course-nlp——6-rnn-english-numbers
本文参考自https://github.com/fastai/course-nlp。
使用 RNN 预测数字的英文单词版本
在上一课中,我们将 RNN 用作语言模型的一部分。今天,我们将深入了解 RNN 是什么以及它们如何工作。我们将使用尝试预测数字的英文单词版本的问题来实现这一点。
让我们预测这个序列中接下来应该是什么:
eight thousand one , eight thousand two , eight thousand three , eight thousand four , eight thousand five , eight thousand six , eight thousand seven , eight thousand eight , eight thousand nine , eight thousand ten , eight thousand eleven , eight thousand twelve…
Jeremy 创建了这个合成数据集,以便有更好的方法来检查事情是否正常、调试和了解发生了什么。在尝试新想法时,最好有一个较小的数据集来这样做,以便快速了解你的想法是否有前途(有关其他示例,请参阅 Imagenette 和 Imagewoof)这个英文单词数字将作为学习 RNN 的良好数据集。我们今天的任务是预测计数时接下来会出现哪个单词。
在深度学习中,有两种类型的数字
参数是学习到的数字。激活是计算出的数字(通过仿射函数和元素非线性)。
当你学习深度学习中的任何新概念时,问问自己:这是一个参数还是一个激活?
提醒自己:指出隐藏状态,从没有 for 循环的版本转到 for 循环。这是人们感到困惑的步骤。
Data
from fastai.text import *
bs=64
path = untar_data(URLs.HUMAN_NUMBERS)
path.ls()
[PosixPath('/home/racheltho/.fastai/data/human_numbers/models'),PosixPath('/home/racheltho/.fastai/data/human_numbers/valid.txt'),PosixPath('/home/racheltho/.fastai/data/human_numbers/train.txt')]
def readnums(d): return [', '.join(o.strip() for o in open(path/d).readlines())]
train.txt 为我们提供了以英文单词写出的数字序列:
train_txt = readnums('train.txt'); train_txt[0][:80]
'one, two, three, four, five, six, seven, eight, nine, ten, eleven, twelve, thirt'
valid_txt = readnums('valid.txt'); valid_txt[0][-80:]
' nine thousand nine hundred ninety eight, nine thousand nine hundred ninety nine'
train = TextList(train_txt, path=path)
valid = TextList(valid_txt, path=path)src = ItemLists(path=path, train=train, valid=valid).label_for_lm()
data = src.databunch(bs=bs)
train[0].text[:80]
'xxbos one , two , three , four , five , six , seven , eight , nine , ten , eleve'
len(data.valid_ds[0][0].data)
13017
bptt 代表时间反向传播。这告诉我们正在考虑多少历史步骤。
data.bptt, len(data.valid_dl)
(70, 3)
我们的验证集中有 3 个批次:
13017 个标记,每行文本中约有 ~70 个标记,每批次有 64 行文本。
13017/70/bs
2.905580357142857
我们将每个批次存储在单独的变量中,这样我们就可以通过这个过程更好地理解 RNN 在每个步骤中的作用:
it = iter(data.valid_dl)
x1,y1 = next(it)
x2,y2 = next(it)
x3,y3 = next(it)
it.close()
x1
tensor([[ 2, 19, 11, ..., 36, 9, 19],[ 9, 19, 11, ..., 24, 20, 9],[11, 27, 18, ..., 9, 19, 11],...,[20, 11, 20, ..., 11, 20, 10],[20, 11, 20, ..., 24, 9, 20],[20, 10, 26, ..., 20, 11, 20]], device='cuda:0')
numel() is a PyTorch method to return the number of elements in a tensor:
x1.numel()+x2.numel()+x3.numel()
13440
x1.shape, y1.shape
(torch.Size([64, 70]), torch.Size([64, 70]))
x2.shape, y2.shape
(torch.Size([64, 70]), torch.Size([64, 70]))
x3.shape, y3.shape
(torch.Size([64, 70]), torch.Size([64, 70]))
v = data.valid_ds.vocab
v.itos
['xxunk','xxpad','xxbos','xxeos','xxfld','xxmaj','xxup','xxrep','xxwrep',',','hundred','thousand','one','two','three','four','five','six','seven','eight','nine','twenty','thirty','forty','fifty','sixty','seventy','eighty','ninety','ten','eleven','twelve','thirteen','fourteen','fifteen','sixteen','seventeen','eighteen','nineteen']
x1[:,0]
tensor([ 2, 9, 11, 12, 13, 11, 10, 9, 10, 14, 19, 25, 19, 15, 16, 11, 19, 9,10, 9, 19, 25, 19, 11, 19, 11, 10, 9, 19, 20, 11, 26, 20, 23, 20, 20,24, 20, 11, 14, 11, 11, 9, 14, 9, 20, 10, 20, 35, 17, 11, 10, 9, 17,9, 20, 10, 20, 11, 20, 11, 20, 20, 20], device='cuda:0')
y1[:,0]
tensor([19, 19, 27, 10, 9, 12, 32, 19, 26, 10, 11, 15, 11, 10, 9, 15, 11, 19,26, 19, 11, 18, 11, 18, 9, 18, 21, 19, 10, 10, 20, 9, 11, 16, 11, 11,13, 11, 13, 9, 13, 14, 20, 10, 20, 11, 24, 11, 9, 9, 16, 17, 20, 10,20, 11, 24, 11, 19, 9, 19, 11, 11, 10], device='cuda:0')
v.itos[9], v.itos[11], v.itos[12], v.itos[13], v.itos[10]
(',', 'thousand', 'one', 'two', 'hundred')
v.textify(x1[0])
'xxbos eight thousand one , eight thousand two , eight thousand three , eight thousand four , eight thousand five , eight thousand six , eight thousand seven , eight thousand eight , eight thousand nine , eight thousand ten , eight thousand eleven , eight thousand twelve , eight thousand thirteen , eight thousand fourteen , eight thousand fifteen , eight thousand sixteen , eight thousand seventeen , eight'
v.textify(x1[1])
', eight thousand forty six , eight thousand forty seven , eight thousand forty eight , eight thousand forty nine , eight thousand fifty , eight thousand fifty one , eight thousand fifty two , eight thousand fifty three , eight thousand fifty four , eight thousand fifty five , eight thousand fifty six , eight thousand fifty seven , eight thousand fifty eight , eight thousand fifty nine ,'
v.textify(x2[1])
'eight thousand sixty , eight thousand sixty one , eight thousand sixty two , eight thousand sixty three , eight thousand sixty four , eight thousand sixty five , eight thousand sixty six , eight thousand sixty seven , eight thousand sixty eight , eight thousand sixty nine , eight thousand seventy , eight thousand seventy one , eight thousand seventy two , eight thousand seventy three , eight thousand'
v.textify(y1[0])
'eight thousand one , eight thousand two , eight thousand three , eight thousand four , eight thousand five , eight thousand six , eight thousand seven , eight thousand eight , eight thousand nine , eight thousand ten , eight thousand eleven , eight thousand twelve , eight thousand thirteen , eight thousand fourteen , eight thousand fifteen , eight thousand sixteen , eight thousand seventeen , eight thousand'
v.textify(x2[0])
'thousand eighteen , eight thousand nineteen , eight thousand twenty , eight thousand twenty one , eight thousand twenty two , eight thousand twenty three , eight thousand twenty four , eight thousand twenty five , eight thousand twenty six , eight thousand twenty seven , eight thousand twenty eight , eight thousand twenty nine , eight thousand thirty , eight thousand thirty one , eight thousand thirty two ,'
v.textify(x3[0])
'eight thousand thirty three , eight thousand thirty four , eight thousand thirty five , eight thousand thirty six , eight thousand thirty seven , eight thousand thirty eight , eight thousand thirty nine , eight thousand forty , eight thousand forty one , eight thousand forty two , eight thousand forty three , eight thousand forty four , eight thousand forty five , eight thousand forty six , eight'
v.textify(x1[1])
', eight thousand forty six , eight thousand forty seven , eight thousand forty eight , eight thousand forty nine , eight thousand fifty , eight thousand fifty one , eight thousand fifty two , eight thousand fifty three , eight thousand fifty four , eight thousand fifty five , eight thousand fifty six , eight thousand fifty seven , eight thousand fifty eight , eight thousand fifty nine ,'
v.textify(x2[1])
'eight thousand sixty , eight thousand sixty one , eight thousand sixty two , eight thousand sixty three , eight thousand sixty four , eight thousand sixty five , eight thousand sixty six , eight thousand sixty seven , eight thousand sixty eight , eight thousand sixty nine , eight thousand seventy , eight thousand seventy one , eight thousand seventy two , eight thousand seventy three , eight thousand'
v.textify(x3[1])
'seventy four , eight thousand seventy five , eight thousand seventy six , eight thousand seventy seven , eight thousand seventy eight , eight thousand seventy nine , eight thousand eighty , eight thousand eighty one , eight thousand eighty two , eight thousand eighty three , eight thousand eighty four , eight thousand eighty five , eight thousand eighty six , eight thousand eighty seven , eight thousand eighty'
v.textify(x3[-1])
'ninety , nine thousand nine hundred ninety one , nine thousand nine hundred ninety two , nine thousand nine hundred ninety three , nine thousand nine hundred ninety four , nine thousand nine hundred ninety five , nine thousand nine hundred ninety six , nine thousand nine hundred ninety seven , nine thousand nine hundred ninety eight , nine thousand nine hundred ninety nine xxbos eight thousand one , eight'
data.show_batch(ds_type=DatasetType.Valid)

