JavaApi操作ElasticSearch(强烈推荐)
ElasticSearch 高级
1 javaApi操作es环境搭建
在elasticsearch官网中提供了各种语言的客户端:https://www.elastic.co/guide/en/elasticsearch/client/index.html
而Java的客户端就有两个:
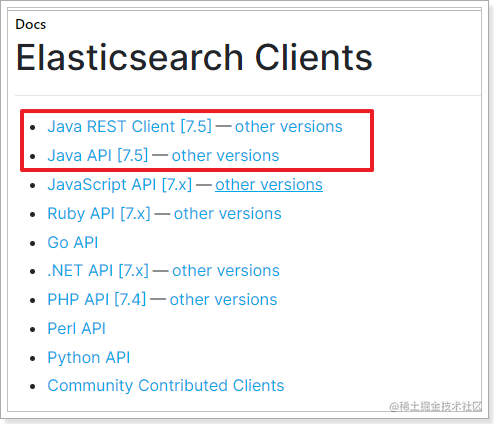
不过Java API这个客户端(Transport Client)已经在7.0以后过期了,而且在8.0版本中将直接废弃。所以我们会学习Java REST Client:
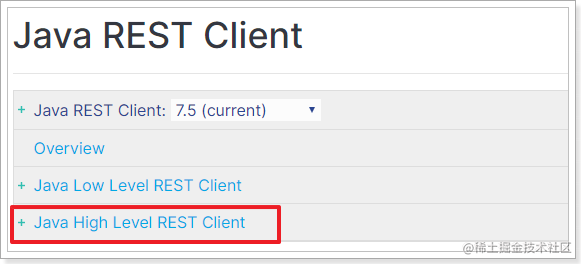
然后再选择High Level REST Client这个。
Java REST Client 其实就是利用Java语言向 ES服务发 Http的请求,因此请求和操作与前面学习的REST API 一模一样。
1.1 工程搭建及初始化
1.1.1 创建工程引入依赖
新建基于Maven的Java项目,相关信息如下:
pom.xml:
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><java.version>1.8</java.version>
</properties>
<dependencies><!--elastic客户端--><!--elastic客户端--><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.4.2</version></dependency><!-- Junit单元测试 --><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><!--lombok @Data --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.8</version></dependency><!--JSON工具 --><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.49</version></dependency><!--common工具--><dependency><groupId>org.apache.commons</groupId><artifactId>commons-lang3</artifactId><version>3.8.1</version></dependency>
</dependencies>
实体类:
com.it.esdemo.pojo.User
package com.it.sh.esdemo.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
/*** @Description:* @Version: V1.0*/
@Data
@AllArgsConstructor
public class User {private Long id;private String name;// 姓名private Integer age;// 年龄private String gender;// 性别private String note;// 备注
}
扩展:
使用Lombok需要两个条件:
1)引入依赖:
<!--lombok-->
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.8</version>
</dependency>
2)编辑器idea安装插件:
在线装,参考:https://plugins.jetbrains.com/plugin/6317-lombok
1.1.2 初始化连接ES
在官网上可以看到连接ES的教程:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high-getting-started-initialization.html
首先需要与ES建立连接,ES提供了一个客户端RestHighLevelClient。
代码如下:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http"),new HttpHost("localhost", 9201, "http")));
ES中的所有操作都是通过RestHighLevelClient来完成的:
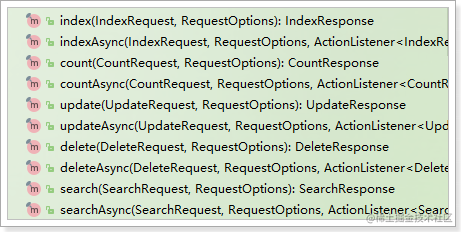
为了后面测试方便,我们写到一个单元测试中,并且通过@Before注解来初始化客户端连接。
com.it.sh.esdemo.ElasticSearchTest
package com.it.sh.esdemo;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.After;
import org.junit.Before;
import java.io.IOException;
//ES测试类
public class ElasticSearchTest {//客户端对象private RestHighLevelClient client;/*** 建立连接*/@Beforepublic void init() throws IOException {//创建Rest客户端client = new RestHighLevelClient(RestClient.builder(//如果是集群,则设置多个主机,注意端口是http协议的端口new HttpHost("localhost", 9200, "http")
// ,new HttpHost("localhost", 9201, "http")
// ,new HttpHost("localhost", 9202, "http")));}/*** 创建索引库-测试* @throws Exception*/@Testpublic void testCreateIndex() throws Exception{System.out.println(client);// org.elasticsearch.client.RestHighLevelClient@6c61a903}
/*** 关闭客户端连接*/@Afterpublic void close() throws IOException {client.close();}
}
1.2 创建索引库及映射
开发中,往往库和映射的操作一起完成,官网详细文档地址:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.x/_index_apis.html
这里我们主要实现库和映射的创建。查询、删除等功能大家可参考文档自己实现。
1.2.1 思路分析
按照官网给出的步骤,创建索引包括下面四个步骤:
- 创建CreateIndexRequest对象,并指定索引库名称
- 指定settings配置
- 指定mapping配置
- 发起请求,得到响应
其实仔细分析,与我们在Kibana中的Rest风格API完全一致:
PUT /hello
{"settings": {"number_of_shards": 3,"number_of_replicas": 1},"mappings": {}
}
1.2.2 设计映射规则
Java代码中设置mapping,依然与REST中一致,需要JSON风格的映射规则。因此我们先在kibana中给User实体类定义好映射规则。
谨记三个是否原则
User包括下面的字段:
-
Id:主键,在ES中是唯一标示
- type:long
-
name:姓名
- type:keyword
- 是否分词:不分词
- 是否索引:需要在姓名查询,则需要索引
- 是否存储:存储
-
age:年龄
- type:integer
- 是否分词:不分词
- 是否索引:索引
- 是否存储:存储
-
gender:性别
- type:keyword
- 是否分词:不分词
- 是否索引:索引
- 是否存储:存储
-
note:备注,用户详细信息
- type:text
- 是否分词:分词,
使用ik_max_word - 是否索引:索引
- 是否存储:存储
映射如下:
PUT /user
{"settings": {"number_of_shards": 1,"number_of_replicas": 1},"mappings": {"properties": {"id": {"type": "long"},"name":{"type": "keyword"},"age":{"type": "integer"},"gender":{"type": "keyword"},"note":{"type": "text","analyzer": "ik_max_word"}}}
}
1.2.3 代码实现
我们在上面新建的ElasticDemo类中新建单元测试,完成代码,思路就是之前分析的4步骤:
- 创建CreateIndexRequest对象,并指定索引库名称
- 指定settings配置
- 指定mapping配置
- 发起请求,得到响应
package com.it.sh.esdemo;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
private RestHighLevelClient client;
/*** 创建索引* @throws IOException*/@Testpublic void testCreateIndex() throws IOException {// 1.创建CreateIndexRequest对象,并指定索引库名称CreateIndexRequest request = new CreateIndexRequest("user");// 2.指定settings配置(可以默认)request.settings(Settings.builder().put("index.number_of_shards", 3).put("index.number_of_replicas", 1));// 3.指定mapping配置request.mapping("{\n" +" "properties": {\n" +" "id": {\n" +" "type": "long"\n" +" },\n" +" "name":{\n" +" "type": "keyword"\n" +" },\n" +" "age":{\n" +" "type": "integer"\n" +" },\n" +" "gender":{\n" +" "type": "keyword"\n" +" },\n" +" "note":{\n" +" "type": "text",\n" +" "analyzer": "ik_max_word"\n" +" }\n" +" }\n" +" }",//指定映射的内容的类型为jsonXContentType.JSON);// 4.发起请求,得到响应(同步操作)CreateIndexResponse response = client.indices().create(request, RequestOptions.DEFAULT);
//打印结果System.out.println("response = " + response.isAcknowledged());}
返回结果:
response = true
2 javaApi操作es文档操作
2.1 新增&修改文档
文档操作包括:新增文档、查询文档、修改文档、删除文档等。
CRUD官网地址:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.x/java-rest-high-supported-apis.html
新增的官网地址:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.x/java-rest-high-document-index.html
2.1.1 思路分析
根据官网文档,实现的步骤如下:
- 准备文档数据
- 创建IndexRequest对象,并指定索引库名称
- 指定新增的数据的id
- 将新增的文档数据变成JSON格式
- 将JSON数据添加到IndexRequest中
- 发起请求,得到结果
2.1.2 代码实现
新增文档:
/*** 测试插入一个文档* @throws IOException*/@Testpublic void addDocument() throws Exception{//1. 准备文档数据User user = new User(110L, "张三", 22, "0", "上海市青浦区徐金珍");//2. 创建IndexRequest对象,并指定索引库名称IndexRequest indexRequest = new IndexRequest("user");//3. 指定新增的数据的idindexRequest.id(user.getId().toString());//4. 将新增的文档数据变成JSON格式// user.setAge(null);String userJson = JSON.toJSONString(user);//5. 将JSON数据添加到IndexRequest中indexRequest.source(userJson, XContentType.JSON);//6. 发起请求,得到结果IndexResponse response = client.index(indexRequest, RequestOptions.DEFAULT);System.out.println("indexResponse= "+response.getResult());
}
结果:
indexResponse = CREATED
注意:新增的ID一致时,是执行修改操作
我们直接测试过,新增的时候如果ID存在则变成修改,我们试试,再次执行刚才的代码,可以看到结果变了:
indexResponse = UPDATED
结论:在ES中如果ID一致则执行修改操作,其实质是先删除后添加。
2.2 根据ID查询文档
官网地址:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.x/java-rest-high-document-get.html
2.2.1 思路分析
这里的查询是根据id查询,必须知道文档的id才可以。
根据官网文档,实现的步骤如下:
- 创建GetRequest 对象,并指定索引库名称、文档ID
- 发起请求,得到结果
- 从结果中得到source,是json字符串
- 将JSON反序列化为对象
2.2.2 代码实现
/*** 测试根据id查询一个文档* @throws IOException*/@Testpublic void testfindDocumentById() throws Exception{//1. 创建GetRequest 对象,并指定索引库名称、文档IDGetRequest getRequest = new GetRequest("user", "110");//2. 发起请求,得到结果GetResponse response = client.get(getRequest, RequestOptions.DEFAULT);//3. 从结果中得到source,是json字符串String sourceAsString = response.getSourceAsString();//4. 将JSON反序列化为对象User user = JSON.parseObject(sourceAsString, User.class);System.out.println(user);}
结果如下:
User(id=110, name=张三, age=null, gender=0, note=上海市青浦区徐金珍)
2.3 删除文档
官网地址:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.x/java-rest-high-document-delete.html
2.3.1 实例分析
- 创建DeleteRequest对象,指定索引库名称、文档ID
- 发起请求
2.3.2 代码实现
/*** 根据id删除文档* @throws IOException*/@Testpublic void testDeleteDocumentById() throws IOException {// 1.创建DeleteRequest对象,指定索引库名称、文档IDDeleteRequest request = new DeleteRequest("user","110");// 2.发起请求DeleteResponse deleteResponse = client.delete(request, RequestOptions.DEFAULT);
System.out.println("deleteResponse = " + deleteResponse.getResult());}
结果:
deleteResponse = DELETED
2.4 批量处理
如果我们需要把数据库中的所有用户信息都导入索引库,可以批量查询出多个用户,但是刚刚的新增文档是一次新增一个文档,这样效率太低了。
因此ElasticSearch提供了批处理的方案:BulkRequest
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.x/java-rest-high-document-bulk.html
2.4.1 批量导入脚本
# 批量导入的脚本
POST _bulk
{"index":{"_index":"user","_type":"_doc","_id":"1"}}
{"age":18,"gender":"1","id":1,"name":"Rose","note":"Rose同学在学表演11"}
{"index":{"_index":"user","_type":"_doc","_id":"2"}}
{"age":38,"gender":"1","id":2,"name":"Jack","note":"Jack同学在学JavaEE"}
{"index":{"_index":"user","_type":"_doc","_id":"3"}}
{"age":38,"gender":"1","id":2,"name":"Jack","note":"Jack同学在学JavaEE"}
{"index":{"_index":"user","_type":"_doc","_id":"4"}}
{"age":23,"gender":"0","id":3,"name":"小红","note":"小红同学在学唱歌"}
{"index":{"_index":"user","_type":"_doc","_id":"5"}}
{"age":20,"gender":"1","id":4,"name":"小明","note":"小明同学在学JavaSE"}
{"index":{"_index":"user","_type":"_doc","_id":"6"}}
{"age":33,"gender":"1","id":5,"name":"达摩","note":"达摩和尚在达摩院学唱歌"}
{"index":{"_index":"user","_type":"_doc","_id":"7"}}
{"age":24,"gender":"1","id":6,"name":"鲁班","note":"鲁班同学走在乡间小路上"}
{"index":{"_index":"user","_type":"_doc","_id":"8"}}
{"age":26,"gender":"0","id":7,"name":"孙尚香","note":"孙尚香同学想带阿斗回东吴"}
{"index":{"_index":"user","_type":"_doc","_id":"9"}}
{"age":27,"gender":"1","id":8,"name":"李白","note":"李白同学在山顶喝着酒唱着歌"}
{"index":{"_index":"user","_type":"_doc","_id":"10"}}
{"age":28,"gender":"0","id":9,"name":"甄姬","note":"甄姬同学弹奏一曲东风破"}
{"index":{"_index":"user","_type":"_doc","_id":"11"}}
{"age":27,"gender":"0","id":10,"name":"虞姬","note":"虞姬同学在和项羽谈情说爱"}
2.4.2 思路分析
A
BulkRequestcan be used to execute multiple index, update and/or delete operations using a single request.
一个BulkRequest可以在一次请求中执行多个 新增、更新、删除请求。
所以,BulkRequest就是把多个其它增、删、改请求整合,然后一起发送到ES来执行。
我们拿批量新增来举例,步骤如下:
- 从数据库查询文档数据
- 创建BulkRequest对象
- 创建多个IndexRequest对象,组织文档数据,并添加到BulkRequest中
- 发起请求
2.4.3 代码实现
/*** 大量数据批量添加* @throws IOException*/@Testpublic void testBulkAddDocumentList() throws IOException {// 1.从数据库查询文档数据//第一步:准备数据源。本案例使用List来模拟数据源。List<User> users = Arrays.asList(new User(1L, "Rose", 18, "1", "Rose同学在学表演"),new User(2L, "Jack", 38, "1", "Jack同学在学JavaEE"),new User(3L, "小红", 23, "0", "小红同学在学唱歌"),new User(4L, "小明", 20, "1", "小明同学在学JavaSE"),new User(5L, "达摩", 33, "1", "达摩和尚在达摩院学唱歌"),new User(6L, "鲁班", 24, "1", "鲁班同学走在乡间小路上"),new User(7L, "孙尚香", 26, "0", "孙尚香同学想带阿斗回东吴"),new User(8L, "李白", 27, "1", "李白同学在山顶喝着酒唱着歌"),new User(9L, "甄姬", 28, "0", "甄姬同学弹奏一曲东风破"),new User(10L, "虞姬", 27, "0", "虞姬同学在和项羽谈情说爱"));// 2.创建BulkRequest对象BulkRequest bulkRequest = new BulkRequest();// 3.创建多个IndexRequest对象,并添加到BulkRequest中for (User user : userList) {bulkRequest.add(new IndexRequest("user").id(user.getId().toString()).source(JSON.toJSONString(user), XContentType.JSON));}// 4.发起请求BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println("status: " + bulkResponse.status());}
结果如下:
status: OK
可以再Kibana中通过GET /user/_search看到查询的结果。
提示:
可以批量处理增删改:
3 javaApi操作es文档搜索
ElasticSearch的强大之处就在于它具备了完善切强大的查询功能。
搜索相关功能主要包括:
-
基本查询
-
分词查询
-
词条查询
-
范围查询
-
布尔查询
- Filter功能
-
-
source筛选
-
排序
-
分页
-
高亮
-
聚合
官方文档:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.x/java-rest-high-search.html
3.1 相关API说明
3.1.1 构建查询条件API
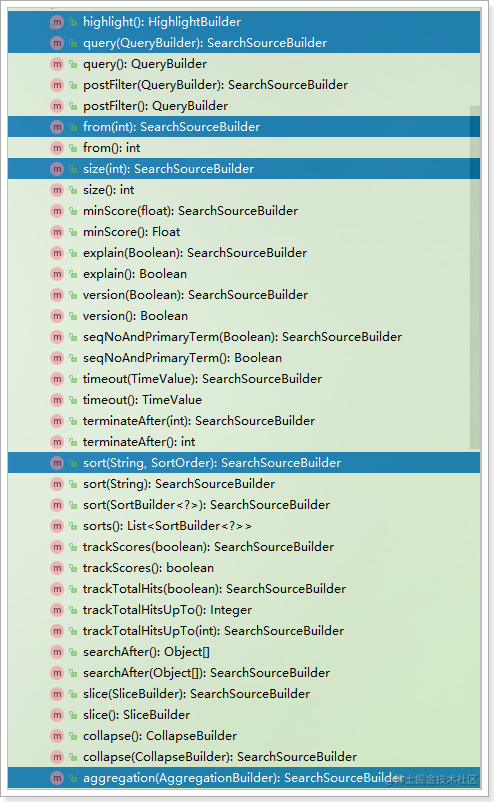
- SearchSourceBuilder
在Java客户端中,SearchSourceBuilder就是用来构建上面提到的大JSON对象,其中包含了5个方法:
- query(QueryBuilder):查询条件
- sort(String, SortOrder):排序条件
- from(int)和size(int):分页条件
- highlight(HighlightBuilder):高亮条件
- aggregation(AggregationBuilder):聚合条件
如图:
是不是与REST风格API的JSON对象一致?
接下来,再逐个来看每一个查询子属性。
- 查询条件QueryBuilders
SearchSourceBuilder的query(QueryBuilder)方法,用来构建查询条件,而查询分为:
- 分词查询:MatchQuery
- 词条查询:TermQuery
- 布尔查询:BooleanQuery
- 范围查询:RangeQuery
- 模糊查询:FuzzyQuery
- …
这些查询有一个统一的工具类来提供:QueryBuilders

