SIMBA方法解读
目录
- 预处理
- scRNA-seq
- scATAC-seq
- 图构建(5种场景)
- scRNA-seq分析
- scATAC-seq分析
- 多模态分析
- 批次整合
- 多模态整合
- 图学习
- SIMBA空间中查询实体
- 识别TF-target genes
预处理
scRNA-seq
过滤掉在少于三个细胞中表达的基因。原始计数按文库大小标准化,然后进行对数转换。可选地,可以执行HVG选择以删除非信息性基因并加速训练过程。在将特征输入限制为通过HVG选择确定的特征输入时,未观察到所得细胞嵌入的显著差异,但不会生成非可变基因的 SIMBA 嵌入,因为它们未在图中编码。
scATAC-seq
过滤掉少于三个细胞中的peak。或者,实施一个可扩展的基于截断 SVD 的程序来选择峰,作为初步步骤,以额外过滤非信息峰并加速训练过程。首先,选择前 k 个主成分 (PC),其中 k 的选择基于方差图。然后,对于前 k 个 PC 中的每一个,使用由“kneed”实现的拐点检测算法根据载荷自动选择peak。最后,将为每个 PC 选择的峰组合起来并表示为“变量峰”。与使用 scRNA-seq 数据的观察结果类似,变量峰选择的可选步骤对生成的细胞嵌入的影响可以忽略不计。尽管对生成的嵌入的影响微乎其微,但此特征选择步骤在减少训练过程时间方面具有显着的实际优势。
使用 JASPAR2020 中的“Biostrings”和“motifmatchr”包执行 k-mer 和motif扫描。SIMBA 的实现中包含一个方便的 R 命令行脚本“scan_for_kmers_motifs.R”,它将peak列表(格式为 bed 文件)转换为稀疏的peaks-by-k mers和peaks-by-motifs矩阵,该矩阵存储为 hdf5 格式的文件。
图构建(5种场景)
scRNA-seq分析
在构建细胞和基因graph时,如果基因在给定细胞中表达,则在细胞和基因之间添加一条边。为了区分每条边的强度,提出了一种bins方法,将基因表达值分为不同的级别,同时保留原始分布。不同级别的基因表达由不同类型的关系编码。具体来说,首先使用基于 k-means 的程序近似归一化基因表达矩阵中非零值的分布。首先,将连续的非零值分箱到 n 个区间(默认情况下,n = 5)。使用一维 k 均值聚类定义箱宽,其中每个箱中的值分配给相同的聚类中心。然后将连续矩阵转换为离散矩阵,其中 1、…、n 用于表示 n 个基因表达级别。零值保留在此矩阵中。然后,通过将两种类型的实体(细胞和基因)编码为节点,将具有 n 个不同权重的关系(即 n 个基因表达级别)编码为边来构建图。这 n 个关系权重的范围从 1.0 到 5.0,步长为 5 / n,表示基因表达水平(最低:1.0,最高:5.0),因此与高表达水平相对应的边对嵌入的影响比中等或低表达水平的边更大。正如预期的那样,观察到,随着bins数量的增加,离散化分布接近原始分布。然而,表达分辨率的增加对生成的嵌入影响不大。此离散化是在 SIMBA 包中使用函数“si.tl.discretize()”实现的。
除了关系类型权重外,SIMBA 还支持在构建图时将基因表达值直接编码为边权重。此过程会生成与分箱过程类似的嵌入。这进一步表明离散化bins在捕获生物信息方面是有效的。这种对边权重的支持是在 SIMBA 包中使用函数“si.tl.gen_graph(add_edge_weights=True)”实现的。
scATAC-seq分析
peak-by-cell矩阵被二值化:“1”表示峰内至少有一个read,否则分配“0”。该图是通过将两种类型的实体(细胞和峰)编码为节点,将它们之间的关系(表示给定峰在细胞中的存在)编码为边来构建的。单个关系类型的权重为 1.0。当 DNA 序列特征可用时,它们被使用 k-mer 和motif实体作为节点编码到图中。这是通过首先将peak-by-k mer或peak-by-motif矩阵二值化,然后使用peak、k-mer 和motif作为节点,并使用peak内这些实体的存在作为这些额外节点和峰节点之间的边来构建原始peak-by-cell图的扩展。k-mer 和峰之间的关系被分配了 0.02 的权重,而 TF 基序之间的关系被分配了 0.2 的权重。值得注意的是,根据具体的分析任务,k-mers 和motif可以彼此独立地用作图的节点输入。
多模态分析