我们将迭代地考虑一些不同的模型,构建更传统的 RNN。
单一全连接模型
data = src.databunch(bs=bs, bptt=3)
x,y = data.one_batch()
x.shape,y.shape
(torch.Size([64, 3]), torch.Size([64, 3]))
nv = len(v.itos); nv
39
nh=64
def loss4(input,target): return F.cross_entropy(input, target[:,-1])
def acc4 (input,target): return accuracy(input, target[:,-1])
x[:,0]
tensor([13, 13, 10, 9, 18, 9, 11, 11, 13, 19, 16, 23, 24, 9, 12, 9, 13, 14,15, 11, 10, 22, 15, 9, 10, 14, 11, 16, 10, 28, 11, 9, 20, 9, 15, 15,11, 18, 10, 28, 23, 24, 9, 16, 10, 16, 19, 20, 12, 10, 22, 16, 17, 17,17, 11, 24, 10, 9, 15, 16, 9, 18, 11])
Layer names:
i_h: input to hiddenh_h: hidden to hiddenh_o: hidden to outputbn: batchnorm
class Model0(nn.Module):def __init__(self):super().__init__()self.i_h = nn.Embedding(nv,nh) # green arrowself.h_h = nn.Linear(nh,nh) # brown arrowself.h_o = nn.Linear(nh,nv) # blue arrowself.bn = nn.BatchNorm1d(nh)def forward(self, x):h = self.bn(F.relu(self.i_h(x[:,0])))if x.shape[1]>1:h = h + self.i_h(x[:,1])h = self.bn(F.relu(self.h_h(h)))if x.shape[1]>2:h = h + self.i_h(x[:,2])h = self.bn(F.relu(self.h_h(h)))return self.h_o(h)
learn = Learner(data, Model0(), loss_func=loss4, metrics=acc4)
learn.fit_one_cycle(6, 1e-4)

