HBase数据库面试知识点:第一部分 - 基础概念与特点(持续更新中)
目录
一、HBase基础概念
1. HBase定义
2. 核心组件
3. HBase的特点
二、HBase与传统RDBMS的区别
1. 数据类型
2. 数据操作
3. 存储方式
4. 伸缩性
5. 事务性
三、HBase数据模型
四、HBase的特点
五、HBase与Hadoop生态系统的关系
一、HBase基础概念
1. HBase定义
HBase是一个开源的、分布式的、面向列的NoSQL数据库,它是Apache Hadoop生态系统中的一部分。HBase基于Hadoop的分布式文件系统(HDFS)来存储数据,并提供了高可靠性、高性能、可伸缩性和面向列的数据存储能力。HBase的设计初衷是为了解决传统关系型数据库(RDBMS)在处理大规模数据集时的性能瓶颈和扩展性问题。
2. 核心组件
- HBase Master:负责处理客户端的写请求,管理Region的分配和负载均衡,以及维护集群的状态信息。
- HBase RegionServer:负责数据的存储和读取,管理多个Region。
- Region:HBase数据表在物理存储上的划分单元,每个Region由多个Store组成。
- Store:存储某个列族(ColumnFamily)数据的场所,包含多个MemStore和一个或多个HFile。
- MemStore:位于RegionServer内存中,用于暂存新写入的数据,待数据达到一定大小或达到触发条件后,会将其刷新到HFile中。
- HFile:HBase中数据的物理存储格式,是存储在HDFS上的二进制文件。
3. HBase的特点
- 高可扩展性:HBase通过水平扩展可以支持PB级别的数据存储,集群中的节点数量可以动态增加或减少,以应对数据增长和访问压力的变化。
- 高可靠性:HBase通过数据复制和分布存储实现高可靠性。默认情况下,每个Region的数据会复制三份存储在不同的RegionServer上,确保数据的冗余和容错。此外,HBase还利用ZooKeeper来实现集群的协调和管理,确保服务的高可用性和稳定性。
- 高性能:HBase支持高速的读写操作,尤其适用于实时数据访问和处理场景。其面向列的存储模式使得在读取特定列数据时具有更高的效率,减少了不必要的IO开销。
- 面向列:与传统的行式存储数据库不同,HBase采用面向列的存储模式。每个表由多个列族组成,每个列族包含多个列。这种存储模式使得HBase在处理大规模数据和高并发访问时具有优势,能够更有效地利用磁盘空间和网络带宽资源。
二、HBase与传统RDBMS的区别
1. 数据类型
- HBase主要存储字符串类型的数据,而传统的关系数据库管理系统(RDBMS)支持多种数据类型(如整数、浮点数、日期等)。在HBase中,数据通常以字节数组(byte array)的形式存储和传输,这使得HBase在处理非结构化数据和半结构化数据时更加灵活和高效。
2. 数据操作
- HBase仅支持表内数据的操作,不支持复杂的表间关系操作(如JOIN操作)。而RDBMS支持复杂的SQL查询和表间关系操作,提供了更丰富的数据处理和分析能力。
3. 存储方式
- HBase采用面向列的存储模式,将同一列的数据存储在一起。这种存储方式使得在读取特定列数据时具有更高的效率,因为只需要读取和解析包含该列数据的部分数据块即可。而RDBMS采用行式存储模式,将同一行的数据存储在一起。这种存储方式在处理包含多列数据的记录时具有较高的效率,但在读取特定列数据时可能需要读取和解析整个记录的数据块。
4. 伸缩性
- HBase支持水平扩展,可以通过增加节点数量来扩展集群的处理能力和存储容量。而RDBMS的扩展性相对较差,通常需要通过升级硬件或采用分区等技术来提高性能和容量。
5. 事务性
- HBase没有事务支持,对数据的更新和删除操作是异步的,并且不保证数据的一致性。而RDBMS支持事务管理,可以通过ACID属性来保证数据的一致性和可靠性。在HBase中,对于需要强一致性的数据操作,需要借助外部工具或框架来实现(如HBase的Coprocessor或与其他系统(如Kafka、Flink等)集成)。
三、HBase数据模型
HBase的数据模型与关系型数据库有显著的不同。它基于行键(RowKey)、列族(ColumnFamily)、列(Column)和单元格(Cell)的层次结构。
- 行键(RowKey):
