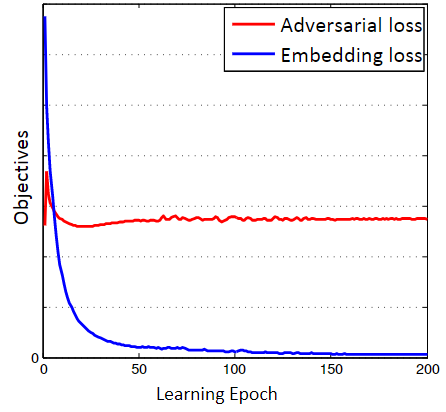
图5:训练过程中嵌入损失和对抗性损失的曲线,在维基百科数据集上为ACMR计算
结合标签预测和结构保存的效果
我们的ACMR框架的特征映射模块是由标签预测和结构保存两个过程组合而成的。为了更详细地研究这种组合的效果,我们开发并评估了ACMR的两种变体:仅有Limi的ACMR和仅有Limd的ACMR。这两种情况下的优化步骤都与ACMR类似。表5显示了ACMR及其在维基百科数据集和Pascal Sentence数据集上的两种变体的性能。我们看到,模内判别性和模间不变性都对最终的检索率有贡献,这表明在我们的嵌入损失模型中同时优化Limi和Limd比只优化其中一个条款的效果更好。我们还看到,模内判别力项对整体性能的贡献要大于模间不变性项,因为在实践中,不同模态之间的一致关系很难被发掘。
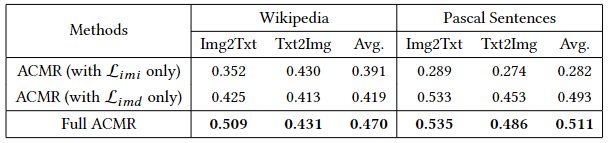
表5:使用ACMR方法、仅有Limi的ACMR方法和仅有Limd的ACMR方法进行跨模态检索的性能
模型参数的影响
在之前的实验中,我们根据经验在特征映射器的目标函数(即公式8)中设置了模型参数α和β。由于α和β分别控制了模内判别力和模间不变性的建模贡献,这里我们把带有深度特征的维基百科数据集作为测试平台,并分析了这些参数在训练期间对学习到的跨模态表征的影响。此外,我们还评估了影响算法中描述的极小化极大博弈的参数k。1. 特别是,我们将α、β的范围设定为{0.01, 0.1, 0, 1, 10, 100},k的范围设定为{1, 2, 3, 4, 5, 6}。
α=0和β=0分别代表仅有Limi的ACMR和仅有Limd的ACMR。评估是通过改变一个参数(如α)而固定另一个参数(如β)进行的。图6(a)显示了不同的α和β值下ACMR的性能。我们可以看到,当α和β在[0.01, 0.1]的范围内时,ACMR表现良好。此外,只用Limi的ACMR和只用Limd的ACMR得到的mAP分数表明,与Limi相比,Limd对整体性能的贡献更大,这与之前的观察结果一致,如表5所示。图6(b)显示了不同k值下ACMR的性能。该图表明,在实践中,专门努力寻找一个合适的k值(例如,k=4或5)有助于整个优化过程。
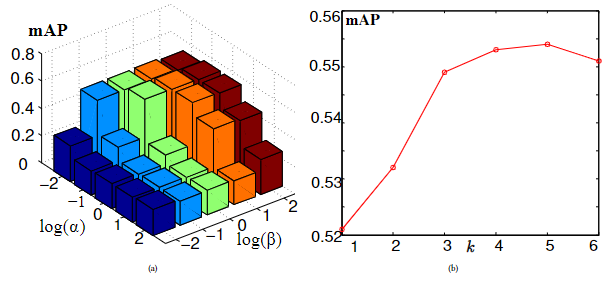
图6:使用不同的模型参数值:(a)α和β;(b)维基百科数据集的k,ACMR的跨模态检索性能
结论
本文提出了一种新的方法(ACMR)来学习跨模态检索中既具有判别力又具有模态不变性的表征。ACMR基于一种对抗性的学习方法,在一个极小化极大博弈中涉及两个过程:一个是产生模态不变和判别性表征的特征预测器,另一个是试图检测一个项目的模态的模态分类器,给定一个未知的特征表示。我们还引入了三联体约束,以确保跨模态语义数据结构在映射到共同子空间时得到良好的保留。在四个跨模态数据集上的综合实验结果和广泛的分析表明,我们的算法和方法设计选择是有效的,与最先进的方法相比,跨模式检索性能更优。
相关文章:
论文阅读:Adversarial Cross-Modal Retrieval对抗式跨模式检索
Adversarial Cross-Modal Retrieval 对抗式跨模式检索 跨模态检索研究的核心是学习一个共同的子空间,不同模态的数据可以直接相互比较。本文提出了一种新的对抗性跨模态检索(ACMR)方法,它在对抗性学习的基础上寻求有效的共同子空间…...