循环也一样
让我们重构一下,使用 for 循环。它的作用和之前一样:
class Model1(nn.Module):def __init__(self):super().__init__()self.i_h = nn.Embedding(nv,nh) # green arrowself.h_h = nn.Linear(nh,nh) # brown arrowself.h_o = nn.Linear(nh,nv) # blue arrowself.bn = nn.BatchNorm1d(nh)def forward(self, x):h = torch.zeros(x.shape[0], nh).to(device=x.device)for i in range(x.shape[1]):h = h + self.i_h(x[:,i])h = self.bn(F.relu(self.h_h(h)))return self.h_o(h)
这是展开的 RNN 图(我们之前的 RNN 图)和卷起的 RNN 图(我们现在的 RNN 图)之间的区别:
learn = Learner(data, Model1(), loss_func=loss4, metrics=acc4)
learn.fit_one_cycle(6, 1e-4)
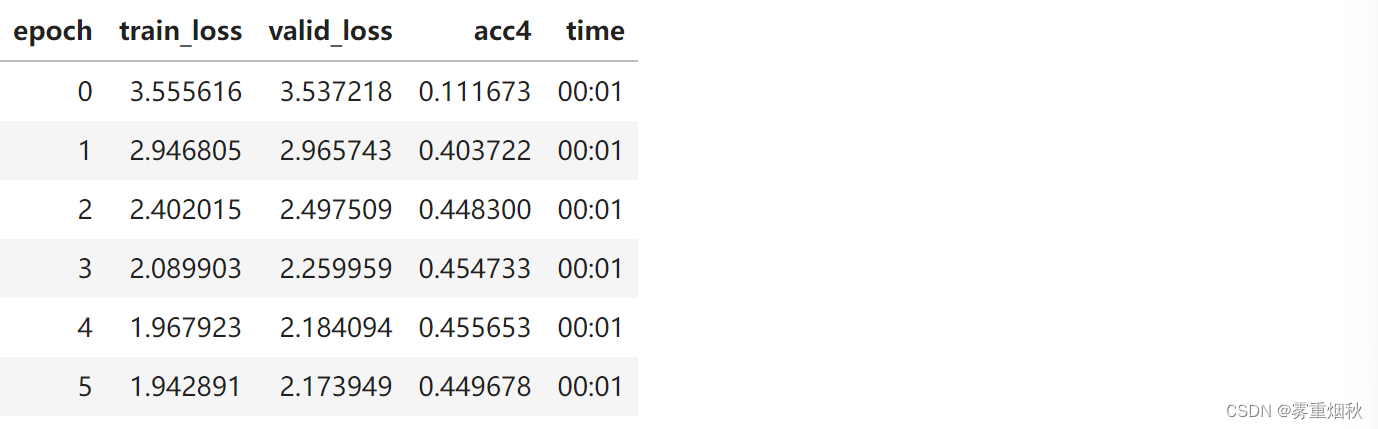
我们的准确性大致相同,因为我们做的事情与以前相同。
多重全连接模型
之前,我们只是预测一行文本中的最后一个单词。给定 70 个标记,标记 71 是什么?这种方法会丢弃大量数据。为什么不根据标记 1 预测标记 2,然后预测标记 3,然后预测标记 4,依此类推?我们将修改模型来做到这一点。
data = src.databunch(bs=bs, bptt=20)
x,y = data.one_batch()
x.shape,y.shape
(torch.Size([64, 20]), torch.Size([64, 20]))
class Model2(nn.Module):def __init__(self):super().__init__()self.i_h = nn.Embedding(nv,nh)self.h_h = nn.Linear(nh,nh)self.h_o = nn.Linear(nh,nv)self.bn = nn.BatchNorm1d(nh)def forward(self, x):h = torch.zeros(x.shape[0], nh).to(device=x.device)res = []for i in range(x.shape[1]):h = h + self.i_h(x[:,i])h = F.relu(self.h_h(h))res.append(self.h_o(self.bn(h)))return torch.stack(res, dim=1)
learn = Learner(data, Model2(), metrics=accuracy)
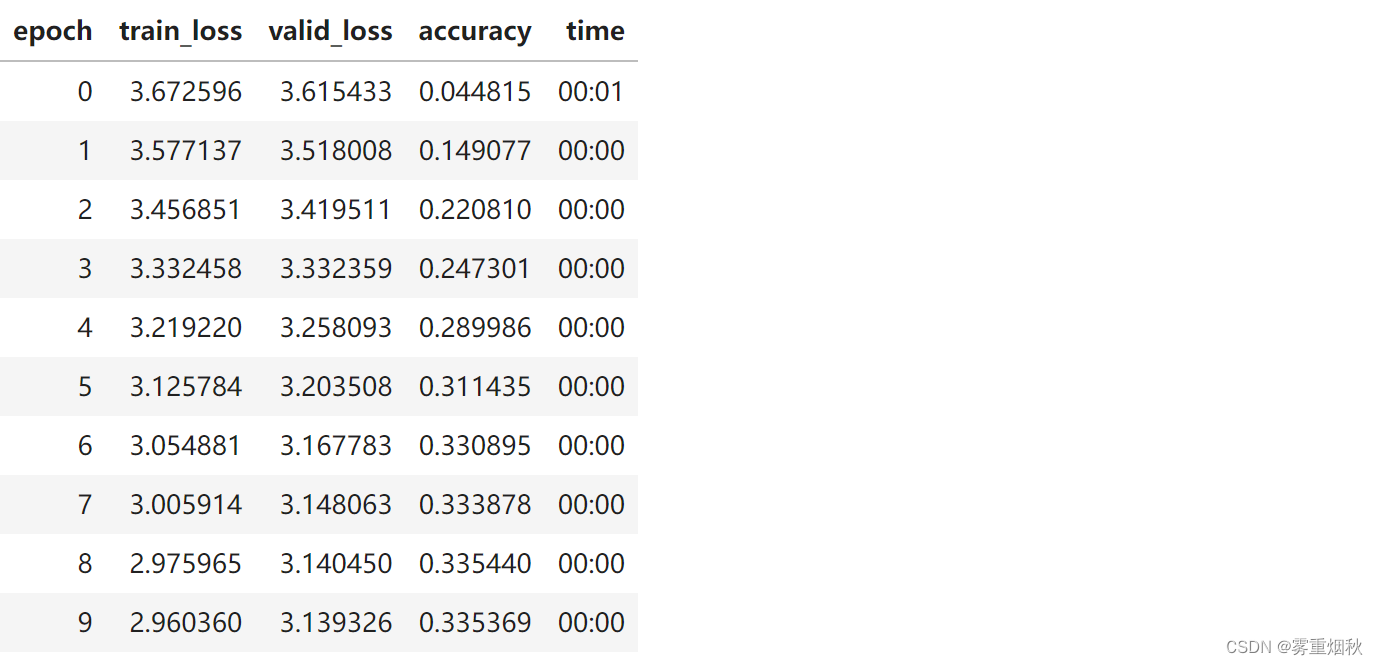
请注意,我们的准确率现在变差了,因为我们在做一项更艰巨的任务。当我们预测单词 k(k<70)时,我们能获得的历史记录比我们仅预测单词 71 时要少。(Model2每次forward调用时都重新初始化h)
维持状态
为了解决这个问题,让我们保留上一行文本的隐藏状态,这样我们就不会在每一行新文本上重新开始。
class Model3(nn.Module):def __init__(self):super().__init__()self.i_h = nn.Embedding(nv,nh)self.h_h = nn.Linear(nh,nh)self.h_o = nn.Linear(nh,nv)self.bn = nn.BatchNorm1d(nh)self.h = torch.zeros(bs, nh).cuda()def forward(self, x):res = []h = self.hfor i in range(x.shape[1]):h = h + self.i_h(x[:,i])h = F.relu(self.h_h(h))res.append(self.bn(h))self.h = h.detach()res = torch.stack(res, dim=1)res = self.h_o(res)return res
learn = Learner(data, Model3(), metrics=accuracy)
earn.fit_one_cycle(20, 3e-3)
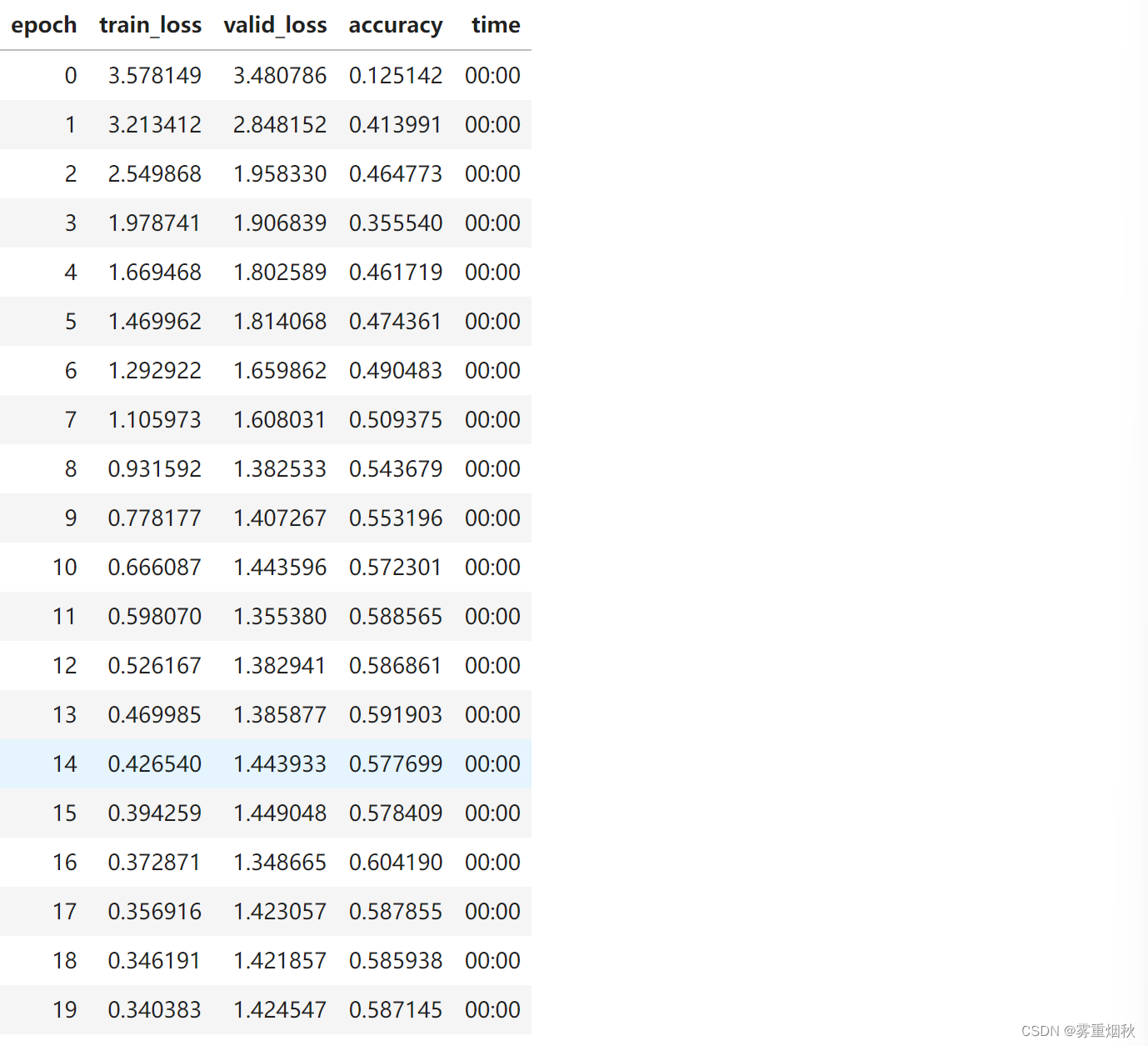
现在我们获得的准确性比以前更高了!(h.detach()防止累积梯度回传)
nn.RNN
class Model4(nn.Module):def __init__(self):super().__init__()self.i_h = nn.Embedding(nv,nh)self.rnn = nn.RNN(nh,nh, batch_first=True)self.h_o = nn.Linear(nh,nv)self.bn = BatchNorm1dFlat(nh)self.h = torch.zeros(1, bs, nh).cuda()def forward(self, x):res,h = self.rnn(self.i_h(x), self.h)self.h = h.detach()return self.h_o(self.bn(res))
learn = Learner(data, Model4(), metrics=accuracy)
learn.fit_one_cycle(20, 3e-3)