将上述使用 scRNA-seq 和 scATAC-seq 数据构建图的策略结合起来,构建了多组学图。
批次整合
按照“scRNA-seq分析”中所述构建每个批次的图。通过基于截断随机 SVD 的程序推断不同批次细胞之间的边缘,以链接不同批次的不相交图。更具体地说,在 scRNA 序列数据的情况下,考虑两个基因表达矩阵 X 1 n 1 × m X1_{n_{1}\times m} X1n1×m和 X 2 n 2 × m X2_{n_{2}\times m} X2n2×m,其中 n 1 n_{1} n1和 n 2 n_{2} n2分别是两个批次的细胞数量, m m m是gene数量。
然后计算: X = X 1 × X 2 T X=X1\times X2^{T} X=X1×X2T随后对 X X X 执行截断随机 SVD: X = U × Σ × V T X=U\times \Sigma\times V^{T} X=U×Σ×VT其中, U U U是 n 1 × d n_{1}\times d n1×d的矩阵, Σ \Sigma Σ是 d × d d\times d d×d的矩阵, V V V是 n 2 × d n_{2}\times d n2×d的矩阵,默认 d = 20 d=20 d=20。
U U U 和 V V V 都进一步进行了 L2 归一化。对于 U U U 中的每个细胞,我们在 V V V 中搜索 k 个最近邻居,反之亦然(默认情况下,k = 20)。最终,只有 U U U 和 V V V 之间的相互最近邻居被保留为细胞之间的边(注意是推断的边)。推断不同批次细胞之间的边的过程在 SIMBA 包中的函数“si.tl.infer_edges()”中实现。
对于多个批次,SIMBA 可以灵活地推断任意一对batch-pair之间的边。然而,在实践中,边是在最大的数据集或包含最完整预期细胞类型集的数据集与其他数据集之间推断的。
多模态整合
scRNA-seq 和 scATAC-seq 图分别按照“scRNA-seq 分析”和“scATAC-seq 分析”中的步骤构建。为了推断 scRNA-seq 和 scATAC-seq 细胞之间的边,首先计算 scATAC-seq 数据的基因活性分数(gene activity score)。更具体地说,对于每个基因,考虑 TSS (转录起始位点)上游和下游 100 kb 内的peak。与基因体区域重叠或在基因体上游 5 kb 内的peak的权重为 1.0。否则,使用指数衰减函数根据peak value与 TSS 的距离对其进行加权: e x p ( − d i s t a n c e 5000 ) exp(\frac{-distance}{5000}) exp(5000−distance)。随后,将每个基因的gene score计算为所考虑峰值的加权和。然后将这些基因得分缩放到相应的基因大小。这些步骤由 SIMBA 中的函数“si.tl.gene_scores()”实现。为了方便用户,SIMBA 包整理了几个常用参考基因组的基因注释,包括 hg19、hg38、mm9 和 mm10。一旦获得基因得分,就执行“批次整合”中描述的相同程序,使用 SIMBA 中的函数“si.tl.infer_edges()”推断 scRNA-seq 和 scATAC-seq 分析的细胞之间的边。
生成图的过程在 SIMBA 包中的函数“si.tl.gen_graph()”中实现。
图学习
在构建生物实体之间的多关系图之后,作者采用了知识图谱和推荐系统中的图嵌入技术来为这些实体构建无监督表示。
提供一个input无向图 G = ( V , E ) G=(V,E) G=(V,E),其中 V V V是一组实体(节点) E E E是一组边,在源实体 u u u 和目标实体 v v v 之间存在通用边 e = ( u , v ) e = (u, v) e=(u,v)。进一步假设每个实体都有不同的已知类型(例如,细胞或peak)。
图嵌入方法通过随机梯度下降优化edge预测目标,为每个 v ∈ V v ∈ V v∈V 学习一个 D D D 维嵌入向量,其中实验中使用 D = 50 D = 50 D=50。实体 v v v的embedding记为 θ v \theta_{v} θv。