计算机网络复习
什么是DHCP和DNS DNS(Domain Name System,域名系统),因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网,而不用去记住能够被机器直接读取的IP数串。通过主机名,最终得到该主机名对应的…...
unity动画--动画绑定,转换,用脚本触发
文章目录如何制作和添加动画大概过程示例图将多组图片转化为动画放在对象身上实现动画之间的切换使用脚本触发Parameters(Trigger)如何制作和添加动画 大概过程示例图 将多组图片转化为动画放在对象身上 首先,我们要为我们要对象添加animator 然后我们要设置对应的…...

车载汽车充气泵PCBA方案
汽车为什么会需要充气泵呢?其实是由于乘用车中没有供气源,所以就必需充气泵来给避震器供气。充气泵是为了保障汽车车胎对汽车的行驶安全所配备的,防止遇上紧急问题时没有解决方案,同时也可以检测轮胎胎压。现阶段的充气泵方案&…...

Android 连接 MySQL 数据库教程
在 Android 应用程序中连接 MySQL 数据库可以帮助开发人员实现更丰富的数据管理功能。本教程将介绍如何在 Android 应用程序中使用低版本的 MySQL Connector/J 驱动程序来连接 MySQL 数据库。 步骤一:下载 MySQL Connector/J 驱动程序 首先,我们需要下…...
tmall.item.update.schema.get( 天猫编辑商品规则获取 )
¥开放平台免费API必须用户授权 Schema方式编辑天猫商品时,编辑商品规则获取 公共参数 请求地址: HTTP地址 http://gw.api.taobao.com/router/rest 公共请求参数: 公共响应参数: 点击获取key和secret 请求示例 TaobaoClient client new DefaultTaobao…...

Leetcode 2379. 得到 K 个黑块的最少涂色次数
目录 一、题目内容和对应链接 1.题目对应链接 2.题目内容 二、我的想法 三、其他人的题解 一、题目内容和对应链接 1.题目对应链接 Leetcode 2379. 得到 K 个黑块的最少涂色次数 2.题目内容 给你一个长度为 n 下标从 0 开始的字符串 blocks ,blocks[i] 要…...