2-layer GRU
当你拥有较长的时间尺度和较深的网络时,这些就变得无法训练。解决这个问题的一种方法是添加 mini-NN 来决定保留多少绿色箭头和多少橙色箭头。这些 mini-NN 可以是 GRU 或 LSTM。我们将在后面的课程中介绍更多细节。
class Model5(nn.Module):def __init__(self):super().__init__()self.i_h = nn.Embedding(nv,nh)self.rnn = nn.GRU(nh, nh, 2, batch_first=True)self.h_o = nn.Linear(nh,nv)self.bn = BatchNorm1dFlat(nh)self.h = torch.zeros(2, bs, nh).cuda()def forward(self, x):res,h = self.rnn(self.i_h(x), self.h)self.h = h.detach()return self.h_o(self.bn(res))
learn = Learner(data, Model5(), metrics=accuracy)
learn.fit_one_cycle(10, 1e-2)
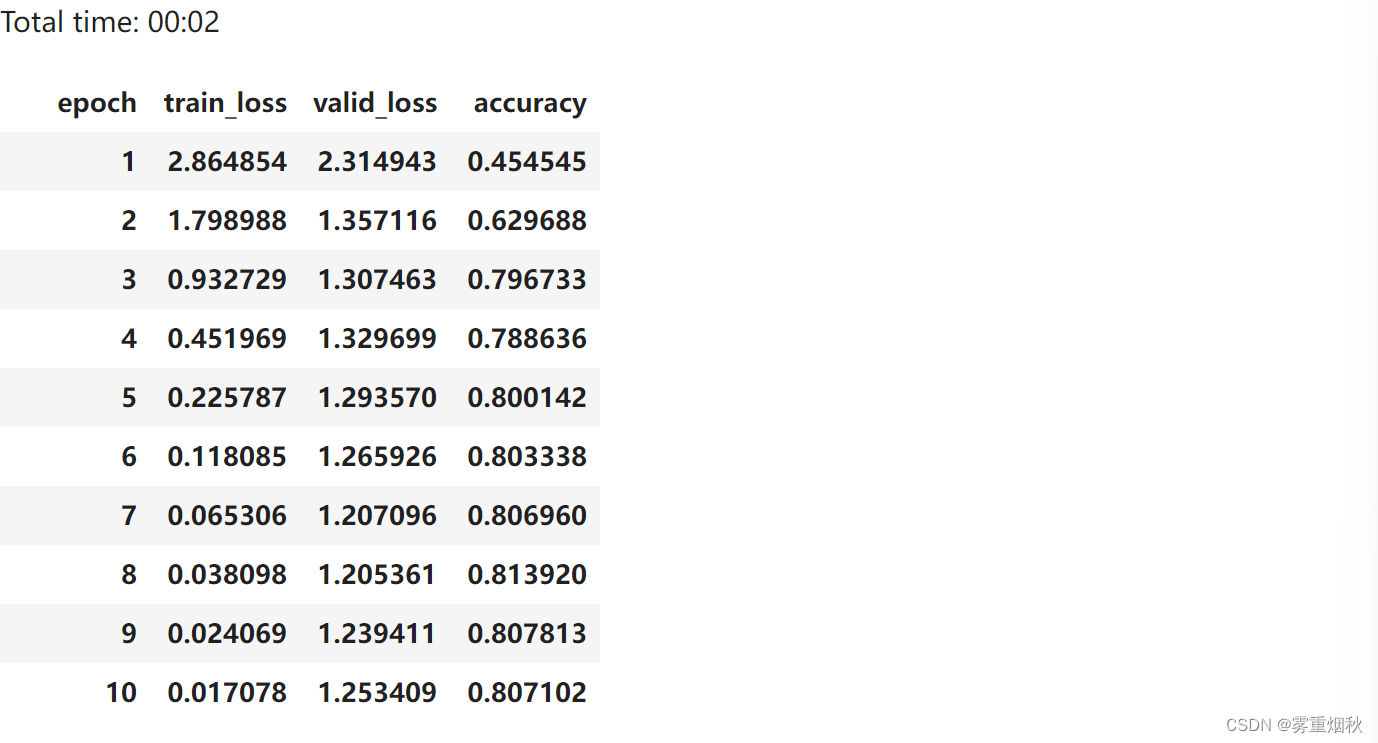
Connection to ULMFit
在上一课中,我们基本上用分类器替换了 self.h_o 来对文本进行分类。
结尾
RNN 只是一个重构的全连接神经网络。
你可以使用相同的方法处理任何序列标记任务(词性、分类材料是否敏感等)
相关文章:
course-nlp——6-rnn-english-numbers
本文参考自https://github.com/fastai/course-nlp。 使用 RNN 预测数字的英文单词版本 在上一课中,我们将 RNN 用作语言模型的一部分。今天,我们将深入了解 RNN 是什么以及它们如何工作。我们将使用尝试预测数字的英文单词版本的问题来实现这一点。 让…...