- 是HBase表中每条记录的唯一标识。
- 设计原则:长度建议10~100字节,但越短越好,避免超过16字节,以提高存储和查询效率。
- 重要性:决定了数据在HBase中的物理存储顺序和访问方式。
- 列族(ColumnFamily):
- 是HBase中数据的逻辑分组,可以包含多个列。
- 特点是所有列族的数据在物理存储上是分开的,但属于同一列族的数据会存储在一起。
- 设计时,列族的数量不宜过多,一般建议每个表不超过几个列族。
- 列(Column):
- 列是列族下的具体字段,由列名和时间戳组成。
- 在HBase中,列的数量可以动态增加,同一表中的不同行可以有不同的列。
- 单元格(Cell):
- 是行、列、时间戳和数据值的组合。
- 数据值以字节数组的形式存储,可以是任意类型的数据,但HBase内部只处理字节数组。
四、HBase的特点
- 稀疏性:
- 在HBase中,空(null)的列并不占用存储空间,表可以设计得非常稀疏。
- 这使得HBase非常适合存储半结构化或非结构化数据,如日志文件、用户行为数据等。
- 多版本数据:
- HBase支持数据的多个版本,每个单元中的数据可以有多个版本。
- 版本号通常是数据插入时的时间戳,可以根据需要查询和恢复数据的旧版本。
- 数据类型单一:
- HBase中的数据都是字符串(或字节数组)类型,没有类型系统。
- 这简化了数据处理的复杂性,但也需要用户自行处理数据类型转换和验证。
- 主从架构:
- HBase采用主从架构,其中HBase Master是主节点,负责管理和协调集群的运行;RegionServer是从节点,负责数据的存储和读取。
- 这种架构使得HBase能够支持高并发的读写操作,并提供了较好的容错性和可扩展性。
- 与Hive的区别:
- Hive是基于Hadoop的一个数据仓库工具,提供了类似SQL的查询接口;而HBase是一个NoSQL数据库,提供了面向列的存储和访问方式。
- Hive适用于离线批处理查询场景,而HBase适用于实时数据访问和处理场景。两者可以配合使用,如将Hive的数据导出到HBase进行实时查询。
五、HBase与Hadoop生态系统的关系
- HBase是Hadoop生态系统中的一个重要组件,与HDFS、MapReduce、ZooKeeper等紧密集成。
- HDFS为HBase提供底层存储支持,使得HBase能够处理大规模数据集。
- ZooKeeper用于管理HBase集群的状态信息,如Region的位置、节点的状态等。
- MapReduce可以与HBase结合使用,进行大规模数据分析和处理。
相关文章:
)
HBase数据库面试知识点:第一部分 - 基础概念与特点(持续更新中)
目录 一、HBase基础概念 1. HBase定义 2. 核心组件 3. HBase的特点 二、HBase与传统RDBMS的区别 1. 数据类型 2. 数据操作 3. 存储方式 4. 伸缩性 5. 事务性 三、HBase数据模型 四、HBase的特点 五、HBase与Hadoop生态系统的关系 一、HBase基础概念 1. HBase定义 …...

一个高效的go语言字符串转驼峰命名算法实现函数
在go语言的开发中我们经常需要对各种命名进行规范, 今天给大家介绍的是一个高效的将字符串转 驼峰命名 (即 首字母大写的命名方式)的函数。 // 字符串转驼峰命名 // author tekintian <tekintiangmail.com> func CamelStr(str string) …...

Python中__init__方法的魔力:构建对象的基石
Python中__init__方法的魔力:构建对象的基石 在Python的世界中,__init__方法是一个特殊的存在。它不仅是类的构造函数,更是对象生命周期的起点。通过__init__方法,我们可以初始化对象的状态,设置属性,甚至…...
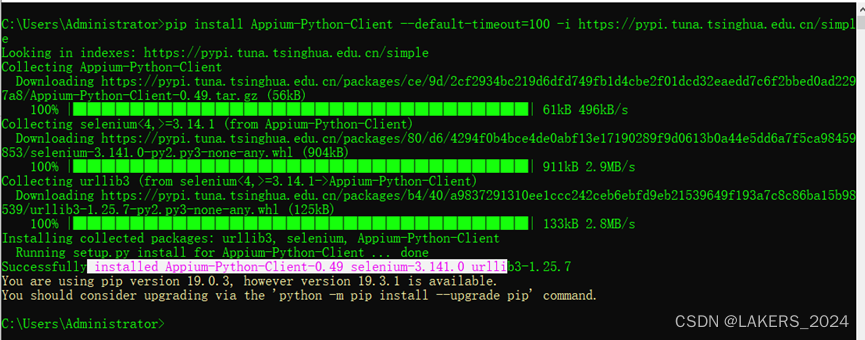
Appium安装及配置(Windows环境)
在做app相关自动化测试,需要使用appium来做中转操作,下面来介绍一下appium的环境安装配置 appium官方文档:欢迎 - Appium Documentation 一、下载appium 下载地址:https://github.com/appium/appium-desktop/releases?page3 通…...