[深入理解SSD系列 闪存实战2.1.3] 固态硬盘闪存的物理学原理_NAND Flash 的读、写、擦工作原理
2.1.3.1 Flash 的物理学原理与发明历程 经典物理学认为 物体越过势垒,有一阈值能量;粒子能量小于此能量则不能越过,大于此能 量则可以越过。例如骑自行车过小坡,先用力骑,如果坡很低,不蹬自行车也能 靠惯性过去。如果坡很高,不蹬自行车,车到一半就停住,然后退回去。 …...
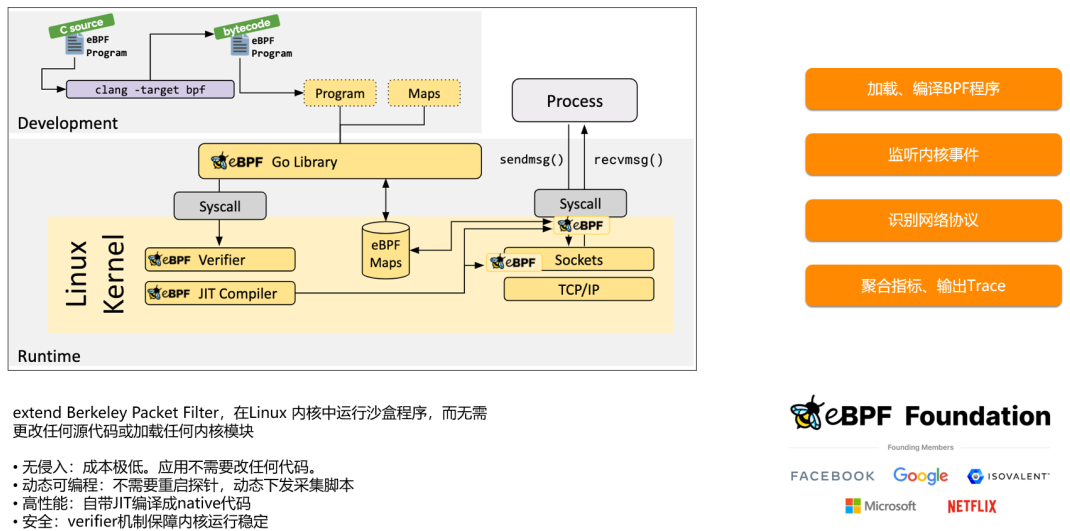
总结:Linux内核相关
一、介绍看eBPF和Cilium相关内容时,碰到Cilium是运行在第 3/4 层,不明白怎么做到的,思考原理的时候就想到了内容,本文记录下内核相关知识。https://www.oschina.net/p/cilium?hmsraladdin1e1二、Linux内核主要由哪几个部分组成Li…...
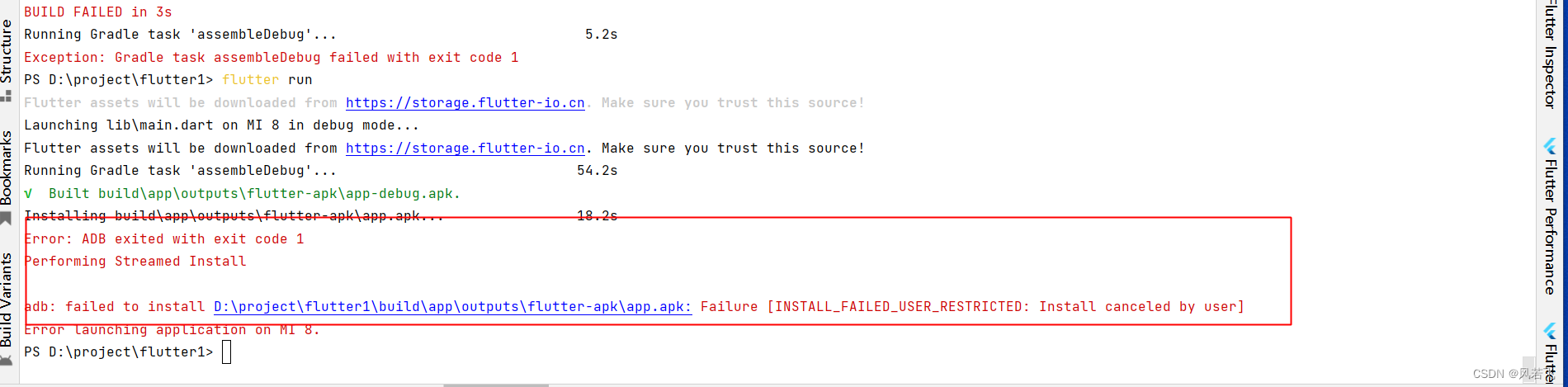
flutter工程创建过程中遇到一些问题。
安装环境版本:JDK7.-JDK 8 Andriod SDK 10 flutter 版本 3.0 1.当创建完后flutter工程后会遇到 run gradle task assemlble Debug 的问题,需要设置远程仓库,共需要修改三个地方build.gradle两处以及flutter 下面的D:\FVM\versions\3.0.0\pac…...
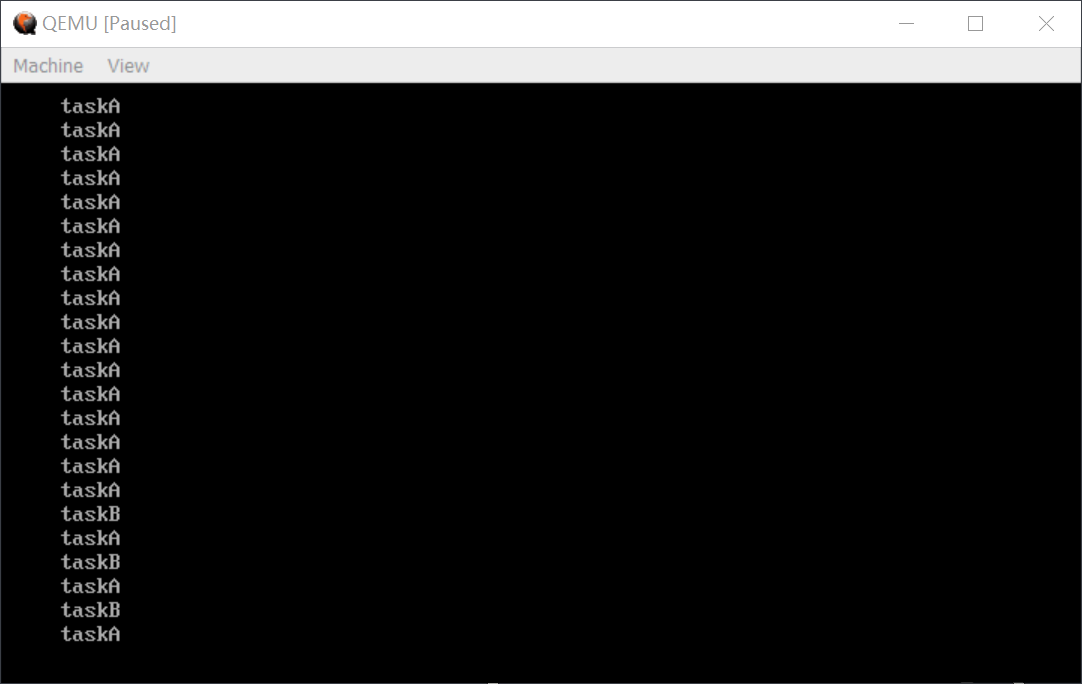
记录实现操作系统互斥锁的一次思考
今天实现操作系统互斥锁的时候遇到一个有趣的问题。 场景 有两个进程分别名为 taskA,taskB,采取时间片轮转的方式交替运行——也即维护了一个 ready_queue,根据时钟中断来 FIFO 地调度任务。它们的任务是无限循环调用 sys_print() 来打印自…...

