Spark MLlib 机器学习详解
目录
🍉引言
🍉Spark MLlib 简介
🍈 主要特点
🍈常见应用场景
🍉安装与配置
🍉数据处理与准备
🍈加载数据
🍈数据预处理
🍉分类模型
🍈逻辑回归
🍈评价模型
🍉回归模型
🍈线性回归
🍈评价模型
🍉聚类模型
🍈K-means 聚类
🍈评价模型
🍉降维模型
🍈PCA 主成分分析
🍉 协同过滤
🍈ALS 模型
🍈评价模型
🍉实战案例:房价预测
🍈数据加载与预处理
🍈模型训练与预测
🍈模型评估
🍈结果分析
🍉总结
🍉引言
- Apache Spark 是一个开源的分布式计算框架,它提供了高效的处理大规模数据集的能力。Spark MLlib 是 Spark 的机器学习库,旨在提供可扩展的、易于使用的机器学习算法。MLlib 提供了一系列工具,用于分类、回归、聚类、协同过滤、降维等任务。
- 本文将详细介绍 Spark MLlib 的功能及其应用,结合实例讲解如何在实际数据处理中使用这些功能。
🍉Spark MLlib 简介

🍈 主要特点
- 易于使用:提供了丰富的 API,支持 Scala、Java、Python 和 R 等多种编程语言。
- 高度可扩展:可以处理海量数据,适用于大规模机器学习任务。
- 丰富的算法库:支持分类、回归、聚类、降维、协同过滤等常用算法。
🍈常见应用场景
- 分类:如垃圾邮件检测、图像识别、情感分析等。
- 回归:如房价预测、股票价格预测等。
- 聚类:如客户分群、图像分割等。
- 协同过滤:如推荐系统等。
- 降维:如特征选择、特征提取等。
🍉安装与配置
在使用 Spark MLlib 之前,需要确保已经安装了 Apache Spark。可以通过以下命令安装Spark:
# 安装 Spark
!apt-get install -y spark# 安装 PySpark
!pip install pyspark
🍉数据处理与准备
机器学习的第一步通常是数据的获取与预处理。以下示例演示如何加载数据并进行预处理。
🍈加载数据
我们使用一个简单的示例数据集:波士顿房价数据集。该数据集包含506个样本,每个样本有13个特征和1个目标变量(房价)。
from pyspark.sql import SparkSession# 创建 SparkSession
spark = SparkSession.builder.appName("MLlibExample").getOrCreate()# 加载数据集
data_path = "path/to/boston_housing.csv"
data = spark.read.csv(data_path, header=True, inferSchema=True)
data.show(5)
🍈数据预处理
预处理步骤包括数据清洗、特征选择、数据标准化等。
from pyspark.sql.functions import col
from pyspark.ml.feature import VectorAssembler, StandardScaler# 选择特征和目标变量
feature_columns = data.columns[:-1]
target_column = data.columns[-1]# 将特征列组合成一个向量
assembler = VectorAssembler(inputCols=feature_columns, outputCol="features")
data = assembler.transform(data)# 标准化特征
scaler = StandardScaler(inputCol="features", outputCol="scaledFeatures")
scaler_model = scaler.fit(data)
data = scaler_model.transform(data)# 选择最终的数据集
data = data.select(col("scaledFeatures").alias("features"), col(target_column).alias("label"))
data.show(5)
🍉分类模型
🍈逻辑回归
逻辑回归是一种常用的分类算法。以下示例演示如何使用逻辑回归进行分类。
from pyspark.ml.classification import LogisticRegression# 创建逻辑回归模型
lr = LogisticRegression(featuresCol="features", labelCol="label")# 拆分数据集
train_data, test_data = data.randomSplit([0.8, 0.2])# 训练模型
lr_model = lr.fit(train_data)# 预测
predictions = lr_model.transform(test_data)
predictions.select("features", "label", "prediction").show(5)
🍈评价模型
模型评估是机器学习过程中的重要环节。我们可以使用准确率、精确率、召回率等指标来评估分类模型。
from pyspark.ml.evaluation import MulticlassClassificationEvaluator# 评价模型
evaluator = MulticlassClassificationEvaluator(labelCol="label", predictionCol="prediction", metricName="accuracy")
accuracy = evaluator.evaluate(predictions)
print(f"Accuracy: {accuracy}")
🍉回归模型
🍈线性回归
线性回归用于预测连续值。以下示例演示如何使用线性回归进行预测。
from pyspark.ml.regression import LinearRegression# 创建线性回归模型
lr = LinearRegression(featuresCol="features", labelCol="label")# 训练模型
lr_model = lr.fit(train_data)# 预测
predictions = lr_model.transform(test_data)
predictions.select("features", "label", "prediction").show(5)
🍈评价模型
我们可以使用均方误差(MSE)、均方根误差(RMSE)等指标来评估回归模型。
from pyspark.ml.evaluation import RegressionEvaluator# 评价模型
evaluator = RegressionEvaluator(labelCol="label", predictionCol="prediction", metricName="rmse")
rmse = evaluator.evaluate(predictions)
print(f"RMSE: {rmse}")