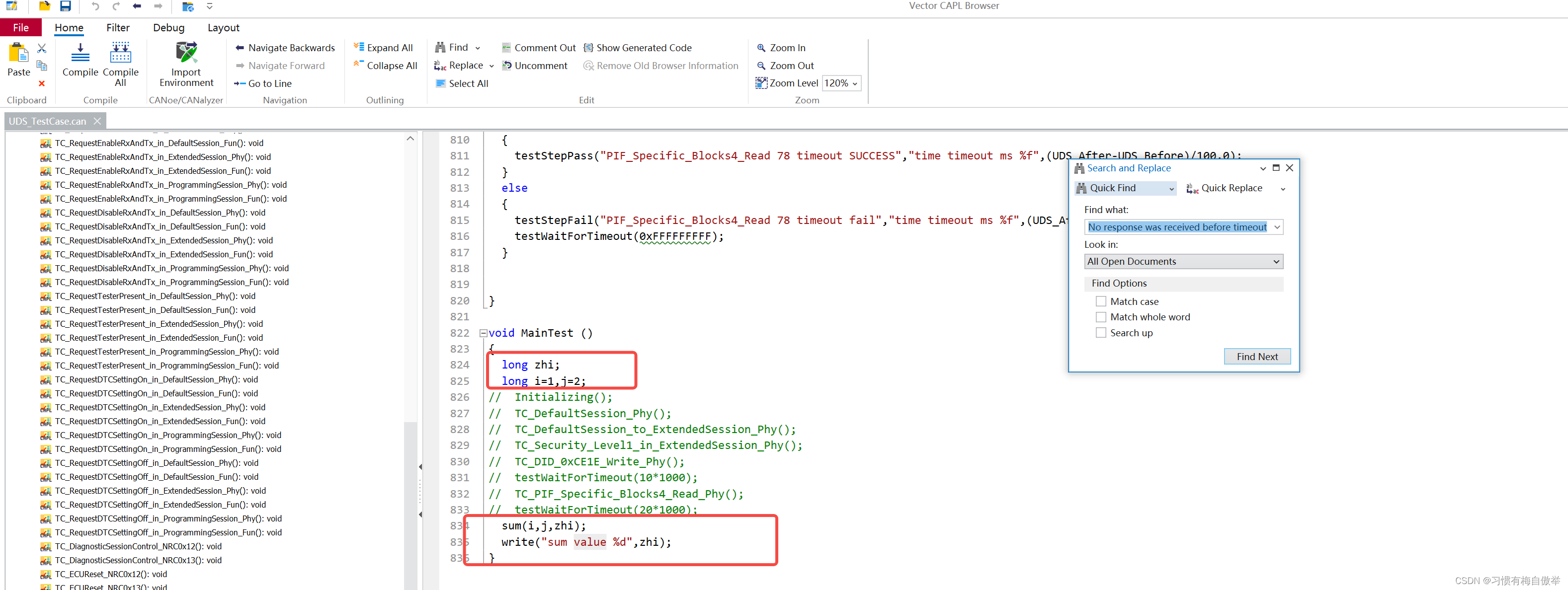
CANOE制造dll文件,以及应用dll文件
1、使用canoe自带的capl dll 2、然后使用Visual Studio 2022 打开项目 3、项目打开后修改下项目属性 4、修改capldll.cpp文件 4.1 添加的内容 void CAPLEXPORT far CAPLPASCAL appSum(long i, long j, long* s){*s i j;} {"sum", (CAPL_FARCALL)appSum, "…...

C++结合OpenCV进行图像处理与分类
⭐️我叫忆_恒心,一名喜欢书写博客的在读研究生👨🎓。 如果觉得本文能帮到您,麻烦点个赞👍呗! 近期会不断在专栏里进行更新讲解博客~~~ 有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三…...

