探索大模型技术及其前沿应用——TextIn文档解析技术
前言
中国图象图形大会(CCIG 2024)于近期在西安召开,此次大会将面向开放创新、交叉融合的发展趋势,为图像图形相关领域的专家学者和产业界同仁,搭建一个展示创新成果、展望未来发展,集高度、深度、广度三位于一体的交流平台。大会期间,合合信息智能创新事业部研发总监常扬做了《文档解析技术加速大模型训练与应用》主题报告,介绍了TextIn文档解析技术的技术特征。下面为大家分享一下这次报告的主要内容。
发展现状
目前大模型训练和应用过程中面临训练Token耗尽、训练语料质量要求高、LLM文档问答应用中文档解析不精准的问题。目前互联网能够提供的语料资源预计将在2026年耗尽,提升大模型应用效果需要更多更高质量的语料。同时文档类语料(chart-pdf或chart-excel等)识别精度很差,严重影响模型应用效果。
而目前提高大模型训练效果最佳场景集中于书籍、论文等文档中,而它们往往都是PDF格式,甚至是图片扫描件。我们再训练时需要对这些文档进行文档格式识别、图表内容及标题提取、版面正确解析、阅读顺序处理的转换,同时要确保转换速度足够快。比如下面这个gpt阅读文档的例子: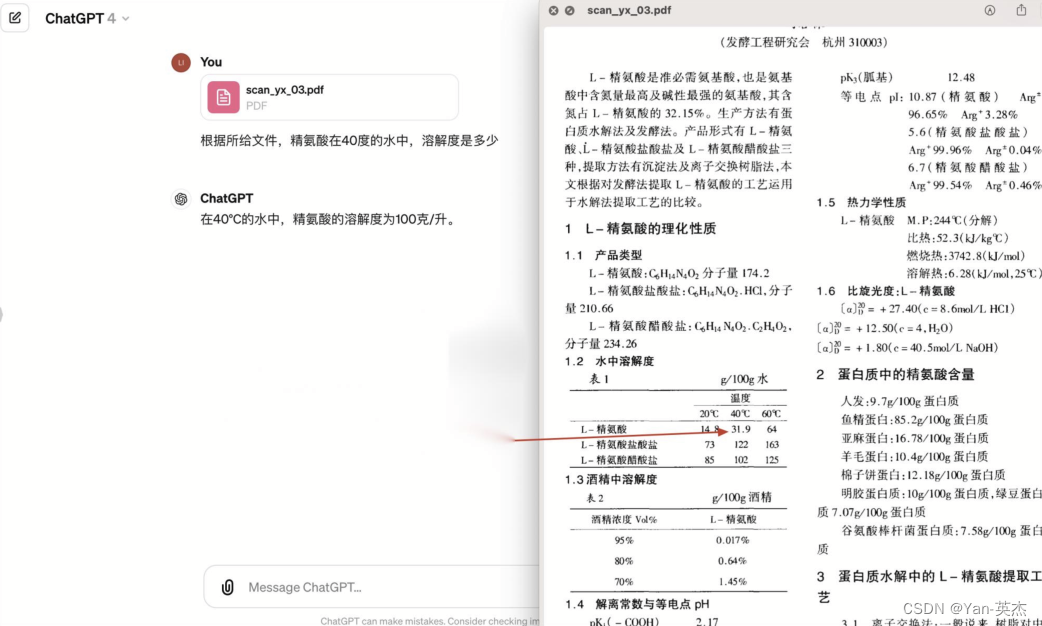
在这个例子中,由于文章包含一个非标准的列表,使得大模型没有识别到内容。

这个例子中,由于双栏排版使得大模型识别到了错误的内容。这些例子都说明目前迫切需要一个具备多文档元素识别、版面分析、高性能的文档解析技术,并将其应用在大模型的准备过程中。
技术难点
由于文档版式多样,模型很难有一个统一的处理方式。比如下面的一些例子:

在这个例子中,页眉的形式多种多样,没有统一的格式。
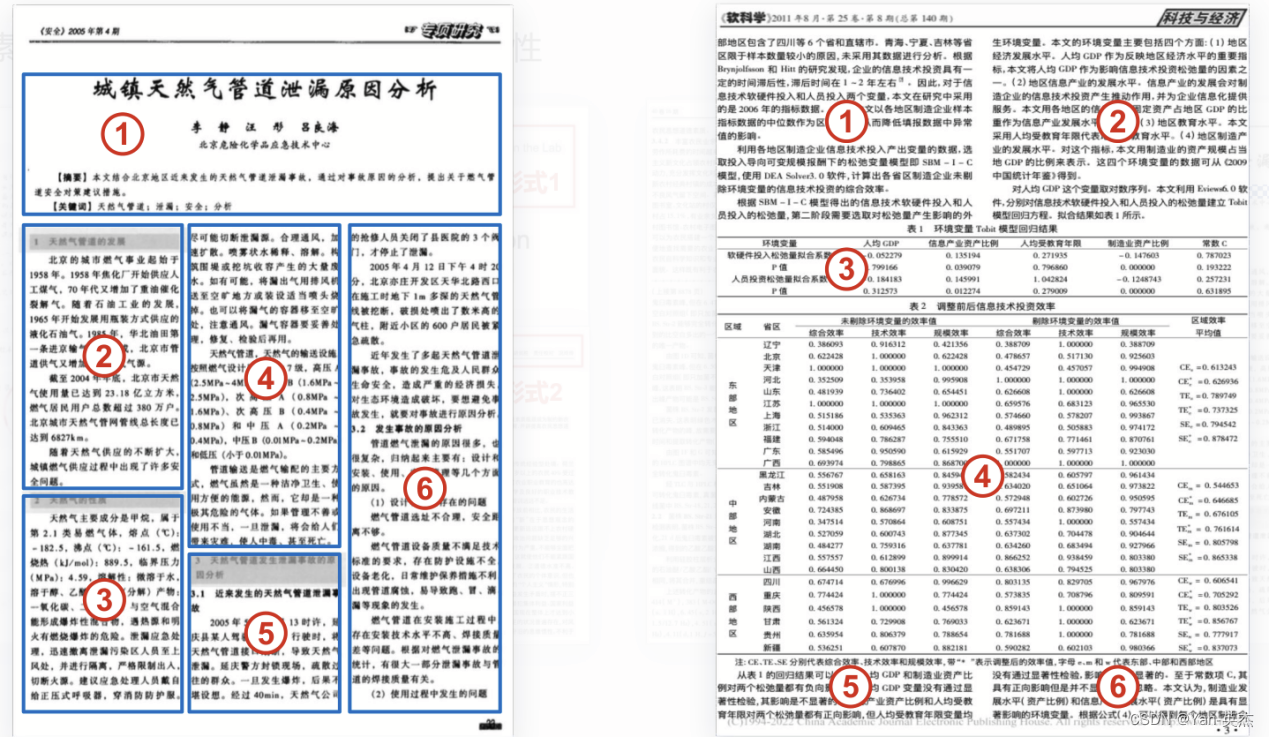
这个例子中表格和多栏排版混合为文档解析增加了困难。
这个例子中无线表格和合并单元格会使得文字无法定位。