3.1.2 搜索结果API
在Kibana中回顾看一下搜索结果:
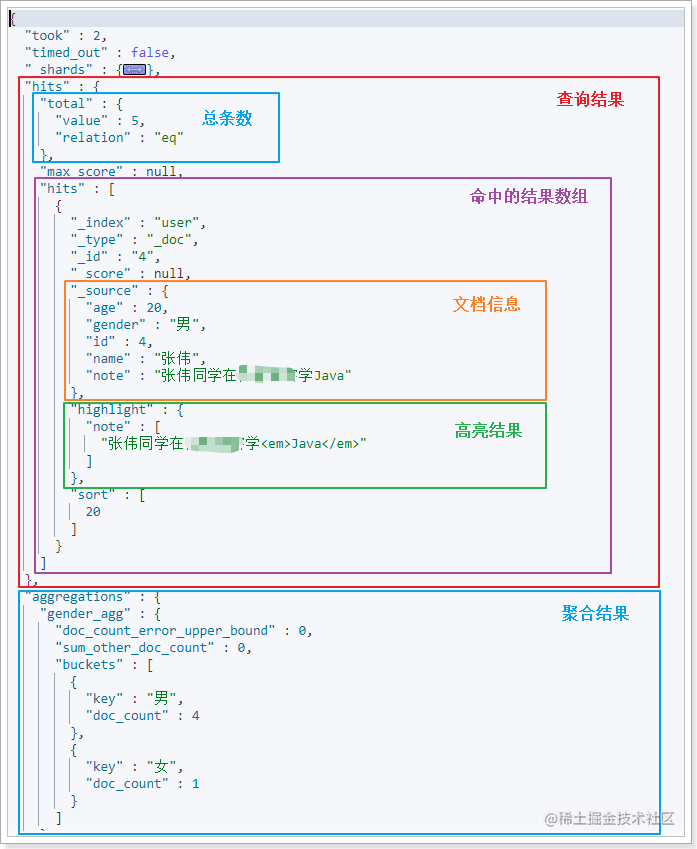
搜索得到的结果整体是一个JSON对象,包含下列2个属性:
-
hits:查询结果,其中又包含两个属性:
-
total:总命中数量
-
hits:查询到的文档数据,是一个数组,数组中的每个对象就包含一个文档结果,又包含:
- _source:文档原始信息
- highlight:高亮结果信息
-
-
aggregations:聚合结果对象,其中包含多个属性,属性名称由添加聚合时的名称来确定:
-
gender_agg:这个是我们创建聚合时用的
聚合名称,其中包含聚合结果- buckets:聚合结果数组
-
Java客户端中的SearchResponse代表整个JSON结果
- SearchResponse
Java客户端中的SearchResponse代表整个JSON结果,包含下面的方法:
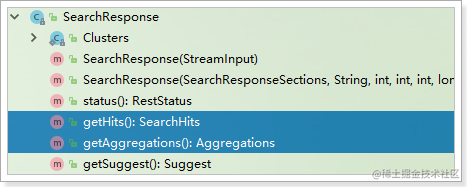
包含两个方法:
- getHits():返回的是SearchHits,代表查询结果
- getAggregations():返回的是Aggregations,代表聚合结果
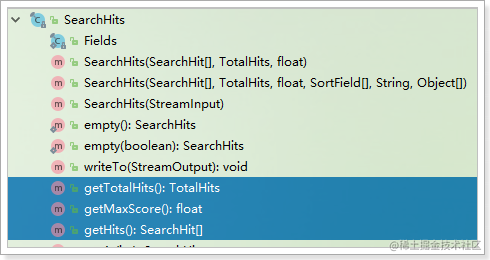
- SearchHits查询结果
SearchHits代表查询结果的JSON对象:
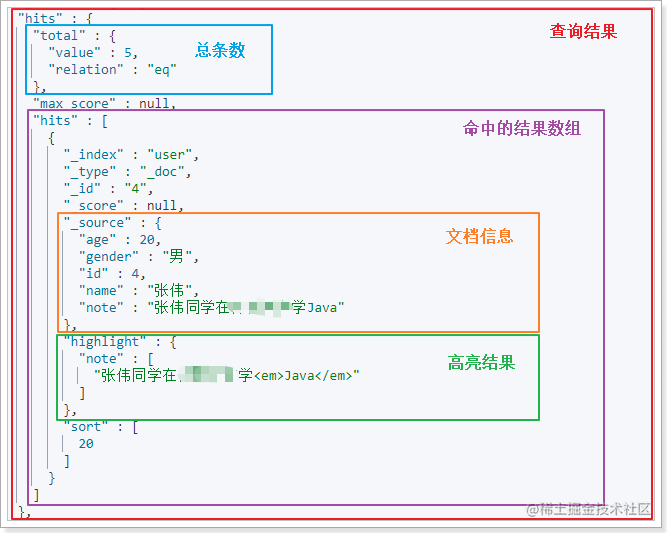
包含下面的方法:
核心方法有3个:
- getTotalHists():返回TotalHists,总命中数
- getHits():返回SearchHit数组
- getMaxScore():返回float,文档的最大得分
- SearchHit结果对象
SearchHit封装的就是结果数组中的每一个JSON对象:

包含这样的方法:
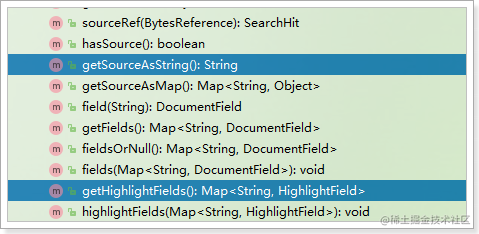
- getSourceAsString():返回的是
_source - getHighLightFields():返回是高亮结果
3.2 查询所有-matchAll
3.2.1 脚本
GET /user/_search
{"query": {"match_all": {}}
}
3.2.2 JavaAPI
3.2.2.1 思路分析
-
创建SearchSourceBuilder对象
- 添加查询条件QueryBuilders
- 如:添加排序、分页等其它条件
-
创建SearchRequest对象,并制定索引库名称
-
添加SearchSourceBuilder对象到SearchRequest对象source中
-
发起请求,得到结果
-
解析结果SearchResponse
-
获取总条数
-
获取SearchHits数组,并遍历
- 获取其中的
_source,是JSON数据 - 把
_source反序列化为User对象
- 获取其中的
-
3.2.2.2 代码实现
/*** 查询所有* @throws IOException*/@Testpublic void matchAllSearch() throws IOException {// 1.创建SearchSourceBuilder对象SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();// 1.1.添加查询条件QueryBuilders,这里选择match_all,查询所有sourceBuilder.query(QueryBuilders.matchAllQuery());// 1.2.添加排序、分页等其它条件(暂忽略)
// 2.创建SearchRequest对象,并指定索引库名称SearchRequest request = new SearchRequest("user");// 3.添加SearchSourceBuilder对象到SearchRequest对象中request.source(sourceBuilder);// 4.发起请求,得到结果SearchResponse response = client.search(request, RequestOptions.DEFAULT);// 5.解析结果SearchHits searchHits = response.getHits();// 5.1.获取总条数long total = searchHits.getTotalHits().value;System.out.println("total = " + total);// 5.2.获取SearchHit数组,并遍历SearchHit[] hits = searchHits.getHits();for (SearchHit hit : hits) {//获取分数System.out.println("文档得分:"+hit.getScore());// - 获取其中的`_source`,是JSON数据String json = hit.getSourceAsString();// - 把`_source`反序列化为User对象User user = JSON.parseObject(json, User.class);System.out.println("user = " + user);}}
3.2.2.3 测试运行

3.3 词条查询-termQuery
3.3.1 脚本
term查询和字段类型有关系,首先回顾一下ElasticSearch两个数据类型
ElasticSearch两个数据类型
- text:会分词,不支持聚合
- keyword:不会分词,将全部内容作为一个词条,支持聚合
term查询:不会对查询条件进行分词。
# 词条查询
GET /user/_search
{"query": {"term": {"name": {"value": "小红"}}}
}
3.3.2 JavaAPI
3.3.2.1 思路分析
-
创建SearchSourceBuilder对象
- 添加查询条件QueryBuilders.termQuery()
-
创建SearchRequest对象,并制定索引库名称
-
添加SearchSourceBuilder对象到SearchRequest对象source中
-
发起请求,得到结果
-
解析结果SearchResponse
-
获取总条数
-
获取SearchHits数组,并遍历
- 获取其中的
_source,是JSON数据 - 把
_source反序列化为User对象
- 获取其中的
-
3.3.2.2 代码实现
/*** 词条查询termQuery-不分词* @throws Exception*/@Testpublic void termQuery() throws Exception{//1. 创建SearchSourceBuilder对象SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();// 1. 添加查询条件QueryBuilders.termQuery()sourceBuilder.query(QueryBuilders.termQuery("name", "小红"));//2. 创建SearchRequest对象,并制定索引库名称SearchRequest request = new SearchRequest("user");//3. 添加SearchSourceBuilder对象到SearchRequest对象source中request.source(sourceBuilder);//4. 发起请求,得到结果SearchResponse response = client.search(request, RequestOptions.DEFAULT);//5. 解析结果SearchResponseSearchHits searchHits = response.getHits();// 1. 获取总条数System.out.println("总记录数:" + searchHits.getTotalHits().value);// 2. 获取SearchHits数组,并遍历for (SearchHit searchHit : searchHits) {// * 获取其中的`_source`,是JSON数据String userJson = searchHit.getSourceAsString();// * 把`_source`反序列化为User对象User user = JSON.parseObject(userJson, User.class);System.out.println(user);}}
3.3.2.3 测试运行

3.4 分词匹配查询-matchQuery
3.4.1 脚本
match查询:
- 会对查询条件进行分词。
- 然后将分词后的查询条件和词条进行等值匹配
- 默认取并集(OR)
# match查询
GET /user/_search
{"query": {"match": {"note": "唱歌 javaee"}}
}
# 查看分词效果
GET /_analyze
{"text": "唱歌 javaee","analyzer": "ik_max_word"
}
3.4.2 JavaAPI
3.4.2.1 思路分析
我们通过上面的代码发现,很多的代码都是重复的,所以我们来抽取一下通用代码。
我们只需要传递构建的条件对象即可完成查询。
3.4.2.2 代码实现
- 抽取通用方法代码
/*** 抽取通用构建查询条件执行查询方法* @throws Exception*/public void printResultByQuery(QueryBuilder queryBuilder) throws Exception{//1. 创建SearchSourceBuilder对象SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();// ************ 构建查询条件************sourceBuilder.query(queryBuilder);//2. 创建SearchRequest对象,并制定索引库名称SearchRequest request = new SearchRequest("user");//3. 添加SearchSourceBuilder对象到SearchRequest对象source中request.source(sourceBuilder);//4. 发起请求,得到结果SearchResponse response = client.search(request, RequestOptions.DEFAULT);//5. 解析结果SearchResponseSearchHits searchHits = response.getHits();// 1. 获取总条数System.out.println("总记录数:" + searchHits.getTotalHits().value);// 2. 获取SearchHits数组,并遍历for (SearchHit searchHit : searchHits) {// * 获取其中的`_source`,是JSON数据String userJson = searchHit.getSourceAsString();// * 把`_source`反序列化为User对象User user = JSON.parseObject(userJson, User.class);System.out.println(user);}}
- 基于抽取方法测试 matchQuery 匹配查询
/*** 匹配查询MatchQuery 对条件进行分词* @throws Exception*/@Testpublic void matchQuery() throws Exception{MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("note", "唱歌 javaee");printResultByQuery(queryBuilder);}
3.4.2.3 测试运行

小结:
- term query会去倒排索引中寻找确切的term,它并不知道分词器的存在。这种查询适合keyword 、numeric、date
- match query知道分词器的存在。并且理解是如何被分词的
3.5 范围&排序查询-range&sort
3.5.1 脚本
# 范围查询&排序
GET user/_search
{"query": {"range": {"age": { # 范围查询字段"gte": 22,"lt": 27}}},"sort": [ # 排序,如果是多个条件则在数组中添加排序列即可{"id": {"order": "asc"}}]
}
注意: 不能使用分词的字段排序
3.5.2 JavaAPI
3.5.2.1 思路分析
- 构建范围查询对象 QueryBuilders.rangeQuery
- 在
sourceBuilder添加排序条件(排序是对结果的重组,对条件不产生影响)
3.5.2.2 代码实现
- 编写测试方法
/*** 条件查询 + 排序* @throws Exception*/
@Test
public void rangeQuery() throws Exception{RangeQueryBuilder queryBuilder = QueryBuilders.rangeQuery("age");// 22 <= age < 27queryBuilder.gte(22);queryBuilder.lt(27);printResultByQuery(queryBuilder);
}
- 在printResultByQuery方法中
sourceBuilder.query(queryBuilder)后添加排序:
// ***** 添加排序
sourceBuilder.sort("id", SortOrder.DESC);
3.5.2.3 测试运行