计算机SCI期刊的分值是什么意思? - 易智编译EaseEditing
影响因子(Impact Factor,IF)是美国ISI(科学信息研究所)的JCR(期刊引证报告)中的一项数据。 即某期刊前两年发表的论文在统计当年的被引用总次数除以该期刊在前两年内发表的论文总数。这是一个国际上通行的期刊评价指标。 例如,某期刊2005年影…...
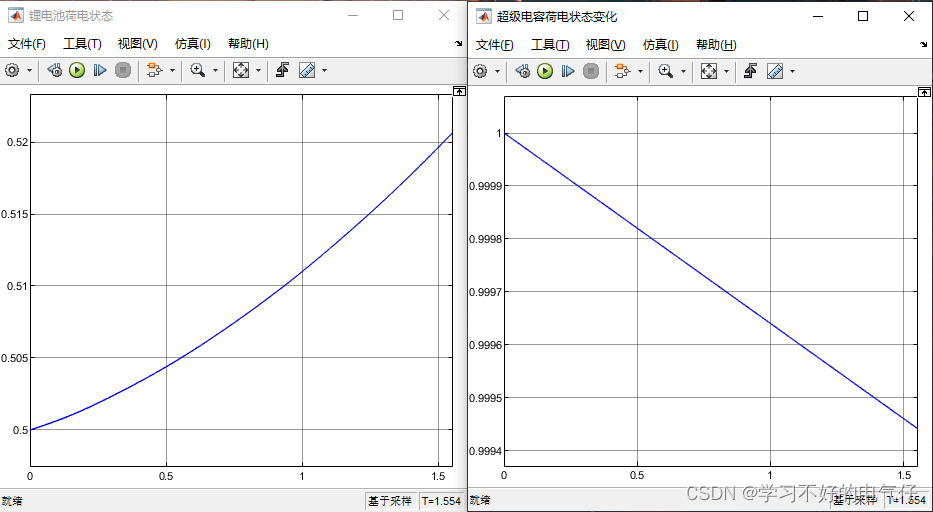
5MW风电永磁直驱发电机-1200V直流并网MATLAB仿真模型
MATLAB2016b运行。主体模型:风机传动模块、PMSG模块、蓄电池模块、超级电容模块、无穷大电源。蓄电池控制、风机控制、逆变器控制。风机输出功率:直流母线电压:逆变器输出电压:逆变器输出电流:混合储能荷电状态&#x…...