qnx 查看cpu使用
http://www.qnx.com/developers/docs/7.1/index.html#com.qnx.doc.neutrino.utilities/topic/h/hogs.html 【QNX】Hogs命令使用总结-CSDN博客 hogs hogs -S c #按照cpu排序 hogs -S m #按照内存排序 hogs -s 2 869113958 查看某一进程 hogs -% 10c 只看cpu超过…...

设备上CCD功能增加(从接线到程序)
今天终于完成了一个上面交给我的一个小项目,给设备增加一个CCD拍照功能,首先先说明一下本次使用基恩士的CCD相机,控制器,还有软件(三菱程序与基恩士程序)。如果对你有帮助,欢迎评论收藏…...

QT C++ QTableWidget 表格合并 setSpan 简单例子
这里说的合并指的是单元格,不是表头。span的意思是跨度、宽度、范围。 setSpan函数需要设定行、列、行跨几格,列跨几格。 //函数原型如下 void QTableView::setSpan(int row, i nt column, 、 int rowSpanCount,/*行跨过的格数*/ int columnSpanCount…...
Nvidia/算能 +FPGA+AI大算力边缘计算盒子:医疗健康智能服务
北京天星医疗股份有限公司(简称“天星医疗”)作为国产运动医学的领导者,致力于提供运动医学的整体临床解决方案,公司坐落于北京经济技术开发区。应用于肩关节、膝关节、足/踝关节、髋关节、肘关节、手/腕关节的运动医学设备、植入物和手术器械共计300多个…...

Oracle 误删数据后回滚
使用闪回查询 使用闪回查询,可以回滚到指定时间点的数据,可以通过系统时间(YYYY-MM-DD HH24:MI:SS)或SCN回滚数据。 SQL> select * from tableName as of timestamp(sysdate-1/24); SQL> select * from tableName as of scn(123456); 3、闪回事务或…...
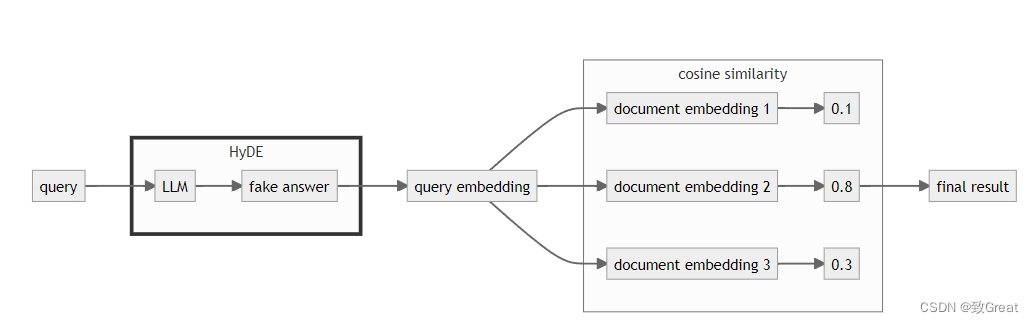
【RAG提升技巧】查询改写HyDE
简介 提高 RAG 推理能力的一个好方法是添加查询理解层 ——在实际查询向量存储之前添加查询转换。以下是四种不同的查询转换: 路由:保留初始查询,同时查明其所属的适当工具子集。然后,将这些工具指定为合适的选项。查询重写&…...

前端面试题日常练-day56 【面试题】
题目 希望这些选择题能够帮助您进行前端面试的准备,答案在文末 1. PHP中的预定义变量$_SERVER用于存储什么类型的数据? a) 用户的输入数据 b) 浏览器发送的请求信息 c) 服务器的配置信息 d) PHP脚本中定义的变量 2. 在PHP中,以下哪个函数…...

【frp】frpc客户端在ubuntu服务器上的配置
FRP简单配置内网穿透 官方仓库 ,说明比较简单 复杂一点要付费加入星球了。 而且frp还支持插件,目前还不清楚具体使用。 幸好,这位大神给出的非常详细 而且客户端与服务端都是部署在ubuntu的: 【frp】服务端配置与systemd启动 进行了frps的简单配置。 局域网内的机器是ubunt…...

构建LangChain应用程序的示例代码:20、使用LangChain的SQLDatabase包装器连接到Databricks运行时并执行查询操作教程
Databricks SQL 数据库连接 概述 这个笔记本介绍了如何使用LangChain的SQLDatabase包装器连接到Databricks运行时和Databricks SQL。 内容分为三个部分:安装和设置、连接到Databricks以及示例。 安装和设置 !pip install databricks-sql-connector # 安装Datab…...
)
PHP Standards Recommendations(PSR)
以下是 PHP Standards Recommendations(PSR)的全部内容: PSR-1:基础编码标准:规定了 PHP 代码的基本格式和要求,包括文件的编码、标签的使用、代码的组织等。PSR-2:编码风格指南:是对…...
[word] word2019中制表符的妙用 #媒体#笔记#知识分享
word2019中制表符的妙用 word2019表格功能是非常强大的,很多朋友都认为以前的制表符已经没有什么用途了,其实不然,在一切特殊的场合,word2019制表符还是非常有用的,下面就为大家介绍word2019中制表符的妙用。 步骤1、…...