3.6 查询所有过滤结果-boolQuery
boolQuery:对多个查询条件连接。
连接方式:
- must(and):条件必须成立
- must_not(not):条件必须不成立
- should(or):条件可以成立
- filter:条件必须成立,性能比must高。不会计算得分
得分: 即条件匹配度,匹配度越高,得分越高
3.6.1 脚本
# 查询note中包含同学
# 且性别为女的
# 年龄在20到30之间的
GET user/_search
{"query": {"bool": {"must": [{"match": {"note": "同学"}}],"filter":[ {"term": {"gender": "0"}},{"range":{"age": {"gte": 20,"lte": 30}}}]}}
}
bool查询中添加查询条件一般是一个即可,然后在后面根据结果过滤,这样效率会比较高。
3.6.2 JavaAPI
3.6.2.1 思路分析
布尔查询:boolQuery
- 查询note中包含同学 - match
- 且性别为女的 - term
- 年龄在20到30之间的 - range
must 、filter为连接方式
term、match为不同的查询方式
3.6.2.2 代码实现
/*** 匹配查询BoolQuery 布尔查询+过滤* @throws Exception*/
@Test
public void boolQuery() throws Exception{// 1.构建bool条件对象BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();// 2.构建matchQuery对象,查询备注信息`note`包含: 同学MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("note", "同学");queryBuilder.must(matchQueryBuilder);
// 3.过滤姓名`gender`性别为女:0TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("gender", "0");queryBuilder.filter(termQueryBuilder);
// 4.过滤年龄`age`在:20-30RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("age").gte(20).lte(30);queryBuilder.filter(rangeQueryBuilder);printResultByQuery(queryBuilder);
}
3.6.2.3 测试运行

3.7 分页查询-from、Size
默认情况下ES会设置size=10,查询10条记录。 通过from和size来指定分页的开始位置及每页大小。
3.7.1 脚本
# 分页查询
GET user/_search
{"query": {"bool": {"must": [{"match": {"note": "同学"}}]}},"sort": [{"id": {"order": "asc"}}], "from": 1, # 开始记录数= (page-1) * size"size": 2
}
3.7.2 JavaAPI
3.7.2.1 思路分析
- 设置bool查询match匹配
- 设置id排序
- 设置分页查询
3.7.2.2 代码实现
- 新增查询方法,设置查询条件
/*** 布尔查询 分页* @throws Exception*/@Testpublic void testBoolQueryByPage() throws Exception{// 1.构建bool条件对象BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();// 2.构建matchQuery对象,查询相信信息`note`为: 同学MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("note", "同学");queryBuilder.must(matchQueryBuilder);printResultByQuery(queryBuilder);}
- 在
printResultByQuery设置分页参数
// ***** 设置分页 from size
int page = 2; // 当前页
int size = 2; // 一页显示条数
int from = (page - 1) * size; // 每一页起始条数
sourceBuilder.from(from);
sourceBuilder.size(size);
3.7.2.3 测试运行

3.8 高亮查询-highlight
高亮是在搜索结果中把搜索关键字标记出来,因此必须使用match这样的条件搜索。
elasticsearch中实现高亮的语法比较简单:
高亮三要素:
-
pre_tags:前置标签,可以省略,默认是em
-
post_tags:后置标签,可以省略,默认是em
-
fields:需要高亮的字段
- title:这里声明title字段需要高亮,后面可以为这个字段设置特有配置,也可以空
3.8.1 脚本
GET user/_search
{"query": {"match": {"note": "同学"}},"highlight": { # 设置高亮"fields": {"note": { # 设置高亮显示的字段"pre_tags": "<font color='red'>", # 高亮显示前缀"post_tags": "</font>" # 高亮显示后缀}}}
}
结果:

3.8.2 JavaAPI
3.8.2.1 思路分析
- 创建高亮对象设置高亮三要素
- 解析高亮结果
- 封装到结果集中
3.8.2.2 代码实现
- 在
printResultByQuery创建高亮对象设置高亮三要素
// ***** 设置高亮三要素
HighlightBuilder highlight = SearchSourceBuilder.highlight();
highlight.field("note"); // 高亮显示域
highlight.preTags("<font color='red'>"); // 高亮显示前缀
highlight.postTags("</font>"); // 高亮显示后缀
sourceBuilder.highlighter(highlight);
- 在
printResultByQuery执行完成后解析结果并封装
//5. 解析结果SearchResponse
SearchHits searchHits = response.getHits();
// 1. 获取总条数
System.out.println("总记录数:" + searchHits.getTotalHits().value);
// 2. 获取SearchHits数组,并遍历
for (SearchHit searchHit : searchHits) {// 获取其中的`_source`,是JSON数据String userJson = searchHit.getSourceAsString();// 把`_source`反序列化为User对象User user = JSON.parseObject(userJson, User.class);
// ***** 解析高亮数据HighlightField highlightField = searchHit.getHighlightFields().get("note"); // get("高亮显示域名称")Text[] fragments = highlightField.getFragments();String note = StringUtils.join(fragments);// 判断如果是可以获取到数据则更新到用户对象中if (StringUtils.isNotBlank(note)) {user.setNote(note);}System.out.println(user);
}
3.9 聚合查询-aggregation
3.9.1 脚本
# 按照性别分桶 分桶后计算每个分桶的年龄平均值
GET user/_search
{"size": 0,"aggs": { "terms_by_gender":{"terms": {"field": "gender"},"aggs": {"avg_by_age": {"avg": {"field": "age"}}}}}
}
结果:
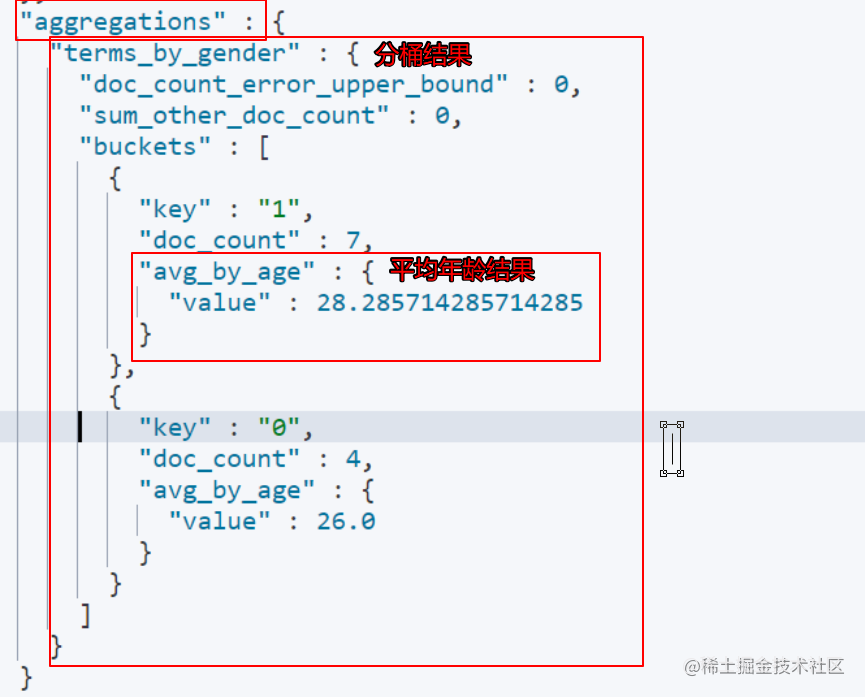
3.9.2 桶分组查询JavaAPI
1.11.2.1 思路分析
新建一个测试类ElasticSearchAggsTest,实现步骤:
- 创建SearchRequest对象,并制定索引库名称
- 创建SearchSourceBuilder对象,设置分组相关参数
- 添加SearchSourceBuilder对象到SearchRequest对象source中
- 执行查询
- 得到查询结果
- 解析分组查询数据
1.11.2.2 代码实现
/*** 文档聚合统计* @作者 it* @创建日期 2023/3/3 8:54**/
public class EsDemo05 {RestHighLevelClient client;@Testpublic void aggregations() throws IOException {//1. 创建搜索请求SearchRequest searchRequest = new SearchRequest("user");// 封装查询条件SearchSourceBuilder builder = new SearchSourceBuilder();// 通过工具类 AggregationBuilders 可以快捷的构建 聚合条件// 方法名: 聚合类型 参数1: 自定义的聚合名称TermsAggregationBuilder termsBuilder = AggregationBuilders.terms("terms_by_gender").field("gender");AvgAggregationBuilder avgBuilder = AggregationBuilders.avg("avg_by_age").field("age");// 分桶之后再求平均值termsBuilder.subAggregation(avgBuilder);builder.aggregation(termsBuilder);// 设置搜索条件内容searchRequest.source(builder);//2. 执行搜索SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);// 获取聚合结果 总的聚合结果Aggregations aggregations = searchResponse.getAggregations();// 根据自定义的聚合名称 找到对应的聚合类型处理结果// 注意: 你是什么聚合类型,用对应的聚合类型接口来接收Terms termsResult = aggregations.get("terms_by_gender");// 处理的分桶信息List<? extends Terms.Bucket> buckets = termsResult.getBuckets();for (Terms.Bucket bucket : buckets) {System.out.println("当前分桶的key==> " + bucket.getKeyAsString());System.out.println("当前分桶的文档数量==> " + bucket.getDocCount());// 获取 子聚合的总结果Aggregations subAggs = bucket.getAggregations();// 在子聚合结果中 找到对应自定名称的聚合处理结果Avg avgResult = subAggs.get("avg_by_age");System.out.println("当前分桶的平均值==>"+avgResult.getValue());}}/*** 初始化es的客户端*/@Beforepublic void init(){client = new RestHighLevelClient(RestClient.builder(new HttpHost("192.168.200.150",9200)));}
/*** 关闭客户端*/@Afterpublic void close(){try {client.close();} catch (IOException e) {e.printStackTrace();}}
}
2 ElasticSearch 集群
2.1 集群概述
单点的elasticsearch存在哪些可能出现的问题呢?
- 单台机器存储容量有限
- 单服务器容易出现单点故障,无法实现高可用
- 单服务的并发处理能力有限
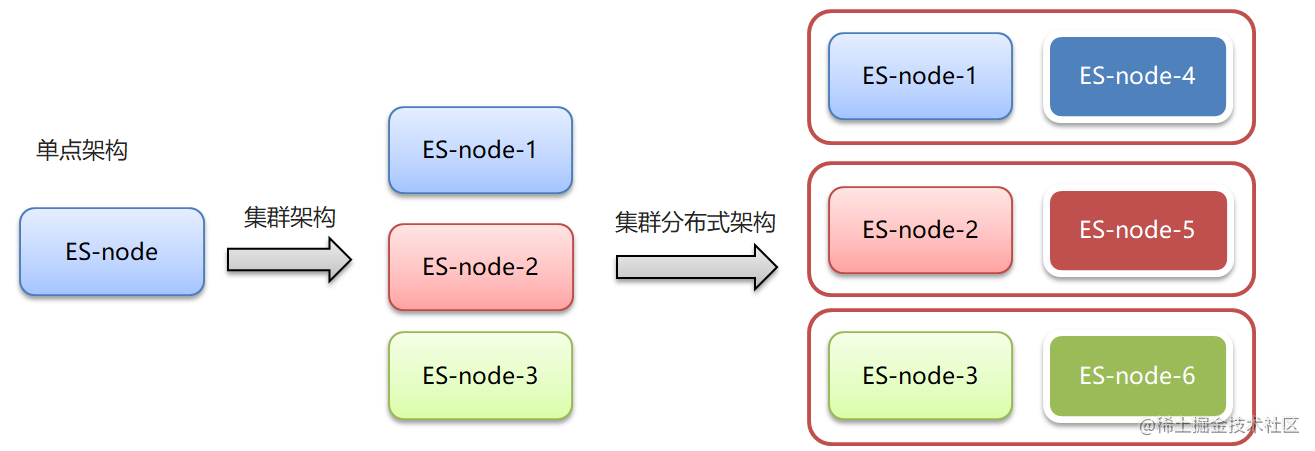
所以,为了应对这些问题,我们需要对elasticsearch搭建集群
-
集群和分布式:
- 集群:多个人做一样的事。
- 分布式:多个人做不一样的事
-
集群解决的问题:
- 让系统高可用
- 分担请求压力
-
分布式解决的问题:
- 分担存储和计算的压力,提速
- 解耦
-
集群和分布式架构往往是并存的
2.2 ES集群相关概念
es 集群:
- ElasticSearch 天然支持分布式
- ElasticSearch 的设计隐藏了分布式本身的复杂性
ES集群相关概念:
-
集群(cluster):一组拥有共同的 cluster name 的 节点。
-
节点(node) :集群中的一个 Elasticearch 实例
-
索引(index) :es存储数据的地方。相当于关系数据库中的database概念
-
分片(shard) :索引可以被拆分为不同的部分进行存储,称为分片。在集群环境下,一个索引的不同分片可以拆分到不同的节点中
解决问题:数据量太大,单点存储量有限的问题。
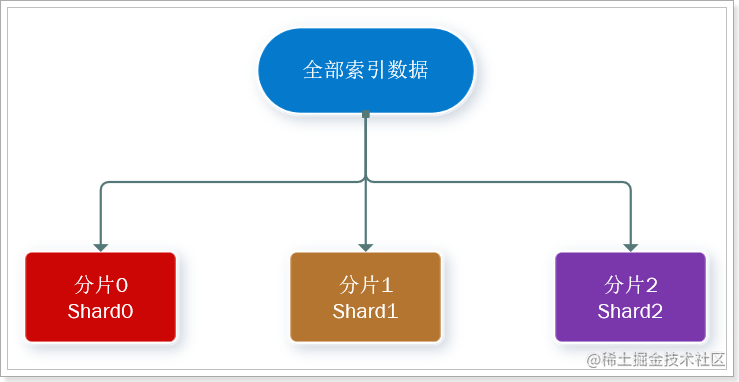
> 此处,我们把数据分成3片:shard0、shard1、shard2
-
主分片(Primary shard):相对于副本分片的定义。
-
副本分片(Replica shard)每个主分片可以有一个或者多个副本,数据和主分片一样。
数据备份可以保证高可用,但是每个分片备份一份,所需要的节点数量就会翻一倍,成本实在是太高了!
为了在高可用和成本间寻求平衡,我们可以这样做:
- 首先对数据分片,存储到不同节点
- 然后对每个分片进行备份,放到对方节点,完成互相备份
这样可以大大减少所需要的服务节点数量,如图,我们以3分片,每个分片备份一份为例:
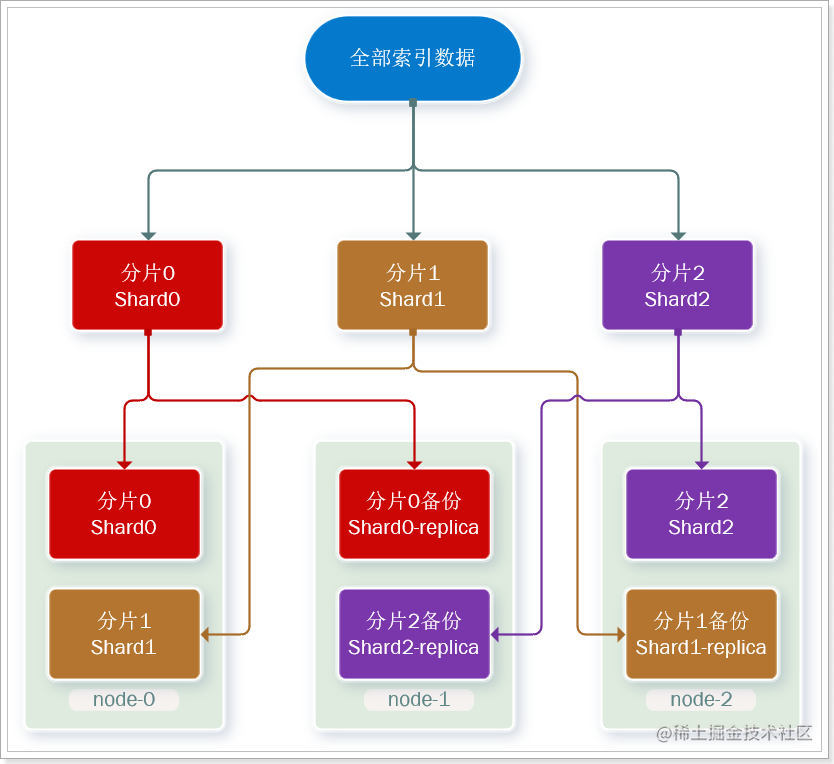
现在,每个分片都有1个备份,存储在3个节点:
- node0:保存了分片0和1
- node1:保存了分片0和2
- node2:保存了分片1和2
2.3 集群搭建
本章节基于Docker安装。
2.3.1 集群机器规划
| cluster name | node name | IP Addr | http端口 / 通信端口 |
|---|---|---|---|
| itcast-es | node1 | 192.168.200.151 | 9200 / 9700 |
| itcast-es | node2 | 192.168.200.152 | 9200 / 9700 |
| itcast-es | node3 | 192.168.200.153 | 9200 / 9700 |
2.3.2 搭建步骤
1)在三台机器上同时执行以下命令
docker run -id --name elasticsearch \-e "http.host=0.0.0.0" \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e http.cors.enabled=true \-e http.cors.allow-origin="*" \-e http.cors.allow-headers=X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization \-e http.cors.allow-credentials=true \-v es-data:/usr/share/elasticsearch/data \-v es-logs:/usr/share/elasticsearch/logs \-v es-plugins:/usr/share/elasticsearch/plugins \-v es-config:/usr/share/elasticsearch/config \--privileged \--hostname elasticsearch \-p 9200:9200 \-p 9300:9300 \-p 9700:9700 \
elasticsearch:7.4.2
2)分别在三台机器上修改elasticsearch.yml配置文件
-
配置文件位置:
1、查看目录数据卷
docker volume inspect es-config
[{"CreatedAt": "2020-11-17T14:32:14+08:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/es-config/_data","Name": "es-config","Options": null,"Scope": "local"}
]
2、进入Mountpoint对应的目录
cd /var/lib/docker/volumes/es-config/_data
3、修改每一台机器的配置文件
- node1机器
elasticsearch.yml配置
#集群名称
cluster.name: itcast-es
#节点名称
node.name: node1
#是不是有资格主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#ip地址
network.host: 0.0.0.0
network.publish_host: 192.168.200.151
#端口
http.port: 9200
#内部节点之间沟通端口
transport.tcp.port: 9700
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["192.168.200.151","192.168.200.152","192.168.200.153"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node1", "node2","node3"]
bootstrap.memory_lock: false
- node2机器
elasticsearch.yml配置
#集群名称
cluster.name: itcast-es
#节点名称
node.name: node2
#是不是有资格主节点
node.master: true
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#ip地址
network.host: 0.0.0.0
network.publish_host: 192.168.200.152
#端口
http.port: 9200
#内部节点之间沟通端口
transport.tcp.port: 9700
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["192.168.200.151","192.168.200.152","192.168.200.153"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node1", "node2","node3"]
bootstrap.memory_lock: false
- node3 机器
elasticsearch.yml配置
#集群名称
cluster.name: itcast-es
#节点名称
node.name: node3
#是不是有资格主节点
node.master: false
#是否存储数据
node.data: true
#最大集群节点数
node.max_local_storage_nodes: 3
#ip地址
network.host: 0.0.0.0
network.publish_host: 192.168.200.153
#端口
http.port: 9200
#内部节点之间沟通端口
transport.tcp.port: 9700
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["192.168.200.151","192.168.200.152","192.168.200.153"]
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node1", "node2","node3"]
bootstrap.memory_lock: false
3)分别重启三台es机器
docker restart elasticsearch
# 注意:重启之前把 data和logs文件夹清空
4)访问http://192.168.200.151:9200/_cat/health?v 查看集群状态