10 个常见的 JavaScript 面试问题以及如何回答它们
你在准备 JavaScript 面试吗?别再看了!本文将介绍10 个常见的 JavaScript 面试问题以及如何在代码示例和解释的帮助下回答这些问题。1. JavaScript 中的提升是什么?提升是 JavaScript 中的一种行为,其中变量和函数声明被移动到其作…...

字节跳动-今日头条后端开发一面面经
飞书50min 1、实习经历? 2、参加竞赛经历? 3、TCP和UDP的区别? 4、cookie和session的区别? 5、session如何做分布式? 6、概率题目,A和B轮流抛硬币,谁先抛到正面就获胜,A先抛硬币&…...

再见 ETHDenver 2023
我们来一起回顾Web3中规模最大,持续时间最长的以太坊史诗级建造周我们正在庆祝#YearoftheSpork,并借助 Web3 中最大的以太坊社区活动之一拉开了黑客马拉松赛季的序幕。ETH Denver 旨在围绕一个共同的目标聚集了志同道合的人,我们非常高兴今年…...

阿里云dataworks表操作
–odps sql –– –author:宋文理 –create time: –– 创建表 创建非分区表、分区表、外部表或聚簇表。 限制条件 分区表的分区层级不能超过6级。例如某张表以日期为分区列,分区层级为年/月/周/日/时/分。 一张表允许的分区个数支持按照具体的项目配置,…...

【latex】总结最近使用到的画图、表格及公式操作
前言 推荐使用overleaf写latex文章,内含很多会议/期刊的模板,可以直接套用。 https://www.overleaf.com下文都是在写论文过程中比较头疼的部分,有人建议我写完文章,最后再调整格式。但图片过大看起来实在是不适~ 插入图片 \beg…...

excel表格数字乱码怎么恢复正常
excel表格数字乱码怎么恢复正常?作为可以进行数据存储、提取、计算的excel表格,经常会遇到excel表格数字乱码这一情况。这可能是由于输入的数字位数较多,数字出现乱码。出现这种情况将会大大影响我们的工作。那么我们该怎么办?这里小编将为您带来excel…...

泰山众筹电商模式的分析
泰山众筹模式是电商平台营销玩法,市场上高活跃度的现象也证实了众筹模式的口碑,结合社交电商的模型,会员和产品销量都会得到飞跃,并且这样结合以后,泰山众筹模式也会更长久、合理,以及可持续。 泰山众筹模…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

AI,如何重构理解、匹配与决策?
AI 时代,我们如何理解消费? 作者|王彬 封面|Unplash 人们通过信息理解世界。 曾几何时,PC 与移动互联网重塑了人们的购物路径:信息变得唾手可得,商品决策变得高度依赖内容。 但 AI 时代的来…...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...

【网络安全】开源系统getshell漏洞挖掘
审计过程: 在入口文件admin/index.php中: 用户可以通过m,c,a等参数控制加载的文件和方法,在app/system/entrance.php中存在重点代码: 当M_TYPE system并且M_MODULE include时,会设置常量PATH_OWN_FILE为PATH_APP.M_T…...

MySQL 索引底层结构揭秘:B-Tree 与 B+Tree 的区别与应用
文章目录 一、背景知识:什么是 B-Tree 和 BTree? B-Tree(平衡多路查找树) BTree(B-Tree 的变种) 二、结构对比:一张图看懂 三、为什么 MySQL InnoDB 选择 BTree? 1. 范围查询更快 2…...
零知开源——STM32F103RBT6驱动 ICM20948 九轴传感器及 vofa + 上位机可视化教程
STM32F1 本教程使用零知标准板(STM32F103RBT6)通过I2C驱动ICM20948九轴传感器,实现姿态解算,并通过串口将数据实时发送至VOFA上位机进行3D可视化。代码基于开源库修改优化,适合嵌入式及物联网开发者。在基础驱动上新增…...