对于edge e = ( u , v ) e=(u,v) e=(u,v),记 s e = θ u ⋅ θ v s_{e}=\theta_{u}\cdot\theta_{v} se=θu⋅θv为 e e e的得分,损失为: L e = − l o g e x p ( s e ) ∑ e ′ ∈ N e x p ( s e ′ ) w e L_{e}=-log\frac{exp(s_{e})}{\sum_{e'\in N}exp(s_{e'})}w_{e} Le=−log∑e′∈Nexp(se′)exp(se)we其中, N N N是通过破坏 e e e 生成的一组“负样本”候选边, w e w_e we 是边权重,默认情况下是关系权重,但在每种关系类型中可能因边而异。例如,细胞和基因之间的边可以编码为具有不同边权重的单一关系,这些边权重编码标准化的基因表达水平(见“scRNA-seq分析”)。
通过将目标边 e = ( u , v ) e = (u, v) e=(u,v) 中的源实体或目标实体替换为随机采样的实体来构建负样本。因此,例如,对于cell-peak的边,仅对cell和peak实体之间的负候选样本进行采样。这种设置至关重要,因为大多数随机选择的边是无效的(例如,峰-峰)。
使用了 PyTorch-BigGraph 框架,该框架可以高效计算多种实体类型的多关系图嵌入,并且可以扩展到包含数百万或数十亿个实体的图。对于 130 万个细胞,PyTorch-BigGraph 训练本身仅需大约 1.5 小时,使用 12 个 CPU 核心,无需 GPU。
SIMBA空间中查询实体
信息丰富的 SIMBA 嵌入空间可用作实体(包括细胞和特征)的数据库。为了在“SIMBA 数据库”中查询给定细胞或特征的邻近实体,我们首先根据其 SIMBA 嵌入构建所有实体的 k-d 树。然后,使用欧几里得距离在树中搜索最近的邻居。为此,SIMBA 查询可以在指定半径内执行 k 最近邻居 (KNN) 或最近邻居搜索。SIMBA 还提供了将搜索限制为某些类型实体的选项,当某种类型的实体数量远远超过其他实体时,这很有用。例如,给定细胞的 k 个最近特征可能都是峰值,而基因是感兴趣的特征。在这种情况下,SIMBA 允许用户添加“过滤器”以确保在指定类型的实体内执行最近邻居搜索。此过程在函数“st.tl.query()”中实现,其可视化在 SIMBA 包中的函数“st.pl.query()”中实现。
识别TF-target genes
为了推断给定主调节因子的靶基因,我们假定,在共享的 SIMBA 嵌入空间中,(1)靶基因靠近 TF 基序和 TF 基因,表明靶基因的表达与 TF 的表达和 TF 基序的可及性高度相关,并且以细胞类型特异性的方式呈现;(2)靶基因位点附近的可及区域(峰)必须靠近 TF 基序和靶 TF 基因,表明靶基因位点附近的顺式调控元件的可及性与 TF 的表达和 TF 基序的可及性高度相关,并且以细胞类型特异性的方式呈现。
给定一个主调节因子,通过比较 SIMBA 共嵌入空间中 TF 基因、TF 基序和候选靶基因基因组位点附近的峰的位置来识别其靶基因。
更具体地说,我们首先分别搜索该主调节因子的基序(TF 基序)和基因(TF 基因)周围的 k 个最近邻基因(默认 k = 200)。这些邻居基因的并集就是初始的候选靶基因集。然后根据以下标准对这些基因进行筛选:假定靶基因 TSS 上游和下游 100 kb 内的开放区域(峰)必须包含 TF 基序。
接下来,对于每个候选靶基因,我们计算了 SIMBA 嵌入空间中的四种距离:(1) 候选靶基因与 TF 基因的嵌入之间的距离;(2) 候选靶基因与 TF 基序的嵌入之间的距离;(3) 候选靶基因与 TF 基序的基因组位点附近的峰之间的距离;以及 (4) 候选靶基因与其基因组位点附近的峰之间的距离。所有距离(默认为欧几里得距离)都转换为所有基因或所有峰之间的等级,以使距离在不同的主调节器之间具有可比性。
最终的靶基因列表由计算出的排名决定,使用两个标准:(1)TF 基因或 TF 基序最近的峰值中至少有一个在预定范围内;(2)候选靶基因的平均排名在预定范围内。此过程在 SIMBA 中的函数“st.tl. find_target_genes ()”中实现。
相关文章:
SIMBA方法解读
目录 预处理scRNA-seqscATAC-seq 图构建(5种场景)scRNA-seq分析scATAC-seq分析多模态分析批次整合多模态整合 图学习SIMBA空间中查询实体识别TF-target genes 预处理 scRNA-seq 过滤掉在少于三个细胞中表达的基因。原始计数按文库大小标准化࿰…...