🍉聚类模型
🍈K-means 聚类
K-means 是一种常用的聚类算法。以下示例演示如何使用 K-means 进行聚类。
from pyspark.ml.clustering import KMeans# 创建 K-means 模型
kmeans = KMeans(featuresCol="features", k=3)# 训练模型
kmeans_model = kmeans.fit(data)# 预测
predictions = kmeans_model.transform(data)
predictions.select("features", "prediction").show(5)
🍈评价模型
我们可以使用轮廓系数(Silhouette Coefficient)等指标来评估聚类模型。
from pyspark.ml.evaluation import ClusteringEvaluator# 评价模型
evaluator = ClusteringEvaluator(featuresCol="features", predictionCol="prediction", metricName="silhouette")
silhouette = evaluator.evaluate(predictions)
print(f"Silhouette Coefficient: {silhouette}")
🍉降维模型
🍈PCA 主成分分析
PCA 是一种常用的降维技术,用于减少数据的维度,同时保留尽可能多的信息。以下示例演示如何使用 PCA 进行降维。
from pyspark.ml.feature import PCA# 创建 PCA 模型
pca = PCA(k=3, inputCol="features", outputCol="pcaFeatures")# 训练模型
pca_model = pca.fit(data)# 转换数据
pca_result = pca_model.transform(data)
pca_result.select("features", "pcaFeatures").show(5)
🍉 协同过滤
🍈ALS 模型
ALS(交替最小二乘法)是一种常用的协同过滤算法,常用于推荐系统。以下示例演示如何使用 ALS 进行推荐。
from pyspark.ml.recommendation import ALS# 创建 ALS 模型
als = ALS(userCol="userId", itemCol="movieId", ratingCol="rating")# 训练模型
als_model = als.fit(train_data)# 预测
predictions = als_model.transform(test_data)
predictions.select("userId", "movieId", "rating", "prediction").show(5)
🍈评价模型
我们可以使用均方误差(MSE)等指标来评估协同过滤模型。
evaluator = RegressionEvaluator(labelCol="rating", predictionCol="prediction", metricName="rmse")
rmse = evaluator.evaluate(predictions)
print(f"RMSE: {rmse}")
🍉实战案例:房价预测
接下来,我们将通过一个实战案例,完整展示如何使用 Spark MLlib 进行房价预测。步骤包括数据加载与预处理、模型训练与预测、模型评估。
🍈数据加载与预处理
# 加载数据集
data_path = "path/to/boston_housing.csv"
data = spark.read.csv(data_path, header=True, inferSchema=True)# 数据预处理
assembler = VectorAssembler(inputCols=data.columns[:-1], outputCol="features")
data = assembler.transform(data)scaler = StandardScaler(inputCol="features", outputCol="scaledFeatures")
scaler_model = scaler.fit(data)
data = scaler_model.transform(data)data = data.select(col("scaledFeatures").alias("features"), col("label"))
🍈模型训练与预测
我们将使用线性回归模型进行房价预测。
# 拆分数据集
train_data, test_data = data.randomSplit([0.8, 0.2])# 创建线性回归模型
lr = LinearRegression(featuresCol="features", labelCol="label")# 训练模型
lr_model = lr.fit(train_data)# 预测
predictions = lr_model.transform(test_data)
🍈模型评估
# 评价模型
evaluator = RegressionEvaluator(labelCol="label", predictionCol="prediction", metricName="rmse")
rmse = evaluator.evaluate(predictions)
print(f"RMSE: {rmse}")
🍈结果分析
我们可以通过绘图等手段进一步分析预测结果。
import matplotlib.pyplot as plt# 提取实际值和预测值
actual = predictions.select("label").toPandas()
predicted = predictions.select("prediction").toPandas()# 绘制实际值与预测值对比图
plt.figure(figsize=(10, 6))
plt.scatter(actual, predicted, alpha=0.5)
plt.xlabel("Actual")
plt.ylabel("Predicted")
plt.title("Actual vs Predicted")
plt.show()
🍉总结
- 本文详细介绍了 Spark MLlib 的功能及其应用,结合实例演示了分类、回归、聚类、降维、协同过滤等常用机器学习任务的实现过程。通过这些实例,我们可以看到 Spark MLlib 强大的数据处理和机器学习能力,非常适合大规模数据的处理与分析。
- 在实际应用中,根据具体需求选择合适的算法和模型,并通过数据预处理、特征选择、模型训练与评估等步骤,不断优化和提升模型性能,从而解决实际问题。
- 希望本文能够为读者提供一个全面的 Spark MLlib 机器学习的参考,帮助读者更好地理解和应用这一强大的工具。