这个例子中,公式的出现阻碍了文字信息的识别和提取。
在这些例子里,我们观察到有元素遮盖、重叠,元素(页眉页脚等)有多样性;版式(双栏、跨页、三栏)造成的阅读顺序差异,多栏中插入表格的影响,无线表格以及单元格合并拆分带来的识别困难,单行公式、行内公式以及表格内公式的影响等等一些问题。
TextIn文档解析技术
针对上面的问题,合合信息研发了TextIn文档解析技术,它专注于处理电子档、扫描件。在识别到文档类型后会提取其中的文字,之后基于合合信息多年的技术积累,对文档进行物理和逻辑版面分析。整个处理流程如下:
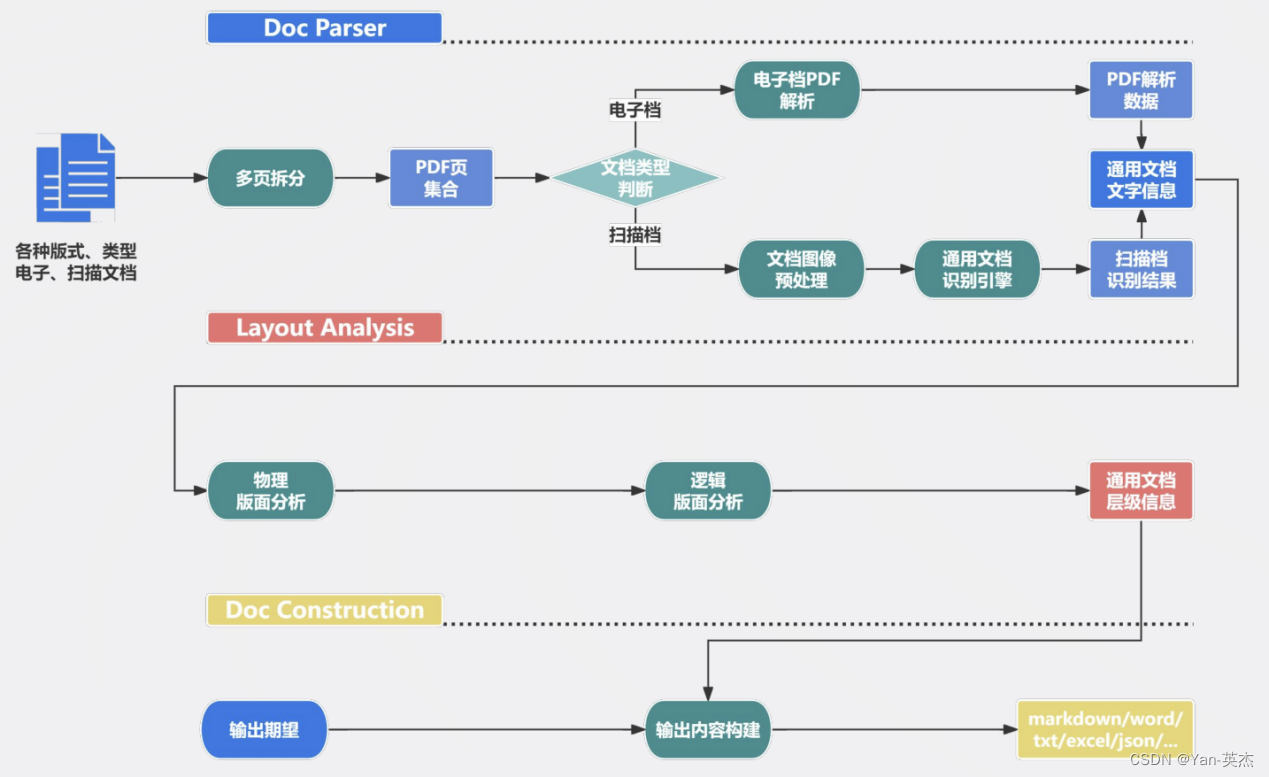
首先将各种类型的文档进行多页拆分,之后按照文档类型进行对应的预处理,然后提取文档数据,整合为通用文档文字信息。之后再对文档进行物理版面分析以及逻辑版面分析,将其与文字信息合并为一个通用文档层级信息。最后依据模型训练需求,将结果转换为指定的格式。
核心技术
TextIn的核心技术选用了业界领先的模块,旨在实现高精度的文档解析效果。这些模块涵盖了文档图像预处理算法、版面分析算法框架以及逻辑版面分析算法,具体功能如下:
文档图像预处理算法包括区域提取、干扰去除、形变矫正、图像恢复和图像增强等模块。这些模块的主要任务是提升文字信息提取的准确性和效率。
区域提取可以识别并提取出文档中具有文字信息的区域,确保后续处理聚焦在有用的部分。

形变矫正通过分析形变文档的偏移场,将其矫正为正常的图像,并利用附近的像素点填充缺失部分,确保图像的完整性。

图像恢复和图像增强则进一步优化图像质量,使得文字信息更加清晰和易于识别。图像文档干扰去除算法使用U2net卷积提取出图像的背景,然后通过cab技术去除干扰,得到一个更高质量的图像。

版面分析算法框架分为物理版面分析和逻辑版面分析两个主要模块。物理版面分析侧重于视觉特征,识别文档中的各个元素,将相关性高的文字聚合到一个区域,这一过程主要关注文档的视觉布局和结构。逻辑版面分析则侧重于语义特征,聚焦于文档结构,其主要任务是通过语义建模将不同的文字块形成层次结构,例如通过树状结构展示文档的语义层次关系。检测模型选用了单阶段的检测模型,关注小规模数据和模型的调优,以提升识别精度

文档布局分析将文档转换为标准的“页-节-段-切片”层次化布局,有助于系统更高效地处理文档内容。

大模型在工作时,先定位目标页面,再寻找相关切片,从而提高运行速度和精度。逻辑版面分析算法通过预测每个段落与上一个段落的关系,将其分为子标题、子段落、合并、旁系、主标题、表格标题等类型。如果是旁系类型,则继续向上查找父节点,并判断其层级关系,直至找到最终的父节点。
通过这一系列技术,TextIn在文档解析工作上展现了卓越的效果。