VueRoute url参数
版本 4.x 获取query参数 使用$router.query,可以获取参数对应的json对象。 获取url参数 需要在路由配置中定义。使用$router.param获取。...
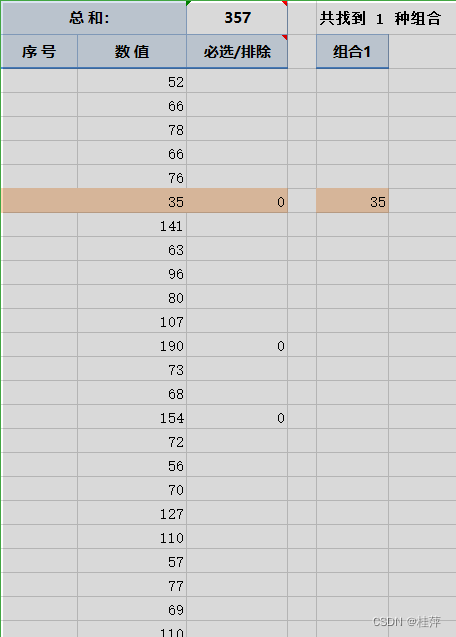
WPS表格插件方方格子【凑数】功能:选出和等于固定数字的数
文章目录 后来发现可以下载方方格子插件,使用【凑数】功能https://ffcell.lanzouj.com/iwhfc1kjhayh【凑数】快速【凑数】 导师让沾发票,需要选出若干个数额的发票,使它们的和等于一个指定数。不知道怎么办了,查了一下,…...