健康状况结果解释: cluster: 集群名称 status: 集群状态 #green代表健康;#yellow代表分配了所有主分片,但至少缺少一个副本,此时集群数据仍旧完整;#red 代表部分主分片不可用,可能已经丢失数据。 node.total: 代表在线的节点总数量 node.data: 代表在线的数据节点的数量 shards: 存活的分片数量 pri: 存活的主分片数量 正常情况下 shards的数量是pri的两倍。 relo: 迁移中的分片数量,正常情况为 0 init: 初始化中的分片数量 正常情况为 0 unassign: 未分配的分片 正常情况为 0 pending_tasks: 准备中的任务,任务指迁移分片等 正常情况为 0 max_task_wait_time: 任务最长等待时间 active_shards_percent: 正常分片百分比 正常情况为 100%
可以访问:http://192.168.200.153:9200/_cat/nodes?v&pretty 查看集群
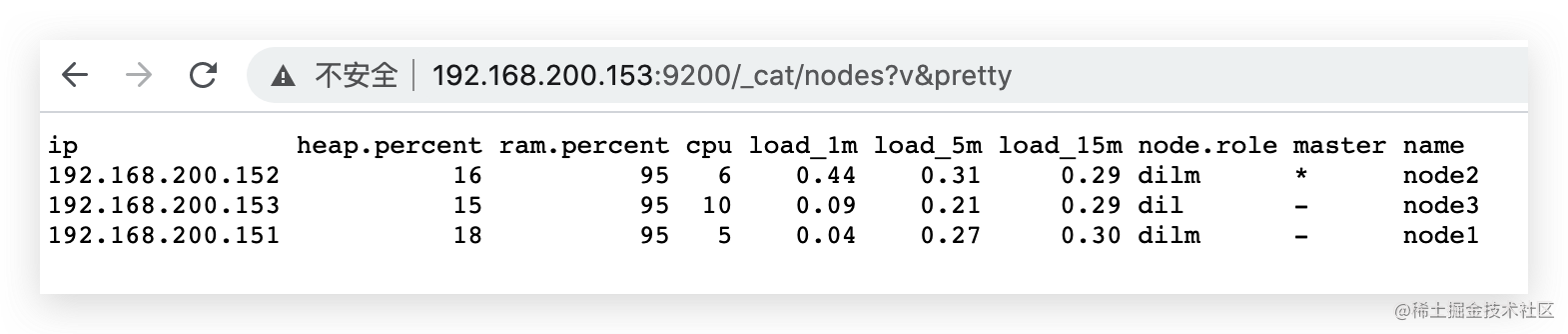
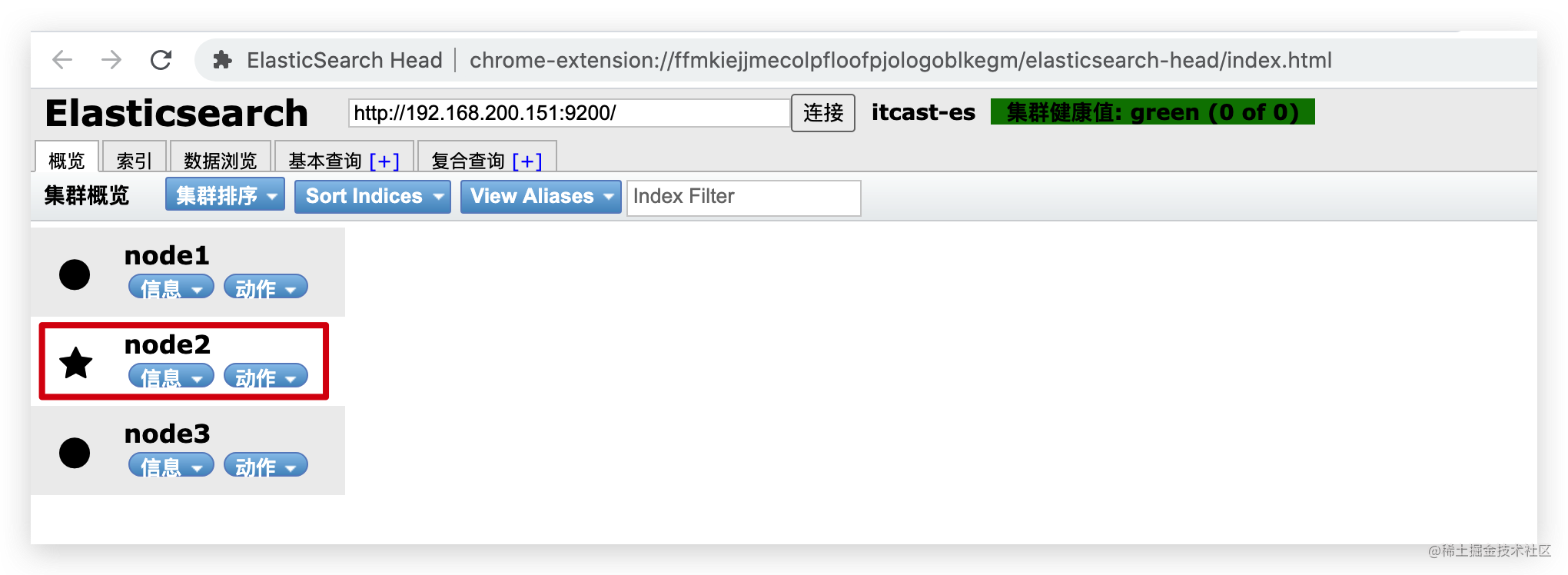
2.4 kibina管理集群
Docker 执行下方命令:
docker run -di --name kibana \
-p 5601:5601 \
-v kibana-config:/usr/share/kibana/config \
kibana:7.4.2
kibana.yml 其他配置:
#支持中文
i18n.locale: "zh-CN"
#5602避免与之前的冲突
server.port: 5601
server.host: "0.0.0.0"
server.name: "kibana-itcast-cluster"
elasticsearch.hosts: ["http://192.168.200.151:9200","http://192.168.200.152:9200","http://192.168.200.153:9200"]
elasticsearch.requestTimeout: 99999
浏览器访问:http://192.168.200.151:5601/app/monitoring#/no-data?_g=()
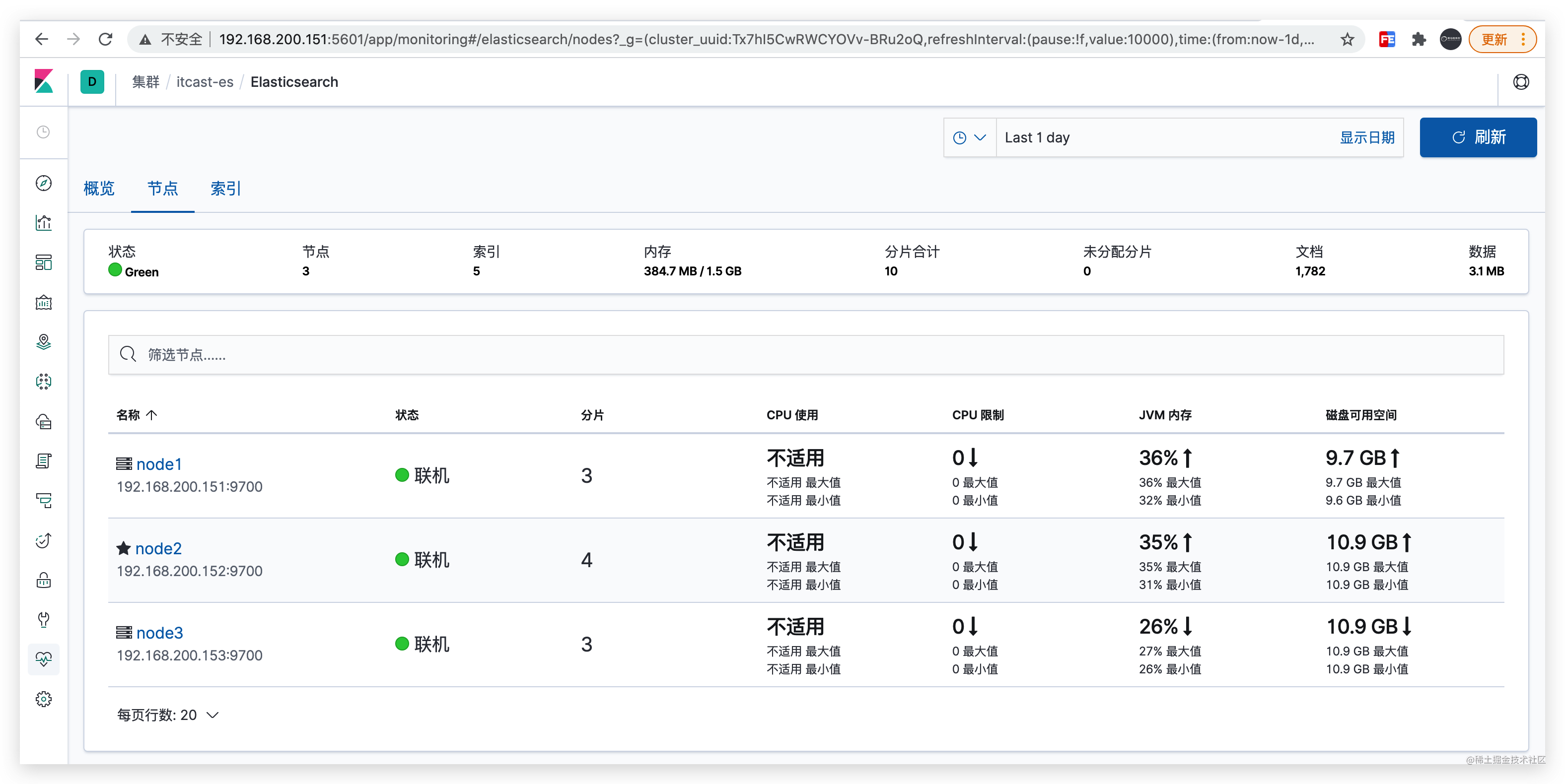
2.5 JavaAPI 访问集群
//客户端对象private RestHighLevelClient client;/*** 建立连接*/@Beforepublic void init() throws IOException {//创建Rest客户端client = new RestHighLevelClient(RestClient.builder(//如果是集群,则设置多个主机,注意端口是http协议的端口new HttpHost("192.168.200.151", 9200, "http"),new HttpHost("192.168.200.152", 9200, "http"),new HttpHost("192.168.200.153", 9200, "http")));}
/*** 创建索引库-测试* @throws Exception*/@Testpublic void testCreateIndex() throws Exception{// 1 创建CreateIndexRequest对象,并指定索引库名称CreateIndexRequest indexRequest = new CreateIndexRequest("user");// 2 设置指定settings配置(可以默认)indexRequest.settings(Settings.builder().put("index.number_of_shards", 3).put("index.number_of_replicas", 1));// 3 设置mappingindexRequest.mapping( "{\n" +" "properties": {\n" +" "id": {\n" +" "type": "long"\n" +" },\n" +" "name":{\n" +" "type": "keyword"\n" +" },\n" +" "age":{\n" +" "type": "integer"\n" +" },\n" +" "gender":{\n" +" "type": "keyword"\n" +" },\n" +" "note":{\n" +" "type": "text",\n" +" "analyzer": "ik_max_word"\n" +" }\n" +" }\n" +" }", XContentType.JSON);
// 4 发起请求CreateIndexResponse response = client.indices().create(indexRequest, RequestOptions.DEFAULT);System.out.println(response.isAcknowledged());}
/*** 关闭客户端连接*/@Afterpublic void close() throws IOException {client.close();}
2.6 分片配置
在创建索引时,如果不指定分片配置,则默认主分片1,副本分片1。
在创建索引时,可以通过settings设置分片
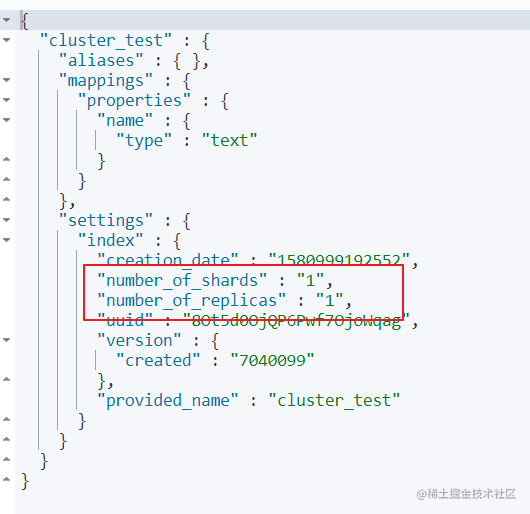
分片配置
#分片配置
#"number_of_shards": 3, 主分片数量
#"number_of_replicas": 1 主分片备份数量,每一个主分片有一个备份
# 3个主分片+3个副分片=6个分片
PUT cluster_test1
{"settings": {"number_of_shards": 3,"number_of_replicas": 1}, "mappings": {"properties": {"name":{"type": "text"}}}
}
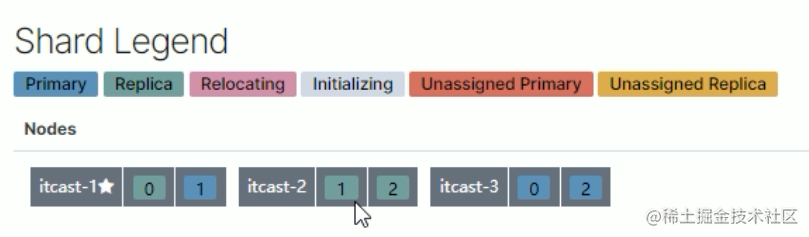
1.三个节点正常运行(0、1、2分片标号)
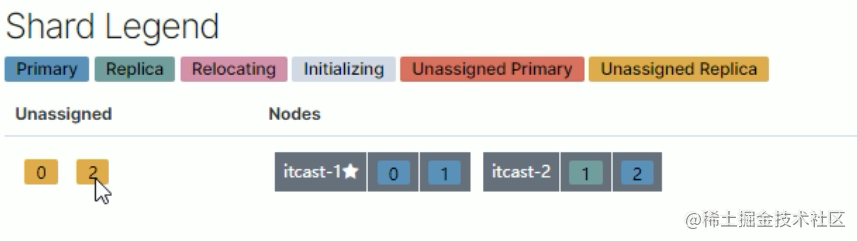
2.itcast-3 挂掉
3.将挂掉节点的分片,自平衡到其他节点
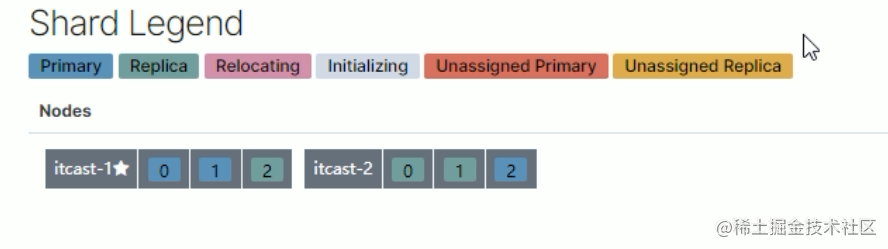
4.itcast-3 恢复正常后,节点分片将自平衡回去(并不一定是原来的分片)
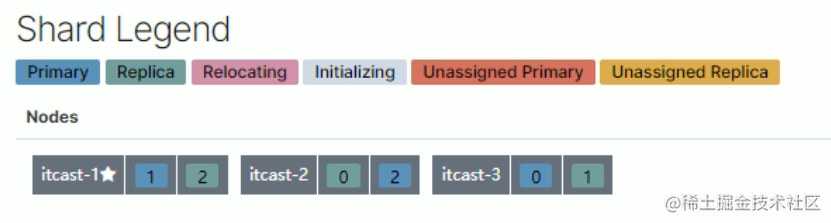
分片与自平衡
•当节点挂掉后,挂掉的节点分片会自平衡到其他节点中
注意:分片数量一旦确定好,不能修改。
索引分片推荐配置方案:
- 每个分片推荐大小10-30GB
- 分片数量推荐 = 节点数量 * 1~3倍
思考:比如有1000GB数据,应该有多少个分片?多少个节点
- 每个分片20GB 则可以分为40个分片
- 分片数量推荐 = 节点数量 * 1~3倍 --> 40/2=20 即20个节点
2.7 路由原理
路由原理
文档存入对应的分片,ES计算分片编号的过程,称为路由。
Elasticsearch 是怎么知道一个文档应该存放到哪个分片中呢?
查询时,根据文档id查询文档, Elasticsearch 又该去哪个分片中查询数据呢?
- 路由算法 :shard_index = hash(id) % number_of_primary_shards