此外,在与生成式模型的配合应用上,TextIn同样表现出色,进一步提升了文档解析和处理的整体性能。
技术解析
DocUNet网络
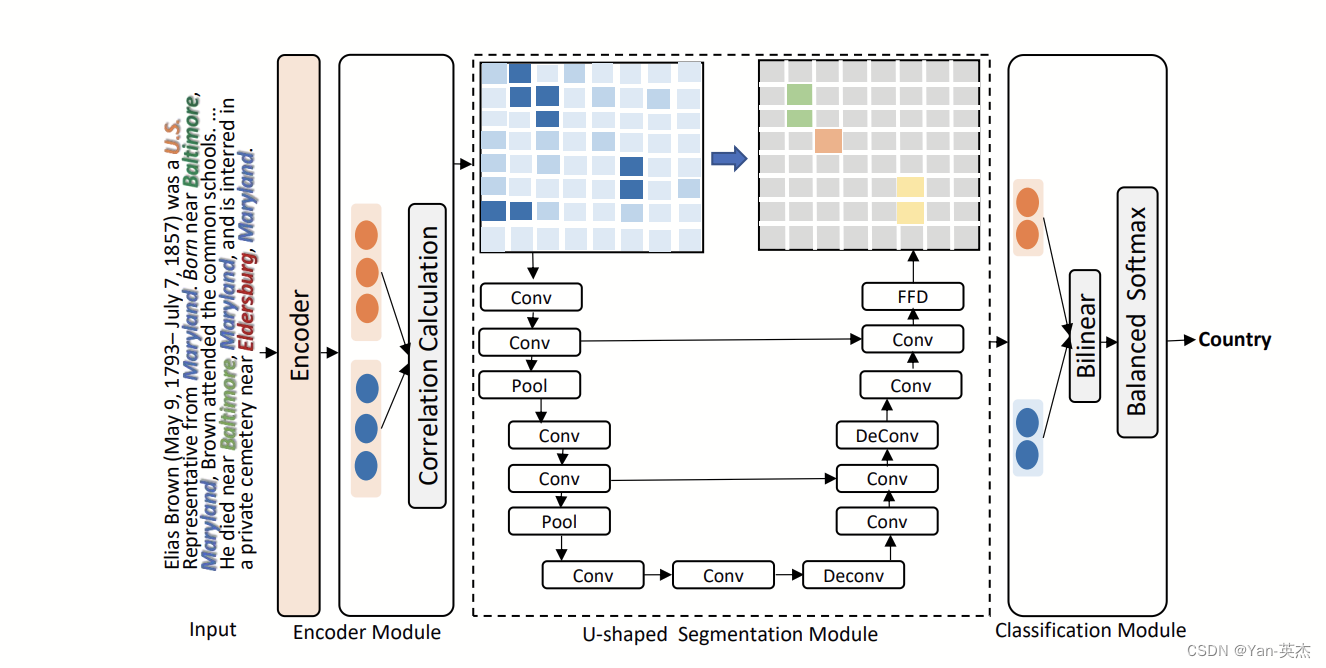
DocUNet模型可以捕获文档级RE的三元组之间的本地上下文信息和全局相互依赖性,将文档级RE表述为语义分割。具体来说,用一个编码器模块来捕获实体的上下文信息,并引用一个U形分割模块来捕获图像样式特征图上的三元组之间的全局相互依赖性。它的主要步骤是:首先通过一个编码器提取输入图像的特征,然后计算相关性并传入U形分割模块进行预测,最后通过损失函数调整结果,进行分类。
U2Net网络
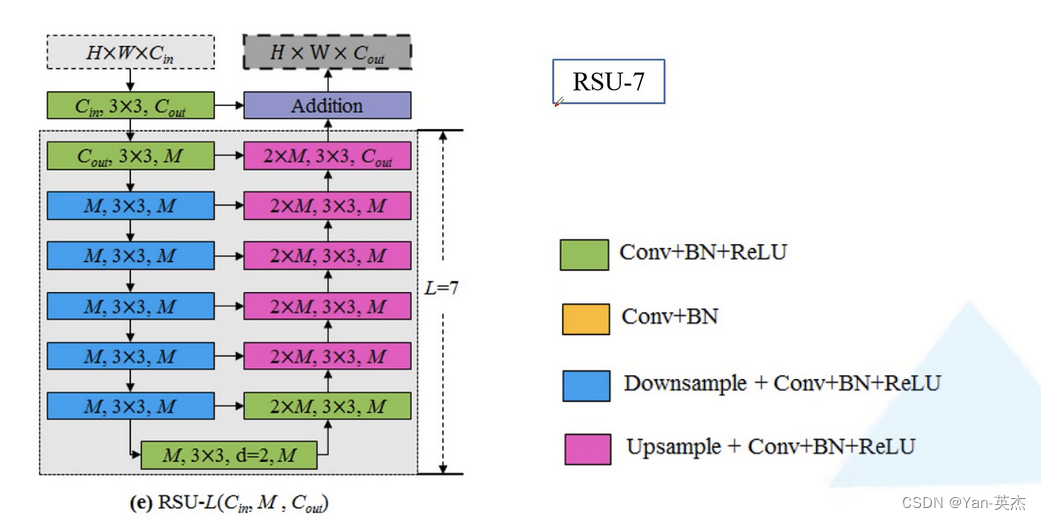
U2net是一种用于图像分割的神经网络模型。它的网络结构为大型的U-net结构的每一个block里面也为U-net结构。其中Block总共分两种,一种是Encoder1-4以及Decoder1-4,另一种是Encoder5-6和Decoder5。