相关文章:
Spark MLlib 机器学习详解
目录 🍉引言 🍉Spark MLlib 简介 🍈 主要特点 🍈常见应用场景 🍉安装与配置 🍉数据处理与准备 🍈加载数据 🍈数据预处理 🍉分类模型 🍈逻辑回归 &a…...
MySQL报ERROR 2002 (HY000)解决
今天在连接客户服务器时MySQL的时候报: ERROR 2002 (HY000): Can’t connect to local MySQL server through socket ‘/tmp/mysql/mysql.sock’ (2) [rootXXX ~]# mysql -uroot -p Enter password: ERROR 2002 (HY000): Can’t connect to local MySQL server through socket…...

【校招】【社招】字节跳动UG营销算法工程师招聘
【校招】【社招】字节跳动UG营销算法工程师招聘 需要营销、广告、搜索、推荐等领域的人才加入 岗位简介 字节跳动增长智能-激励中台团队负责公司国内字节所有主要App(包含但不仅限于抖音/抖音极速版/抖音火山版/今日头条/头条极速版/番茄小说/番茄畅听/西瓜视频&…...
Go实战 | 使用Go-Fiber采用分层架构搭建一个简单的Web服务
前言 📢博客主页:程序源⠀-CSDN博客 📢欢迎点赞👍收藏⭐留言📝如有错误敬请指正! 一、环境准备、示例介绍 Go语言安装,GoLand编辑器 这个示例实现了一个简单的待办事项(todo…...

Web自动化测试框架+PO模式分层实战(超细整理)
前言 PO模式 在UI级的自动化测试中,对象设计模式表示测试正在交互的web应用,程序用户界面中的一个区域,这个是减少了代码的重复,也就是说,如果用户界面发生了改变,只需要在一个地方修改程序就可以了。 优…...
光猫、路由器的路由模式、桥接模式、拨号上网
下面提到的路由器都是家用路由器 一、联网条件 1.每台电脑、路由器、光猫想要上网,都必须有ip地址。 2.电脑获取ip 可以设置静态ip 或 向DHCP服务器(集成在路由器上) 请求ip 电话线上网时期,猫只负责模拟信号和数字信号的转换,电脑需要使…...
iOS--工厂设计模式
iOS--工厂设计模式 设计模式的概念和意义类族模式UIButton作为类族模式的例子总结 三种工厂设计模式简单工厂模式(Simple Factory Pattern):代码实例 工厂方法模式(Factory Method Pattern):代码实例 抽象工…...

[Python]用Qt6和Pillow实现截图小工具
本文章主要讲述的内容是,使用python语言借助PyQt6和Pillow库进行简单截图工具的开发,含义一个简单的范围裁剪和软件界面。 主要解决的问题是,在高DPI显示屏下,坐标点的偏差导致QWidget显示图片不全、剪裁范围偏差问题。 适合有一点…...