太阳能航空障碍灯在航空安全发挥什么作用_鼎跃安全
随着我国经济的快速发展,空域已经成为经济发展的重要领域。航空运输、空中旅游、无人机物流、飞行汽车等经济活动为空域经济发展提供了巨大潜力。然而,空域安全作为空域经济发展的关键因素,受到了广泛关注。 随着空域经济活动的多样化和密集…...
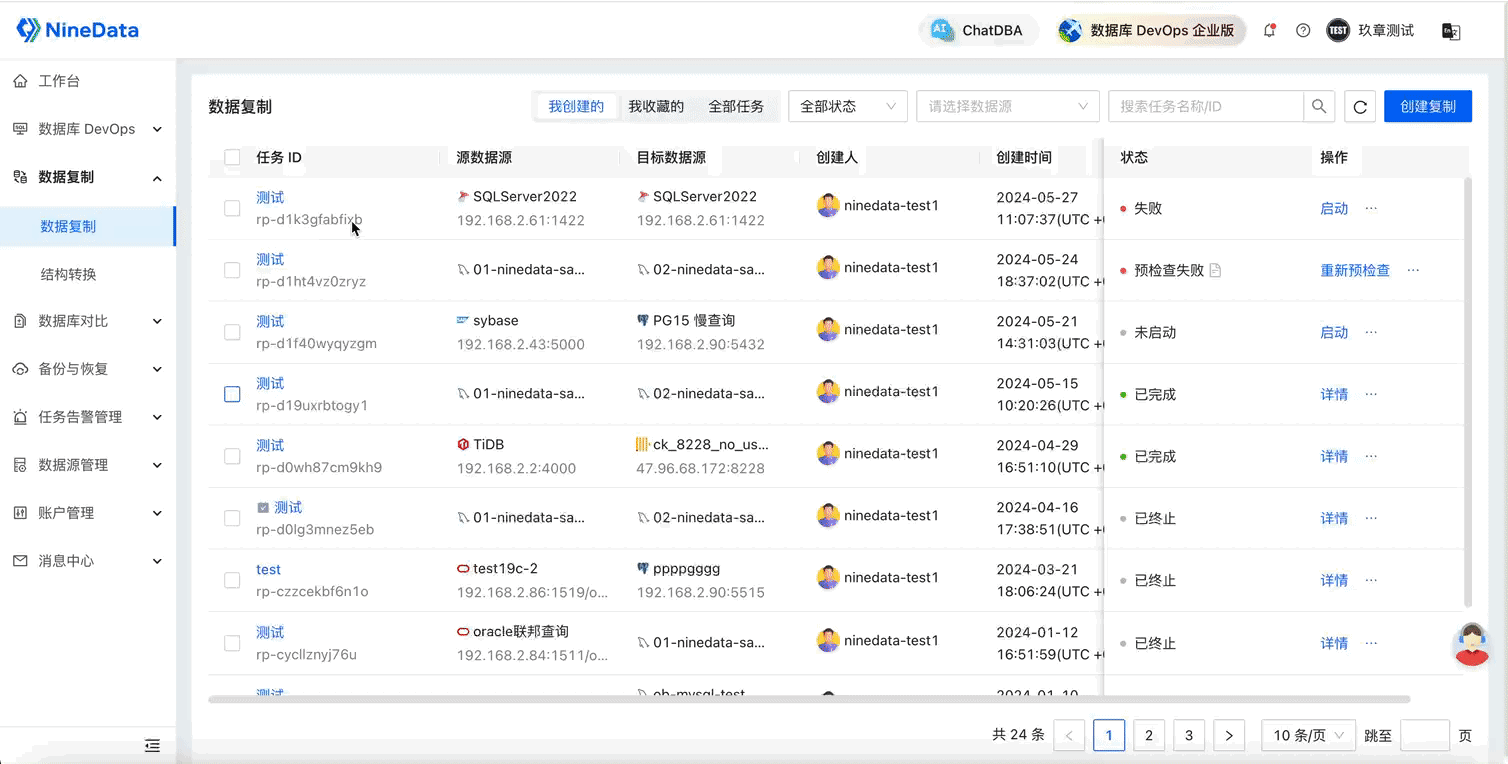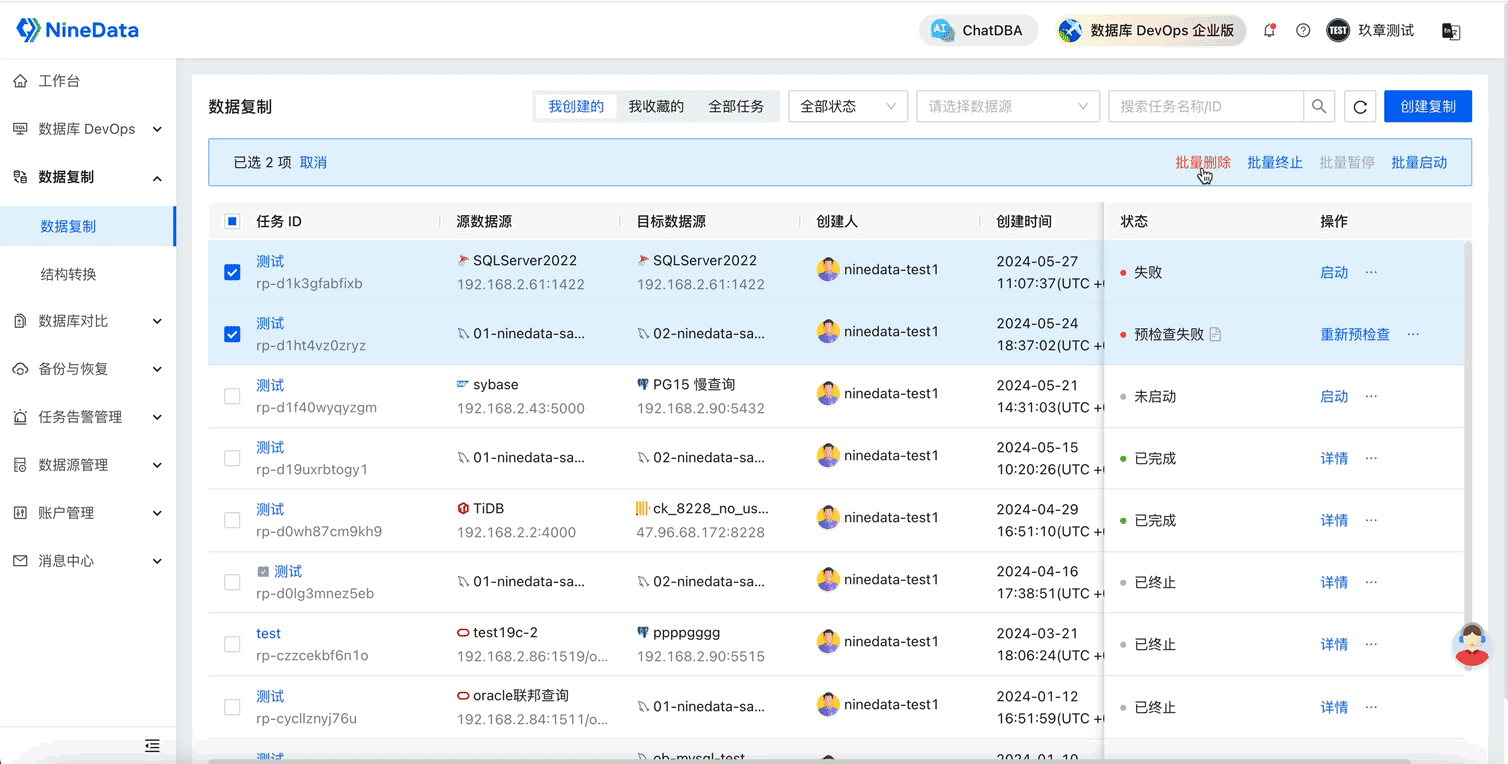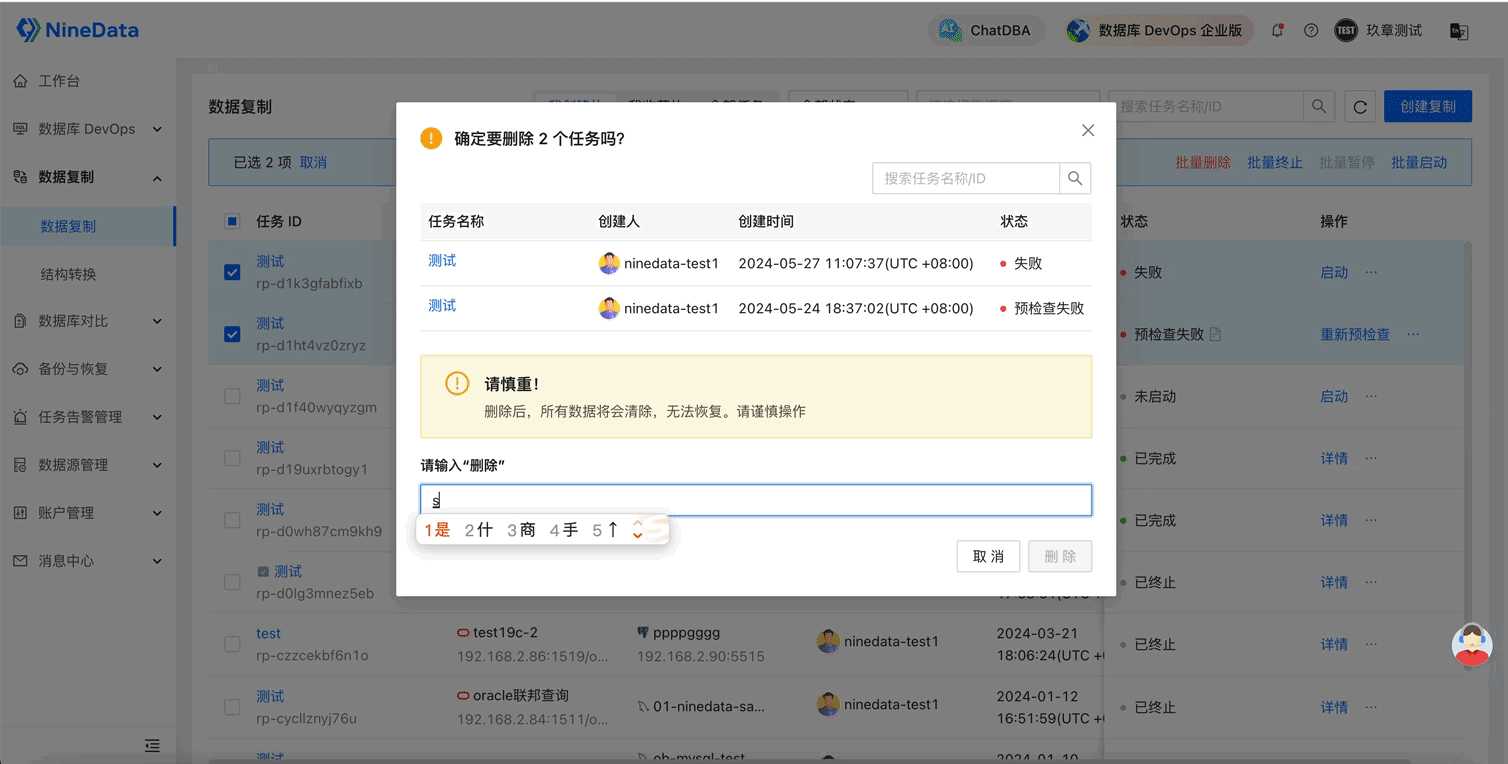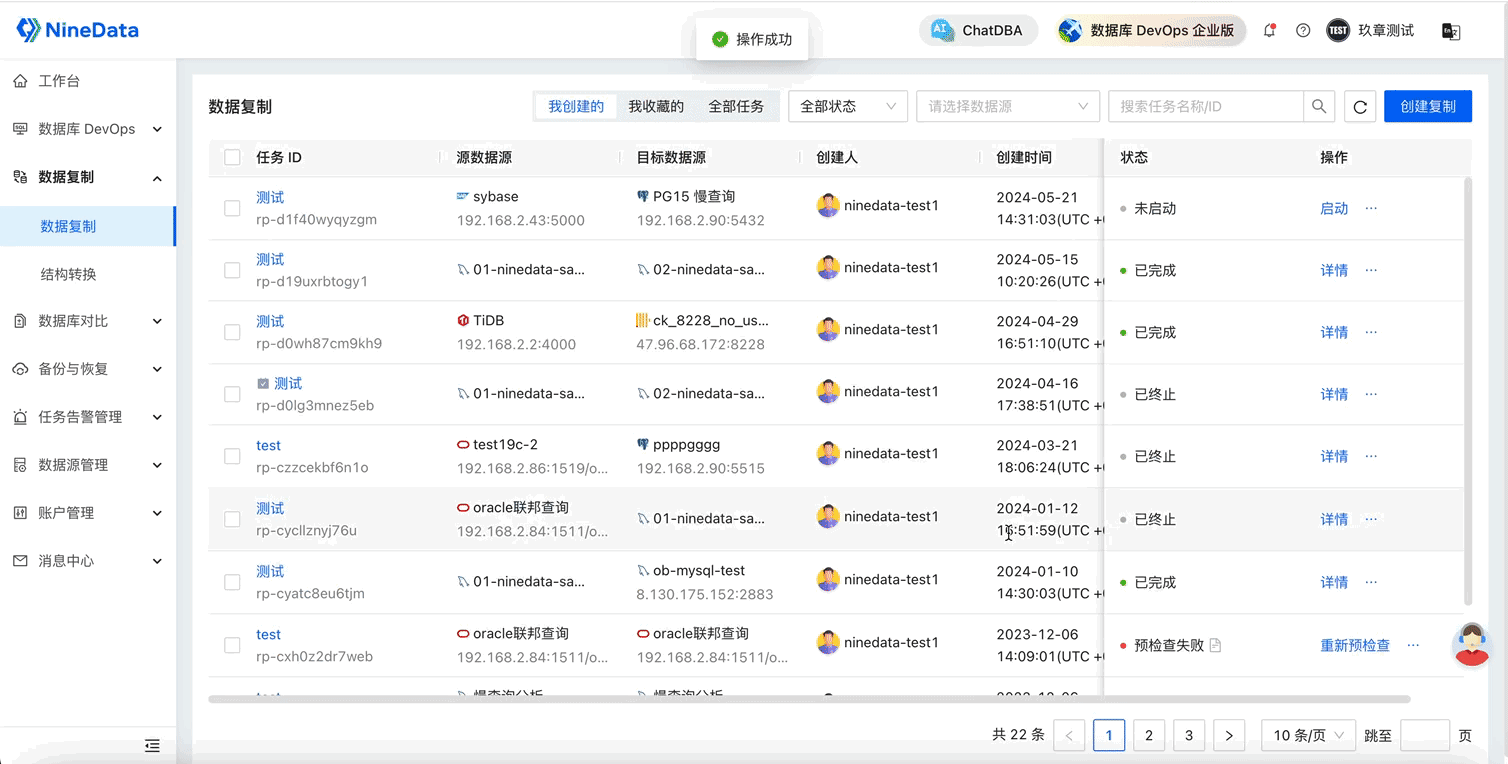
NineData云原生智能数据管理平台新功能发布|2024年5月版
重点发布 数据库 DevOps - 表分组查询 在企业用户规模达到一定程度后,分库分表成为一种常见的数据库架构选择。在这种情况下,查询和维护数据需要高效的解决方案,以避免手动逐一查询、变更和汇总多个分库和分表的繁琐操作。 库分组变更…...