Master-Worker 架构的灰度发布难题
作者:石超 一、前言 Master-Worker 架构是成熟的分布式系统设计模式,具有集中控制、资源利用率高、容错简单等优点。我们数据中心内的几乎所有分布式系统都采用了这样的架构。  我们曾经发生过级联故障,造成了整个集群范围的服…...
钢基础知识介绍
钢铁是一种铁碳合金,含有一定量的碳和其他合金元素,如硅、锰等。而钢材则是经过加工处理后的钢铁材料,具有更高的强度、硬度、塑性和韧性。钢铁的硬度、强度和耐磨性相对较低,而钢材经过加工处理后,其硬度、强度和耐磨…...
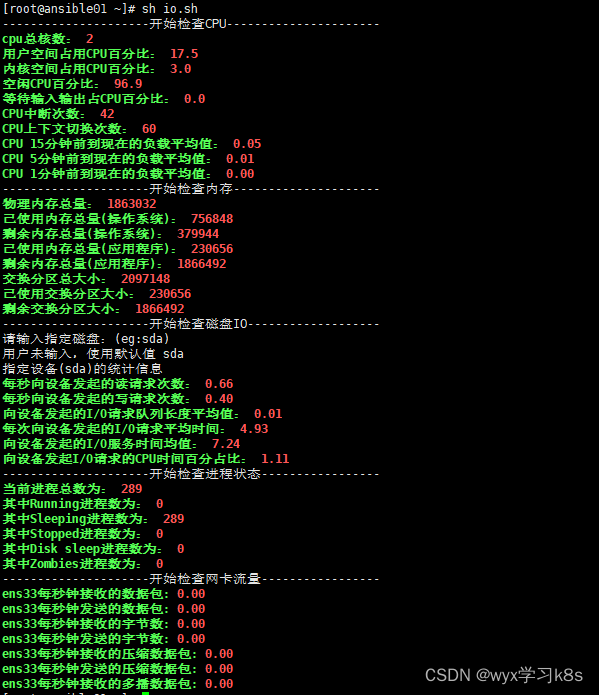
linux 系统监控脚本
1.对CPU的监控函数 function GetCpu(){cpu_numgrep -c "model name" /proc/cpuinfocpu_usertop -b -n 1 | grep Cpu | awk {print $2} | cut -f 1 -d "%"cpu_systemtop -b -n 1 | grep Cpu | awk {print $4} | cut -f 1 -d "%"cpu_idletop -b -…...

K8s Pod的QoS类
文章目录 OverviewPod的QoS分类Guaranteed1.如何将 Pod 设置为保证Guaranteed2. Kubernetes 调度器如何管理Guaranteed类的Pod Burstable1. 如何将 Pod 设置为Burstable2.b. Kubernetes 调度程序如何管理 Burstable Pod BestEffort1. 如何将 Pod 设置为 BestEffort2. Kubernete…...
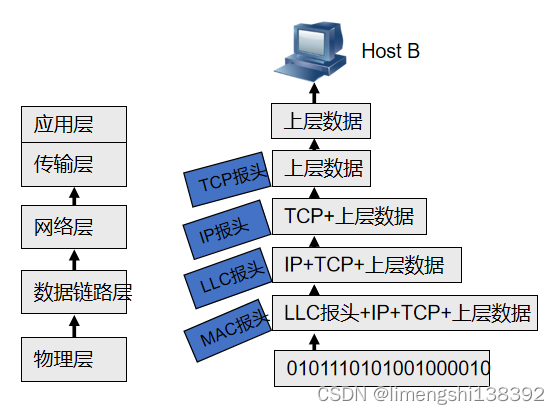
TCP/IP协议栈
一、TCP/IP协议栈和OSI参考模型对比 二、TCP/IP五层功能 三、TCP/IP模型的层间通信与数据封装 四、TCP/IP模型的层间通信与数据解封装...

Vector容器详解
Vector容器详解 本文将详细介绍C#中的Vector容器,包括其定义、特点、使用方法以及示例代码。 目录 Vector容器简介Vector容器的特点Vector容器的使用方法示例代码 1. Vector容器简介 Vector容器是一种动态数组,它可以自动调整大小以容纳更多的元素。…...