Podman和Docker的区别
Podman 和 Docker 都是用于容器化的工具,但它们在架构、安全性、容器编排以及一些设计理念上有显著的区别: 架构设计: Docker 使用客户端-服务器(C/S)架构,包含一个名为 dockerd 的守护进程,该进程以 root …...
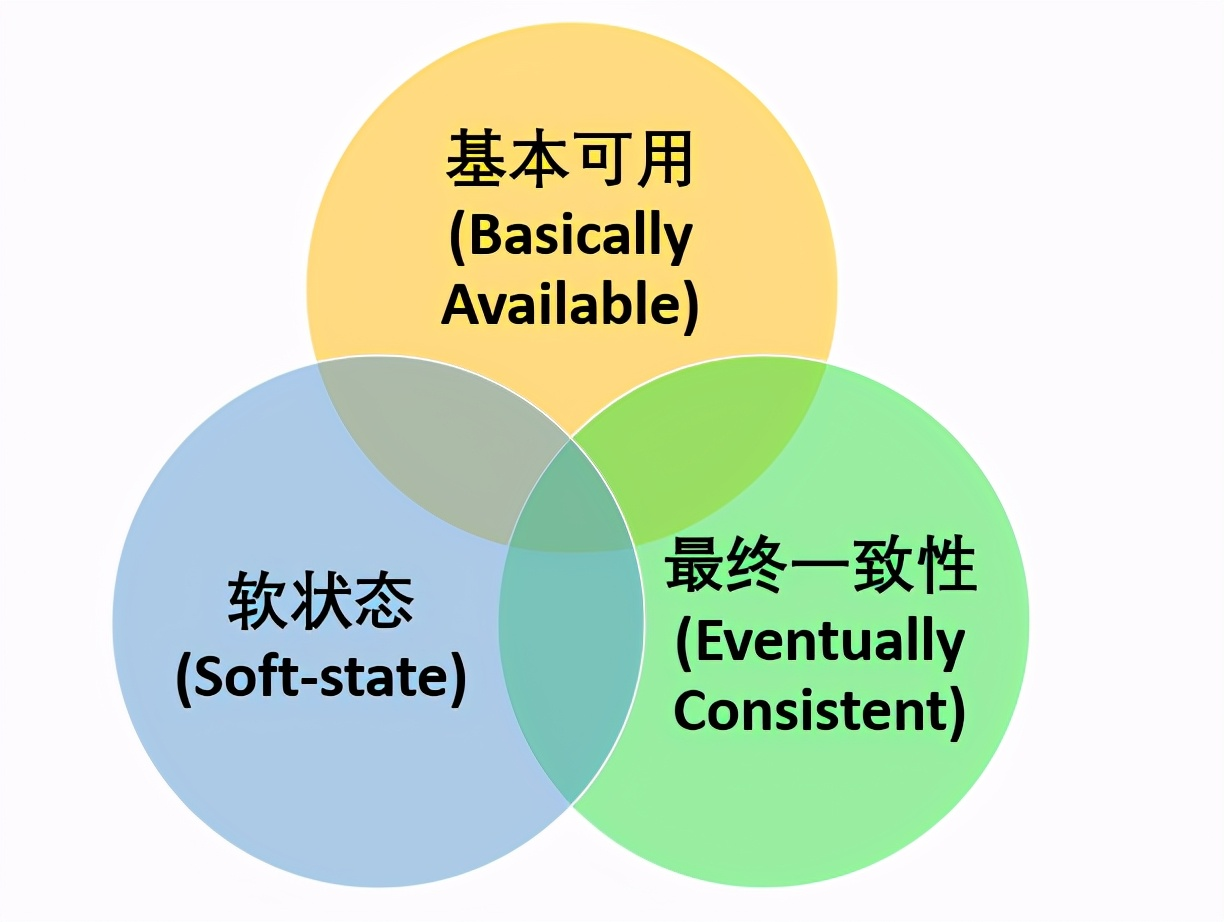
Go微服务: 分布式Cap定理和Base理论
分布式中的Cap定理 CAP理论 C: 一致性,是站在分布式的角度,要么读取到数据,要么读取失败,比如数据库主从,同步时的时候加锁,同步完成才能读到同步的数据,同步完成,才返回数据给程序&…...
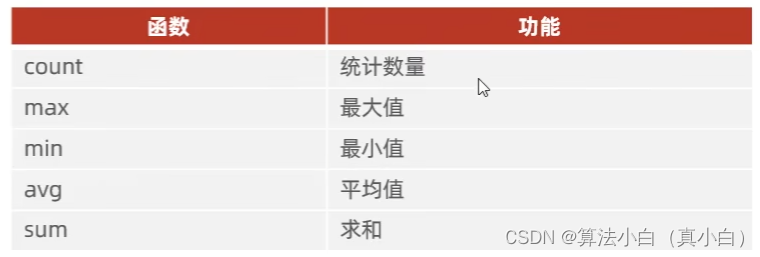
Mysql学习(四)——SQL通用语法之DQL
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 DQLDQL-语法基本查询条件查询聚合函数分组查询排序查询分页查询 DQL DQL数据查询语言,用来查询数据库中表的记录。 DQL-语法 select 字段列表 from 表…...
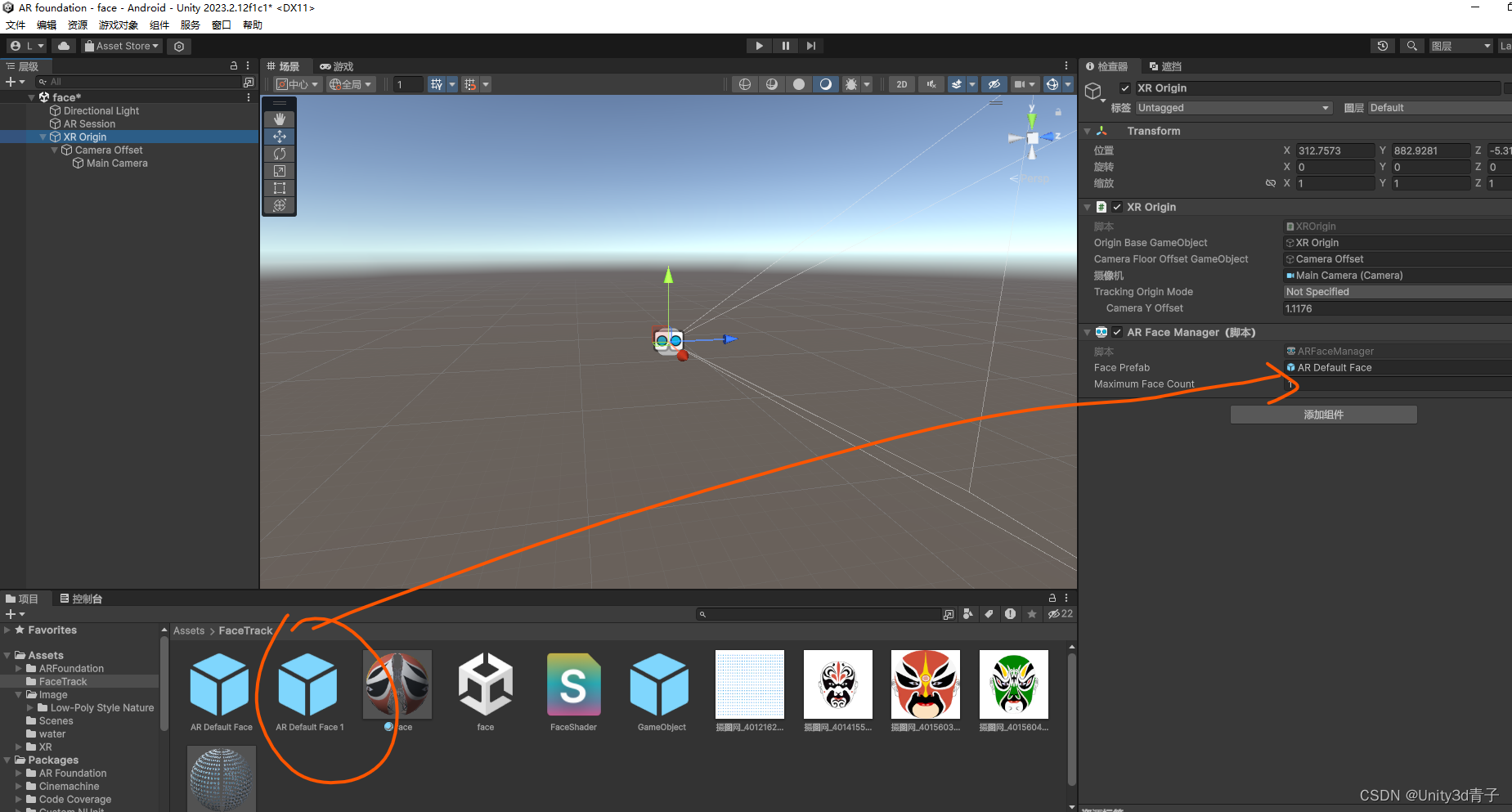
【ARFoundation自学05】人脸追踪(AR Face manager)实现