【Android面试八股文】使用equals和==进行比较的区别?
使用equals和==进行比较的区别 这道题想考察什么 ? 在开发中当需要对引用类型和基本数据类型比较时应该怎么做,为什么有区别。 考察的知识点 equals 的实现以及栈和堆的内存管理 考生应该如何回答 在 Java 中,equals() 方法和 == 运算符用于比较对象之间的相等性,但它…...
利用架构挖掘增强云管理
管理当今复杂的云环境比以往任何时候都更加重要。 大多数企业依赖 AWS、Azure、Kubernetes 和 Microsoft Entra ID 等各种平台来支持其运营,但管理这些平台可能会带来重大挑战。 云优化的最大挑战涉及安全性、成本管理和了解云基础设施内错综复杂的相互依赖关系。…...
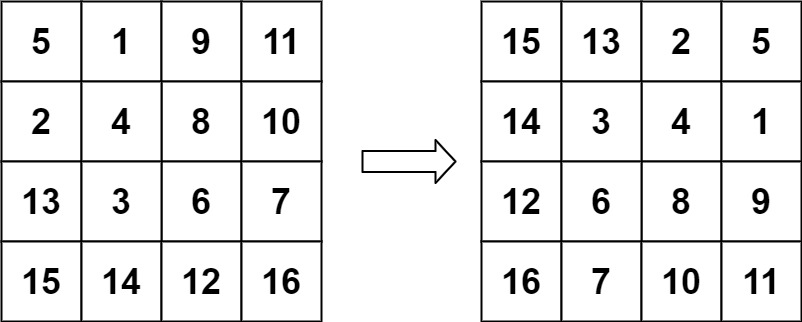
力扣 48.旋转图像
题目描述: 给定一个 n n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。 你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。 示例 1: 输入:matrix [[1,2,3],…...