第一种block在Encoder阶段,每通过一个block后都会通过最大池化层下采样2倍,在Decoder阶段,通过每一个block前都会用双线性插值进行上采样。如下图,绿色代表卷积+BN+ReLU,蓝色代表下采样+卷积+BN+ReLU,紫色代表上采样+卷积+BN+ReLU,在RSU-7中下采样了5次,也即把输入特征图下采样了32倍,同样在Decoder阶段上采样了32倍还原为原始图像大小。
 第二种block是RSU-4F主要是在RSU-4的基础上,将下采样和上采样换成了膨胀卷积,整个过程中特征图大小不变。
第二种block是RSU-4F主要是在RSU-4的基础上,将下采样和上采样换成了膨胀卷积,整个过程中特征图大小不变。

在每个block工作完成后,将每个阶段的特征图进行融合,并对他们做3*3的卷积,卷积核个数为1,再用线性插值进行上采样恢复到原图大小,进行concat拼接,使用sigmoid函数输出最终分割结果。
Transformer模型
Transformer模型是近年大火的模型。它由多个编码器和解码器块堆叠构成,每个块包括两个子层:多头自注意力层和全连接前馈层。每个子层后增加了一个残差连接,并进行层归一化操作。
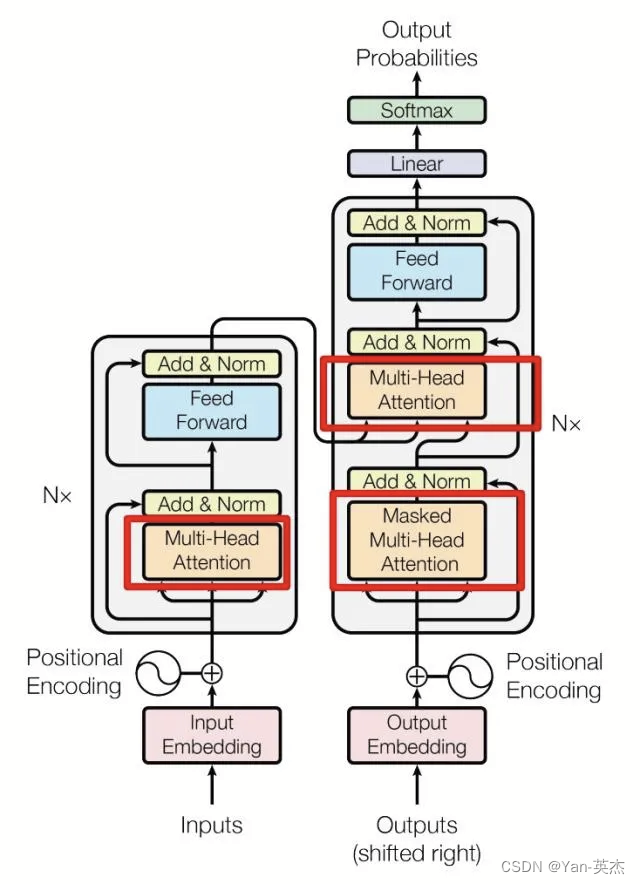
多头自注意力层包含若干自注意力层。自注意力层使用权重矩阵得到查询向量Q、键向量K和值向量V,带入公式即可得到输出,最终的输出即为前馈神经网络的输入。全连接前馈层包括一个两层的全连接网络和一个非线性激活函数。
残差连接与归一化层的引入可以解决梯度消失的问题。残差连接需要输入和输出的维度相同,此处将输出维度设置成 . 归一化将每一层神经元的输入都转成均值方差都一样的,可以加快收敛。
解码器相比编码器增加了一个多他自注意力层,并采用了掩码操作,目的是防止Q去对序列中尚未解码的位置施加操作。解码器输出结果经过线性连接后,由一个Softmax层计算预测值。
体验TextIn文本解析Demo
TextIn的官网上提供了一个对给定的句子列表进行向量化,并计算句子之间的相似度的案例。下面是详细步骤:
首先我们定义一个包含两个句子的列表 sentences。
sentences = ["数据1", "数据2"]之后使用 'acge_text_embedding' 预训练模型初始化 SentenceTransformer 对象,并将其赋值给 model 变量。
model = SentenceTransformer('acge_text_embedding')接下来使用 model.encode() 方法对 sentences 列表中的句子进行向量化,得到两组嵌入向量 embeddings_1 和 embeddings_2。设置参数normalize_embeddings为True,表示归一化这些向量,使其长度为1。
embeddings_1 = model.encode(sentences, normalize_embeddings=True)
embeddings_2 = model.encode(sentences, normalize_embeddings=True)最后计算两组向量 embeddings_1 和 embeddings_2 之间的相似度。@ 符号表示矩阵乘法,embeddings_2.T 表示 embeddings_2 的转置矩阵。这将得到一个相似度矩阵 similarity,其中 similarity[i][j] 表示 sentences[i] 和 sentences[j] 之间的余弦相似度。
similarity = embeddings_1 @ embeddings_2.T完整代码如下:
from sentence_transformers import SentenceTransformersentences = ["数据1", "数据2"]
model = SentenceTransformer('acge_text_embedding')
print(model.max_seq_length)
embeddings_1 = model.encode(sentences, normalize_embeddings=True)
embeddings_2 = model.encode(sentences, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)总结
上海合合信息科技股份有限公司通过其智能文字识别技术TextIn文档解析在电子档解析和扫描档识别领域表现出色,保证了准确识别且不漏检、不错检。该技术在处理无线表、跨页表格、页眉、页脚、公式、图像、印章、流程图、目录树等元素方面非常出色。此外,TextIn文档解析已经适配云服务集群,在云服务方面综合体验良好,速度快、服务稳定,能够实现100页PDF解析工作最快1.46秒。上海合合信息科技股份有限公司还致力于为全球企业和个人用户提供创新的数字化、智能化服务,其开发的C端产品全球累计用户下载超过23亿,月活跃用户约1.3亿,其中名片全能王和扫描全能王免费版在App Store排行榜上名列前茅。
相关文章:
探索大模型技术及其前沿应用——TextIn文档解析技术
前言 中国图象图形大会(CCIG 2024)于近期在西安召开,此次大会将面向开放创新、交叉融合的发展趋势,为图像图形相关领域的专家学者和产业界同仁,搭建一个展示创新成果、展望未来发展,集高度、深度、广度三位…...