1. 修改摄像机朝向渲染方式-选中user 这个方式就会调用前置摄像头 2 创建 AR Session、XR Origin,然后在XR Origin上面添加组件 注意:XR Origin 老版本仍然叫 AR Session Origin 接下来在XR Origin上面添加AR Face Manager组件,如下图&am…...
Vulnhub-DC-2
靶机IP:192.168.20.135 网络有问题的可以看下搭建Vulnhub靶机网络问题(获取不到IP) kaliIP:192.168.20.128 扫描靶机端口及服务版本 发现开放了80和7744端口 并且是wordpress建站 dirsearch扫描目录 访问前端界面,发现存在重定向 在hosts文件中增加192.168.2…...
VNC server ubuntu20 配置
介绍 最近想使用实验室的4卡服务器跑一些深度学习实验,因为跑的是三维建图实验,需要配上可视化界面,本来自带的IPMI可以可视化,但分辨率固定在640*480,看起来很别扭,就捣鼓服务器远程可视化访问了两天&…...
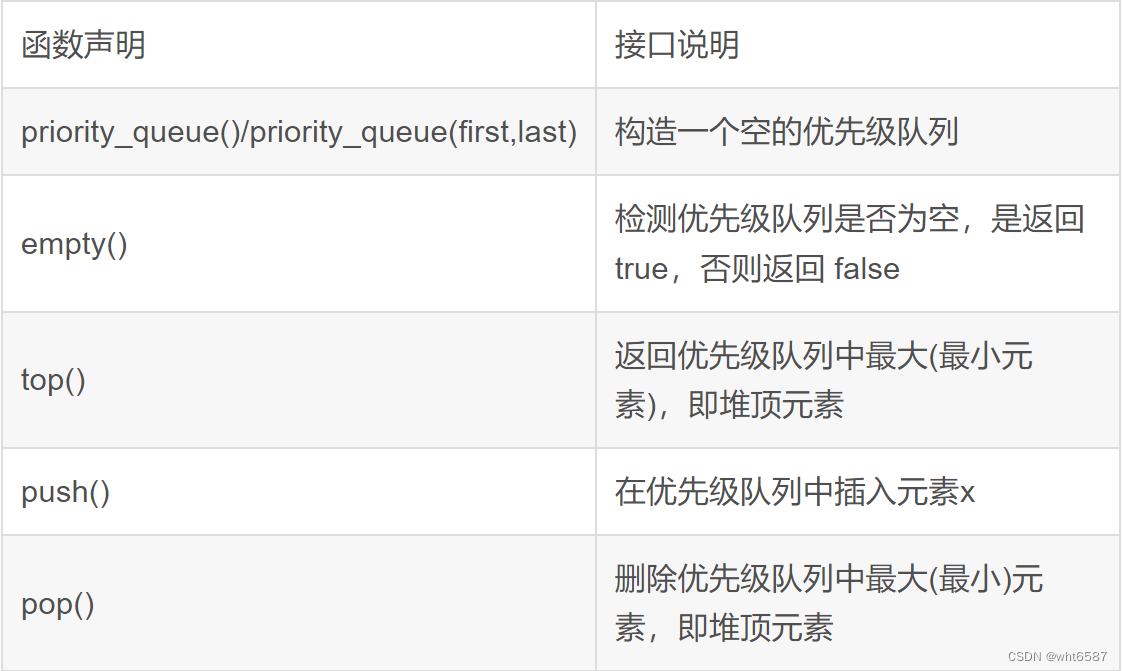
c++--priority_queue和仿函数
目录 1.priority_queue 实现: 2.仿函数 priority_queue仿函数 实现代码 1.priority_queue 优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的,其实就是个堆,默认是大根堆。…...