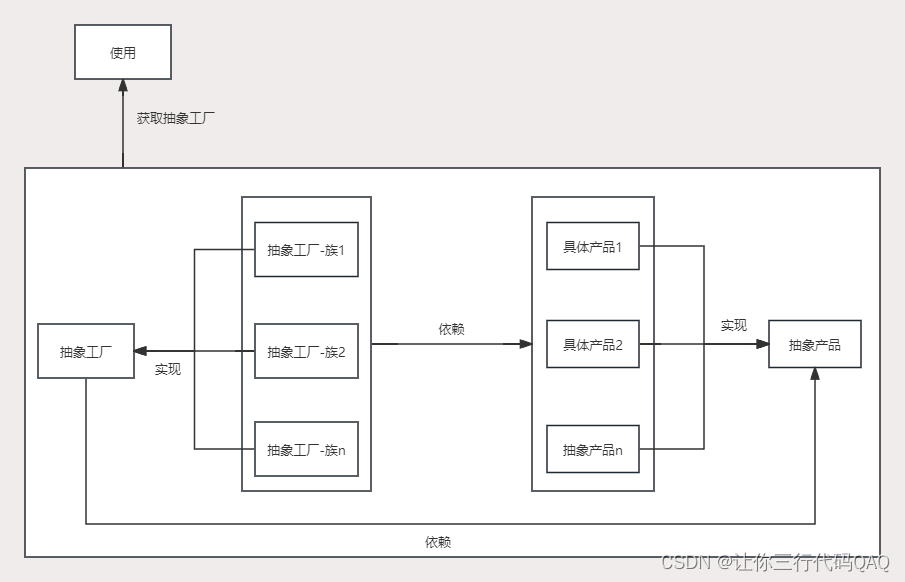
设计模式-抽象工厂(创建型)
创建型-抽象工厂 角色 抽象工厂: 声明创建一个族产品对象的方法,每个方法对应一中产品,抽象工厂可以是接口,也可以是抽象类;具体工厂: 实现抽象工厂接口,复杂创建具体的一族产品;抽…...
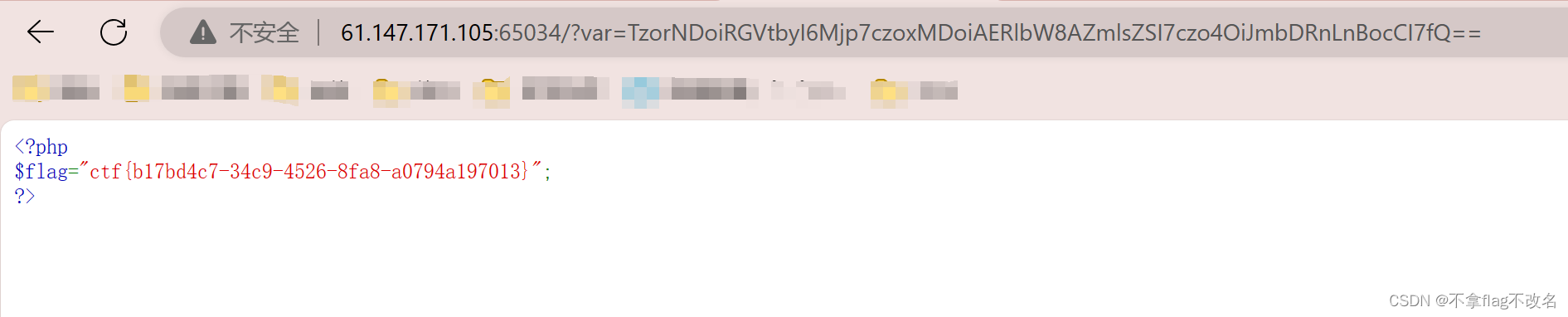
攻防世界---web---Web_php_unserialize
1、题目描述 2、 3、分析代码 class Demo { private $file fl4g.php; }:定义了一个名为Demo的类,该类有一个私有属性$file,默认值为fl4g.php。 $a serialize(new Demo);:创建了一个Demo类的实例,并对其进行序列化&a…...

嵌入式学习记录
一 环境搭建 1.Ubuntu ssh登陆开发板,短命令替换ssh命令 交叉编译命令 sudo gedit ~/.bashrc # 文件结尾加入: alias tob"ssh root192.168.1.104" alias gb"arm-buildroot-linux-gnueabihf-gcc"往后终端输入top 相当于输入ssh roo…...

使用from…import语句导入模块
自学python如何成为大佬(目录):https://blog.csdn.net/weixin_67859959/article/details/139049996?spm1001.2014.3001.5501 在使用import语句导入模块时,每执行一条import语句都会创建一个新的命名空间(namespace),并且在该命名…...