Java HashMap 扩容机制深度解析
HashMap 的一个关键性能优化就是扩容机制,即在哈希表达到一定负载因子时,自动进行扩容,以保持检索效率。 在这篇文章中,我们将深入研究 HashMap 的扩容机制,了解其原理和影响因素。 1. 初始容量和负载因子 在深入了解…...

一、Electron 环境初步搭建
新建一个文件夹,然后进行 npm init -y 进行初始化,然后我们在进行 npm i electron --save-dev , 此时我们按照官网的教程进行一个初步的搭建, 1.在 package.json 文件进行修改 {"name": "electron-ui","version…...

ffmpeg编码器编码元数据的过程以及编码前后的差异
编码方式为avcodec_send_frame:将原始帧发送到编码器进行编码 编码过程完成于avcodec_receive_packet:从编码器接收编码后的压缩数据,也就是说已经编码压缩完成了,并存储到avpacket中,此时元数据被分割成多个NALU单元&…...
AB测试学习(附有相关代码)
目录 一、基本概念1. 定义2. 作用3. 原理 二、实验基本原则三、实验步骤四、实验步骤详解1. 确定实验目的2. 确定实验变量3. 实验指标设计3.1 实验指标类型(按作用区分)3.1.1 核心指标3.1.2 驱动指标(跟踪指标)3.1.3 护栏指标 3.2…...
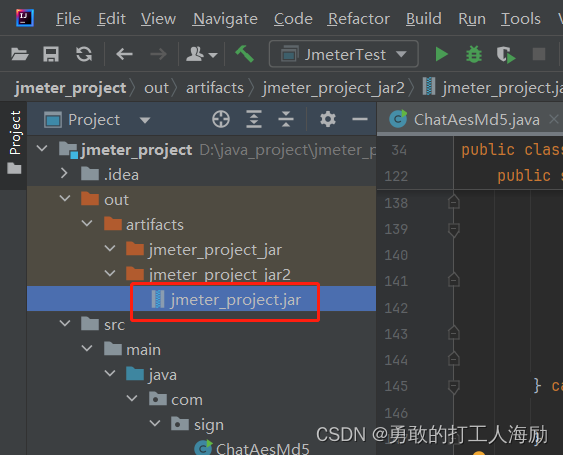
用idea将java文件打成jar包
一、用idea将java文件打成jar包 1、在idea上选择file—Project Structure 2、Artifacts —点–JAR—From modules with dependencies 3、选择要打包的java文件 4、Build — Build Artifacts 5、找到刚才添加的Artifacts直接Build 6、生成jar包文件...