Harmony os Next——关系型数据库relationalStore.RdbStore的使用
Harmony os Next——关系型数据库relationalStore.RdbStore的使用 描述数据库的使用建表定义表信息创建数据库表 创建数据库操作对象增更新查询删数据库的初始化 描述 本文通过存储一个简单的用户信息到数据库中为例,进行阐述relationalStore.RdbStore数据库的CRUD…...

快手直播限流怎么办?
直播限流怎么办?这期把直播间限流的所有原因都讲得明明白白,如果你直播间昨天还播的好好的,今天突然间贴地飞行,按照这个思路框架去排查,准没问题。 第一件事情肯定是排查一下评分问题, 信用分、口碑分、…...
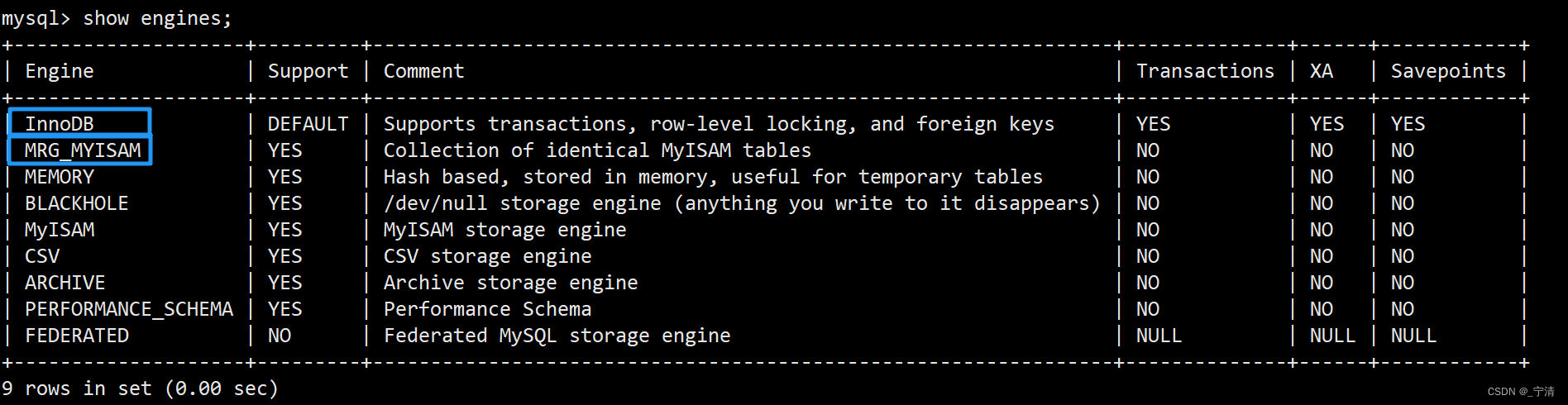
【MySQL】数据库入门基础
文章目录 一、数据库的概念1. 什么是数据库2. 主流数据库3. mysql和mysqld的区别 二、MySQL基本使用1. 安装MySQL服务器在 CentOS 上安装 MySQL 服务器在 Ubuntu 上安装 MySQL 服务器验证安装 2. 服务器管理启动服务器查看服务器连接服务器停止服务器重启服务器 3. 服务器&…...