idea mac快捷键
Mac快捷键 快捷键 说明 ⌘ F 在当前窗口查找 ⌘ ⇧ F 在全工程查找 ⌘ ⇧ ⌥ N 查找类中的方法或变量 F3 / ⇧ F3 移动到搜索结果的下/上一匹配处 ⌘ R 在当前窗口替换 ⌘ ⇧ R 在全工程替换 ⌘ ⇧ V 可以将最近使用的剪贴板内容选择插入到文本 ⌥…...
)
Day1——一些感想,学习计划和自我激励(不重要,跳过吧)
笨人刚刚接触计算机的时候,属于是两眼一抹黑。高考后玩了一整个暑假,脑子已经丢掉了,学起来很痛苦,但是也在学习过程中接触到了很多新鲜的东西,现在对于计算机的各种方向,我都很想试试(试试就逝…...
网络安全渗透工具汇总
一、HackBar github地址:https://github.com/Mr-xn/hackbar2.1.3.git 介绍 HackBar是一款基于浏览器的渗透测试工具,可以简化目标网站的攻击流程。它可以轻松地注入JavaScript和其他脚本,进行SQL注入、XSS攻击、各种类型的扫描等。该工具…...
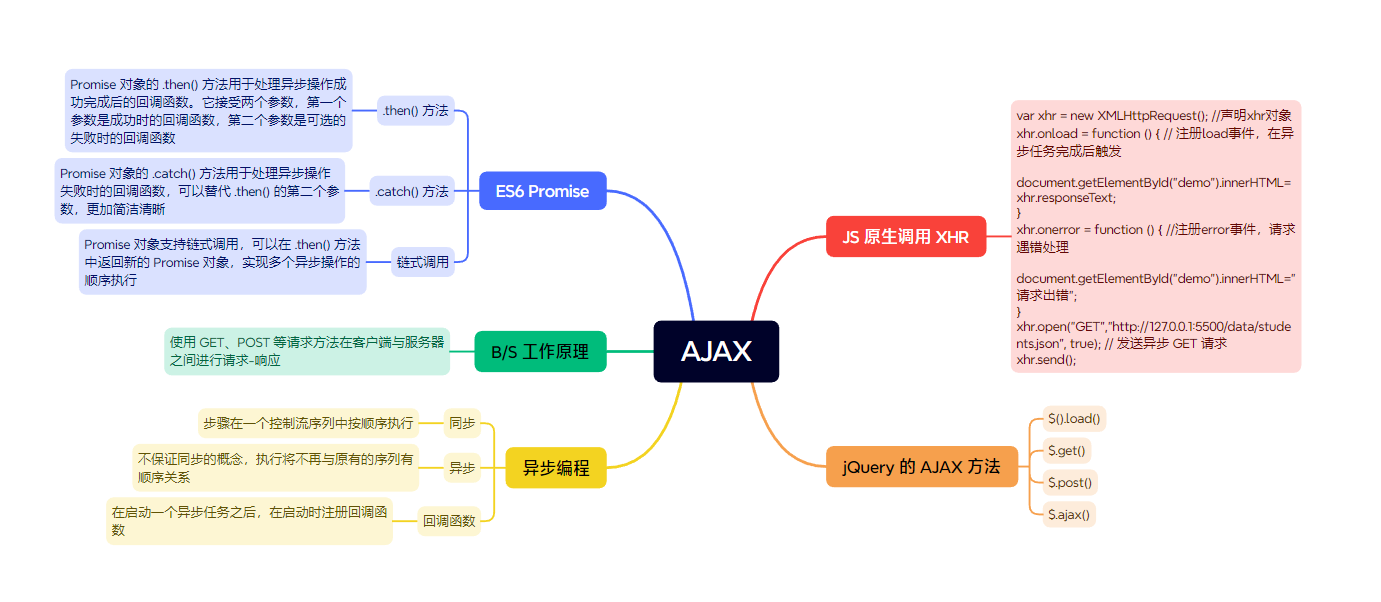
JavaScript 学习笔记 总结
回顾: Web页面标准 页面结构:HTML4、HTML5页面外观和布局:CSS页面行为:JavaScript强调三者的分离前后端分离开发模式 响应式设计Bootstrap框架入门 Bootstrap总结 基础 下载和使用基础样式:文本样式、图片样式、表格…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...