查询id为5的文档:假如hash(5)=17 ,根据算法17%3=2
2.8 脑裂
ElasticSearch 集群正常状态:
- 一个正常es集群中只有一个主节点(Master),主节点负责管理整个集群。如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。
- 集群的所有节点都会选择同一个节点作为主节点。
脑裂现象:
- 脑裂问题的出现就是因为从节点在选择主节点上出现分歧导致一个集群出现多个主节点从而使集群分裂,使得集群处于异常状态。
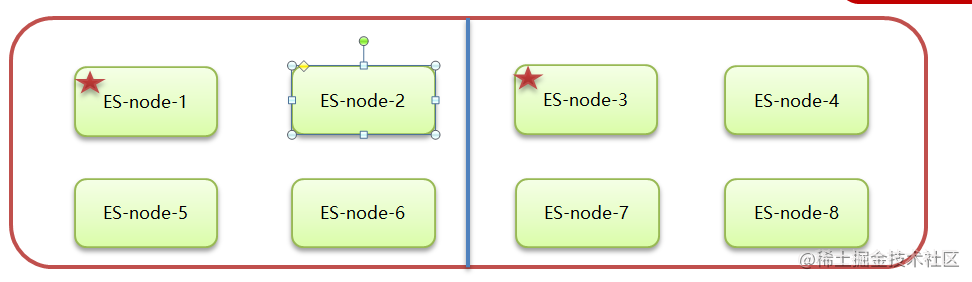
脑裂产生的原因:
-
网络原因:网络延迟
- 一般es集群会在内网部署,也可能在外网部署,比如阿里云。
- 内网一般不会出现此问题,外网的网络出现问题的可能性大些。
-
节点负载
- 主节点的角色既为master又为data。数据访问量较大时,可能会导致Master节点停止响应(假死状态)。

-
JVM内存回收
- 当Master节点设置的JVM内存较小时,引发JVM的大规模内存回收,造成ES进程失去响应。
避免脑裂:
-
网络原因:
discovery.zen.ping.timeout超时时间配置大一点。默认是3S -
节点负载:角色分离策略
-
候选主节点配置为
- node.master: true
- node.data: false
-
数据节点配置为
- node.master: false
- node.data: true
-
-
JVM内存回收:修改 config/jvm.options 文件的 -Xms 和 -Xmx 为服务器的内存一半。
相关文章:
JavaApi操作ElasticSearch(强烈推荐)
ElasticSearch 高级 1 javaApi操作es环境搭建 在elasticsearch官网中提供了各种语言的客户端:https://www.elastic.co/guide/en/elasticsearch/client/index.html 而Java的客户端就有两个: 不过Java API这个客户端(Transport Client&#…...

NFT的前景,元宇宙的发展
互联网的普及和数字技术的广泛应用,成为消费升级的新动力,在不断创造出更好的数字化生活的同时,也改变了人们的消费习惯、消费内容、消费模式,甚至是消费理念,数字经济时代的文化消费呈现出新的特征。 2020年有关机构工…...

C#基础教程20 预处理器指令
文章目录 C#预处理指令教程简介预处理指令格式指令名 参数预处理指令类型条件编译指令if#if 条件表达式宏定义指令总结C#预处理指令教程 简介 预处理指令是在编译代码之前进行的一种处理,可以让程序员在编译前根据需要对代码进行一些修改、调整或者控制。C#语言中的预处理指令…...