cannot allocate memory in static TLS block
如果不是内存太小,那是不是因为glibc太旧呢? 考虑 glibc 2.22 以后的版本。 glibc-2.22 中加入了如下commit:f8aeae347377f3dfa8cbadde057adf1827fb1d44 https://sourceware.org/git/?pglibc.git;acommit;hf8aeae347377f3dfa8cbadde057adf1…...

Leetcode 654:最大二叉树
给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建: 创建一个根节点,其值为 nums 中的最大值。递归地在最大值 左边 的 子数组前缀上 构建左子树。递归地在最大值 右边 的 子数组后缀上 构建右子树。 返回 nums 构建的 最大二叉树…...

css实现圆环展示百分比,根据值动态展示所占比例
代码如下 <view class""><view class"circle-chart"><view v-if"!!num" class"pie-item" :style"{background: conic-gradient(var(--one-color) 0%,#E9E6F1 ${num}%),}"></view><view v-else …...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

学习STC51单片机32(芯片为STC89C52RCRC)OLED显示屏2
每日一言 今天的每一份坚持,都是在为未来积攒底气。 案例:OLED显示一个A 这边观察到一个点,怎么雪花了就是都是乱七八糟的占满了屏幕。。 解释 : 如果代码里信号切换太快(比如 SDA 刚变,SCL 立刻变&#…...

【无标题】路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论
路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论 一、传统路径模型的根本缺陷 在经典正方形路径问题中(图1): mermaid graph LR A((A)) --- B((B)) B --- C((C)) C --- D((D)) D --- A A -.- C[无直接路径] B -…...

【Redis】笔记|第8节|大厂高并发缓存架构实战与优化
缓存架构 代码结构 代码详情 功能点: 多级缓存,先查本地缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新缓存采用读写锁提升性能采用Redis的发布订阅机制通知所有实例更新本地缓存适用读多…...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...