Ansible——group模块
目录 参数总结 语法示例 创建用户组 删除用户组 设置组的 GID 创建系统组 修改组的 GID 添加用户组并附加其他组属性 删除指定 GID 的用户组 帮助信息 Playbook示例 基本示例 1. 创建用户组 2. 删除用户组 进阶示例 1. 修改组的 GID 2. 综合管理多个用户组 3…...
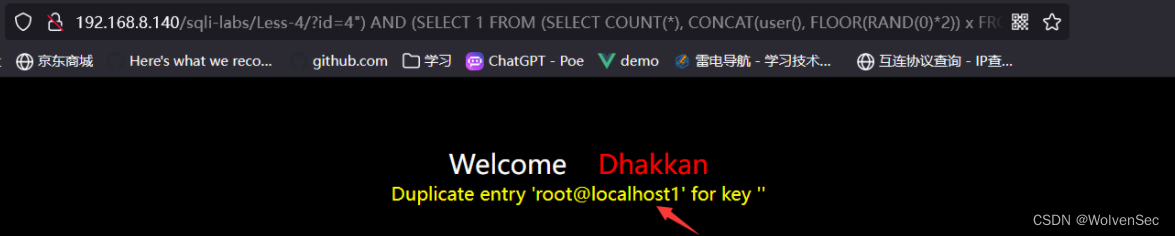
Sql注入-报错注入
报错注入(Error-Based Injection)是一种通过引起数据库报错并从错误信息中提取有用信息的SQL注入攻击手法;攻击者利用数据库在处理异常情况时返回的错误消息,来推断出数据库结构、字段名甚至数据内容;这种攻击方法依赖…...

pyqt 回车触发两次editingFinished的解决办法
在英文Qt论坛看到的解决办法 def editingFinished_triger(self):#self.sender() is the QlineEditif not self.sender().isModified(): returnself.sender().setModified(False)#treat code ...#treat code ...下面是一个错误使用editingFinished的例子 在上面界面中有一个文本…...
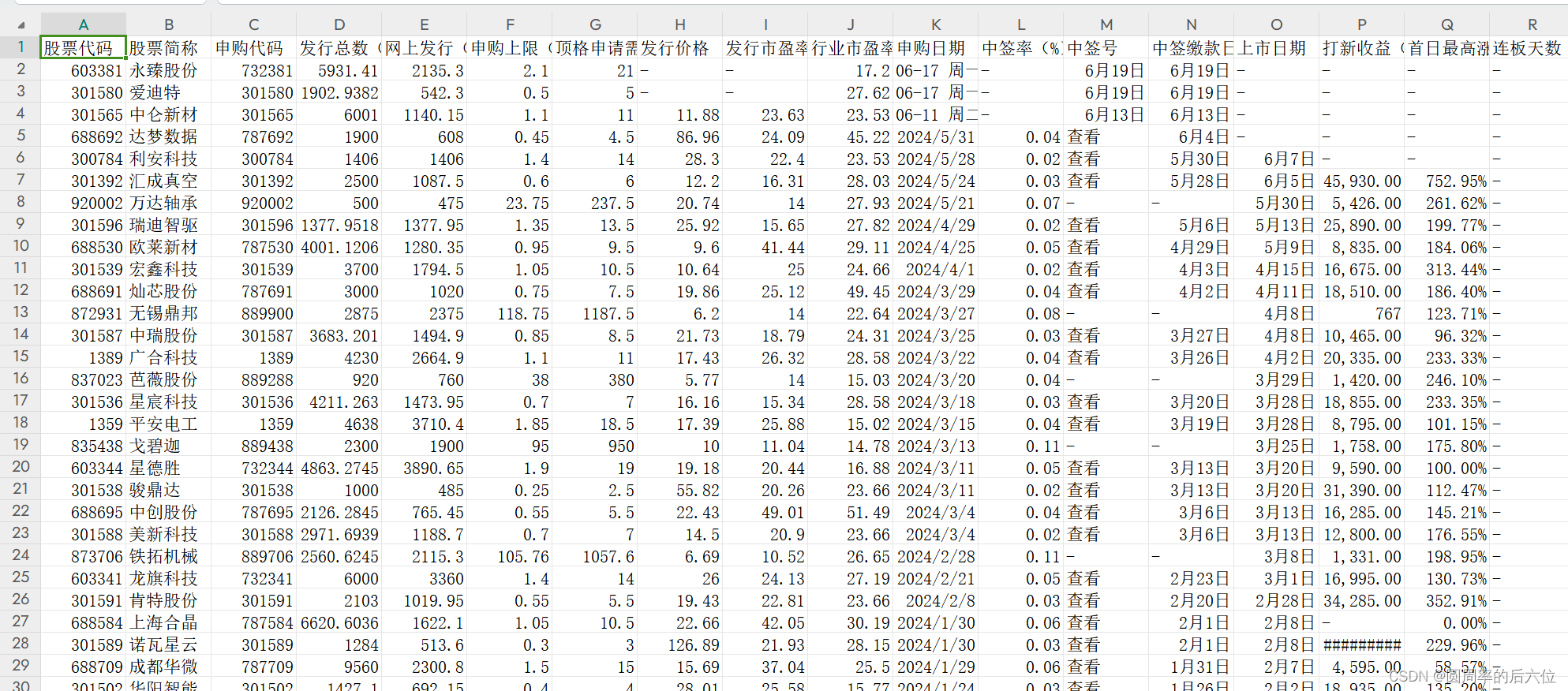
爬取股票数据python
最近在搜集数据要做分析,一般的数据来源是一手数据(生产的)和二手数据(来自其他地方的)。 今天我们爬取同花顺这个网站的数据。url为:https://data.10jqka.com.cn/ipo/xgsgyzq/ 话不多说直接上代码。有帮…...