【FPGA】Verilog:时序电路设计 | 二进制计数器 | 计数器 | 分频器 | 时序约束
前言:本章内容主要是演示Vivado下利用Verilog语言进行电路设计、仿真、综合和下载 示例:计数器与分频器 功能特性: 采用 Xilinx Artix-7 XC7A35T芯片 配置方式:USB-JTAG/SPI Flash 高达100MHz 的内部时钟速度 存储器&#…...

国外SEO策略指南:确保你的网站排名第一!
如果你想在谷歌等搜索引擎中获得更高的排名并吸引更多的流量和潜在客户,那么你需要了解一些国外SEO策略。 下面是一些可以帮助你提高谷歌排名的关键策略。 网站结构和内容优化 谷歌的搜索算法会考虑网站的结构和内容。 因此,你需要优化网站结构&…...

Tik Tok新手秘籍,做好五点可轻松起号
新手做TikTok需要有一个具体的规划布局,如果没有深思熟虑就上手开始的话,很有可能会导致功亏一篑,甚至是浪费时间。因此,想要做好 TikTok,就必须从最基本的运营细节开始,一步一步来,下面为大家分…...
【Linux】网络入门
🎇Linux: 博客主页:一起去看日落吗分享博主的在Linux中学习到的知识和遇到的问题博主的能力有限,出现错误希望大家不吝赐教分享给大家一句我很喜欢的话: 看似不起波澜的日复一日,一定会在某一天让你看见坚持…...
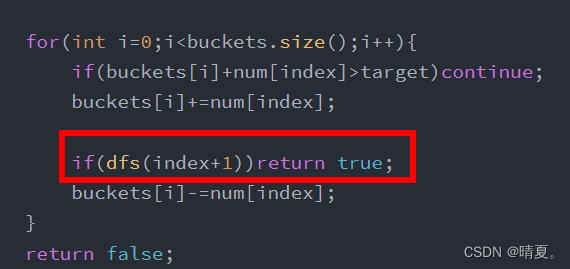
回溯法——力扣题型全解【更新中】
(本文源自网上教程的笔记) 回溯基础理论 回溯搜索法,它是一种搜索的方式。 回溯是递归的副产品,只要有递归就会有回溯。 所以以下讲解中,回溯函数也就是递归函数,指的都是一个函数。 回溯法的效率 虽然…...

【华为机试真题详解 Python实现】分奖金【2023 Q1 | 100分】
文章目录 前言题目描述输入描述输出描述示例 1题目解析参考代码前言 《华为机试真题详解》专栏含牛客网华为专栏、华为面经试题、华为OD机试真题。 如果您在准备华为的面试,期间有想了解的可以私信我,我会尽可能帮您解答,也可以给您一些建议! 本文解法非最优解(即非性能…...

netlink进行网卡重命名
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <errno.h> #include <unistd.h> #include <sys/socket.h> #include <linux/if.h> #include <linux/netlink.h>#define MAX_PAYLOAD 1024 // 最大负载长…...
-1:针对COVID-19,使用聚类方法有效提取生物特性关联进而识别预防COVID-19的药物)
2023年春【数据分析与挖掘】文献精读(一)-1:针对COVID-19,使用聚类方法有效提取生物特性关联进而识别预防COVID-19的药物
分享给大家——动漫《画江湖之不良人》第四季片尾,主人公 李星云所说的一段话: 悠悠众生,因果循环,大道至简,世间若尽是不如意事, 越是执着,便越是苦,不如安下心来,看该看的风景,做好该做之事。 初行娆疆,所悟如此, 就像曾经有一位紫衣姑娘,第一次来中原时,一样…...
用法)
【Go自学第三节】Go的范围(Range)用法
Go 语言中 range 关键字用于 for 循环中迭代数组(array)、切片(slice)、通道(channel)或集合(map)的元素。在数组和切片中它返回元素的索引和索引对应的值,在集合中返回 key-value 对。 在讲Go语言的range之前,我们先回顾下Python中range的用法 for i …...
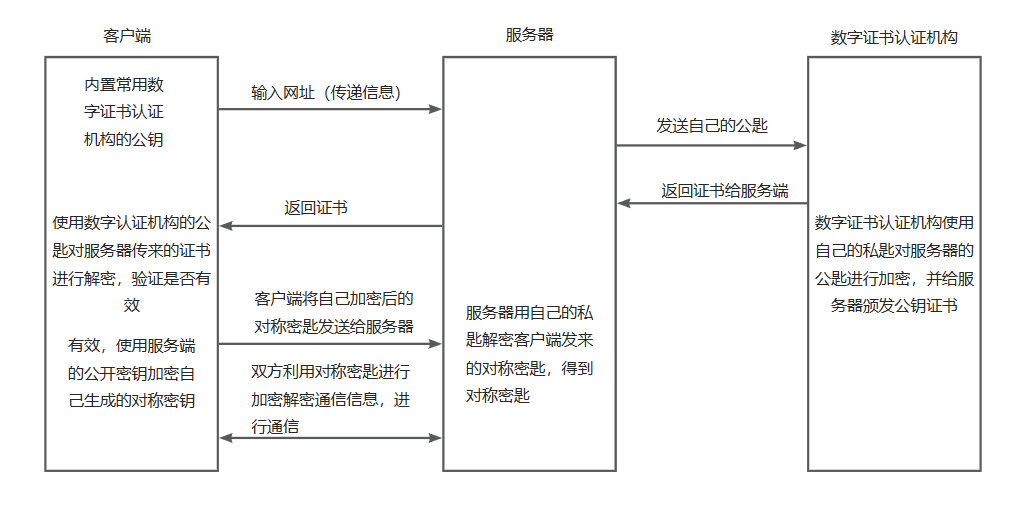
【备战面试】每日10道面试题打卡-Day6
本篇总结的是计算机网络知识相关的面试题,后续也会更新其他相关内容 文章目录1、HTTP 与 HTTPS 有哪些区别?2、HTTPS的加密过程是什么?3、GET与POST有什么区别?4、讲讲HTTP各个版本的区别?5、HTTP与FTP的区别ÿ…...

Stable Diffusion 个人推荐的各种模型及设置参数、扩展应用等合集(不断更新中)
一、说明 | 表示或者 表示 以上 二、模型 适用风景、房子、车子等漫画类风格 模型的VAE不要用模型附带的,好像就是naifu的官方vae,很老了,用 vae-ft-mse-840000-ema-pruned.ckpt 或者是 kl-f8-anime2.ckpt; 嵌入模型要下载作者…...

Salesforce 2023财年逆风增长,现金流达历史最高!
在过去的一年里,Salesforce一直是华尔街最关注的公司之一。3月1日,CRM领域的全球领导者Salesforce公布了截至2023年1月31日的第四季度和整个财年的业绩。 Salesforce主席兼首席执行官Marc Benioff表示: Salesforce全年实现了314亿美元的收入…...

2023年3月全国数据治理工程师认证DAMA-CDGA/CDGP考试怎么通过?
弘博创新是DAMA中国授权的数据治理人才培养基地,贴合市场需求定制教学体系,采用行业资深名师授课,理论与实践案例相结合,快速全面提升个人/企业数据治理专业知识与实践经验,通过考试还能获得数据专业领域证书。 DAMA认…...
【安卓软件】KMPlayer-一款完美的媒体播放器 可以播放所有格式的字幕和视频
KM PlayerKM Player是一款未编码的视频播放器,让您无需编码即可方便地播放各种格式的视频,并为您的新体验添加了字幕支持、视频播放速度和手势等功能。KMPlayer 拥有美观和直观的设计,让您可以更方便地管理和播放视频!功能高品质视…...

ClickHouse--分布式查询多副本的路由规则
前言在集群情况下,数据写入可以有写本地表和写分布式表2种方案,但是面向集群查询时,只能通过Distributed表引擎实现。本文主要介绍分布式查询多副本的路由规则。该配置项为:load_balancerandom/nearest_hostname/in_order/first_o…...

Linux 常用命令总结
本篇博客记录读研以来高频使用的 linux 系统下的命令合集 命令分类程序运行系统相关文件处理文件传输相关命令文件显示相关命令文件排列相关命令Anaconda 相关命令tmux 终端复用神器使用tips程序运行 自动保存日志,替代write命令: xxx | tee ./xxx.log…...

超分扩散模型 SR3 可以做图像去雨、去雾等恢复任务吗?
文章目录前言代码及原文链接主要的点如何进行图像恢复前言 关于扩散模型以及条件扩散模型的介绍,大家可以前往我的上一篇博客:扩散模型diffusion model用于图像恢复任务详细原理 (去雨,去雾等皆可),附实现代码。 SR3是利用扩散模…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...
)
IGP(Interior Gateway Protocol,内部网关协议)
IGP(Interior Gateway Protocol,内部网关协议) 是一种用于在一个自治系统(AS)内部传递路由信息的路由协议,主要用于在一个组织或机构的内部网络中决定数据包的最佳路径。与用于自治系统之间通信的 EGP&…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

MySQL 索引底层结构揭秘:B-Tree 与 B+Tree 的区别与应用
文章目录 一、背景知识:什么是 B-Tree 和 BTree? B-Tree(平衡多路查找树) BTree(B-Tree 的变种) 二、结构对比:一张图看懂 三、为什么 MySQL InnoDB 选择 BTree? 1. 范围查询更快 2…...

【FTP】ftp文件传输会丢包吗?批量几百个文件传输,有一些文件没有传输完整,如何解决?
FTP(File Transfer Protocol)本身是一个基于 TCP 的协议,理论上不会丢包。但 FTP 文件传输过程中仍可能出现文件不完整、丢失或损坏的情况,主要原因包括: ✅ 一、FTP传输可能“丢包”或文件不完整的原因 原因描述网络…...

前端高频面试题2:浏览器/计算机网络
本专栏相关链接 前端高频面试题1:HTML/CSS 前端高频面试题2:浏览器/计算机网络 前端高频面试题3:JavaScript 1.什么是强缓存、协商缓存? 强缓存: 当浏览器请求资源时,首先检查本地缓存是否命中。如果命…...

职坐标物联网全栈开发全流程解析
物联网全栈开发涵盖从物理设备到上层应用的完整技术链路,其核心流程可归纳为四大模块:感知层数据采集、网络层协议交互、平台层资源管理及应用层功能实现。每个模块的技术选型与实现方式直接影响系统性能与扩展性,例如传感器选型需平衡精度与…...