通过SpringCloudGateway中的GlobalFilter实现鉴权过滤
1.pom.xml中加入gateway jar包 <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency> 2.创建权限过滤器 SecurityFilter /*** 鉴权过滤***/ Slf4j Component …...

TCP/IP(网络编程)
一、网络每一层的作用 *网络接口层和物理层的作用:屏蔽硬件的差异,通过底层的驱动,会提供统一的接口,供网络层使用 *网络层的作用:实现端到端的传输 *传输层:数据应该交给哪一个任…...

网工内推 | 网络运维工程师,H3CIE认证优先,13薪,享股票期权
01 畅读 🔷招聘岗位:高级网络运维工程师 🔷职责描述: 1.负责线上业务网络技术运维工作,保障并优化线上网络质量; 2.规划并构建公司线上业务网络架构; 3.规划线上业务网络质量评估与监控体系&…...
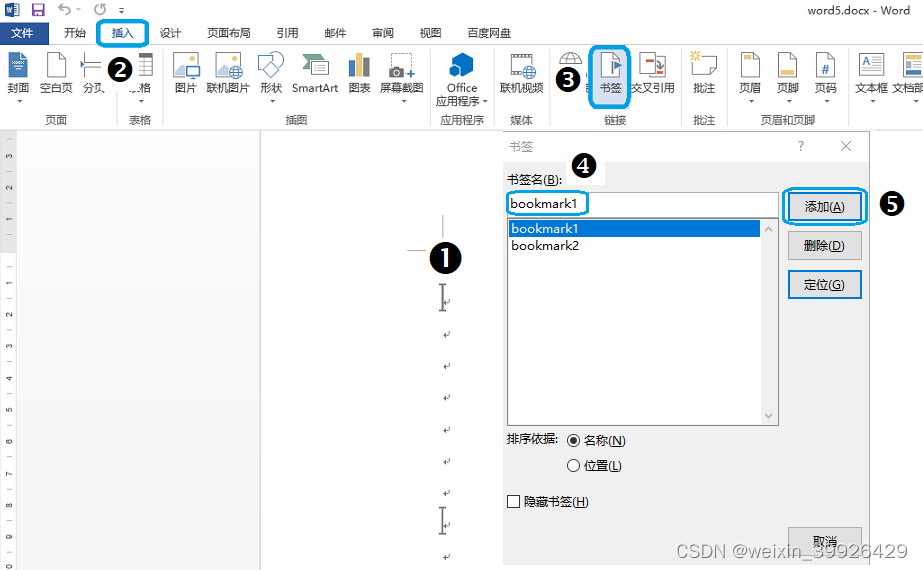
QT C++ 基于word模板 在书签位置写入文字和图片
如果你有按模版批量自动化操作word文件的需求,那么本文能给你一定的帮助。 它能满足你程序自动化生成报表的需求。常常用于上位机、测试仪器的软件中。 需要你你自己做个word模版文档,添加2个书签。点按钮,会按照你的模板文档生成一个同样的…...
)
根据word模板生成word内容(JAVA)
主要是借助 poi-tl 来实现业务需求 当时第一次尝试的是Apache poi不是很好用,不推荐 第二次是xml,找的眼睛都花了,不推荐 要求:jdk1.8,Apache POI5.2.2 我这里使用的是5.2.3版本 文档:Poi-tl Documentati…...
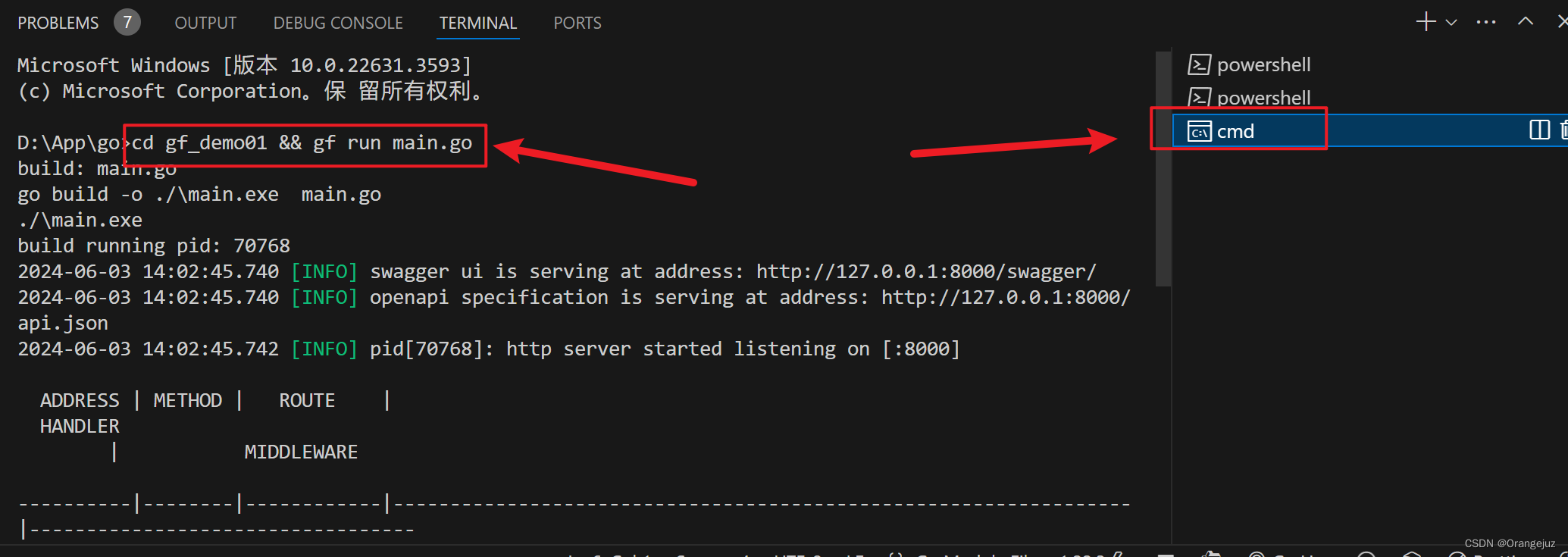
vscode运行命令报错:标记“”不是此版本中的有效语句分隔符。
1. 报错问题 标记“&&”不是此版本中的有效语句分隔符。 2. 解决办法 将 terminal 中的 owershell 改成 cmd 就 ok...