每日新闻掌握【2024年6月4日 星期二】
2024年6月4日 星期二 农历四月廿八 TOP大新闻 张雪峰近2万元志愿填报服务已售罄 2024年高考临近,考生紧张的是考场上能否如常发挥,而考场之下,家长们已经开始为孩子的志愿填报焦心。峰学蔚来是由张雪峰打造专门提供高考志愿填报服务的APP&am…...
智谱AI 发布最新开源模型GLM-4-9B,通用能力超Llama-3-8B,多模态版本比肩GPT-4V
自 2023 年 3 月 14 日开源 ChatGLM-6B 以来,GLM 系列模型受到广泛关注和认可。特别是 ChatGLM3-6B 开源以后,开发者对智谱AI 第四代模型的开源充满期待。 为了使小模型(10B 以下)具备更加强大的能力,GLM 技术团队进行…...
从写简历到谈薪资的最全教程
从写简历到谈薪资的最全教程 目录简历注意事项举个例子写简历投递简历也有技巧模拟面试的重要性面试经验怎么刷不断迭代达越来越强斗智斗勇谈薪资拿到offer就结束了吗?我能给你的帮助 目录 大家好,我是一名普通本科毕业的学生,工作数年&#…...
)
Vue3 响应式API:高级函数(二)
shallowRef() shallowRef 是一个特殊的 ref 创建函数,它允许你创建一个只追踪顶层属性变化的响应式引用。与 ref 不同的是,shallowRef 创建的响应式引用对其内部值的深层嵌套属性是不敏感的,也就是说,只有当 shallowRef 的 .valu…...
攻击?)
『大模型笔记』什么是提示词注入(Prompt Injection)攻击?
什么是提示词注入(Prompt Injection)攻击? 文章目录 一. 什么是提示词注入(Prompt Injection)?二. 参考文献一. 什么是提示词注入(Prompt Injection)? 想花1美元买一辆新SUV吗?有人真的尝试过这样做。事实上,他们在一家特定汽车经销商的网站聊天机器人上进行了尝试。为了…...

SD-WAN与IPSec的对比
在现代企业中,随着网络环境的日益复杂,SD-WAN和IPSec作为两种关键的网络技术,各有其独特的优势和应用场景。那么,SD-WAN和IPSec究竟有什么不同?企业在不同情况下应该选择哪种技术呢? SD-WAN和IPSec的基本概…...

Ceph入门到精通-ceph经典盘符飘逸问题处理步骤
在Ceph存储系统中,"盘符飘逸"通常指的是Ceph OSD(Object Storage Daemon)使用的磁盘在系统重启后没有被正确挂载或识别。这可能是由于多种原因造成的,例如磁盘连接问题、驱动问题或配置错误。以下是解决此问题的步骤: 确认磁盘状态: 使用lsblk或fdisk -l命令来…...

【CV算法工程师必看】作为一个图像算法工程师,需要会什么,要学哪些技术栈?
作为一个图像算法工程师,除了基本的编程技能和理论知识,还需要掌握一系列的技术栈。以下是详细的技能和技术栈分类: 编程语言 Python: 主要用于快速开发和原型设计。常用库:OpenCV、Pillow、NumPy、SciPy、Scikit-image、TensorFlow、PyTorch。C++: 高性能要求的项目中广…...

【造化弄人:计算机系大学生真的象当年的高速公路收费员一样吗?】
曾经高速公路的收费员是多么的自豪和骄傲,按照常逻辑,车是越来越多,收费员应该越来越多?但现实情况,大家有目共睹! 不论你的车子怎么跑,只要上高速就要交费,那时候的收费员…...

民主测评要做些什么?
民主测评,作为一种重要的民主管理工具,旨在通过广泛征求群众意见,对特定对象或事项进行客观、公正的评价。它不仅是推动民主参与、民主监督的重要手段,也是提升治理效能、促进社会和谐的有效途径。以下将详细介绍民主测评的主要过…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...