前端角色负责人岗
定位: 有效搭建、领导、优化一个自驱力强的前端团队,通过制度和工具把控质量和提高团队的生产力。 素质要求: 资深的技术专家且在流程规范、技术上自成体系;团队基础建设和持续集成方面需要有丰富的经验;具备组织管…...

git根据历史某次提交创建新分支
有时候项目在做版本管理的时候,忘记了创建某次版本的分支,而直接在主分支上进行开发了,这个时候,想要对某次提交单独拉出来一个版本分支,就需要用到这个功能: git checkout -b 新分支名 某次提交的id 找到…...

如何评价GPT-4o?GPT-4o和ChatGPT4.0的区别是啥呢?
如何评价GPT-4o? GPT-4o代表了人工智能领域的一个重要里程碑,它不仅继承了GPT-4的强大智能,还在多模态交互方面取得了显著进步。以下是几个方面的分析: 技术特点 多模态交互能力:GPT-4o支持文本、音频和图像的任意组合输入与输出…...

从零开始:用EmbeddingGemma-300M搭建学术论文溯源系统
从零开始:用EmbeddingGemma-300M搭建学术论文溯源系统 1. 学术论文溯源系统的核心价值 在科研工作中,我们经常遇到这样的困境:阅读一篇论文时,发现某个重要结论似曾相识,却怎么也想不起具体出处;或是想验…...

Navicat Premium 16快捷键全攻略:从SQL注释到窗口切换,提升效率的10个必备技巧
Navicat Premium 16快捷键全攻略:从SQL注释到窗口切换,提升效率的10个必备技巧 在数据库管理的日常工作中,效率往往取决于细节。Navicat Premium 16作为一款功能强大的数据库管理工具,其快捷键系统就像隐藏在界面之下的效率引擎。…...

大模型实习复盘:GPT老师带你一个个接口硬啃
总结:互联网中厂大厂,尤其是给你权限给你机器玩的,去,提升极大。小公司or普通研究院,非常一般。一段实习,通常需要满足一些前置的技术条件才能拿到offer。但offer只是开始,还需要自己有意识地在…...

Qtile配置终极指南:10个Python配置文件编写技巧
Qtile配置终极指南:10个Python配置文件编写技巧 【免费下载链接】qtile :cookie: A full-featured, hackable tiling window manager written and configured in Python (X11 Wayland) 项目地址: https://gitcode.com/gh_mirrors/qt/qtile Qtile是一款功能全…...

Fader库:Arduino轻量级软件PWM LED渐变控制方案
1. Fader库概述:面向嵌入式LED调光的轻量级PWM渐变控制方案Fader是一个专为Arduino平台设计的轻量级LED亮度渐变控制库,其核心目标是提供一种资源占用极低、响应迅速且易于集成的软件PWM渐变方案。在资源受限的8位MCU(如ATmega328P࿰…...

MySQL 索引特性与性能优化全解
🔥草莓熊Lotso:个人主页 ❄️个人专栏: 《C知识分享》 《Linux 入门到实践:零基础也能懂》 ✨生活是默默的坚持,毅力是永久的享受! 🎬 博主简介: 文章目录前言:一. 索引是什么1.1 初…...

词云AI电话机器人在金融风控与合规通知的核心价值与应用场景-系列五
金融行业对风控与合规的要求极高:逾期提醒不能断,交易核实不能慢,授信通知不能错,续保提醒不能漏。词云AI电话机器人以自动化、可留痕、高并发的智能外呼能力,承担风险预警、交易核实、授信告知、还款与续保提醒等高频…...

Windows下OpenClaw安装指南:快速接入SecGPT-14B安全模型
Windows下OpenClaw安装指南:快速接入SecGPT-14B安全模型 1. 为什么选择OpenClawSecGPT-14B组合 去年我在做安全日志分析时,每天要手动检查数百条告警,直到发现OpenClaw这个能直接操控本地电脑的AI智能体框架。配合专门训练的安全大模型SecG…...

OpenClaw开发提效指南:Qwen3-14b_int4_awq辅助日志分析与命令执行
OpenClaw开发提效指南:Qwen3-14b_int4_awq辅助日志分析与命令执行 1. 为什么开发者需要OpenClaw 作为一名全栈开发者,我每天要处理数十个项目的日志文件、执行测试脚本、生成汇总报告。这些重复性工作不仅枯燥,还容易出错。直到我发现OpenC…...

WPS样式与题注的隐藏用法:这样设置,让你的技术文档像专业手册一样清晰
WPS样式与题注的隐藏用法:这样设置,让你的技术文档像专业手册一样清晰 在技术文档撰写领域,格式混乱往往是内容质量的第一杀手。想象一下这样的场景:当你需要修改某个章节标题时,所有交叉引用的图表编号都需要手动更新…...