搜索与图论:树的重心
搜索与图论:树的重心 题目描述参考代码 题目描述 输入样例 9 1 2 1 7 1 4 2 8 2 5 4 3 3 9 4 6输出样例 4参考代码 #include <cstring> #include <iostream> #include <algorithm>using namespace std;const int N 100010, M N * 2;int n, m…...

程序代写,代码编写
Java 项目代做,小程序,安卓,鸿蒙,VUE 程序代写 Java调试安装、项目运行、代码代做、环境配置、工具安装、代码讲解、代码调试、代码运行、代码部署、项目调试、项目部署、Java Web、Spring Boot、项目设计、前后端分离、代码报错解…...
PbootCms微信小程序官网模版/企业官网/社交电商官网/网络工作室/软件公司官网
在数字化时代,企业网站已成为吸引潜在客户、提升企业形象、和扩大品牌影响力的必备工具。因此,一个优秀的企业网站模板显得尤为重要。 企业官网的内容框架通常都包含企业形象、产品或服务类型、信息展示等部分,设计师需要借助和企业形象契合…...
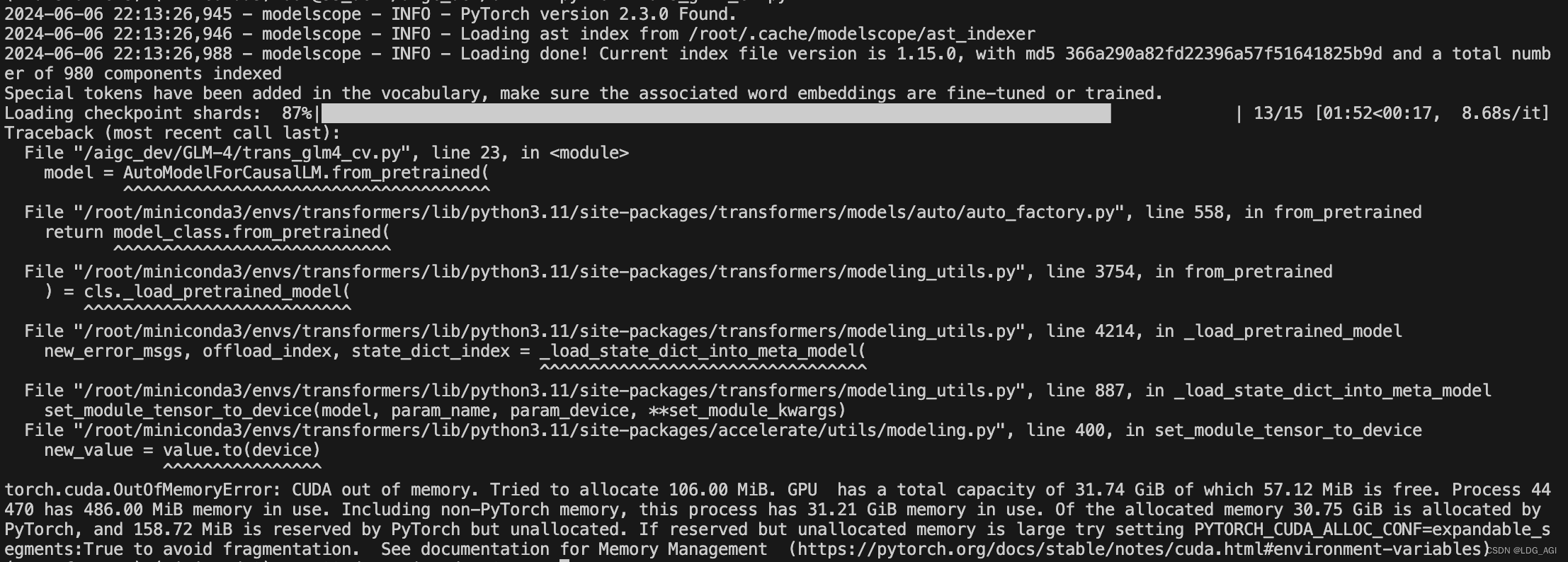
【机器学习】GLM4-9B-Chat大模型/GLM-4V-9B多模态大模型概述、原理及推理实战
目录 一、引言 二、模型简介 2.1 GLM4-9B 模型概述 2.2 GLM4-9B 模型架构 三、模型推理 3.1 GLM4-9B-Chat 语言模型 3.1.1 model.generate 3.1.2 model.chat 3.2 GLM-4V-9B 多模态模型 3.2.1 多模态模型概述 3.2.2 多模态模型实践 四、总结 一、引言…...

Kotlin 函数式接口
文章目录 定义实例化Kotlin 调用 Java 单抽象方法接口 定义 在 Kotlin 中,如果一个接口只有一个抽象方法(其他非抽象成员数量不限),可以写成类似函数的形式。 fun interface Editable {// 此处 abstract 可省略abstract fun edi…...
【数据结构】平衡二叉树(AVL树)
目录 前言 一、AVL树概念 二、AVL树节点定义 三、AVL树插入 1. 按照二叉搜索树的方式插入新节点 2. 维护节点的平衡因子与调整树的结构 a. 新节点插入较高左子树的左侧---左左:右单旋 b. 新节点插入较高右子树的右侧---右右:左单旋 c. 新节点插入…...
python数据文件处理库-pandas
内容目录 一、pandas介绍二、数据加载和写出三、数据清洗四、数据转换五、数据查询和筛选六、数据统计七、数据可视化 pandas 是一个 Python提供的快速、灵活的数据结构处理包,让“关系型”或“标记型”数据的交互既简单又直观。 官网地址: https://pandas.pydata.o…...

stm32 h5 串口采用DMA循环BUFF接收数据
当使用STM32H5系列的MCU进行串口(USART)通信,并希望使用DMA(Direct Memory Access)进行循环缓冲区(Circular Buffer)接收数据时,你需要进行以下配置步骤: 初始化串口&…...

海外媒体通稿:9个极具创意的旅游业媒体推广案例分享-华媒舍
如今,旅游业正迅速发展,媒体推广成为吸引游客的关键。为了更好地展示旅游目的地,许多创意而富有创新的媒体推广策略应运而生。本文将介绍九个极富创意的旅游业媒体推广案例,为广大从业者带来灵感和借鉴。 1. 视频系列:…...

接口自动化框架封装思想建立(全)
httprunner框架(上) 一、什么是Httprunner? 1.httprunner是一个面向http协议的通用测试框架,以前比较流行的是2.X版本。 2.他的思想是只需要维护yaml/json文件就可以实现接口自动化测试,性能测试,线上监…...

char [] 赋新值
在C语言中,字符数组(char [])的值可以通过多种方式进行赋值。以下是一些常见的方法: 1、直接初始化: char str[50] "Hello, World!";2、使用strcpy()函数: char str[50]; strcpy(str, "…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...

力扣-35.搜索插入位置
题目描述 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 class Solution {public int searchInsert(int[] nums, …...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...

深度剖析 DeepSeek 开源模型部署与应用:策略、权衡与未来走向
在人工智能技术呈指数级发展的当下,大模型已然成为推动各行业变革的核心驱动力。DeepSeek 开源模型以其卓越的性能和灵活的开源特性,吸引了众多企业与开发者的目光。如何高效且合理地部署与运用 DeepSeek 模型,成为释放其巨大潜力的关键所在&…...